 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RACER: Rapid Collaborative Exploration with a Decentralized Multi-UAV System
Sep 18, 2022

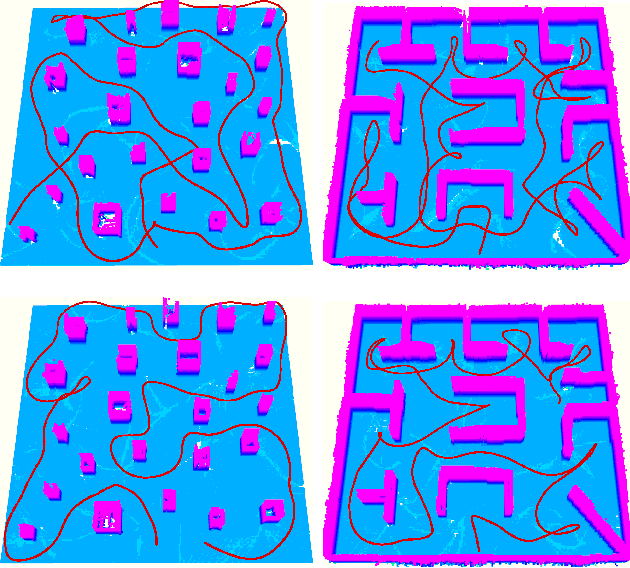

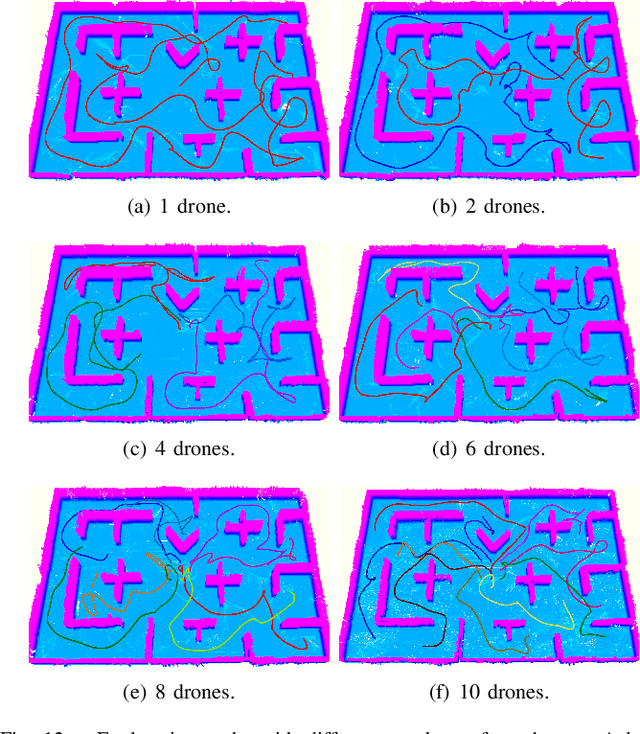
Although the use of multiple Unmanned Aerial Vehicles (UAVs) has great potential for fast autonomous exploration, it has received far too little attention. In this paper, we present RACER, a RApid Collaborative ExploRation approach using a fleet of decentralized UAVs. To effectively dispatch the UAVs, a pairwise interaction based on an online hgrid space decomposition is used. It ensures that all UAVs simultaneously explore distinct regions, using only asynchronous and limited communication. Further, we optimize the coverage paths of unknown space and balance the workloads partitioned to each UAV with a Capacitated Vehicle Routing Problem(CVRP) formulation. Given the task allocation, each UAV constantly updates the coverage path and incrementally extracts crucial information to support the exploration planning. A hierarchical planner finds exploration paths, refines local viewpoints and generates minimum-time trajectories in sequence to explore the unknown space agilely and safely. The proposed approach is evaluated extensively, showing high exploration efficiency, scalability and robustness to limited communication. Furthermore, for the first time, we achieve fully decentralized collaborative exploration with multiple UAVs in real world. We will release our implementation as an open-source package.
Real-time Human Detection Model for Edge Devices
Nov 20, 2021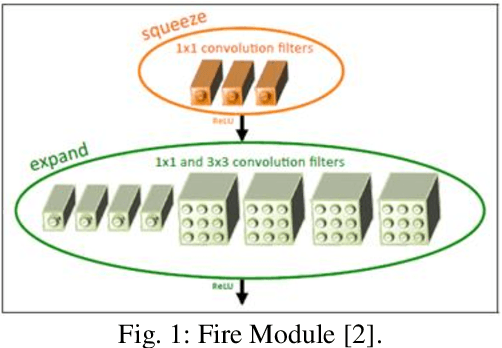
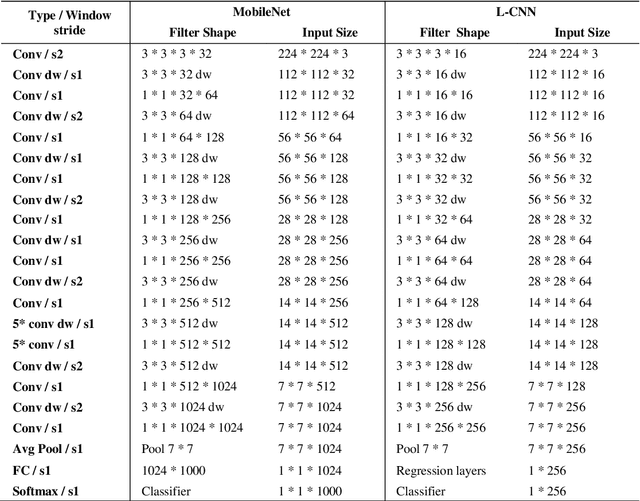
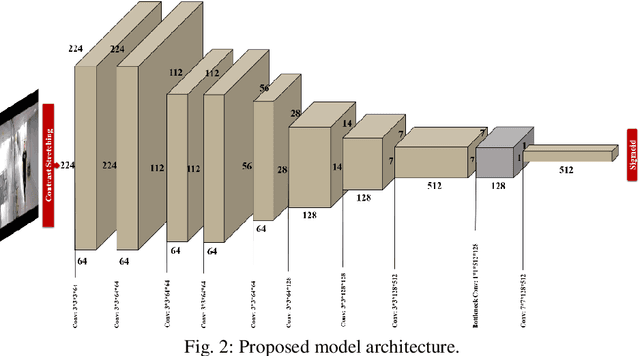
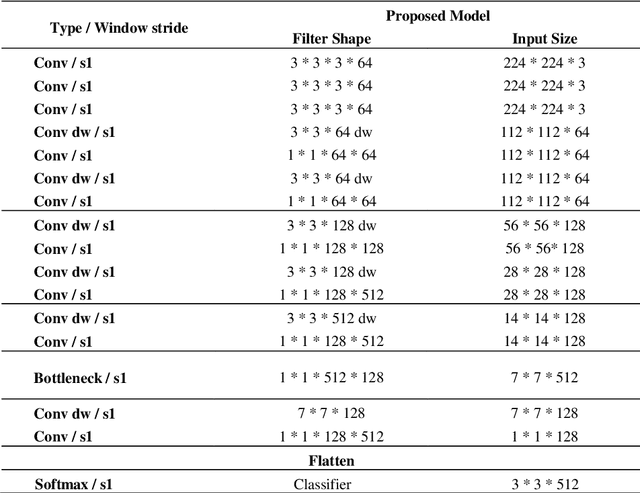
Building a small-sized fast surveillance system model to fit on limited resource devices is a challenging, yet an important task. Convolutional Neural Networks (CNNs) have replaced traditional feature extraction and machine learning models in detection and classification tasks. Various complex large CNN models are proposed that achieve significant improvement in the accuracy. Lightweight CNN models have been recently introduced for real-time tasks. This paper suggests a CNN-based lightweight model that can fit on a limited edge device such as Raspberry Pi. Our proposed model provides better performance time, smaller size and comparable accuracy with existing method. The model performance is evaluated on multiple benchmark datasets. It is also compared with existing models in terms of size, average processing time, and F-score. Other enhancements for future research are suggested.
Image Classification using Sequence of Pixels
Sep 23, 2022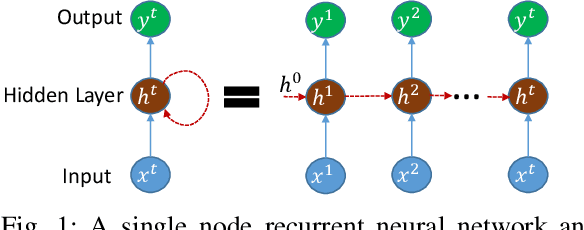
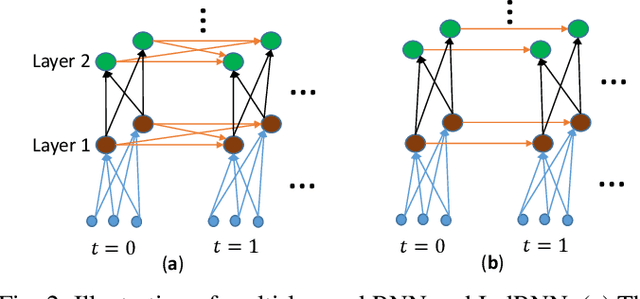

This study compares sequential image classification methods based on recurrent neural networks. We describe methods based on recurrent neural networks such as Long-Short-Term memory(LSTM), bidirectional Long-Short-Term memory(BiLSTM) architectures, etc. We also review the state-of-the-art sequential image classification architectures. We mainly focus on LSTM, BiLSTM, temporal convolution network, and independent recurrent neural network architecture in the study. It is known that RNN lacks in learning long-term dependencies in the input sequence. We use a simple feature construction method using orthogonal Ramanujan periodic transform on the input sequence. Experiments demonstrate that if these features are given to LSTM or BiLSTM networks, the performance increases drastically. Our focus in this study is to increase the training accuracy simultaneously reducing the training time for the LSTM and BiLSTM architecture, but not on pushing the state-of-the-art results, so we use simple LSTM/BiLSTM architecture. We compare sequential input with the constructed feature as input to single layer LSTM and BiLSTM network for MNIST and CIFAR datasets. We observe that sequential input to the LSTM network with 128 hidden unit training for five epochs results in training accuracy of 33% whereas constructed features as input to the same LSTM network results in training accuracy of 90% with 1/3 lesser time.
Understandable Robots
Sep 22, 2022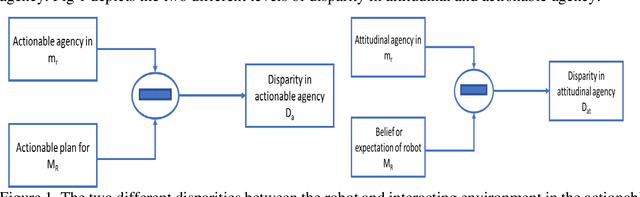
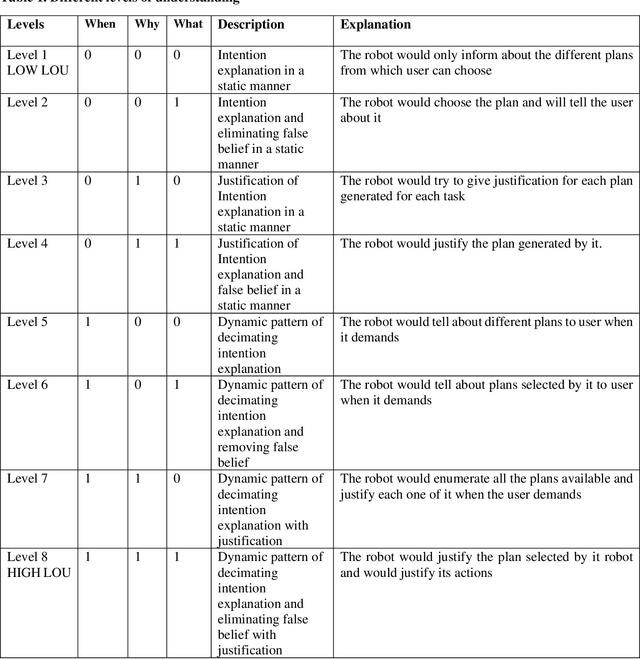


Finally, the work will include an investigation of the contextual form of explanations. In this study, we will include a time-bounded scenario in which the different levels of understanding will be tested to enable us to evaluate suitable and comprehensible explanations. For this we have proposed different levels of understanding (LOU). A user study will be designed to compare different LOU for different contexts of interaction. A user study simultating a hospital environment will be investigated.
Detecting Anomalies within Smart Buildings using Do-It-Yourself Internet of Things
Oct 04, 2022Detecting anomalies at the time of happening is vital in environments like buildings and homes to identify potential cyber-attacks. This paper discussed the various mechanisms to detect anomalies as soon as they occur. We shed light on crucial considerations when building machine learning models. We constructed and gathered data from multiple self-build (DIY) IoT devices with different in-situ sensors and found effective ways to find the point, contextual and combine anomalies. We also discussed several challenges and potential solutions when dealing with sensing devices that produce data at different sampling rates and how we need to pre-process them in machine learning models. This paper also looks at the pros and cons of extracting sub-datasets based on environmental conditions.
* Journal of Ambient Intelligence and Humanized Computing (2022)
Amortized Bayesian Inference of GISAXS Data with Normalizing Flows
Oct 04, 2022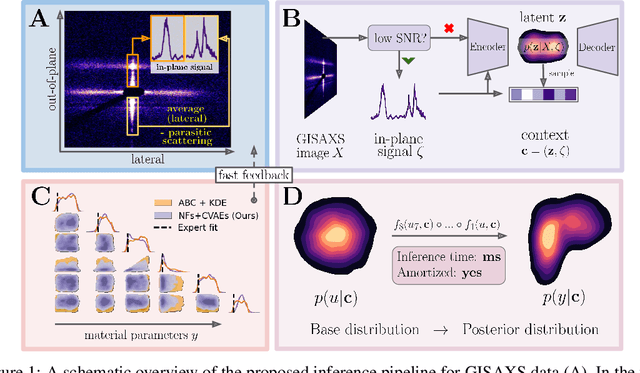
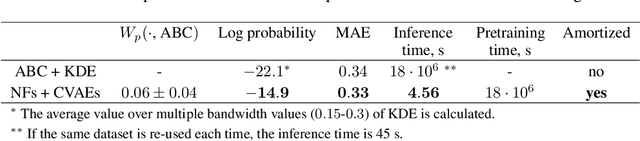
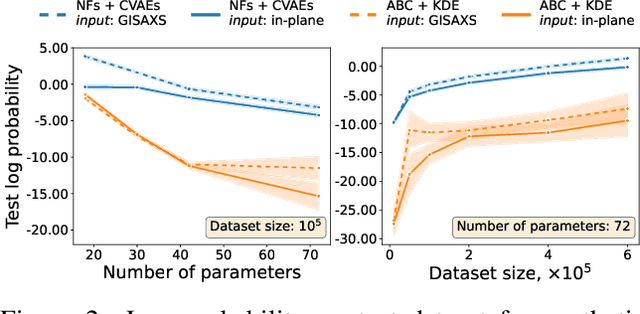

Grazing-Incidence Small-Angle X-ray Scattering (GISAXS) is a modern imaging technique used in material research to study nanoscale materials. Reconstruction of the parameters of an imaged object imposes an ill-posed inverse problem that is further complicated when only an in-plane GISAXS signal is available. Traditionally used inference algorithms such as Approximate Bayesian Computation (ABC) rely on computationally expensive scattering simulation software, rendering analysis highly time-consuming. We propose a simulation-based framework that combines variational auto-encoders and normalizing flows to estimate the posterior distribution of object parameters given its GISAXS data. We apply the inference pipeline to experimental data and demonstrate that our method reduces the inference cost by orders of magnitude while producing consistent results with ABC.
Online Search-based Collision-inclusive Motion Planning and Control for Impact-resilient Mobile Robots
Sep 27, 2022

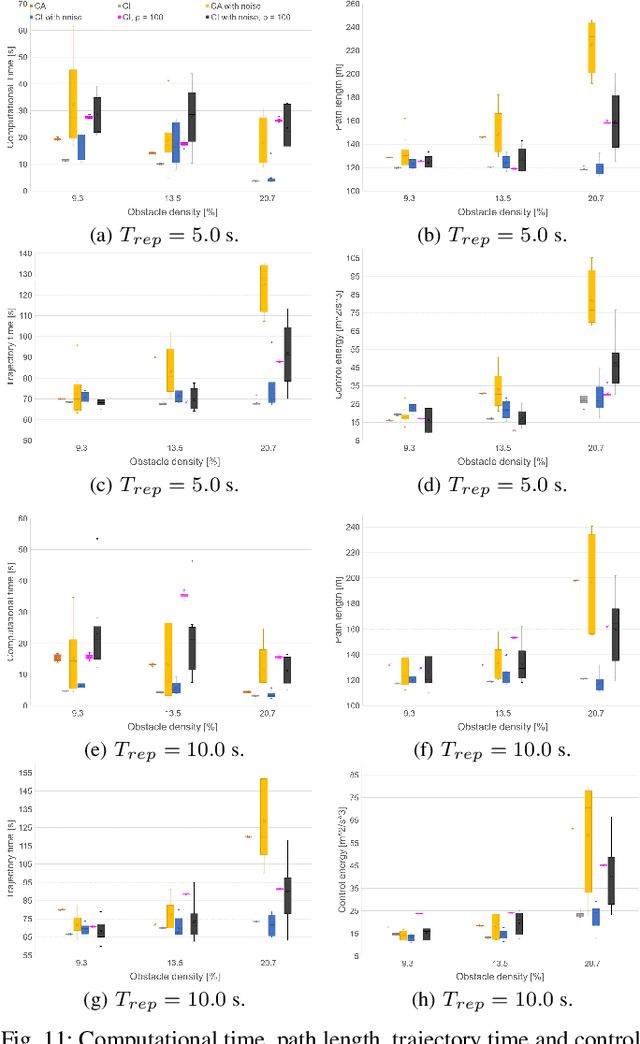
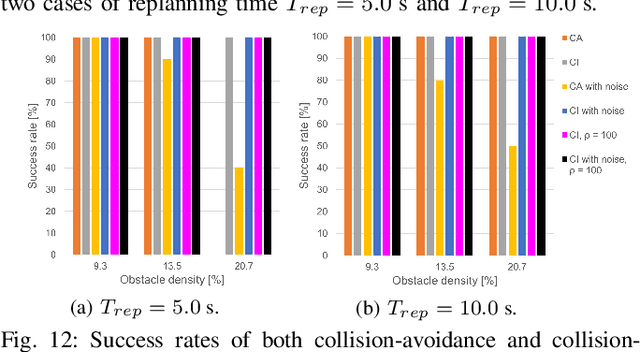
This paper focuses on the emerging paradigm shift of collision-inclusive motion planning and control for impact-resilient mobile robots, and develops a unified hierarchical framework for navigation in unknown and partially-observable cluttered spaces. At the lower-level, we develop a deformation recovery control and trajectory replanning strategy that handles collisions that may occur at run-time, locally. The low-level system actively detects collisions (via embedded Hall effect sensors on a mobile robot built in-house), enables the robot to recover from them, and locally adjusts the post-impact trajectory. Then, at the higher-level, we propose a search-based planning algorithm to determine how to best utilize potential collisions to improve certain metrics, such as control energy and computational time. Our method builds upon A* with jump points. We generate a novel heuristic function, and a collision checking and adjustment technique, thus making the A* algorithm converge faster to reach the goal by exploiting and utilizing possible collisions. The overall hierarchical framework generated by combining the global A* algorithm and the local deformation recovery and replanning strategy, as well as individual components of this framework, are tested extensively both in simulation and experimentally. An ablation study draws links to related state-of-the-art search-based collision-avoidance planners (for the overall framework), as well as search-based collision-avoidance and sampling-based collision-inclusive global planners (for the higher level). Results demonstrate our method's efficacy for collision-inclusive motion planning and control in unknown environments with isolated obstacles for a class of impact-resilient robots operating in 2D.
Characterization of causal ancestral graphs for time series with latent confounders
Dec 15, 2021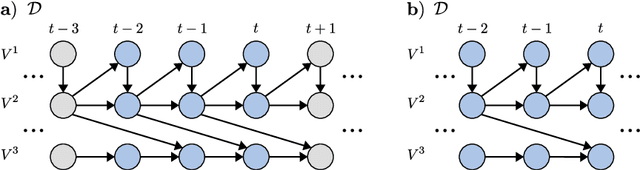
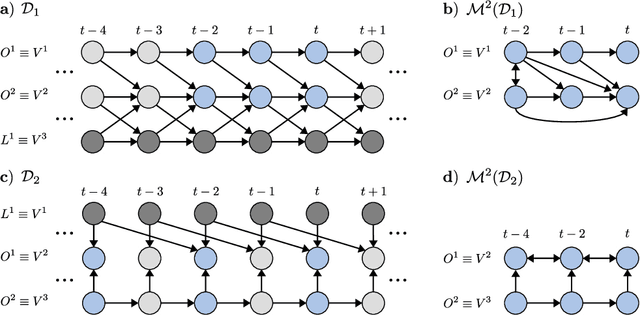


Generalizing directed maximal ancestral graphs, we introduce a class of graphical models for representing time lag specific causal relationships and independencies among finitely many regularly sampled and regularly subsampled time steps of multivariate time series with unobserved variables. We completely characterize these graphs and show that they entail constraints beyond those that have previously been considered in the literature. This allows for stronger causal inferences without having imposed additional assumptions. In generalization of directed partial ancestral graphs we further introduce a graphical representation of Markov equivalence classes of the novel type of graphs and show that these are more informative than what current state-of-the-art causal discovery algorithms learn. We also analyze the additional information gained by increasing the number of observed time steps.
Learning to Reuse Distractors to support Multiple Choice Question Generation in Education
Oct 25, 2022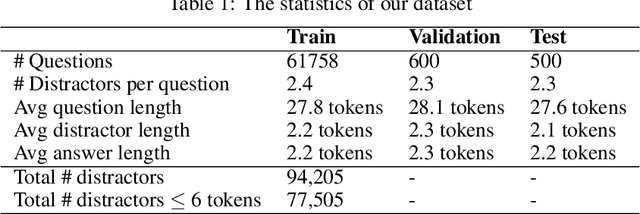
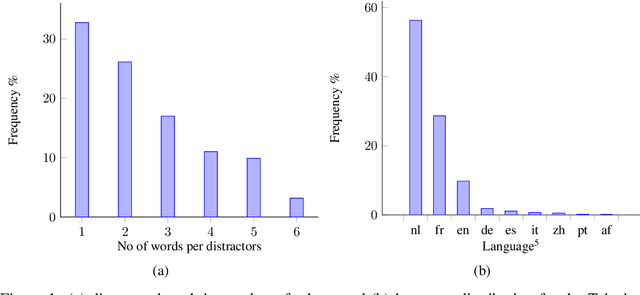
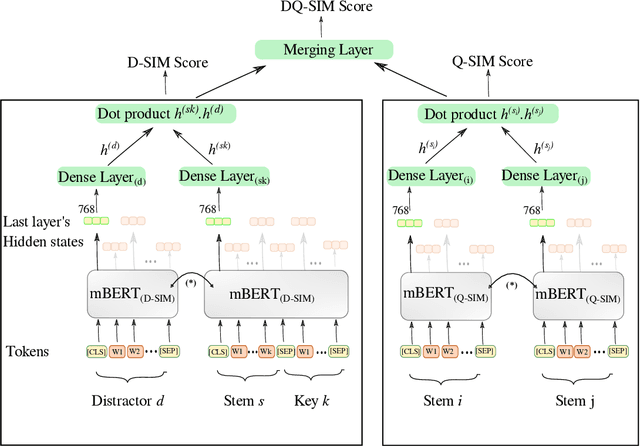

Multiple choice questions (MCQs) are widely used in digital learning systems, as they allow for automating the assessment process. However, due to the increased digital literacy of students and the advent of social media platforms, MCQ tests are widely shared online, and teachers are continuously challenged to create new questions, which is an expensive and time-consuming task. A particularly sensitive aspect of MCQ creation is to devise relevant distractors, i.e., wrong answers that are not easily identifiable as being wrong. This paper studies how a large existing set of manually created answers and distractors for questions over a variety of domains, subjects, and languages can be leveraged to help teachers in creating new MCQs, by the smart reuse of existing distractors. We built several data-driven models based on context-aware question and distractor representations, and compared them with static feature-based models. The proposed models are evaluated with automated metrics and in a realistic user test with teachers. Both automatic and human evaluations indicate that context-aware models consistently outperform a static feature-based approach. For our best-performing context-aware model, on average 3 distractors out of the 10 shown to teachers were rated as high-quality distractors. We create a performance benchmark, and make it public, to enable comparison between different approaches and to introduce a more standardized evaluation of the task. The benchmark contains a test of 298 educational questions covering multiple subjects & languages and a 77k multilingual pool of distractor vocabulary for future research.
Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization
Oct 23, 2022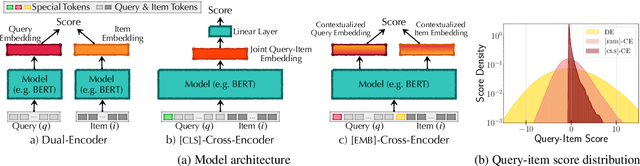
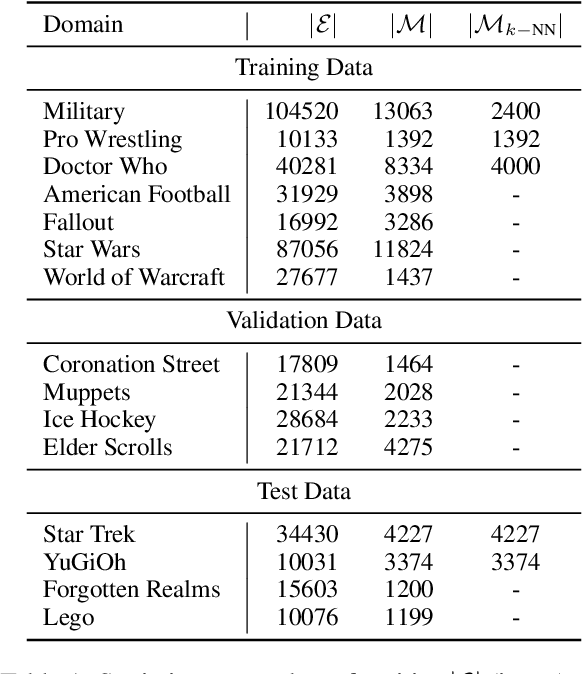

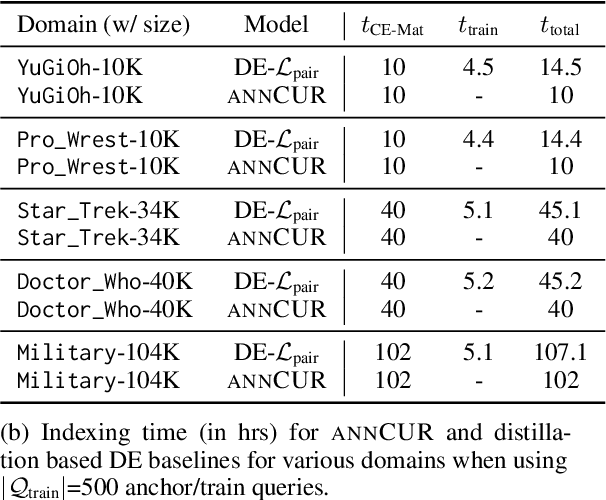
Efficient k-nearest neighbor search is a fundamental task, foundational for many problems in NLP. When the similarity is measured by dot-product between dual-encoder vectors or $\ell_2$-distance, there already exist many scalable and efficient search methods. But not so when similarity is measured by more accurate and expensive black-box neural similarity models, such as cross-encoders, which jointly encode the query and candidate neighbor. The cross-encoders' high computational cost typically limits their use to reranking candidates retrieved by a cheaper model, such as dual encoder or TF-IDF. However, the accuracy of such a two-stage approach is upper-bounded by the recall of the initial candidate set, and potentially requires additional training to align the auxiliary retrieval model with the cross-encoder model. In this paper, we present an approach that avoids the use of a dual-encoder for retrieval, relying solely on the cross-encoder. Retrieval is made efficient with CUR decomposition, a matrix decomposition approach that approximates all pairwise cross-encoder distances from a small subset of rows and columns of the distance matrix. Indexing items using our approach is computationally cheaper than training an auxiliary dual-encoder model through distillation. Empirically, for k > 10, our approach provides test-time recall-vs-computational cost trade-offs superior to the current widely-used methods that re-rank items retrieved using a dual-encoder or TF-IDF.