 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FAQS: Communication-efficient Federate DNN Architecture and Quantization Co-Search for personalized Hardware-aware Preferences
Oct 16, 2022
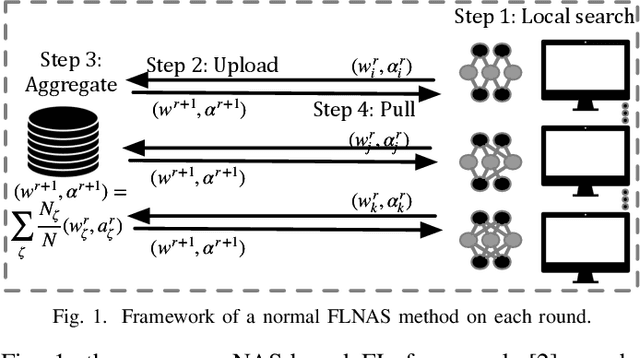
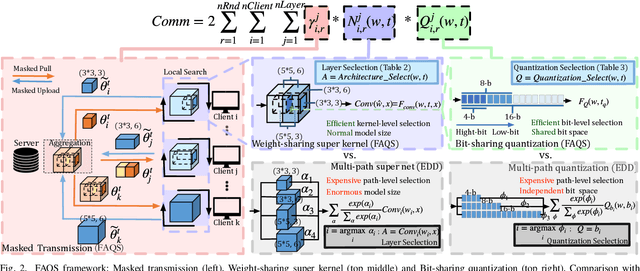
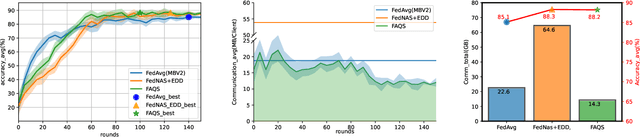
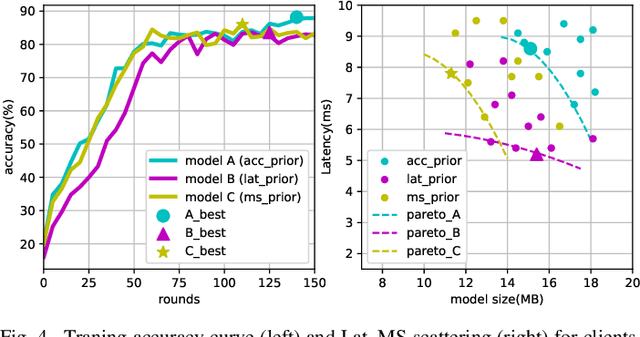
Due to user privacy and regulatory restrictions, federate learning (FL) is proposed as a distributed learning framework for training deep neural networks (DNN) on decentralized data clients. Recent advancements in FL have applied Neural Architecture Search (NAS) to replace the predefined one-size-fit-all DNN model, which is not optimal for all tasks of various data distributions, with searchable DNN architectures. However, previous methods suffer from expensive communication cost rasied by frequent large model parameters transmission between the server and clients. Such difficulty is further amplified when combining NAS algorithms, which commonly require prohibitive computation and enormous model storage. Towards this end, we propose FAQS, an efficient personalized FL-NAS-Quantization framework to reduce the communication cost with three features: weight-sharing super kernels, bit-sharing quantization and masked transmission. FAQS has an affordable search time and demands very limited size of transmitted messages at each round. By setting different personlized pareto function loss on local clients, FAQS can yield heterogeneous hardware-aware models for various user preferences. Experimental results show that FAQS achieves average reduction of 1.58x in communication bandwith per round compared with normal FL framework and 4.51x compared with FL+NAS framwork.
Low PAPR Pilot for Delay-Doppler Domain Modulation
Sep 30, 2022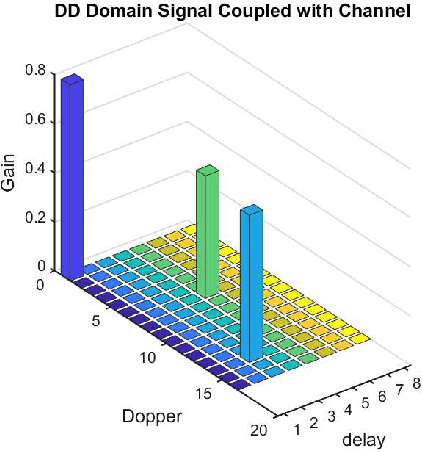
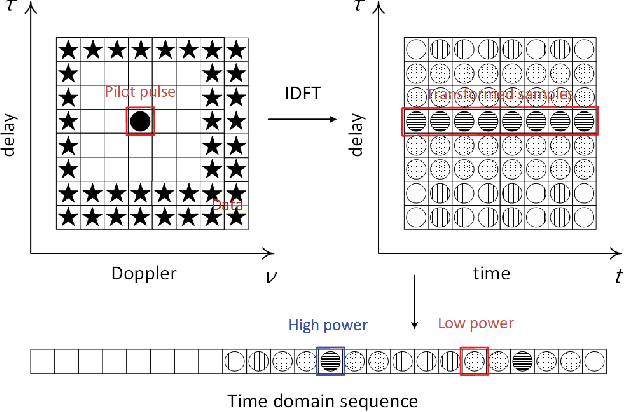
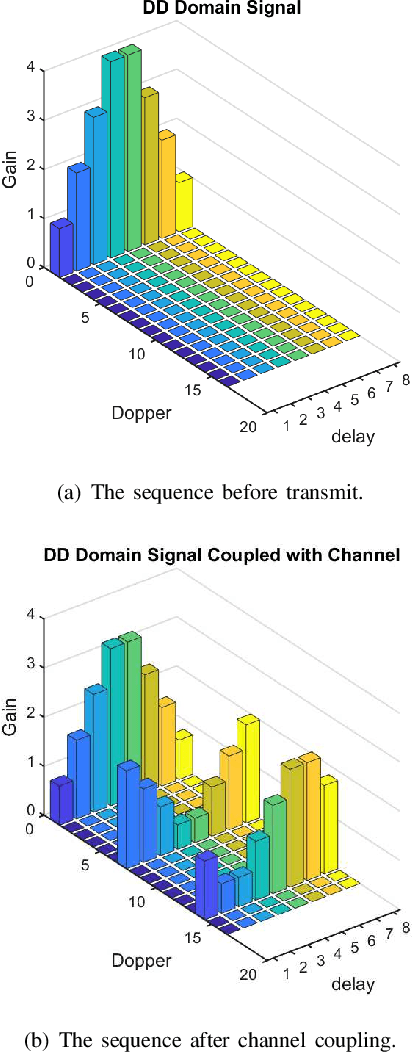
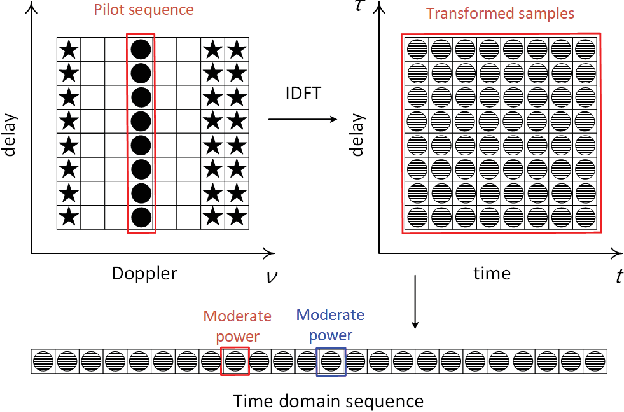
This paper studies the low PAPR pilot design in delay-Doppler domain modulation. We adopt a sequence based pilot design instead of the conventional pulse pilot, to mitigate the PAPR issue. We develop simple channel estimation algorithm composes of two-stages which are path identification and channel coefficient estimation. The quantitative analysis on the channel estimation error model is provided. Based on which the principle of pilot sequence design in delay-Doppler domain is revealed. Experiment results shows that the proposed scheme maintains a relatively low PAPR in time domain samples, while the channel estimation performance approaches the ideal channel estimation in limited-Doppler-Shift channel model.
ContactNet: Online Multi-Contact Planning for Acyclic Legged Robot Locomotion
Sep 30, 2022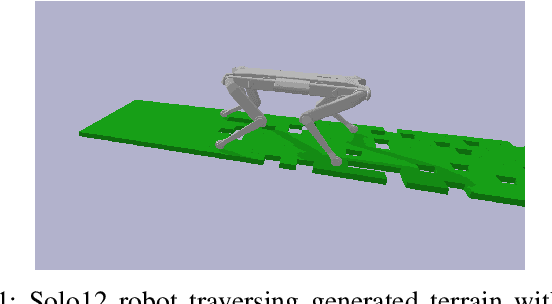

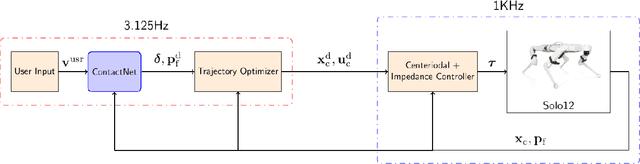
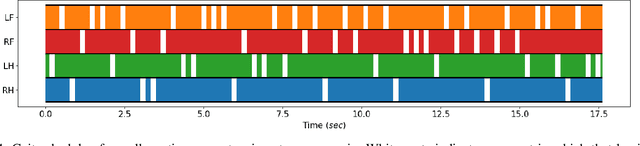
Online trajectory optimization techniques generally depend on heuristic-based contact planners in order to have low computation times and achieve high replanning frequencies. In this work, we propose ContactNet, a fast acyclic contact planner based on a multi-output regression neural network. ContactNet ranks discretized stepping regions, allowing to quickly choose the best feasible solution, even in complex environments. The low computation time, in the order of 1 ms, makes possible the execution of the contact planner concurrently with a trajectory optimizer in a Model Predictive Control (MPC) fashion. We demonstrate the effectiveness of the approach in simulation in different complex scenarios with the quadruped robot Solo12.
Totally-ordered Sequential Rules for Utility Maximization
Sep 27, 2022
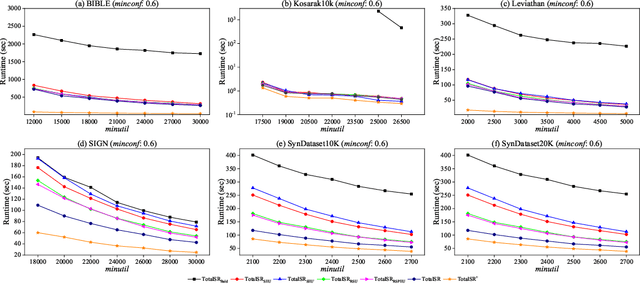

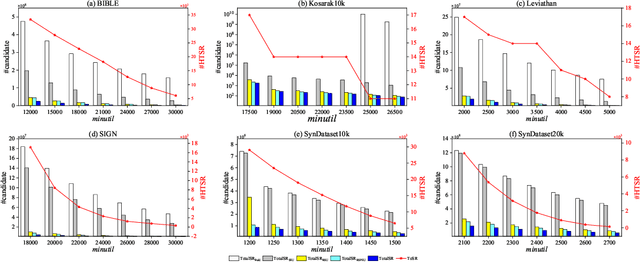
High utility sequential pattern mining (HUSPM) is a significant and valuable activity in knowledge discovery and data analytics with many real-world applications. In some cases, HUSPM can not provide an excellent measure to predict what will happen. High utility sequential rule mining (HUSRM) discovers high utility and high confidence sequential rules, allowing it to solve the problem in HUSPM. All existing HUSRM algorithms aim to find high-utility partially-ordered sequential rules (HUSRs), which are not consistent with reality and may generate fake HUSRs. Therefore, in this paper, we formulate the problem of high utility totally-ordered sequential rule mining and propose two novel algorithms, called TotalSR and TotalSR+, which aim to identify all high utility totally-ordered sequential rules (HTSRs). TotalSR creates a utility table that can efficiently calculate antecedent support and a utility prefix sum list that can compute the remaining utility in O(1) time for a sequence. We also introduce a left-first expansion strategy that can utilize the anti-monotonic property to use a confidence pruning strategy. TotalSR can also drastically reduce the search space with the help of utility upper bounds pruning strategies, avoiding much more meaningless computation. In addition, TotalSR+ uses an auxiliary antecedent record table to more efficiently discover HTSRs. Finally, there are numerous experimental results on both real and synthetic datasets demonstrating that TotalSR is significantly more efficient than algorithms with fewer pruning strategies, and TotalSR+ is significantly more efficient than TotalSR in terms of running time and scalability.
Time varying regression with hidden linear dynamics
Dec 29, 2021We revisit a model for time-varying linear regression that assumes the unknown parameters evolve according to a linear dynamical system. Counterintuitively, we show that when the underlying dynamics are stable the parameters of this model can be estimated from data by combining just two ordinary least squares estimates. We offer a finite sample guarantee on the estimation error of our method and discuss certain advantages it has over Expectation-Maximization (EM), which is the main approach proposed by prior work.
Sig-Wasserstein GANs for Time Series Generation
Nov 01, 2021
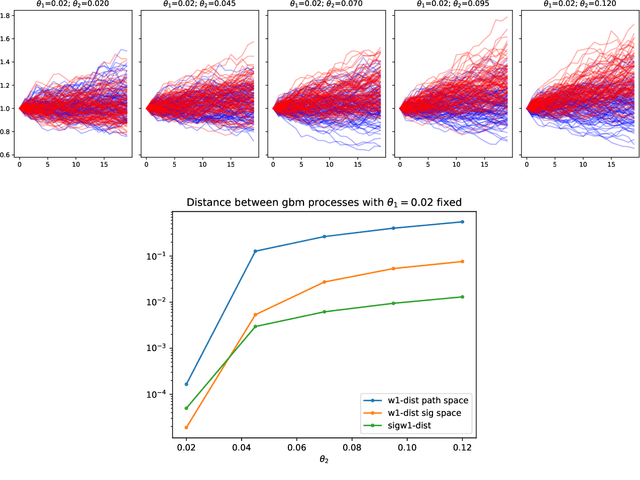
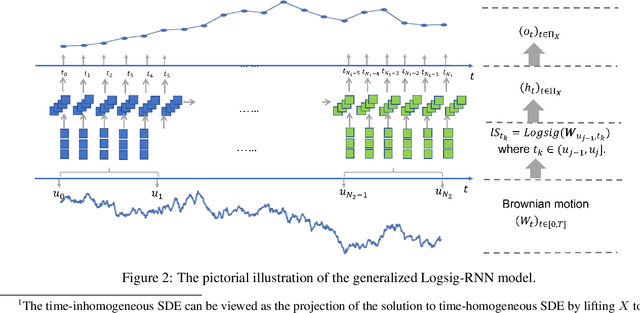
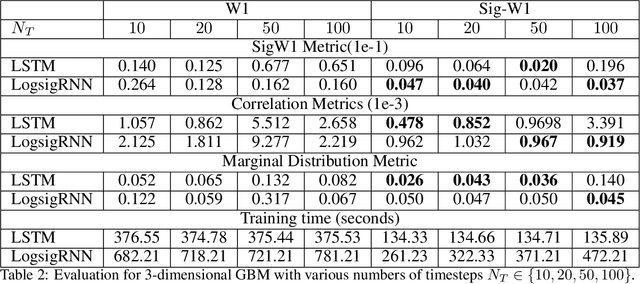
Synthetic data is an emerging technology that can significantly accelerate the development and deployment of AI machine learning pipelines. In this work, we develop high-fidelity time-series generators, the SigWGAN, by combining continuous-time stochastic models with the newly proposed signature $W_1$ metric. The former are the Logsig-RNN models based on the stochastic differential equations, whereas the latter originates from the universal and principled mathematical features to characterize the measure induced by time series. SigWGAN allows turning computationally challenging GAN min-max problem into supervised learning while generating high fidelity samples. We validate the proposed model on both synthetic data generated by popular quantitative risk models and empirical financial data. Codes are available at https://github.com/SigCGANs/Sig-Wasserstein-GANs.git.
Towards Robust Real-time Audio-Visual Speech Enhancement
Dec 16, 2021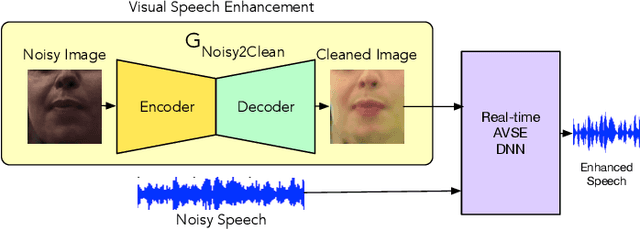
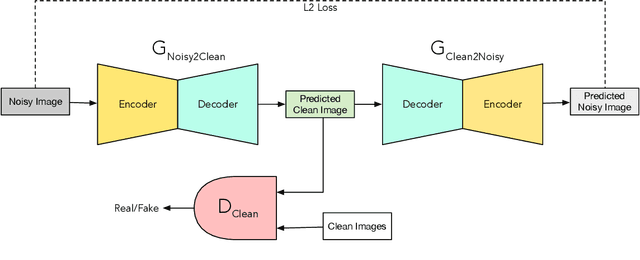
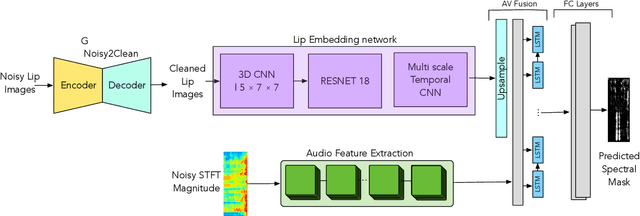

The human brain contextually exploits heterogeneous sensory information to efficiently perform cognitive tasks including vision and hearing. For example, during the cocktail party situation, the human auditory cortex contextually integrates audio-visual (AV) cues in order to better perceive speech. Recent studies have shown that AV speech enhancement (SE) models can significantly improve speech quality and intelligibility in very low signal to noise ratio (SNR) environments as compared to audio-only SE models. However, despite significant research in the area of AV SE, development of real-time processing models with low latency remains a formidable technical challenge. In this paper, we present a novel framework for low latency speaker-independent AV SE that can generalise on a range of visual and acoustic noises. In particular, a generative adversarial networks (GAN) is proposed to address the practical issue of visual imperfections in AV SE. In addition, we propose a deep neural network based real-time AV SE model that takes into account the cleaned visual speech output from GAN to deliver more robust SE. The proposed framework is evaluated on synthetic and real noisy AV corpora using objective speech quality and intelligibility metrics and subjective listing tests. Comparative simulation results show that our real time AV SE framework outperforms state-of-the-art SE approaches, including recent DNN based SE models.
Earthquake Phase Association with Graph Neural Networks
Sep 15, 2022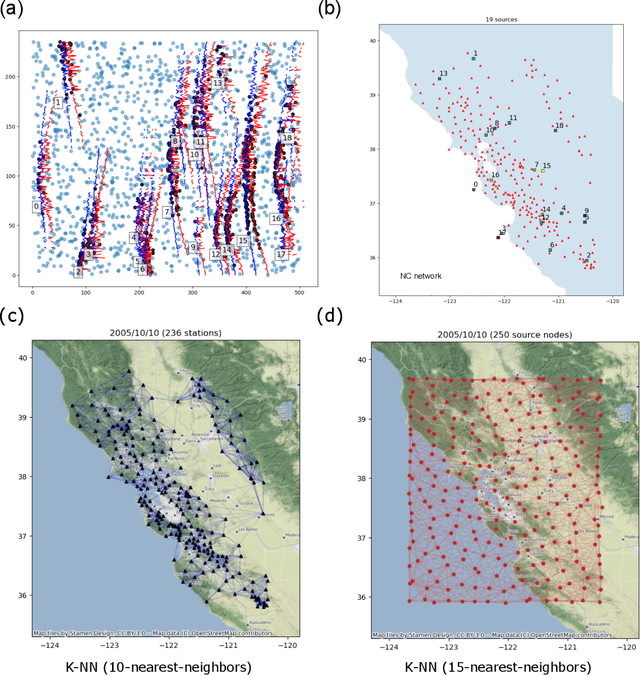
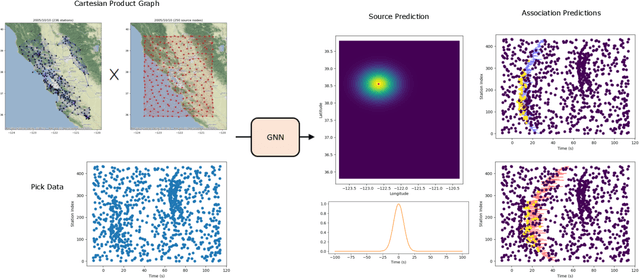
Seismic phase association connects earthquake arrival time measurements to their causative sources. Effective association must determine the number of discrete events, their location and origin times, and it must differentiate real arrivals from measurement artifacts. The advent of deep learning pickers, which provide high rates of picks from closely overlapping small magnitude earthquakes, motivates revisiting the phase association problem and approaching it using the methods of deep learning. We have developed a Graph Neural Network associator that simultaneously predicts both source space-time localization, and discrete source-arrival association likelihoods. The method is applicable to arbitrary geometry, time-varying seismic networks of hundreds of stations, and is robust to high rates of sources and input picks with variable noise and quality. Our Graph Earthquake Neural Interpretation Engine (GENIE) uses one graph to represent the station set and another to represent the spatial source region. GENIE learns relationships from data in this combined representation that enable it to determine robust source and source-arrival associations. We train on synthetic data, and test our method on real data from the Northern California (NC) seismic network using input generated by the PhaseNet deep learning phase picker. We successfully re-detect ~96% of all events M>1 reported by the USGS during 500 random days between 2000$\unicode{x2013}$2022. Over a 100-day continuous interval of processing in 2017$\unicode{x2013}$2018, we detect ~4.2x the number of events reported by the USGS. Our new events have small magnitude estimates below the magnitude of completeness of the USGS catalog, and are located close to the active faults and quarries in the region. Our results demonstrate that GENIE can effectively solve the association problem under complex seismic monitoring conditions.
Exploring Low Rank Training of Deep Neural Networks
Sep 27, 2022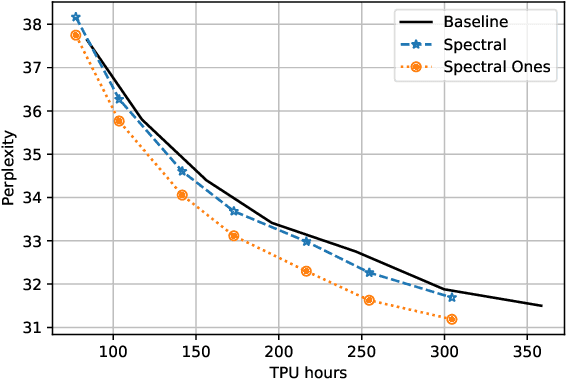

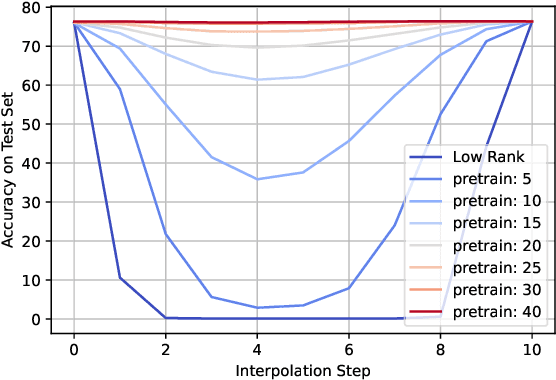
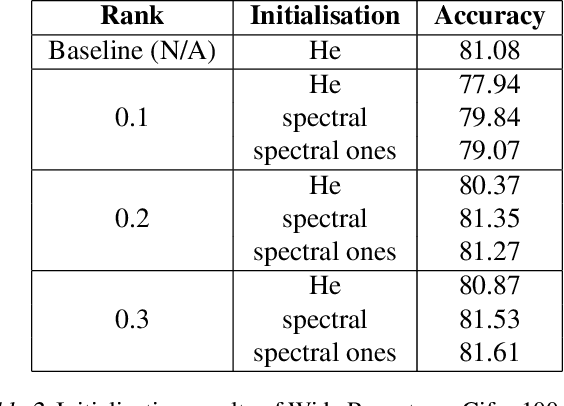
Training deep neural networks in low rank, i.e. with factorised layers, is of particular interest to the community: it offers efficiency over unfactorised training in terms of both memory consumption and training time. Prior work has focused on low rank approximations of pre-trained networks and training in low rank space with additional objectives, offering various ad hoc explanations for chosen practice. We analyse techniques that work well in practice, and through extensive ablations on models such as GPT2 we provide evidence falsifying common beliefs in the field, hinting in the process at exciting research opportunities that still need answering.
Improved Multi-objective Data Stream Clustering with Time and Memory Optimization
Jan 13, 2022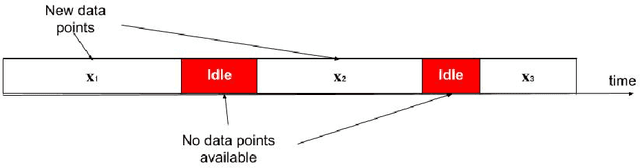
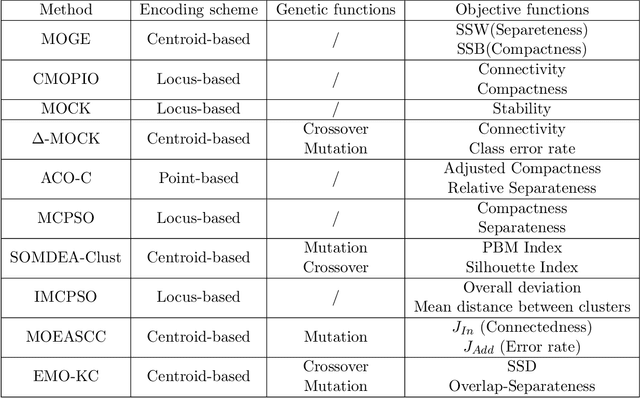
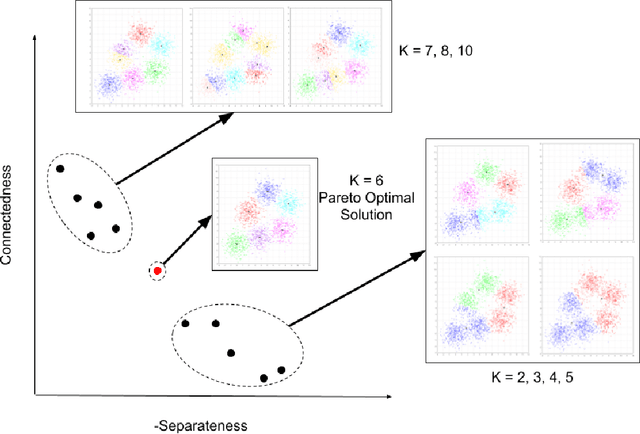
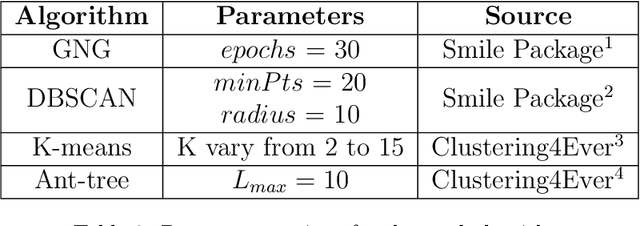
The analysis of data streams has received considerable attention over the past few decades due to sensors, social media, etc. It aims to recognize patterns in an unordered, infinite, and evolving stream of observations. Clustering this type of data requires some restrictions in time and memory. This paper introduces a new data stream clustering method (IMOC-Stream). This method, unlike the other clustering algorithms, uses two different objective functions to capture different aspects of the data. The goal of IMOC-Stream is to: 1) reduce computation time by using idle times to apply genetic operations and enhance the solution. 2) reduce memory allocation by introducing a new tree synopsis. 3) find arbitrarily shaped clusters by using a multi-objective framework. We conducted an experimental study with high dimensional stream datasets and compared them to well-known stream clustering techniques. The experiments show the ability of our method to partition the data stream in arbitrarily shaped, compact, and well-separated clusters while optimizing the time and memory. Our method also outperformed most of the stream algorithms in terms of NMI and ARAND measures.