 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Advancing Biomedical Text Mining with Community Challenges
Mar 07, 2024
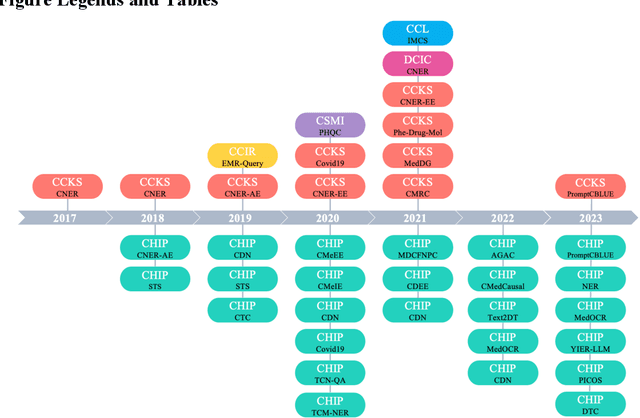
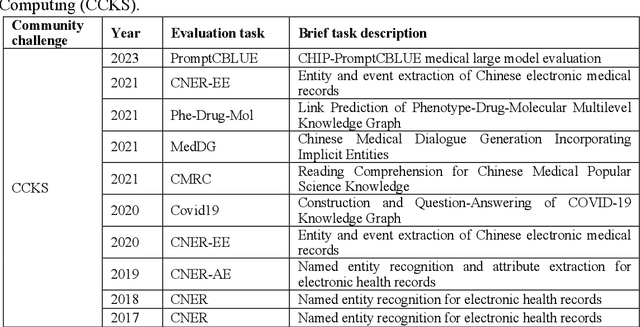
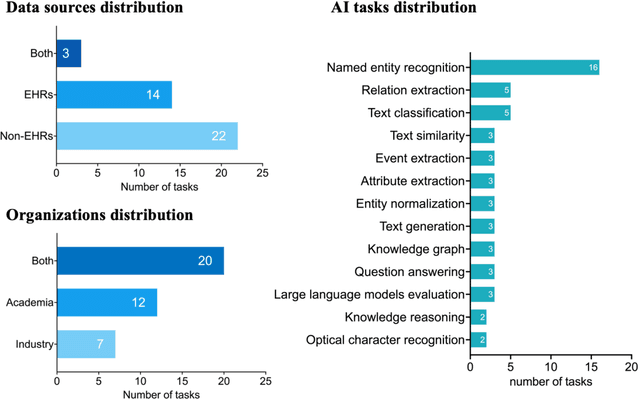
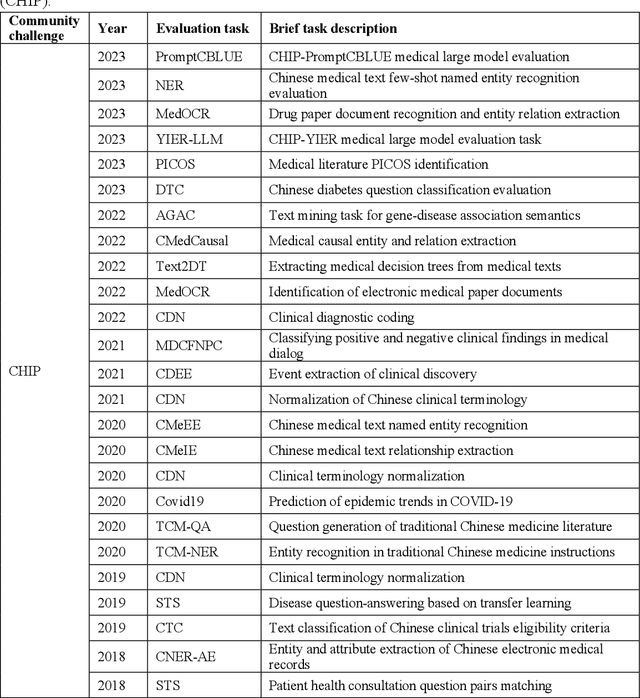
The field of biomedical research has witnessed a significant increase in the accumulation of vast amounts of textual data from various sources such as scientific literatures, electronic health records, clinical trial reports, and social media. However, manually processing and analyzing these extensive and complex resources is time-consuming and inefficient. To address this challenge, biomedical text mining, also known as biomedical natural language processing, has garnered great attention. Community challenge evaluation competitions have played an important role in promoting technology innovation and interdisciplinary collaboration in biomedical text mining research. These challenges provide platforms for researchers to develop state-of-the-art solutions for data mining and information processing in biomedical research. In this article, we review the recent advances in community challenges specific to Chinese biomedical text mining. Firstly, we collect the information of these evaluation tasks, such as data sources and task types. Secondly, we conduct systematic summary and comparative analysis, including named entity recognition, entity normalization, attribute extraction, relation extraction, event extraction, text classification, text similarity, knowledge graph construction, question answering, text generation, and large language model evaluation. Then, we summarize the potential clinical applications of these community challenge tasks from translational informatics perspective. Finally, we discuss the contributions and limitations of these community challenges, while highlighting future directions in the era of large language models.
Optical turbulence profiling at the Table Mountain Facility with the Laser Communication Relay Demonstration GEO downlink
Mar 07, 2024
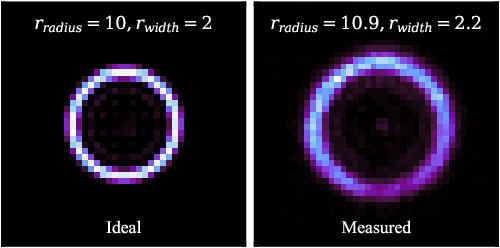
We present the first time the profile of atmospheric optical turbulence has been measured using the transmitted beam from a satellite laser communication terminal. A Ring Image Next Generation Scintillation Sensor (RINGSS) instrument for turbulence profiling, as described in Tokovinin (MNRAS, 502.1, 2021), was deployed at the NASA/Jet Propulsion Laboratory's Table Mountain Facility (TMF) in California. The optical turbulence profile was measured with the downlink optical beam from the Laser Communication Relay Demonstration (LCRD) Geostationary satellite. LCRD conducts links with the Optical Communication Telescope Laboratory ground station and the RINGSS instrument was co-located at TMF to conduct measurements. Turbulence profiles were measured at day and night and atmospheric coherence lengths were compared with other turbulence monitors such as a solar scintillometer and Polaris monitor. RINGSS sensitivity to boundary layer turbulence, a feature not provided by many profilers, is also shown to agree well with a boundary layer scintillometer at TMF. Diurnal evolution of optical turbulence and measured profiles are presented. The robust correlation of RINGSS with other turbulence monitors demonstrates the concept of free-space optical communications turbulence profiling, which could be adopted as a way to support optical ground stations in a future Geostationary feeder link network. These results also provide further evidence that RINGSS, a relatively new instrument concept, is effective even in strong daytime turbulence and with reasonable ground layer sensitivity.
Time-Series Classification for Dynamic Strategies in Multi-Step Forecasting
Feb 13, 2024Multi-step forecasting (MSF) in time-series, the ability to make predictions multiple time steps into the future, is fundamental to almost all temporal domains. To make such forecasts, one must assume the recursive complexity of the temporal dynamics. Such assumptions are referred to as the forecasting strategy used to train a predictive model. Previous work shows that it is not clear which forecasting strategy is optimal a priori to evaluating on unseen data. Furthermore, current approaches to MSF use a single (fixed) forecasting strategy. In this paper, we characterise the instance-level variance of optimal forecasting strategies and propose Dynamic Strategies (DyStrat) for MSF. We experiment using 10 datasets from different scales, domains, and lengths of multi-step horizons. When using a random-forest-based classifier, DyStrat outperforms the best fixed strategy, which is not knowable a priori, 94% of the time, with an average reduction in mean-squared error of 11%. Our approach typically triples the top-1 accuracy compared to current approaches. Notably, we show DyStrat generalises well for any MSF task.
DEMOS: Dynamic Environment Motion Synthesis in 3D Scenes via Local Spherical-BEV Perception
Mar 04, 2024

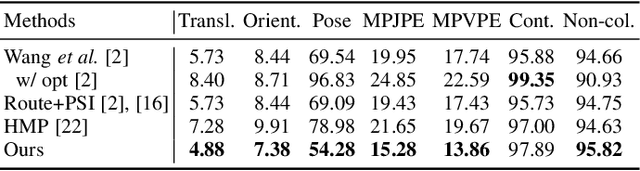
Motion synthesis in real-world 3D scenes has recently attracted much attention. However, the static environment assumption made by most current methods usually cannot be satisfied especially for real-time motion synthesis in scanned point cloud scenes, if multiple dynamic objects exist, e.g., moving persons or vehicles. To handle this problem, we propose the first Dynamic Environment MOtion Synthesis framework (DEMOS) to predict future motion instantly according to the current scene, and use it to dynamically update the latent motion for final motion synthesis. Concretely, we propose a Spherical-BEV perception method to extract local scene features that are specifically designed for instant scene-aware motion prediction. Then, we design a time-variant motion blending to fuse the new predicted motions into the latent motion, and the final motion is derived from the updated latent motions, benefitting both from motion-prior and iterative methods. We unify the data format of two prevailing datasets, PROX and GTA-IM, and take them for motion synthesis evaluation in 3D scenes. We also assess the effectiveness of the proposed method in dynamic environments from GTA-IM and Semantic3D to check the responsiveness. The results show our method outperforms previous works significantly and has great performance in handling dynamic environments.
Time Series Diffusion in the Frequency Domain
Feb 08, 2024Fourier analysis has been an instrumental tool in the development of signal processing. This leads us to wonder whether this framework could similarly benefit generative modelling. In this paper, we explore this question through the scope of time series diffusion models. More specifically, we analyze whether representing time series in the frequency domain is a useful inductive bias for score-based diffusion models. By starting from the canonical SDE formulation of diffusion in the time domain, we show that a dual diffusion process occurs in the frequency domain with an important nuance: Brownian motions are replaced by what we call mirrored Brownian motions, characterized by mirror symmetries among their components. Building on this insight, we show how to adapt the denoising score matching approach to implement diffusion models in the frequency domain. This results in frequency diffusion models, which we compare to canonical time diffusion models. Our empirical evaluation on real-world datasets, covering various domains like healthcare and finance, shows that frequency diffusion models better capture the training distribution than time diffusion models. We explain this observation by showing that time series from these datasets tend to be more localized in the frequency domain than in the time domain, which makes them easier to model in the former case. All our observations point towards impactful synergies between Fourier analysis and diffusion models.
Feedback-Generation for Programming Exercises With GPT-4
Mar 07, 2024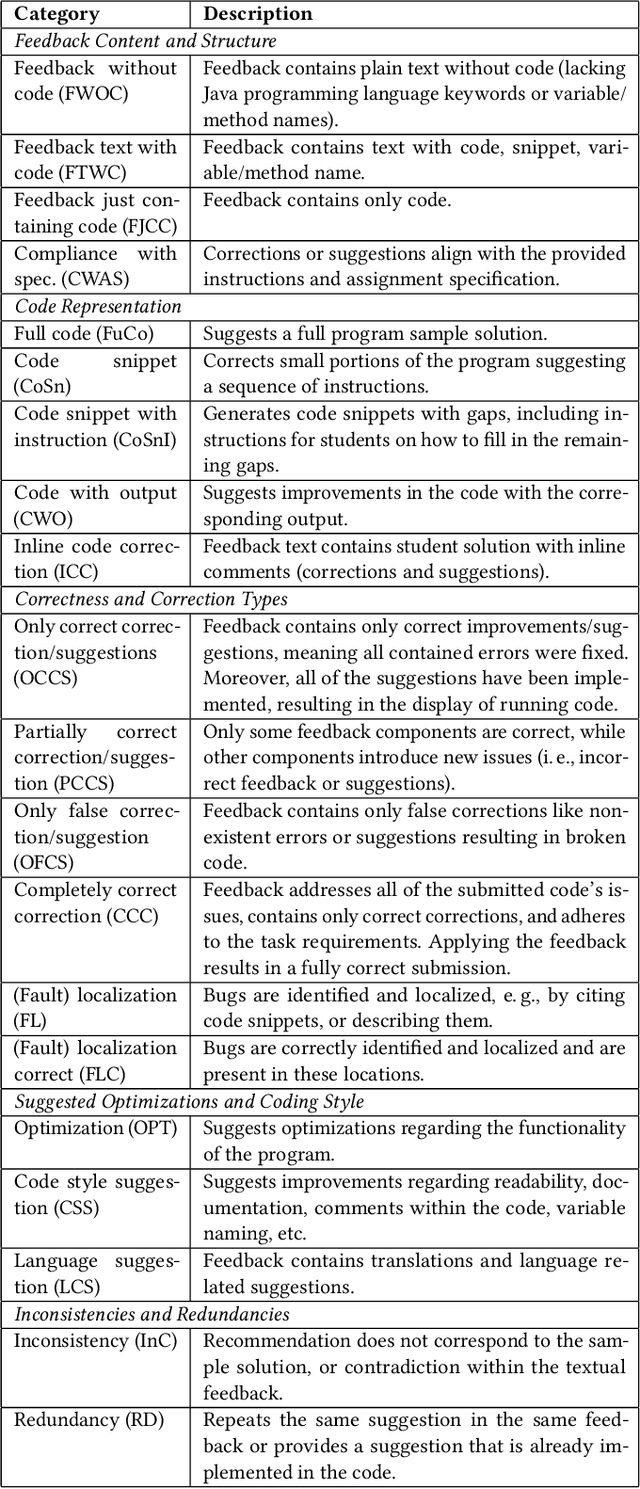
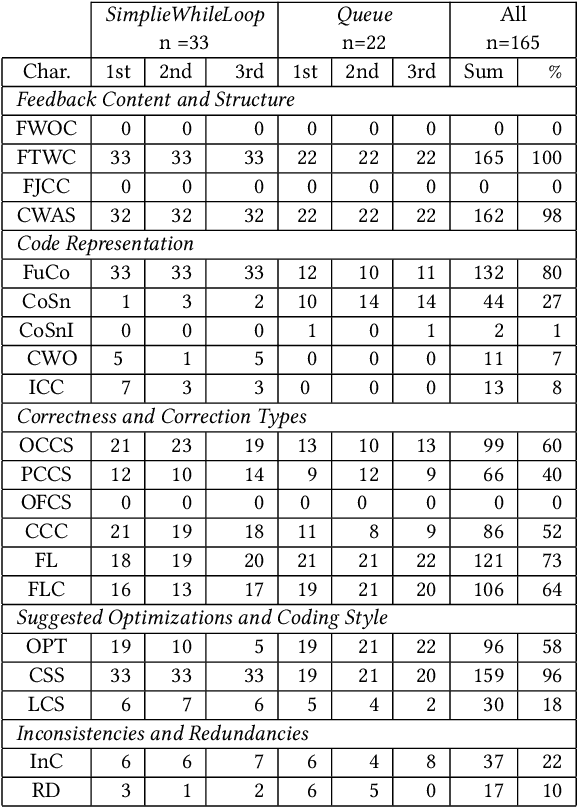
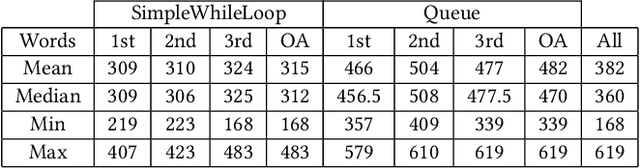
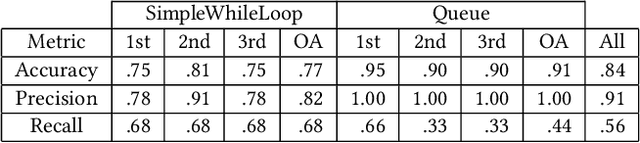
Ever since Large Language Models (LLMs) and related applications have become broadly available, several studies investigated their potential for assisting educators and supporting students in higher education. LLMs such as Codex, GPT-3.5, and GPT 4 have shown promising results in the context of large programming courses, where students can benefit from feedback and hints if provided timely and at scale. This paper explores the quality of GPT-4 Turbo's generated output for prompts containing both the programming task specification and a student's submission as input. Two assignments from an introductory programming course were selected, and GPT-4 was asked to generate feedback for 55 randomly chosen, authentic student programming submissions. The output was qualitatively analyzed regarding correctness, personalization, fault localization, and other features identified in the material. Compared to prior work and analyses of GPT-3.5, GPT-4 Turbo shows notable improvements. For example, the output is more structured and consistent. GPT-4 Turbo can also accurately identify invalid casing in student programs' output. In some cases, the feedback also includes the output of the student program. At the same time, inconsistent feedback was noted such as stating that the submission is correct but an error needs to be fixed. The present work increases our understanding of LLMs' potential, limitations, and how to integrate them into e-assessment systems, pedagogical scenarios, and instructing students who are using applications based on GPT-4.
A Decade of Privacy-Relevant Android App Reviews: Large Scale Trends
Mar 07, 2024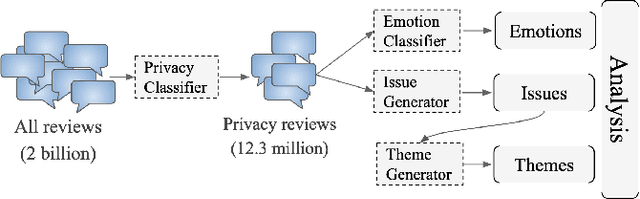

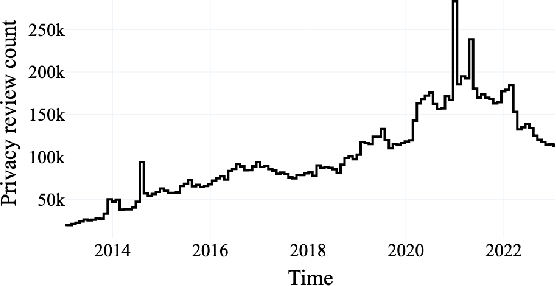
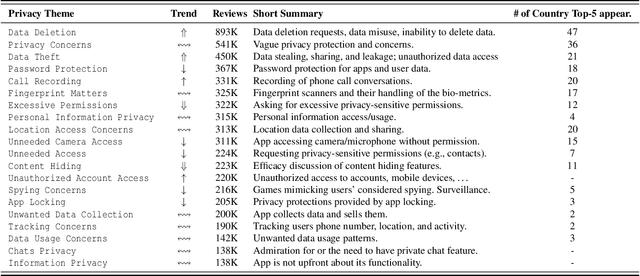
We present an analysis of 12 million instances of privacy-relevant reviews publicly visible on the Google Play Store that span a 10 year period. By leveraging state of the art NLP techniques, we examine what users have been writing about privacy along multiple dimensions: time, countries, app types, diverse privacy topics, and even across a spectrum of emotions. We find consistent growth of privacy-relevant reviews, and explore topics that are trending (such as Data Deletion and Data Theft), as well as those on the decline (such as privacy-relevant reviews on sensitive permissions). We find that although privacy reviews come from more than 200 countries, 33 countries provide 90% of privacy reviews. We conduct a comparison across countries by examining the distribution of privacy topics a country's users write about, and find that geographic proximity is not a reliable indicator that nearby countries have similar privacy perspectives. We uncover some countries with unique patterns and explore those herein. Surprisingly, we uncover that it is not uncommon for reviews that discuss privacy to be positive (32%); many users express pleasure about privacy features within apps or privacy-focused apps. We also uncover some unexpected behaviors, such as the use of reviews to deliver privacy disclaimers to developers. Finally, we demonstrate the value of analyzing app reviews with our approach as a complement to existing methods for understanding users' perspectives about privacy
Improving Uncertainty Sampling with Bell Curve Weight Function
Mar 03, 2024
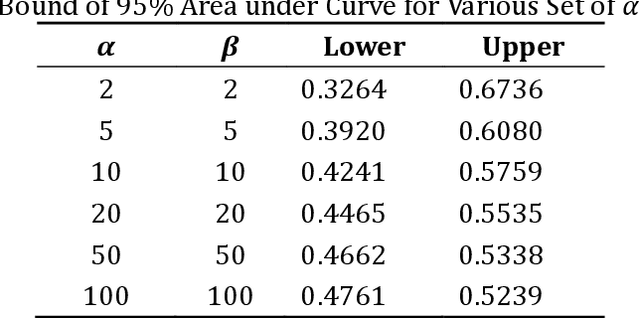
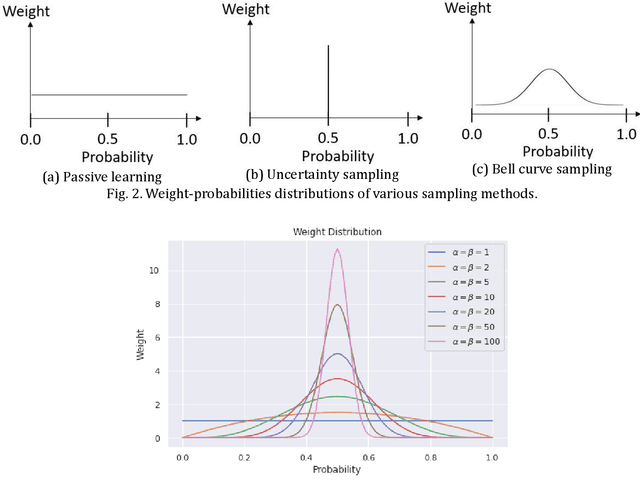
Typically, a supervised learning model is trained using passive learning by randomly selecting unlabelled instances to annotate. This approach is effective for learning a model, but can be costly in cases where acquiring labelled instances is expensive. For example, it can be time-consuming to manually identify spam mails (labelled instances) from thousands of emails (unlabelled instances) flooding an inbox during initial data collection. Generally, we answer the above scenario with uncertainty sampling, an active learning method that improves the efficiency of supervised learning by using fewer labelled instances than passive learning. Given an unlabelled data pool, uncertainty sampling queries the labels of instances where the predicted probabilities, p, fall into the uncertainty region, i.e., $p \approx 0.5$. The newly acquired labels are then added to the existing labelled data pool to learn a new model. Nonetheless, the performance of uncertainty sampling is susceptible to the area of unpredictable responses (AUR) and the nature of the dataset. It is difficult to determine whether to use passive learning or uncertainty sampling without prior knowledge of a new dataset. To address this issue, we propose bell curve sampling, which employs a bell curve weight function to acquire new labels. With the bell curve centred at p=0.5, bell curve sampling selects instances whose predicted values are in the uncertainty area most of the time without neglecting the rest. Simulation results show that, most of the time bell curve sampling outperforms uncertainty sampling and passive learning in datasets of different natures and with AUR.
* 9 pages, 9 figures, journal
Secret-Key Capacity from MIMO Channel Probing
Mar 04, 2024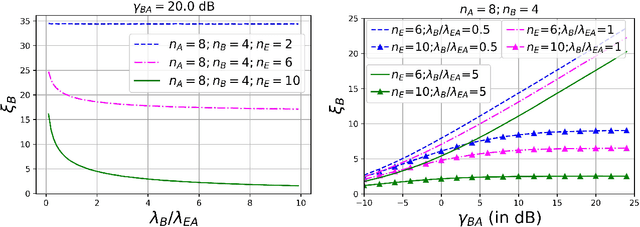
Revealing expressions of secret-key capacity (SKC) based on data sets from Gaussian MIMO channel probing are presented. It is shown that Maurer's upper and lower bounds on SKC coincide when the used data sets are produced from one-way channel probing. As channel coherence time increases, SKC in bits per probing channel use is always lower bounded by a positive value unless eavesdropper's observations are noiseless, which is unlike SKC solely based on reciprocal channels.
IMBUE: Improving Interpersonal Effectiveness through Simulation and Just-in-time Feedback with Human-Language Model Interaction
Feb 19, 2024Navigating certain communication situations can be challenging due to individuals' lack of skills and the interference of strong emotions. However, effective learning opportunities are rarely accessible. In this work, we conduct a human-centered study that uses language models to simulate bespoke communication training and provide just-in-time feedback to support the practice and learning of interpersonal effectiveness skills. We apply the interpersonal effectiveness framework from Dialectical Behavioral Therapy (DBT), DEAR MAN, which focuses on both conversational and emotional skills. We present IMBUE, an interactive training system that provides feedback 25% more similar to experts' feedback, compared to that generated by GPT-4. IMBUE is the first to focus on communication skills and emotion management simultaneously, incorporate experts' domain knowledge in providing feedback, and be grounded in psychology theory. Through a randomized trial of 86 participants, we find that IMBUE's simulation-only variant significantly improves participants' self-efficacy (up to 17%) and reduces negative emotions (up to 25%). With IMBUE's additional just-in-time feedback, participants demonstrate 17% improvement in skill mastery, along with greater enhancements in self-efficacy (27% more) and reduction of negative emotions (16% more) compared to simulation-only. The improvement in skill mastery is the only measure that is transferred to new and more difficult situations; situation specific training is necessary for improving self-efficacy and emotion reduction.