 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Auto-TransRL: Autonomous Composition of Vision Pipelines for Robotic Perception
Sep 07, 2022
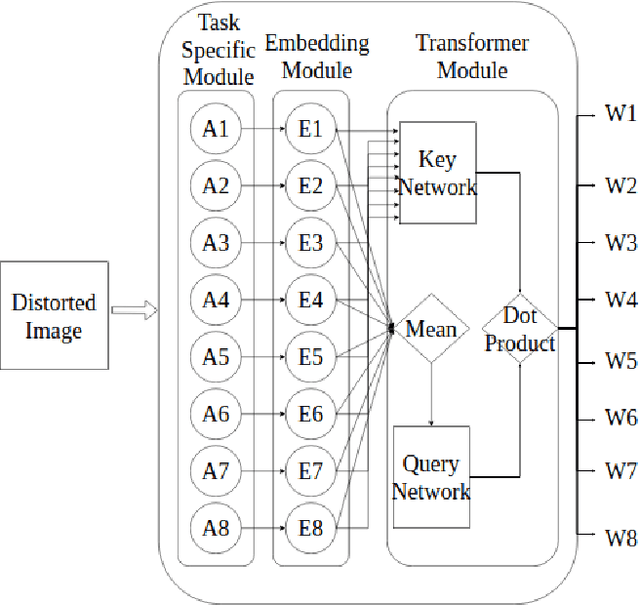
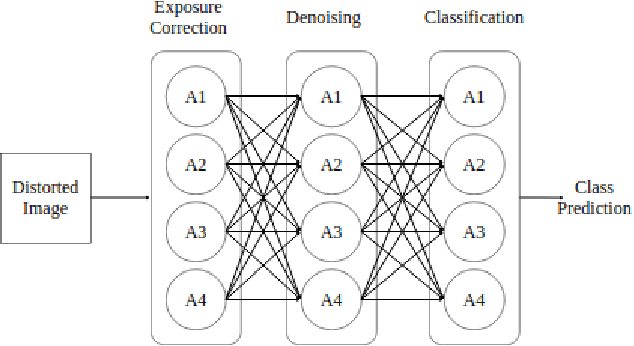
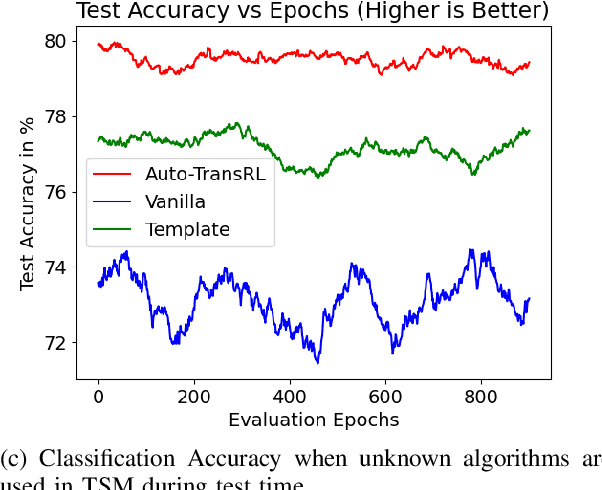
Creating a vision pipeline for different datasets to solve a computer vision task is a complex and time consuming process. Currently, these pipelines are developed with the help of domain experts. Moreover, there is no systematic structure to construct a vision pipeline apart from relying on experience, trial and error or using template-based approaches. As the search space for choosing suitable algorithms for achieving a particular vision task is large, human exploration for finding a good solution requires time and effort. To address the following issues, we propose a dynamic and data-driven way to identify an appropriate set of algorithms that would be fit for building the vision pipeline in order to achieve the goal task. We introduce a Transformer Architecture complemented with Deep Reinforcement Learning to recommend algorithms that can be incorporated at different stages of the vision workflow. This system is both robust and adaptive to dynamic changes in the environment. Experimental results further show that our method also generalizes well to recommend algorithms that have not been used while training and hence alleviates the need of retraining the system on a new set of algorithms introduced during test time.
Multimodal Crop Type Classification Fusing Multi-Spectral Satellite Time Series with Farmers Crop Rotations and Local Crop Distribution
Aug 23, 2022
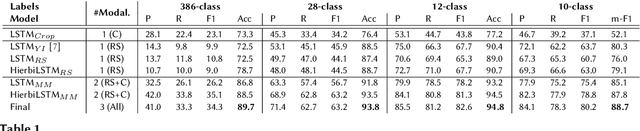
Accurate, detailed, and timely crop type mapping is a very valuable information for the institutions in order to create more accurate policies according to the needs of the citizens. In the last decade, the amount of available data dramatically increased, whether it can come from Remote Sensing (using Copernicus Sentinel-2 data) or directly from the farmers (providing in-situ crop information throughout the years and information on crop rotation). Nevertheless, the majority of the studies are restricted to the use of one modality (Remote Sensing data or crop rotation) and never fuse the Earth Observation data with domain knowledge like crop rotations. Moreover, when they use Earth Observation data they are mainly restrained to one year of data, not taking into account the past years. In this context, we propose to tackle a land use and crop type classification task using three data types, by using a Hierarchical Deep Learning algorithm modeling the crop rotations like a language model, the satellite signals like a speech signal and using the crop distribution as additional context vector. We obtained very promising results compared to classical approaches with significant performances, increasing the Accuracy by 5.1 points in a 28-class setting (.948), and the micro-F1 by 9.6 points in a 10-class setting (.887) using only a set of crop of interests selected by an expert. We finally proposed a data-augmentation technique to allow the model to classify the crop before the end of the season, which works surprisingly well in a multimodal setting.
Multi-modal Segment Assemblage Network for Ad Video Editing with Importance-Coherence Reward
Sep 25, 2022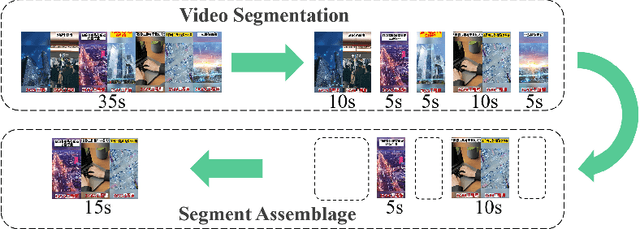

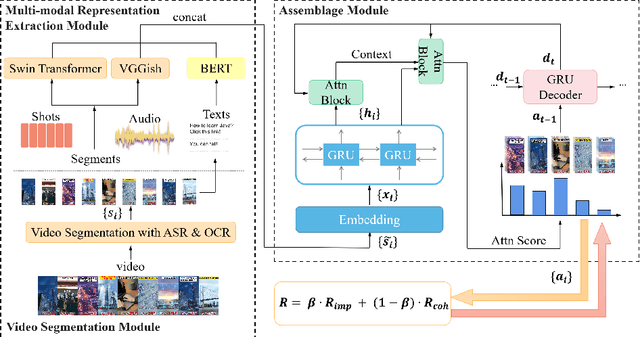
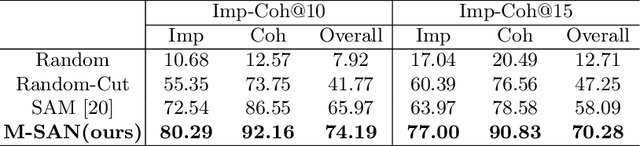
Advertisement video editing aims to automatically edit advertising videos into shorter videos while retaining coherent content and crucial information conveyed by advertisers. It mainly contains two stages: video segmentation and segment assemblage. The existing method performs well at video segmentation stages but suffers from the problems of dependencies on extra cumbersome models and poor performance at the segment assemblage stage. To address these problems, we propose M-SAN (Multi-modal Segment Assemblage Network) which can perform efficient and coherent segment assemblage task end-to-end. It utilizes multi-modal representation extracted from the segments and follows the Encoder-Decoder Ptr-Net framework with the Attention mechanism. Importance-coherence reward is designed for training M-SAN. We experiment on the Ads-1k dataset with 1000+ videos under rich ad scenarios collected from advertisers. To evaluate the methods, we propose a unified metric, Imp-Coh@Time, which comprehensively assesses the importance, coherence, and duration of the outputs at the same time. Experimental results show that our method achieves better performance than random selection and the previous method on the metric. Ablation experiments further verify that multi-modal representation and importance-coherence reward significantly improve the performance. Ads-1k dataset is available at: https://github.com/yunlong10/Ads-1k
Deep-MDS Framework for Recovering the 3D Shape of 2D Landmarks from a Single Image
Oct 27, 2022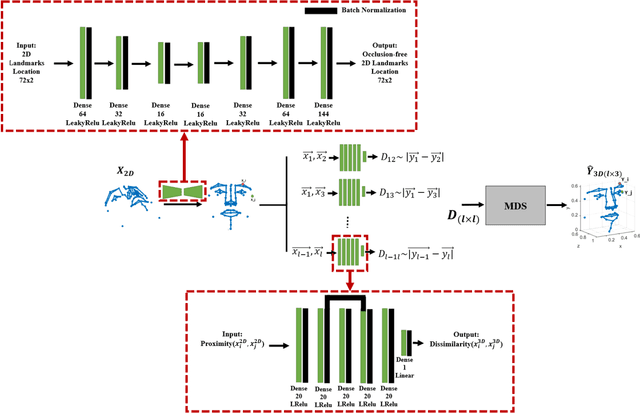

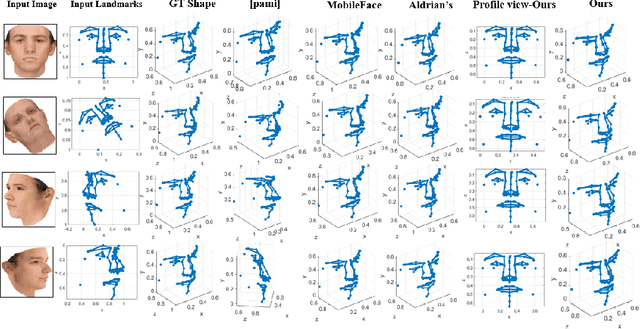
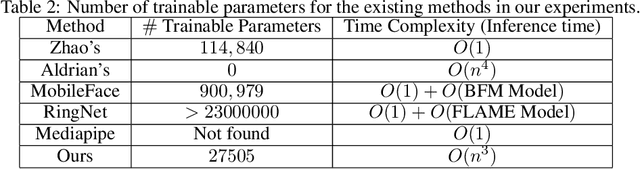
In this paper, a low parameter deep learning framework utilizing the Non-metric Multi-Dimensional scaling (NMDS) method, is proposed to recover the 3D shape of 2D landmarks on a human face, in a single input image. Hence, NMDS approach is used for the first time to establish a mapping from a 2D landmark space to the corresponding 3D shape space. A deep neural network learns the pairwise dissimilarity among 2D landmarks, used by NMDS approach, whose objective is to learn the pairwise 3D Euclidean distance of the corresponding 2D landmarks on the input image. This scheme results in a symmetric dissimilarity matrix, with the rank larger than 2, leading the NMDS approach toward appropriately recovering the 3D shape of corresponding 2D landmarks. In the case of posed images and complex image formation processes like perspective projection which causes occlusion in the input image, we consider an autoencoder component in the proposed framework, as an occlusion removal part, which turns different input views of the human face into a profile view. The results of a performance evaluation using different synthetic and real-world human face datasets, including Besel Face Model (BFM), CelebA, CoMA - FLAME, and CASIA-3D, indicates the comparable performance of the proposed framework, despite its small number of training parameters, with the related state-of-the-art and powerful 3D reconstruction methods from the literature, in terms of efficiency and accuracy.
Learning Failure-Inducing Models for Testing Software-Defined Networks
Oct 27, 2022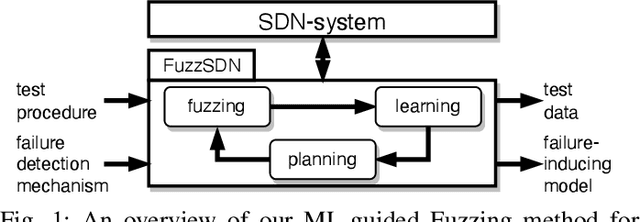

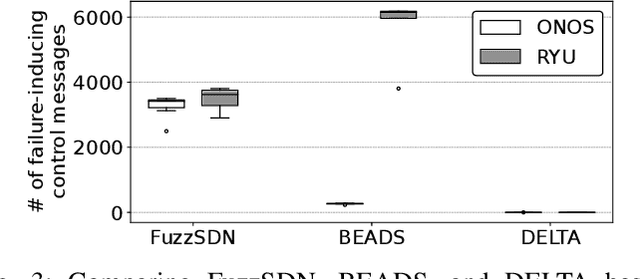
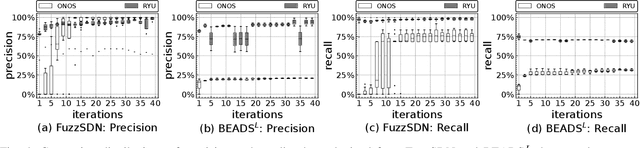
Software-defined networks (SDN) enable flexible and effective communication systems, e.g., data centers, that are managed by centralized software controllers. However, such a controller can undermine the underlying communication network of an SDN-based system and thus must be carefully tested. When an SDN-based system fails, in order to address such a failure, engineers need to precisely understand the conditions under which it occurs. In this paper, we introduce a machine learning-guided fuzzing method, named FuzzSDN, aiming at both (1) generating effective test data leading to failures in SDN-based systems and (2) learning accurate failure-inducing models that characterize conditions under which such system fails. This is done in a synergistic manner where models guide test generation and the latter also aims at improving the models. To our knowledge, FuzzSDN is the first attempt to simultaneously address these two objectives for SDNs. We evaluate FuzzSDN by applying it to systems controlled by two open-source SDN controllers. Further, we compare FuzzSDN with two state-of-the-art methods for fuzzing SDNs and two baselines (i.e., simple extensions of these two existing methods) for learning failure-inducing models. Our results show that (1) compared to the state-of-the-art methods, FuzzSDN generates at least 12 times more failures, within the same time budget, with a controller that is fairly robust to fuzzing and (2) our failure-inducing models have, on average, a precision of 98% and a recall of 86%, significantly outperforming the baselines.
Learned Inertial Odometry for Autonomous Drone Racing
Oct 27, 2022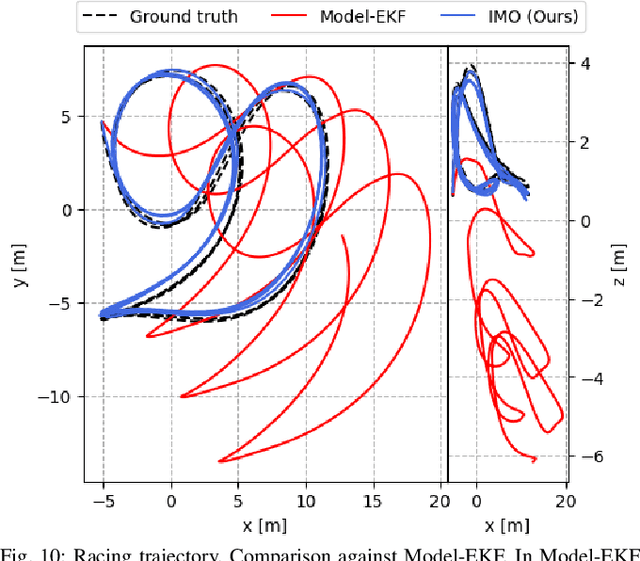
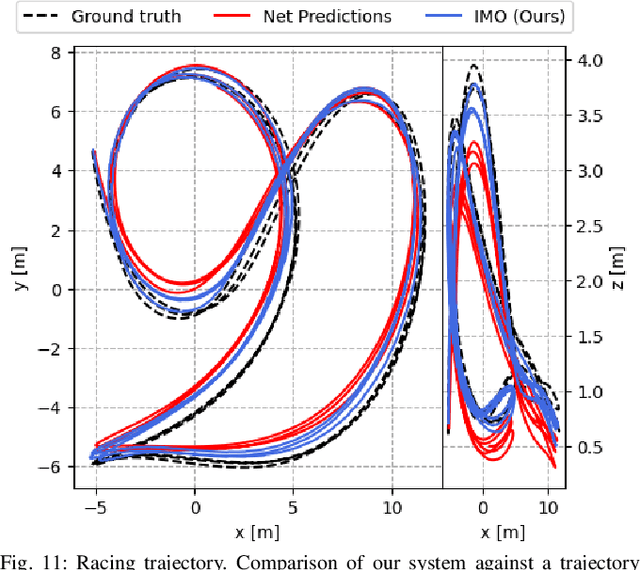
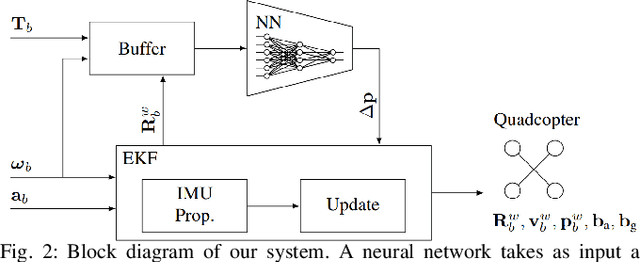
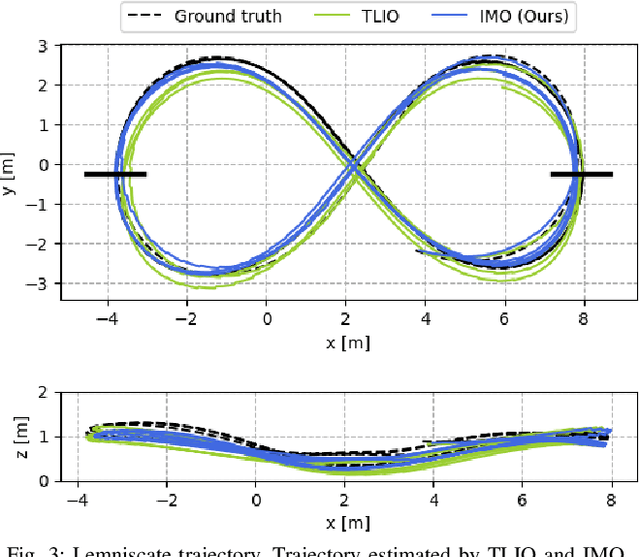
Inertial odometry is an attractive solution to the problem of state estimation for agile quadrotor flight. It is inexpensive, lightweight, and it is not affected by perceptual degradation. However, only relying on the integration of the inertial measurements for state estimation is infeasible. The errors and time-varying biases present in such measurements cause the accumulation of large drift in the pose estimates. Recently, inertial odometry has made significant progress in estimating the motion of pedestrians. State-of-the-art algorithms rely on learning a motion prior that is typical of humans but cannot be transferred to drones. In this work, we propose a learning-based odometry algorithm that uses an inertial measurement unit (IMU) as the only sensor modality for autonomous drone racing tasks. The core idea of our system is to couple a model-based filter, driven by the inertial measurements, with a learning-based module that has access to the control commands. We show that our inertial odometry algorithm is superior to the state-of-the-art filter-based and optimization-based visual- inertial odometry as well as the state-of-the-art learned-inertial odometry. Additionally, we show that our system is comparable to a visual-inertial odometry solution that uses a camera and exploits the known gate location and appearance. We believe that the application in autonomous drone racing paves the way for novel research in inertial odometry for agile quadrotor flight. We will release the code upon acceptance.
Fractional SDE-Net: Generation of Time Series Data with Long-term Memory
Jan 16, 2022
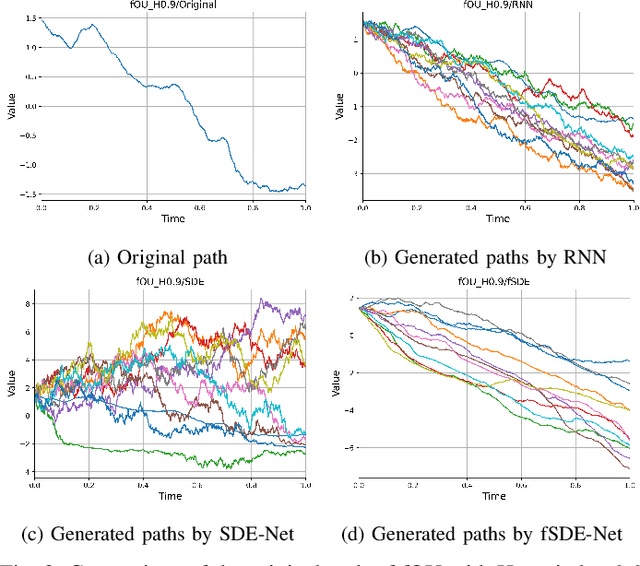
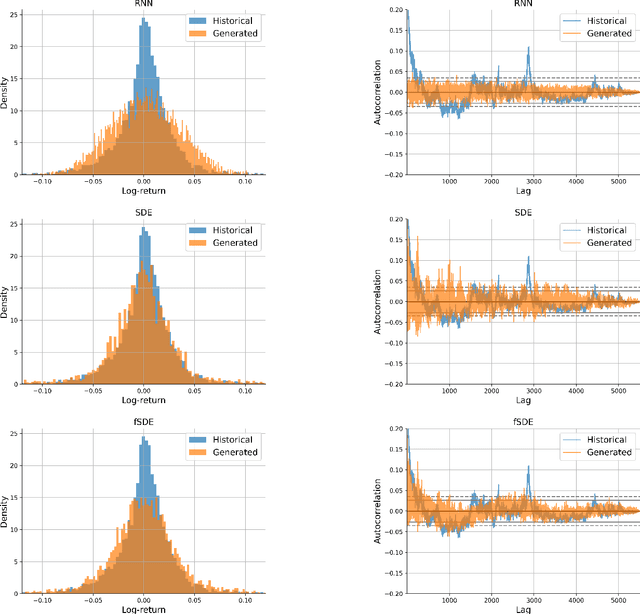
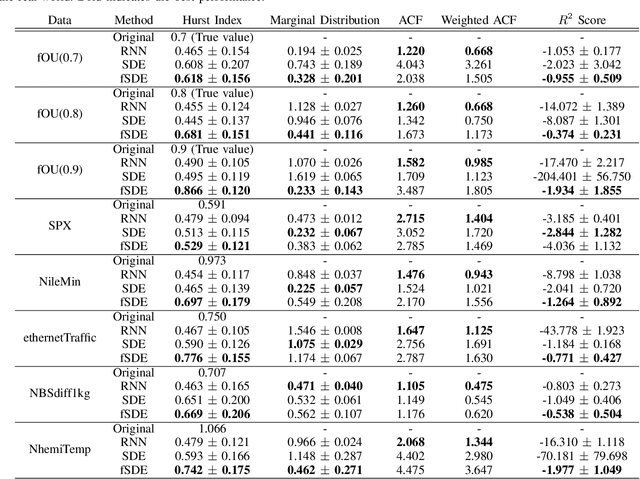
In this paper, we focus on generation of time-series data using neural networks. It is often the case that input time-series data, especially taken from real financial markets, is irregularly sampled, and its noise structure is more complicated than i.i.d. type. To generate time series with such a property, we propose fSDE-Net: neural fractional Stochastic Differential Equation Network. It generalizes the neural SDE model by using fractional Brownian motion with Hurst index larger than half, which exhibits long-term memory property. We derive the solver of fSDE-Net and theoretically analyze the existence and uniqueness of the solution to fSDE-Net. Our experiments demonstrate that the fSDE-Net model can replicate distributional properties well.
Long Short-Term Memory Neural Network for Financial Time Series
Jan 20, 2022

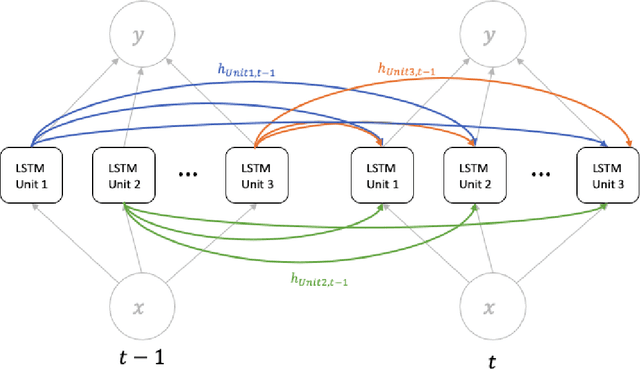
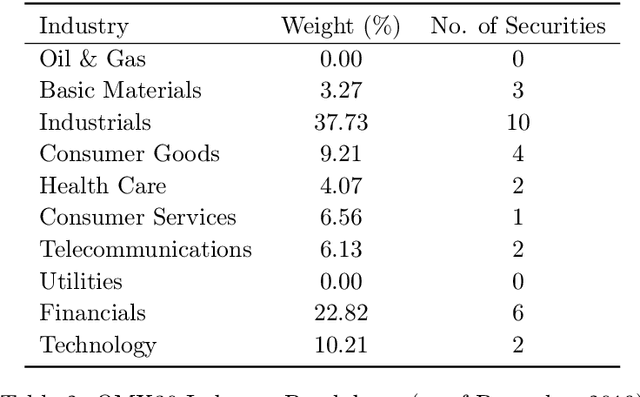
Performance forecasting is an age-old problem in economics and finance. Recently, developments in machine learning and neural networks have given rise to non-linear time series models that provide modern and promising alternatives to traditional methods of analysis. In this paper, we present an ensemble of independent and parallel long short-term memory (LSTM) neural networks for the prediction of stock price movement. LSTMs have been shown to be especially suited for time series data due to their ability to incorporate past information, while neural network ensembles have been found to reduce variability in results and improve generalization. A binary classification problem based on the median of returns is used, and the ensemble's forecast depends on a threshold value, which is the minimum number of LSTMs required to agree upon the result. The model is applied to the constituents of the smaller, less efficient Stockholm OMX30 instead of other major market indices such as the DJIA and S&P500 commonly found in literature. With a straightforward trading strategy, comparisons with a randomly chosen portfolio and a portfolio containing all the stocks in the index show that the portfolio resulting from the LSTM ensemble provides better average daily returns and higher cumulative returns over time. Moreover, the LSTM portfolio also exhibits less volatility, leading to higher risk-return ratios.
Persistent Homology Guided Monte-Carlo Tree Search for Effective Non-Prehensile Manipulation
Oct 04, 2022
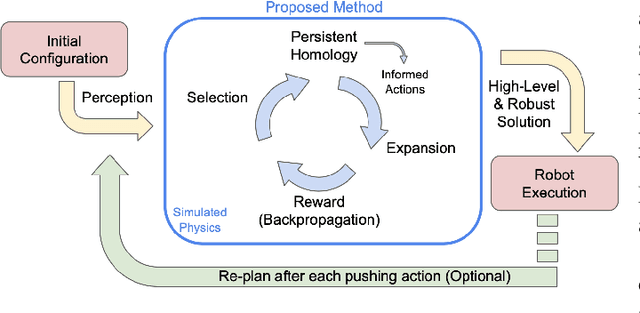
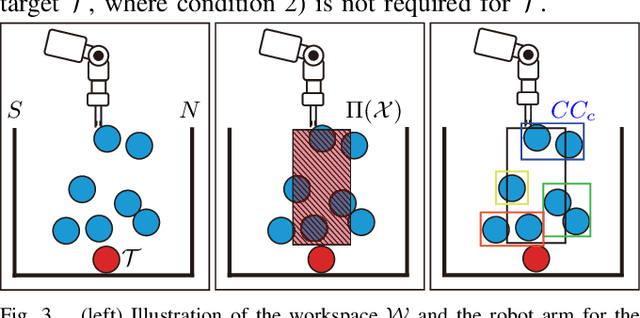

Performing object retrieval tasks in messy real-world workspaces involves the challenges of \emph{uncertainty} and \emph{clutter}. One option is to solve retrieval problems via a sequence of prehensile pick-n-place operations, which can be computationally expensive to compute in highly-cluttered scenarios and also inefficient to execute. The proposed framework selects the option of performing non-prehensile actions, such as pushing, to clean a cluttered workspace to allow a robotic arm to retrieve a target object. Non-prehensile actions, allow to interact simultaneously with multiple objects, which can speed up execution. At the same time, they can significantly increase uncertainty as it is not easy to accurately estimate the outcome of a pushing operation in clutter. The proposed framework integrates topological tools and Monte-Carlo tree search to achieve effective and robust pushing for object retrieval problems. In particular, it proposes using persistent homology to automatically identify manageable clustering of blocking objects in the workspace without the need for manually adjusting hyper-parameters. Furthermore, MCTS uses this information to explore feasible actions to push groups of objects together, aiming to minimize the number of pushing actions needed to clear the path to the target object. Real-world experiments using a Baxter robot, which involves some noise in actuation, show that the proposed framework achieves a higher success rate in solving retrieval tasks in dense clutter compared to state-of-the-art alternatives. Moreover, it produces high-quality solutions with a small number of pushing actions improving the overall execution time. More critically, it is robust enough that it allows to plan the sequence of actions offline and then execute them reliably online with Baxter.
A Survey of Computer Vision Technologies In Urban and Controlled-environment Agriculture
Oct 20, 2022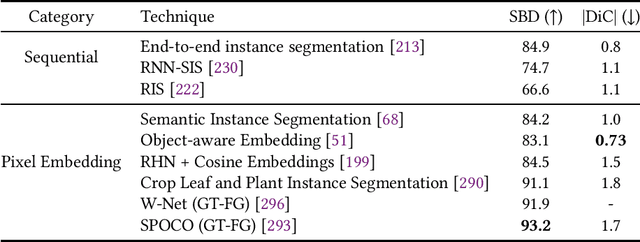
In the evolution of agriculture to its next stage, Agriculture 5.0, artificial intelligence will play a central role. Controlled-environment agriculture, or CEA, is a special form of urban and suburban agricultural practice that offers numerous economic, environmental, and social benefits, including shorter transportation routes to population centers, reduced environmental impact, and increased productivity. Due to its ability to control environmental factors, CEA couples well with computer vision (CV) in the adoption of real-time monitoring of the plant conditions and autonomous cultivation and harvesting. The objective of this paper is to familiarize CV researchers with agricultural applications and agricultural practitioners with the solutions offered by CV. We identify five major CV applications in CEA, analyze their requirements and motivation, and survey the state of the art as reflected in 68 technical papers using deep learning methods. In addition, we discuss five key subareas of computer vision and how they related to these CEA problems, as well as nine vision-based CEA datasets. We hope the survey will help researchers quickly gain a bird-eye view of the striving research area and will spark inspiration for new research and development.