 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GAPX: Generalized Autoregressive Paraphrase-Identification X
Oct 05, 2022

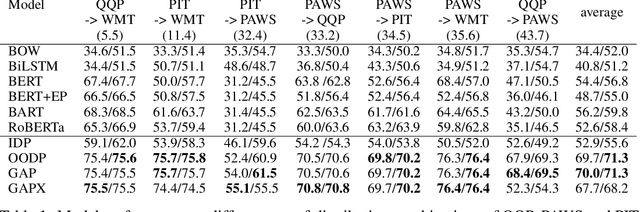
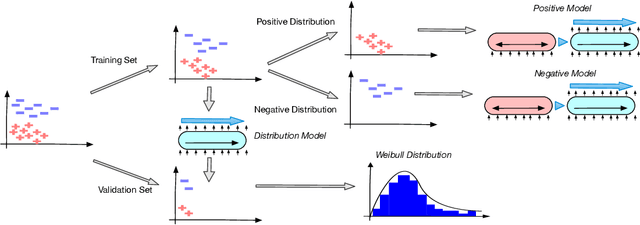
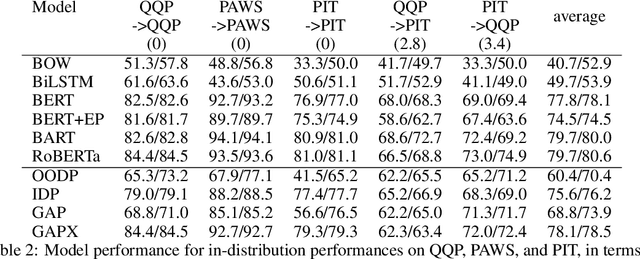
Paraphrase Identification is a fundamental task in Natural Language Processing. While much progress has been made in the field, the performance of many state-of-the-art models often suffer from distribution shift during inference time. We verify that a major source of this performance drop comes from biases introduced by negative examples. To overcome these biases, we propose in this paper to train two separate models, one that only utilizes the positive pairs and the other the negative pairs. This enables us the option of deciding how much to utilize the negative model, for which we introduce a perplexity based out-of-distribution metric that we show can effectively and automatically determine how much weight it should be given during inference. We support our findings with strong empirical results.
Cell tracking for live-cell microscopy using an activity-prioritized assignment strategy
Oct 20, 2022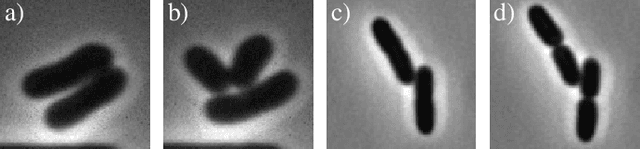


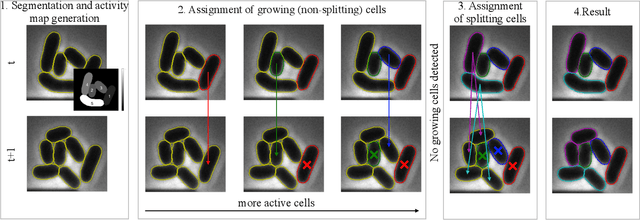
Cell tracking is an essential tool in live-cell imaging to determine single-cell features, such as division patterns or elongation rates. Unlike in common multiple object tracking, in microbial live-cell experiments cells are growing, moving, and dividing over time, to form cell colonies that are densely packed in mono-layer structures. With increasing cell numbers, following the precise cell-cell associations correctly over many generations becomes more and more challenging, due to the massively increasing number of possible associations. To tackle this challenge, we propose a fast parameter-free cell tracking approach, which consists of activity-prioritized nearest neighbor assignment of growing cells and a combinatorial solver that assigns splitting mother cells to their daughters. As input for the tracking, Omnipose is utilized for instance segmentation. Unlike conventional nearest-neighbor-based tracking approaches, the assignment steps of our proposed method are based on a Gaussian activity-based metric, predicting the cell-specific migration probability, thereby limiting the number of erroneous assignments. In addition to being a building block for cell tracking, the proposed activity map is a standalone tracking-free metric for indicating cell activity. Finally, we perform a quantitative analysis of the tracking accuracy for different frame rates, to inform life scientists about a suitable (in terms of tracking performance) choice of the frame rate for their cultivation experiments, when cell tracks are the desired key outcome.
Efficiently Reconfiguring a Connected Swarm of Labeled Robots
Sep 22, 2022

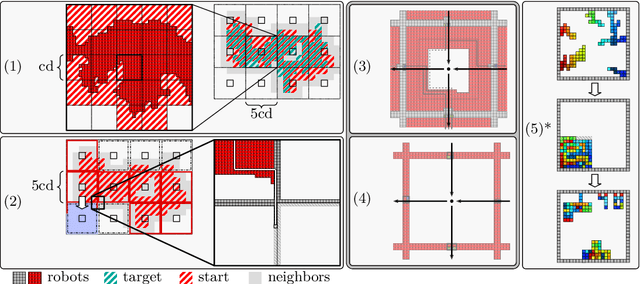
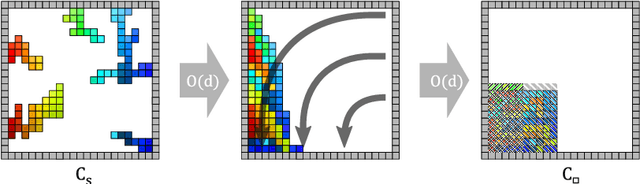
When considering motion planning for a swarm of $n$ labeled robots, we need to rearrange a given start configuration into a desired target configuration via a sequence of parallel, continuous, collision-free robot motions. The objective is to reach the new configuration in a minimum amount of time; an important constraint is to keep the swarm connected at all times. Problems of this type have been considered before, with recent notable results achieving constant stretch for not necessarily connected reconfiguration: If mapping the start configuration to the target configuration requires a maximum Manhattan distance of $d$, the total duration of an overall schedule can be bounded to $\mathcal{O}(d)$, which is optimal up to constant factors. However, constant stretch could only be achieved if disconnected reconfiguration is allowed, or for scaled configurations (which arise by increasing all dimensions of a given object by the same multiplicative factor) of unlabeled robots. We resolve these major open problems by (1) establishing a lower bound of $\Omega(\sqrt{n})$ for connected, labeled reconfiguration and, most importantly, by (2) proving that for scaled arrangements, constant stretch for connected reconfiguration can be achieved. In addition, we show that (3) it is NP-hard to decide whether a makespan of 2 can be achieved, while it is possible to check in polynomial time whether a makespan of 1 can be achieved.
Semantic Clustering of a Sequence of Satellite Images
Aug 29, 2022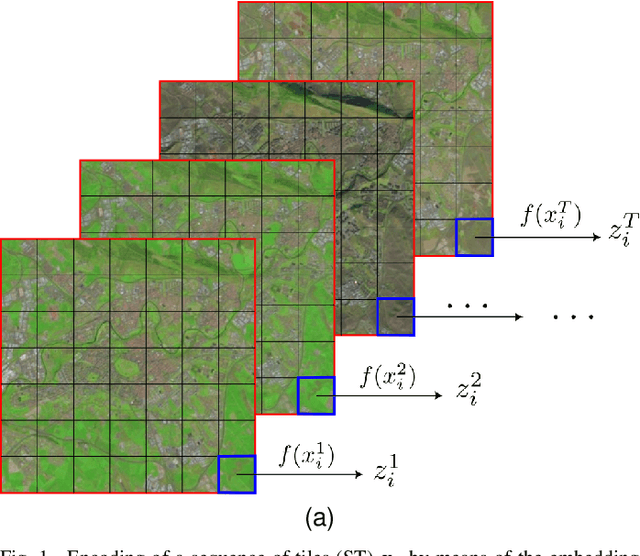
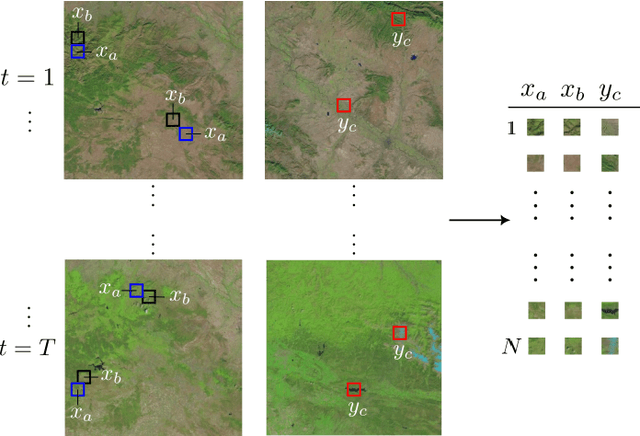
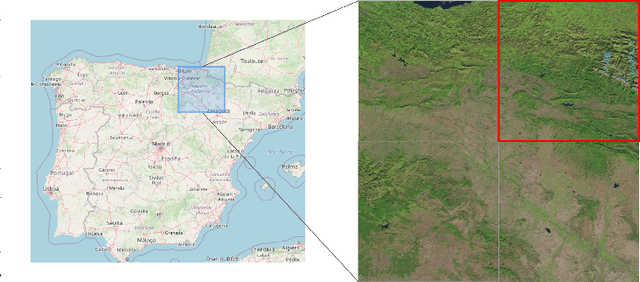
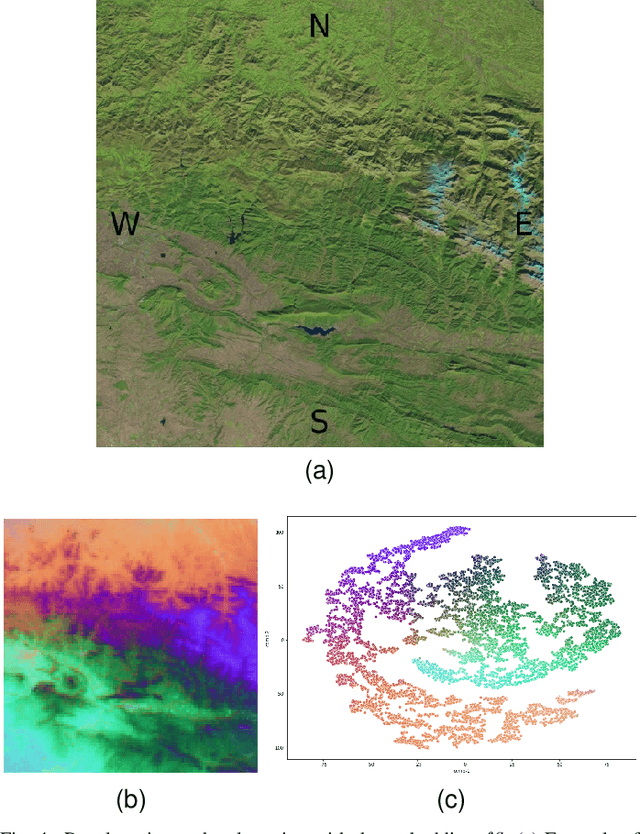
Satellite images constitute a highly valuable and abundant resource for many real world applications. However, the labeled data needed to train most machine learning models are scarce and difficult to obtain. In this context, the current work investigates a fully unsupervised methodology that, given a temporal sequence of satellite images, creates a partition of the ground according to its semantic properties and their evolution over time. The sequences of images are translated into a grid of multivariate time series of embedded tiles. The embedding and the partitional clustering of these sequences of tiles are constructed in two iterative steps: In the first step, the embedding is able to extract the information of the sequences of tiles based on a geographical neighborhood, and the tiles are grouped into clusters. In the second step, the embedding is refined by using the neighborhood defined by the clusters, and the final clustering of the sequences of tiles is obtained. We illustrate the methodology by conducting the semantic clustering of a sequence of 20 satellite images of the region of Navarra (Spain). The results show that the clustering of multivariate time series is robust and contains trustful spatio-temporal semantic information about the region under study. We unveil the close connection that exists between the geographic and embedded spaces, and find out that the semantic properties attributed to these kinds of embeddings are fully exploited and even enhanced by the proposed clustering of time series.
Optimal consumption-investment choices under wealth-driven risk aversion
Oct 03, 2022
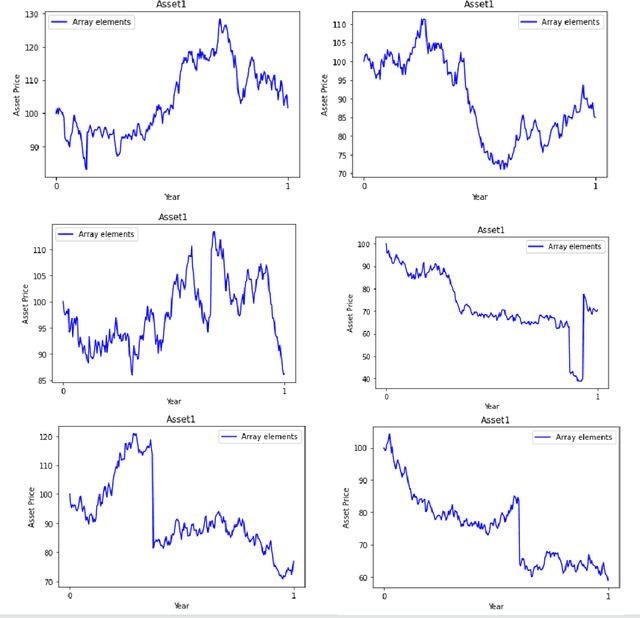
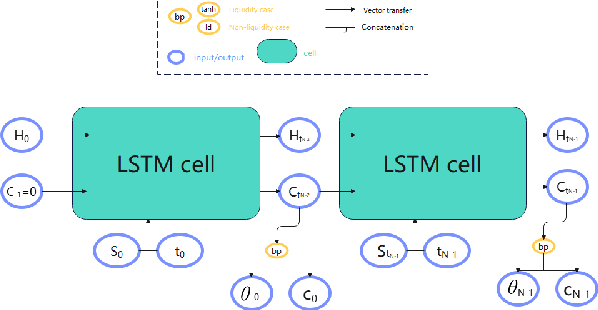
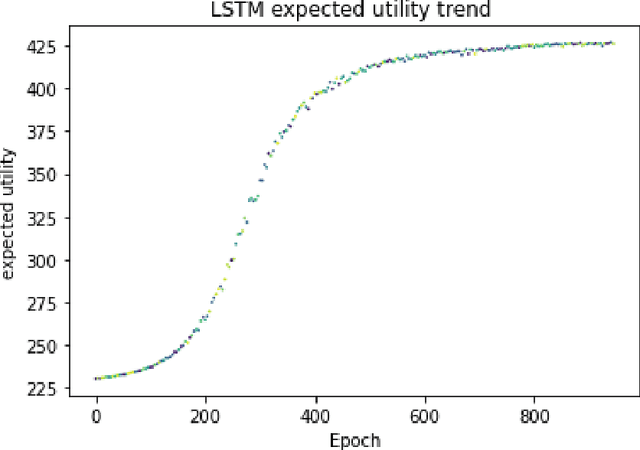
CRRA utility where the risk aversion coefficient is a constant is commonly seen in various economics models. But wealth-driven risk aversion rarely shows up in investor's investment problems. This paper mainly focus on numerical solutions to the optimal consumption-investment choices under wealth-driven aversion done by neural network. A jump-diffusion model is used to simulate the artificial data that is needed for the neural network training. The WDRA Model is set up for describing the investment problem and there are two parameters that require to be optimized, which are the investment rate of the wealth on the risky assets and the consumption during the investment time horizon. Under this model, neural network LSTM with one objective function is implemented and shows promising results.
A large sample theory for infinitesimal gradient boosting
Oct 03, 2022Infinitesimal gradient boosting is defined as the vanishing-learning-rate limit of the popular tree-based gradient boosting algorithm from machine learning (Dombry and Duchamps, 2021). It is characterized as the solution of a nonlinear ordinary differential equation in a infinite-dimensional function space where the infinitesimal boosting operator driving the dynamics depends on the training sample. We consider the asymptotic behavior of the model in the large sample limit and prove its convergence to a deterministic process. This infinite population limit is again characterized by a differential equation that depends on the population distribution. We explore some properties of this population limit: we prove that the dynamics makes the test error decrease and we consider its long time behavior.
Adaptive Time-Channel Beamforming for Time-of-Flight Correction
Oct 17, 2021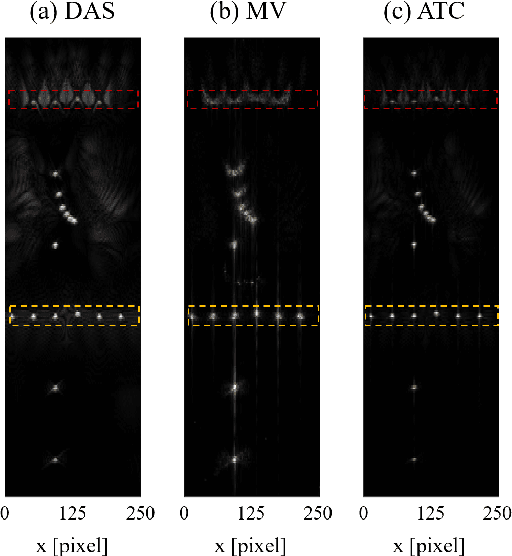
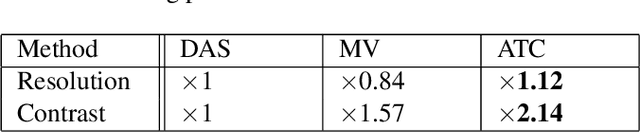
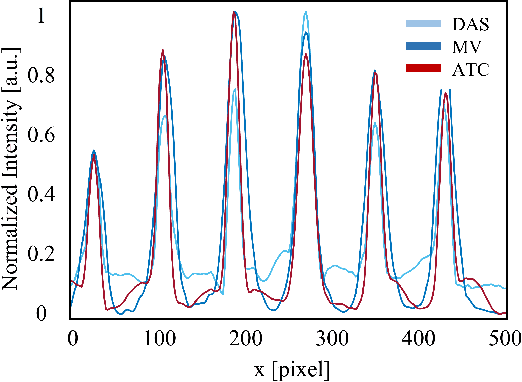
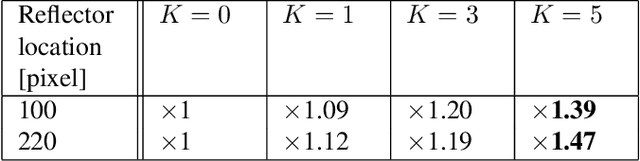
Adaptive beamforming can lead to substantial improvement in resolution and contrast of ultrasound images over standard delay and sum beamforming. Here we introduce the adaptive time-channel (ATC) beamformer, a data-driven approach that combines spatial and temporal information simultaneously, thus generalizing minimum variance beamformers. Moreover, we broaden the concept of apodization to the temporal dimension. Our approach reduces noises by allowing for the weights to adapt in both the temporal and spatial dimensions, thereby reducing artifacts caused by the media's inhomogeneities. We apply our method to in-silico data and show 12% resolution enhancement along with 2-fold contrast improvement, and significant noise reduction with respect to delay and sum and minimum variance beamformers.
AMD-DBSCAN: An Adaptive Multi-density DBSCAN for datasets of extremely variable density
Oct 15, 2022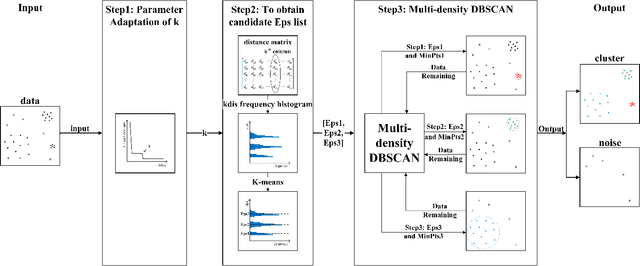
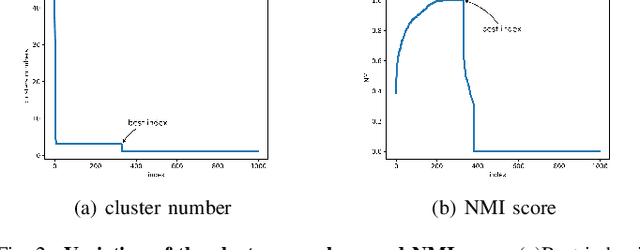
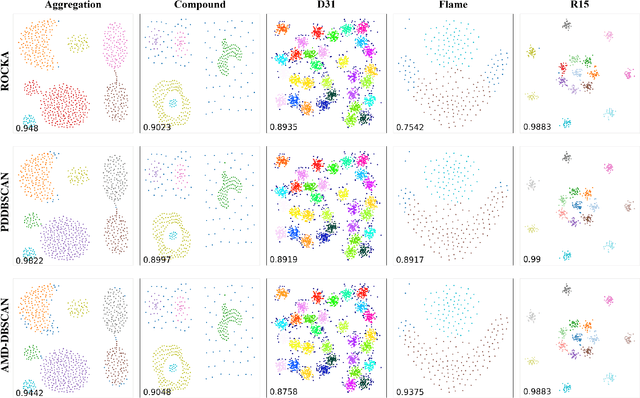
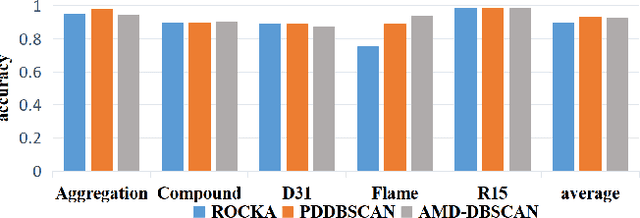
DBSCAN has been widely used in density-based clustering algorithms. However, with the increasing demand for Multi-density clustering, previous traditional DSBCAN can not have good clustering results on Multi-density datasets. In order to address this problem, an adaptive Multi-density DBSCAN algorithm (AMD-DBSCAN) is proposed in this paper. An improved parameter adaptation method is proposed in AMD-DBSCAN to search for multiple parameter pairs (i.e., Eps and MinPts), which are the key parameters to determine the clustering results and performance, therefore allowing the model to be applied to Multi-density datasets. Moreover, only one hyperparameter is required for AMD-DBSCAN to avoid the complicated repetitive initialization operations. Furthermore, the variance of the number of neighbors (VNN) is proposed to measure the difference in density between each cluster. The experimental results show that our AMD-DBSCAN reduces execution time by an average of 75% due to lower algorithm complexity compared with the traditional adaptive algorithm. In addition, AMD-DBSCAN improves accuracy by 24.7% on average over the state-of-the-art design on Multi-density datasets of extremely variable density, while having no performance loss in Single-density scenarios.
Runtime-Assured, Real-Time Neural Control of Microgrids
Feb 20, 2022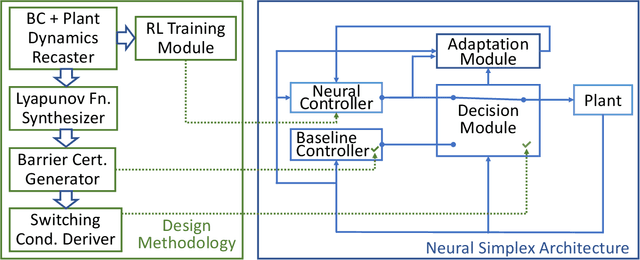
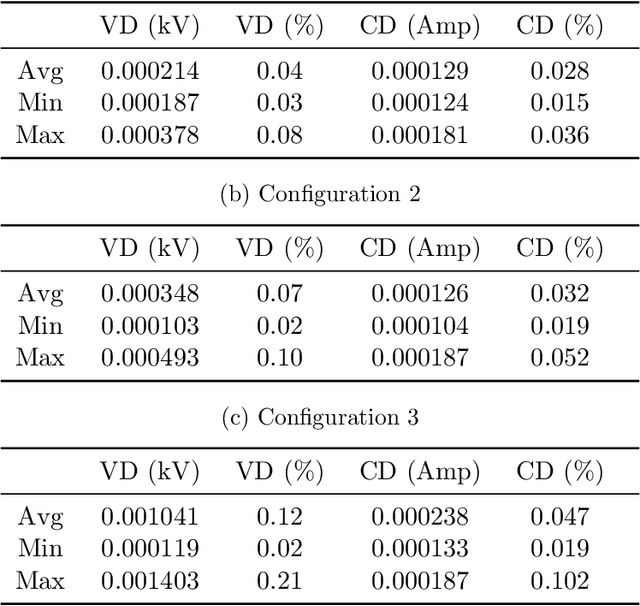
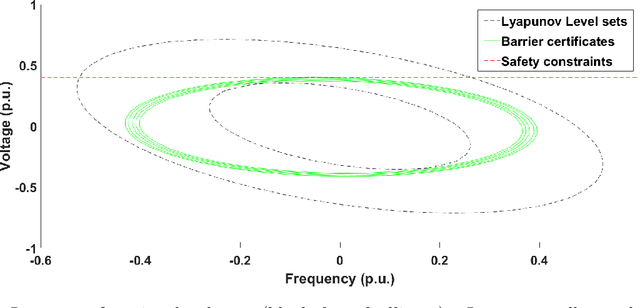
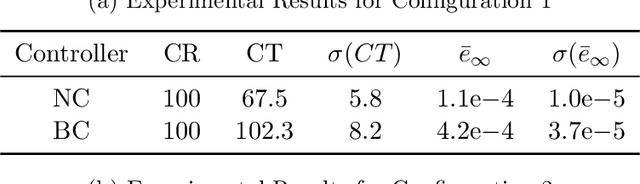
We present SimpleMG, a new, provably correct design methodology for runtime assurance of microgrids (MGs) with neural controllers. Our approach is centered around the Neural Simplex Architecture, which in turn is based on Sha et al.'s Simplex Control Architecture. Reinforcement Learning is used to synthesize high-performance neural controllers for MGs. Barrier Certificates are used to establish SimpleMG's runtime-assurance guarantees. We present a novel method to derive the condition for switching from the unverified neural controller to the verified-safe baseline controller, and we prove that the method is correct. We conduct an extensive experimental evaluation of SimpleMG using RTDS, a high-fidelity, real-time simulation environment for power systems, on a realistic model of a microgrid comprising three distributed energy resources (battery, photovoltaic, and diesel generator). Our experiments confirm that SimpleMG can be used to develop high-performance neural controllers for complex microgrids while assuring runtime safety, even in the presence of adversarial input attacks on the neural controller. Our experiments also demonstrate the benefits of online retraining of the neural controller while the baseline controller is in control
A review of probabilistic forecasting and prediction with machine learning
Sep 17, 2022
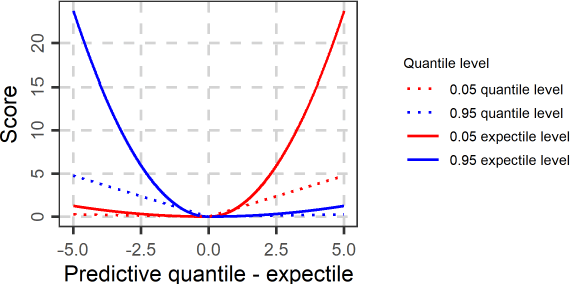
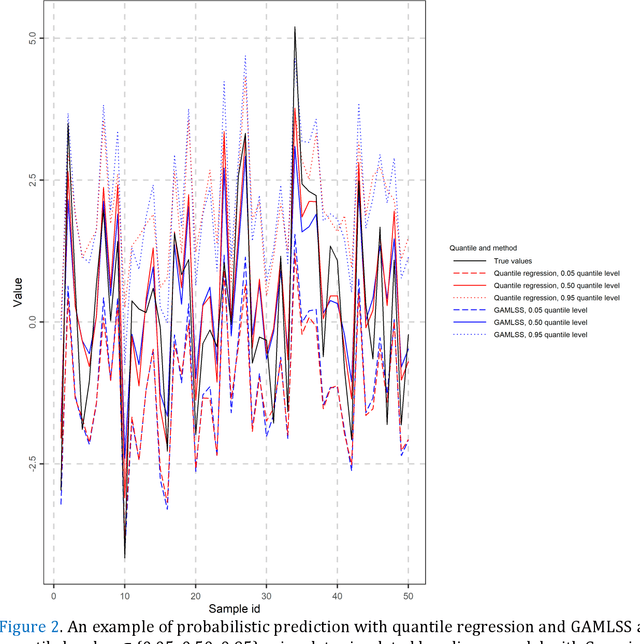
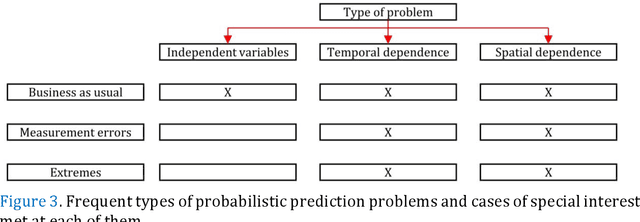
Predictions and forecasts of machine learning models should take the form of probability distributions, aiming to increase the quantity of information communicated to end users. Although applications of probabilistic prediction and forecasting with machine learning models in academia and industry are becoming more frequent, related concepts and methods have not been formalized and structured under a holistic view of the entire field. Here, we review the topic of predictive uncertainty estimation with machine learning algorithms, as well as the related metrics (consistent scoring functions and proper scoring rules) for assessing probabilistic predictions. The review covers a time period spanning from the introduction of early statistical (linear regression and time series models, based on Bayesian statistics or quantile regression) to recent machine learning algorithms (including generalized additive models for location, scale and shape, random forests, boosting and deep learning algorithms) that are more flexible by nature. The review of the progress in the field, expedites our understanding on how to develop new algorithms tailored to users' needs, since the latest advancements are based on some fundamental concepts applied to more complex algorithms. We conclude by classifying the material and discussing challenges that are becoming a hot topic of research.