 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GoonDAE: Denoising-Based Driver Assistance for Off-Road Teleoperation
Sep 08, 2022
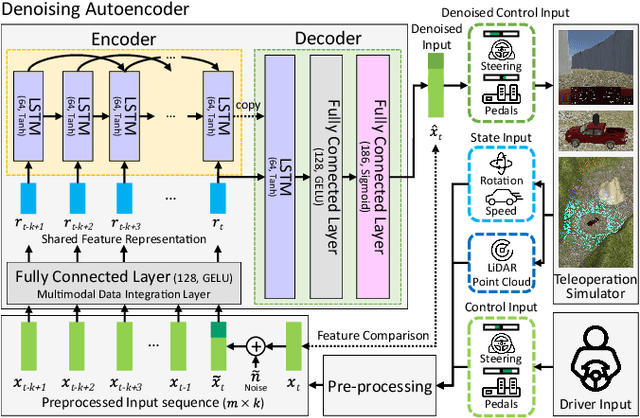
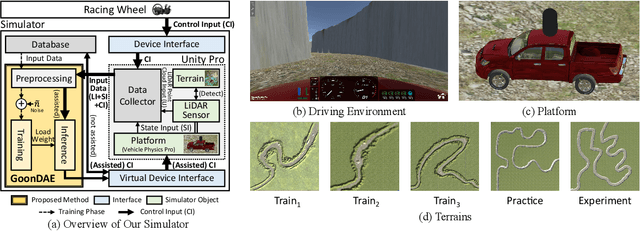
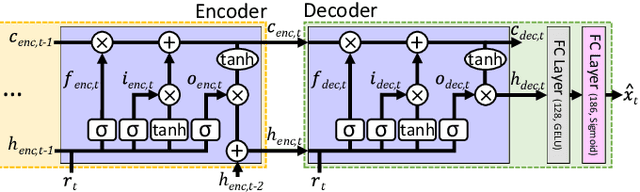
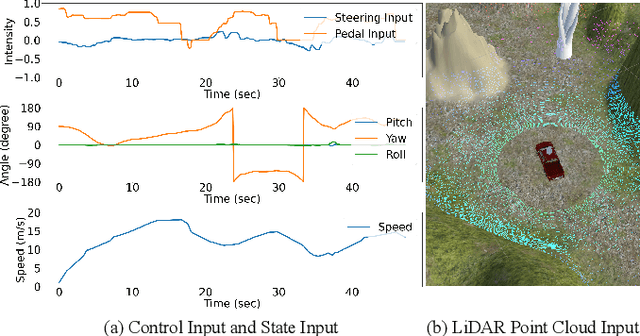
Because of the limitations of autonomous driving technologies, teleoperation is widely used in dangerous environments such as military operations. However, the teleoperated driving performance depends considerably on the driver's skill level. Moreover, unskilled drivers need extensive training time for teleoperations in unusual and harsh environments. To address this problem, we propose a novel denoising-based driver assistance method, namely GoonDAE, for real-time teleoperated off-road driving. The unskilled driver control input is assumed to be the same as the skilled driver control input but with noise. We designed a skip-connected long short-term memory (LSTM)-based denoising autoencoder (DAE) model to assist the unskilled driver control input by denoising. The proposed GoonDAE was trained with skilled driver control input and sensor data collected from our simulated off-road driving environment. To evaluate GoonDAE, we conducted an experiment with unskilled drivers in the simulated environment. The results revealed that the proposed system considerably enhanced driving performance in terms of driving stability.
P2M-DeTrack: Processing-in-Pixel-in-Memory for Energy-efficient and Real-Time Multi-Object Detection and Tracking
May 28, 2022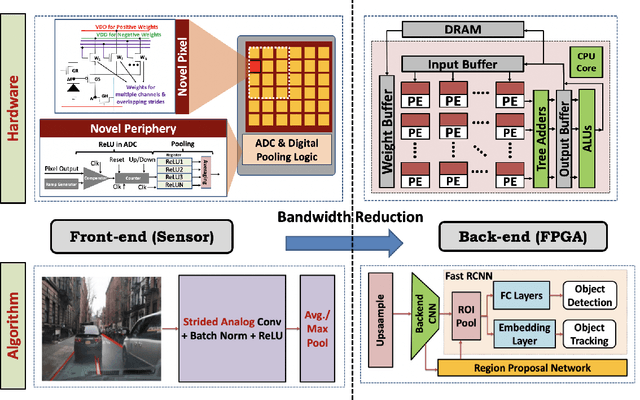
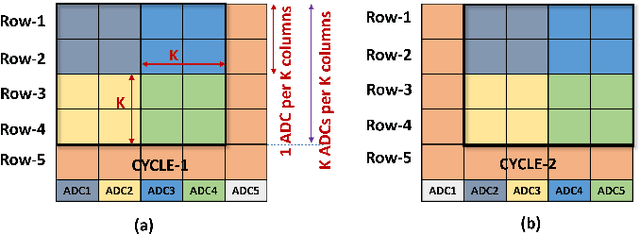
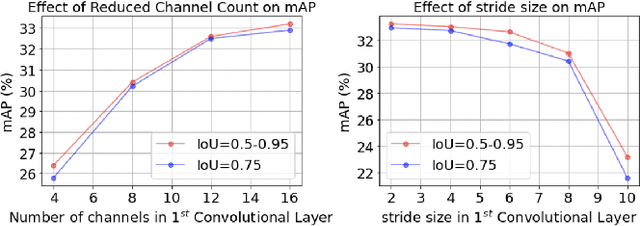
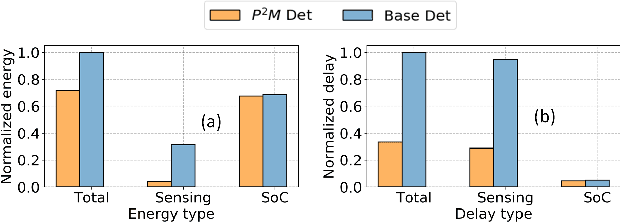
Today's high resolution, high frame rate cameras in autonomous vehicles generate a large volume of data that needs to be transferred and processed by a downstream processor or machine learning (ML) accelerator to enable intelligent computing tasks, such as multi-object detection and tracking. The massive amount of data transfer incurs significant energy, latency, and bandwidth bottlenecks, which hinders real-time processing. To mitigate this problem, we propose an algorithm-hardware co-design framework called Processing-in-Pixel-in-Memory-based object Detection and Tracking (P2M-DeTrack). P2M-DeTrack is based on a custom faster R-CNN-based model that is distributed partly inside the pixel array (front-end) and partly in a separate FPGA/ASIC (back-end). The proposed front-end in-pixel processing down-samples the input feature maps significantly with judiciously optimized strided convolution and pooling. Compared to a conventional baseline design that transfers frames of RGB pixels to the back-end, the resulting P2M-DeTrack designs reduce the data bandwidth between sensor and back-end by up to 24x. The designs also reduce the sensor and total energy (obtained from in-house circuit simulations at Globalfoundries 22nm technology node) per frame by 5.7x and 1.14x, respectively. Lastly, they reduce the sensing and total frame latency by an estimated 1.7x and 3x, respectively. We evaluate our approach on the multi-object object detection (tracking) task of the large-scale BDD100K dataset and observe only a 0.5% reduction in the mean average precision (0.8% reduction in the identification F1 score) compared to the state-of-the-art.
Students taught by multimodal teachers are superior action recognizers
Oct 09, 2022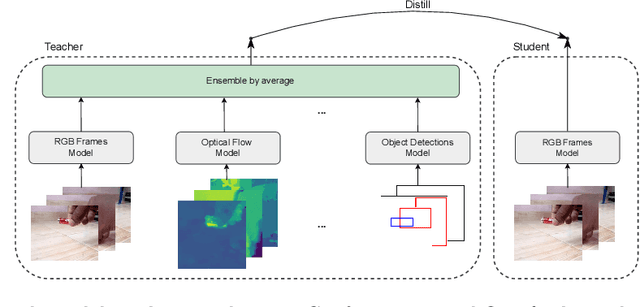

The focal point of egocentric video understanding is modelling hand-object interactions. Standard models -- CNNs, Vision Transformers, etc. -- which receive RGB frames as input perform well, however, their performance improves further by employing additional modalities such as object detections, optical flow, audio, etc. as input. The added complexity of the required modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such multimodal approaches, while using only the RGB images as input at inference time. Our approach is based on multimodal knowledge distillation, featuring a multimodal teacher (in the current experiments trained only using object detections, optical flow and RGB frames) and a unimodal student (using only RGB frames as input). We present preliminary results which demonstrate that the resulting model -- distilled from a multimodal teacher -- significantly outperforms the baseline RGB model (trained without knowledge distillation), as well as an omnivorous version of itself (trained on all modalities jointly), in both standard and compositional action recognition.
Randomized Signature Layers for Signal Extraction in Time Series Data
Jan 02, 2022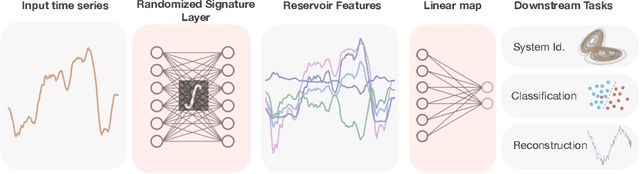

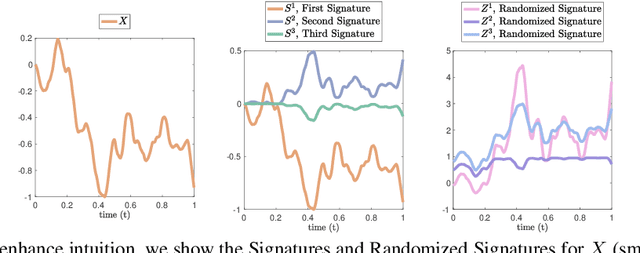
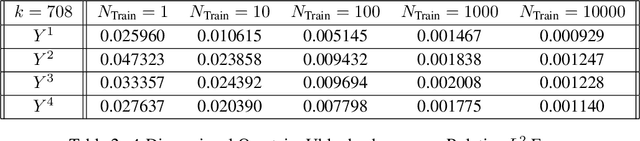
Time series analysis is a widespread task in Natural Sciences, Social Sciences, and Engineering. A fundamental problem is finding an expressive yet efficient-to-compute representation of the input time series to use as a starting point to perform arbitrary downstream tasks. In this paper, we build upon recent works that use the Signature of a path as a feature map and investigate a computationally efficient technique to approximate these features based on linear random projections. We present several theoretical results to justify our approach and empirically validate that our random projections can effectively retrieve the underlying Signature of a path. We show the surprising performance of the proposed random features on several tasks, including (1) mapping the controls of stochastic differential equations to the corresponding solutions and (2) using the Randomized Signatures as time series representation for classification tasks. When compared to corresponding truncated Signature approaches, our Randomizes Signatures are more computationally efficient in high dimensions and often lead to better accuracy and faster training. Besides providing a new tool to extract Signatures and further validating the high level of expressiveness of such features, we believe our results provide interesting conceptual links between several existing research areas, suggesting new intriguing directions for future investigations.
InferES : A Natural Language Inference Corpus for Spanish Featuring Negation-Based Contrastive and Adversarial Examples
Oct 06, 2022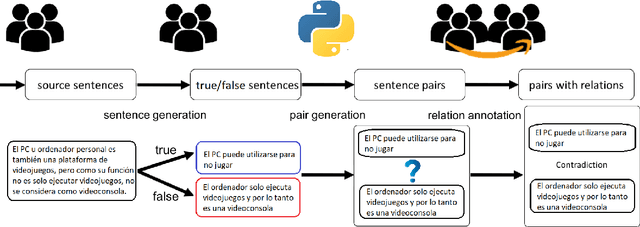
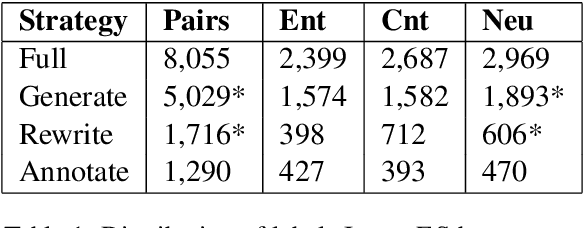
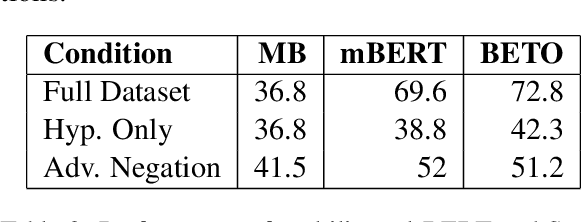
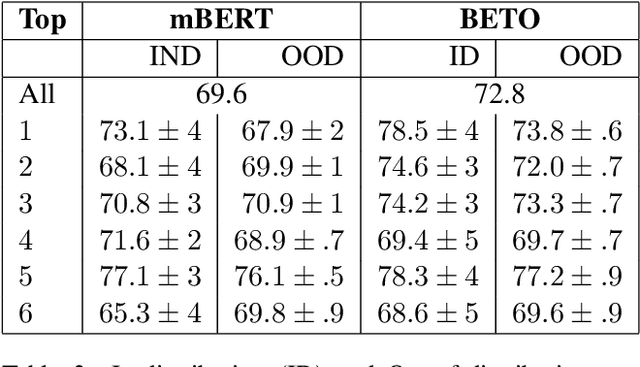
In this paper, we present InferES - an original corpus for Natural Language Inference (NLI) in European Spanish. We propose, implement, and analyze a variety of corpus-creating strategies utilizing expert linguists and crowd workers. The objectives behind InferES are to provide high-quality data, and, at the same time to facilitate the systematic evaluation of automated systems. Specifically, we focus on measuring and improving the performance of machine learning systems on negation-based adversarial examples and their ability to generalize across out-of-distribution topics. We train two transformer models on InferES (8,055 gold examples) in a variety of scenarios. Our best model obtains 72.8% accuracy, leaving a lot of room for improvement. The "hypothesis-only" baseline performs only 2%-5% higher than majority, indicating much fewer annotation artifacts than prior work. We find that models trained on InferES generalize very well across topics (both in- and out-of-distribution) and perform moderately well on negation-based adversarial examples.
Deep Representations for Time-varying Brain Datasets
May 23, 2022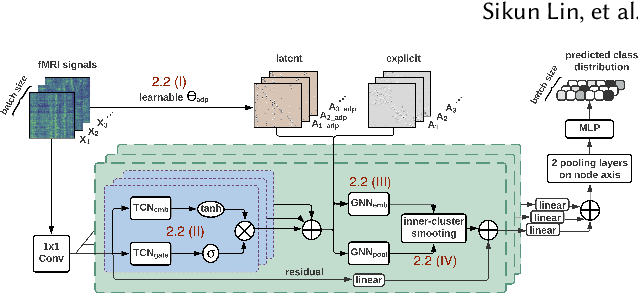

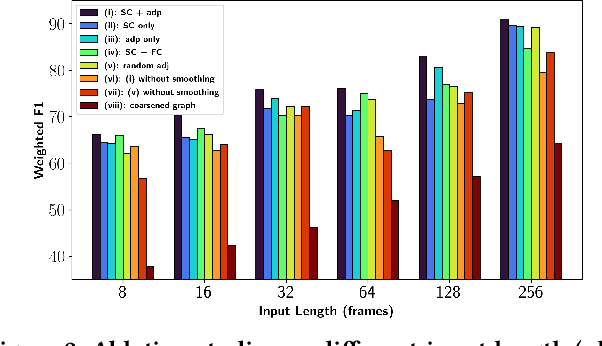
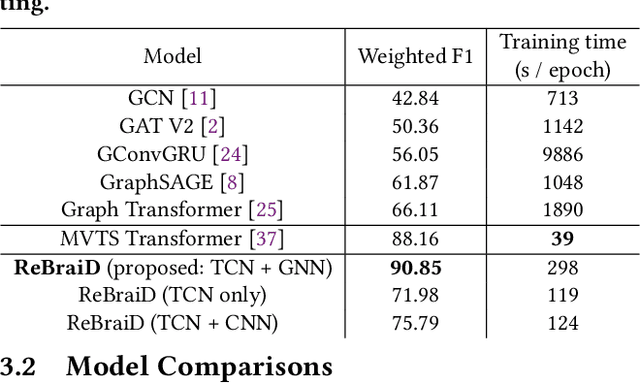
Finding an appropriate representation of dynamic activities in the brain is crucial for many downstream applications. Due to its highly dynamic nature, temporally averaged fMRI (functional magnetic resonance imaging) can only provide a narrow view of underlying brain activities. Previous works lack the ability to learn and interpret the latent dynamics in brain architectures. This paper builds an efficient graph neural network model that incorporates both region-mapped fMRI sequences and structural connectivities obtained from DWI (diffusion-weighted imaging) as inputs. We find good representations of the latent brain dynamics through learning sample-level adaptive adjacency matrices and performing a novel multi-resolution inner cluster smoothing. These modules can be easily adapted to and are potentially useful for other applications outside the neuroscience domain. We also attribute inputs with integrated gradients, which enables us to infer (1) highly involved brain connections and subnetworks for each task, (2) temporal keyframes of imaging sequences that characterize tasks, and (3) subnetworks that discriminate between individual subjects. This ability to identify critical subnetworks that characterize signal states across heterogeneous tasks and individuals is of great importance to neuroscience and other scientific domains. Extensive experiments and ablation studies demonstrate our proposed method's superiority and efficiency in spatial-temporal graph signal modeling with insightful interpretations of brain dynamics.
KENN: Enhancing Deep Neural Networks by Leveraging Knowledge for Time Series Forecasting
Feb 16, 2022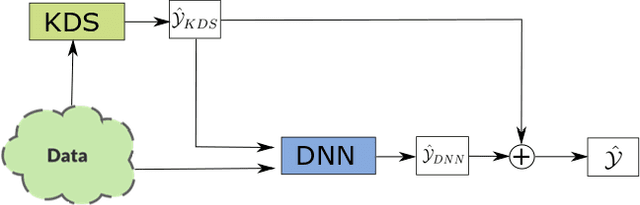
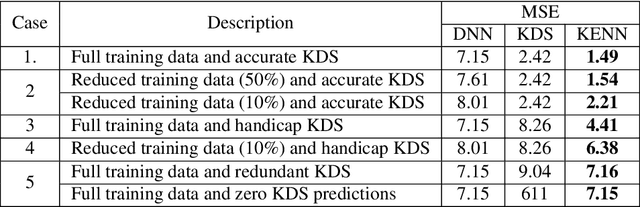
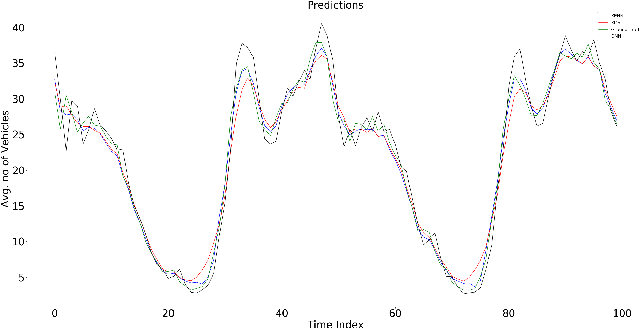
End-to-end data-driven machine learning methods often have exuberant requirements in terms of quality and quantity of training data which are often impractical to fulfill in real-world applications. This is specifically true in time series domain where problems like disaster prediction, anomaly detection, and demand prediction often do not have a large amount of historical data. Moreover, relying purely on past examples for training can be sub-optimal since in doing so we ignore one very important domain i.e knowledge, which has its own distinct advantages. In this paper, we propose a novel knowledge fusion architecture, Knowledge Enhanced Neural Network (KENN), for time series forecasting that specifically aims towards combining strengths of both knowledge and data domains while mitigating their individual weaknesses. We show that KENN not only reduces data dependency of the overall framework but also improves performance by producing predictions that are better than the ones produced by purely knowledge and data driven domains. We also compare KENN with state-of-the-art forecasting methods and show that predictions produced by KENN are significantly better even when trained on only 50\% of the data.
A Hybrid Partitioning Strategy for Backward Reachability of Neural Feedback Loops
Oct 14, 2022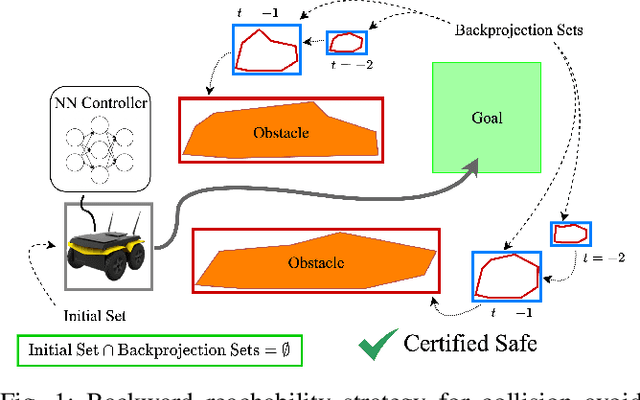
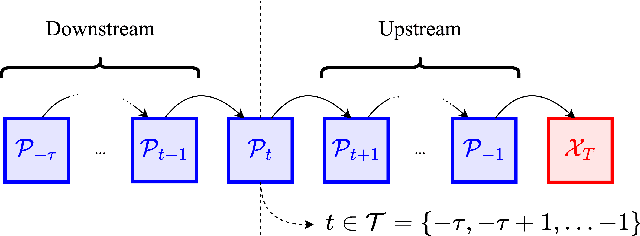
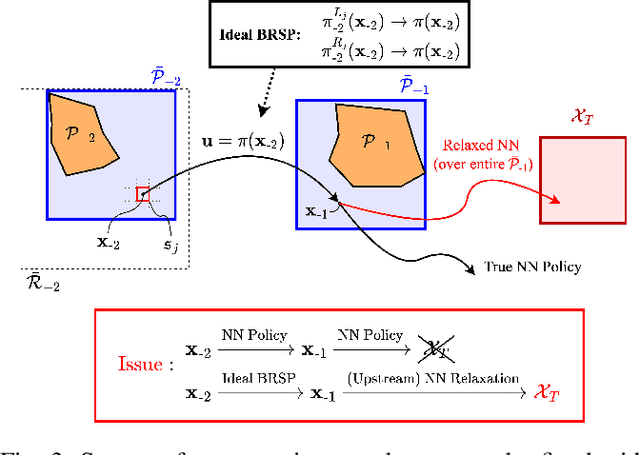
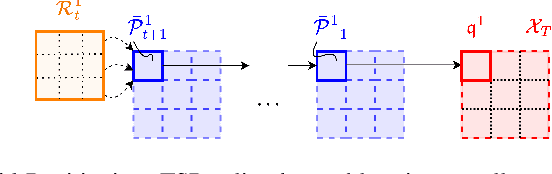
As neural networks become more integrated into the systems that we depend on for transportation, medicine, and security, it becomes increasingly important that we develop methods to analyze their behavior to ensure that they are safe to use within these contexts. The methods used in this paper seek to certify safety for closed-loop systems with neural network controllers, i.e., neural feedback loops, using backward reachability analysis. Namely, we calculate backprojection (BP) set over-approximations (BPOAs), i.e., sets of states that lead to a given target set that bounds dangerous regions of the state space. The system's safety can then be certified by checking its current state against the BPOAs. While over-approximating BPs is significantly faster than calculating exact BP sets, solving the relaxed problem leads to conservativeness. To combat conservativeness, partitioning strategies can be used to split the problem into a set of sub-problems, each less conservative than the unpartitioned problem. We introduce a hybrid partitioning method that uses both target set partitioning (TSP) and backreachable set partitioning (BRSP) to overcome a lower bound on estimation error that is present when using BRSP. Numerical results demonstrate a near order-of-magnitude reduction in estimation error compared to BRSP or TSP given the same computation time.
Distributional Reward Estimation for Effective Multi-Agent Deep Reinforcement Learning
Oct 14, 2022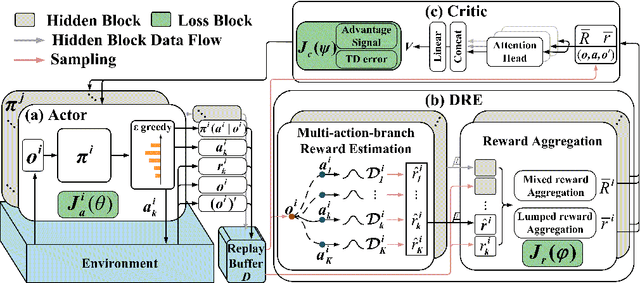
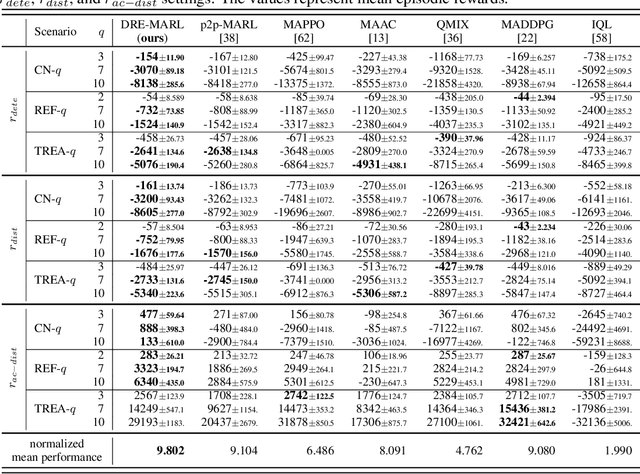
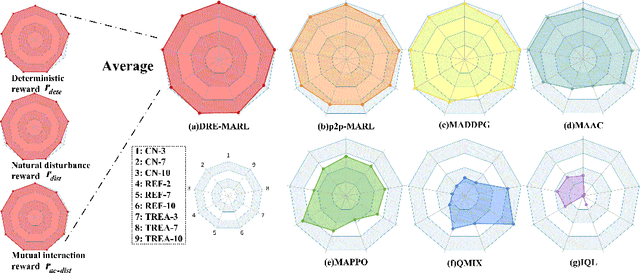
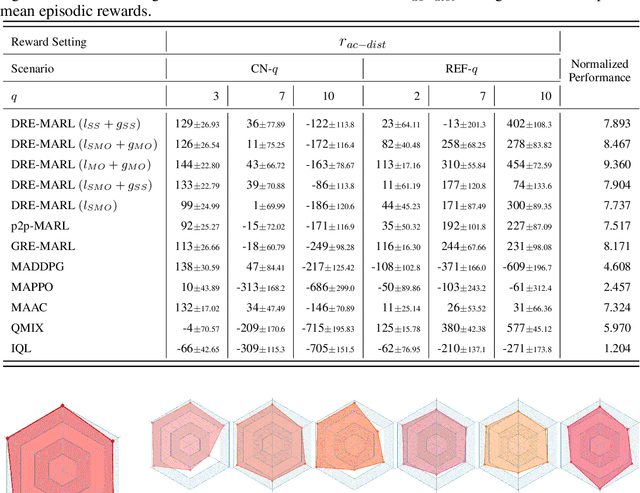
Multi-agent reinforcement learning has drawn increasing attention in practice, e.g., robotics and automatic driving, as it can explore optimal policies using samples generated by interacting with the environment. However, high reward uncertainty still remains a problem when we want to train a satisfactory model, because obtaining high-quality reward feedback is usually expensive and even infeasible. To handle this issue, previous methods mainly focus on passive reward correction. At the same time, recent active reward estimation methods have proven to be a recipe for reducing the effect of reward uncertainty. In this paper, we propose a novel Distributional Reward Estimation framework for effective Multi-Agent Reinforcement Learning (DRE-MARL). Our main idea is to design the multi-action-branch reward estimation and policy-weighted reward aggregation for stabilized training. Specifically, we design the multi-action-branch reward estimation to model reward distributions on all action branches. Then we utilize reward aggregation to obtain stable updating signals during training. Our intuition is that consideration of all possible consequences of actions could be useful for learning policies. The superiority of the DRE-MARL is demonstrated using benchmark multi-agent scenarios, compared with the SOTA baselines in terms of both effectiveness and robustness.
Generative Adversarial Learning for Trusted and Secure Clustering in Industrial Wireless Sensor Networks
Oct 14, 2022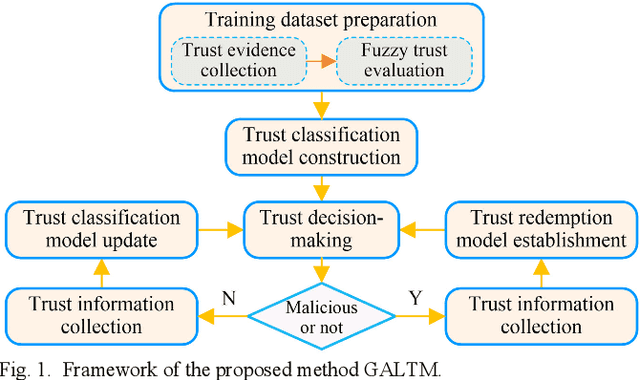
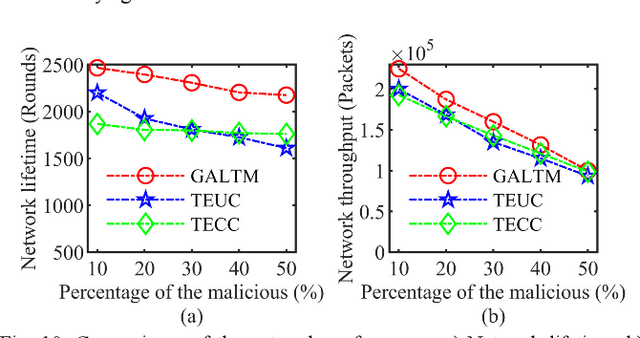
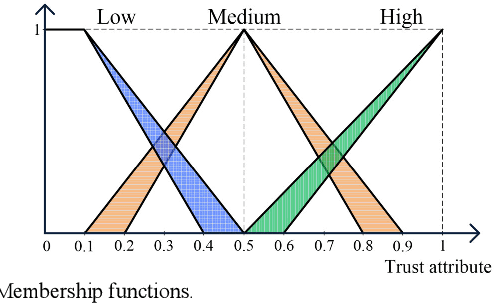
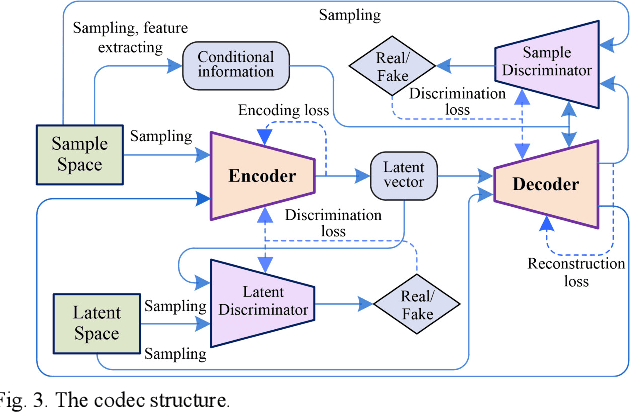
Traditional machine learning techniques have been widely used to establish the trust management systems. However, the scale of training dataset can significantly affect the security performances of the systems, while it is a great challenge to detect malicious nodes due to the absence of labeled data regarding novel attacks. To address this issue, this paper presents a generative adversarial network (GAN) based trust management mechanism for Industrial Wireless Sensor Networks (IWSNs). First, type-2 fuzzy logic is adopted to evaluate the reputation of sensor nodes while alleviating the uncertainty problem. Then, trust vectors are collected to train a GAN-based codec structure, which is used for further malicious node detection. Moreover, to avoid normal nodes being isolated from the network permanently due to error detections, a GAN-based trust redemption model is constructed to enhance the resilience of trust management. Based on the latest detection results, a trust model update method is developed to adapt to the dynamic industrial environment. The proposed trust management mechanism is finally applied to secure clustering for reliable and real-time data transmission, and simulation results show that it achieves a high detection rate up to 96%, as well as a low false positive rate below 8%.