 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learned end-to-end high-resolution lensless fiber imaging toward intraoperative real-time cancer diagnosis
Feb 28, 2022
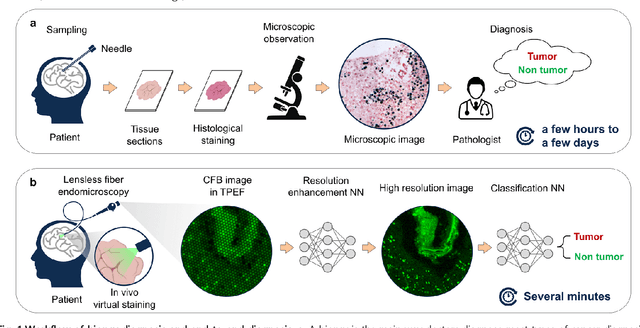
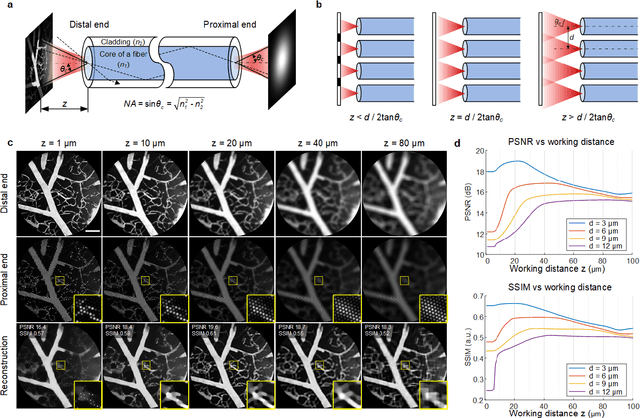
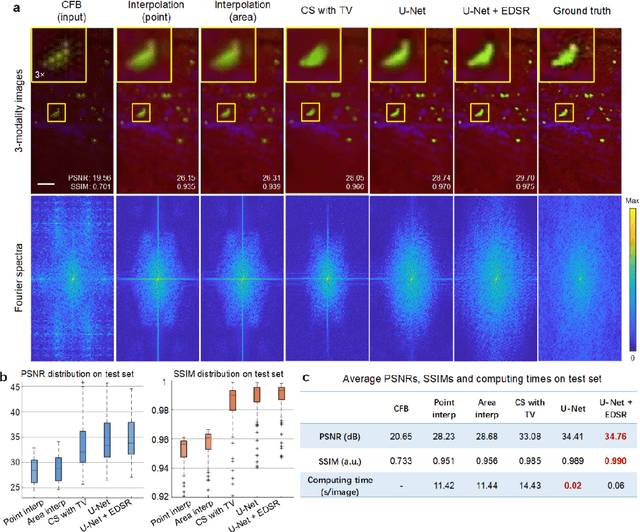
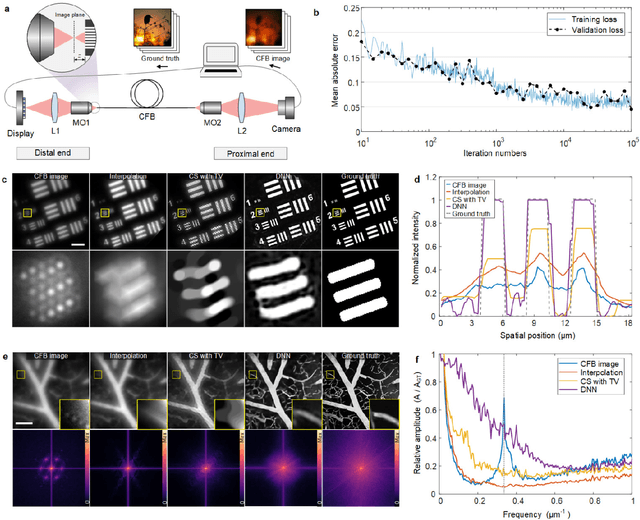
Endomicroscopy is indispensable for minimally invasive diagnostics in clinical practice. For optical keyhole monitoring of surgical interventions, high-resolution fiber endoscopic imaging is considered to be very promising, especially in combination with label-free imaging techniques to realize in vivo diagnosis. However, the inherent honeycomb-artifacts of coherent fiber bundles (CFB) reduce the resolution and limit the clinical applications. We propose an end-to-end lensless fiber imaging scheme toward intraoperative real-time cancer diagnosis. The framework includes resolution enhancement and classification networks that use single-shot fiber bundle images to provide both high-resolution images and tumor diagnosis result. The well-trained resolution enhancement network not only recovers high-resolution features beyond the physical limitations of CFB, but also helps improving tumor recognition rate. Especially for glioblastoma, the resolution enhancement network helps increasing the classification accuracy from 90.8% to 95.6%. The novel technique can enable histological real-time imaging through lensless fiber endoscopy and is promising for rapid and minimal-invasive intraoperative diagnosis in clinics.
Channel Modeling for UAV-to-Ground Communications with Posture Variation and Fuselage Scattering Effect
Oct 11, 2022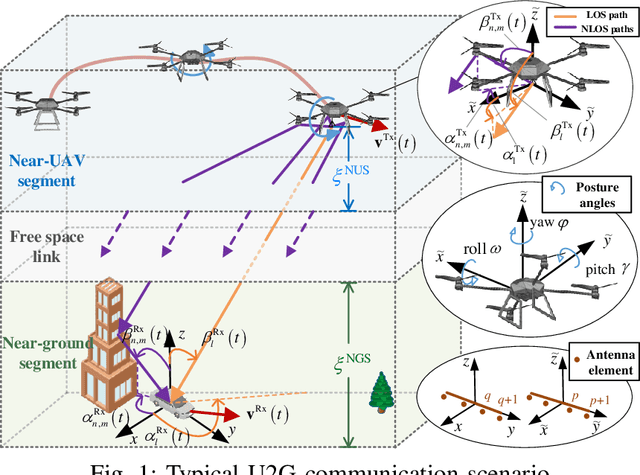
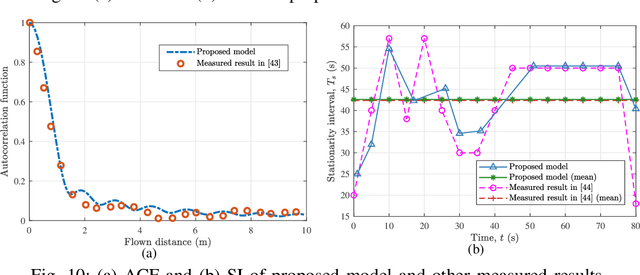
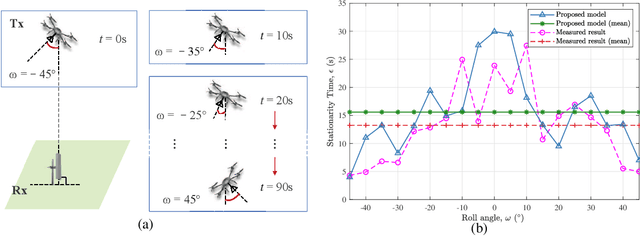
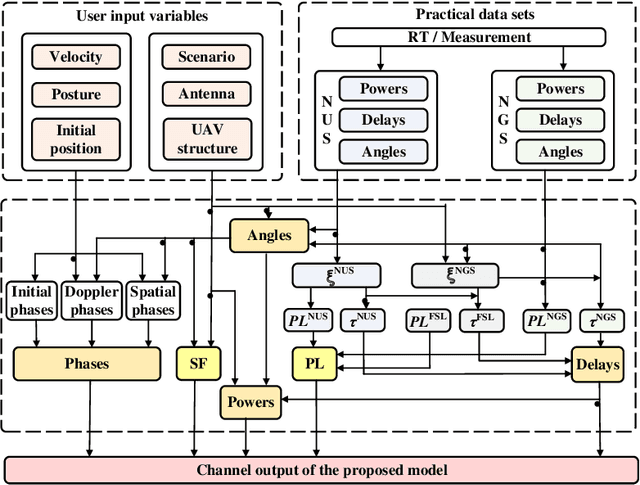
Unmanned aerial vehicle (UAV)-to-ground (U2G) channel models play a pivotal role for reliable communications between UAV and ground terminal. This paper proposes a three-dimensional (3D) non-stationary hybrid model including both large-scale and small-scale fading for U2G multiple-input-multiple-output (MIMO) channels. Distinctive channel characteristics under U2G scenarios, i.e., 3D trajectory and posture of UAV, fuselage scattering effect (FSE), and posture variation fading (PVF), are incorporated into the proposed model. The channel parameters, i.e., path loss (PL), shadow fading (SF), path delay, and path angle, are generated incorporating machine learning (ML) and ray tracing (RT) techniques to capture the structure-related characteristics. In order to guarantee the physical continuity of channel parameters such as Doppler phase and path power, the time evolution methods of inter- and intra- stationary intervals are proposed. Key statistical properties , i.e., temporal autocorrection function (ACF), power delay profile (PDP), level crossing rate (LCR), average fading duration (AFD), and stationary interval (SI) are given, and the impact of the change of fuselage and posture variation is analyzed. It is demonstrated that both posture variation and fuselage scattering have crucial effects on channel characteristics. The validity and practicability of the proposed model are verified by comparing the simulation results with the measured ones.
The Typical Behavior of Bandit Algorithms
Oct 11, 2022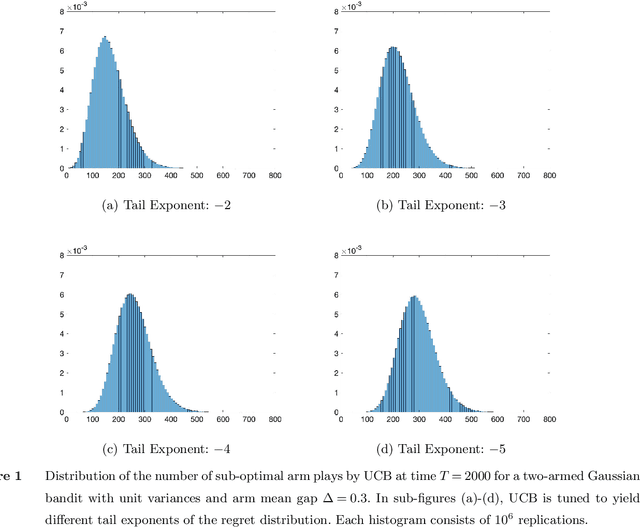
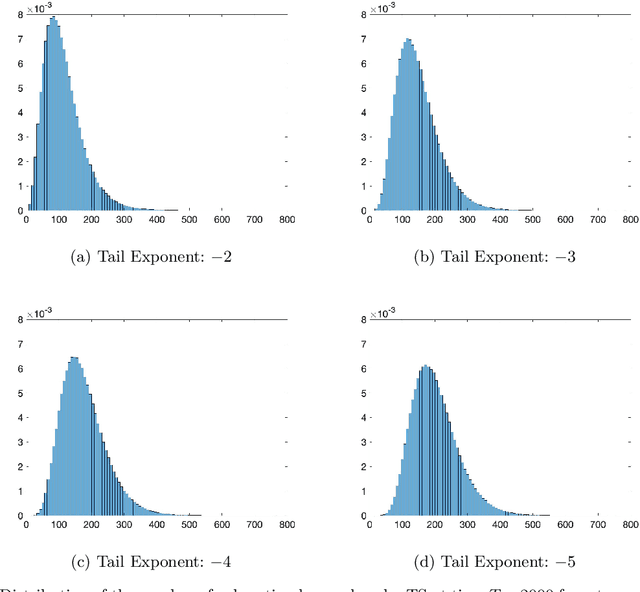
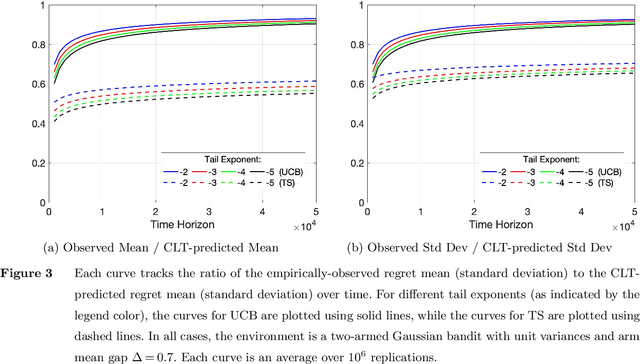
We establish strong laws of large numbers and central limit theorems for the regret of two of the most popular bandit algorithms: Thompson sampling and UCB. Here, our characterizations of the regret distribution complement the characterizations of the tail of the regret distribution recently developed by Fan and Glynn (2021) (arXiv:2109.13595). The tail characterizations there are associated with atypical bandit behavior on trajectories where the optimal arm mean is under-estimated, leading to mis-identification of the optimal arm and large regret. In contrast, our SLLN's and CLT's here describe the typical behavior and fluctuation of regret on trajectories where the optimal arm mean is properly estimated. We find that Thompson sampling and UCB satisfy the same SLLN and CLT, with the asymptotics of both the SLLN and the (mean) centering sequence in the CLT matching the asymptotics of expected regret. Both the mean and variance in the CLT grow at $\log(T)$ rates with the time horizon $T$. Asymptotically as $T \to \infty$, the variability in the number of plays of each sub-optimal arm depends only on the rewards received for that arm, which indicates that each sub-optimal arm contributes independently to the overall CLT variance.
CASAPose: Class-Adaptive and Semantic-Aware Multi-Object Pose Estimation
Oct 11, 2022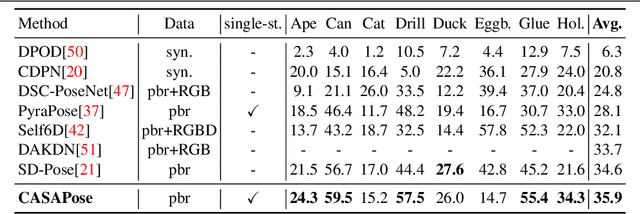

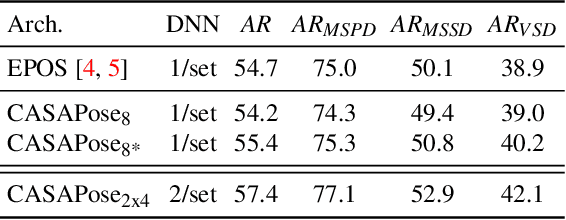
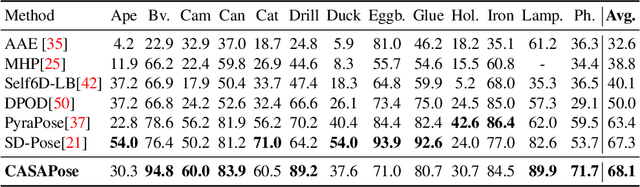
Applications in the field of augmented reality or robotics often require joint localisation and 6d pose estimation of multiple objects. However, most algorithms need one network per object class to be trained in order to provide the best results. Analysing all visible objects demands multiple inferences, which is memory and time-consuming. We present a new single-stage architecture called CASAPose that determines 2D-3D correspondences for pose estimation of multiple different objects in RGB images in one pass. It is fast and memory efficient, and achieves high accuracy for multiple objects by exploiting the output of a semantic segmentation decoder as control input to a keypoint recognition decoder via local class-adaptive normalisation. Our new differentiable regression of keypoint locations significantly contributes to a faster closing of the domain gap between real test and synthetic training data. We apply segmentation-aware convolutions and upsampling operations to increase the focus inside the object mask and to reduce mutual interference of occluding objects. For each inserted object, the network grows by only one output segmentation map and a negligible number of parameters. We outperform state-of-the-art approaches in challenging multi-object scenes with inter-object occlusion and synthetic training.
Trading Off Resource Budgets for Improved Regret Bounds
Oct 11, 2022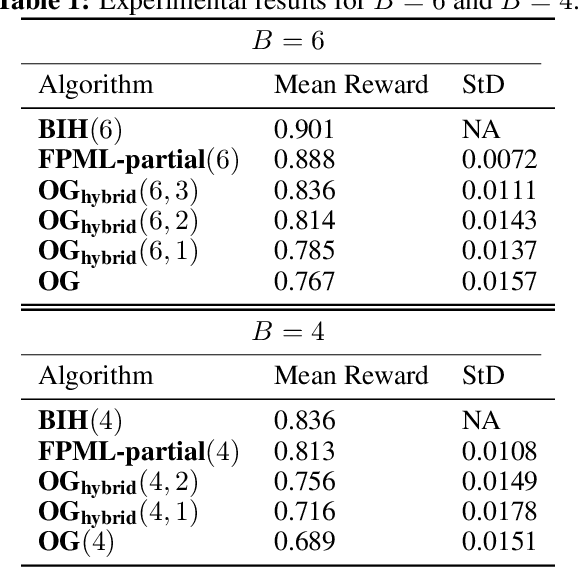
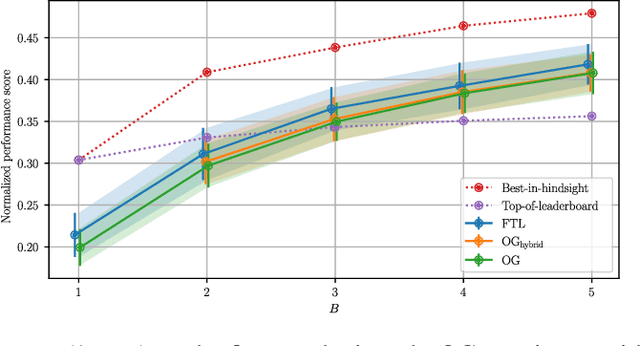
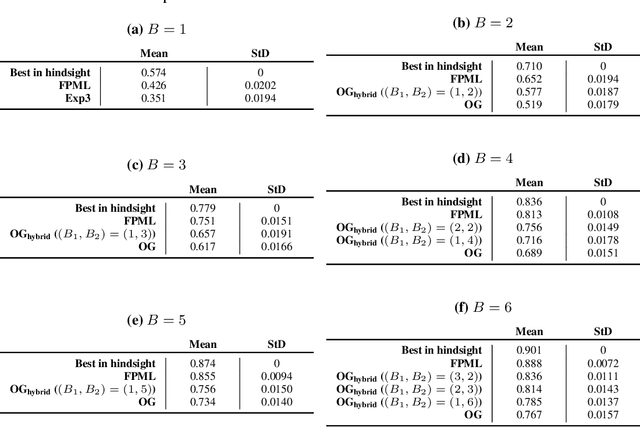
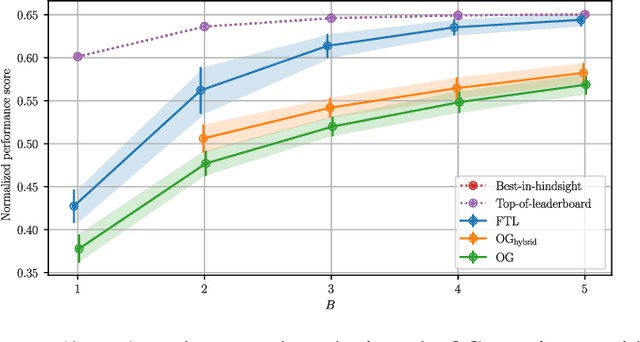
In this work we consider a variant of adversarial online learning where in each round one picks $B$ out of $N$ arms and incurs cost equal to the $\textit{minimum}$ of the costs of each arm chosen. We propose an algorithm called Follow the Perturbed Multiple Leaders (FPML) for this problem, which we show (by adapting the techniques of Kalai and Vempala [2005]) achieves expected regret $\mathcal{O}(T^{\frac{1}{B+1}}\ln(N)^{\frac{B}{B+1}})$ over time horizon $T$ relative to the $\textit{single}$ best arm in hindsight. This introduces a trade-off between the budget $B$ and the single-best-arm regret, and we proceed to investigate several applications of this trade-off. First, we observe that algorithms which use standard regret minimizers as subroutines can sometimes be adapted by replacing these subroutines with FPML, and we use this to generalize existing algorithms for Online Submodular Function Maximization [Streeter and Golovin, 2008] in both the full feedback and semi-bandit feedback settings. Next, we empirically evaluate our new algorithms on an online black-box hyperparameter optimization problem. Finally, we show how FPML can lead to new algorithms for Linear Programming which require stronger oracles at the benefit of fewer oracle calls.
ViFiCon: Vision and Wireless Association Via Self-Supervised Contrastive Learning
Oct 11, 2022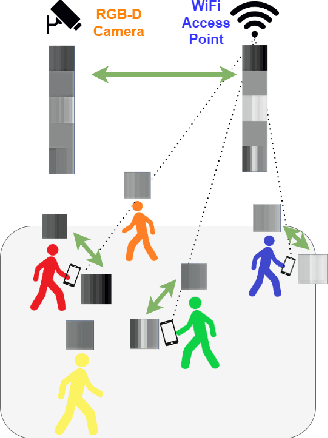

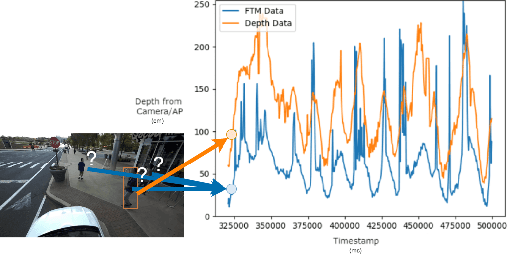

We introduce ViFiCon, a self-supervised contrastive learning scheme which uses synchronized information across vision and wireless modalities to perform cross-modal association. Specifically, the system uses pedestrian data collected from RGB-D camera footage as well as WiFi Fine Time Measurements (FTM) from a user's smartphone device. We represent the temporal sequence by stacking multi-person depth data spatially within a banded image. Depth data from RGB-D (vision domain) is inherently linked with an observable pedestrian, but FTM data (wireless domain) is associated only to a smartphone on the network. To formulate the cross-modal association problem as self-supervised, the network learns a scene-wide synchronization of the two modalities as a pretext task, and then uses that learned representation for the downstream task of associating individual bounding boxes to specific smartphones, i.e. associating vision and wireless information. We use a pre-trained region proposal model on the camera footage and then feed the extrapolated bounding box information into a dual-branch convolutional neural network along with the FTM data. We show that compared to fully supervised SoTA models, ViFiCon achieves high performance vision-to-wireless association, finding which bounding box corresponds to which smartphone device, without hand-labeled association examples for training data.
Zero-Order One-Point Estimate with Distributed Stochastic Gradient-Tracking Technique
Oct 11, 2022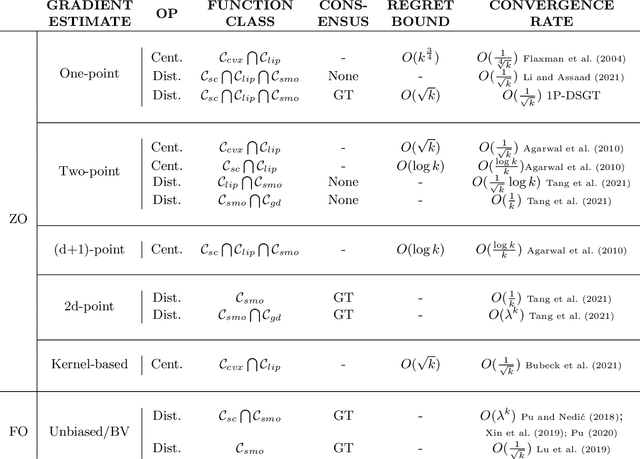
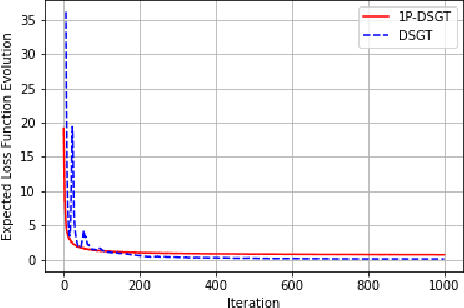
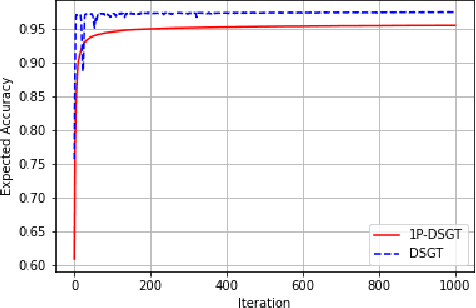
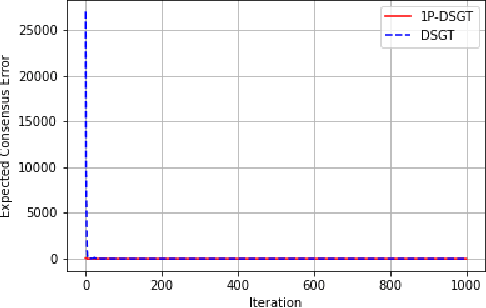
In this work, we consider a distributed multi-agent stochastic optimization problem, where each agent holds a local objective function that is smooth and convex, and that is subject to a stochastic process. The goal is for all agents to collaborate to find a common solution that optimizes the sum of these local functions. With the practical assumption that agents can only obtain noisy numerical function queries at exactly one point at a time, we extend the distributed stochastic gradient-tracking method to the bandit setting where we don't have an estimate of the gradient, and we introduce a zero-order (ZO) one-point estimate (1P-DSGT). We analyze the convergence of this novel technique for smooth and convex objectives using stochastic approximation tools, and we prove that it converges almost surely to the optimum. We then study the convergence rate for when the objectives are additionally strongly convex. We obtain a rate of $O(\frac{1}{\sqrt{k}})$ after a sufficient number of iterations $k > K_2$ which is usually optimal for techniques utilizing one-point estimators. We also provide a regret bound of $O(\sqrt{k})$, which is exceptionally good compared to the aforementioned techniques. We further illustrate the usefulness of the proposed technique using numerical experiments.
Sampling-Based Trajectory (re)planning for Differentially Flat Systems: Application to a 3D Gantry Crane
Sep 12, 2022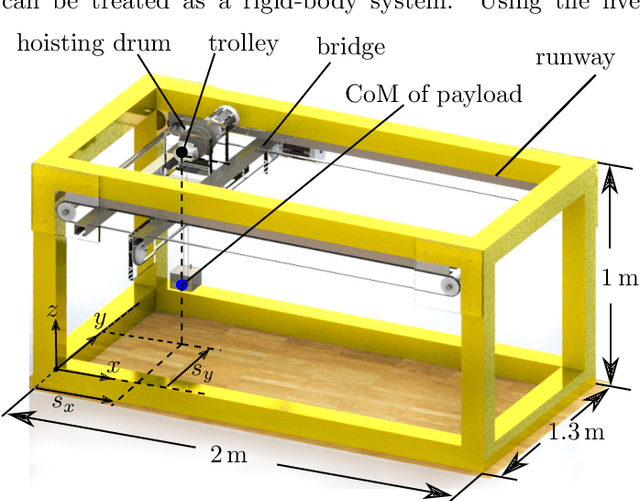
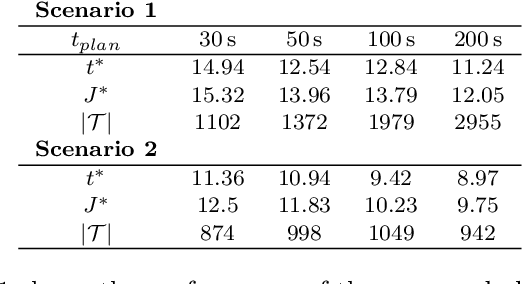
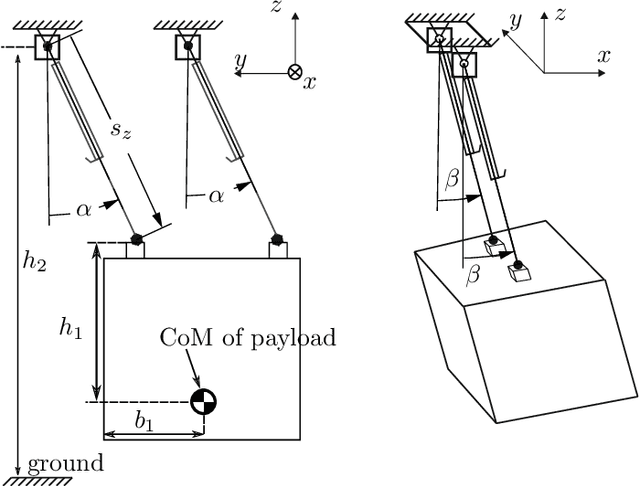
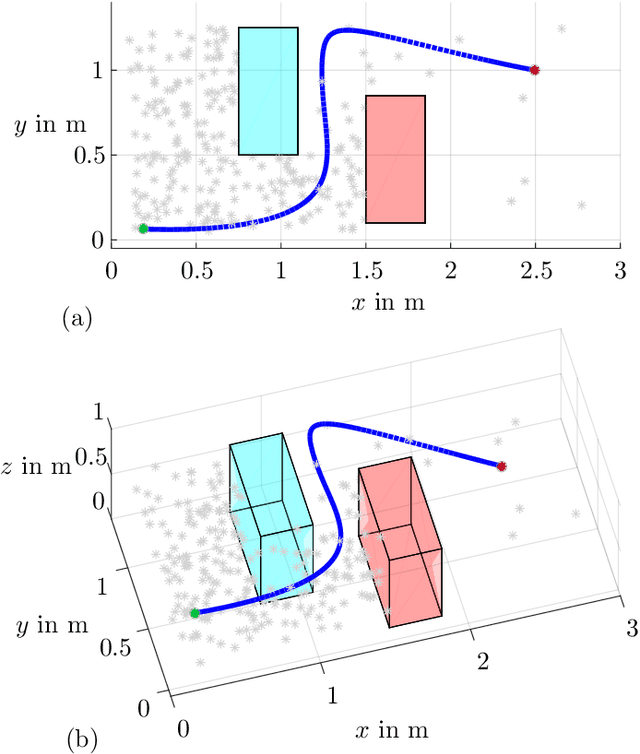
In this paper, a sampling-based trajectory planning algorithm for a laboratory-scale 3D gantry crane in an environment with static obstacles and subject to bounds on the velocity and acceleration of the gantry crane system is presented. The focus is on developing a fast motion planning algorithm for differentially flat systems, where intermediate results can be stored and reused for further tasks, such as replanning. The proposed approach is based on the informed optimal rapidly exploring random tree algorithm (informed RRT*), which is utilized to build trajectory trees that are reused for replanning when the start and/or target states change. In contrast to state-of-the-art approaches, the proposed motion planning algorithm incorporates a linear quadratic minimum time (LQTM) local planner. Thus, dynamic properties such as time optimality and the smoothness of the trajectory are directly considered in the proposed algorithm. Moreover, by integrating the branch-and-bound method to perform the pruning process on the trajectory tree, the proposed algorithm can eliminate points in the tree that do not contribute to finding better solutions. This helps to curb memory consumption and reduce the computational complexity during motion (re)planning. Simulation results for a validated mathematical model of a 3D gantry crane show the feasibility of the proposed approach.
Access Control with Encrypted Feature Maps for Object Detection Models
Sep 29, 2022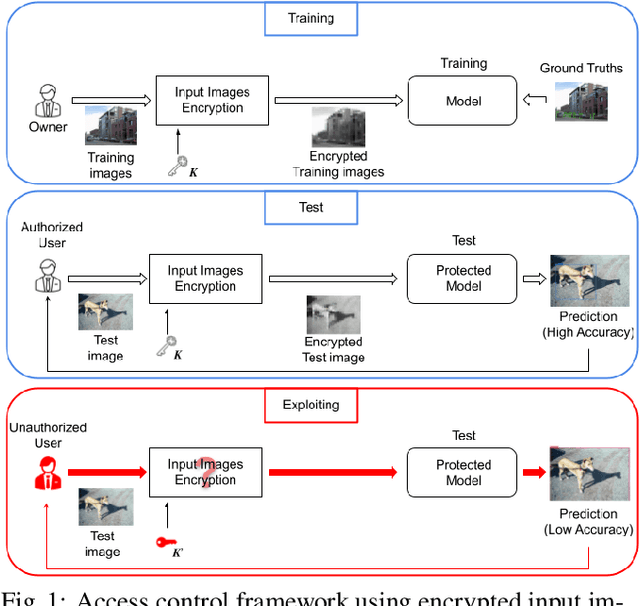
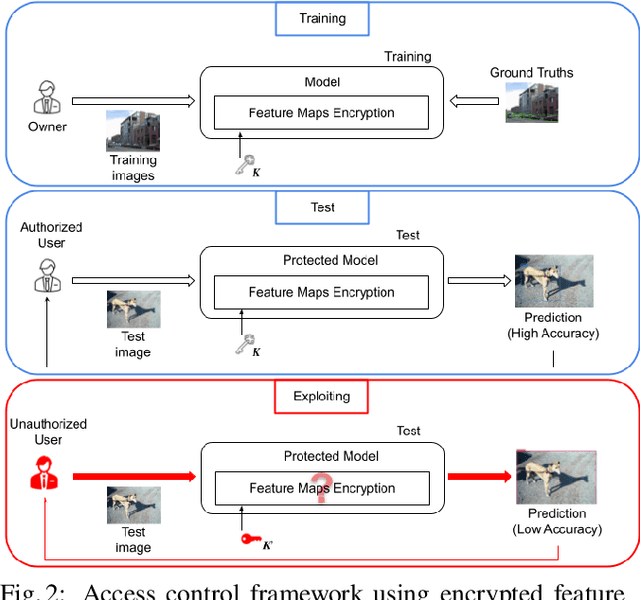
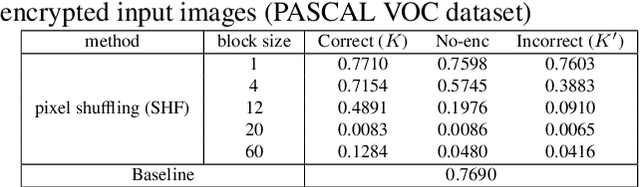
In this paper, we propose an access control method with a secret key for object detection models for the first time so that unauthorized users without a secret key cannot benefit from the performance of trained models. The method enables us not only to provide a high detection performance to authorized users but to also degrade the performance for unauthorized users. The use of transformed images was proposed for the access control of image classification models, but these images cannot be used for object detection models due to performance degradation. Accordingly, in this paper, selected feature maps are encrypted with a secret key for training and testing models, instead of input images. In an experiment, the protected models allowed authorized users to obtain almost the same performance as that of non-protected models but also with robustness against unauthorized access without a key.
Adaptive-SpikeNet: Event-based Optical Flow Estimation using Spiking Neural Networks with Learnable Neuronal Dynamics
Sep 21, 2022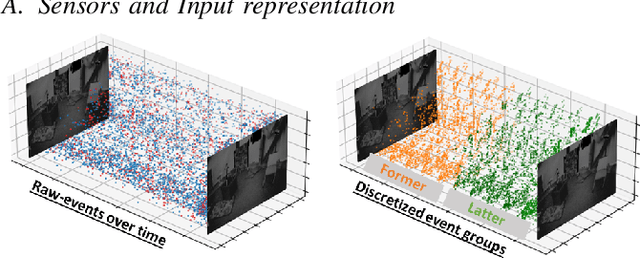
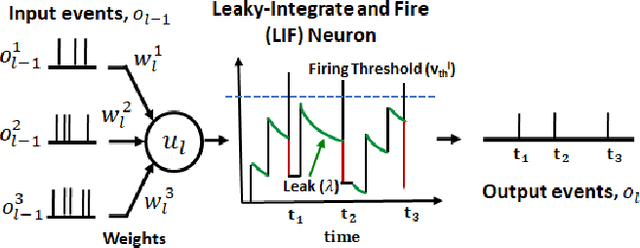
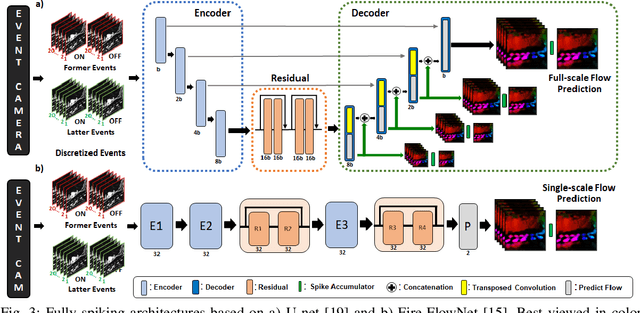
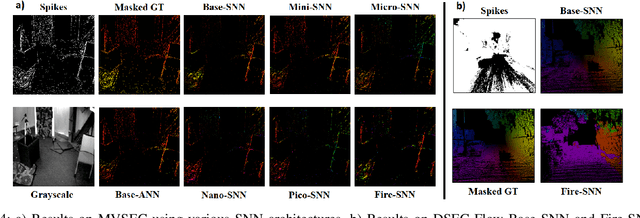
Event-based cameras have recently shown great potential for high-speed motion estimation owing to their ability to capture temporally rich information asynchronously. Spiking Neural Networks (SNNs), with their neuro-inspired event-driven processing can efficiently handle such asynchronous data, while neuron models such as the leaky-integrate and fire (LIF) can keep track of the quintessential timing information contained in the inputs. SNNs achieve this by maintaining a dynamic state in the neuron memory, retaining important information while forgetting redundant data over time. Thus, we posit that SNNs would allow for better performance on sequential regression tasks compared to similarly sized Analog Neural Networks (ANNs). However, deep SNNs are difficult to train due to vanishing spikes at later layers. To that effect, we propose an adaptive fully-spiking framework with learnable neuronal dynamics to alleviate the spike vanishing problem. We utilize surrogate gradient-based backpropagation through time (BPTT) to train our deep SNNs from scratch. We validate our approach for the task of optical flow estimation on the Multi-Vehicle Stereo Event-Camera (MVSEC) dataset and the DSEC-Flow dataset. Our experiments on these datasets show an average reduction of 13% in average endpoint error (AEE) compared to state-of-the-art ANNs. We also explore several down-scaled models and observe that our SNN models consistently outperform similarly sized ANNs offering 10%-16% lower AEE. These results demonstrate the importance of SNNs for smaller models and their suitability at the edge. In terms of efficiency, our SNNs offer substantial savings in network parameters (48x) and computational energy (51x) while attaining ~10% lower EPE compared to the state-of-the-art ANN implementations.