 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
STDAN: Deformable Attention Network for Space-Time Video Super-Resolution
Mar 14, 2022

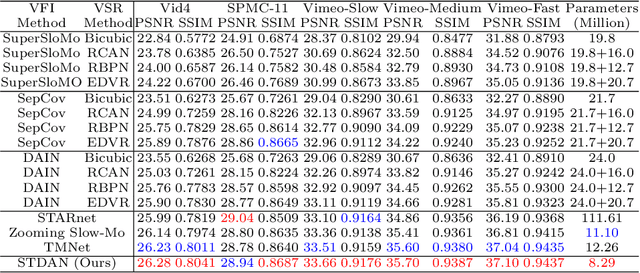
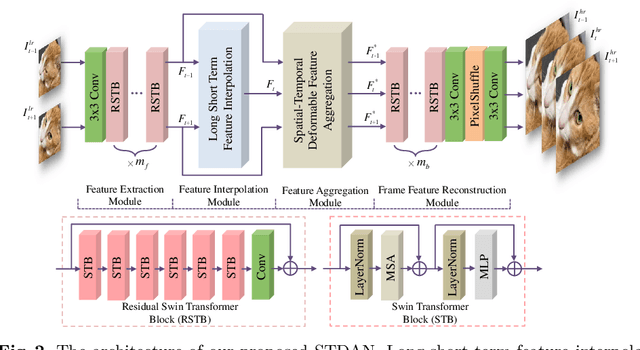
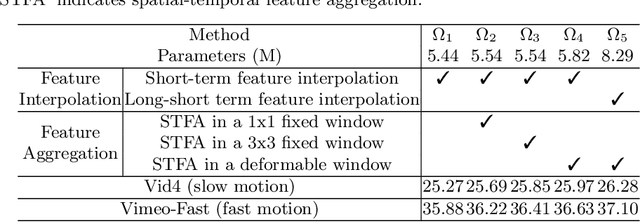
The target of space-time video super-resolution (STVSR) is to increase the spatial-temporal resolution of low-resolution (LR) and low frame rate (LFR) videos. Recent approaches based on deep learning have made significant improvements, but most of them only use two adjacent frames, that is, short-term features, to synthesize the missing frame embedding, which suffers from fully exploring the information flow of consecutive input LR frames. In addition, existing STVSR models hardly exploit the temporal contexts explicitly to assist high-resolution (HR) frame reconstruction. To address these issues, in this paper, we propose a deformable attention network called STDAN for STVSR. First, we devise a long-short term feature interpolation (LSTFI) module, which is capable of excavating abundant content from more neighboring input frames for the interpolation process through a bidirectional RNN structure. Second, we put forward a spatial-temporal deformable feature aggregation (STDFA) module, in which spatial and temporal contexts in dynamic video frames are adaptively captured and aggregated to enhance SR reconstruction. Experimental results on several datasets demonstrate that our approach outperforms state-of-the-art STVSR methods.
Micro-Vibration Modes Reconstruction Based on Micro-Doppler Coincidence Imaging
Aug 30, 2022



Micro-vibration, a ubiquitous nature phenomenon, can be seen as a characteristic feature on the objects, these vibrations always have tiny amplitudes which are much less than the wavelengths of the sensing systems, thus these motions information can only be reflected in the phase item of echo. Normally the conventional radar system can detect these micro vibrations through the time frequency analyzing, but these vibration characteristics can only be reflected by time-frequency spectrum, the spatial distribution of these micro vibrations can not be reconstructed precisely. Ghost imaging (GI), a novel imaging method also known as Coincidence Imaging that originated in the quantum and optical fields, can reconstruct unknown images using computational methods. To reconstruct the spatial distribution of micro vibrations, this paper proposes a new method based on a coincidence imaging system. A detailed model of target micro-vibration is created first, taking into account two categories: discrete and continuous targets. We use the first-order field correlation feature to obtain objective different micro vibration distribution based on the complex target models and time-frequency analysis in this work.
Scale-Aware Neural Architecture Search for Multivariate Time Series Forecasting
Dec 14, 2021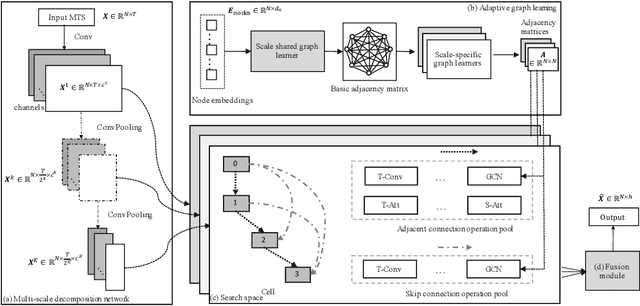
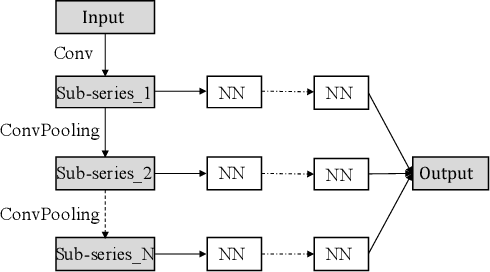
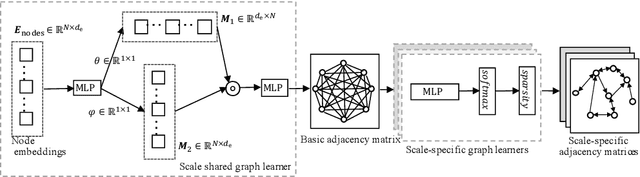
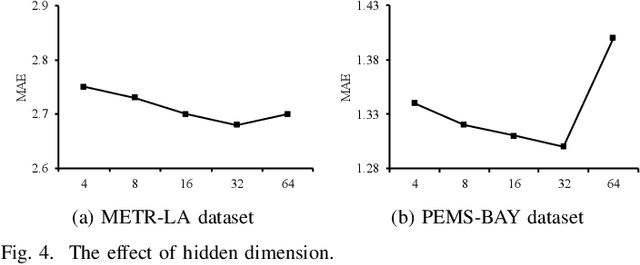
Multivariate time series (MTS) forecasting has attracted much attention in many intelligent applications. It is not a trivial task, as we need to consider both intra-variable dependencies and inter-variable dependencies. However, existing works are designed for specific scenarios, and require much domain knowledge and expert efforts, which is difficult to transfer between different scenarios. In this paper, we propose a scale-aware neural architecture search framework for MTS forecasting (SNAS4MTF). A multi-scale decomposition module transforms raw time series into multi-scale sub-series, which can preserve multi-scale temporal patterns. An adaptive graph learning module infers the different inter-variable dependencies under different time scales without any prior knowledge. For MTS forecasting, a search space is designed to capture both intra-variable dependencies and inter-variable dependencies at each time scale. The multi-scale decomposition, adaptive graph learning, and neural architecture search modules are jointly learned in an end-to-end framework. Extensive experiments on two real-world datasets demonstrate that SNAS4MTF achieves a promising performance compared with the state-of-the-art methods.
Look Ma, Only 400 Samples! Revisiting the Effectiveness of Automatic N-Gram Rule Generation for Spelling Normalization in Filipino
Oct 06, 2022
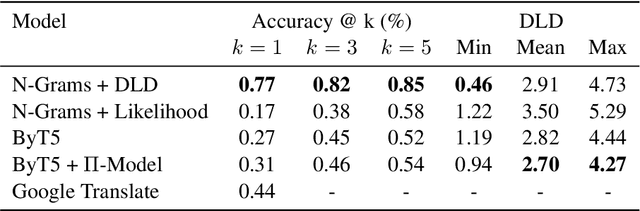
With 84.75 million Filipinos online, the ability for models to process online text is crucial for developing Filipino NLP applications. To this end, spelling correction is a crucial preprocessing step for downstream processing. However, the lack of data prevents the use of language models for this task. In this paper, we propose an N-Gram + Damerau Levenshtein distance model with automatic rule extraction. We train the model on 300 samples, and show that despite limited training data, it achieves good performance and outperforms other deep learning approaches in terms of accuracy and edit distance. Moreover, the model (1) requires little compute power, (2) trains in little time, thus allowing for retraining, and (3) is easily interpretable, allowing for direct troubleshooting, highlighting the success of traditional approaches over more complex deep learning models in settings where data is unavailable.
AdaInt: Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement
Apr 29, 2022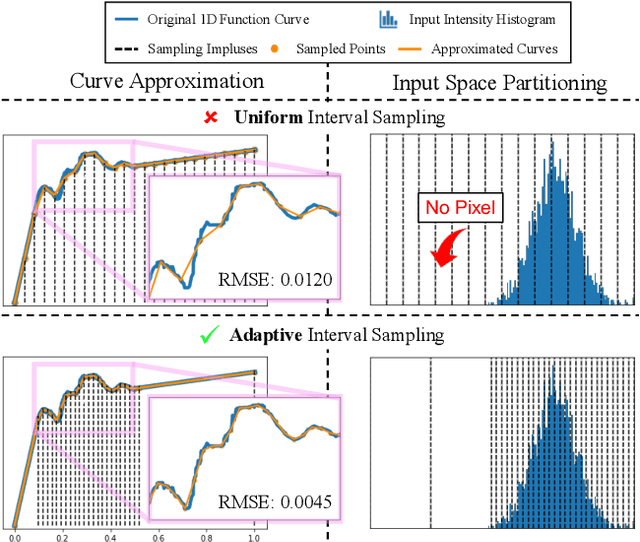

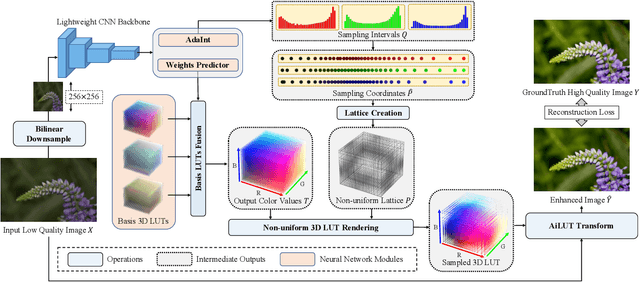
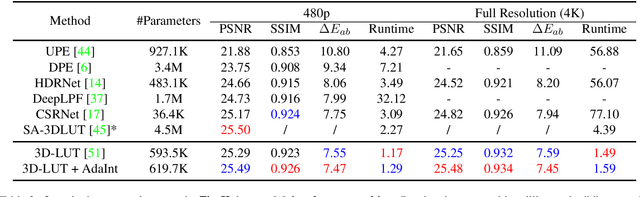
The 3D Lookup Table (3D LUT) is a highly-efficient tool for real-time image enhancement tasks, which models a non-linear 3D color transform by sparsely sampling it into a discretized 3D lattice. Previous works have made efforts to learn image-adaptive output color values of LUTs for flexible enhancement but neglect the importance of sampling strategy. They adopt a sub-optimal uniform sampling point allocation, limiting the expressiveness of the learned LUTs since the (tri-)linear interpolation between uniform sampling points in the LUT transform might fail to model local non-linearities of the color transform. Focusing on this problem, we present AdaInt (Adaptive Intervals Learning), a novel mechanism to achieve a more flexible sampling point allocation by adaptively learning the non-uniform sampling intervals in the 3D color space. In this way, a 3D LUT can increase its capability by conducting dense sampling in color ranges requiring highly non-linear transforms and sparse sampling for near-linear transforms. The proposed AdaInt could be implemented as a compact and efficient plug-and-play module for a 3D LUT-based method. To enable the end-to-end learning of AdaInt, we design a novel differentiable operator called AiLUT-Transform (Adaptive Interval LUT Transform) to locate input colors in the non-uniform 3D LUT and provide gradients to the sampling intervals. Experiments demonstrate that methods equipped with AdaInt can achieve state-of-the-art performance on two public benchmark datasets with a negligible overhead increase. Our source code is available at https://github.com/ImCharlesY/AdaInt.
Calibration and Uncertainty Characterization for Ultra-Wideband Two-Way-Ranging Measurements
Oct 12, 2022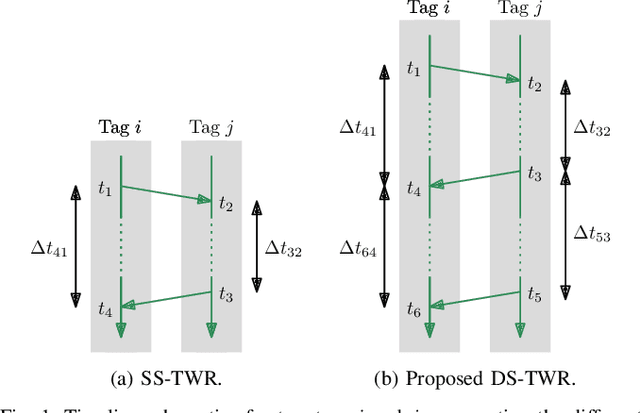

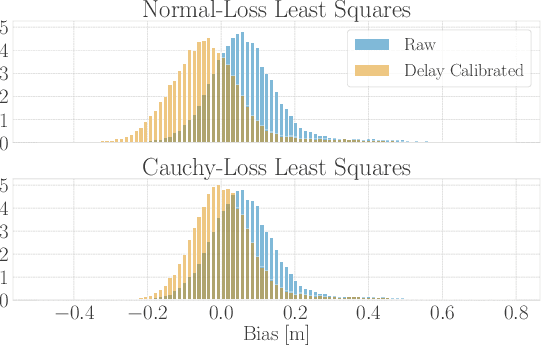
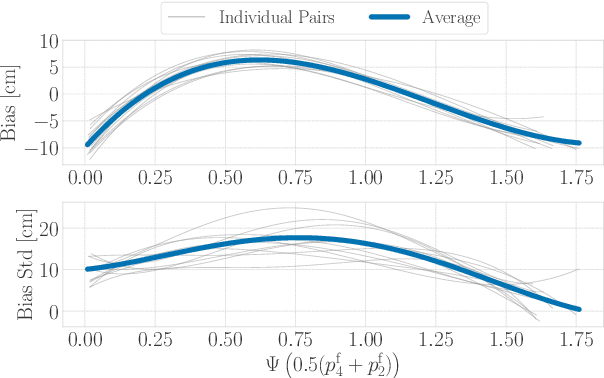
Ultra-Wideband (UWB) systems are becoming increasingly popular for indoor localization, where range measurements are obtained by measuring the time-of-flight of radio signals. However, the range measurements typically suffer from a systematic error or bias that must be corrected for high-accuracy localization. In this paper, a ranging protocol is proposed alongside a robust and scalable antenna-delay calibration procedure to accurately and efficiently calibrate antenna delays for many UWB tags. Additionally, the bias and uncertainty of the measurements are modelled as a function of the received-signal power. The full calibration procedure is presented using experimental training data of 3 aerial robots fitted with 2 UWB tags each, and then evaluated on 2 test experiments. A localization problem is then formulated on the experimental test data, and the calibrated measurements and their modelled uncertainty are fed into an extended Kalman filter (EKF). The proposed calibration is shown to yield an average of 46% improvement in localization accuracy. Lastly, the paper is accompanied by an open-source UWB-calibration Python library, which can be found at https://github.com/decarsg/uwb_calibration.
Self-supervised video pretraining yields strong image representations
Oct 12, 2022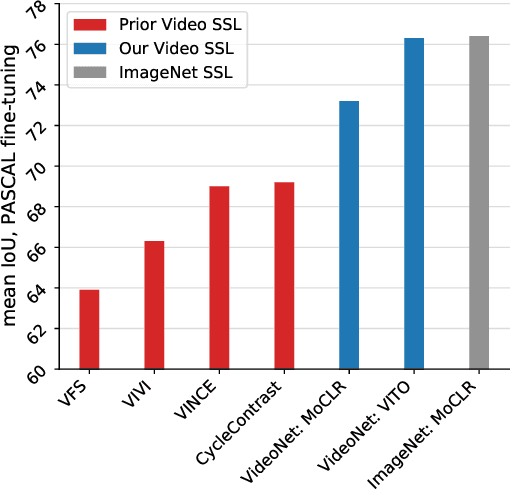
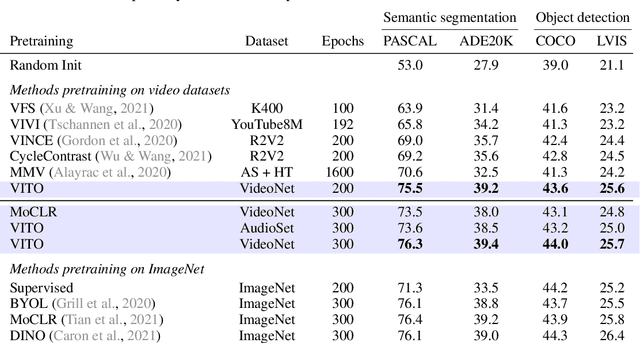
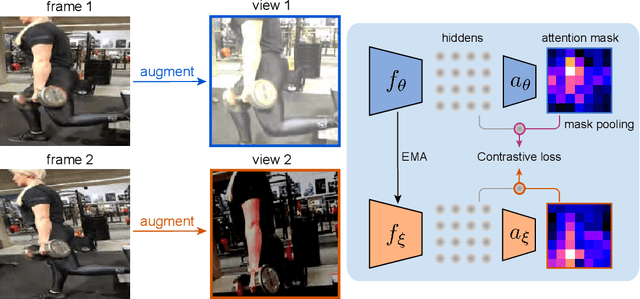
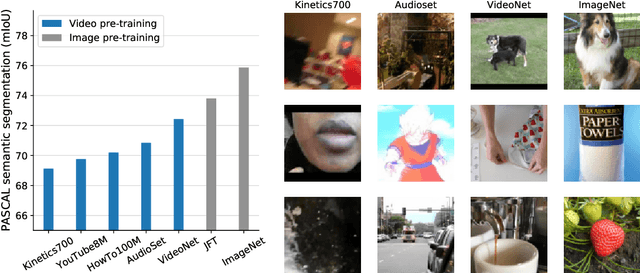
Videos contain far more information than still images and hold the potential for learning rich representations of the visual world. Yet, pretraining on image datasets has remained the dominant paradigm for learning representations that capture spatial information, and previous attempts at video pretraining have fallen short on image understanding tasks. In this work we revisit self-supervised learning of image representations from the dynamic evolution of video frames. To that end, we propose a dataset curation procedure that addresses the domain mismatch between video and image datasets, and develop a contrastive learning framework which handles the complex transformations present in natural videos. This simple paradigm for distilling knowledge from videos to image representations, called VITO, performs surprisingly well on a variety of image-based transfer learning tasks. For the first time, our video-pretrained model closes the gap with ImageNet pretraining on semantic segmentation on PASCAL and ADE20K and object detection on COCO and LVIS, suggesting that video-pretraining could become the new default for learning image representations.
TriangleNet: Edge Prior Augmented Network for Semantic Segmentation through Cross-Task Consistency
Oct 12, 2022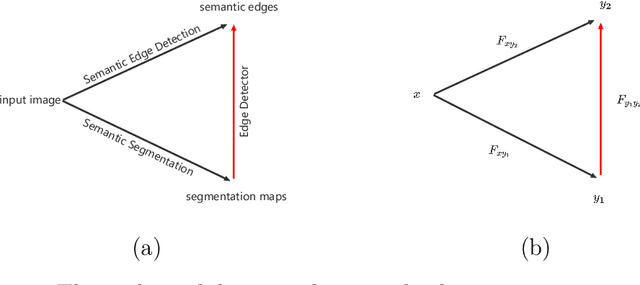

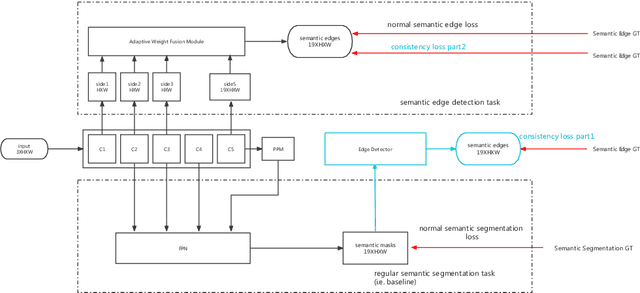
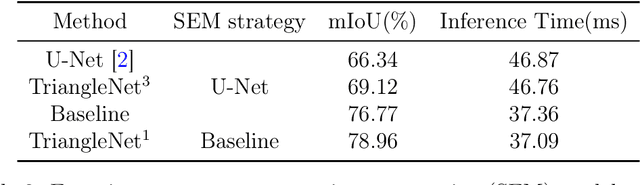
Semantic segmentation is a classic computer vision problem dedicated to labeling each pixel with its corresponding category. As a basic task for advanced tasks such as industrial quality inspection, remote sensing information extraction, medical diagnostic aid, and autonomous driving, semantic segmentation has been developed for a long time in combination with deep learning, and a lot of works have been accumulated. However, neither the classic FCN-based works nor the popular Transformer-based works have attained fine-grained localization of pixel labels, which remains the main challenge in this field. Recently, with the popularity of autonomous driving, the segmentation of road scenes has received more and more attention. Based on the cross-task consistency theory, we incorporate edge priors into semantic segmentation tasks to obtain better results. The main contribution is that we provide a model-agnostic method that improves the accuracy of semantic segmentation models with zero extra inference runtime overhead, verified on the datasets of road and non-road scenes. From our experimental results, our method can effectively improve semantic segmentation accuracy.
OpenCQA: Open-ended Question Answering with Charts
Oct 12, 2022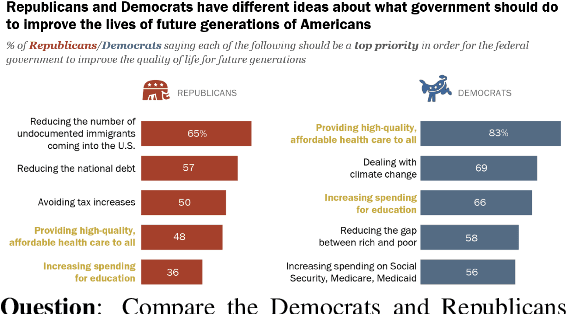

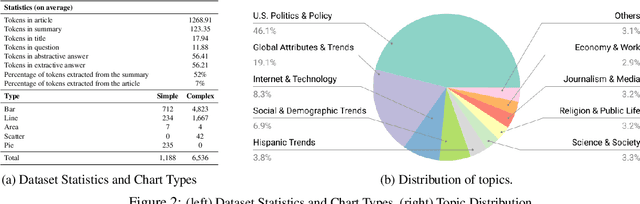
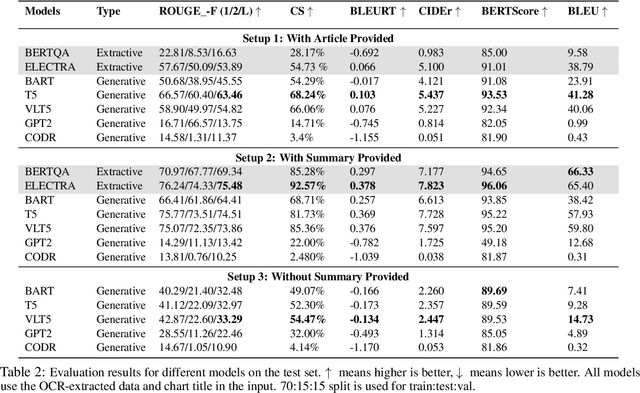
Charts are very popular to analyze data and convey important insights. People often analyze visualizations to answer open-ended questions that require explanatory answers. Answering such questions are often difficult and time-consuming as it requires a lot of cognitive and perceptual efforts. To address this challenge, we introduce a new task called OpenCQA, where the goal is to answer an open-ended question about a chart with descriptive texts. We present the annotation process and an in-depth analysis of our dataset. We implement and evaluate a set of baselines under three practical settings. In the first setting, a chart and the accompanying article is provided as input to the model. The second setting provides only the relevant paragraph(s) to the chart instead of the entire article, whereas the third setting requires the model to generate an answer solely based on the chart. Our analysis of the results show that the top performing models generally produce fluent and coherent text while they struggle to perform complex logical and arithmetic reasoning.
Near-Optimal Multi-Agent Learning for Safe Coverage Control
Oct 12, 2022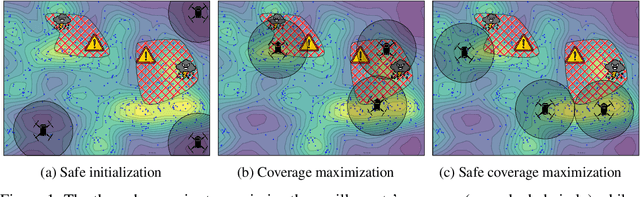
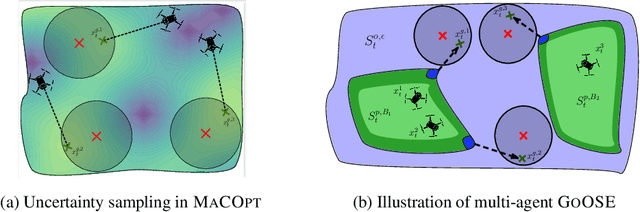
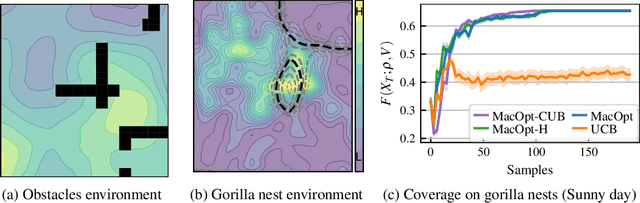
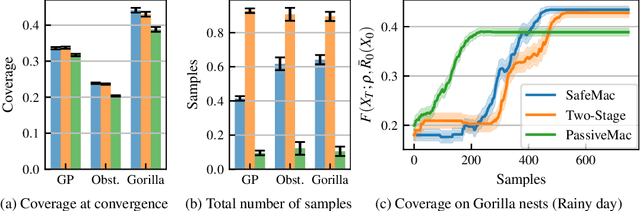
In multi-agent coverage control problems, agents navigate their environment to reach locations that maximize the coverage of some density. In practice, the density is rarely known $\textit{a priori}$, further complicating the original NP-hard problem. Moreover, in many applications, agents cannot visit arbitrary locations due to $\textit{a priori}$ unknown safety constraints. In this paper, we aim to efficiently learn the density to approximately solve the coverage problem while preserving the agents' safety. We first propose a conditionally linear submodular coverage function that facilitates theoretical analysis. Utilizing this structure, we develop MacOpt, a novel algorithm that efficiently trades off the exploration-exploitation dilemma due to partial observability, and show that it achieves sublinear regret. Next, we extend results on single-agent safe exploration to our multi-agent setting and propose SafeMac for safe coverage and exploration. We analyze SafeMac and give first of its kind results: near optimal coverage in finite time while provably guaranteeing safety. We extensively evaluate our algorithms on synthetic and real problems, including a bio-diversity monitoring task under safety constraints, where SafeMac outperforms competing methods.