 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Randomized Signature Layers for Signal Extraction in Time Series Data
Jan 02, 2022
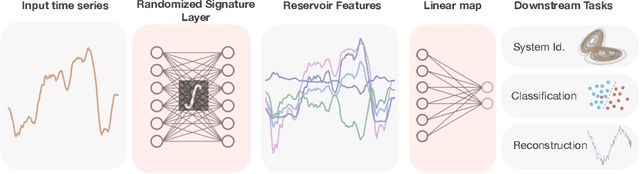

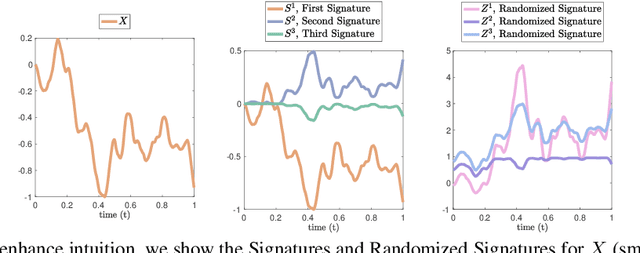
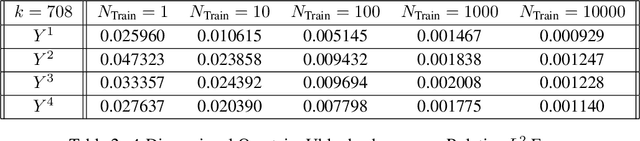
Time series analysis is a widespread task in Natural Sciences, Social Sciences, and Engineering. A fundamental problem is finding an expressive yet efficient-to-compute representation of the input time series to use as a starting point to perform arbitrary downstream tasks. In this paper, we build upon recent works that use the Signature of a path as a feature map and investigate a computationally efficient technique to approximate these features based on linear random projections. We present several theoretical results to justify our approach and empirically validate that our random projections can effectively retrieve the underlying Signature of a path. We show the surprising performance of the proposed random features on several tasks, including (1) mapping the controls of stochastic differential equations to the corresponding solutions and (2) using the Randomized Signatures as time series representation for classification tasks. When compared to corresponding truncated Signature approaches, our Randomizes Signatures are more computationally efficient in high dimensions and often lead to better accuracy and faster training. Besides providing a new tool to extract Signatures and further validating the high level of expressiveness of such features, we believe our results provide interesting conceptual links between several existing research areas, suggesting new intriguing directions for future investigations.
Unsupervised Neural Stylistic Text Generation using Transfer learning and Adapters
Oct 07, 2022

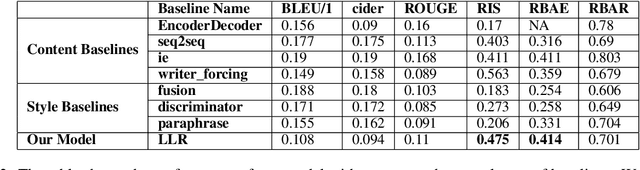

Research has shown that personality is a key driver to improve engagement and user experience in conversational systems. Conversational agents should also maintain a consistent persona to have an engaging conversation with a user. However, text generation datasets are often crowd sourced and thereby have an averaging effect where the style of the generation model is an average style of all the crowd workers that have contributed to the dataset. While one can collect persona-specific datasets for each task, it would be an expensive and time consuming annotation effort. In this work, we propose a novel transfer learning framework which updates only $0.3\%$ of model parameters to learn style specific attributes for response generation. For the purpose of this study, we tackle the problem of stylistic story ending generation using the ROC stories Corpus. We learn style specific attributes from the PERSONALITY-CAPTIONS dataset. Through extensive experiments and evaluation metrics we show that our novel training procedure can improve the style generation by 200 over Encoder-Decoder baselines while maintaining on-par content relevance metrics with
Breaking BERT: Evaluating and Optimizing Sparsified Attention
Oct 07, 2022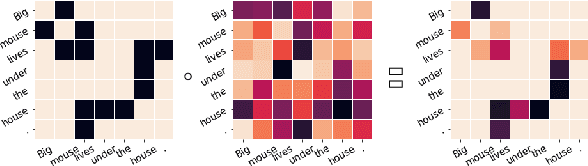


Transformers allow attention between all pairs of tokens, but there is reason to believe that most of these connections - and their quadratic time and memory - may not be necessary. But which ones? We evaluate the impact of sparsification patterns with a series of ablation experiments. First, we compare masks based on syntax, lexical similarity, and token position to random connections, and measure which patterns reduce performance the least. We find that on three common finetuning tasks even using attention that is at least 78% sparse can have little effect on performance if applied at later transformer layers, but that applying sparsity throughout the network reduces performance significantly. Second, we vary the degree of sparsity for three patterns supported by previous work, and find that connections to neighbouring tokens are the most significant. Finally, we treat sparsity as an optimizable parameter, and present an algorithm to learn degrees of neighboring connections that gives a fine-grained control over the accuracy-sparsity trade-off while approaching the performance of existing methods.
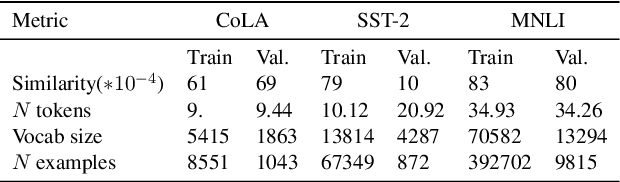
Are Representations Built from the Ground Up? An Empirical Examination of Local Composition in Language Models
Oct 07, 2022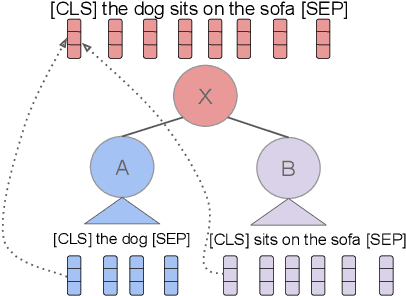

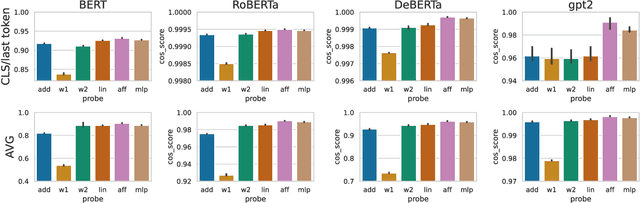

Compositionality, the phenomenon where the meaning of a phrase can be derived from its constituent parts, is a hallmark of human language. At the same time, many phrases are non-compositional, carrying a meaning beyond that of each part in isolation. Representing both of these types of phrases is critical for language understanding, but it is an open question whether modern language models (LMs) learn to do so; in this work we examine this question. We first formulate a problem of predicting the LM-internal representations of longer phrases given those of their constituents. We find that the representation of a parent phrase can be predicted with some accuracy given an affine transformation of its children. While we would expect the predictive accuracy to correlate with human judgments of semantic compositionality, we find this is largely not the case, indicating that LMs may not accurately distinguish between compositional and non-compositional phrases. We perform a variety of analyses, shedding light on when different varieties of LMs do and do not generate compositional representations, and discuss implications for future modeling work.
PCAE: A Framework of Plug-in Conditional Auto-Encoder for Controllable Text Generation
Oct 07, 2022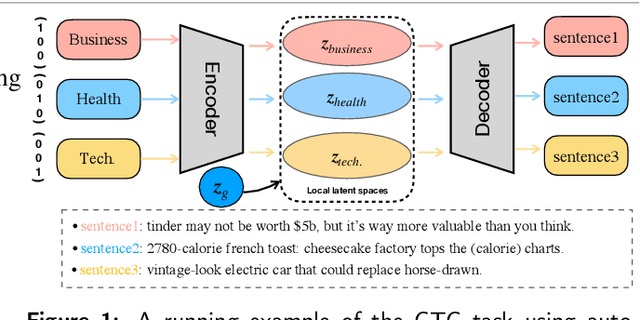

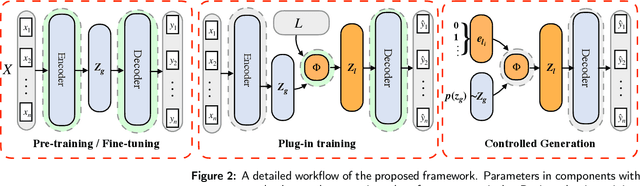

Controllable text generation has taken a gigantic step forward these days. Yet existing methods are either constrained in a one-off pattern or not efficient enough for receiving multiple conditions at every generation stage. We propose a model-agnostic framework Plug-in Conditional Auto-Encoder for Controllable Text Generation (PCAE) towards flexible and semi-supervised text generation. Our framework is "plug-and-play" with partial parameters to be fine-tuned in the pre-trained model (less than a half). Crucial to the success of PCAE is the proposed broadcasting label fusion network for navigating the global latent code to a specified local and confined space. Visualization of the local latent prior well confirms the primary devotion in hidden space of the proposed model. Moreover, extensive experiments across five related generation tasks (from 2 conditions up to 10 conditions) on both RNN- based and pre-trained BART [26] based auto-encoders reveal the high capability of PCAE, which enables generation that is highly manipulable, syntactically diverse and time-saving with minimum labeled samples. We will release our code at https://github.com/ImKeTT/pcae.
Incorporating Gradient Similarity for Robust Time Delay Estimation in Ultrasound Elastography
Mar 30, 2022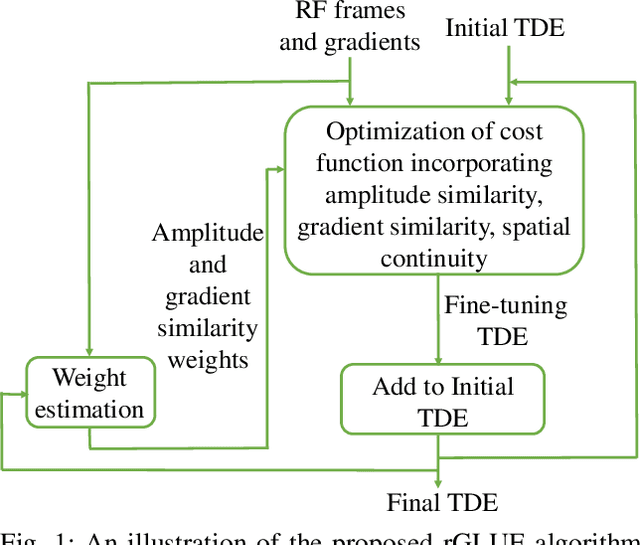


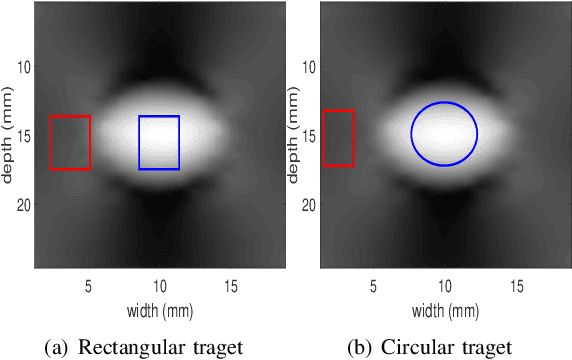
Energy-based ultrasound elastography techniques minimize a regularized cost function consisting of data and continuity terms to obtain local displacement estimates based on the local time-delay estimation (TDE) between radio-frequency (RF) frames. The data term associated with the existing techniques takes only the amplitude similarity into account and hence is not sufficiently robust to the outlier samples present in the RF frames under consideration. This drawback creates noticeable artifacts in the strain image. To resolve this issue, we propose to formulate the data function as a linear combination of the amplitude and gradient similarity constraints. We estimate the adaptive weight concerning each similarity term following an iterative scheme. Finally, we optimize the non-linear cost function in an efficient manner to convert the problem to a sparse system of linear equations which are solved for millions of variables. We call our technique rGLUE: robust data term in GLobal Ultrasound Elastography. rGLUE has been validated using simulation, phantom, in vivo liver, and breast datasets. In all of our experiments, rGLUE substantially outperforms the recent elastography methods both visually and quantitatively. For simulated, phantom, and in vivo datasets, respectively, rGLUE achieves 107%, 18%, and 23% improvements of signal-to-noise ratio (SNR) and 61%, 19%, and 25% improvements of contrast-to-noise ratio (CNR) over GLUE, a recently-published elastography algorithm.
NAF: Neural Attenuation Fields for Sparse-View CBCT Reconstruction
Sep 29, 2022This paper proposes a novel and fast self-supervised solution for sparse-view CBCT reconstruction (Cone Beam Computed Tomography) that requires no external training data. Specifically, the desired attenuation coefficients are represented as a continuous function of 3D spatial coordinates, parameterized by a fully-connected deep neural network. We synthesize projections discretely and train the network by minimizing the error between real and synthesized projections. A learning-based encoder entailing hash coding is adopted to help the network capture high-frequency details. This encoder outperforms the commonly used frequency-domain encoder in terms of having higher performance and efficiency, because it exploits the smoothness and sparsity of human organs. Experiments have been conducted on both human organ and phantom datasets. The proposed method achieves state-of-the-art accuracy and spends reasonably short computation time.
An Embarrassingly Simple Approach for Intellectual Property Rights Protection on Recurrent Neural Networks
Oct 04, 2022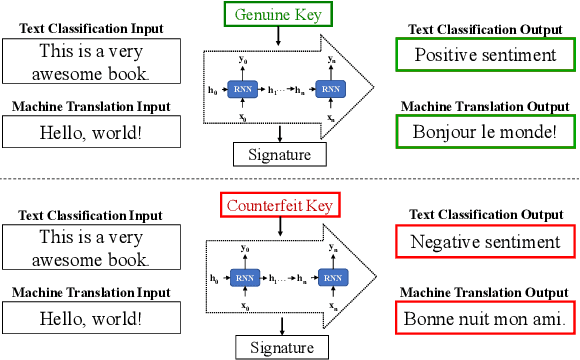
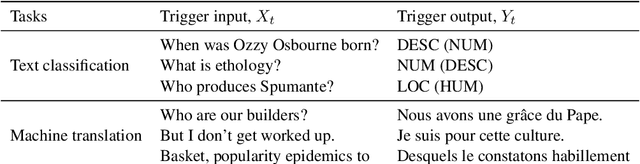
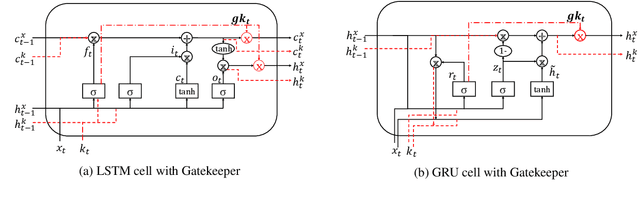
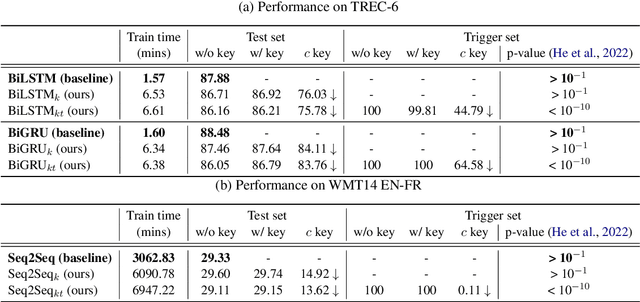
Capitalise on deep learning models, offering Natural Language Processing (NLP) solutions as a part of the Machine Learning as a Service (MLaaS) has generated handsome revenues. At the same time, it is known that the creation of these lucrative deep models is non-trivial. Therefore, protecting these inventions intellectual property rights (IPR) from being abused, stolen and plagiarized is vital. This paper proposes a practical approach for the IPR protection on recurrent neural networks (RNN) without all the bells and whistles of existing IPR solutions. Particularly, we introduce the Gatekeeper concept that resembles the recurrent nature in RNN architecture to embed keys. Also, we design the model training scheme in a way such that the protected RNN model will retain its original performance iff a genuine key is presented. Extensive experiments showed that our protection scheme is robust and effective against ambiguity and removal attacks in both white-box and black-box protection schemes on different RNN variants. Code is available at https://github.com/zhiqin1998/RecurrentIPR
SecureFedYJ: a safe feature Gaussianization protocol for Federated Learning
Oct 04, 2022

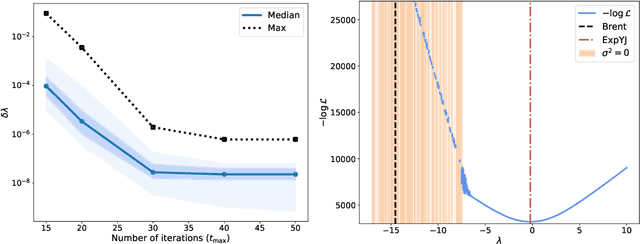
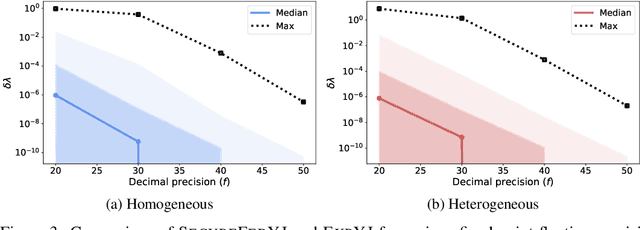
The Yeo-Johnson (YJ) transformation is a standard parametrized per-feature unidimensional transformation often used to Gaussianize features in machine learning. In this paper, we investigate the problem of applying the YJ transformation in a cross-silo Federated Learning setting under privacy constraints. For the first time, we prove that the YJ negative log-likelihood is in fact convex, which allows us to optimize it with exponential search. We numerically show that the resulting algorithm is more stable than the state-of-the-art approach based on the Brent minimization method. Building on this simple algorithm and Secure Multiparty Computation routines, we propose SecureFedYJ, a federated algorithm that performs a pooled-equivalent YJ transformation without leaking more information than the final fitted parameters do. Quantitative experiments on real data demonstrate that, in addition to being secure, our approach reliably normalizes features across silos as well as if data were pooled, making it a viable approach for safe federated feature Gaussianization.
Positive Pair Distillation Considered Harmful: Continual Meta Metric Learning for Lifelong Object Re-Identification
Oct 04, 2022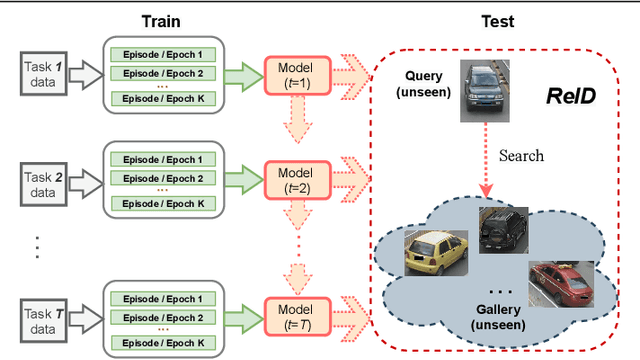

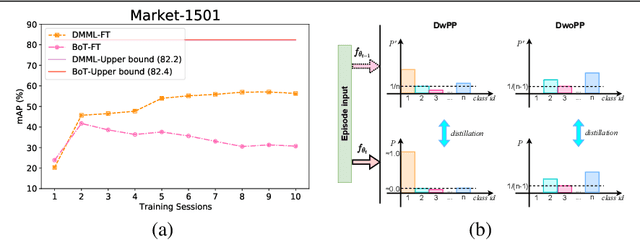

Lifelong object re-identification incrementally learns from a stream of re-identification tasks. The objective is to learn a representation that can be applied to all tasks and that generalizes to previously unseen re-identification tasks. The main challenge is that at inference time the representation must generalize to previously unseen identities. To address this problem, we apply continual meta metric learning to lifelong object re-identification. To prevent forgetting of previous tasks, we use knowledge distillation and explore the roles of positive and negative pairs. Based on our observation that the distillation and metric losses are antagonistic, we propose to remove positive pairs from distillation to robustify model updates. Our method, called Distillation without Positive Pairs (DwoPP), is evaluated on extensive intra-domain experiments on person and vehicle re-identification datasets, as well as inter-domain experiments on the LReID benchmark. Our experiments demonstrate that DwoPP significantly outperforms the state-of-the-art. The code is here: https://github.com/wangkai930418/DwoPP_code