 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RASR: Risk-Averse Soft-Robust MDPs with EVaR and Entropic Risk
Sep 09, 2022
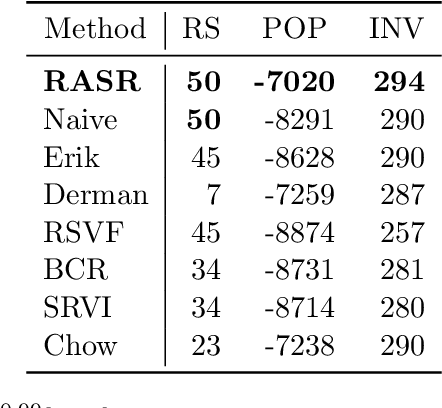

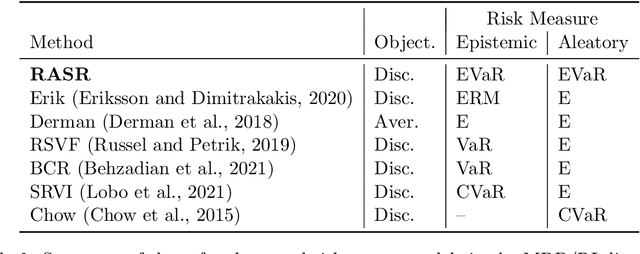
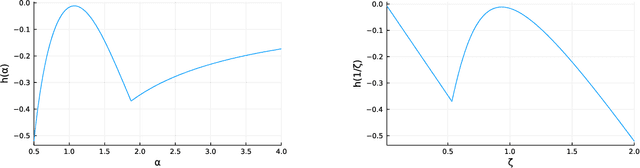
Prior work on safe Reinforcement Learning (RL) has studied risk-aversion to randomness in dynamics (aleatory) and to model uncertainty (epistemic) in isolation. We propose and analyze a new framework to jointly model the risk associated with epistemic and aleatory uncertainties in finite-horizon and discounted infinite-horizon MDPs. We call this framework that combines Risk-Averse and Soft-Robust methods RASR. We show that when the risk-aversion is defined using either EVaR or the entropic risk, the optimal policy in RASR can be computed efficiently using a new dynamic program formulation with a time-dependent risk level. As a result, the optimal risk-averse policies are deterministic but time-dependent, even in the infinite-horizon discounted setting. We also show that particular RASR objectives reduce to risk-averse RL with mean posterior transition probabilities. Our empirical results show that our new algorithms consistently mitigate uncertainty as measured by EVaR and other standard risk measures.
FedPC: Federated Learning for Language Generation with Personal and Context Preference Embeddings
Oct 07, 2022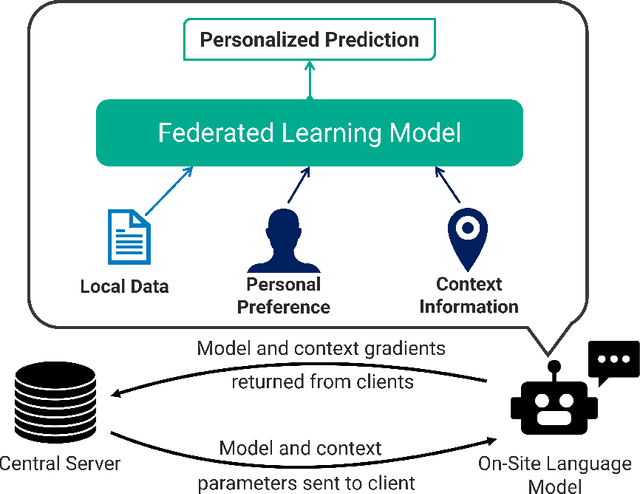
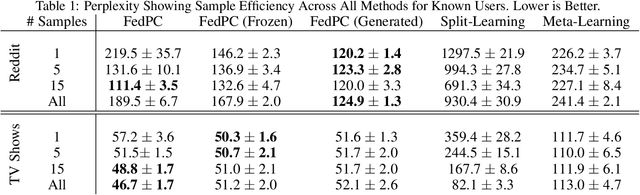
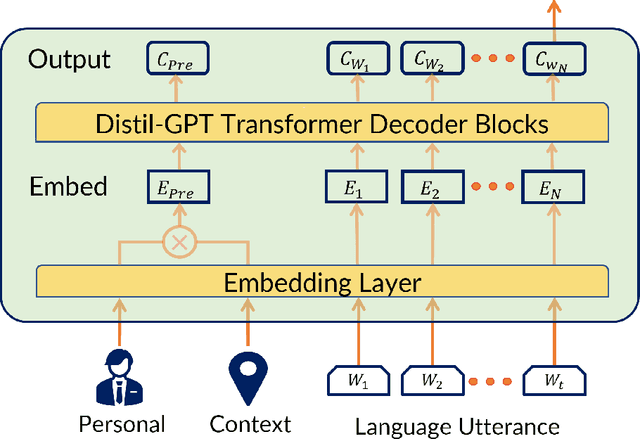
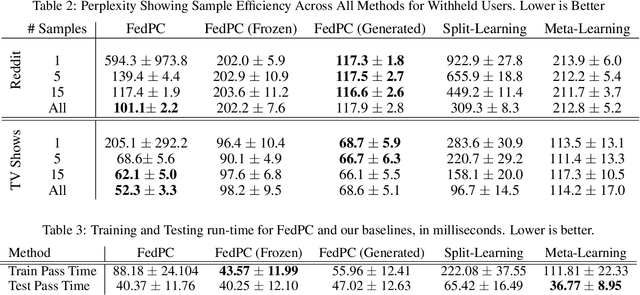
Federated learning is a training paradigm that learns from multiple distributed users without aggregating data on a centralized server. Such a paradigm promises the ability to deploy machine-learning at-scale to a diverse population of end-users without first collecting a large, labeled dataset for all possible tasks. As federated learning typically averages learning updates across a decentralized population, there is a growing need for personalization of federated learning systems (i.e conversational agents must be able to personalize to a specific user's preferences). In this work, we propose a new direction for personalization research within federated learning, leveraging both personal embeddings and shared context embeddings. We also present an approach to predict these ``preference'' embeddings, enabling personalization without backpropagation. Compared to state-of-the-art personalization baselines, our approach achieves a 50\% improvement in test-time perplexity using 0.001\% of the memory required by baseline approaches, and achieving greater sample- and compute-efficiency.
Novice Type Error Diagnosis with Natural Language Models
Oct 07, 2022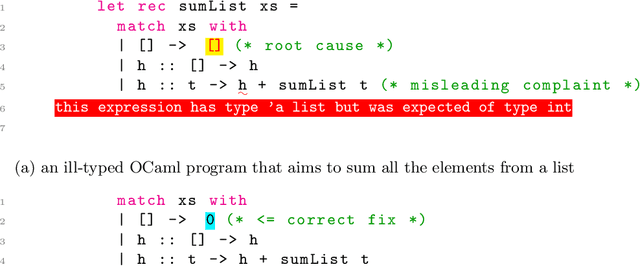
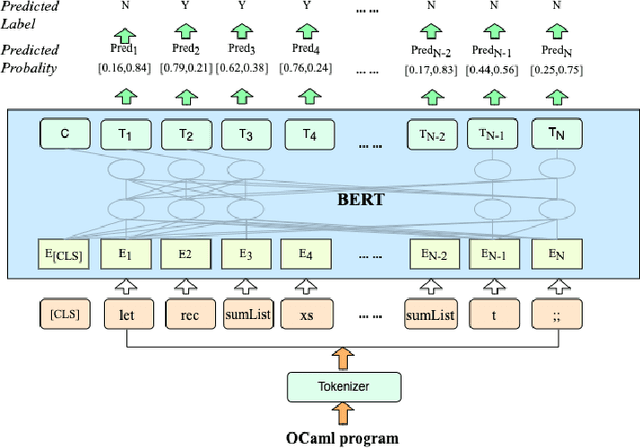
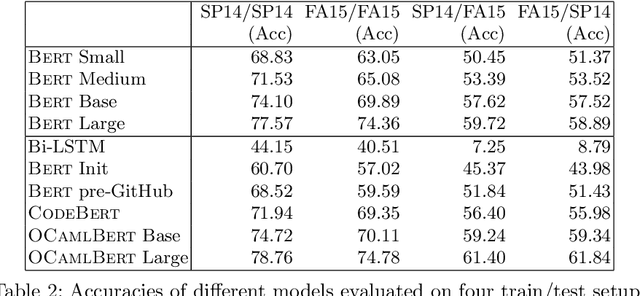
Strong static type systems help programmers eliminate many errors without much burden of supplying type annotations. However, this flexibility makes it highly non-trivial to diagnose ill-typed programs, especially for novice programmers. Compared to classic constraint solving and optimization-based approaches, the data-driven approach has shown great promise in identifying the root causes of type errors with higher accuracy. Instead of relying on hand-engineered features, this work explores natural language models for type error localization, which can be trained in an end-to-end fashion without requiring any features. We demonstrate that, for novice type error diagnosis, the language model-based approach significantly outperforms the previous state-of-the-art data-driven approach. Specifically, our model could predict type errors correctly 62% of the time, outperforming the state-of-the-art Nate's data-driven model by 11%, in a more rigorous accuracy metric. Furthermore, we also apply structural probes to explain the performance difference between different language models.
Computational imaging with the human brain
Oct 07, 2022
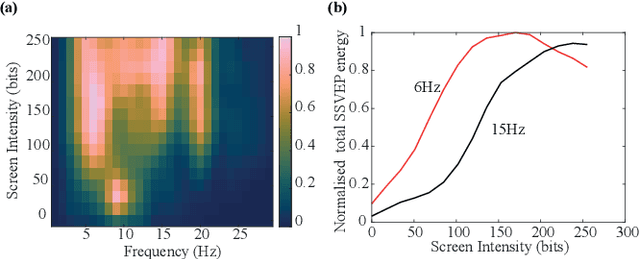


Brain-computer interfaces (BCIs) are enabling a range of new possibilities and routes for augmenting human capability. Here, we propose BCIs as a route towards forms of computation, i.e. computational imaging, that blend the brain with external silicon processing. We demonstrate ghost imaging of a hidden scene using the human visual system that is combined with an adaptive computational imaging scheme. This is achieved through a projection pattern `carving' technique that relies on real-time feedback from the brain to modify patterns at the light projector, thus enabling more efficient and higher resolution imaging. This brain-computer connectivity demonstrates a form of augmented human computation that could in the future extend the sensing range of human vision and provide new approaches to the study of the neurophysics of human perception. As an example, we illustrate a simple experiment whereby image reconstruction quality is affected by simultaneous conscious processing and readout of the perceived light intensities.
Massive MIMO Evolution Towards 3GPP Release 18
Oct 15, 2022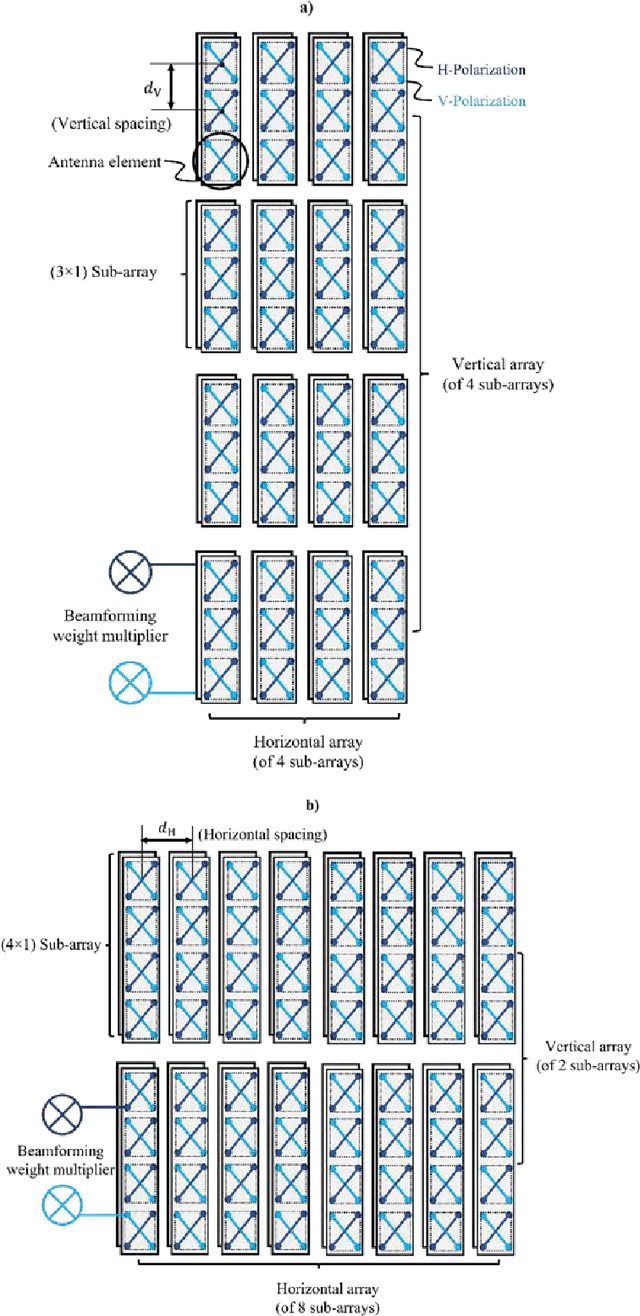

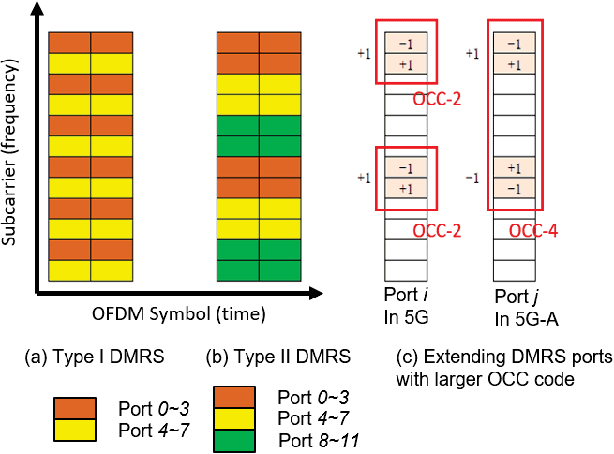
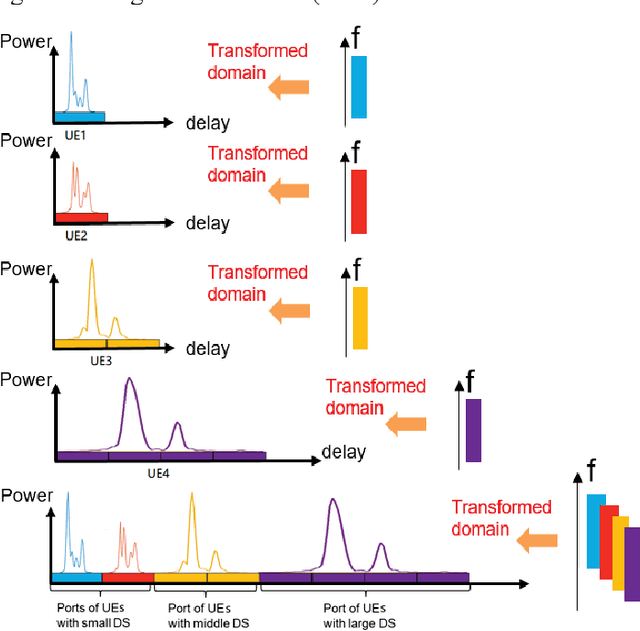
Since the introduction of fifth-generation new radio (5G-NR) in Third Generation Partnership Project (3GPP) Release 15, swift progress has been made to evolve 5G with 3GPP Release 18 emerging. A critical aspect is the design of massive multiple-input multiple-output (MIMO) technology. In this line, this paper makes several important contributions: We provide a comprehensive overview of the evolution of standardized massive MIMO features from 3GPP Release 15 to 17 for both time/frequency-division duplex operation across bands FR-1 and FR-2. We analyze the progress on channel state information (CSI) frameworks, beam management frameworks and present enhancements for uplink CSI. We shed light on emerging 3GPP Release 18 problems requiring imminent attention. These include advanced codebook design and sounding reference signal design for coherent joint transmission (CJT) with multiple transmission/reception points (multi- TRPs). We discuss advancements in uplink demodulation reference signal design, enhancements for mobility to provide accurate CSI estimates, and unified transmission configuration indicator framework tailored for FR-2 bands. For each concept, we provide system level simulation results to highlight their performance benefits. Via field trials in an outdoor environment at Shanghai Jiaotong University, we demonstrate the gains of multi-TRP CJT relative to single TRP at 3.7 GHz.
Belief propagation generalizes backpropagation
Oct 02, 2022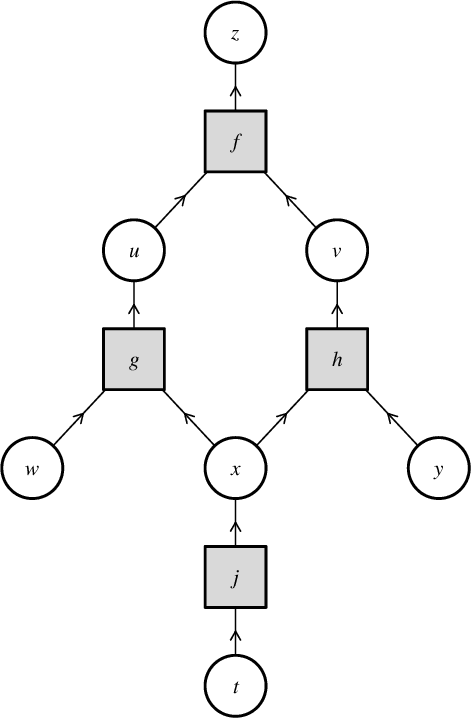
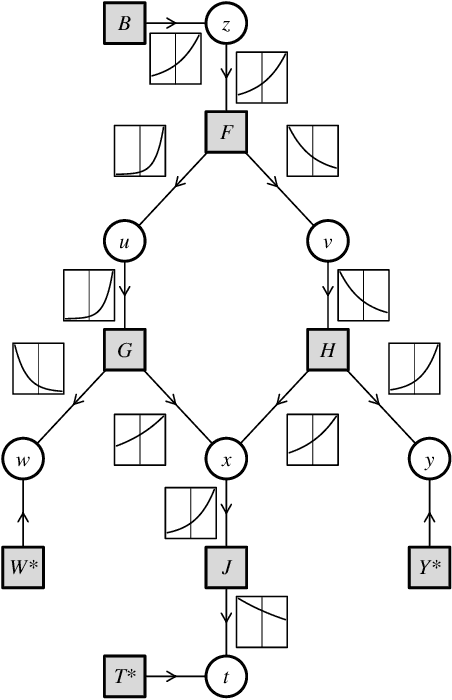
The two most important algorithms in artificial intelligence are backpropagation and belief propagation. In spite of their importance, the connection between them is poorly characterized. We show that when an input to backpropagation is converted into an input to belief propagation so that (loopy) belief propagation can be run on it, then the result of belief propagation encodes the result of backpropagation; thus backpropagation is recovered as a special case of belief propagation. In other words, we prove for apparently the first time that belief propagation generalizes backpropagation. Our analysis is a theoretical contribution, which we motivate with the expectation that it might reconcile our understandings of each of these algorithms, and serve as a guide to engineering researchers seeking to improve the behavior of systems that use one or the other.
Learning Non-Stationary Time-Series with Dynamic Pattern Extractions
Nov 20, 2021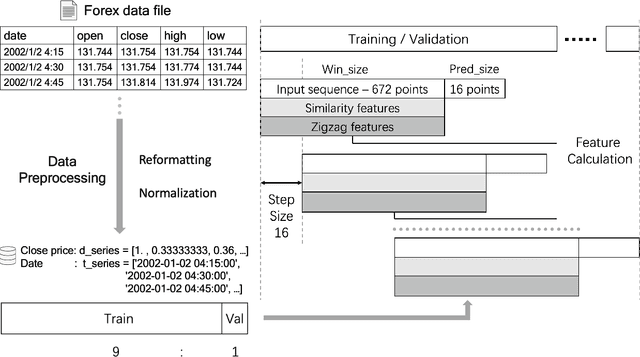
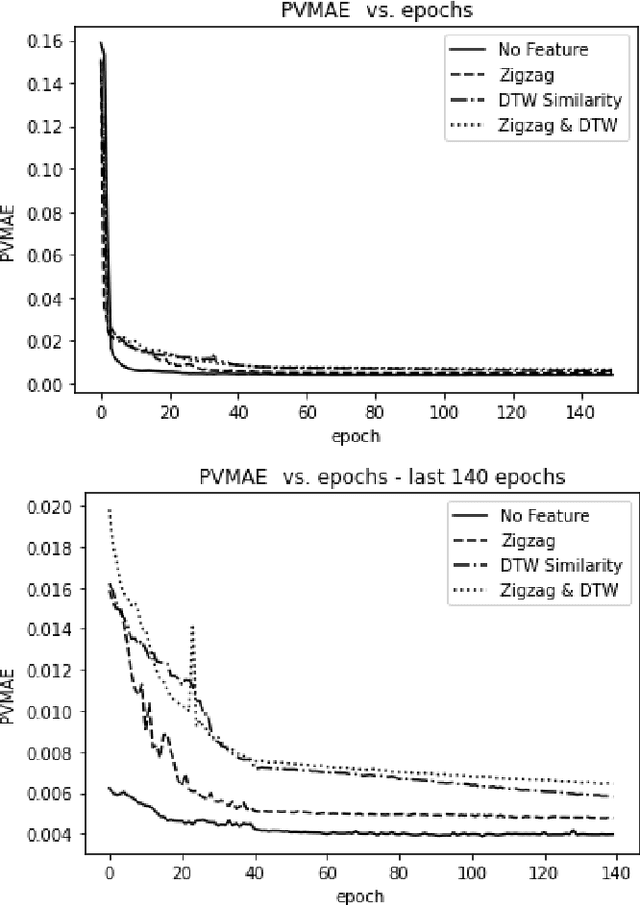
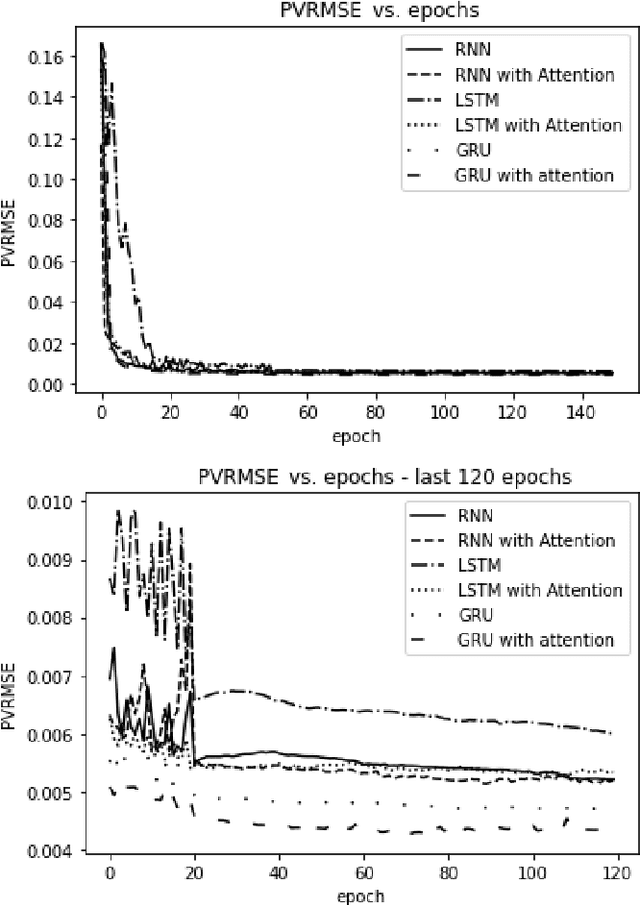
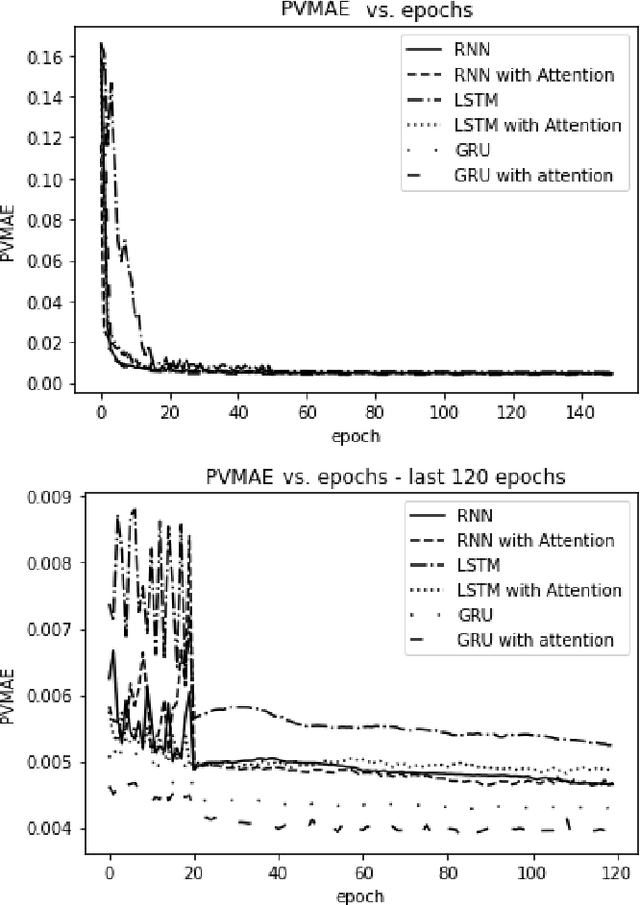
The era of information explosion had prompted the accumulation of a tremendous amount of time-series data, including stationary and non-stationary time-series data. State-of-the-art algorithms have achieved a decent performance in dealing with stationary temporal data. However, traditional algorithms that tackle stationary time-series do not apply to non-stationary series like Forex trading. This paper investigates applicable models that can improve the accuracy of forecasting future trends of non-stationary time-series sequences. In particular, we focus on identifying potential models and investigate the effects of recognizing patterns from historical data. We propose a combination of \rebuttal{the} seq2seq model based on RNN, along with an attention mechanism and an enriched set features extracted via dynamic time warping and zigzag peak valley indicators. Customized loss functions and evaluating metrics have been designed to focus more on the predicting sequence's peaks and valley points. Our results show that our model can predict 4-hour future trends with high accuracy in the Forex dataset, which is crucial in realistic scenarios to assist foreign exchange trading decision making. We further provide evaluations of the effects of various loss functions, evaluation metrics, model variants, and components on model performance.
Revisiting Crowd Counting: State-of-the-art, Trends, and Future Perspectives
Sep 14, 2022
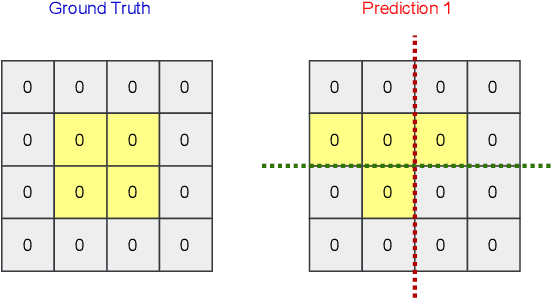
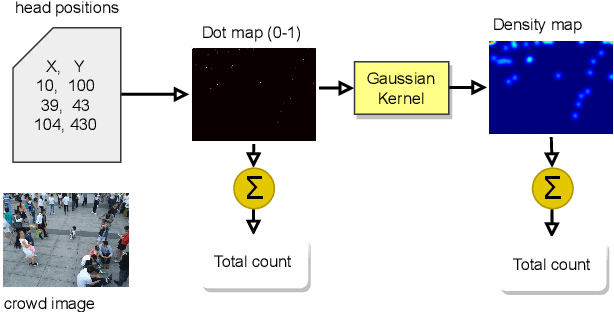
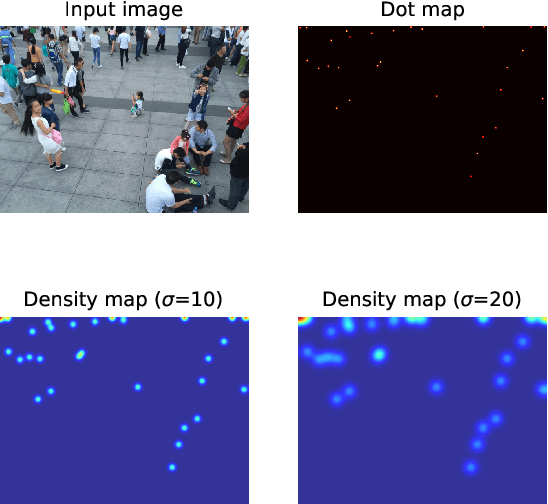
Crowd counting is an effective tool for situational awareness in public places. Automated crowd counting using images and videos is an interesting yet challenging problem that has gained significant attention in computer vision. Over the past few years, various deep learning methods have been developed to achieve state-of-the-art performance. The methods evolved over time vary in many aspects such as model architecture, input pipeline, learning paradigm, computational complexity, and accuracy gains etc. In this paper, we present a systematic and comprehensive review of the most significant contributions in the area of crowd counting. Although few surveys exist on the topic, our survey is most up-to date and different in several aspects. First, it provides a more meaningful categorization of the most significant contributions by model architectures, learning methods (i.e., loss functions), and evaluation methods (i.e., evaluation metrics). We chose prominent and distinct works and excluded similar works. We also sort the well-known crowd counting models by their performance over benchmark datasets. We believe that this survey can be a good resource for novice researchers to understand the progressive developments and contributions over time and the current state-of-the-art.
Hardware Acceleration of Sampling Algorithms in Sample and Aggregate Graph Neural Networks
Sep 07, 2022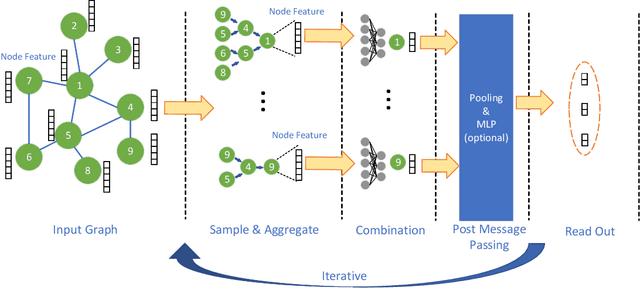
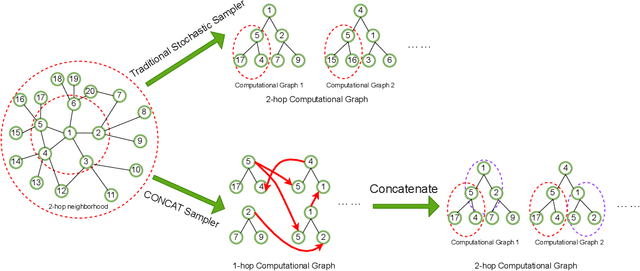
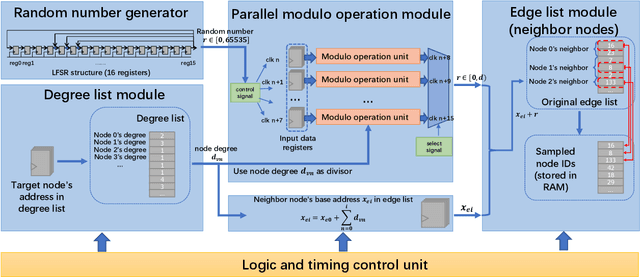
Sampling is an important process in many GNN structures in order to train larger datasets with a smaller computational complexity. However, compared to other processes in GNN (such as aggregate, backward propagation), the sampling process still costs tremendous time, which limits the speed of training. To reduce the time of sampling, hardware acceleration is an ideal choice. However, state of the art GNN acceleration proposal did not specify how to accelerate the sampling process. What's more, directly accelerating traditional sampling algorithms will make the structure of the accelerator very complicated. In this work, we made two contributions: (1) Proposed a new neighbor sampler: CONCAT Sampler, which can be easily accelerated on hardware level while guaranteeing the test accuracy. (2) Designed a CONCAT-sampler-accelerator based on FPGA, with which the neighbor sampling process boosted to about 300-1000 times faster compared to the sampling process without it.
Learning Temporal Point Processes for Efficient Retrieval of Continuous Time Event Sequences
Feb 17, 2022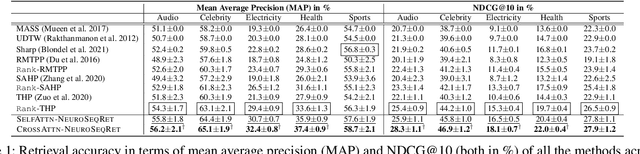
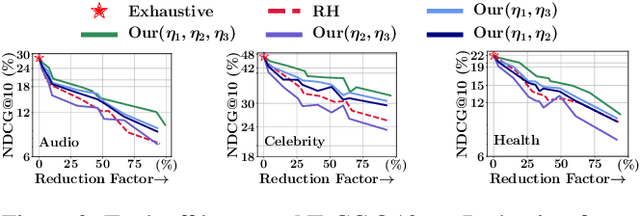

Recent developments in predictive modeling using marked temporal point processes (MTPP) have enabled an accurate characterization of several real-world applications involving continuous-time event sequences (CTESs). However, the retrieval problem of such sequences remains largely unaddressed in literature. To tackle this, we propose NEUROSEQRET which learns to retrieve and rank a relevant set of continuous-time event sequences for a given query sequence, from a large corpus of sequences. More specifically, NEUROSEQRET first applies a trainable unwarping function on the query sequence, which makes it comparable with corpus sequences, especially when a relevant query-corpus pair has individually different attributes. Next, it feeds the unwarped query sequence and the corpus sequence into MTPP guided neural relevance models. We develop two variants of the relevance model which offer a tradeoff between accuracy and efficiency. We also propose an optimization framework to learn binary sequence embeddings from the relevance scores, suitable for the locality-sensitive hashing leading to a significant speedup in returning top-K results for a given query sequence. Our experiments with several datasets show the significant accuracy boost of NEUROSEQRET beyond several baselines, as well as the efficacy of our hashing mechanism.