 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Policy-based Approach to the SpecAugment Method for Low Resource E2E ASR
Oct 16, 2022
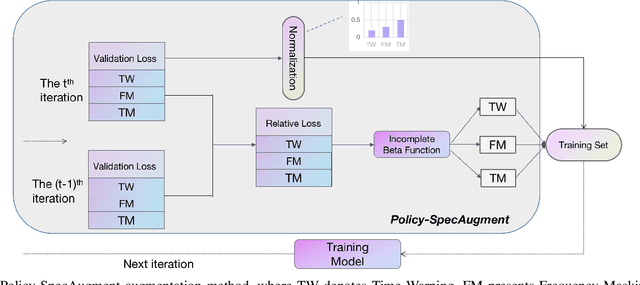
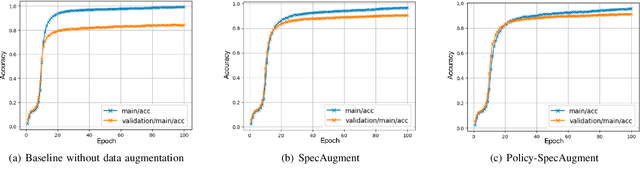
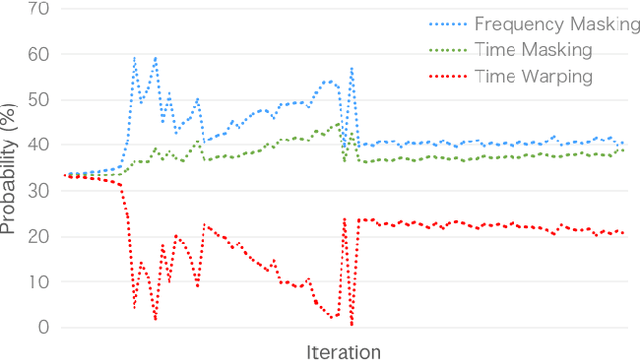
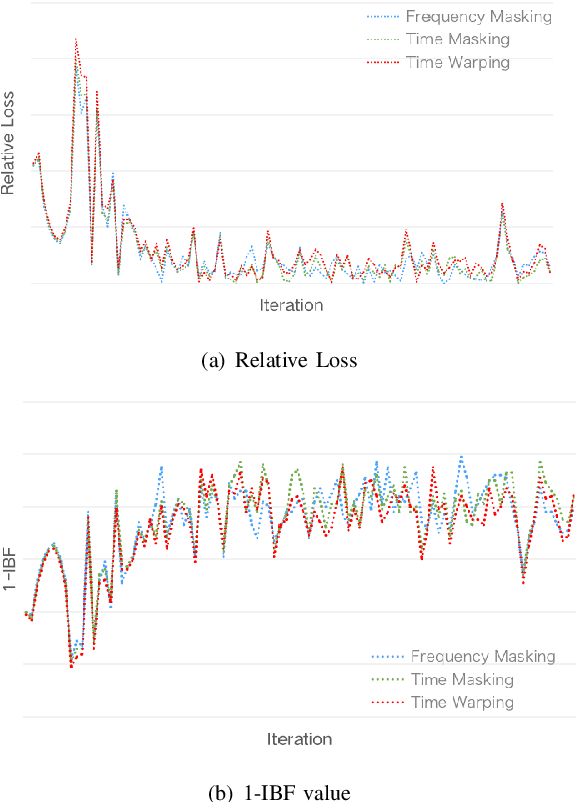
SpecAugment is a very effective data augmentation method for both HMM and E2E-based automatic speech recognition (ASR) systems. Especially, it also works in low-resource scenarios. However, SpecAugment masks the spectrum of time or the frequency domain in a fixed augmentation policy, which may bring relatively less data diversity to the low-resource ASR. In this paper, we propose a policy-based SpecAugment (Policy-SpecAugment) method to alleviate the above problem. The idea is to use the augmentation-select policy and the augmentation-parameter changing policy to solve the fixed way. These policies are learned based on the loss of validation set, which is applied to the corresponding augmentation policies. It aims to encourage the model to learn more diverse data, which the model relatively requires. In experiments, we evaluate the effectiveness of our approach in low-resource scenarios, i.e., the 100 hours librispeech task. According to the results and analysis, we can see that the above issue can be obviously alleviated using our proposal. In addition, the experimental results show that, compared with the state-of-the-art SpecAugment, the proposed Policy-SpecAugment has a relative WER reduction of more than 10% on the Test/Dev-clean set, more than 5% on the Test/Dev-other set, and an absolute WER reduction of more than 1% on all test sets.
The Impact of Task Underspecification in Evaluating Deep Reinforcement Learning
Oct 16, 2022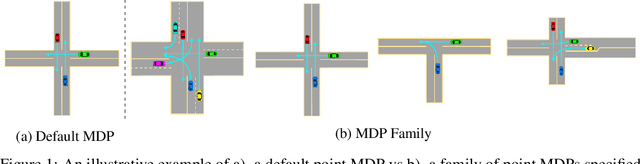

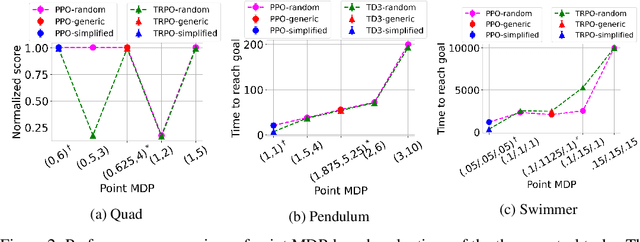
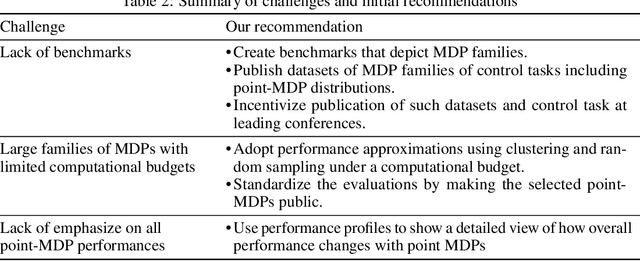
Evaluations of Deep Reinforcement Learning (DRL) methods are an integral part of scientific progress of the field. Beyond designing DRL methods for general intelligence, designing task-specific methods is becoming increasingly prominent for real-world applications. In these settings, the standard evaluation practice involves using a few instances of Markov Decision Processes (MDPs) to represent the task. However, many tasks induce a large family of MDPs owing to variations in the underlying environment, particularly in real-world contexts. For example, in traffic signal control, variations may stem from intersection geometries and traffic flow levels. The select MDP instances may thus inadvertently cause overfitting, lacking the statistical power to draw conclusions about the method's true performance across the family. In this article, we augment DRL evaluations to consider parameterized families of MDPs. We show that in comparison to evaluating DRL methods on select MDP instances, evaluating the MDP family often yields a substantially different relative ranking of methods, casting doubt on what methods should be considered state-of-the-art. We validate this phenomenon in standard control benchmarks and the real-world application of traffic signal control. At the same time, we show that accurately evaluating on an MDP family is nontrivial. Overall, this work identifies new challenges for empirical rigor in reinforcement learning, especially as the outcomes of DRL trickle into downstream decision-making.
Automatic Identification and Classification of Share Buybacks and their Effect on Short-, Mid- and Long-Term Returns
Sep 26, 2022
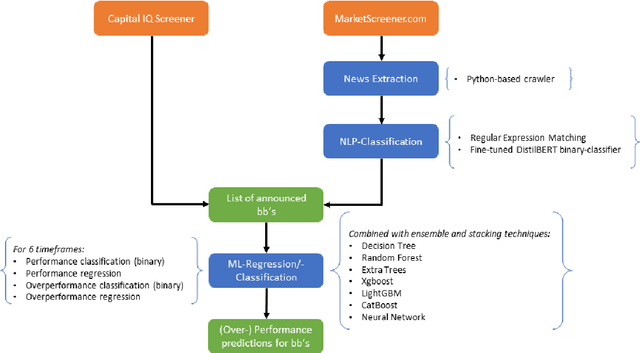
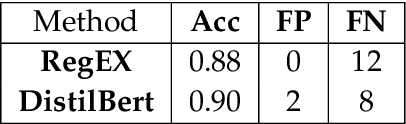
This thesis investigates share buybacks, specifically share buyback announcements. It addresses how to recognize such announcements, the excess return of share buybacks, and the prediction of returns after a share buyback announcement. We illustrate two NLP approaches for the automated detection of share buyback announcements. Even with very small amounts of training data, we can achieve an accuracy of up to 90%. This thesis utilizes these NLP methods to generate a large dataset consisting of 57,155 share buyback announcements. By analyzing this dataset, this thesis aims to show that most companies, which have a share buyback announced are underperforming the MSCI World. A minority of companies, however, significantly outperform the MSCI World. This significant overperformance leads to a net gain when looking at the averages of all companies. If the benchmark index is adjusted for the respective size of the companies, the average overperformance disappears, and the majority underperforms even greater. However, it was found that companies that announce a share buyback with a volume of at least 1% of their market cap, deliver, on average, a significant overperformance, even when using an adjusted benchmark. It was also found that companies that announce share buybacks in times of crisis emerge better than the overall market. Additionally, the generated dataset was used to train 72 machine learning models. Through this, it was able to find many strategies that could achieve an accuracy of up to 77% and generate great excess returns. A variety of performance indicators could be improved across six different time frames and a significant overperformance was identified. This was achieved by training several models for different tasks and time frames as well as combining these different models, generating significant improvement by fusing weak learners, in order to create one strong learner.
Covariance Recovery for One-Bit Sampled Data With Time-Varying Sampling Thresholds-Part I: Stationary Signals
Mar 16, 2022
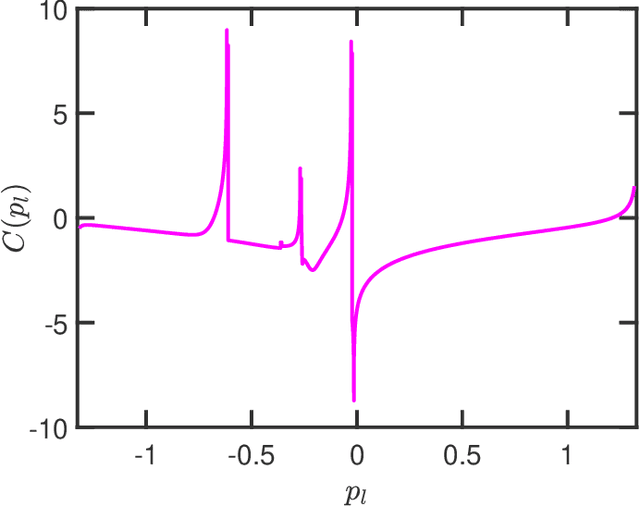
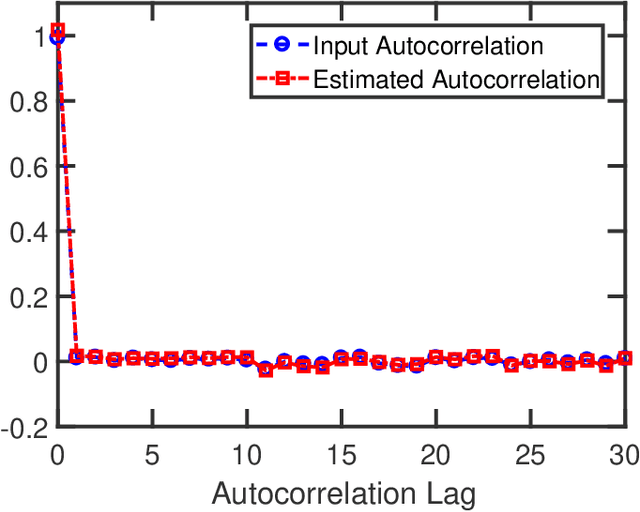
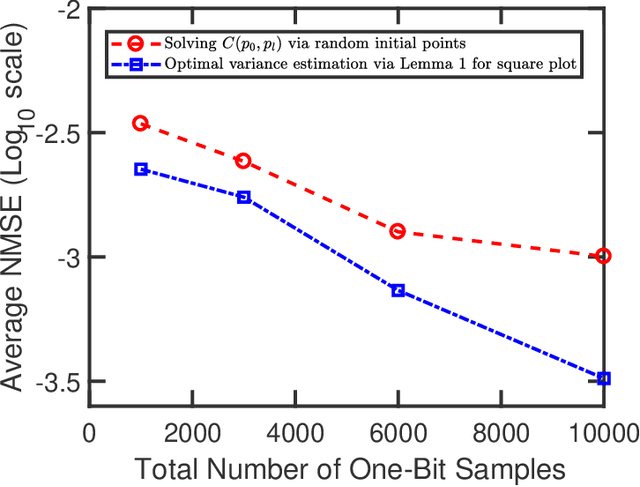
One-bit quantization, which relies on comparing the signals of interest with given threshold levels, has attracted considerable attention in signal processing for communications and sensing. A useful tool for covariance recovery in such settings is the arcsine law, that estimates the normalized covariance matrix of zero-mean stationary input signals. This relation, however, only considers a zero sampling threshold, which can cause a remarkable information loss. In this paper, the idea of the arcsine law is extended to the case where one-bit analog-to-digital converters (ADCs) apply time-varying thresholds. Specifically, three distinct approaches are proposed, investigated, and compared, to recover the autocorrelation sequence of the stationary signals of interest. Additionally, we will study a modification of the Bussgang law, a famous relation facilitating the recovery of the cross-correlation between the one-bit sampled data and the zero-mean stationary input signal. Similar to the case of the arcsine law, the Bussgang law only considers a zero sampling threshold. This relation is also extended to accommodate the more general case of time-varying thresholds for the stationary input signals.
TEFL: Turbo Explainable Federated Learning for 6G Trustworthy Zero-Touch Network Slicing
Oct 18, 2022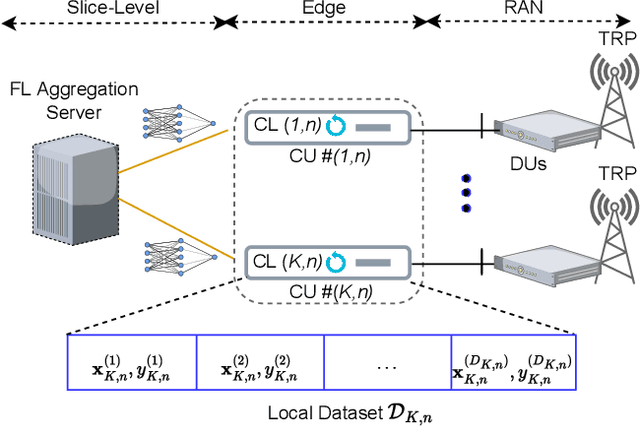
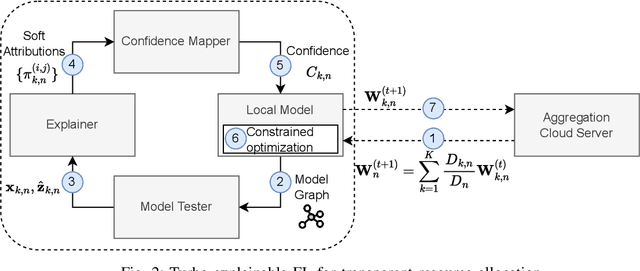

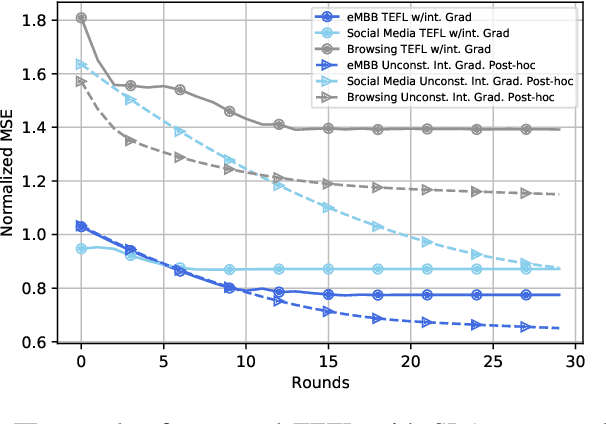
Sixth-generation (6G) networks anticipate intelligently supporting a massive number of coexisting and heterogeneous slices associated with various vertical use cases. Such a context urges the adoption of artificial intelligence (AI)-driven zero-touch management and orchestration (MANO) of the end-to-end (E2E) slices under stringent service level agreements (SLAs). Specifically, the trustworthiness of the AI black-boxes in real deployment can be achieved by explainable AI (XAI) tools to build transparency between the interacting actors in the slicing ecosystem, such as tenants, infrastructure providers and operators. Inspired by the turbo principle, this paper presents a novel iterative explainable federated learning (FL) approach where a constrained resource allocation model and an \emph{explainer} exchange -- in a closed loop (CL) fashion -- soft attributions of the features as well as inference predictions to achieve a transparent and SLA-aware zero-touch service management (ZSM) of 6G network slices at RAN-Edge setup under non-independent identically distributed (non-IID) datasets. In particular, we quantitatively validate the faithfulness of the explanations via the so-called attribution-based \emph{confidence metric} that is included as a constraint in the run-time FL optimization task. In this respect, Integrated-Gradient (IG) as well as Input $\times$ Gradient and SHAP are used to generate the attributions for the turbo explainable FL (TEFL), wherefore simulation results under different methods confirm its superiority over an unconstrained Integrated-Gradient \emph{post-hoc} FL baseline.
Generalizing in the Real World with Representation Learning
Oct 18, 2022
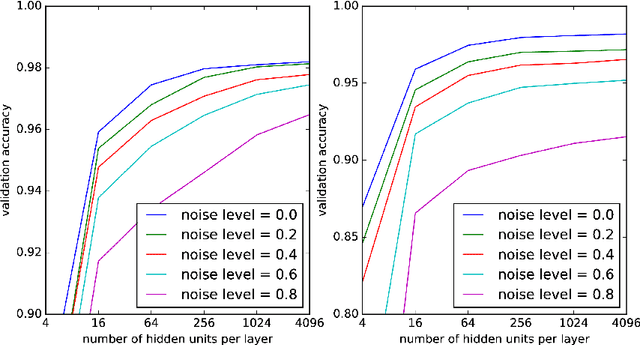
Machine learning (ML) formalizes the problem of getting computers to learn from experience as optimization of performance according to some metric(s) on a set of data examples. This is in contrast to requiring behaviour specified in advance (e.g. by hard-coded rules). Formalization of this problem has enabled great progress in many applications with large real-world impact, including translation, speech recognition, self-driving cars, and drug discovery. But practical instantiations of this formalism make many assumptions - for example, that data are i.i.d.: independent and identically distributed - whose soundness is seldom investigated. And in making great progress in such a short time, the field has developed many norms and ad-hoc standards, focused on a relatively small range of problem settings. As applications of ML, particularly in artificial intelligence (AI) systems, become more pervasive in the real world, we need to critically examine these assumptions, norms, and problem settings, as well as the methods that have become de-facto standards. There is much we still do not understand about how and why deep networks trained with stochastic gradient descent are able to generalize as well as they do, why they fail when they do, and how they will perform on out-of-distribution data. In this thesis I cover some of my work towards better understanding deep net generalization, identify several ways assumptions and problem settings fail to generalize to the real world, and propose ways to address those failures in practice.
Hidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Oct 18, 2022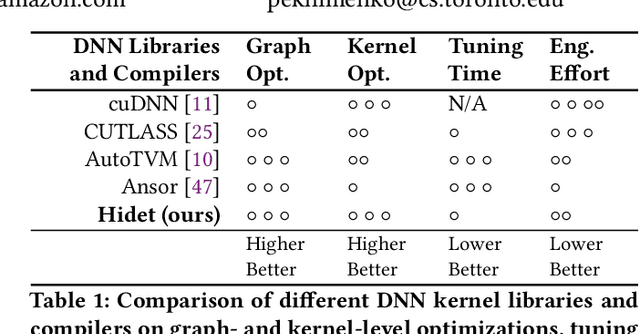
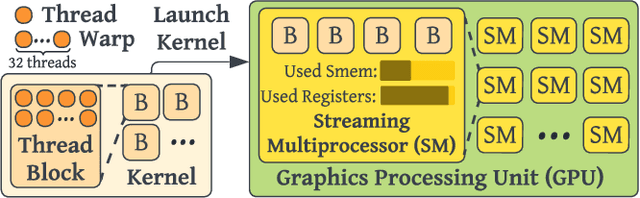

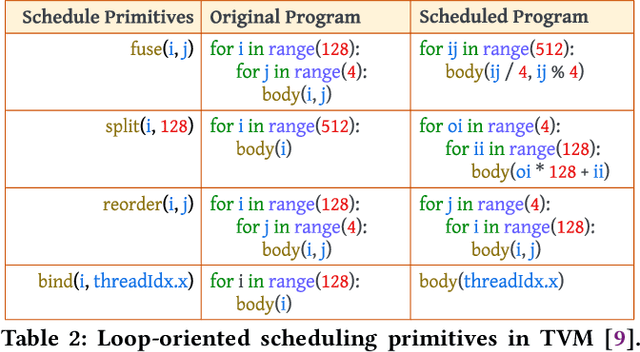
As deep learning models nowadays are widely adopted by both cloud services and edge devices, the latency of deep learning model inferences becomes crucial to provide efficient model serving. However, it is challenging to develop efficient tensor programs for deep learning operators due to the high complexity of modern accelerators (e.g., NVIDIA GPUs and Google TPUs) and the rapidly growing number of operators. Deep learning compilers, such as Apache TVM, adopt declarative scheduling primitives to lower the bar of developing tensor programs. However, we show that this approach is insufficient to cover state-of-the-art tensor program optimizations (e.g., double buffering). In this paper, we propose to embed the scheduling process into tensor programs and use dedicated mappings, called task mappings, to define the computation assignment and ordering directly in the tensor programs. This new approach greatly enriches the expressible optimizations by allowing developers to manipulate tensor programs at a much finer granularity (e.g., allowing program statement-level optimizations). We call the proposed method the task-mapping-oriented programming paradigm. With the proposed paradigm, we implement a deep learning compiler - Hidet. Extensive experiments on modern convolution and transformer models show that Hidet outperforms state-of-the-art DNN inference framework, ONNX Runtime, and compiler, TVM equipped with scheduler AutoTVM and Ansor, by up to 1.48x (1.22x on average) with enriched optimizations. It also reduces the tuning time by 20x and 11x compared with AutoTVM and Ansor, respectively.
Research of an optimization model for servicing a network of ATMs and information payment terminals
Oct 18, 2022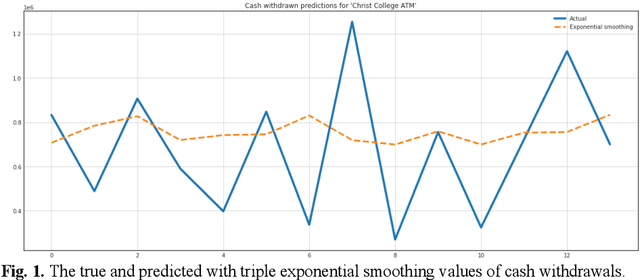
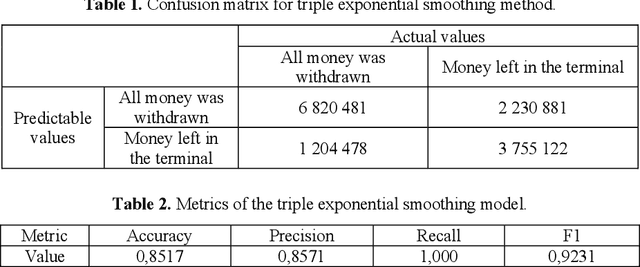
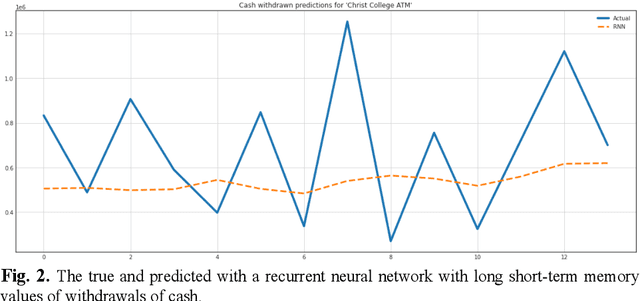

The steadily high demand for cash contributes to the expansion of the network of Bank payment terminals. To optimize the amount of cash in payment terminals, it is necessary to minimize the cost of servicing them and ensure that there are no excess funds in the network. The purpose of this work is to create a cash management system in the network of payment terminals. The article discusses the solution to the problem of determining the optimal amount of funds to be loaded into the terminals, and the effective frequency of collection, which allows to get additional income by investing the released funds. The paper presents the results of predicting daily cash withdrawals at ATMs using a triple exponential smoothing model, a recurrent neural network with long short-term memory, and a model of singular spectrum analysis. These forecasting models allowed us to obtain a sufficient level of correct forecasts with good accuracy and completeness. The results of forecasting cash withdrawals were used to build a discrete optimal control model, which was used to develop an optimal schedule for adding funds to the payment terminal. It is proved that the efficiency and reliability of the proposed model is higher than that of the classical Baumol-Tobin inventory management model: when tested on the time series of three ATMs, the discrete optimal control model did not allow exhaustion of funds and allowed to earn on average 30% more than the classical model.
Virtual Reality via Object Poses and Active Learning: Realizing Telepresence Robots with Aerial Manipulation Capabilities
Oct 18, 2022

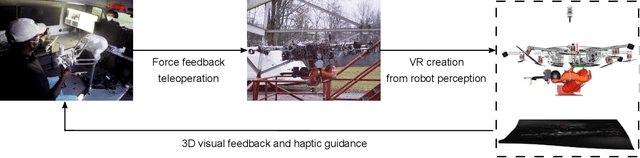
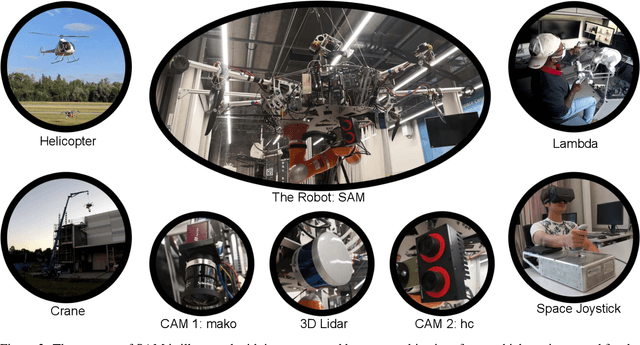
This article presents a novel telepresence system for advancing aerial manipulation in dynamic and unstructured environments. The proposed system not only features a haptic device, but also a virtual reality (VR) interface that provides real-time 3D displays of the robot's workspace as well as a haptic guidance to its remotely located operator. To realize this, multiple sensors namely a LiDAR, cameras and IMUs are utilized. For processing of the acquired sensory data, pose estimation pipelines are devised for industrial objects of both known and unknown geometries. We further propose an active learning pipeline in order to increase the sample efficiency of a pipeline component that relies on Deep Neural Networks (DNNs) based object detection. All these algorithms jointly address various challenges encountered during the execution of perception tasks in industrial scenarios. In the experiments, exhaustive ablation studies are provided to validate the proposed pipelines. Methodologically, these results commonly suggest how an awareness of the algorithms' own failures and uncertainty ("introspection") can be used tackle the encountered problems. Moreover, outdoor experiments are conducted to evaluate the effectiveness of the overall system in enhancing aerial manipulation capabilities. In particular, with flight campaigns over days and nights, from spring to winter, and with different users and locations, we demonstrate over 70 robust executions of pick-and-place, force application and peg-in-hole tasks with the DLR cable-Suspended Aerial Manipulator (SAM). As a result, we show the viability of the proposed system in future industrial applications.
Time Series Forecasting Using Fuzzy Cognitive Maps: A Survey
Jan 10, 2022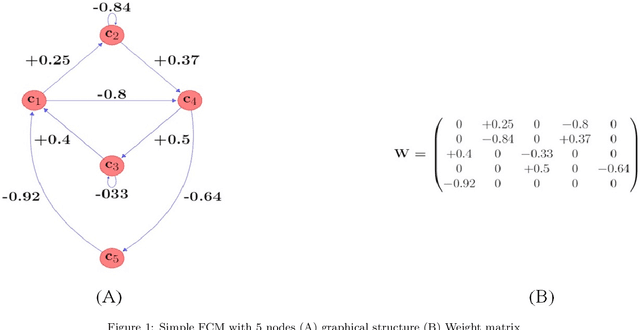
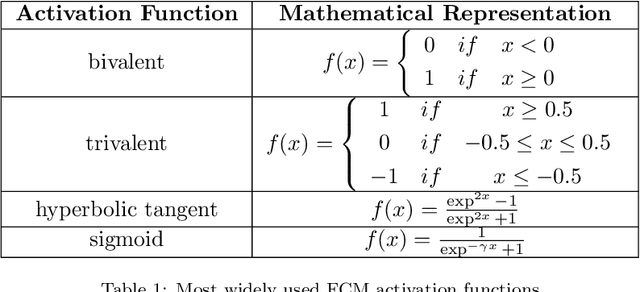

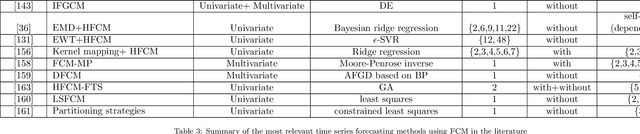
Among various soft computing approaches for time series forecasting, Fuzzy Cognitive Maps (FCM) have shown remarkable results as a tool to model and analyze the dynamics of complex systems. FCM have similarities to recurrent neural networks and can be classified as a neuro-fuzzy method. In other words, FCMs are a mixture of fuzzy logic, neural network, and expert system aspects, which act as a powerful tool for simulating and studying the dynamic behavior of complex systems. The most interesting features are knowledge interpretability, dynamic characteristics and learning capability. The goal of this survey paper is mainly to present an overview on the most relevant and recent FCM-based time series forecasting models proposed in the literature. In addition, this article considers an introduction on the fundamentals of FCM model and learning methodologies. Also, this survey provides some ideas for future research to enhance the capabilities of FCM in order to cover some challenges in the real-world experiments such as handling non-stationary data and scalability issues. Moreover, equipping FCMs with fast learning algorithms is one of the major concerns in this area.