 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AFFDEX 2.0: A Real-Time Facial Expression Analysis Toolkit
Feb 24, 2022


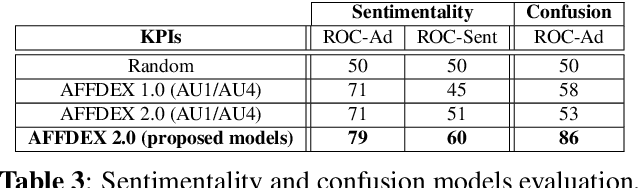

In this paper we introduce AFFDEX 2.0 - a toolkit for analyzing facial expressions in the wild, that is, it is intended for users aiming to; a) estimate the 3D head pose, b) detect facial Action Units (AUs), c) recognize basic emotions and 2 new emotional states (sentimentality and confusion), and d) detect high-level expressive metrics like blink and attention. AFFDEX 2.0 models are mainly based on Deep Learning, and are trained using a large-scale naturalistic dataset consisting of thousands of participants from different demographic groups. AFFDEX 2.0 is an enhanced version of our previous toolkit [1], that is capable of tracking efficiently faces at more challenging conditions, detecting more accurately facial expressions, and recognizing new emotional states (sentimentality and confusion). AFFDEX 2.0 can process multiple faces in real time, and is working across the Windows and Linux platforms.
Adaptive Time-Channel Beamforming for Time-of-Flight Correction
Oct 17, 2021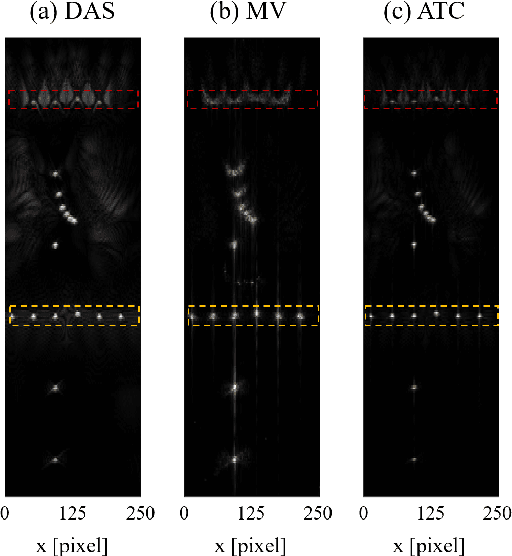
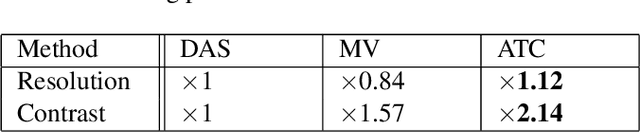
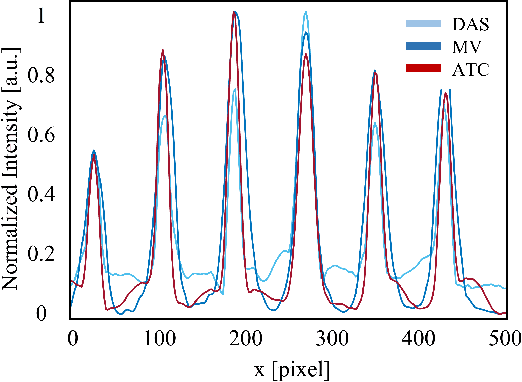
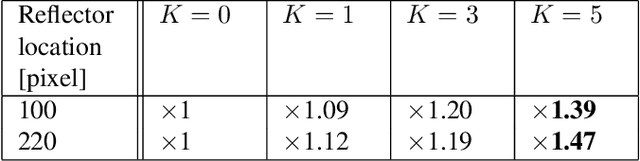
Adaptive beamforming can lead to substantial improvement in resolution and contrast of ultrasound images over standard delay and sum beamforming. Here we introduce the adaptive time-channel (ATC) beamformer, a data-driven approach that combines spatial and temporal information simultaneously, thus generalizing minimum variance beamformers. Moreover, we broaden the concept of apodization to the temporal dimension. Our approach reduces noises by allowing for the weights to adapt in both the temporal and spatial dimensions, thereby reducing artifacts caused by the media's inhomogeneities. We apply our method to in-silico data and show 12% resolution enhancement along with 2-fold contrast improvement, and significant noise reduction with respect to delay and sum and minimum variance beamformers.
Patient-Specific Heart Model Towards Atrial Fibrillation
Oct 23, 2022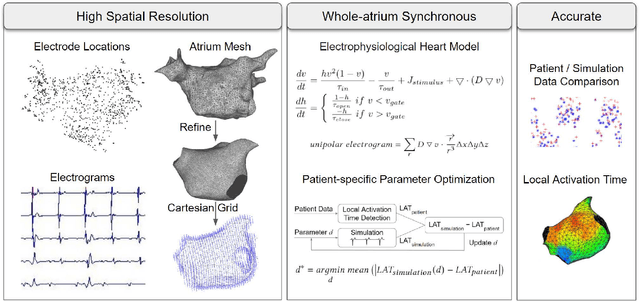
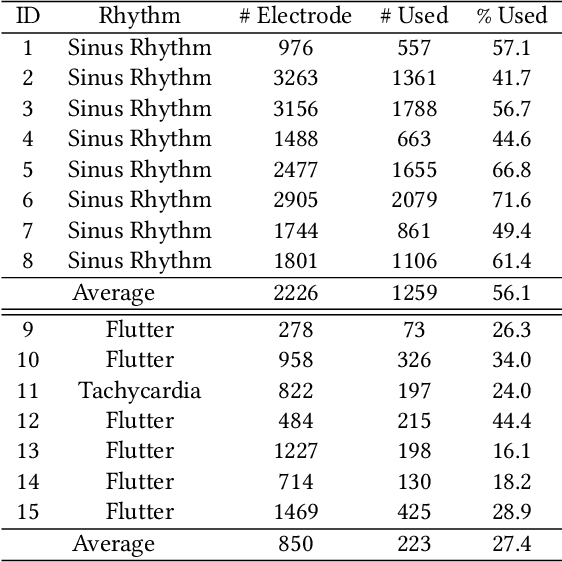
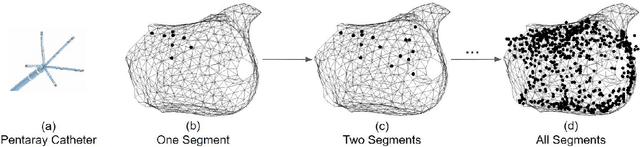
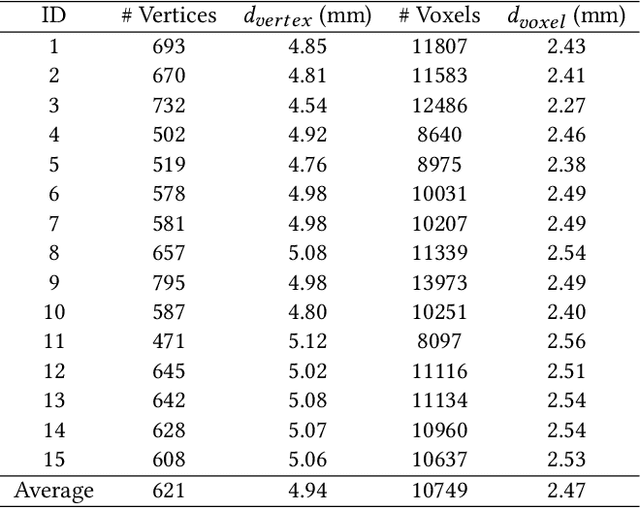
Atrial fibrillation is a heart rhythm disorder that affects tens of millions people worldwide. The most effective treatment is catheter ablation. This involves irreversible heating of abnormal cardiac tissue facilitated by electroanatomical mapping. However, it is difficult to consistently identify the triggers and sources that may initiate or perpetuate atrial fibrillation due to its chaotic behavior. We developed a patient-specific computational heart model that can accurately reproduce the activation patterns to help in localizing these triggers and sources. Our model has high spatial resolution, with whole-atrium temporal synchronous activity, and has patient-specific accurate electrophysiological activation patterns. A total of 15 patients data were processed: 8 in sinus rhythm, 6 in atrial flutter and 1 in atrial tachycardia. For resolution, the average simulation geometry voxel is a cube of 2.47 mm length. For synchrony, the model takes in about 1,500 local electrogram recordings, optimally fits parameters to the individual's atrium geometry and then generates whole-atrium activation patterns. For accuracy, the average local activation time error is 5.47 ms for sinus rhythm, 10.97 ms for flutter and tachycardia; and the average correlation is 0.95 for sinus rhythm, 0.81 for flutter and tachycardia. This promising result demonstrates our model is an effective building block in capturing more complex rhythms such as atrial fibrillation to guide physicians for effective ablation therapy.
Self-supervised Amodal Video Object Segmentation
Oct 23, 2022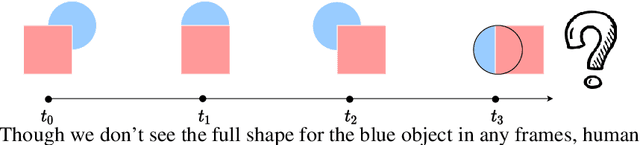
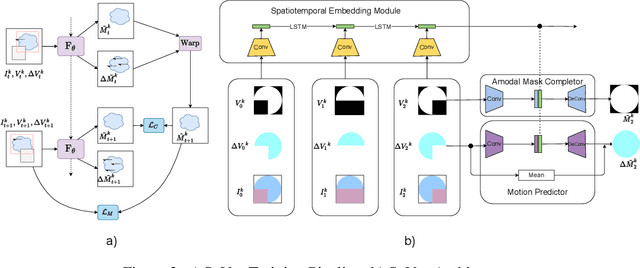
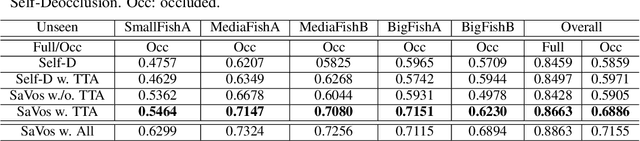

Amodal perception requires inferring the full shape of an object that is partially occluded. This task is particularly challenging on two levels: (1) it requires more information than what is contained in the instant retina or imaging sensor, (2) it is difficult to obtain enough well-annotated amodal labels for supervision. To this end, this paper develops a new framework of Self-supervised amodal Video object segmentation (SaVos). Our method efficiently leverages the visual information of video temporal sequences to infer the amodal mask of objects. The key intuition is that the occluded part of an object can be explained away if that part is visible in other frames, possibly deformed as long as the deformation can be reasonably learned. Accordingly, we derive a novel self-supervised learning paradigm that efficiently utilizes the visible object parts as the supervision to guide the training on videos. In addition to learning type prior to complete masks for known types, SaVos also learns the spatiotemporal prior, which is also useful for the amodal task and could generalize to unseen types. The proposed framework achieves the state-of-the-art performance on the synthetic amodal segmentation benchmark FISHBOWL and the real world benchmark KINS-Video-Car. Further, it lends itself well to being transferred to novel distributions using test-time adaptation, outperforming existing models even after the transfer to a new distribution.
Improved Feature Distillation via Projector Ensemble
Oct 27, 2022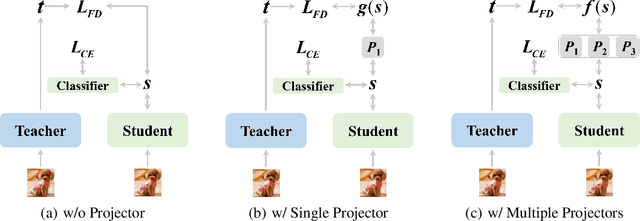

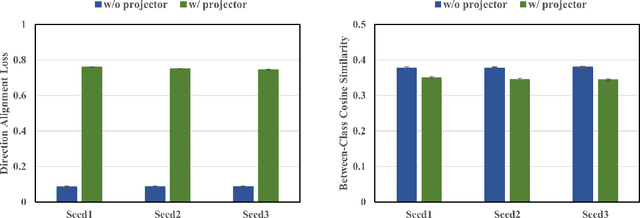

In knowledge distillation, previous feature distillation methods mainly focus on the design of loss functions and the selection of the distilled layers, while the effect of the feature projector between the student and the teacher remains under-explored. In this paper, we first discuss a plausible mechanism of the projector with empirical evidence and then propose a new feature distillation method based on a projector ensemble for further performance improvement. We observe that the student network benefits from a projector even if the feature dimensions of the student and the teacher are the same. Training a student backbone without a projector can be considered as a multi-task learning process, namely achieving discriminative feature extraction for classification and feature matching between the student and the teacher for distillation at the same time. We hypothesize and empirically verify that without a projector, the student network tends to overfit the teacher's feature distributions despite having different architecture and weights initialization. This leads to degradation on the quality of the student's deep features that are eventually used in classification. Adding a projector, on the other hand, disentangles the two learning tasks and helps the student network to focus better on the main feature extraction task while still being able to utilize teacher features as a guidance through the projector. Motivated by the positive effect of the projector in feature distillation, we propose an ensemble of projectors to further improve the quality of student features. Experimental results on different datasets with a series of teacher-student pairs illustrate the effectiveness of the proposed method.
JoJoNet: Joint-contrast and Joint-sampling-and-reconstruction Network for Multi-contrast MRI
Oct 27, 2022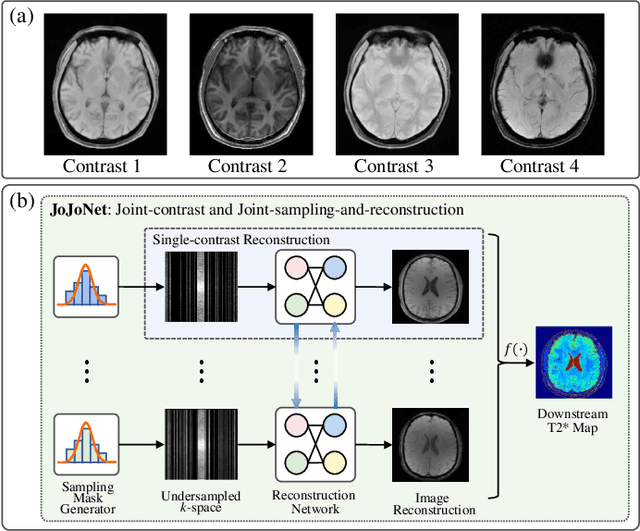
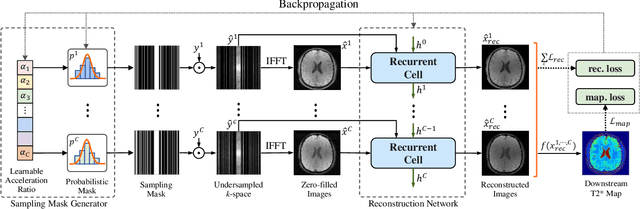
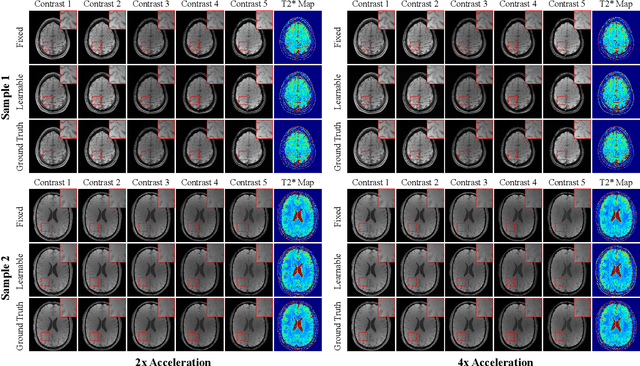
Multi-contrast Magnetic Resonance Imaging (MRI) generates multiple medical images with rich and complementary information for routine clinical use; however, it suffers from a long acquisition time. Recent works for accelerating MRI, mainly designed for single contrast, may not be optimal for multi-contrast scenario since the inherent correlations among the multi-contrast images are not exploited. In addition, independent reconstruction of each contrast usually does not translate to optimal performance of downstream tasks. Motivated by these aspects, in this paper we design an end-to-end framework for accelerating multi-contrast MRI which simultaneously optimizes the entire MR imaging workflow including sampling, reconstruction and downstream tasks to achieve the best overall outcomes. The proposed framework consists of a sampling mask generator for each image contrast and a reconstructor exploiting the inter-contrast correlations with a recurrent structure which enables the information sharing in a holistic way. The sampling mask generator and the reconstructor are trained jointly across the multiple image contrasts. The acceleration ratio of each image contrast is also learnable and can be driven by a downstream task performance. We validate our approach on a multi-contrast brain dataset and a multi-contrast knee dataset. Experiments show that (1) our framework consistently outperforms the baselines designed for single contrast on both datasets; (2) our newly designed recurrent reconstruction network effectively improves the reconstruction quality for multi-contrast images; (3) the learnable acceleration ratio improves the downstream task performance significantly. Overall, this work has potentials to open up new avenues for optimizing the entire multi-contrast MR imaging workflow.
Self-Supervised Training of Speaker Encoder with Multi-Modal Diverse Positive Pairs
Oct 27, 2022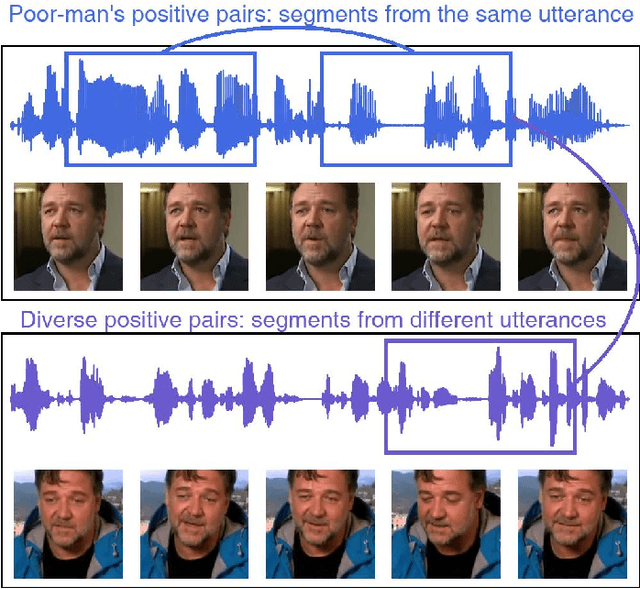
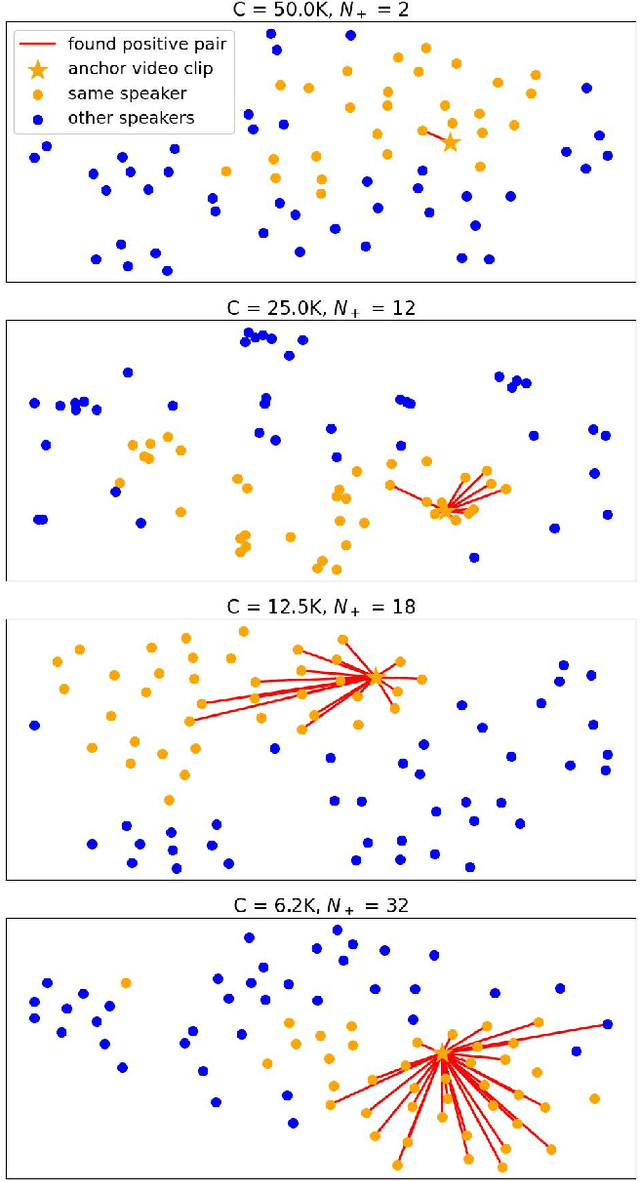
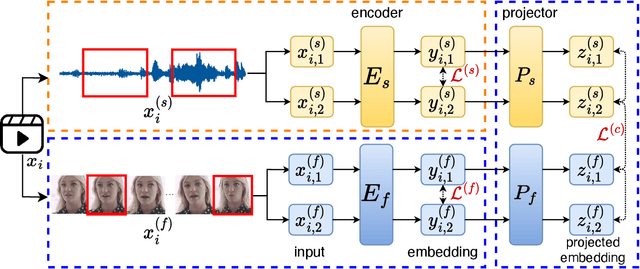
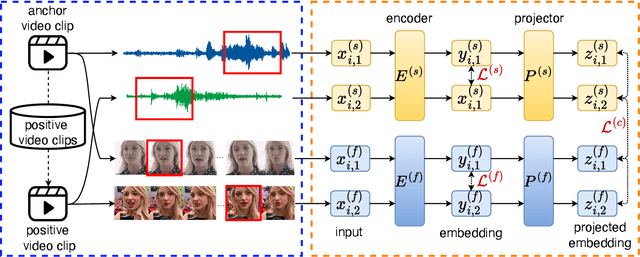
We study a novel neural architecture and its training strategies of speaker encoder for speaker recognition without using any identity labels. The speaker encoder is trained to extract a fixed-size speaker embedding from a spoken utterance of various length. Contrastive learning is a typical self-supervised learning technique. However, the quality of the speaker encoder depends very much on the sampling strategy of positive and negative pairs. It is common that we sample a positive pair of segments from the same utterance. Unfortunately, such poor-man's positive pairs (PPP) lack necessary diversity for the training of a robust encoder. In this work, we propose a multi-modal contrastive learning technique with novel sampling strategies. By cross-referencing between speech and face data, we study a method that finds diverse positive pairs (DPP) for contrastive learning, thus improving the robustness of the speaker encoder. We train the speaker encoder on the VoxCeleb2 dataset without any speaker labels, and achieve an equal error rate (EER) of 2.89\%, 3.17\% and 6.27\% under the proposed progressive clustering strategy, and an EER of 1.44\%, 1.77\% and 3.27\% under the two-stage learning strategy with pseudo labels, on the three test sets of VoxCeleb1. This novel solution outperforms the state-of-the-art self-supervised learning methods by a large margin, at the same time, achieves comparable results with the supervised learning counterpart. We also evaluate our self-supervised learning technique on LRS2 and LRW datasets, where the speaker information is unknown. All experiments suggest that the proposed neural architecture and sampling strategies are robust across datasets.
Personalized Longitudinal Assessment of Multiple Sclerosis Using Smartphones
Sep 20, 2022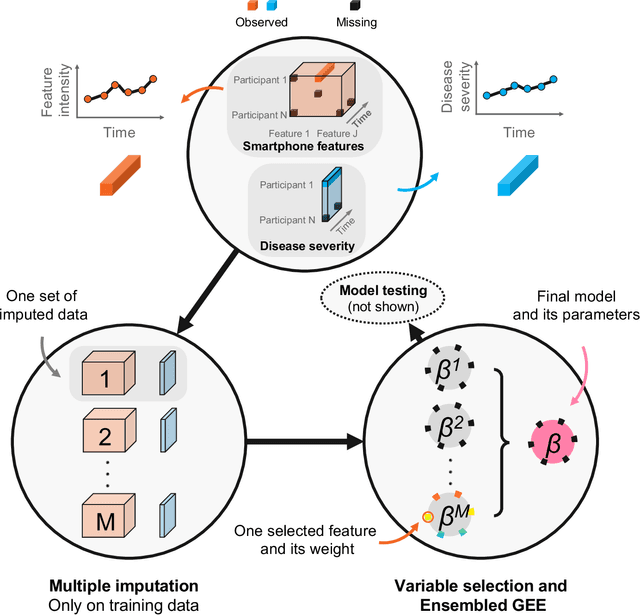

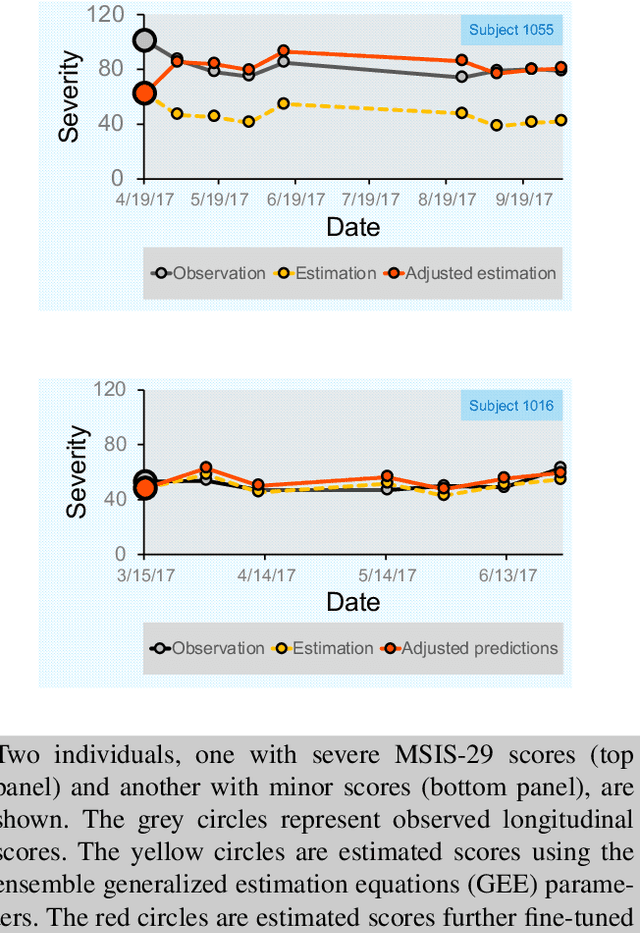
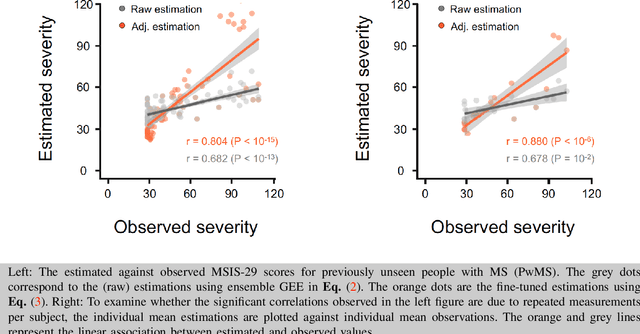
Personalized longitudinal disease assessment is central to quickly diagnosing, appropriately managing, and optimally adapting the therapeutic strategy of multiple sclerosis (MS). It is also important for identifying the idiosyncratic subject-specific disease profiles. Here, we design a novel longitudinal model to map individual disease trajectories in an automated way using sensor data that may contain missing values. First, we collect digital measurements related to gait and balance, and upper extremity functions using sensor-based assessments administered on a smartphone. Next, we treat missing data via imputation. We then discover potential markers of MS by employing a generalized estimation equation. Subsequently, parameters learned from multiple training datasets are ensembled to form a simple, unified longitudinal predictive model to forecast MS over time in previously unseen people with MS. To mitigate potential underestimation for individuals with severe disease scores, the final model incorporates additional subject-specific fine-tuning using data from the first day. The results show that the proposed model is promising to achieve personalized longitudinal MS assessment; they also suggest that features related to gait and balance as well as upper extremity function, remotely collected from sensor-based assessments, may be useful digital markers for predicting MS over time.
Long-time prediction of nonlinear parametrized dynamical systems by deep learning-based reduced order models
Jan 25, 2022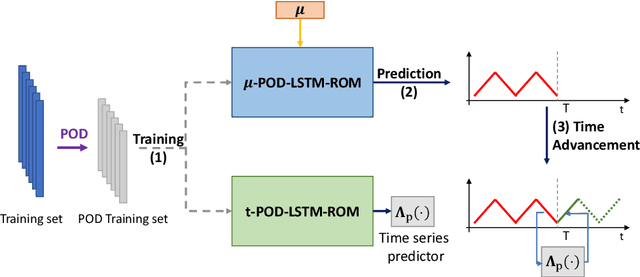
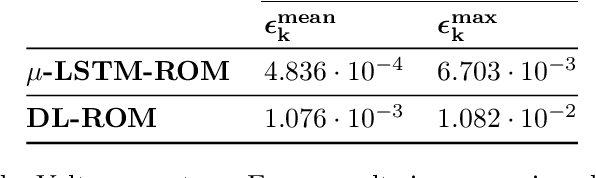
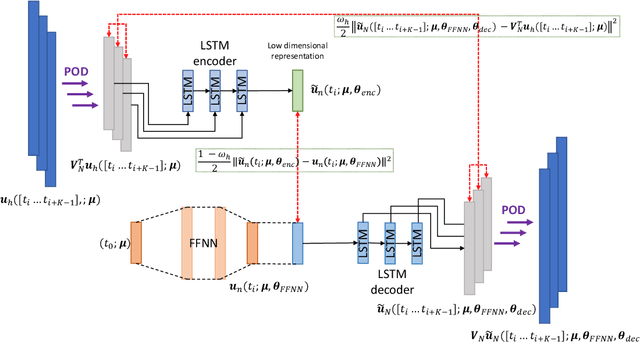

Deep learning-based reduced order models (DL-ROMs) have been recently proposed to overcome common limitations shared by conventional ROMs - built, e.g., exclusively through proper orthogonal decomposition (POD) - when applied to nonlinear time-dependent parametrized PDEs. In particular, POD-DL-ROMs can achieve extreme efficiency in the training stage and faster than real-time performances at testing, thanks to a prior dimensionality reduction through POD and a DL-based prediction framework. Nonetheless, they share with conventional ROMs poor performances regarding time extrapolation tasks. This work aims at taking a further step towards the use of DL algorithms for the efficient numerical approximation of parametrized PDEs by introducing the $\mu t$-POD-LSTM-ROM framework. This novel technique extends the POD-DL-ROM framework by adding a two-fold architecture taking advantage of long short-term memory (LSTM) cells, ultimately allowing long-term prediction of complex systems' evolution, with respect to the training window, for unseen input parameter values. Numerical results show that this recurrent architecture enables the extrapolation for time windows up to 15 times larger than the training time domain, and achieves better testing time performances with respect to the already lightning-fast POD-DL-ROMs.
An adaptive multi-fidelity framework for safety analysis of connected and automated vehicles
Oct 25, 2022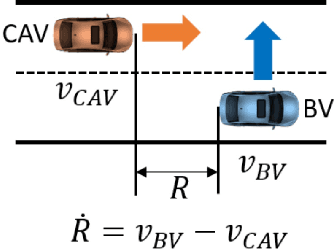
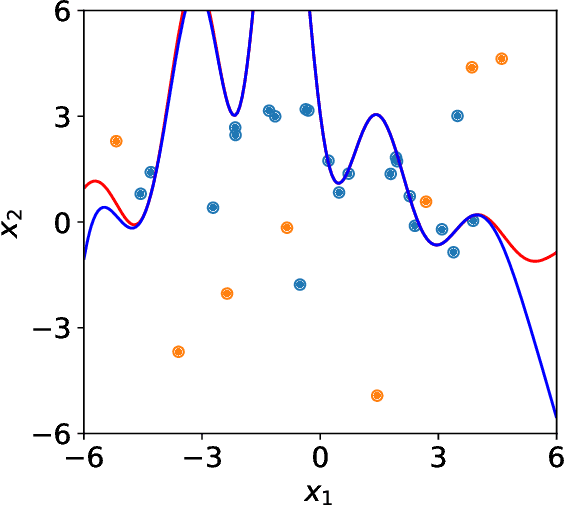
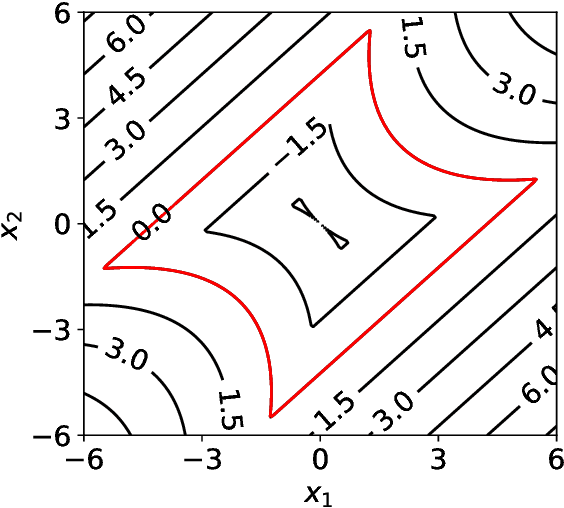
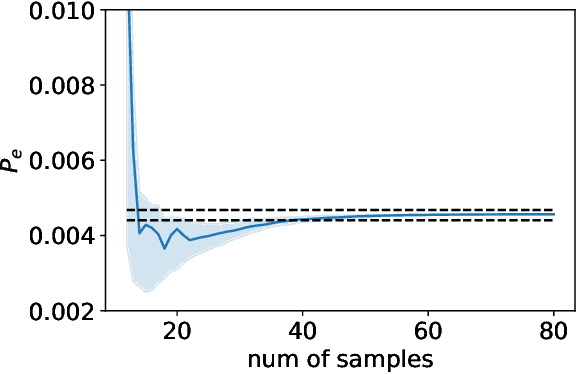
Testing and evaluation are expensive but critical steps in the development and deployment of connected and automated vehicles (CAVs). In this paper, we develop an adaptive sampling framework to efficiently evaluate the accident rate of CAVs, particularly for scenario-based tests where the probability distribution of input parameters is known from the Naturalistic Driving Data. Our framework relies on a surrogate model to approximate the CAV performance and a novel acquisition function to maximize the benefit (information to accident rate) of the next sample formulated through an information-theoretic consideration. In addition to the standard application with only a single high-fidelity model of CAV performance, we also extend our approach to the bi-fidelity context where an additional low-fidelity model can be used at a lower computational cost to approximate the CAV performance. Accordingly for the second case, our approach is formulated such that it allows the choice of the next sample, in terms of both fidelity level (i.e., which model to use) and sampling location to maximize the benefit per cost. Our framework is tested in a widely-considered two-dimensional cut-in problem for CAVs, where Intelligent Driving Model (IDM) with different time resolutions are used to construct the high and low-fidelity models. We show that our single-fidelity method outperforms the existing approach for the same problem, and the bi-fidelity method can further save half of the computational cost to reach a similar accuracy in estimating the accident rate.