 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Covariance Recovery for One-Bit Sampled Data With Time-Varying Sampling Thresholds-Part II: Non-Stationary Signals
Mar 16, 2022
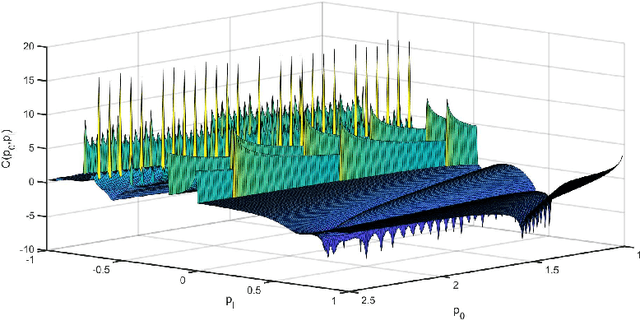
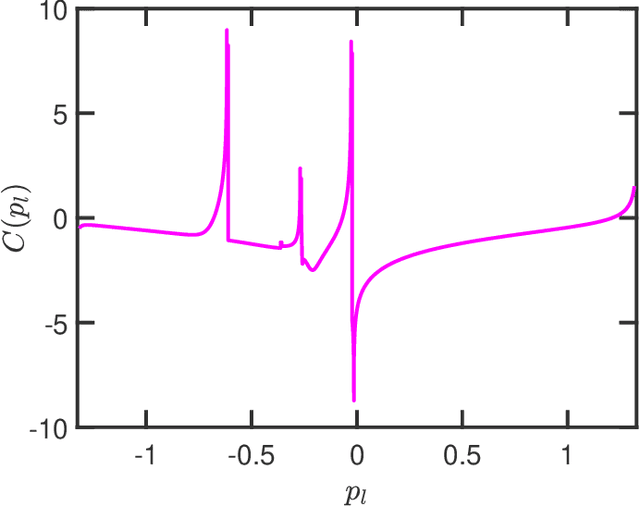
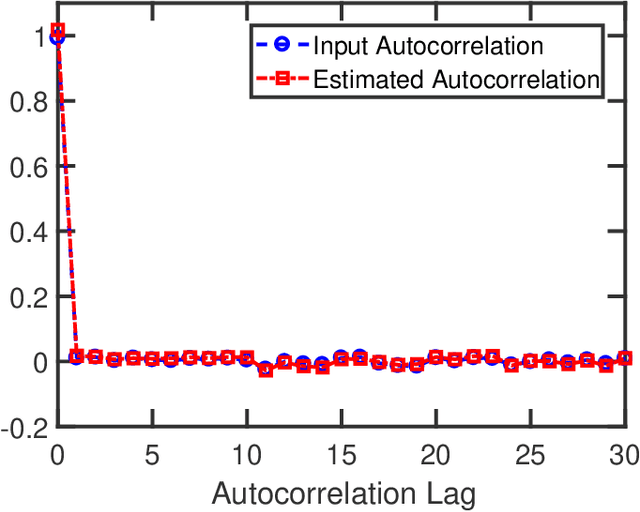
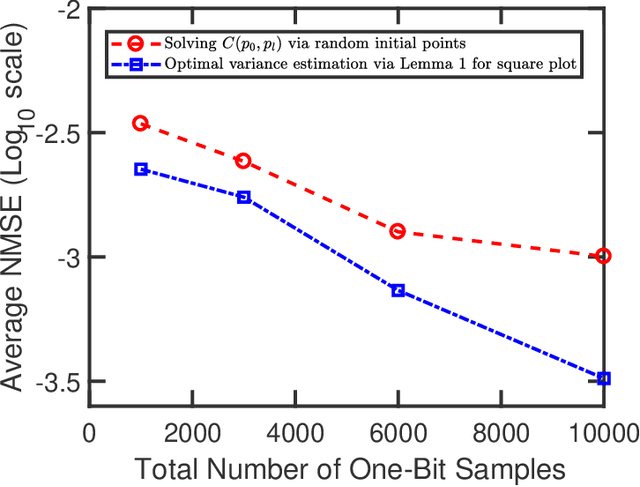
The recovery of the input signal covariance values from its one-bit sampled counterpart has been deemed a challenging task in the literature. To deal with its difficulties, some assumptions are typically made to find a relation between the input covariance matrix and the autocorrelation values of the one-bit sampled data. This includes the arcsine law and the modified arcsine law that were discussed in Part I of this work [2]. We showed that by facilitating the deployment of time-varying thresholds, the modified arcsine law has a promising performance in covariance recovery. However, the modified arcsine law also assumes input signals are stationary, which is typically a simplifying assumption for real-world applications. In fact, in many signal processing applications, the input signals are readily known to be non-stationary with a non-Toeplitz covariance matrix. In this paper, we propose an approach to extending the arcsine law to the case where one-bit ADCs apply time-varying thresholds while dealing with input signals that originate from a non-stationary process. In particular, the recovery methods are shown to accurately recover the time-varying variance and autocorrelation values. Furthermore, we extend the formulation of the Bussgang law to the case where non-stationary input signals are considered.
A review of probabilistic forecasting and prediction with machine learning
Sep 17, 2022
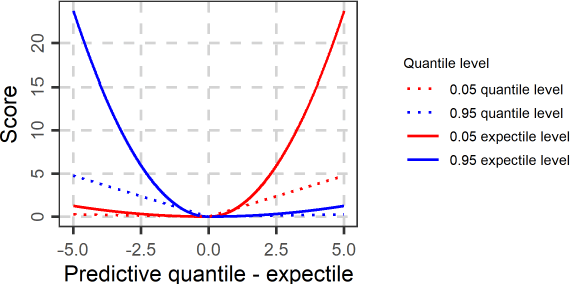
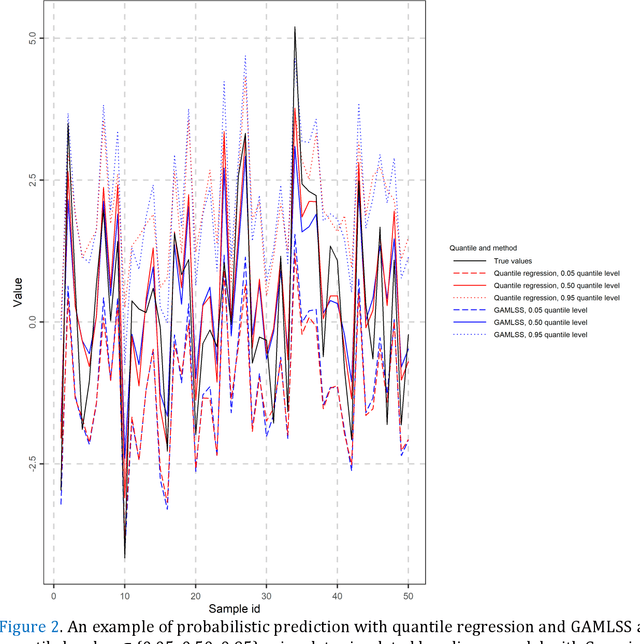
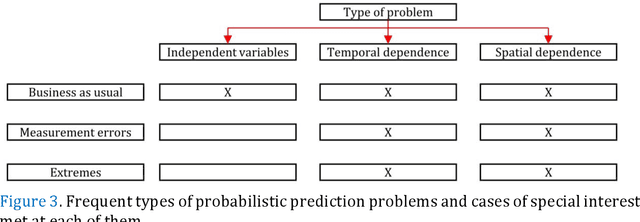
Predictions and forecasts of machine learning models should take the form of probability distributions, aiming to increase the quantity of information communicated to end users. Although applications of probabilistic prediction and forecasting with machine learning models in academia and industry are becoming more frequent, related concepts and methods have not been formalized and structured under a holistic view of the entire field. Here, we review the topic of predictive uncertainty estimation with machine learning algorithms, as well as the related metrics (consistent scoring functions and proper scoring rules) for assessing probabilistic predictions. The review covers a time period spanning from the introduction of early statistical (linear regression and time series models, based on Bayesian statistics or quantile regression) to recent machine learning algorithms (including generalized additive models for location, scale and shape, random forests, boosting and deep learning algorithms) that are more flexible by nature. The review of the progress in the field, expedites our understanding on how to develop new algorithms tailored to users' needs, since the latest advancements are based on some fundamental concepts applied to more complex algorithms. We conclude by classifying the material and discussing challenges that are becoming a hot topic of research.
Fully Proprioceptive Slip-Velocity-Aware State Estimation for Mobile Robots via Invariant Kalman Filtering and Disturbance Observer
Sep 29, 2022
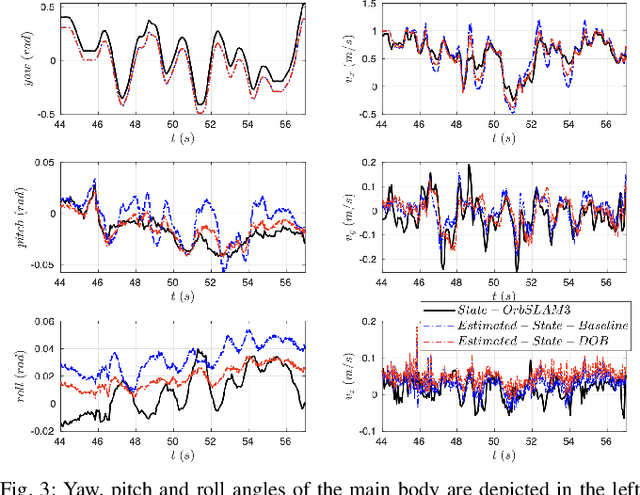
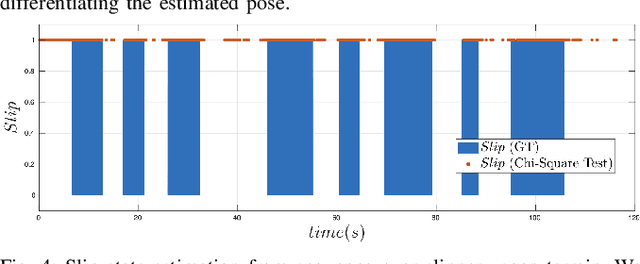

This paper develops a novel slip estimator using the invariant observer design theory and Disturbance Observer (DOB). The proposed state estimator for mobile robots is fully proprioceptive and combines data from an inertial measurement unit and body velocity within a Right Invariant Extended Kalman Filter (RI-EKF). By embedding the slip velocity into $\mathrm{SE}_3(3)$ Lie group, the developed DOB-based RI-EKF provides real-time accurate velocity and slip velocity estimates on different terrains. Experimental results using a Husky wheeled robot confirm the mathematical derivations and show better performance than a standard RI-EKF baseline. Open source software is available for download and reproducing the presented results.
A Double Machine Learning Trend Model for Citizen Science Data
Oct 27, 2022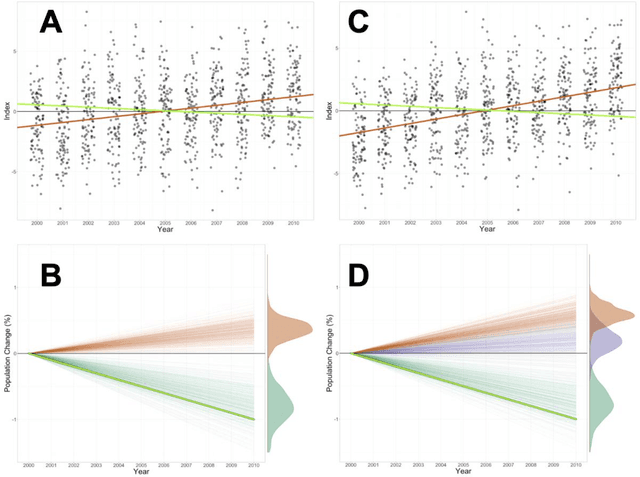
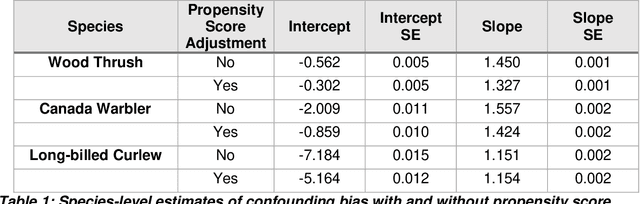
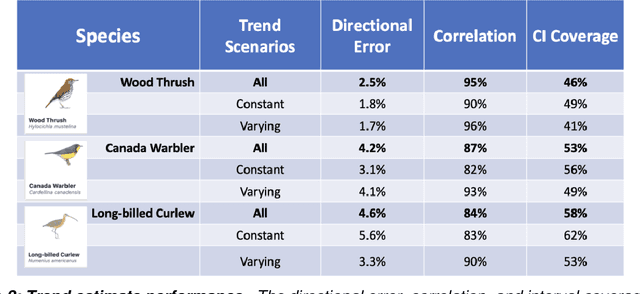
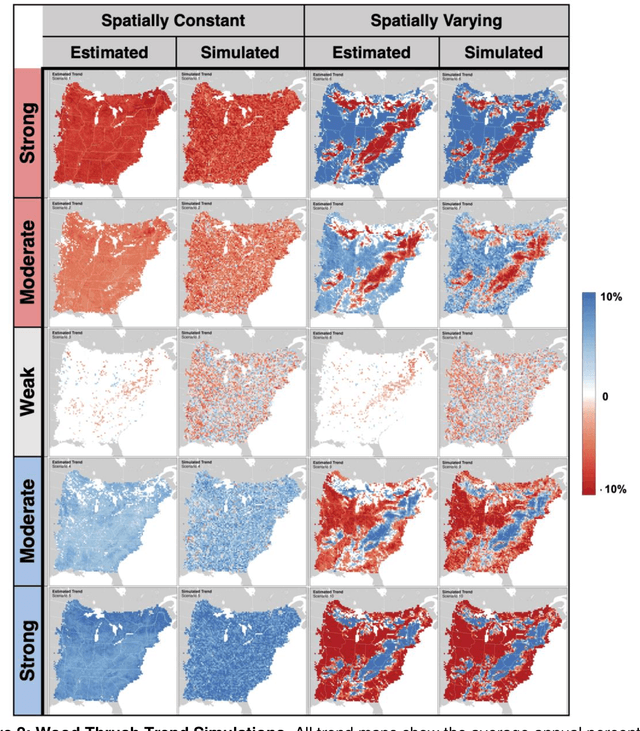
1. Citizen and community-science (CS) datasets have great potential for estimating interannual patterns of population change given the large volumes of data collected globally every year. Yet, the flexible protocols that enable many CS projects to collect large volumes of data typically lack the structure necessary to keep consistent sampling across years. This leads to interannual confounding, as changes to the observation process over time are confounded with changes in species population sizes. 2. Here we describe a novel modeling approach designed to estimate species population trends while controlling for the interannual confounding common in citizen science data. The approach is based on Double Machine Learning, a statistical framework that uses machine learning methods to estimate population change and the propensity scores used to adjust for confounding discovered in the data. Additionally, we develop a simulation method to identify and adjust for residual confounding missed by the propensity scores. Using this new method, we can produce spatially detailed trend estimates from citizen science data. 3. To illustrate the approach, we estimated species trends using data from the CS project eBird. We used a simulation study to assess the ability of the method to estimate spatially varying trends in the face of real-world confounding. Results showed that the trend estimates distinguished between spatially constant and spatially varying trends at a 27km resolution. There were low error rates on the estimated direction of population change (increasing/decreasing) and high correlations on the estimated magnitude. 4. The ability to estimate spatially explicit trends while accounting for confounding in citizen science data has the potential to fill important information gaps, helping to estimate population trends for species, regions, or seasons without rigorous monitoring data.
Student-centric Model of Learning Management System Activity and Academic Performance: from Correlation to Causation
Oct 27, 2022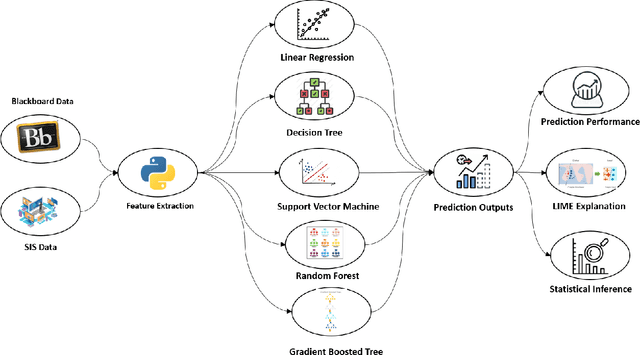
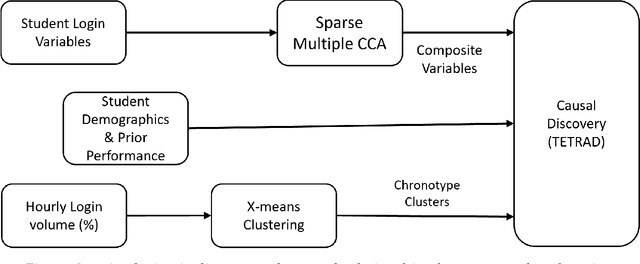
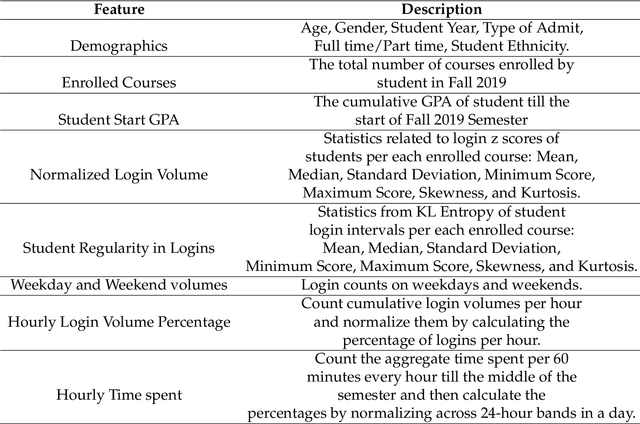
In recent years, there is a lot of interest in modeling students' digital traces in Learning Management System (LMS) to understand students' learning behavior patterns including aspects of meta-cognition and self-regulation, with the ultimate goal to turn those insights into actionable information to support students to improve their learning outcomes. In achieving this goal, however, there are two main issues that need to be addressed given the existing literature. Firstly, most of the current work is course-centered (i.e. models are built from data for a specific course) rather than student-centered; secondly, a vast majority of the models are correlational rather than causal. Those issues make it challenging to identify the most promising actionable factors for intervention at the student level where most of the campus-wide academic support is designed for. In this paper, we explored a student-centric analytical framework for LMS activity data that can provide not only correlational but causal insights mined from observational data. We demonstrated this approach using a dataset of 1651 computing major students at a public university in the US during one semester in the Fall of 2019. This dataset includes students' fine-grained LMS interaction logs and administrative data, e.g. demographics and academic performance. In addition, we expand the repository of LMS behavior indicators to include those that can characterize the time-of-the-day of login (e.g. chronotype). Our analysis showed that student login volume, compared with other login behavior indicators, is both strongly correlated and causally linked to student academic performance, especially among students with low academic performance. We envision that those insights will provide convincing evidence for college student support groups to launch student-centered and targeted interventions that are effective and scalable.
Learning Location from Shared Elevation Profiles in Fitness Apps: A Privacy Perspective
Oct 27, 2022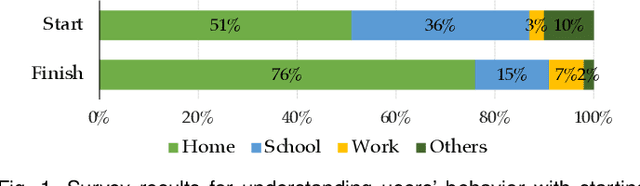
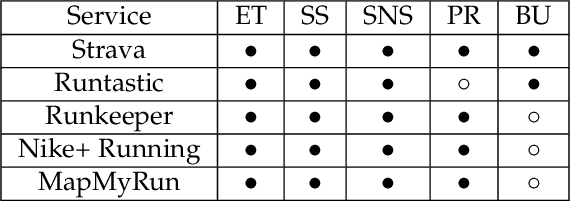
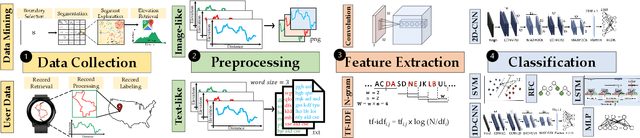
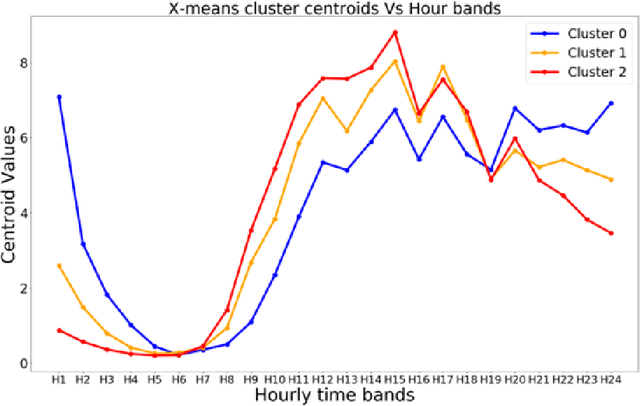
The extensive use of smartphones and wearable devices has facilitated many useful applications. For example, with Global Positioning System (GPS)-equipped smart and wearable devices, many applications can gather, process, and share rich metadata, such as geolocation, trajectories, elevation, and time. For example, fitness applications, such as Runkeeper and Strava, utilize the information for activity tracking and have recently witnessed a boom in popularity. Those fitness tracker applications have their own web platforms and allow users to share activities on such platforms or even with other social network platforms. To preserve the privacy of users while allowing sharing, several of those platforms may allow users to disclose partial information, such as the elevation profile for an activity, which supposedly would not leak the location of the users. In this work, and as a cautionary tale, we create a proof of concept where we examine the extent to which elevation profiles can be used to predict the location of users. To tackle this problem, we devise three plausible threat settings under which the city or borough of the targets can be predicted. Those threat settings define the amount of information available to the adversary to launch the prediction attacks. Establishing that simple features of elevation profiles, e.g., spectral features, are insufficient, we devise both natural language processing (NLP)-inspired text-like representation and computer vision-inspired image-like representation of elevation profiles, and we convert the problem at hand into text and image classification problem. We use both traditional machine learning- and deep learning-based techniques and achieve a prediction success rate ranging from 59.59\% to 99.80\%. The findings are alarming, highlighting that sharing elevation information may have significant location privacy risks.
Breaking the Convergence Barrier: Optimization via Fixed-Time Convergent Flows
Dec 02, 2021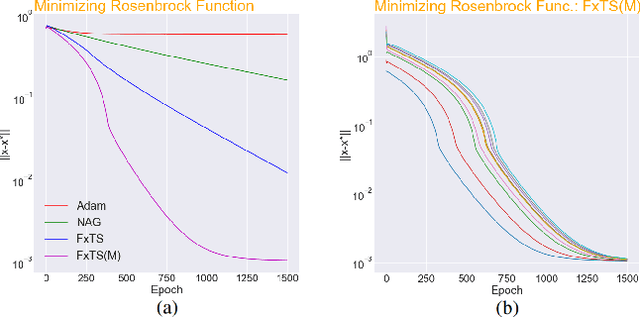
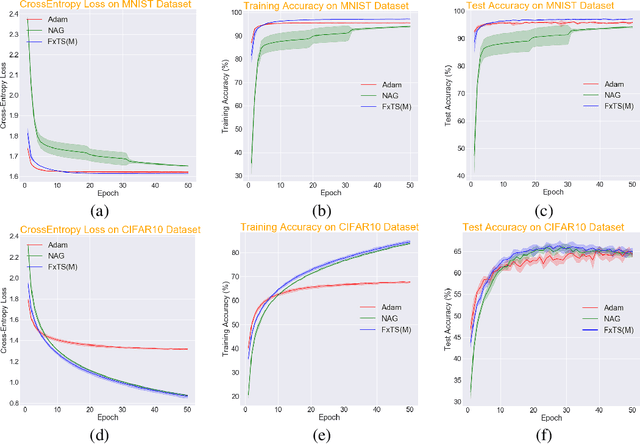
Accelerated gradient methods are the cornerstones of large-scale, data-driven optimization problems that arise naturally in machine learning and other fields concerning data analysis. We introduce a gradient-based optimization framework for achieving acceleration, based on the recently introduced notion of fixed-time stability of dynamical systems. The method presents itself as a generalization of simple gradient-based methods suitably scaled to achieve convergence to the optimizer in a fixed-time, independent of the initialization. We achieve this by first leveraging a continuous-time framework for designing fixed-time stable dynamical systems, and later providing a consistent discretization strategy, such that the equivalent discrete-time algorithm tracks the optimizer in a practically fixed number of iterations. We also provide a theoretical analysis of the convergence behavior of the proposed gradient flows, and their robustness to additive disturbances for a range of functions obeying strong convexity, strict convexity, and possibly nonconvexity but satisfying the Polyak-{\L}ojasiewicz inequality. We also show that the regret bound on the convergence rate is constant by virtue of the fixed-time convergence. The hyperparameters have intuitive interpretations and can be tuned to fit the requirements on the desired convergence rates. We validate the accelerated convergence properties of the proposed schemes on a range of numerical examples against the state-of-the-art optimization algorithms. Our work provides insights on developing novel optimization algorithms via discretization of continuous-time flows.
Out-of-Vocabulary Challenge Report
Sep 14, 2022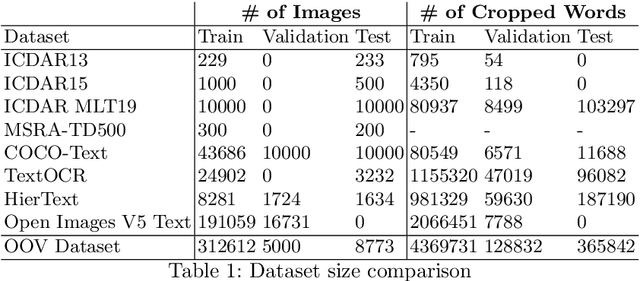
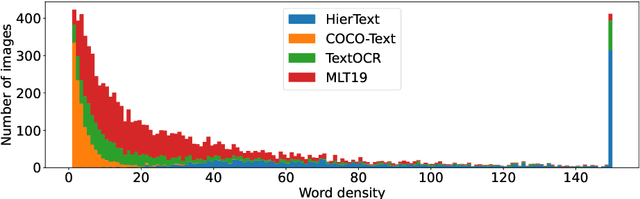

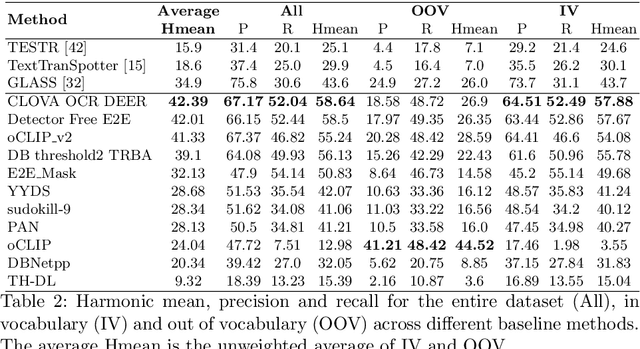
This paper presents final results of the Out-Of-Vocabulary 2022 (OOV) challenge. The OOV contest introduces an important aspect that is not commonly studied by Optical Character Recognition (OCR) models, namely, the recognition of unseen scene text instances at training time. The competition compiles a collection of public scene text datasets comprising of 326,385 images with 4,864,405 scene text instances, thus covering a wide range of data distributions. A new and independent validation and test set is formed with scene text instances that are out of vocabulary at training time. The competition was structured in two tasks, end-to-end and cropped scene text recognition respectively. A thorough analysis of results from baselines and different participants is presented. Interestingly, current state-of-the-art models show a significant performance gap under the newly studied setting. We conclude that the OOV dataset proposed in this challenge will be an essential area to be explored in order to develop scene text models that achieve more robust and generalized predictions.
Bayesian Regression Approach for Building and Stacking Predictive Models in Time Series Analytics
Jan 06, 2022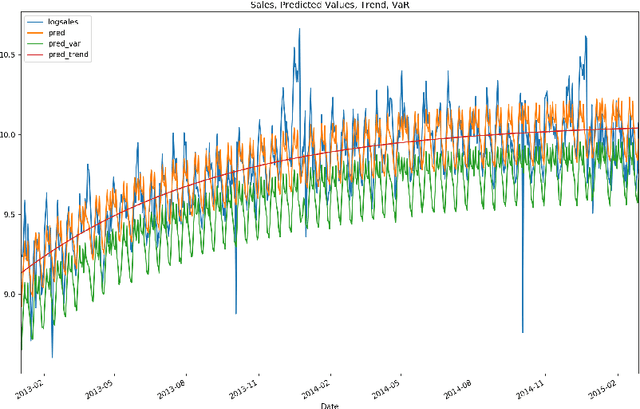
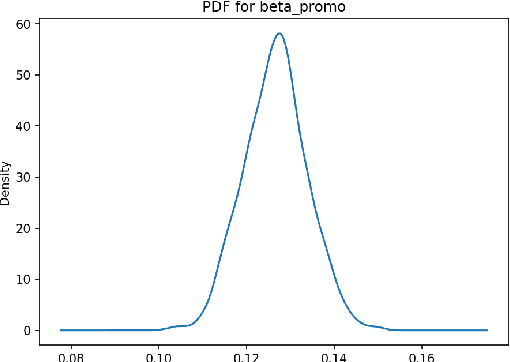
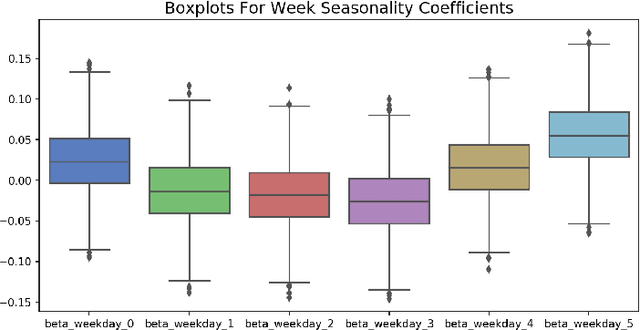
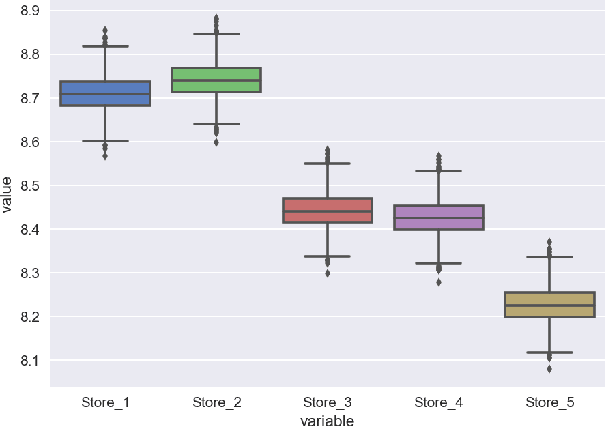
The paper describes the use of Bayesian regression for building time series models and stacking different predictive models for time series. Using Bayesian regression for time series modeling with nonlinear trend was analyzed. This approach makes it possible to estimate an uncertainty of time series prediction and calculate value at risk characteristics. A hierarchical model for time series using Bayesian regression has been considered. In this approach, one set of parameters is the same for all data samples, other parameters can be different for different groups of data samples. Such an approach allows using this model in the case of short historical data for specified time series, e.g. in the case of new stores or new products in the sales prediction problem. In the study of predictive models stacking, the models ARIMA, Neural Network, Random Forest, Extra Tree were used for the prediction on the first level of model ensemble. On the second level, time series predictions of these models on the validation set were used for stacking by Bayesian regression. This approach gives distributions for regression coefficients of these models. It makes it possible to estimate the uncertainty contributed by each model to stacking result. The information about these distributions allows us to select an optimal set of stacking models, taking into account the domain knowledge. The probabilistic approach for stacking predictive models allows us to make risk assessment for the predictions that are important in a decision-making process.
Leap-frog neural network for learning the symplectic evolution from partitioned data
Aug 30, 2022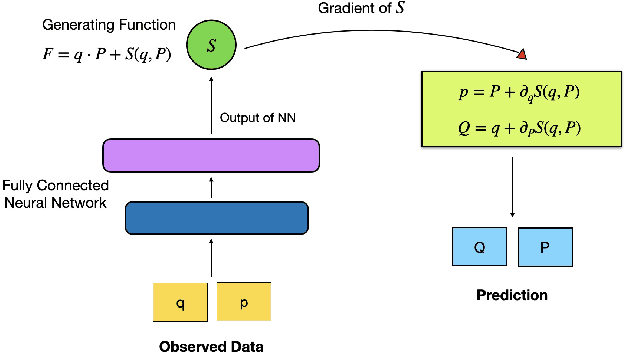

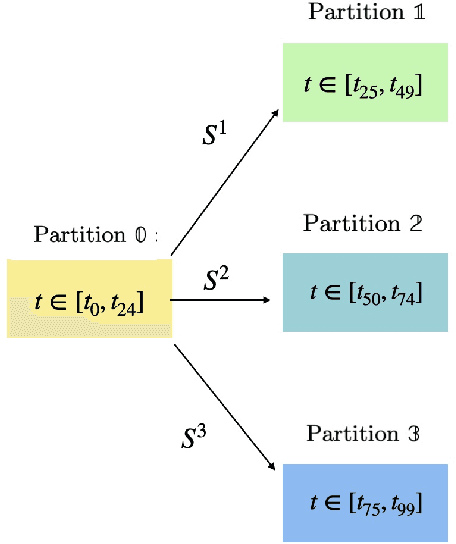
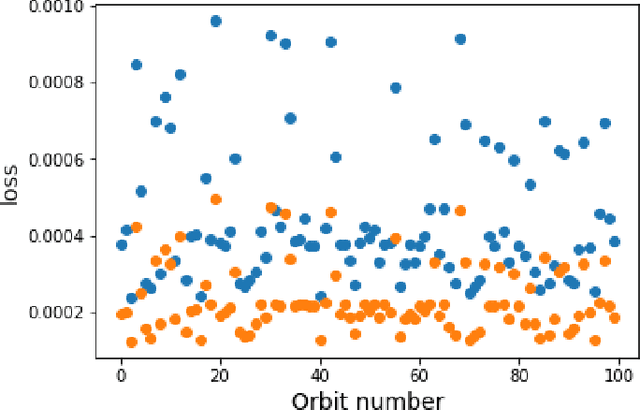
For the Hamiltonian system, this work considers the learning and prediction of the position (q) and momentum (p) variables generated by a symplectic evolution map. Similar to Chen & Tao (2021), the symplectic map is represented by the generating function. In addition, we develop a new learning scheme by splitting the time series (q_i, p_i) into several partitions, and then train a leap-frog neural network (LFNN) to approximate the generating function between the first (i.e. initial condition) and one of the rest partitions. For predicting the system evolution in a short timescale, the LFNN could effectively avoid the issue of accumulative error. Then the LFNN is applied to learn the behavior of the 2:3 resonant Kuiper belt objects, in a much longer time period, and there are two significant improvements on the neural network constructed in our previous work (Li et al. 2022): (1) conservation of the Jacobi integral ; (2) highly accurate prediction of the orbital evolution. We propose that the LFNN may be useful to make the prediction of the long time evolution of the Hamiltonian system.