 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cyber Mobility Mirror: Deep Learning-based Real-time 3D Object Perception and Reconstruction Using Roadside LiDAR
Feb 28, 2022
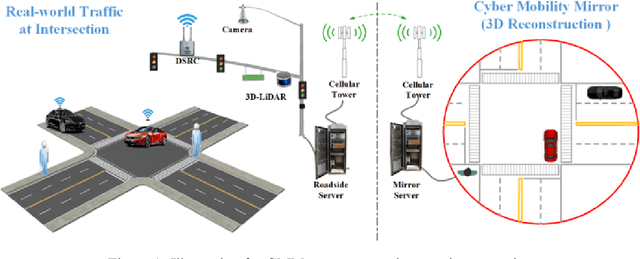
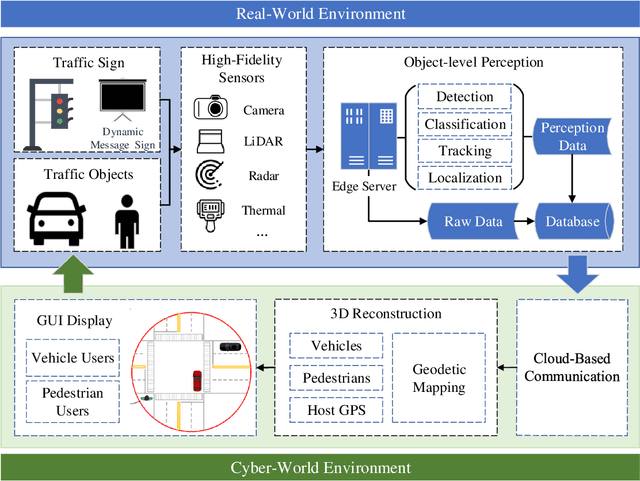
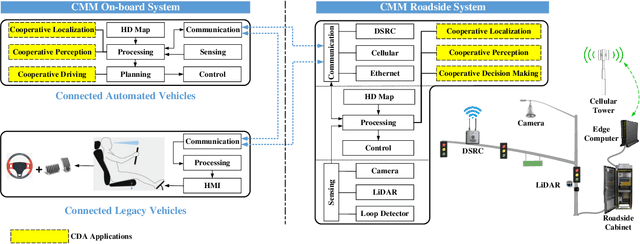
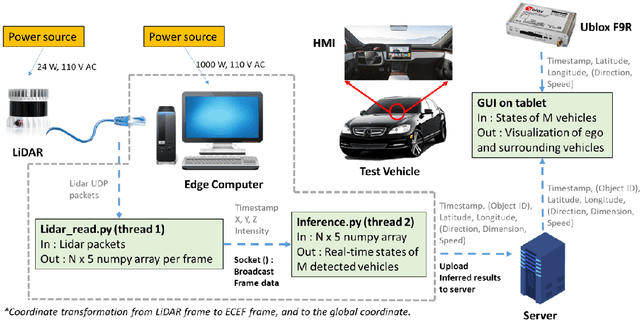
Enabling Cooperative Driving Automation (CDA) requires high-fidelity and real-time perception information, which is available from onboard sensors or vehicle-to-everything (V2X) communications. Nevertheless, the accessibility of this information may suffer from the range and occlusion of perception or limited penetration rates in connectivity. In this paper, we introduce the prototype of Cyber Mobility Mirror (CMM), a next-generation real-time traffic surveillance system for 3D object detection, classification, tracking, and reconstruction, to provide CAVs with wide-range high-fidelity perception information in a mixed traffic environment. The CMM system consists of six main components: 1) the data pre-processor to retrieve and pre-process raw data from the roadside LiDAR; 2) the 3D object detector to generate 3D bounding boxes based on point cloud data; 3) the multi-objects tracker to endow unique IDs to detected objects and estimate their dynamic states; 4) the global locator to map positioning information from the LiDAR coordinate to geographic coordinate using coordinate transformation; 5) the cloud-based communicator to transmit perception information from roadside sensors to equipped vehicles; and 6) the onboard advisor to reconstruct and display the real-time traffic conditions via Graphical User Interface (GUI). In this study, a field-operational prototype system is deployed at a real-world intersection, University Avenue and Iowa Avenue in Riverside, California to assess the feasibility and performance of our CMM system. Results from field tests demonstrate that our CMM prototype system can provide satisfactory perception performance with 96.99% precision and 83.62% recall. High-fidelity real-time traffic conditions (at the object level) can be displayed on the GUI of the equipped vehicle with a frequency of 3-4 Hz.
VulCurator: A Vulnerability-Fixing Commit Detector
Sep 07, 2022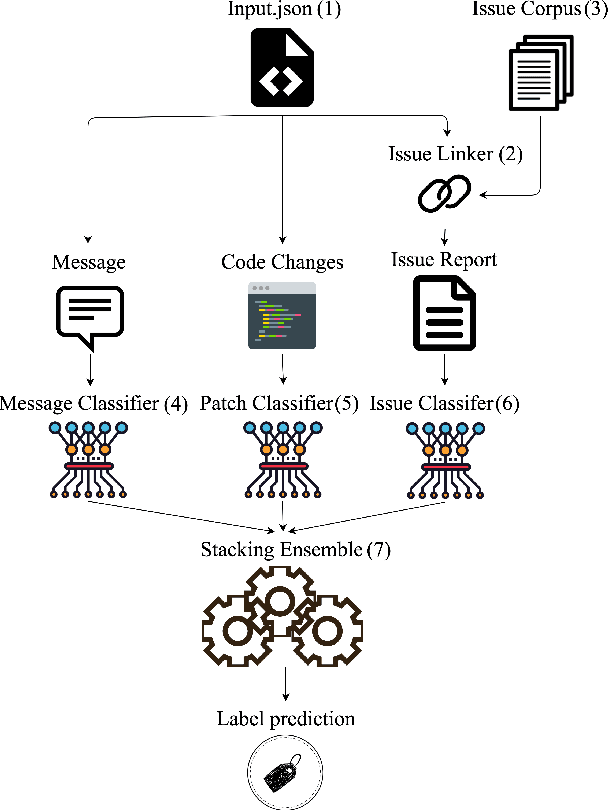

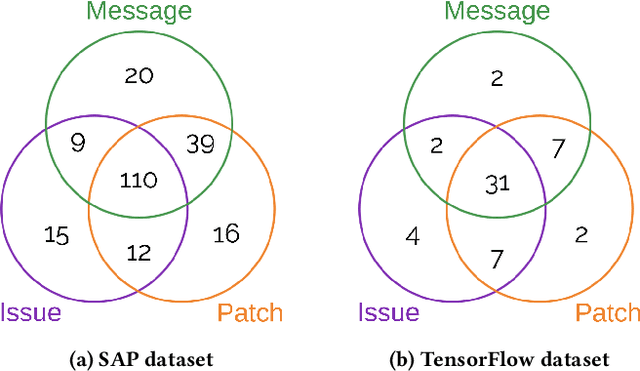

Open-source software (OSS) vulnerability management process is important nowadays, as the number of discovered OSS vulnerabilities is increasing over time. Monitoring vulnerability-fixing commits is a part of the standard process to prevent vulnerability exploitation. Manually detecting vulnerability-fixing commits is, however, time consuming due to the possibly large number of commits to review. Recently, many techniques have been proposed to automatically detect vulnerability-fixing commits using machine learning. These solutions either: (1) did not use deep learning, or (2) use deep learning on only limited sources of information. This paper proposes VulCurator, a tool that leverages deep learning on richer sources of information, including commit messages, code changes and issue reports for vulnerability-fixing commit classifica- tion. Our experimental results show that VulCurator outperforms the state-of-the-art baselines up to 16.1% in terms of F1-score. VulCurator tool is publicly available at https://github.com/ntgiang71096/VFDetector and https://zenodo.org/record/7034132#.Yw3MN-xBzDI, with a demo video at https://youtu.be/uMlFmWSJYOE.
TOSE: A Fast Capacity Estimation Algorithm Based on Spike Approximations
Sep 02, 2022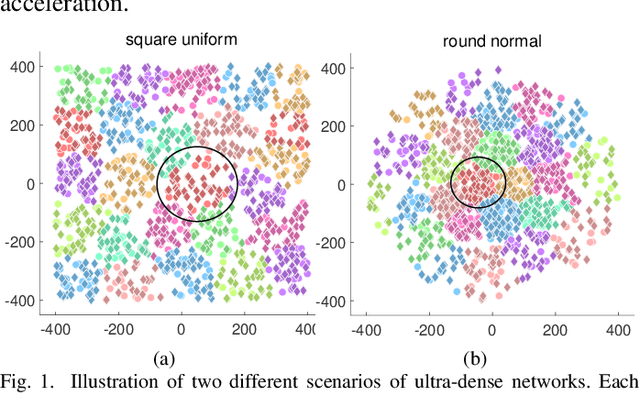
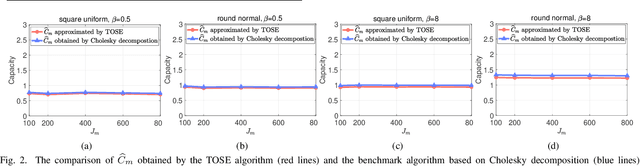
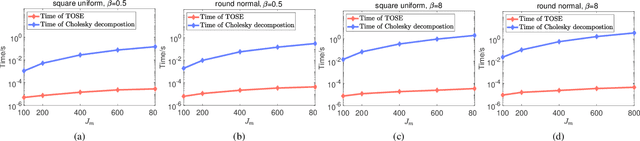
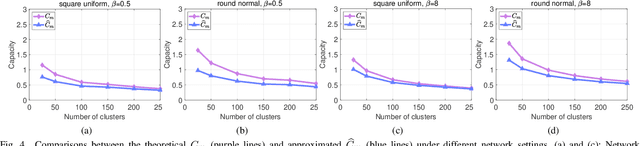
Capacity is one of the most important performance metrics for wireless communication networks. It describes the maximum rate at which the information can be transmitted of a wireless communication system. To support the growing demand for wireless traffic, wireless networks are becoming more dense and complicated, leading to a higher difficulty to derive the capacity. Unfortunately, most existing methods for the capacity calculation take a polynomial time complexity. This will become unaffordable for future ultra-dense networks, where both the number of base stations (BSs) and the number of users are extremely large. In this paper, we propose a fast algorithm TOSE to estimate the capacity for ultra-dense wireless networks. Based on the spiked model of random matrix theory (RMT), our algorithm can avoid the exact eigenvalue derivations of large dimensional matrices, which are complicated and inevitable in conventional capacity calculation methods. Instead, fast eigenvalue estimations can be realized based on the spike approximations in our TOSE algorithm. Our simulation results show that TOSE is an accurate and fast capacity approximation algorithm. Its estimation error is below 5%, and it runs in linear time, which is much lower than the polynomial time complexity of existing methods. In addition, TOSE has superior generality, since it is independent of the distributions of BSs and users, and the shape of network areas.
* 6 pages, 4 figures. arXiv admin note: text overlap with arXiv:2204.03393
Prototypical VoteNet for Few-Shot 3D Point Cloud Object Detection
Oct 11, 2022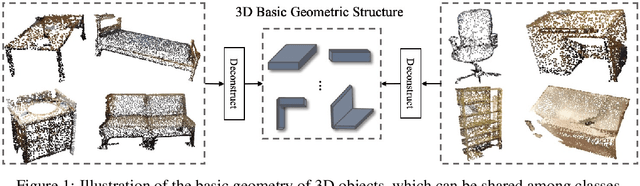
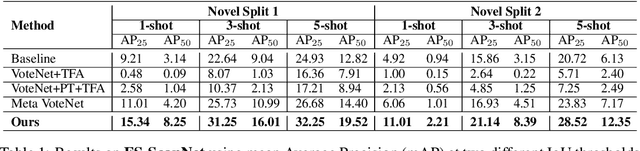
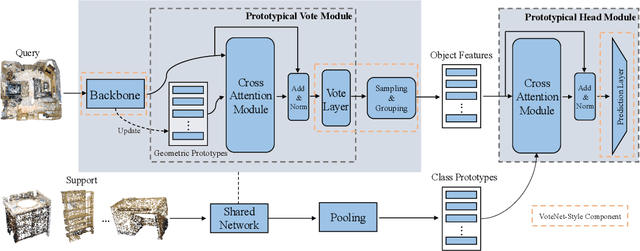
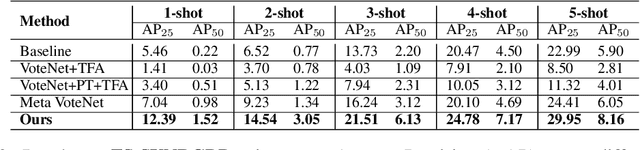
Most existing 3D point cloud object detection approaches heavily rely on large amounts of labeled training data. However, the labeling process is costly and time-consuming. This paper considers few-shot 3D point cloud object detection, where only a few annotated samples of novel classes are needed with abundant samples of base classes. To this end, we propose Prototypical VoteNet to recognize and localize novel instances, which incorporates two new modules: Prototypical Vote Module (PVM) and Prototypical Head Module (PHM). Specifically, as the 3D basic geometric structures can be shared among categories, PVM is designed to leverage class-agnostic geometric prototypes, which are learned from base classes, to refine local features of novel categories.Then PHM is proposed to utilize class prototypes to enhance the global feature of each object, facilitating subsequent object localization and classification, which is trained by the episodic training strategy. To evaluate the model in this new setting, we contribute two new benchmark datasets, FS-ScanNet and FS-SUNRGBD. We conduct extensive experiments to demonstrate the effectiveness of Prototypical VoteNet, and our proposed method shows significant and consistent improvements compared to baselines on two benchmark datasets.
Disentangling Causal Effects from Sets of Interventions in the Presence of Unobserved Confounders
Oct 11, 2022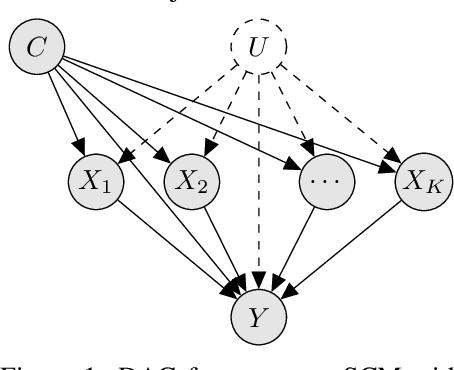
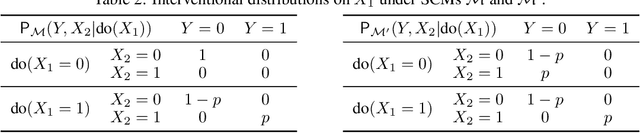
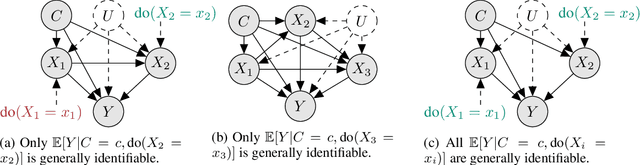
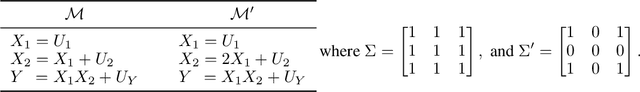
The ability to answer causal questions is crucial in many domains, as causal inference allows one to understand the impact of interventions. In many applications, only a single intervention is possible at a given time. However, in some important areas, multiple interventions are concurrently applied. Disentangling the effects of single interventions from jointly applied interventions is a challenging task -- especially as simultaneously applied interventions can interact. This problem is made harder still by unobserved confounders, which influence both treatments and outcome. We address this challenge by aiming to learn the effect of a single-intervention from both observational data and sets of interventions. We prove that this is not generally possible, but provide identification proofs demonstrating that it can be achieved under non-linear continuous structural causal models with additive, multivariate Gaussian noise -- even when unobserved confounders are present. Importantly, we show how to incorporate observed covariates and learn heterogeneous treatment effects. Based on the identifiability proofs, we provide an algorithm that learns the causal model parameters by pooling data from different regimes and jointly maximizing the combined likelihood. The effectiveness of our method is empirically demonstrated on both synthetic and real-world data.
Transformers generalize differently from information stored in context vs in weights
Oct 11, 2022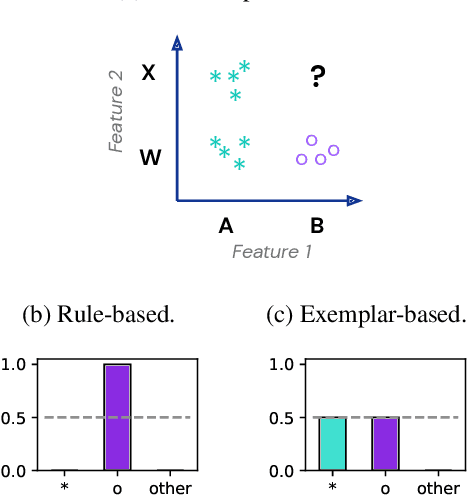
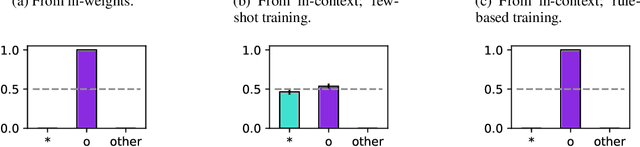
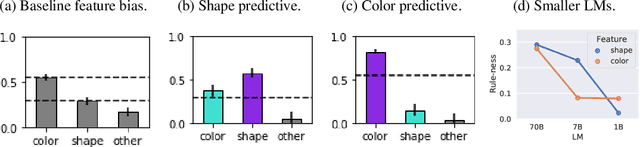
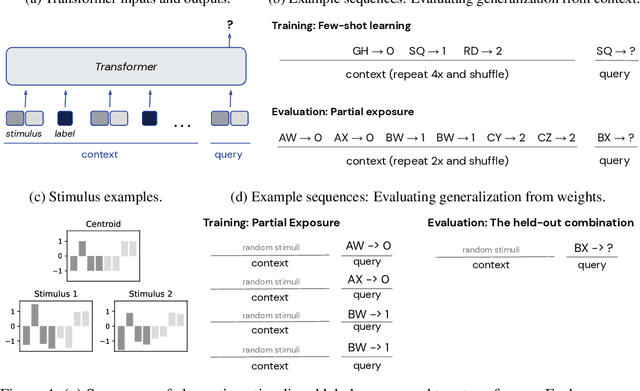
Transformer models can use two fundamentally different kinds of information: information stored in weights during training, and information provided ``in-context'' at inference time. In this work, we show that transformers exhibit different inductive biases in how they represent and generalize from the information in these two sources. In particular, we characterize whether they generalize via parsimonious rules (rule-based generalization) or via direct comparison with observed examples (exemplar-based generalization). This is of important practical consequence, as it informs whether to encode information in weights or in context, depending on how we want models to use that information. In transformers trained on controlled stimuli, we find that generalization from weights is more rule-based whereas generalization from context is largely exemplar-based. In contrast, we find that in transformers pre-trained on natural language, in-context learning is significantly rule-based, with larger models showing more rule-basedness. We hypothesise that rule-based generalization from in-context information might be an emergent consequence of large-scale training on language, which has sparse rule-like structure. Using controlled stimuli, we verify that transformers pretrained on data containing sparse rule-like structure exhibit more rule-based generalization.
MFCCA:Multi-Frame Cross-Channel attention for multi-speaker ASR in Multi-party meeting scenario
Oct 11, 2022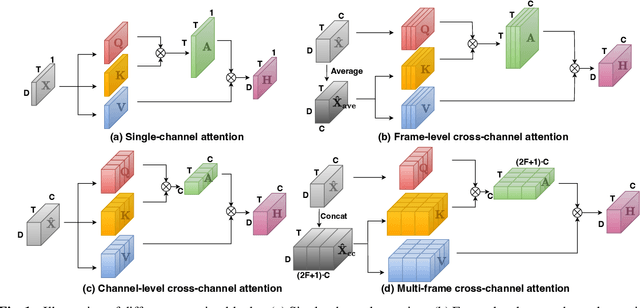
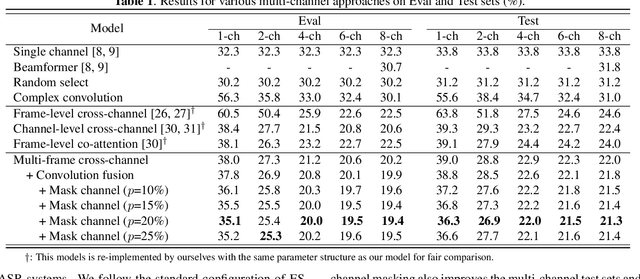
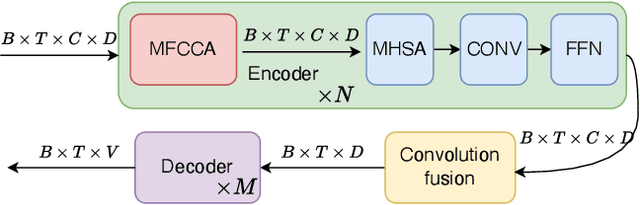
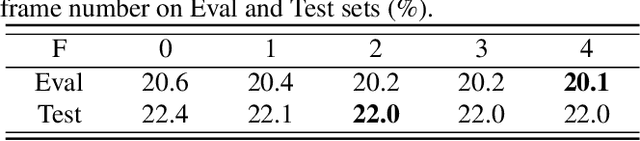
Recently cross-channel attention, which better leverages multi-channel signals from microphone array, has shown promising results in the multi-party meeting scenario. Cross-channel attention focuses on either learning global correlations between sequences of different channels or exploiting fine-grained channel-wise information effectively at each time step. Considering the delay of microphone array receiving sound, we propose a multi-frame cross-channel attention, which models cross-channel information between adjacent frames to exploit the complementarity of both frame-wise and channel-wise knowledge. Besides, we also propose a multi-layer convolutional mechanism to fuse the multi-channel output and a channel masking strategy to combat the channel number mismatch problem between training and inference. Experiments on the AliMeeting, a real-world corpus, reveal that our proposed model outperforms single-channel model by 31.7\% and 37.0\% CER reduction on Eval and Test sets. Moreover, with comparable model parameters and training data, our proposed model achieves a new SOTA performance on the AliMeeting corpus, as compared with the top ranking systems in the ICASSP2022 M2MeT challenge, a recently held multi-channel multi-speaker ASR challenge.
Client Error Clustering Approaches in Content Delivery Networks (CDN)
Oct 11, 2022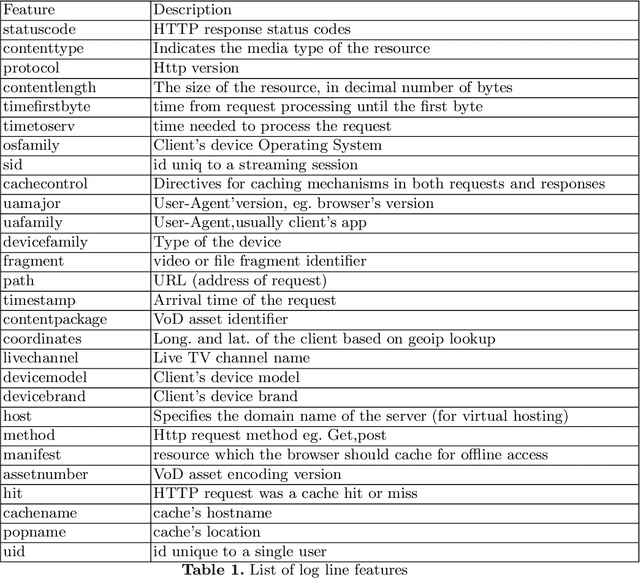
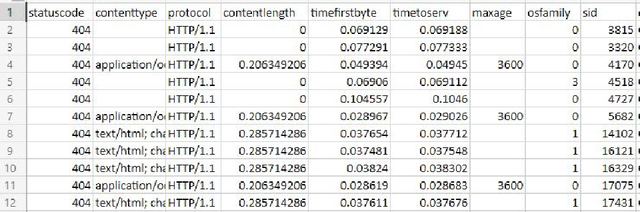

Content delivery networks (CDNs) are the backbone of the Internet and are key in delivering high quality video on demand (VoD), web content and file services to billions of users. CDNs usually consist of hierarchically organized content servers positioned as close to the customers as possible. CDN operators face a significant challenge when analyzing billions of web server and proxy logs generated by their systems. The main objective of this study was to analyze the applicability of various clustering methods in CDN error log analysis. We worked with real-life CDN proxy logs, identified key features included in the logs (e.g., content type, HTTP status code, time-of-day, host) and clustered the log lines corresponding to different host types offering live TV, video on demand, file caching and web content. Our experiments were run on a dataset consisting of proxy logs collected over a 7-day period from a single, physical CDN server running multiple types of services (VoD, live TV, file). The dataset consisted of 2.2 billion log lines. Our analysis showed that CDN error clustering is a viable approach towards identifying recurring errors and improving overall quality of service.
Geometry of Radial Basis Neural Networks for Safety Biased Approximation of Unsafe Regions
Oct 11, 2022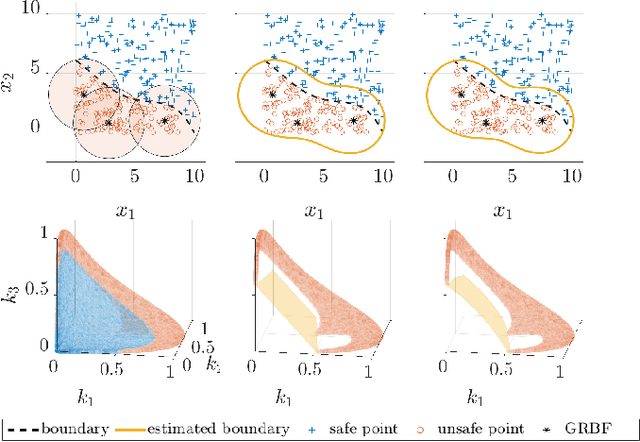
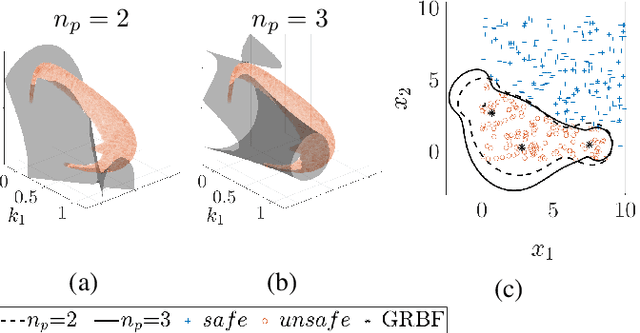
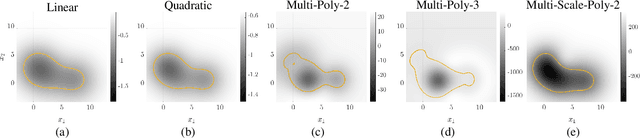

Barrier function-based inequality constraints are a means to enforce safety specifications for control systems. When used in conjunction with a convex optimization program, they provide a computationally efficient method to enforce safety for the general class of control-affine systems. One of the main assumptions when taking this approach is the a priori knowledge of the barrier function itself, i.e., knowledge of the safe set. In the context of navigation through unknown environments where the locally safe set evolves with time, such knowledge does not exist. This manuscript focuses on the synthesis of a zeroing barrier function characterizing the safe set based on safe and unsafe sample measurements, e.g., from perception data in navigation applications. Prior work formulated a supervised machine learning algorithm whose solution guaranteed the construction of a zeroing barrier function with specific level-set properties. However, it did not explore the geometry of the neural network design used for the synthesis process. This manuscript describes the specific geometry of the neural network used for zeroing barrier function synthesis, and shows how the network provides the necessary representation for splitting the state space into safe and unsafe regions.
Human-AI Coordination via Human-Regularized Search and Learning
Oct 11, 2022
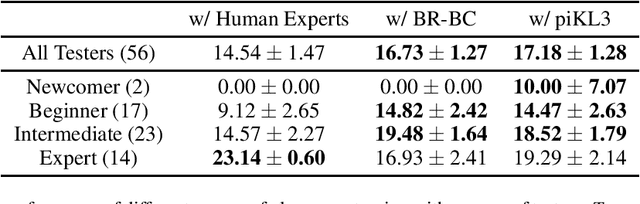
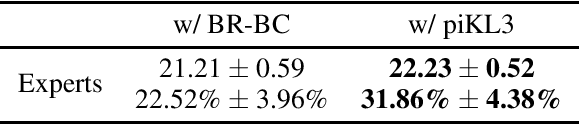
We consider the problem of making AI agents that collaborate well with humans in partially observable fully cooperative environments given datasets of human behavior. Inspired by piKL, a human-data-regularized search method that improves upon a behavioral cloning policy without diverging far away from it, we develop a three-step algorithm that achieve strong performance in coordinating with real humans in the Hanabi benchmark. We first use a regularized search algorithm and behavioral cloning to produce a better human model that captures diverse skill levels. Then, we integrate the policy regularization idea into reinforcement learning to train a human-like best response to the human model. Finally, we apply regularized search on top of the best response policy at test time to handle out-of-distribution challenges when playing with humans. We evaluate our method in two large scale experiments with humans. First, we show that our method outperforms experts when playing with a group of diverse human players in ad-hoc teams. Second, we show that our method beats a vanilla best response to behavioral cloning baseline by having experts play repeatedly with the two agents.