 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Scale Adaptive Graph Neural Network for Multivariate Time Series Forecasting
Jan 13, 2022
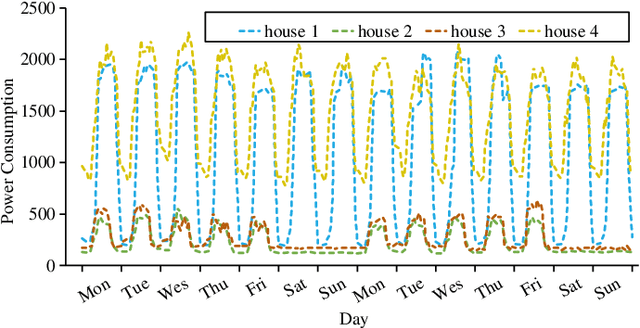
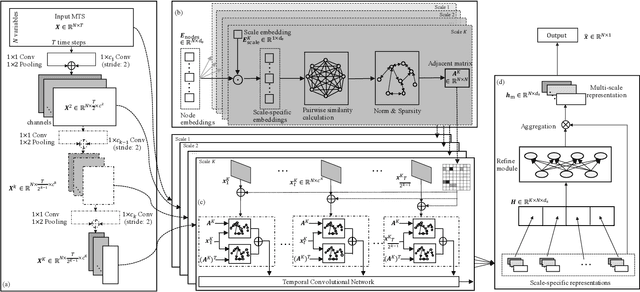
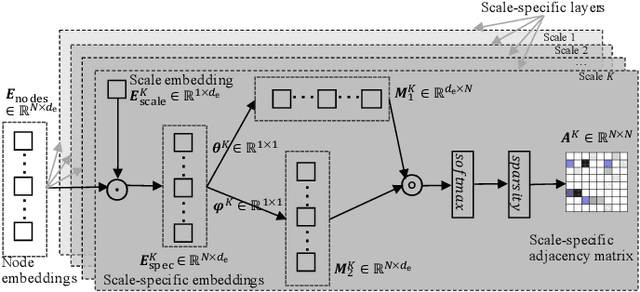
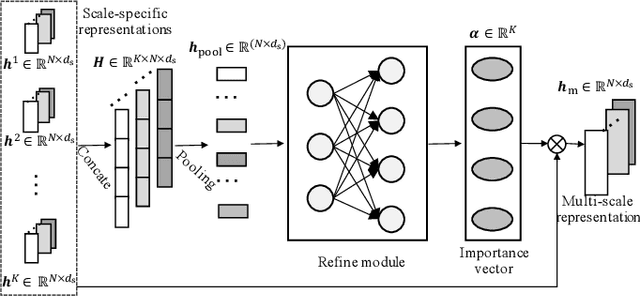
Multivariate time series (MTS) forecasting plays an important role in the automation and optimization of intelligent applications. It is a challenging task, as we need to consider both complex intra-variable dependencies and inter-variable dependencies. Existing works only learn temporal patterns with the help of single inter-variable dependencies. However, there are multi-scale temporal patterns in many real-world MTS. Single inter-variable dependencies make the model prefer to learn one type of prominent and shared temporal patterns. In this paper, we propose a multi-scale adaptive graph neural network (MAGNN) to address the above issue. MAGNN exploits a multi-scale pyramid network to preserve the underlying temporal dependencies at different time scales. Since the inter-variable dependencies may be different under distinct time scales, an adaptive graph learning module is designed to infer the scale-specific inter-variable dependencies without pre-defined priors. Given the multi-scale feature representations and scale-specific inter-variable dependencies, a multi-scale temporal graph neural network is introduced to jointly model intra-variable dependencies and inter-variable dependencies. After that, we develop a scale-wise fusion module to effectively promote the collaboration across different time scales, and automatically capture the importance of contributed temporal patterns. Experiments on four real-world datasets demonstrate that MAGNN outperforms the state-of-the-art methods across various settings.
Magnitude-image based data-consistent deep learning method for MRI super resolution
Sep 07, 2022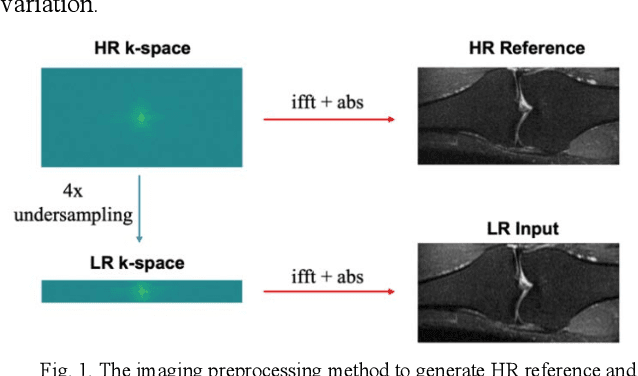
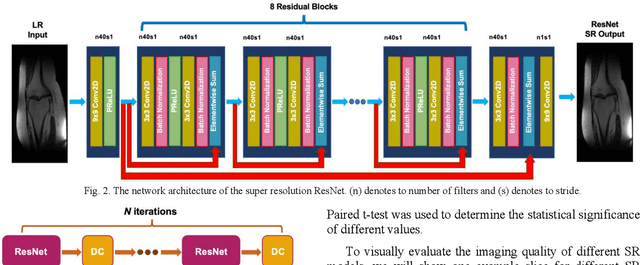
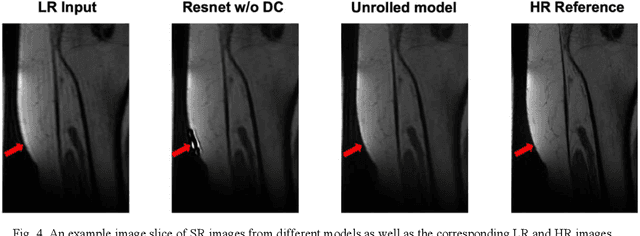
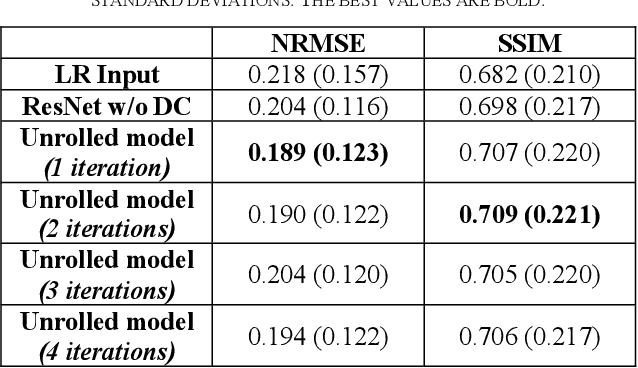
Magnetic Resonance Imaging (MRI) is important in clinic to produce high resolution images for diagnosis, but its acquisition time is long for high resolution images. Deep learning based MRI super resolution methods can reduce scan time without complicated sequence programming, but may create additional artifacts due to the discrepancy between training data and testing data. Data consistency layer can improve the deep learning results but needs raw k-space data. In this work, we propose a magnitude-image based data consistency deep learning MRI super resolution method to improve super resolution images' quality without raw k-space data. Our experiments show that the proposed method can improve NRMSE and SSIM of super resolution images compared to the same Convolutional Neural Network (CNN) block without data consistency module.
Text-Free Learning of a Natural Language Interface for Pretrained Face Generators
Sep 08, 2022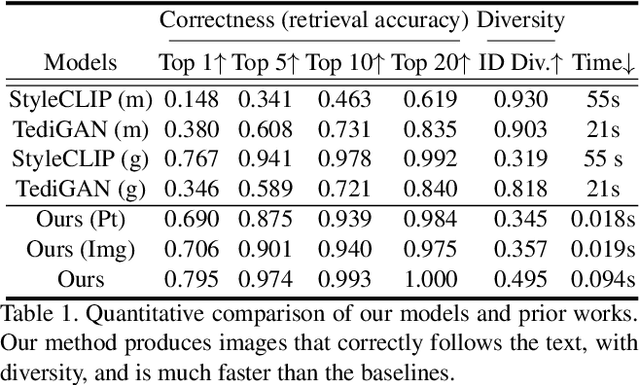
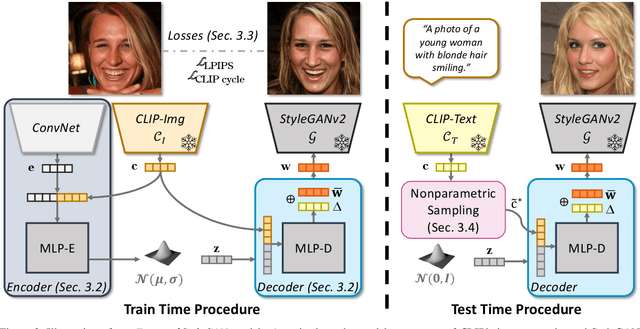
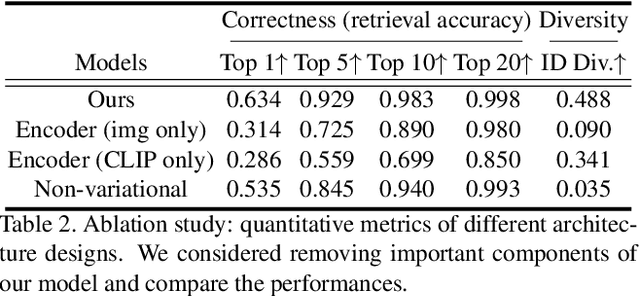

We propose Fast text2StyleGAN, a natural language interface that adapts pre-trained GANs for text-guided human face synthesis. Leveraging the recent advances in Contrastive Language-Image Pre-training (CLIP), no text data is required during training. Fast text2StyleGAN is formulated as a conditional variational autoencoder (CVAE) that provides extra control and diversity to the generated images at test time. Our model does not require re-training or fine-tuning of the GANs or CLIP when encountering new text prompts. In contrast to prior work, we do not rely on optimization at test time, making our method orders of magnitude faster than prior work. Empirically, on FFHQ dataset, our method offers faster and more accurate generation of images from natural language descriptions with varying levels of detail compared to prior work.
Continuous-Time Meta-Learning with Forward Mode Differentiation
Mar 02, 2022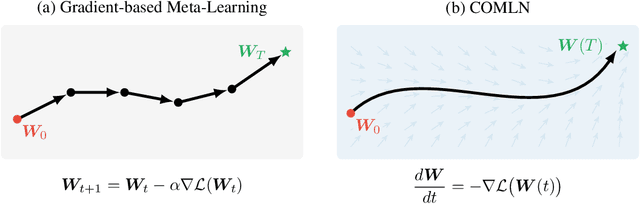
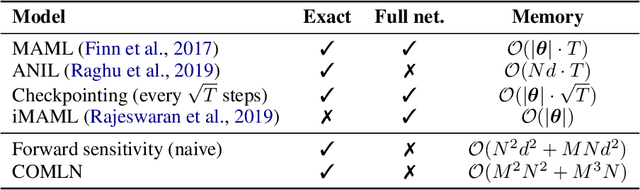
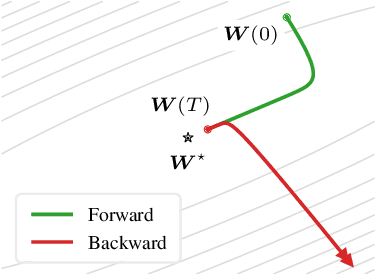
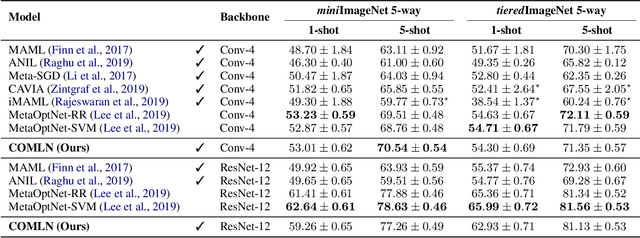
Drawing inspiration from gradient-based meta-learning methods with infinitely small gradient steps, we introduce Continuous-Time Meta-Learning (COMLN), a meta-learning algorithm where adaptation follows the dynamics of a gradient vector field. Specifically, representations of the inputs are meta-learned such that a task-specific linear classifier is obtained as a solution of an ordinary differential equation (ODE). Treating the learning process as an ODE offers the notable advantage that the length of the trajectory is now continuous, as opposed to a fixed and discrete number of gradient steps. As a consequence, we can optimize the amount of adaptation necessary to solve a new task using stochastic gradient descent, in addition to learning the initial conditions as is standard practice in gradient-based meta-learning. Importantly, in order to compute the exact meta-gradients required for the outer-loop updates, we devise an efficient algorithm based on forward mode differentiation, whose memory requirements do not scale with the length of the learning trajectory, thus allowing longer adaptation in constant memory. We provide analytical guarantees for the stability of COMLN, we show empirically its efficiency in terms of runtime and memory usage, and we illustrate its effectiveness on a range of few-shot image classification problems.
Throwing Objects into A Moving Basket While Avoiding Obstacles
Oct 02, 2022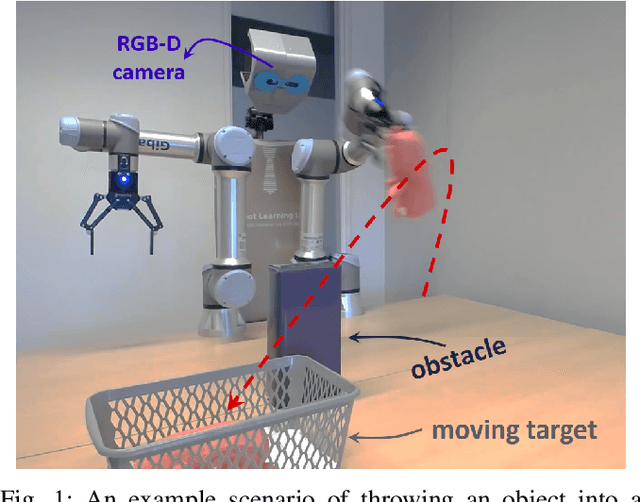

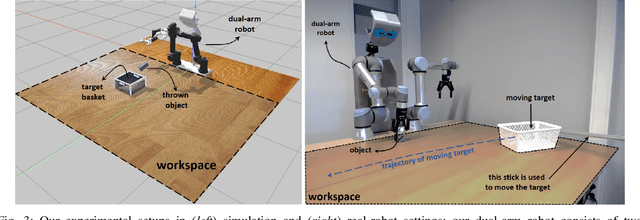

The capabilities of a robot will be increased significantly by exploiting throwing behavior. In particular, throwing will enable robots to rapidly place the object into the target basket, located outside its feasible kinematic space, without traveling to the desired location. In previous approaches, the robot often learned a parameterized throwing kernel through analytical approaches, imitation learning, or hand-coding. There are many situations in which such approaches do not work/generalize well due to various object shapes, heterogeneous mass distribution, and also obstacles that might be presented in the environment. It is obvious that a method is needed to modulate the throwing kernel through its meta parameters. In this paper, we tackle object throwing problem through a deep reinforcement learning approach that enables robots to precisely throw objects into moving baskets while there are obstacles obstructing the path. To the best of our knowledge, we are the first group that addresses throwing objects with obstacle avoidance. Such a throwing skill not only increases the physical reachability of a robot arm but also improves the execution time. In particular, the robot detects the pose of the target object, basket, and obstacle at each time step, predicts the proper grasp configuration for the target object, and then infers appropriate parameters to throw the object into the basket. Due to safety constraints, we develop a simulation environment in Gazebo to train the robot and then use the learned policy in real-robot directly. To assess the performers of the proposed approach, we perform extensive sets of experiments in both simulation and real robots in three scenarios. Experimental results showed that the robot could precisely throw a target object into the basket outside its kinematic range and generalize well to new locations and objects without colliding with obstacles.
TCube: Domain-Agnostic Neural Time-series Narration
Oct 11, 2021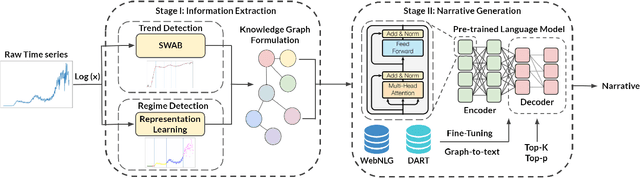
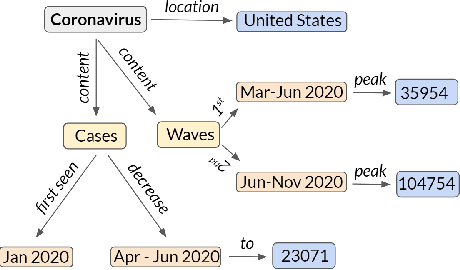
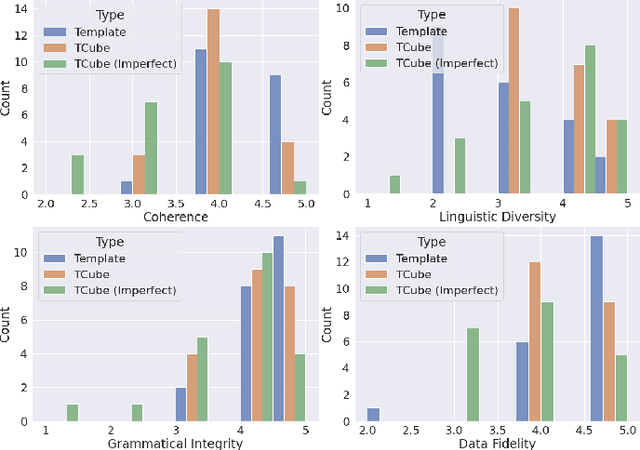
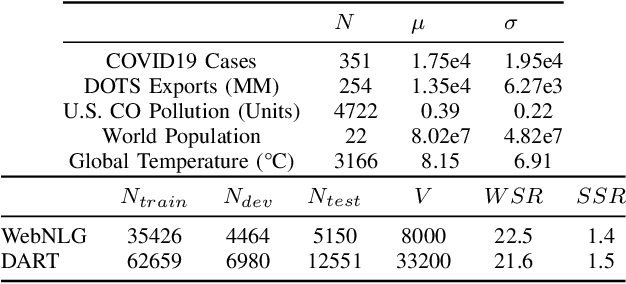
The task of generating rich and fluent narratives that aptly describe the characteristics, trends, and anomalies of time-series data is invaluable to the sciences (geology, meteorology, epidemiology) or finance (trades, stocks, or sales and inventory). The efforts for time-series narration hitherto are domain-specific and use predefined templates that offer consistency but lead to mechanical narratives. We present TCube (Time-series-to-text), a domain-agnostic neural framework for time-series narration, that couples the representation of essential time-series elements in the form of a dense knowledge graph and the translation of said knowledge graph into rich and fluent narratives through the transfer-learning capabilities of PLMs (Pre-trained Language Models). TCube's design primarily addresses the challenge that lies in building a neural framework in the complete paucity of annotated training data for time-series. The design incorporates knowledge graphs as an intermediary for the representation of essential time-series elements which can be linearized for textual translation. To the best of our knowledge, TCube is the first investigation of the use of neural strategies for time-series narration. Through extensive evaluations, we show that TCube can improve the lexical diversity of the generated narratives by up to 65.38% while still maintaining grammatical integrity. The practicality and deployability of TCube is further validated through an expert review (n=21) where 76.2% of participating experts wary of auto-generated narratives favored TCube as a deployable system for time-series narration due to its richer narratives. Our code-base, models, and datasets, with detailed instructions for reproducibility is publicly hosted at https://github.com/Mandar-Sharma/TCube.
FAQS: Communication-efficient Federate DNN Architecture and Quantization Co-Search for personalized Hardware-aware Preferences
Oct 16, 2022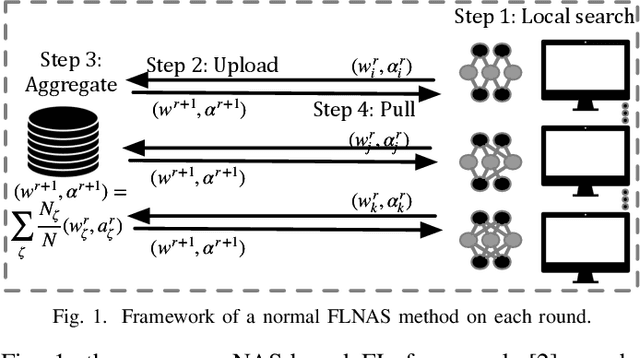
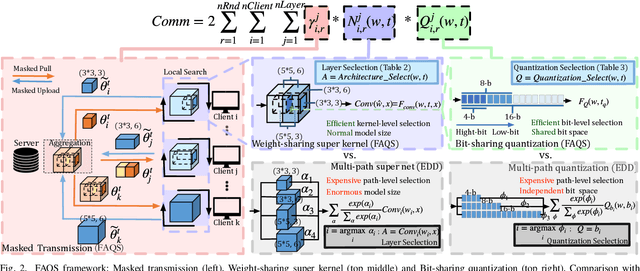
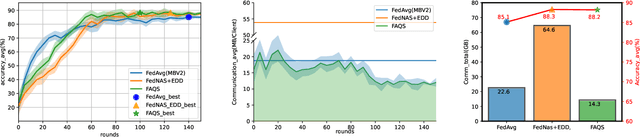
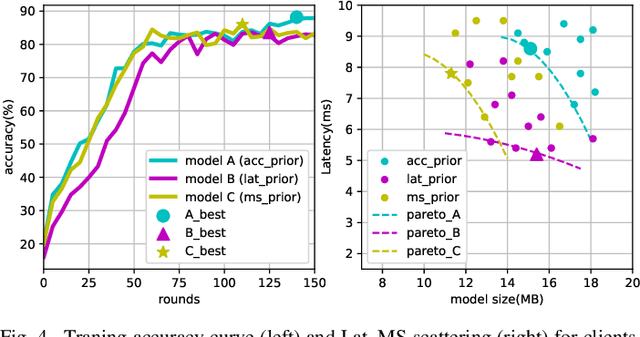
Due to user privacy and regulatory restrictions, federate learning (FL) is proposed as a distributed learning framework for training deep neural networks (DNN) on decentralized data clients. Recent advancements in FL have applied Neural Architecture Search (NAS) to replace the predefined one-size-fit-all DNN model, which is not optimal for all tasks of various data distributions, with searchable DNN architectures. However, previous methods suffer from expensive communication cost rasied by frequent large model parameters transmission between the server and clients. Such difficulty is further amplified when combining NAS algorithms, which commonly require prohibitive computation and enormous model storage. Towards this end, we propose FAQS, an efficient personalized FL-NAS-Quantization framework to reduce the communication cost with three features: weight-sharing super kernels, bit-sharing quantization and masked transmission. FAQS has an affordable search time and demands very limited size of transmitted messages at each round. By setting different personlized pareto function loss on local clients, FAQS can yield heterogeneous hardware-aware models for various user preferences. Experimental results show that FAQS achieves average reduction of 1.58x in communication bandwith per round compared with normal FL framework and 4.51x compared with FL+NAS framwork.
Detecting Anomalies within Smart Buildings using Do-It-Yourself Internet of Things
Oct 04, 2022Detecting anomalies at the time of happening is vital in environments like buildings and homes to identify potential cyber-attacks. This paper discussed the various mechanisms to detect anomalies as soon as they occur. We shed light on crucial considerations when building machine learning models. We constructed and gathered data from multiple self-build (DIY) IoT devices with different in-situ sensors and found effective ways to find the point, contextual and combine anomalies. We also discussed several challenges and potential solutions when dealing with sensing devices that produce data at different sampling rates and how we need to pre-process them in machine learning models. This paper also looks at the pros and cons of extracting sub-datasets based on environmental conditions.
* Journal of Ambient Intelligence and Humanized Computing (2022)
Amortized Bayesian Inference of GISAXS Data with Normalizing Flows
Oct 04, 2022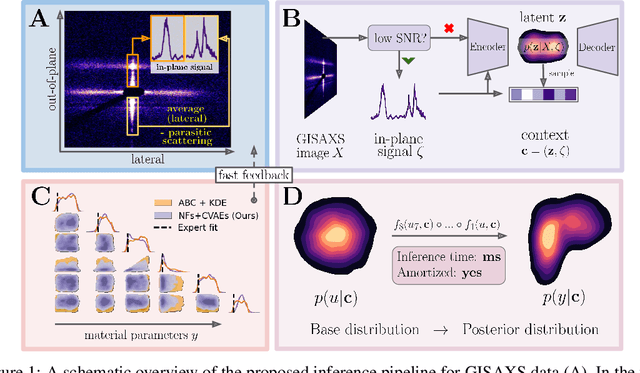
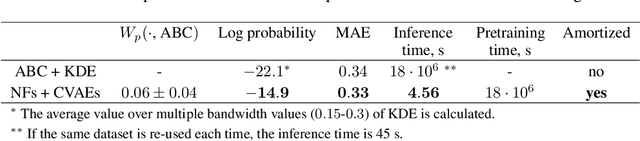
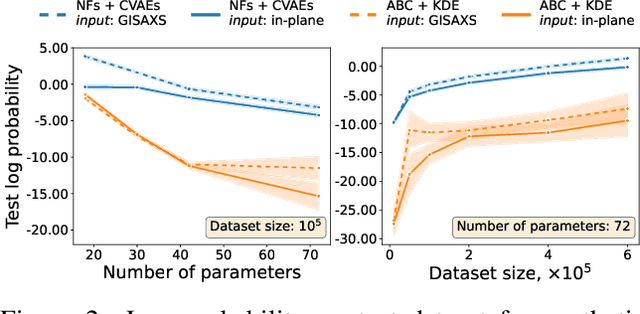

Grazing-Incidence Small-Angle X-ray Scattering (GISAXS) is a modern imaging technique used in material research to study nanoscale materials. Reconstruction of the parameters of an imaged object imposes an ill-posed inverse problem that is further complicated when only an in-plane GISAXS signal is available. Traditionally used inference algorithms such as Approximate Bayesian Computation (ABC) rely on computationally expensive scattering simulation software, rendering analysis highly time-consuming. We propose a simulation-based framework that combines variational auto-encoders and normalizing flows to estimate the posterior distribution of object parameters given its GISAXS data. We apply the inference pipeline to experimental data and demonstrate that our method reduces the inference cost by orders of magnitude while producing consistent results with ABC.
Online Search-based Collision-inclusive Motion Planning and Control for Impact-resilient Mobile Robots
Sep 27, 2022

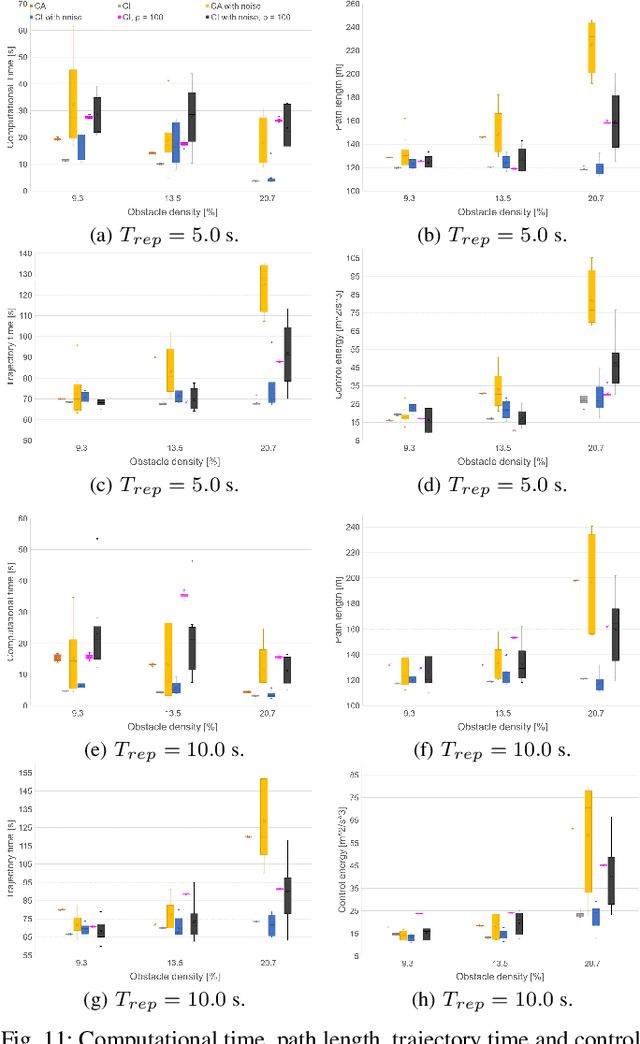
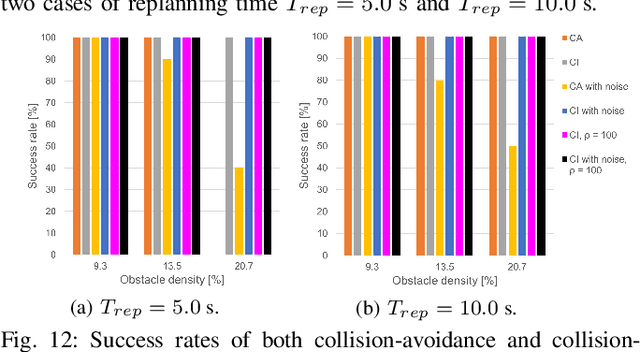
This paper focuses on the emerging paradigm shift of collision-inclusive motion planning and control for impact-resilient mobile robots, and develops a unified hierarchical framework for navigation in unknown and partially-observable cluttered spaces. At the lower-level, we develop a deformation recovery control and trajectory replanning strategy that handles collisions that may occur at run-time, locally. The low-level system actively detects collisions (via embedded Hall effect sensors on a mobile robot built in-house), enables the robot to recover from them, and locally adjusts the post-impact trajectory. Then, at the higher-level, we propose a search-based planning algorithm to determine how to best utilize potential collisions to improve certain metrics, such as control energy and computational time. Our method builds upon A* with jump points. We generate a novel heuristic function, and a collision checking and adjustment technique, thus making the A* algorithm converge faster to reach the goal by exploiting and utilizing possible collisions. The overall hierarchical framework generated by combining the global A* algorithm and the local deformation recovery and replanning strategy, as well as individual components of this framework, are tested extensively both in simulation and experimentally. An ablation study draws links to related state-of-the-art search-based collision-avoidance planners (for the overall framework), as well as search-based collision-avoidance and sampling-based collision-inclusive global planners (for the higher level). Results demonstrate our method's efficacy for collision-inclusive motion planning and control in unknown environments with isolated obstacles for a class of impact-resilient robots operating in 2D.