 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Computational imaging with the human brain
Oct 07, 2022



Brain-computer interfaces (BCIs) are enabling a range of new possibilities and routes for augmenting human capability. Here, we propose BCIs as a route towards forms of computation, i.e. computational imaging, that blend the brain with external silicon processing. We demonstrate ghost imaging of a hidden scene using the human visual system that is combined with an adaptive computational imaging scheme. This is achieved through a projection pattern `carving' technique that relies on real-time feedback from the brain to modify patterns at the light projector, thus enabling more efficient and higher resolution imaging. This brain-computer connectivity demonstrates a form of augmented human computation that could in the future extend the sensing range of human vision and provide new approaches to the study of the neurophysics of human perception. As an example, we illustrate a simple experiment whereby image reconstruction quality is affected by simultaneous conscious processing and readout of the perceived light intensities.
Machine Learning Sensors for Diagnosis of COVID-19 Disease Using Routine Blood Values for Internet of Things Application
Sep 08, 2022
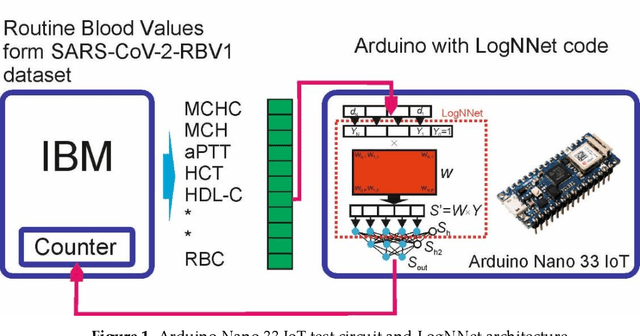
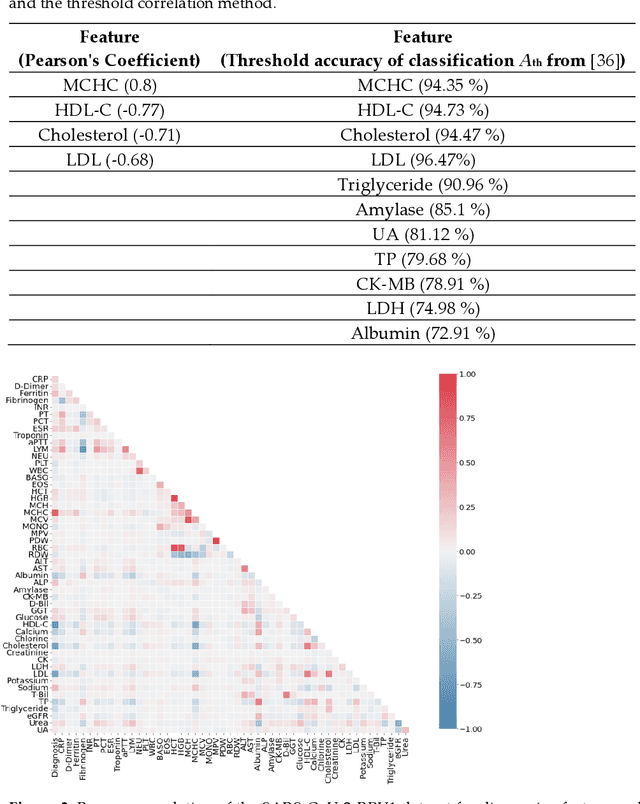
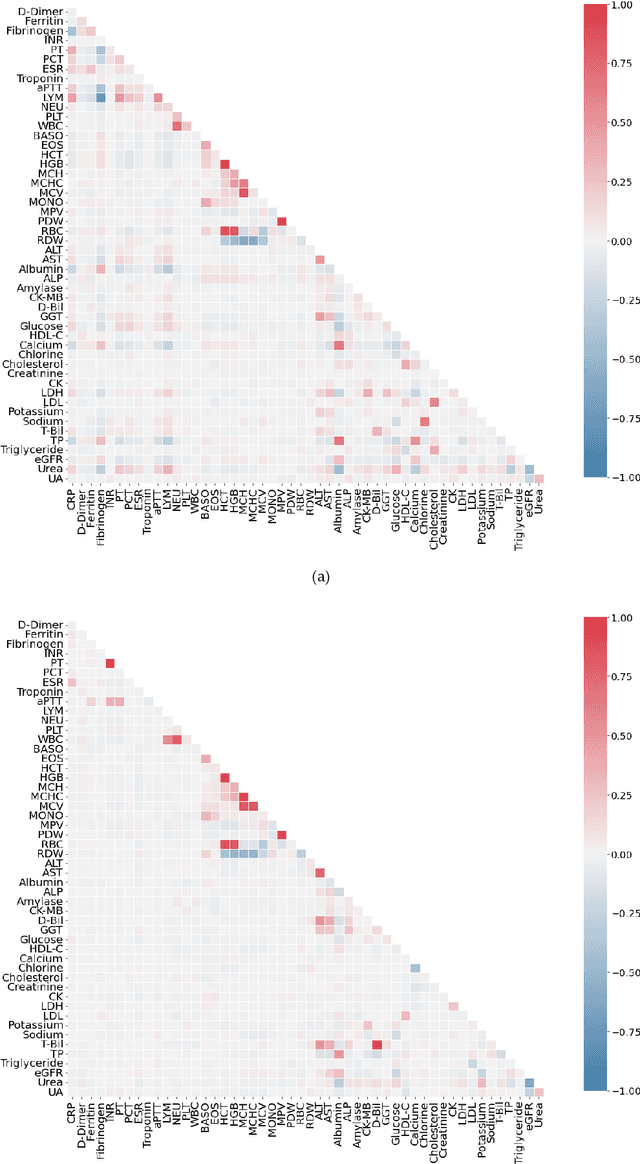
Healthcare digitalization needs effective methods of human sensorics, when various parameters of the human body are instantly monitored in everyday life and connected to the Internet of Things (IoT). In particular, Machine Learning (ML) sensors for the prompt diagnosis of COVID-19 is an important case for IoT application in healthcare and Ambient Assistance Living (AAL). Determining the infected status of COVID-19 with various diagnostic tests and imaging results is costly and time-consuming. The aim of this study is to provide a fast, reliable and economical alternative tool for the diagnosis of COVID-19 based on the Routine Blood Values (RBV) values measured at admission. The dataset of the study consists of a total of 5296 patients with the same number of negative and positive COVID-19 test results and 51 routine blood values. In this study, 13 popular classifier machine learning models and LogNNet neural network model were exanimated. The most successful classifier model in terms of time and accuracy in the detection of the disease was the Histogram-based Gradient Boosting (HGB). The HGB classifier identified the 11 most important features (LDL, Cholesterol, HDL-C, MCHC, Triglyceride, Amylase, UA, LDH, CK-MB, ALP and MCH) to detect the disease with 100% accuracy, learning time 6.39 sec. In addition, the importance of single, double and triple combinations of these features in the diagnosis of the disease was discussed. We propose to use these 11 traits and their combinations as important biomarkers for ML sensors in diagnosis of the disease, supporting edge computing on Arduino and cloud IoT service.
Belief propagation generalizes backpropagation
Oct 02, 2022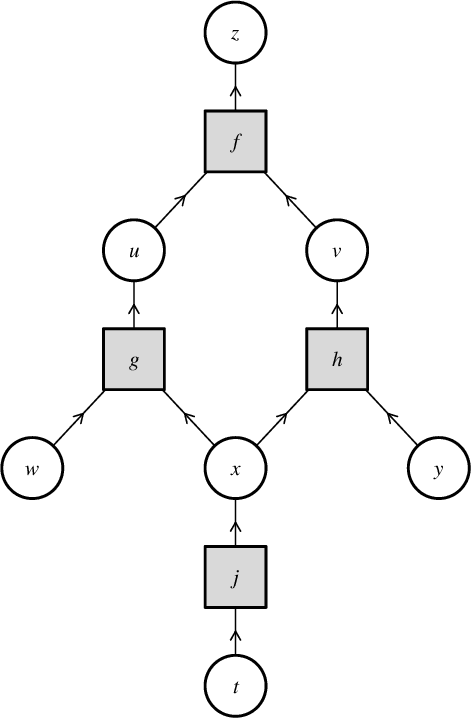
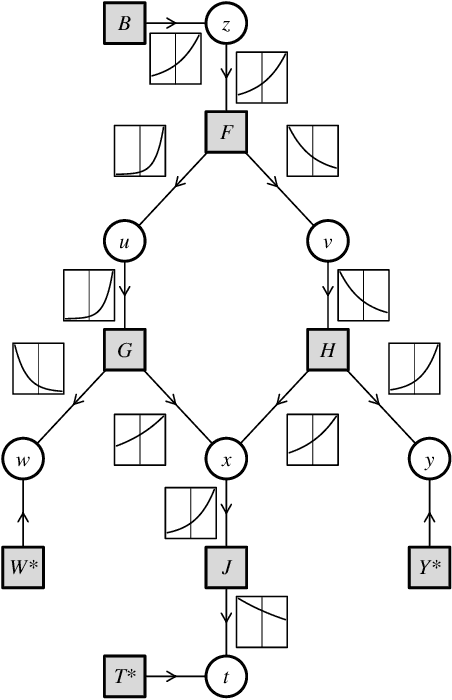
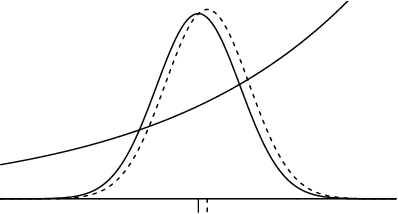
The two most important algorithms in artificial intelligence are backpropagation and belief propagation. In spite of their importance, the connection between them is poorly characterized. We show that when an input to backpropagation is converted into an input to belief propagation so that (loopy) belief propagation can be run on it, then the result of belief propagation encodes the result of backpropagation; thus backpropagation is recovered as a special case of belief propagation. In other words, we prove for apparently the first time that belief propagation generalizes backpropagation. Our analysis is a theoretical contribution, which we motivate with the expectation that it might reconcile our understandings of each of these algorithms, and serve as a guide to engineering researchers seeking to improve the behavior of systems that use one or the other.
spatial-dccrn: dccrn equipped with frame-level angle feature and hybrid filtering for multi-channel speech enhancement
Oct 17, 2022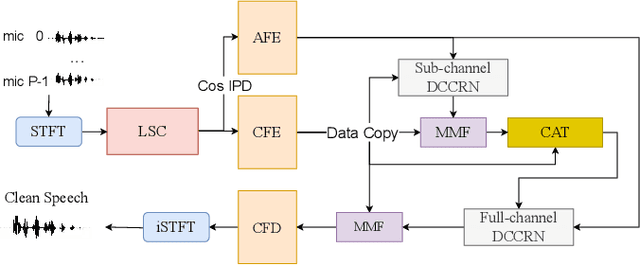
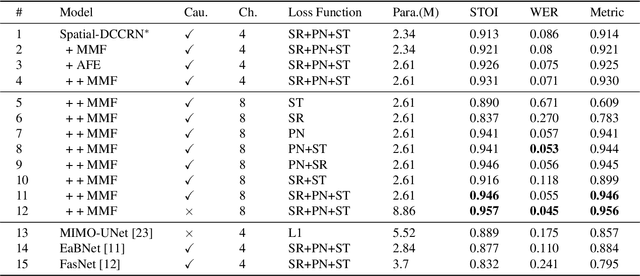
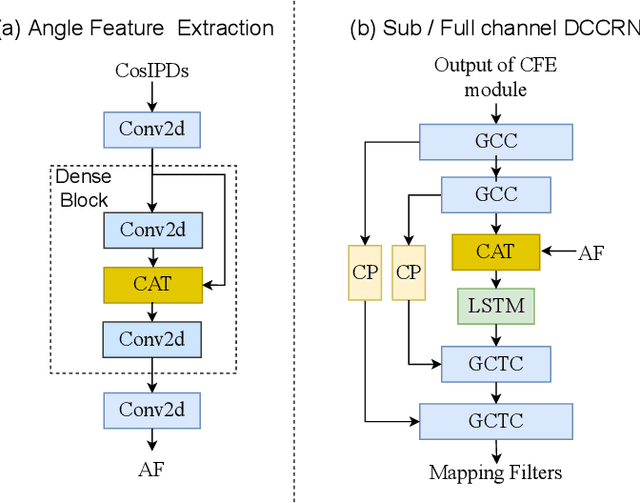
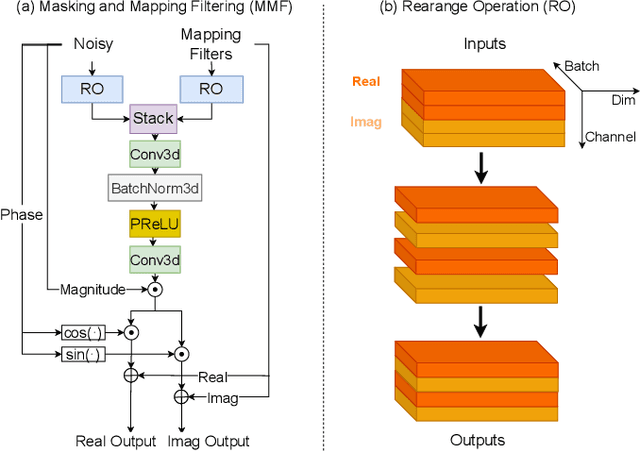
Recently, multi-channel speech enhancement has drawn much interest due to the use of spatial information to distinguish target speech from interfering signal. To make full use of spatial information and neural network based masking estimation, we propose a multi-channel denoising neural network -- Spatial DCCRN. Firstly, we extend S-DCCRN to multi-channel scenario, aiming at performing cascaded sub-channel and full-channel processing strategy, which can model different channels separately. Moreover, instead of only adopting multi-channel spectrum or concatenating first-channel's magnitude and IPD as the model's inputs, we apply an angle feature extraction module (AFE) to extract frame-level angle feature embeddings, which can help the model to apparently perceive spatial information. Finally, since the phenomenon of residual noise will be more serious when the noise and speech exist in the same time frequency (TF) bin, we particularly design a masking and mapping filtering method to substitute the traditional filter-and-sum operation, with the purpose of cascading coarsely denoising, dereverberation and residual noise suppression. The proposed model, Spatial-DCCRN, has surpassed EaBNet, FasNet as well as several competitive models on the L3DAS22 Challenge dataset. Not only the 3D scenario, Spatial-DCCRN outperforms state-of-the-art (SOTA) model MIMO-UNet by a large margin in multiple evaluation metrics on the multi-channel ConferencingSpeech2021 Challenge dataset. Ablation studies also demonstrate the effectiveness of different contributions.
VoxelCache: Accelerating Online Mapping in Robotics and 3D Reconstruction Tasks
Oct 17, 2022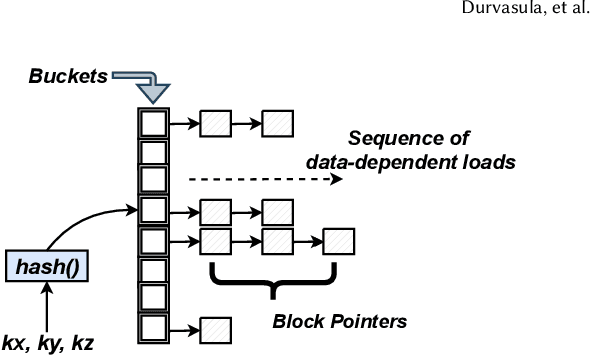
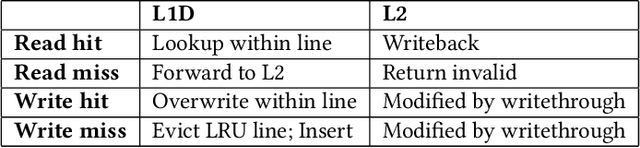
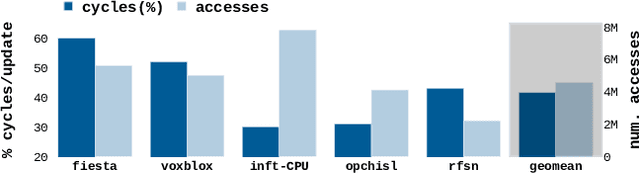
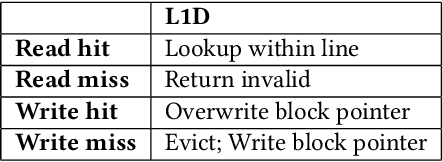
Real-time 3D mapping is a critical component in many important applications today including robotics, AR/VR, and 3D visualization. 3D mapping involves continuously fusing depth maps obtained from depth sensors in phones, robots, and autonomous vehicles into a single 3D representative model of the scene. Many important applications, e.g., global path planning and trajectory generation in micro aerial vehicles, require the construction of large maps at high resolutions. In this work, we identify mapping, i.e., construction and updates of 3D maps to be a critical bottleneck in these applications. The memory required and access times of these maps limit the size of the environment and the resolution with which the environment can be feasibly mapped, especially in resource constrained environments such as autonomous robot platforms and portable devices. To address this challenge, we propose VoxelCache: a hardware-software technique to accelerate map data access times in 3D mapping applications. We observe that mapping applications typically access voxels in the map that are spatially co-located to each other. We leverage this temporal locality in voxel accesses to cache indices to blocks of voxels to enable quick lookup and avoid expensive access times. We evaluate VoxelCache on popularly used mapping and reconstruction applications on both GPUs and CPUs. We demonstrate an average speedup of 1.47X (up to 1.66X) and 1.79X (up to 1.91X) on CPUs and GPUs respectively.
Training a T5 Using Lab-sized Resources
Aug 25, 2022
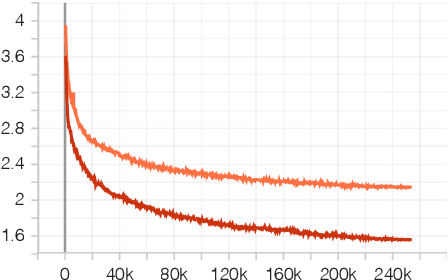
Training large neural language models on large datasets is resource- and time-intensive. These requirements create a barrier to entry, where those with fewer resources cannot build competitive models. This paper presents various techniques for making it possible to (a) train a large language model using resources that a modest research lab might have, and (b) train it in a reasonable amount of time. We provide concrete recommendations for practitioners, which we illustrate with a case study: a T5 model for Danish, the first for this language.
Multitask Learning via Shared Features: Algorithms and Hardness
Sep 07, 2022
We investigate the computational efficiency of multitask learning of Boolean functions over the $d$-dimensional hypercube, that are related by means of a feature representation of size $k \ll d$ shared across all tasks. We present a polynomial time multitask learning algorithm for the concept class of halfspaces with margin $\gamma$, which is based on a simultaneous boosting technique and requires only $\textrm{poly}(k/\gamma)$ samples-per-task and $\textrm{poly}(k\log(d)/\gamma)$ samples in total. In addition, we prove a computational separation, showing that assuming there exists a concept class that cannot be learned in the attribute-efficient model, we can construct another concept class such that can be learned in the attribute-efficient model, but cannot be multitask learned efficiently -- multitask learning this concept class either requires super-polynomial time complexity or a much larger total number of samples.
Hyper Attention Recurrent Neural Network: Tackling Temporal Covariate Shift in Time Series Analysis
Feb 22, 2022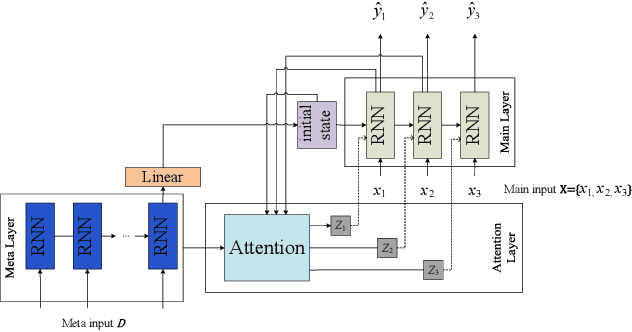
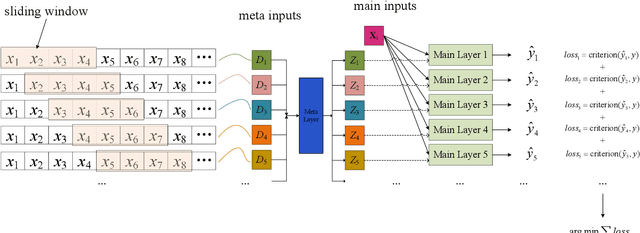
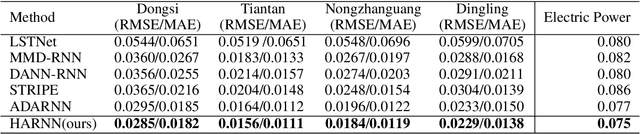
Analyzing long time series with RNNs often suffers from infeasible training. Segmentation is therefore commonly used in data pre-processing. However, in non-stationary time series, there exists often distribution shift among different segments. RNN is easily swamped in the dilemma of fitting bias in these segments due to the lack of global information, leading to poor generalization, known as Temporal Covariate Shift (TCS) problem, which is only addressed by a recently proposed RNN-based model. One of the assumptions in TCS is that the distribution of all divided intervals under the same segment are identical. This assumption, however, may not be true on high-frequency time series, such as traffic flow, that also have large stochasticity. Besides, macro information across long periods isn't adequately considered in the latest RNN-based methods. To address the above issues, we propose Hyper Attention Recurrent Neural Network (HARNN) for the modeling of temporal patterns containing both micro and macro information. An HARNN consists of a meta layer for parameter generation and an attention-enabled main layer for inference. High-frequency segments are transformed into low-frequency segments and fed into the meta layers, while the first main layer consumes the same high-frequency segments as conventional methods. In this way, each low-frequency segment in the meta inputs generates a unique main layer, enabling the integration of both macro information and micro information for inference. This forces all main layers to predict the same target which fully harnesses the common knowledge in varied distributions when capturing temporal patterns. Evaluations on multiple benchmarks demonstrated that our model outperforms a couple of RNN-based methods on a federation of key metrics.
RASR: Risk-Averse Soft-Robust MDPs with EVaR and Entropic Risk
Sep 09, 2022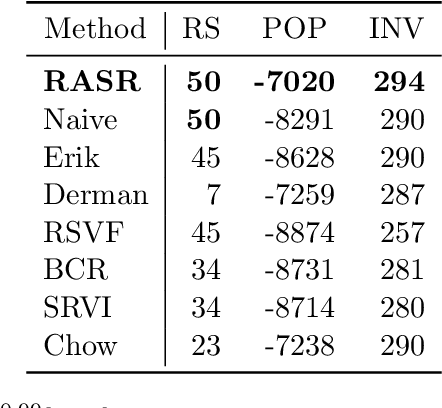

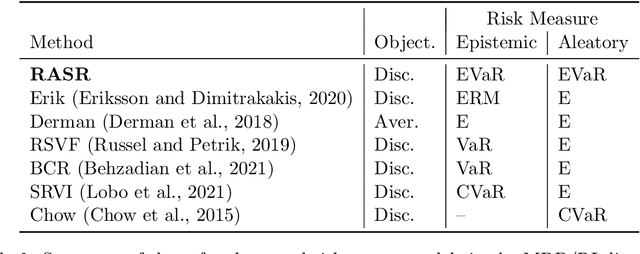
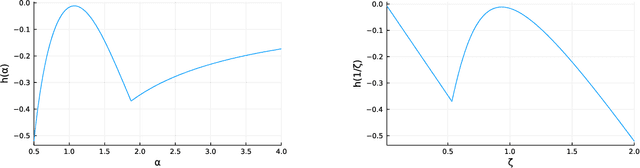
Prior work on safe Reinforcement Learning (RL) has studied risk-aversion to randomness in dynamics (aleatory) and to model uncertainty (epistemic) in isolation. We propose and analyze a new framework to jointly model the risk associated with epistemic and aleatory uncertainties in finite-horizon and discounted infinite-horizon MDPs. We call this framework that combines Risk-Averse and Soft-Robust methods RASR. We show that when the risk-aversion is defined using either EVaR or the entropic risk, the optimal policy in RASR can be computed efficiently using a new dynamic program formulation with a time-dependent risk level. As a result, the optimal risk-averse policies are deterministic but time-dependent, even in the infinite-horizon discounted setting. We also show that particular RASR objectives reduce to risk-averse RL with mean posterior transition probabilities. Our empirical results show that our new algorithms consistently mitigate uncertainty as measured by EVaR and other standard risk measures.
Grounded Video Situation Recognition
Oct 19, 2022
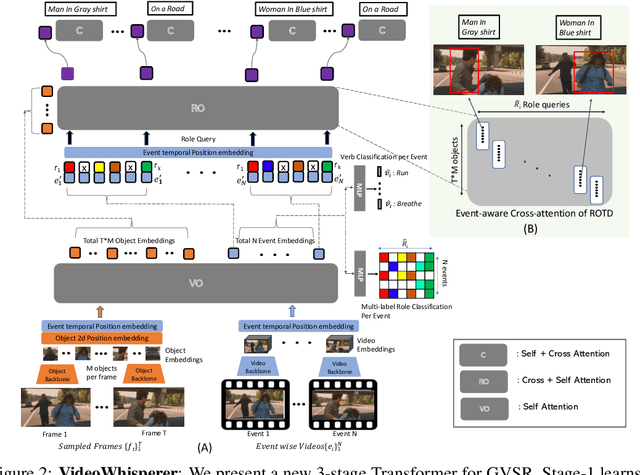


Dense video understanding requires answering several questions such as who is doing what to whom, with what, how, why, and where. Recently, Video Situation Recognition (VidSitu) is framed as a task for structured prediction of multiple events, their relationships, and actions and various verb-role pairs attached to descriptive entities. This task poses several challenges in identifying, disambiguating, and co-referencing entities across multiple verb-role pairs, but also faces some challenges of evaluation. In this work, we propose the addition of spatio-temporal grounding as an essential component of the structured prediction task in a weakly supervised setting, and present a novel three stage Transformer model, VideoWhisperer, that is empowered to make joint predictions. In stage one, we learn contextualised embeddings for video features in parallel with key objects that appear in the video clips to enable fine-grained spatio-temporal reasoning. The second stage sees verb-role queries attend and pool information from object embeddings, localising answers to questions posed about the action. The final stage generates these answers as captions to describe each verb-role pair present in the video. Our model operates on a group of events (clips) simultaneously and predicts verbs, verb-role pairs, their nouns, and their grounding on-the-fly. When evaluated on a grounding-augmented version of the VidSitu dataset, we observe a large improvement in entity captioning accuracy, as well as the ability to localize verb-roles without grounding annotations at training time.