 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient On-Device Session-Based Recommendation
Sep 28, 2022
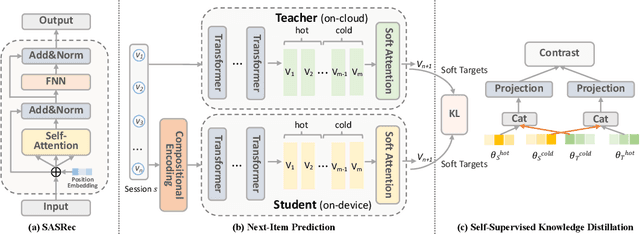
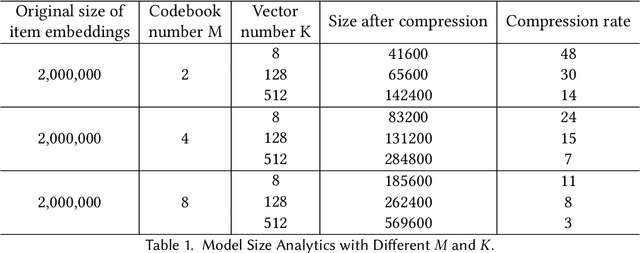
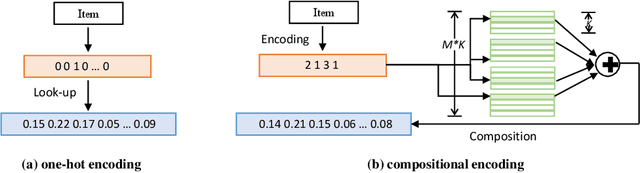

On-device session-based recommendation systems have been achieving increasing attention on account of the low energy/resource consumption and privacy protection while providing promising recommendation performance. To fit the powerful neural session-based recommendation models in resource-constrained mobile devices, tensor-train decomposition and its variants have been widely applied to reduce memory footprint by decomposing the embedding table into smaller tensors, showing great potential in compressing recommendation models. However, these model compression techniques significantly increase the local inference time due to the complex process of generating index lists and a series of tensor multiplications to form item embeddings, and the resultant on-device recommender fails to provide real-time response and recommendation. To improve the online recommendation efficiency, we propose to learn compositional encoding-based compact item representations. Specifically, each item is represented by a compositional code that consists of several codewords, and we learn embedding vectors to represent each codeword instead of each item. Then the composition of the codeword embedding vectors from different embedding matrices (i.e., codebooks) forms the item embedding. Since the size of codebooks can be extremely small, the recommender model is thus able to fit in resource-constrained devices and meanwhile can save the codebooks for fast local inference.Besides, to prevent the loss of model capacity caused by compression, we propose a bidirectional self-supervised knowledge distillation framework. Extensive experimental results on two benchmark datasets demonstrate that compared with existing methods, the proposed on-device recommender not only achieves an 8x inference speedup with a large compression ratio but also shows superior recommendation performance.
An Adaptive Threshold for the Canny Edge Detection with Actor-Critic Algorithm
Sep 19, 2022


Visual surveillance aims to perform robust foreground object detection regardless of the time and place. Object detection shows good results using only spatial information, but foreground object detection in visual surveillance requires proper temporal and spatial information processing. In deep learning-based foreground object detection algorithms, the detection ability is superior to classical background subtraction (BGS) algorithms in an environment similar to training. However, the performance is lower than that of the classical BGS algorithm in the environment different from training. This paper proposes a spatio-temporal fusion network (STFN) that could extract temporal and spatial information using a temporal network and a spatial network. We suggest a method using a semi-foreground map for stable training of the proposed STFN. The proposed algorithm shows excellent performance in an environment different from training, and we show it through experiments with various public datasets. Also, STFN can generate a compliant background image in a semi-supervised method, and it can operate in real-time on a desktop with GPU. The proposed method shows 11.28% and 18.33% higher FM than the latest deep learning method in the LASIESTA and SBI dataset, respectively.
Evaluating Agent Interactions Through Episodic Knowledge Graphs
Sep 26, 2022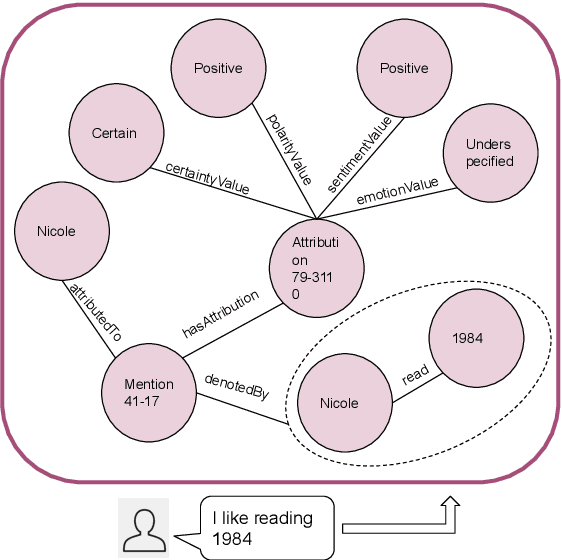
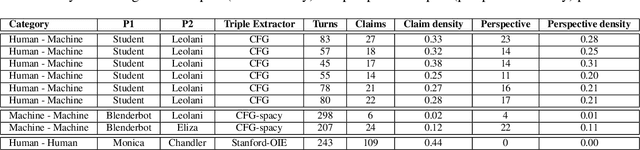
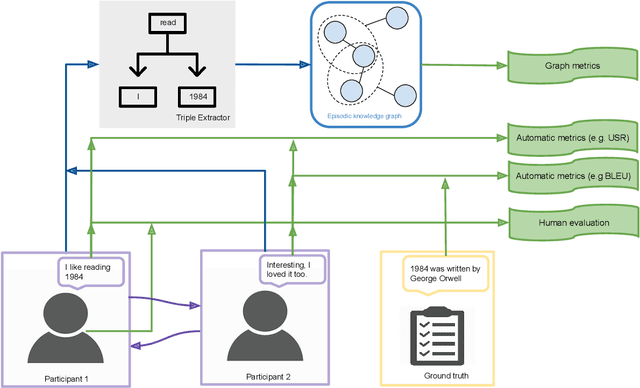
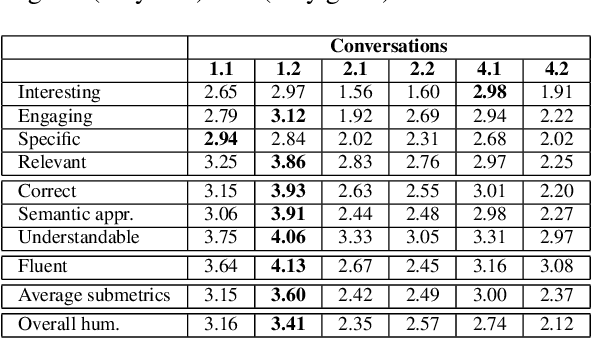
We present a new method based on episodic Knowledge Graphs (eKGs) for evaluating (multimodal) conversational agents in open domains. This graph is generated by interpreting raw signals during conversation and is able to capture the accumulation of knowledge over time. We apply structural and semantic analysis of the resulting graphs and translate the properties into qualitative measures. We compare these measures with existing automatic and manual evaluation metrics commonly used for conversational agents. Our results show that our Knowledge-Graph-based evaluation provides more qualitative insights into interaction and the agent's behavior.
Computing Forward Reachable Sets for Nonlinear Adaptive Multirotor Controllers
Sep 16, 2022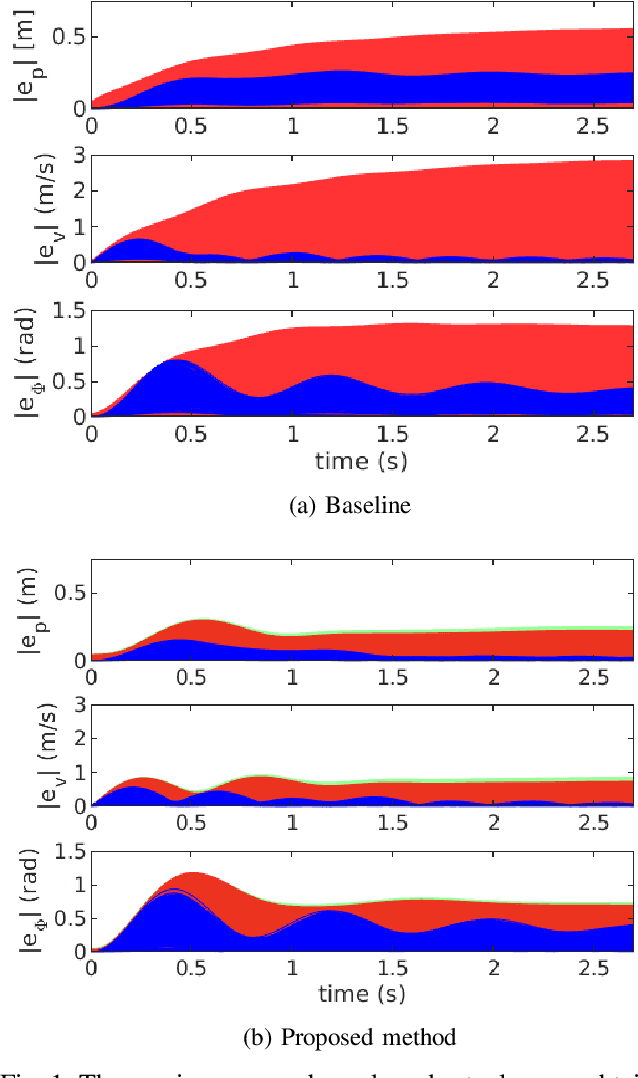
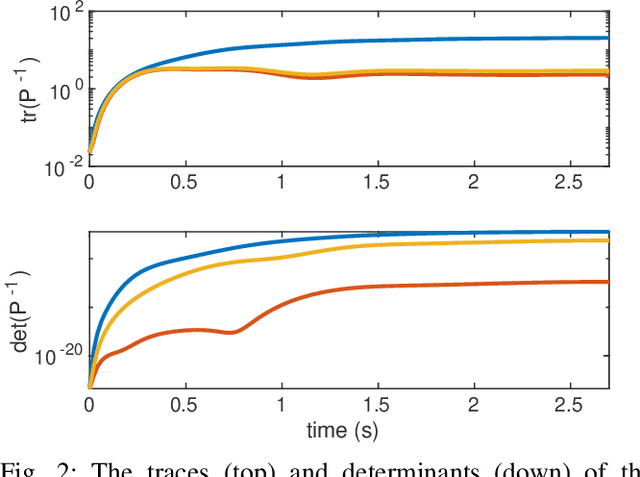
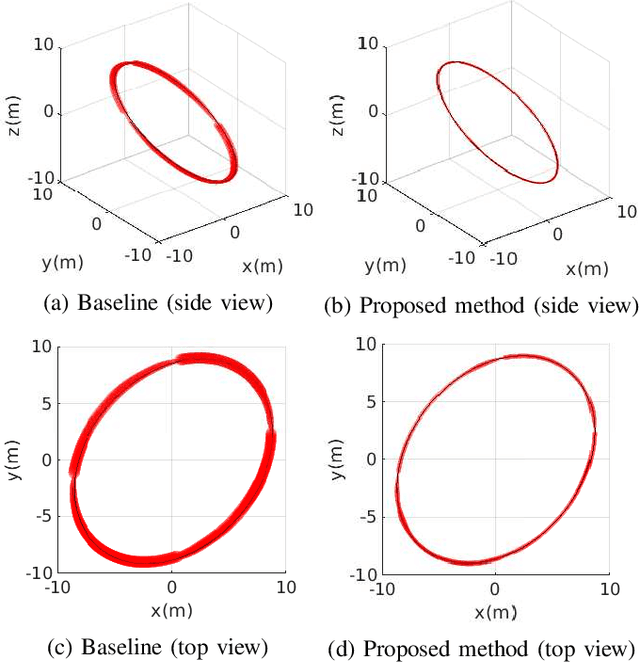
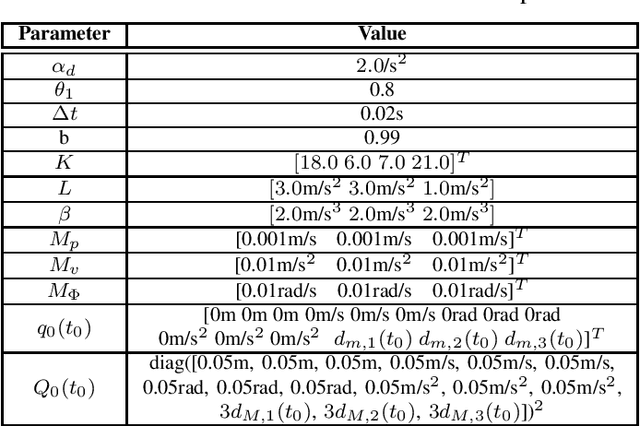
In multirotor systems, guaranteeing safety while considering unknown disturbances is essential for robust trajectory planning. Computing the forward reachable set (FRS), the set of all possible states with bounded disturbances, can be a viable solution to find robust and collision-free trajectories. However, in many cases, the FRS is not calculated in real time and is too conservative to be used in actual applications. In this paper, we mitigate these problems by applying a nonlinear disturbance observer (NDOB) and an adaptive controller to the multirotor system. We formulate the FRS of the closed-loop system combined with the adaptive controller in augmented state space by exploiting the Hamilton-Jacobi reachability analysis and then present the ellipsoidal approximation in a closed-form expression to compute the small FRS in real time. Moreover, tighter disturbance bounds in the prediction horizon are inferred from the NDOB so that a much smaller FRS can be generated. Numerical examples validate the computational efficiency and the smaller scale of the proposed FRS compared to the baseline.
Learning to Reuse Distractors to support Multiple Choice Question Generation in Education
Oct 25, 2022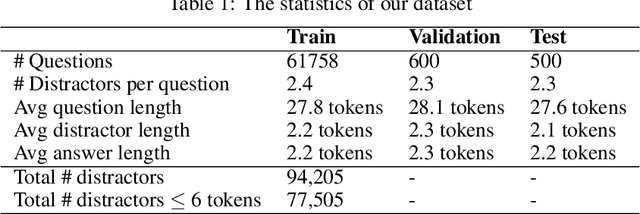
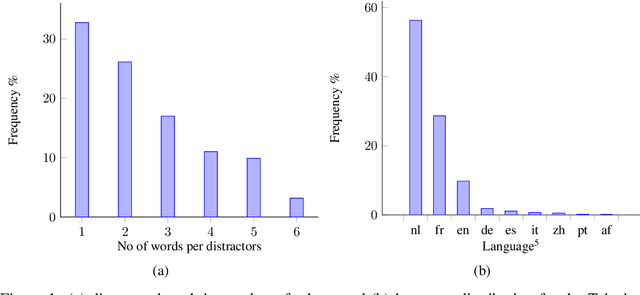
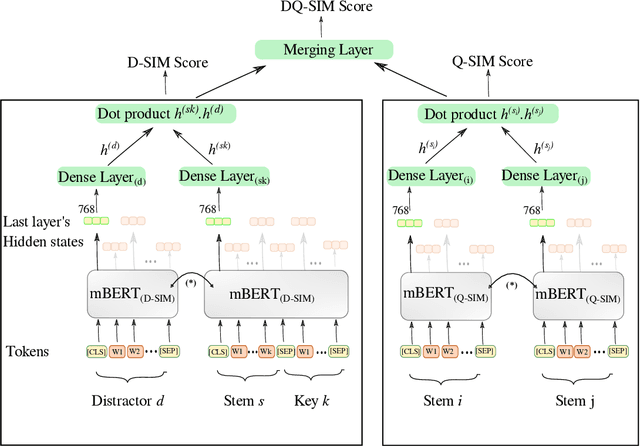

Multiple choice questions (MCQs) are widely used in digital learning systems, as they allow for automating the assessment process. However, due to the increased digital literacy of students and the advent of social media platforms, MCQ tests are widely shared online, and teachers are continuously challenged to create new questions, which is an expensive and time-consuming task. A particularly sensitive aspect of MCQ creation is to devise relevant distractors, i.e., wrong answers that are not easily identifiable as being wrong. This paper studies how a large existing set of manually created answers and distractors for questions over a variety of domains, subjects, and languages can be leveraged to help teachers in creating new MCQs, by the smart reuse of existing distractors. We built several data-driven models based on context-aware question and distractor representations, and compared them with static feature-based models. The proposed models are evaluated with automated metrics and in a realistic user test with teachers. Both automatic and human evaluations indicate that context-aware models consistently outperform a static feature-based approach. For our best-performing context-aware model, on average 3 distractors out of the 10 shown to teachers were rated as high-quality distractors. We create a performance benchmark, and make it public, to enable comparison between different approaches and to introduce a more standardized evaluation of the task. The benchmark contains a test of 298 educational questions covering multiple subjects & languages and a 77k multilingual pool of distractor vocabulary for future research.
Multi-Scale Adaptive Graph Neural Network for Multivariate Time Series Forecasting
Jan 13, 2022
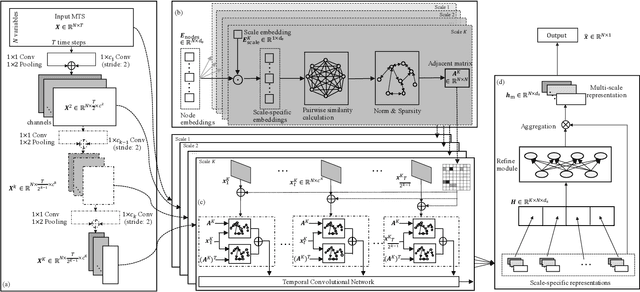
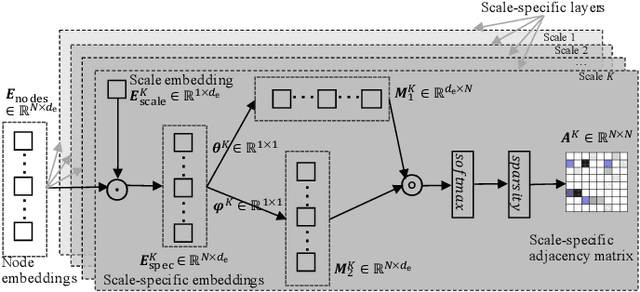
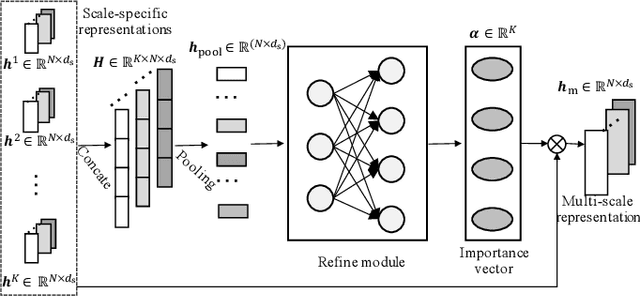
Multivariate time series (MTS) forecasting plays an important role in the automation and optimization of intelligent applications. It is a challenging task, as we need to consider both complex intra-variable dependencies and inter-variable dependencies. Existing works only learn temporal patterns with the help of single inter-variable dependencies. However, there are multi-scale temporal patterns in many real-world MTS. Single inter-variable dependencies make the model prefer to learn one type of prominent and shared temporal patterns. In this paper, we propose a multi-scale adaptive graph neural network (MAGNN) to address the above issue. MAGNN exploits a multi-scale pyramid network to preserve the underlying temporal dependencies at different time scales. Since the inter-variable dependencies may be different under distinct time scales, an adaptive graph learning module is designed to infer the scale-specific inter-variable dependencies without pre-defined priors. Given the multi-scale feature representations and scale-specific inter-variable dependencies, a multi-scale temporal graph neural network is introduced to jointly model intra-variable dependencies and inter-variable dependencies. After that, we develop a scale-wise fusion module to effectively promote the collaboration across different time scales, and automatically capture the importance of contributed temporal patterns. Experiments on four real-world datasets demonstrate that MAGNN outperforms the state-of-the-art methods across various settings.
Towards Adaptive Planning of Assistive-care Robot Tasks
Sep 28, 2022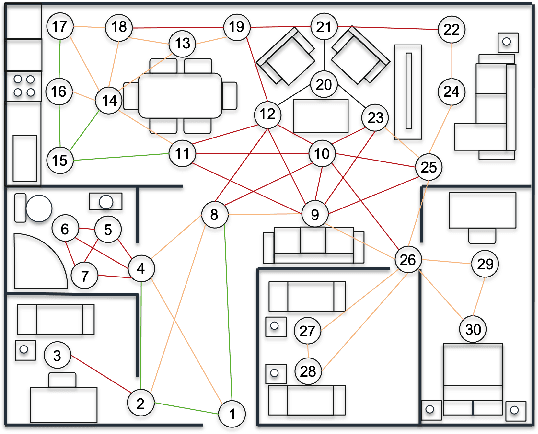

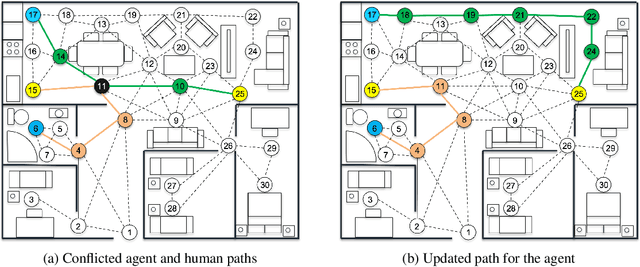
This 'research preview' paper introduces an adaptive path planning framework for robotic mission execution in assistive-care applications. The framework provides a graph-based environment modelling approach, with dynamic path finding performed using Dijkstra's algorithm. A predictive module that uses probabilistic model checking is applied to estimate the human's movement through the environment, allowing run-time re-planning of the robot's path. We illustrate the use of the framework for a simulated assistive-care case study in which a mobile robot navigates through the environment and monitors an end user with mild physical or cognitive impairments.
* In Proceedings FMAS2022 ASYDE2022, arXiv:2209.13181
Neural State-Space Modeling with Latent Causal-Effect Disentanglement
Sep 26, 2022
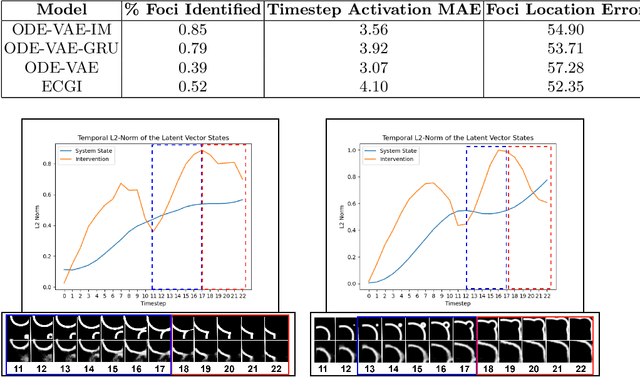


Despite substantial progress in deep learning approaches to time-series reconstruction, no existing methods are designed to uncover local activities with minute signal strength due to their negligible contribution to the optimization loss. Such local activities however can signify important abnormal events in physiological systems, such as an extra foci triggering an abnormal propagation of electrical waves in the heart. We discuss a novel technique for reconstructing such local activity that, while small in signal strength, is the cause of subsequent global activities that have larger signal strength. Our central innovation is to approach this by explicitly modeling and disentangling how the latent state of a system is influenced by potential hidden internal interventions. In a novel neural formulation of state-space models (SSMs), we first introduce causal-effect modeling of the latent dynamics via a system of interacting neural ODEs that separately describes 1) the continuous-time dynamics of the internal intervention, and 2) its effect on the trajectory of the system's native state. Because the intervention can not be directly observed but have to be disentangled from the observed subsequent effect, we integrate knowledge of the native intervention-free dynamics of a system, and infer the hidden intervention by assuming it to be responsible for differences observed between the actual and hypothetical intervention-free dynamics. We demonstrated a proof-of-concept of the presented framework on reconstructing ectopic foci disrupting the course of normal cardiac electrical propagation from remote observations.
TCube: Domain-Agnostic Neural Time-series Narration
Oct 11, 2021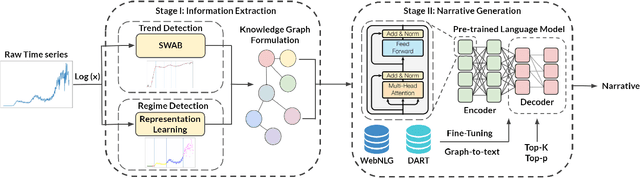
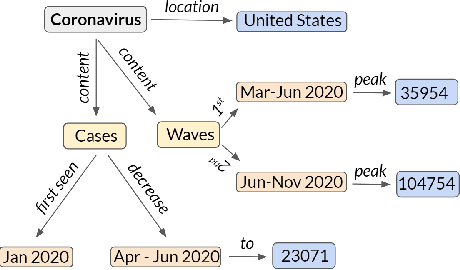
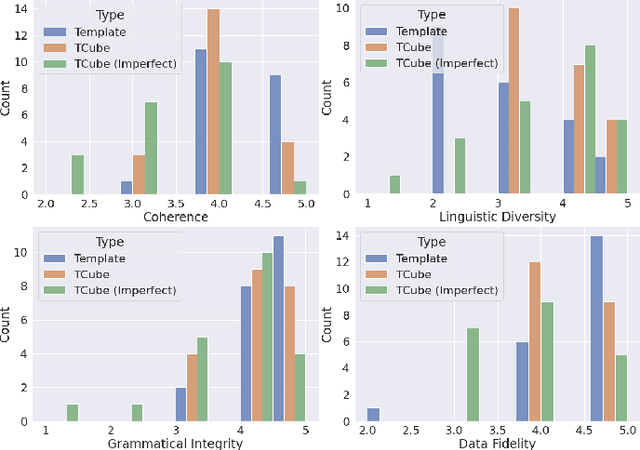
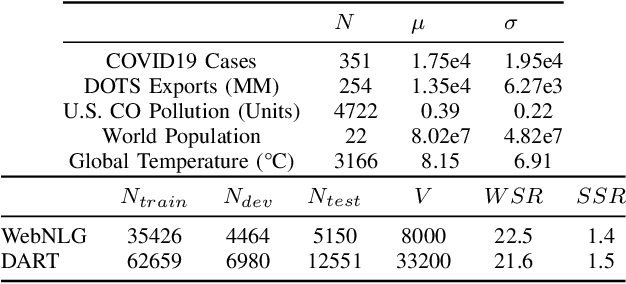
The task of generating rich and fluent narratives that aptly describe the characteristics, trends, and anomalies of time-series data is invaluable to the sciences (geology, meteorology, epidemiology) or finance (trades, stocks, or sales and inventory). The efforts for time-series narration hitherto are domain-specific and use predefined templates that offer consistency but lead to mechanical narratives. We present TCube (Time-series-to-text), a domain-agnostic neural framework for time-series narration, that couples the representation of essential time-series elements in the form of a dense knowledge graph and the translation of said knowledge graph into rich and fluent narratives through the transfer-learning capabilities of PLMs (Pre-trained Language Models). TCube's design primarily addresses the challenge that lies in building a neural framework in the complete paucity of annotated training data for time-series. The design incorporates knowledge graphs as an intermediary for the representation of essential time-series elements which can be linearized for textual translation. To the best of our knowledge, TCube is the first investigation of the use of neural strategies for time-series narration. Through extensive evaluations, we show that TCube can improve the lexical diversity of the generated narratives by up to 65.38% while still maintaining grammatical integrity. The practicality and deployability of TCube is further validated through an expert review (n=21) where 76.2% of participating experts wary of auto-generated narratives favored TCube as a deployable system for time-series narration due to its richer narratives. Our code-base, models, and datasets, with detailed instructions for reproducibility is publicly hosted at https://github.com/Mandar-Sharma/TCube.
Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization
Oct 23, 2022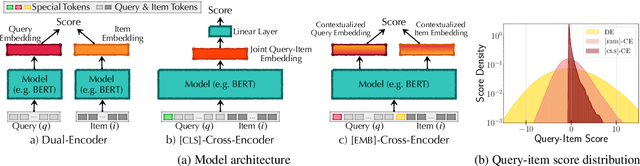
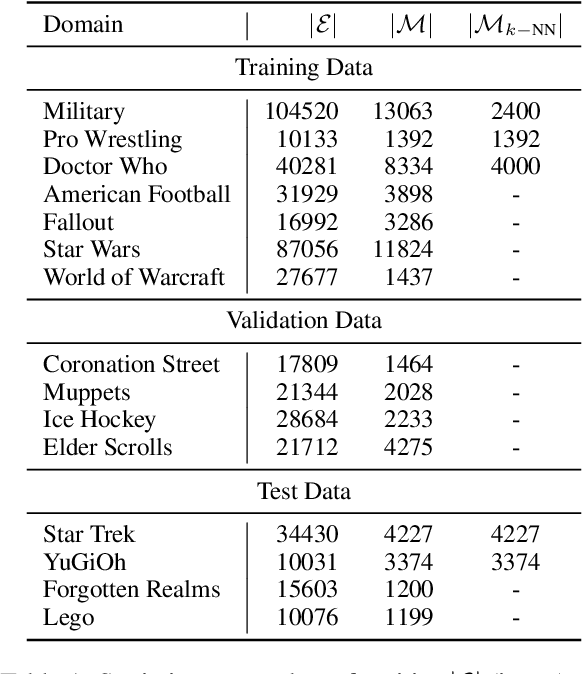

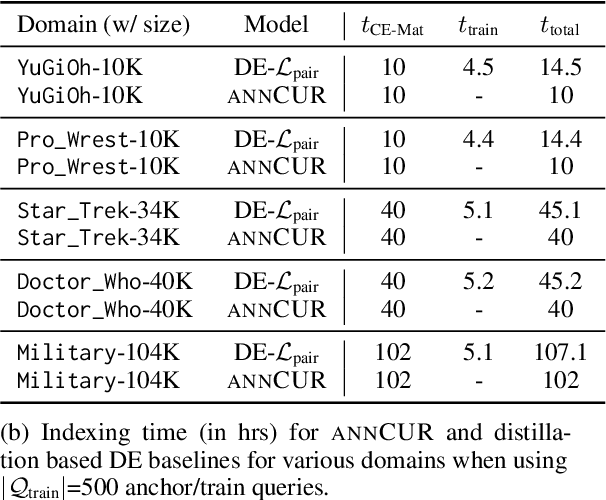
Efficient k-nearest neighbor search is a fundamental task, foundational for many problems in NLP. When the similarity is measured by dot-product between dual-encoder vectors or $\ell_2$-distance, there already exist many scalable and efficient search methods. But not so when similarity is measured by more accurate and expensive black-box neural similarity models, such as cross-encoders, which jointly encode the query and candidate neighbor. The cross-encoders' high computational cost typically limits their use to reranking candidates retrieved by a cheaper model, such as dual encoder or TF-IDF. However, the accuracy of such a two-stage approach is upper-bounded by the recall of the initial candidate set, and potentially requires additional training to align the auxiliary retrieval model with the cross-encoder model. In this paper, we present an approach that avoids the use of a dual-encoder for retrieval, relying solely on the cross-encoder. Retrieval is made efficient with CUR decomposition, a matrix decomposition approach that approximates all pairwise cross-encoder distances from a small subset of rows and columns of the distance matrix. Indexing items using our approach is computationally cheaper than training an auxiliary dual-encoder model through distillation. Empirically, for k > 10, our approach provides test-time recall-vs-computational cost trade-offs superior to the current widely-used methods that re-rank items retrieved using a dual-encoder or TF-IDF.