 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Projection-Free Online Convex Optimization with Time-Varying Constraints
Feb 13, 2024
We consider the setting of online convex optimization with adversarial time-varying constraints in which actions must be feasible w.r.t. a fixed constraint set, and are also required on average to approximately satisfy additional time-varying constraints. Motivated by scenarios in which the fixed feasible set (hard constraint) is difficult to project on, we consider projection-free algorithms that access this set only through a linear optimization oracle (LOO). We present an algorithm that, on a sequence of length $T$ and using overall $T$ calls to the LOO, guarantees $\tilde{O}(T^{3/4})$ regret w.r.t. the losses and $O(T^{7/8})$ constraints violation (ignoring all quantities except for $T$) . In particular, these bounds hold w.r.t. any interval of the sequence. We also present a more efficient algorithm that requires only first-order oracle access to the soft constraints and achieves similar bounds w.r.t. the entire sequence. We extend the latter to the setting of bandit feedback and obtain similar bounds (as a function of $T$) in expectation.
Canonical Form of Datatic Description in Control Systems
Mar 04, 2024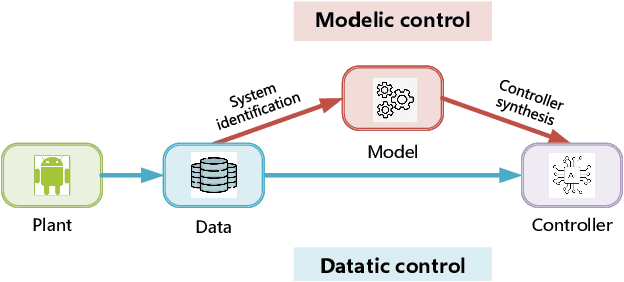
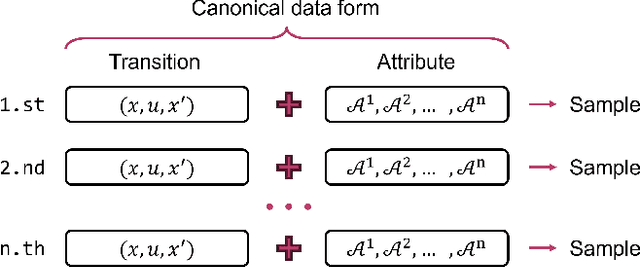
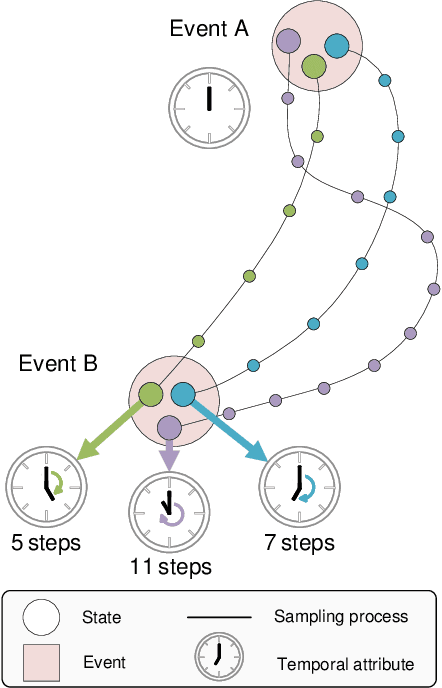
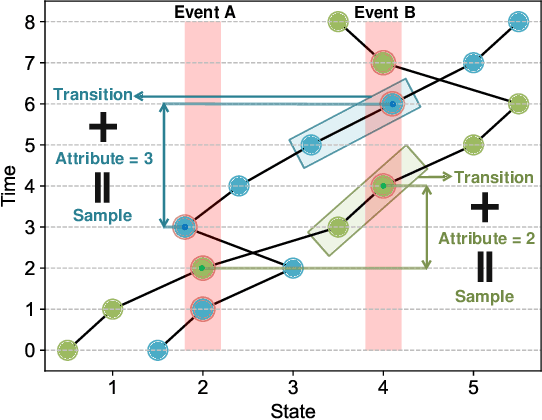
The design of feedback controllers is undergoing a paradigm shift from modelic (i.e., model-driven) control to datatic (i.e., data-driven) control. Canonical form of state space model is an important concept in modelic control systems, exemplified by Jordan form, controllable form and observable form, whose purpose is to facilitate system analysis and controller synthesis. In the realm of datatic control, there is a notable absence in the standardization of data-based system representation. This paper for the first time introduces the concept of canonical data form for the purpose of achieving more effective design of datatic controllers. In a control system, the data sample in canonical form consists of a transition component and an attribute component. The former encapsulates the plant dynamics at the sampling time independently, which is a tuple containing three elements: a state, an action and their corresponding next state. The latter describes one or some artificial characteristics of the current sample, whose calculation must be performed in an online manner. The attribute of each sample must adhere to two requirements: (1) causality, ensuring independence from any future samples; and (2) locality, allowing dependence on historical samples but constrained to a finite neighboring set. The purpose of adding attribute is to offer some kinds of benefits for controller design in terms of effectiveness and efficiency. To provide a more close-up illustration, we present two canonical data forms: temporal form and spatial form, and demonstrate their advantages in reducing instability and enhancing training efficiency in two datatic control systems.
Continuous emission ultrasound: a new paradigm to ultrafast ultrasound imaging
Mar 04, 2024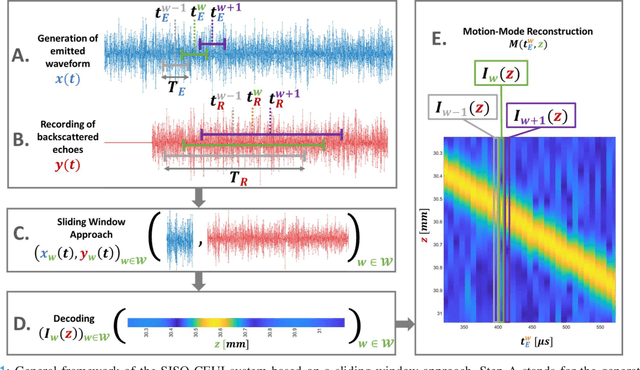
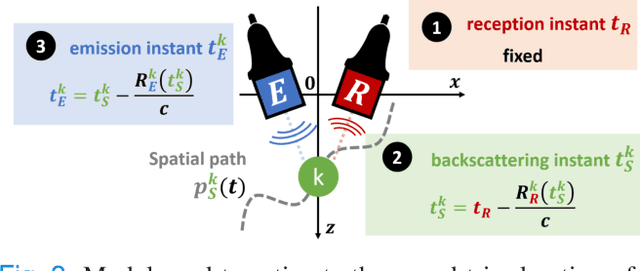
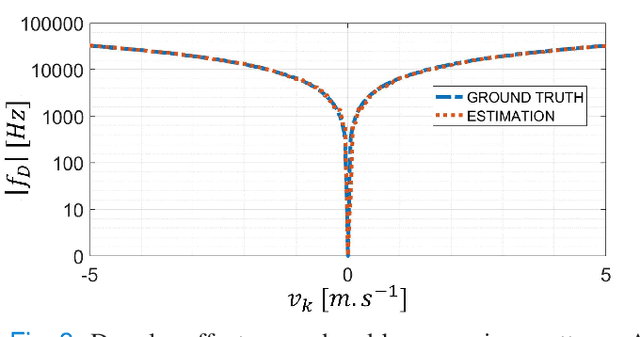

Current imaging techniques in echography rely on the pulse-echo (PE) paradigm which provides a straight-forward access to the in-depth structure of tissues. They inherently face two major challenges: the limitation of the pulse repetition frequency, directly linked to the imaging framerate, and, due to the emission scheme, their blindness to the phenomena that happen in the medium during the majority of the acquisition time. To overcome these limitations, we propose a new paradigm for ultrasound imaging, denoted by continuous emission ultrasound imaging (CUEI) \cite{CEUIpatent2023}, for a single input single output (SISO) device. A continuous insonification of the medium is done by the probe using a coded waveform inspired from the radar and sonar literature. A framework coupling a sliding window approach (SWA) and pulse compression methods processes the recorded echoes to rebuild a motion-mode (M-mode) image from the medium with a high temporal resolution compared to state-of-the-art ultrafast imaging methods. A study on realistic simulated data, with regards to the motion of the medium, has been carried out and, achieved results assess an unequivocal improvement of the slow time frequency up to, at least, two orders of magnitude compared to ultrafast US imaging methods. This enhancement leads, therefore, to a ten times improvement in the temporal separability of the imaging system. In addition, it demonstrates the capability of CEUI to catch relatively short and quick events, in comparison to the imaging period of PE methods, at any instant of the acquisition.
Koopman-Assisted Reinforcement Learning
Mar 04, 2024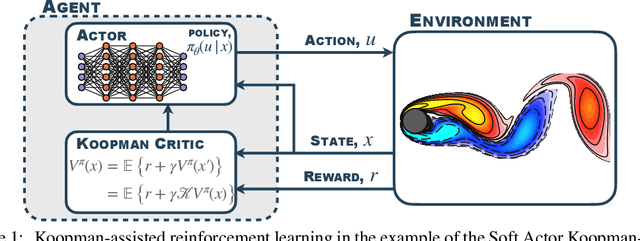
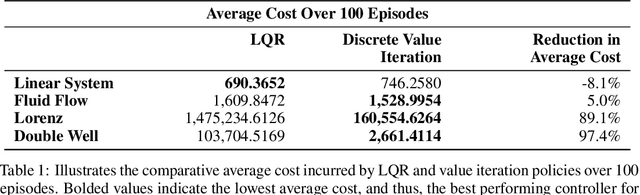
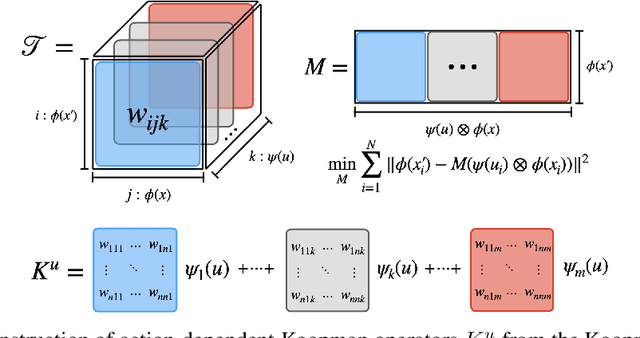
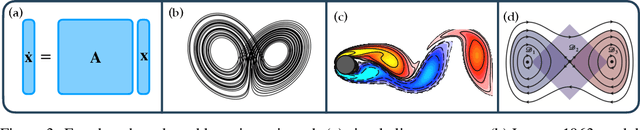
The Bellman equation and its continuous form, the Hamilton-Jacobi-Bellman (HJB) equation, are ubiquitous in reinforcement learning (RL) and control theory. However, these equations quickly become intractable for systems with high-dimensional states and nonlinearity. This paper explores the connection between the data-driven Koopman operator and Markov Decision Processes (MDPs), resulting in the development of two new RL algorithms to address these limitations. We leverage Koopman operator techniques to lift a nonlinear system into new coordinates where the dynamics become approximately linear, and where HJB-based methods are more tractable. In particular, the Koopman operator is able to capture the expectation of the time evolution of the value function of a given system via linear dynamics in the lifted coordinates. By parameterizing the Koopman operator with the control actions, we construct a ``Koopman tensor'' that facilitates the estimation of the optimal value function. Then, a transformation of Bellman's framework in terms of the Koopman tensor enables us to reformulate two max-entropy RL algorithms: soft value iteration and soft actor-critic (SAC). This highly flexible framework can be used for deterministic or stochastic systems as well as for discrete or continuous-time dynamics. Finally, we show that these Koopman Assisted Reinforcement Learning (KARL) algorithms attain state-of-the-art (SOTA) performance with respect to traditional neural network-based SAC and linear quadratic regulator (LQR) baselines on four controlled dynamical systems: a linear state-space system, the Lorenz system, fluid flow past a cylinder, and a double-well potential with non-isotropic stochastic forcing.
DyCE: Dynamic Configurable Exiting for Deep Learning Compression and Scaling
Mar 04, 2024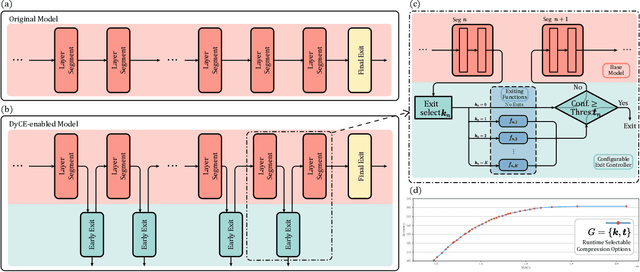
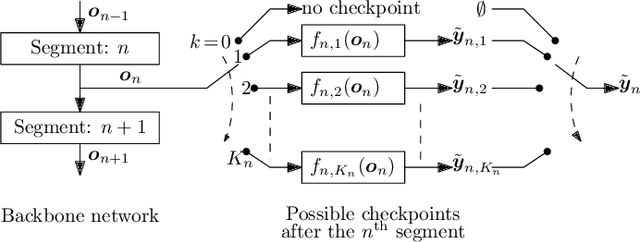
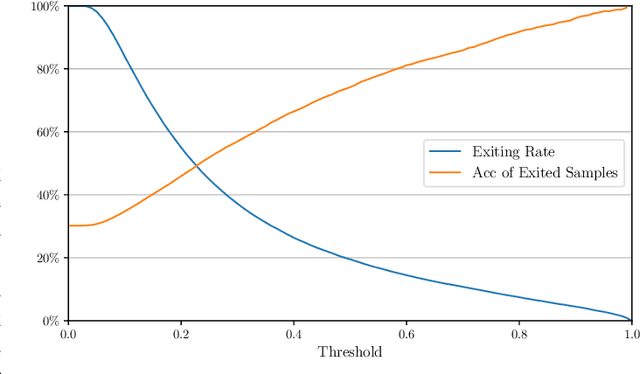
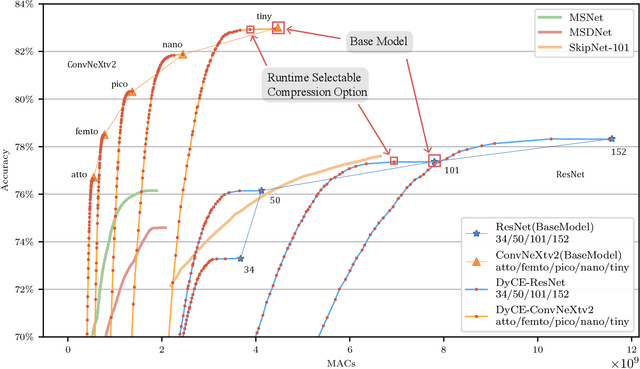
Modern deep learning (DL) models necessitate the employment of scaling and compression techniques for effective deployment in resource-constrained environments. Most existing techniques, such as pruning and quantization are generally static. On the other hand, dynamic compression methods, such as early exits, reduce complexity by recognizing the difficulty of input samples and allocating computation as needed. Dynamic methods, despite their superior flexibility and potential for co-existing with static methods, pose significant challenges in terms of implementation due to any changes in dynamic parts will influence subsequent processes. Moreover, most current dynamic compression designs are monolithic and tightly integrated with base models, thereby complicating the adaptation to novel base models. This paper introduces DyCE, an dynamic configurable early-exit framework that decouples design considerations from each other and from the base model. Utilizing this framework, various types and positions of exits can be organized according to predefined configurations, which can be dynamically switched in real-time to accommodate evolving performance-complexity requirements. We also propose techniques for generating optimized configurations based on any desired trade-off between performance and computational complexity. This empowers future researchers to focus on the improvement of individual exits without latent compromise of overall system performance. The efficacy of this approach is demonstrated through image classification tasks with deep CNNs. DyCE significantly reduces the computational complexity by 23.5% of ResNet152 and 25.9% of ConvNextv2-tiny on ImageNet, with accuracy reductions of less than 0.5%. Furthermore, DyCE offers advantages over existing dynamic methods in terms of real-time configuration and fine-grained performance tuning.
Unveiling Hidden Links Between Unseen Security Entities
Mar 04, 2024
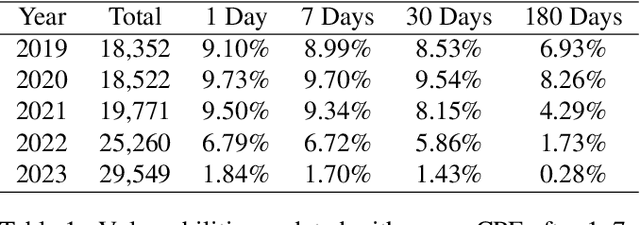
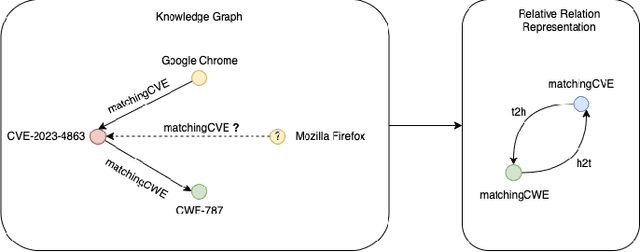

The proliferation of software vulnerabilities poses a significant challenge for security databases and analysts tasked with their timely identification, classification, and remediation. With the National Vulnerability Database (NVD) reporting an ever-increasing number of vulnerabilities, the traditional manual analysis becomes untenably time-consuming and prone to errors. This paper introduces VulnScopper, an innovative approach that utilizes multi-modal representation learning, combining Knowledge Graphs (KG) and Natural Language Processing (NLP), to automate and enhance the analysis of software vulnerabilities. Leveraging ULTRA, a knowledge graph foundation model, combined with a Large Language Model (LLM), VulnScopper effectively handles unseen entities, overcoming the limitations of previous KG approaches. We evaluate VulnScopper on two major security datasets, the NVD and the Red Hat CVE database. Our method significantly improves the link prediction accuracy between Common Vulnerabilities and Exposures (CVEs), Common Weakness Enumeration (CWEs), and Common Platform Enumerations (CPEs). Our results show that VulnScopper outperforms existing methods, achieving up to 78% Hits@10 accuracy in linking CVEs to CPEs and CWEs and presenting an 11.7% improvement over large language models in predicting CWE labels based on the Red Hat database. Based on the NVD, only 6.37% of the linked CPEs are being published during the first 30 days; many of them are related to critical and high-risk vulnerabilities which, according to multiple compliance frameworks (such as CISA and PCI), should be remediated within 15-30 days. Our model can uncover new products linked to vulnerabilities, reducing remediation time and improving vulnerability management. We analyzed several CVEs from 2023 to showcase this ability.
Less is More: Hop-Wise Graph Attention for Scalable and Generalizable Learning on Circuits
Mar 06, 2024While graph neural networks (GNNs) have gained popularity for learning circuit representations in various electronic design automation (EDA) tasks, they face challenges in scalability when applied to large graphs and exhibit limited generalizability to new designs. These limitations make them less practical for addressing large-scale, complex circuit problems. In this work we propose HOGA, a novel attention-based model for learning circuit representations in a scalable and generalizable manner. HOGA first computes hop-wise features per node prior to model training. Subsequently, the hop-wise features are solely used to produce node representations through a gated self-attention module, which adaptively learns important features among different hops without involving the graph topology. As a result, HOGA is adaptive to various structures across different circuits and can be efficiently trained in a distributed manner. To demonstrate the efficacy of HOGA, we consider two representative EDA tasks: quality of results (QoR) prediction and functional reasoning. Our experimental results indicate that (1) HOGA reduces estimation error over conventional GNNs by 46.76% for predicting QoR after logic synthesis; (2) HOGA improves 10.0% reasoning accuracy over GNNs for identifying functional blocks on unseen gate-level netlists after complex technology mapping; (3) The training time for HOGA almost linearly decreases with an increase in computing resources.
Feel the Bite: Robot-Assisted Inside-Mouth Bite Transfer using Robust Mouth Perception and Physical Interaction-Aware Control
Mar 06, 2024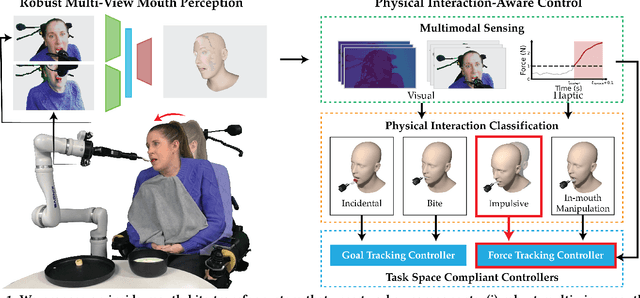

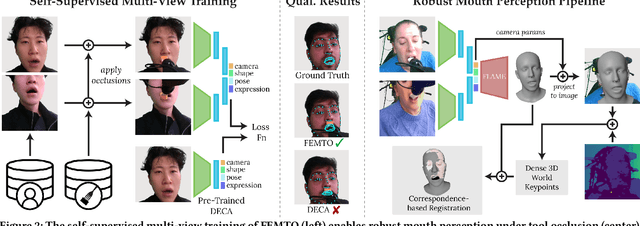
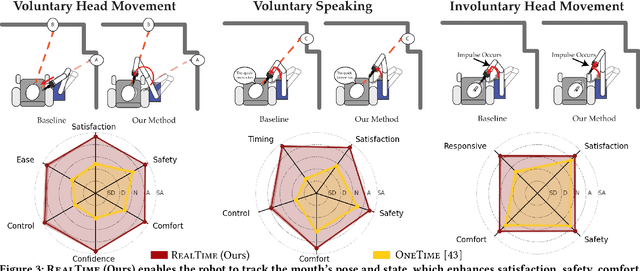
Robot-assisted feeding can greatly enhance the lives of those with mobility limitations. Modern feeding systems can pick up and position food in front of a care recipient's mouth for a bite. However, many with severe mobility constraints cannot lean forward and need direct inside-mouth food placement. This demands precision, especially for those with restricted mouth openings, and appropriately reacting to various physical interactions - incidental contacts as the utensil moves inside, impulsive contacts due to sudden muscle spasms, deliberate tongue maneuvers by the person being fed to guide the utensil, and intentional bites. In this paper, we propose an inside-mouth bite transfer system that addresses these challenges with two key components: a multi-view mouth perception pipeline robust to tool occlusion, and a control mechanism that employs multimodal time-series classification to discern and react to different physical interactions. We demonstrate the efficacy of these individual components through two ablation studies. In a full system evaluation, our system successfully fed 13 care recipients with diverse mobility challenges. Participants consistently emphasized the comfort and safety of our inside-mouth bite transfer system, and gave it high technology acceptance ratings - underscoring its transformative potential in real-world scenarios. Supplementary materials and videos can be found at http://emprise.cs.cornell.edu/bitetransfer/ .
A Knowledge Plug-and-Play Test Bed for Open-domain Dialogue Generation
Mar 06, 2024
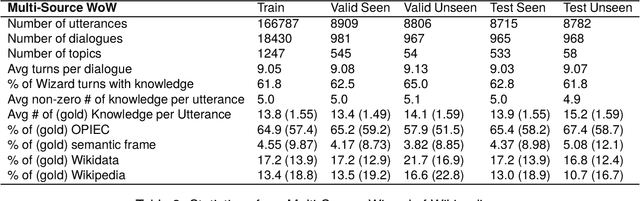

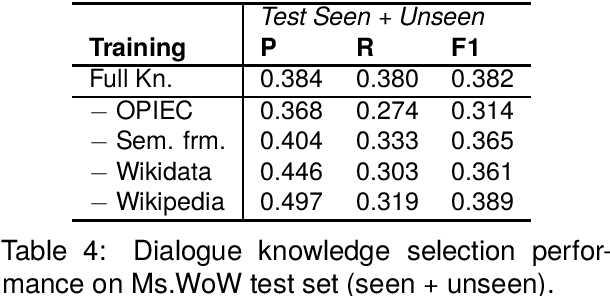
Knowledge-based, open-domain dialogue generation aims to build chit-chat systems that talk to humans using mined support knowledge. Many types and sources of knowledge have previously been shown to be useful as support knowledge. Even in the era of large language models, response generation grounded in knowledge retrieved from additional up-to-date sources remains a practically important approach. While prior work using single-source knowledge has shown a clear positive correlation between the performances of knowledge selection and response generation, there are no existing multi-source datasets for evaluating support knowledge retrieval. Further, prior work has assumed that the knowledge sources available at test time are the same as during training. This unrealistic assumption unnecessarily handicaps models, as new knowledge sources can become available after a model is trained. In this paper, we present a high-quality benchmark named multi-source Wizard of Wikipedia (Ms.WoW) for evaluating multi-source dialogue knowledge selection and response generation. Unlike existing datasets, it contains clean support knowledge, grounded at the utterance level and partitioned into multiple knowledge sources. We further propose a new challenge, dialogue knowledge plug-and-play, which aims to test an already trained dialogue model on using new support knowledge from previously unseen sources in a zero-shot fashion.
Faster Neighborhood Attention: Reducing the O(n^2) Cost of Self Attention at the Threadblock Level
Mar 07, 2024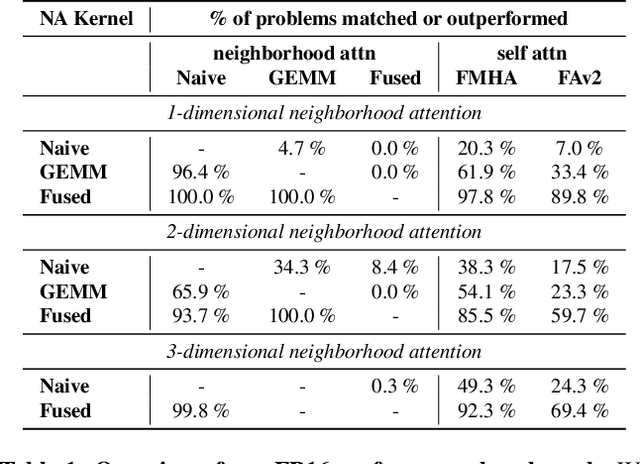
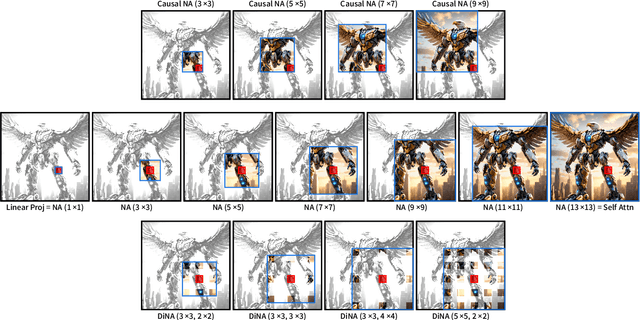
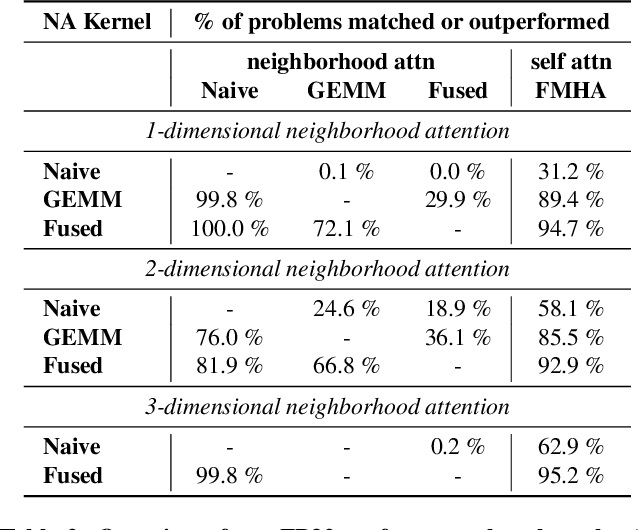
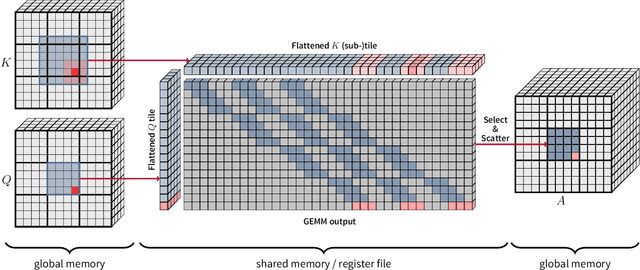
Neighborhood attention reduces the cost of self attention by restricting each token's attention span to its nearest neighbors. This restriction, parameterized by a window size and dilation factor, draws a spectrum of possible attention patterns between linear projection and self attention. Neighborhood attention, and more generally sliding window attention patterns, have long been bounded by infrastructure, particularly in higher-rank spaces (2-D and 3-D), calling for the development of custom kernels, which have been limited in either functionality, or performance, if not both. In this work, we first show that neighborhood attention can be represented as a batched GEMM problem, similar to standard attention, and implement it for 1-D and 2-D neighborhood attention. These kernels on average provide 895% and 272% improvement in full precision latency compared to existing naive kernels for 1-D and 2-D neighborhood attention respectively. We find certain inherent inefficiencies in all unfused neighborhood attention kernels that bound their performance and lower-precision scalability. We also developed fused neighborhood attention; an adaptation of fused dot-product attention kernels that allow fine-grained control over attention across different spatial axes. Known for reducing the quadratic time complexity of self attention to a linear complexity, neighborhood attention can now enjoy a reduced and constant memory footprint, and record-breaking half precision latency. We observe that our fused kernels successfully circumvent some of the unavoidable inefficiencies in unfused implementations. While our unfused GEMM-based kernels only improve half precision performance compared to naive kernels by an average of 496% and 113% in 1-D and 2-D problems respectively, our fused kernels improve naive kernels by an average of 1607% and 581% in 1-D and 2-D problems respectively.