 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Time Series Denoising with Learnable Wavelet Packet Transform
Jun 13, 2022

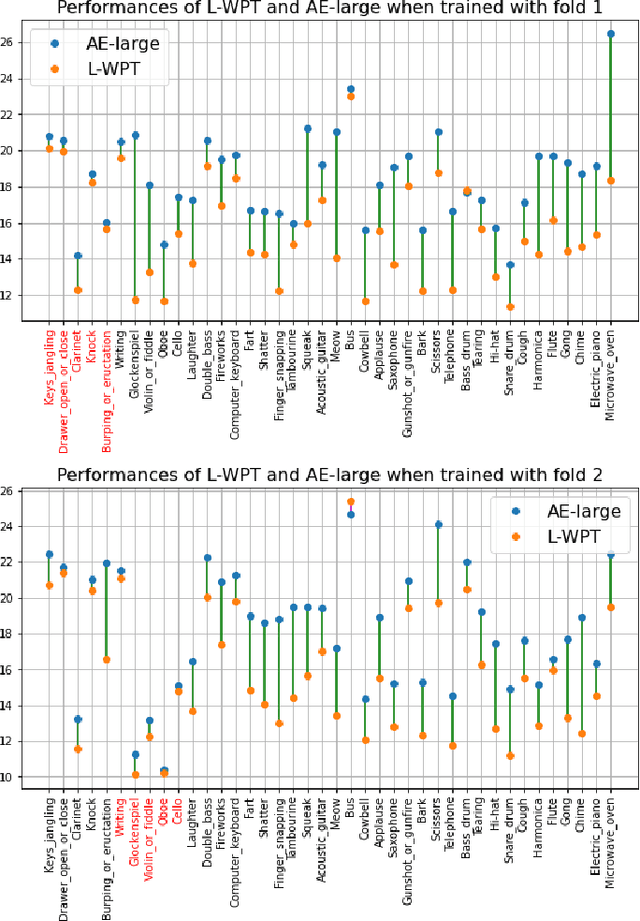
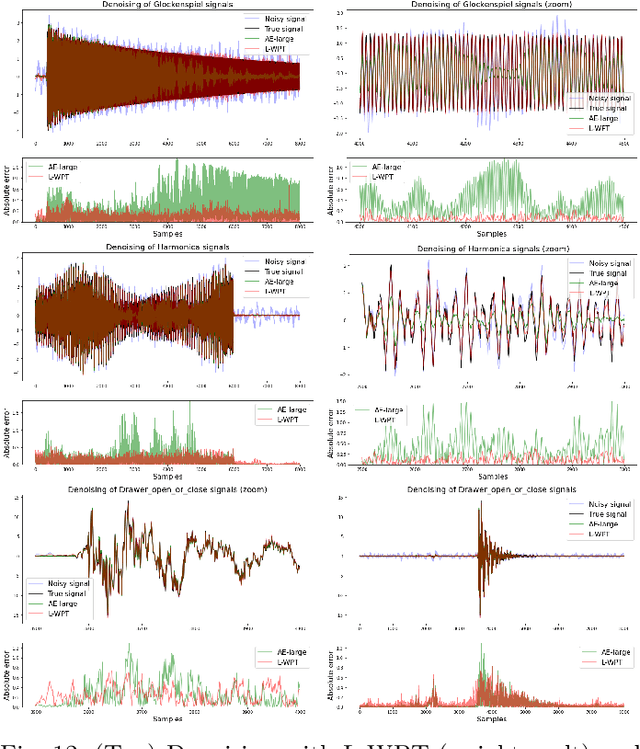
In many applications, signal denoising is often the first pre-processing step before any subsequent analysis or learning task. In this paper, we propose to apply a deep learning denoising model inspired by a signal processing, a learnable version of wavelet packet transform. The proposed algorithm has signficant learning capabilities with few interpretable parameters and has an intuitive initialisation. We propose a post-learning modification of the parameters to adapt the denoising to different noise levels. We evaluate the performance of the proposed methodology on two case studies and compare it to other state of the art approaches, including wavelet schrinkage denoising, convolutional neural network, autoencoder and U-net deep models. The first case study is based on designed functions that have typically been used to study denoising properties of the algorithms. The second case study is an audio background removal task. We demonstrate how the proposed algorithm relates to the universality of signal processing methods and the learning capabilities of deep learning approaches. In particular, we evaluate the obtained denoising performances on structured noisy signals inside and outside the classes used for training. In addition to having good performance in denoising signals inside and outside to the training class, our method shows to be particularly robust when different noise levels, noise types and artifacts are added.
Clustering Embedding Tables, Without First Learning Them
Oct 12, 2022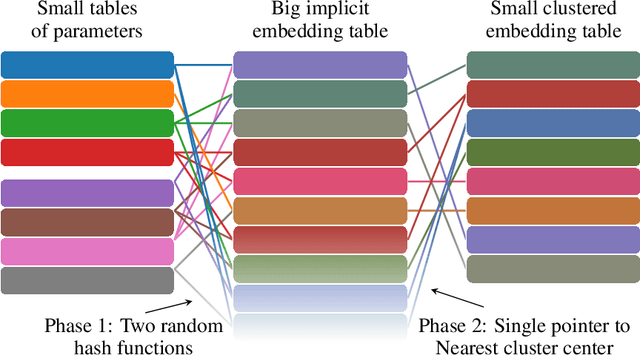
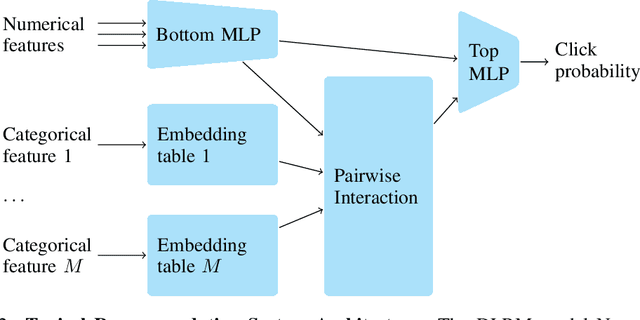

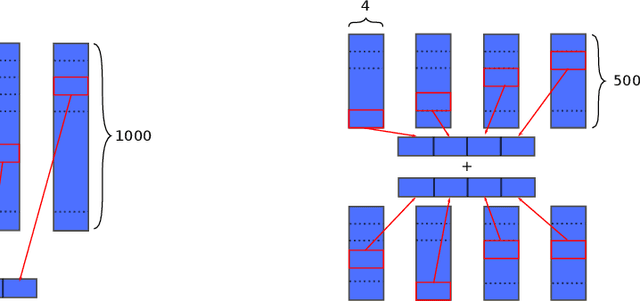
To work with categorical features, machine learning systems employ embedding tables. These tables can become exceedingly large in modern recommendation systems, necessitating the development of new methods for fitting them in memory, even during training. Some of the most successful methods for table compression are Product- and Residual Vector Quantization (Gray & Neuhoff, 1998). These methods replace table rows with references to k-means clustered "codewords." Unfortunately, this means they must first know the table before compressing it, so they can only save memory during inference, not training. Recent work has used hashing-based approaches to minimize memory usage during training, but the compression obtained is inferior to that obtained by "post-training" quantization. We show that the best of both worlds may be obtained by combining techniques based on hashing and clustering. By first training a hashing-based "sketch", then clustering it, and then training the clustered quantization, our method achieves compression ratios close to those of post-training quantization with the training time memory reductions of hashing-based methods. We show experimentally that our method provides better compression and/or accuracy that previous methods, and we prove that our method always converges to the optimal embedding table for least-squares training.
QDTrack: Quasi-Dense Similarity Learning for Appearance-Only Multiple Object Tracking
Oct 12, 2022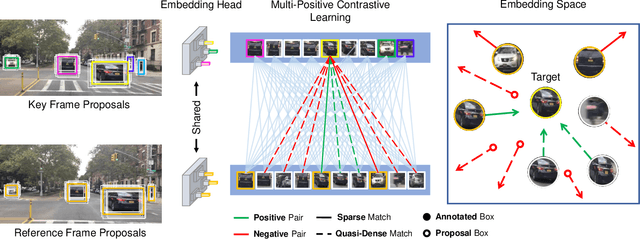
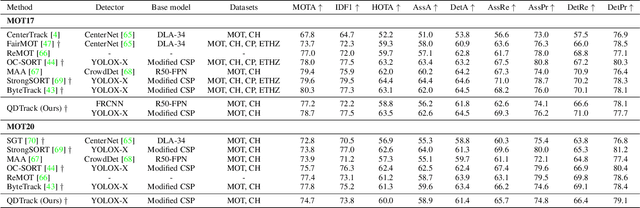
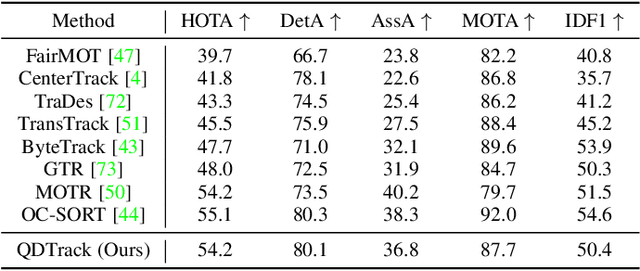
Similarity learning has been recognized as a crucial step for object tracking. However, existing multiple object tracking methods only use sparse ground truth matching as the training objective, while ignoring the majority of the informative regions in images. In this paper, we present Quasi-Dense Similarity Learning, which densely samples hundreds of object regions on a pair of images for contrastive learning. We combine this similarity learning with multiple existing object detectors to build Quasi-Dense Tracking (QDTrack), which does not require displacement regression or motion priors. We find that the resulting distinctive feature space admits a simple nearest neighbor search at inference time for object association. In addition, we show that our similarity learning scheme is not limited to video data, but can learn effective instance similarity even from static input, enabling a competitive tracking performance without training on videos or using tracking supervision. We conduct extensive experiments on a wide variety of popular MOT benchmarks. We find that, despite its simplicity, QDTrack rivals the performance of state-of-the-art tracking methods on all benchmarks and sets a new state-of-the-art on the large-scale BDD100K MOT benchmark, while introducing negligible computational overhead to the detector.
LMQFormer: A Laplace-Prior-Guided Mask Query Transformer for Lightweight Snow Removal
Oct 12, 2022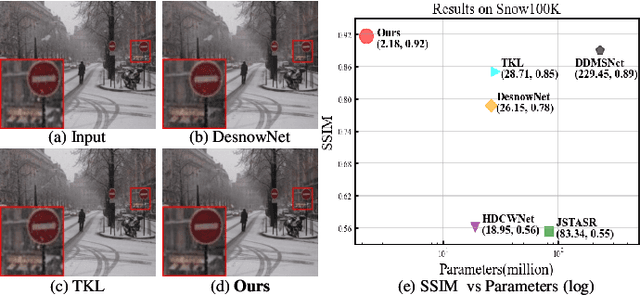



Snow removal aims to locate snow areas and recover clean images without repairing traces. Unlike the regularity and semitransparency of rain, snow with various patterns and degradations seriously occludes the background. As a result, the state-of-the-art snow removal methods usually retains a large parameter size. In this paper, we propose a lightweight but high-efficient snow removal network called Laplace Mask Query Transformer (LMQFormer). Firstly, we present a Laplace-VQVAE to generate a coarse mask as prior knowledge of snow. Instead of using the mask in dataset, we aim at reducing both the information entropy of snow and the computational cost of recovery. Secondly, we design a Mask Query Transformer (MQFormer) to remove snow with the coarse mask, where we use two parallel encoders and a hybrid decoder to learn extensive snow features under lightweight requirements. Thirdly, we develop a Duplicated Mask Query Attention (DMQA) that converts the coarse mask into a specific number of queries, which constraint the attention areas of MQFormer with reduced parameters. Experimental results in popular datasets have demonstrated the efficiency of our proposed model, which achieves the state-of-the-art snow removal quality with significantly reduced parameters and the lowest running time.
AIMY: An Open-source Table Tennis Ball Launcher for Versatile and High-fidelity Trajectory Generation
Oct 12, 2022

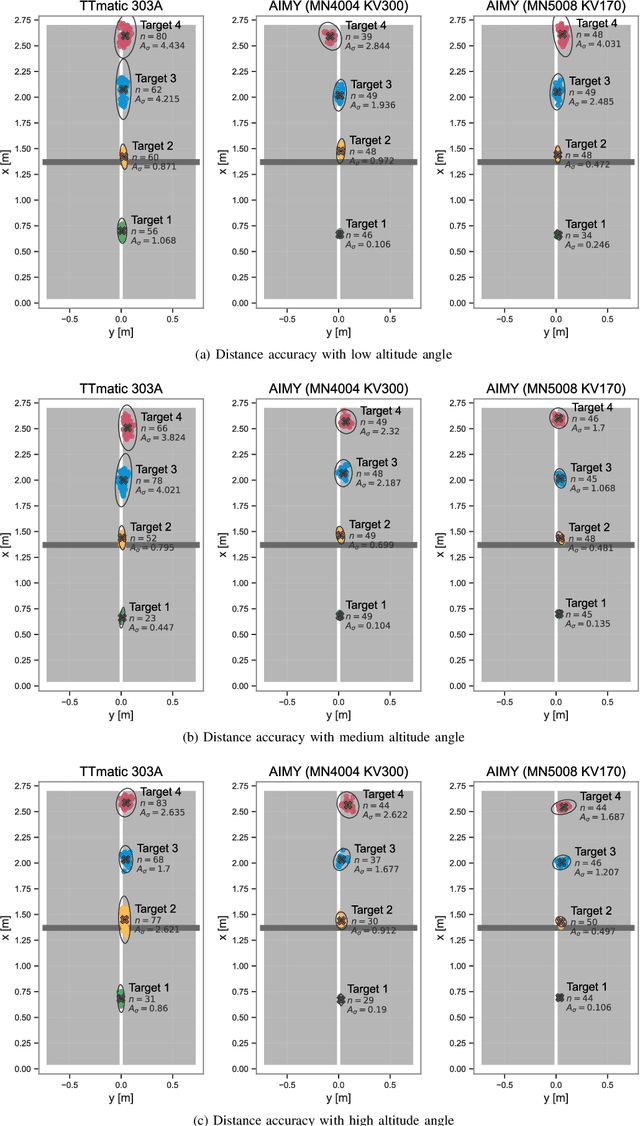
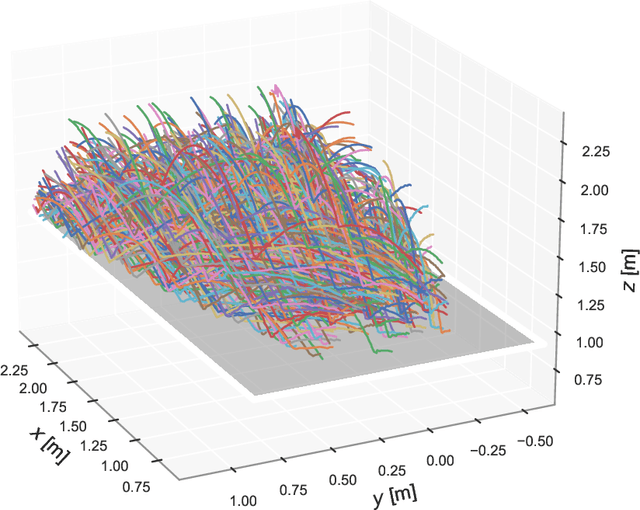
To approach the level of advanced human players in table tennis with robots, generating varied ball trajectories in a reproducible and controlled manner is essential. Current ball launchers used in robot table tennis either do not provide an interface for automatic control or are limited in their capabilities to adapt speed, direction, and spin of the ball. For these reasons, we present AIMY, a three-wheeled open-hardware and open-source table tennis ball launcher, which can generate ball speeds and spins of up to 15.44 m/s and 192/s, respectively, which are comparable to advanced human players. The wheel speeds, launch orientation and time can be fully controlled via an open Ethernet or Wi-Fi interface. We provide a detailed overview of the core design features, as well as open source the software to encourage distribution and duplication within and beyond the robot table tennis research community. We also extensively evaluate the ball launcher's accuracy for different system settings and learn to launch a ball to desired locations. With this ball launcher, we enable long-duration training of robot table tennis approaches where the complexity of the ball trajectory can be automatically adjusted, enabling large-scale real-world online reinforcement learning for table tennis robots.
Improving information retention in large scale online continual learning
Oct 12, 2022



Given a stream of data sampled from non-stationary distributions, online continual learning (OCL) aims to adapt efficiently to new data while retaining existing knowledge. The typical approach to address information retention (the ability to retain previous knowledge) is keeping a replay buffer of a fixed size and computing gradients using a mixture of new data and the replay buffer. Surprisingly, the recent work (Cai et al., 2021) suggests that information retention remains a problem in large scale OCL even when the replay buffer is unlimited, i.e., the gradients are computed using all past data. This paper focuses on this peculiarity to understand and address information retention. To pinpoint the source of this problem, we theoretically show that, given limited computation budgets at each time step, even without strict storage limit, naively applying SGD with constant or constantly decreasing learning rates fails to optimize information retention in the long term. We propose using a moving average family of methods to improve optimization for non-stationary objectives. Specifically, we design an adaptive moving average (AMA) optimizer and a moving-average-based learning rate schedule (MALR). We demonstrate the effectiveness of AMA+MALR on large-scale benchmarks, including Continual Localization (CLOC), Google Landmarks, and ImageNet. Code will be released upon publication.
DiPA: Diverse and Probabilistically Accurate Interactive Prediction
Oct 12, 2022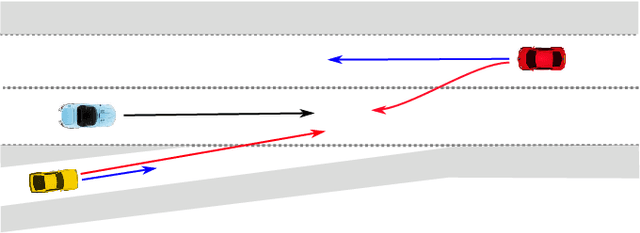
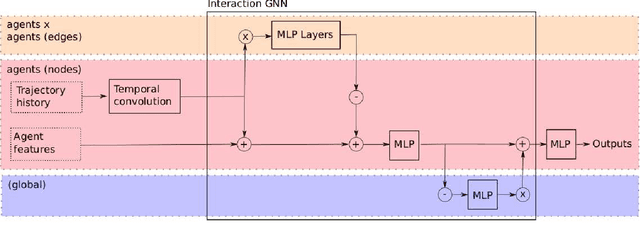

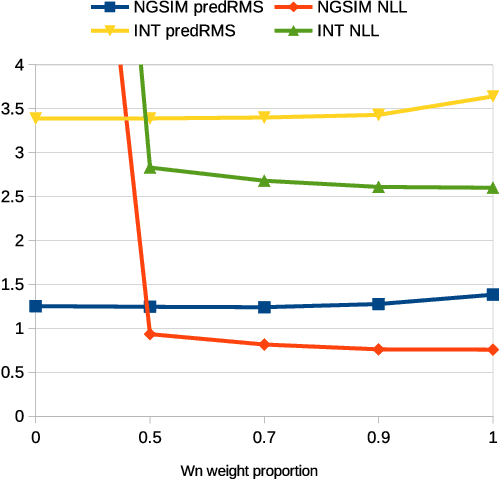
Accurate prediction is important for operating an autonomous vehicle in interactive scenarios. Previous interactive predictors have used closest-mode evaluations, which test if one of a set of predictions covers the ground-truth, but not if additional unlikely predictions are made. The presence of unlikely predictions can interfere with planning, by indicating conflict with the ego plan when it is not likely to occur. Closest-mode evaluations are not sufficient for showing a predictor is useful, an effective predictor also needs to accurately estimate mode probabilities, and to be evaluated using probabilistic measures. These two evaluation approaches, eg. predicted-mode RMS and minADE/FDE, are analogous to precision and recall in binary classification, and there is a challenging trade-off between prediction strategies for each. We present DiPA, a method for producing diverse predictions while also capturing accurate probabilistic estimates. DiPA uses a flexible representation that captures interactions in widely varying road topologies, and uses a novel training regime for a Gaussian Mixture Model that supports diversity of predicted modes, along with accurate spatial distribution and mode probability estimates. DiPA achieves state-of-the-art performance on INTERACTION and NGSIM, and improves over a baseline (MFP) when both closest-mode and probabilistic evaluations are used at the same time.
Digital Signal Analysis based on Convolutional Neural Networks for Active Target Time Projection Chambers
Feb 14, 2022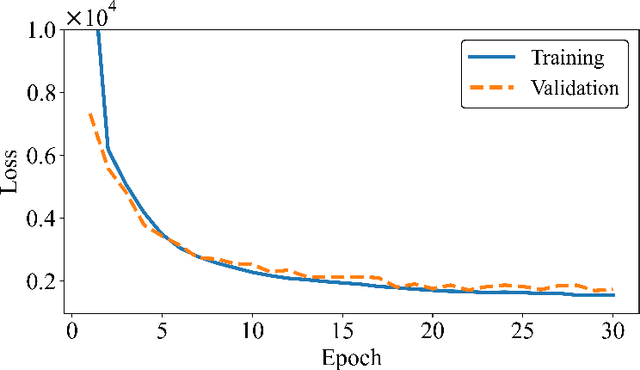
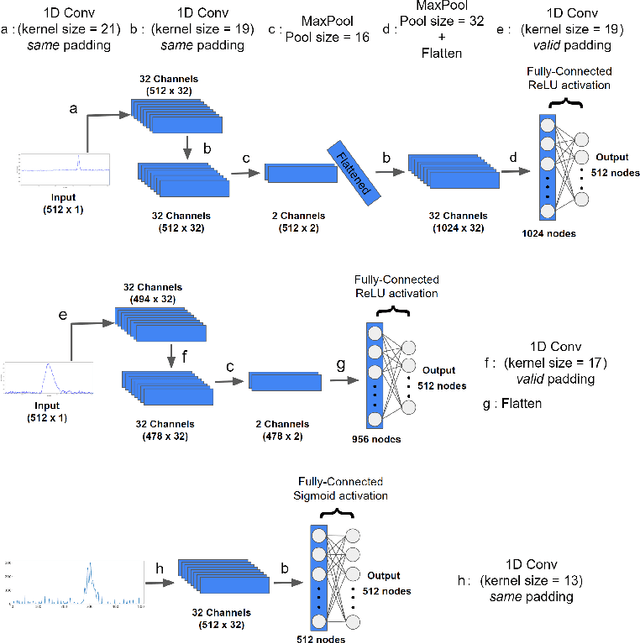
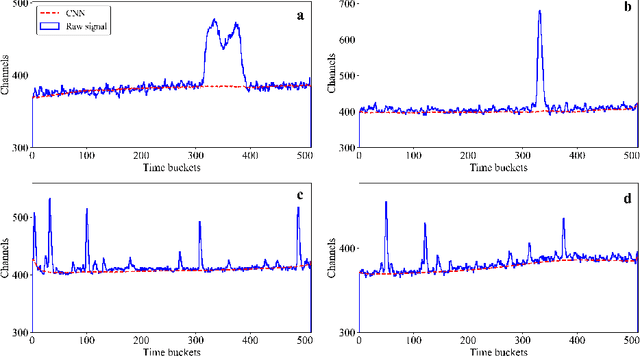
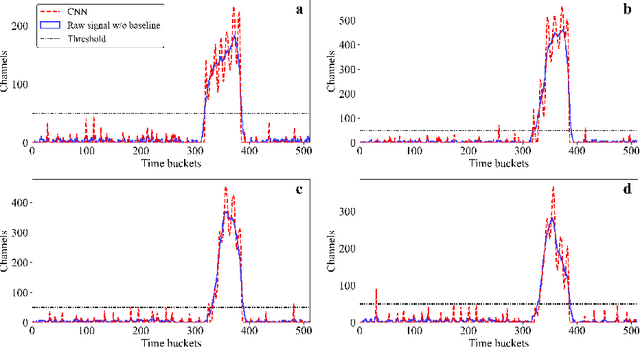
An algorithm for digital signal analysis using convolutional neural networks (CNN) was developed in this work. The main objective of this algorithm is to make the analysis of experiments with active target time projection chambers more efficient. The code is divided in three steps: baseline correction, signal deconvolution and peak detection and integration. The CNNs were able to learn the signal processing models with relative errors of less than 6\%. The analysis based on CNNs provides the same results as the traditional deconvolution algorithms, but considerably more efficient in terms of computing time (about 65 times faster). This opens up new possibilities to improve existing codes and to simplify the analysis of the large amount of data produced in active target experiments.
Inducing Early Neural Collapse in Deep Neural Networks for Improved Out-of-Distribution Detection
Sep 28, 2022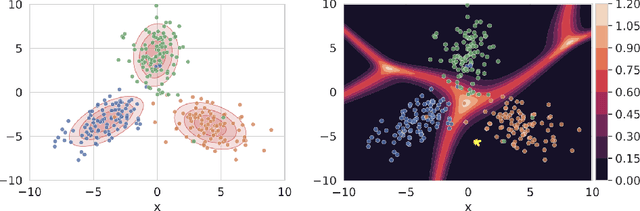
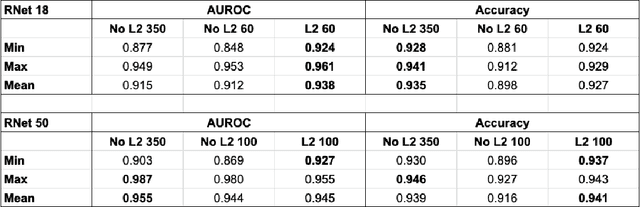
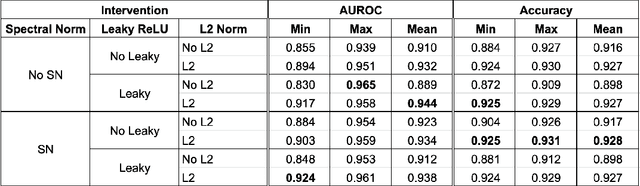
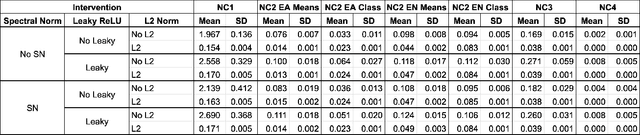
We propose a simple modification to standard ResNet architectures--L2 regularization over feature space--that substantially improves out-of-distribution (OoD) performance on the previously proposed Deep Deterministic Uncertainty (DDU) benchmark. This change also induces early Neural Collapse (NC), which we show is an effect under which better OoD performance is more probable. Our method achieves comparable or superior OoD detection scores and classification accuracy in a small fraction of the training time of the benchmark. Additionally, it substantially improves worst case OoD performance over multiple, randomly initialized models. Though we do not suggest that NC is the sole mechanism or a comprehensive explanation for OoD behaviour in deep neural networks (DNN), we believe NC's simple mathematical and geometric structure can provide a framework for analysis of this complex phenomenon in future work.
Data Feedback Loops: Model-driven Amplification of Dataset Biases
Sep 08, 2022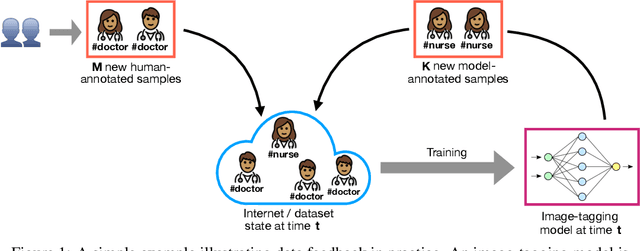

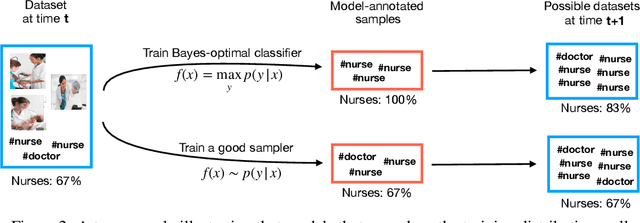

Datasets scraped from the internet have been critical to the successes of large-scale machine learning. Yet, this very success puts the utility of future internet-derived datasets at potential risk, as model outputs begin to replace human annotations as a source of supervision. In this work, we first formalize a system where interactions with one model are recorded as history and scraped as training data in the future. We then analyze its stability over time by tracking changes to a test-time bias statistic (e.g. gender bias of model predictions). We find that the degree of bias amplification is closely linked to whether the model's outputs behave like samples from the training distribution, a behavior which we characterize and define as consistent calibration. Experiments in three conditional prediction scenarios - image classification, visual role-labeling, and language generation - demonstrate that models that exhibit a sampling-like behavior are more calibrated and thus more stable. Based on this insight, we propose an intervention to help calibrate and stabilize unstable feedback systems. Code is available at https://github.com/rtaori/data_feedback.