 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Model Predictive Control Functional Continuous Time Bayesian Network for Self-Management of Multiple Chronic Conditions
May 26, 2022
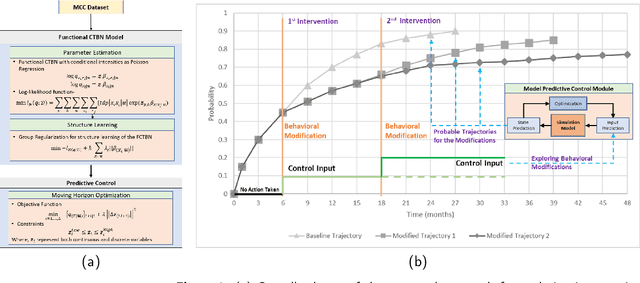
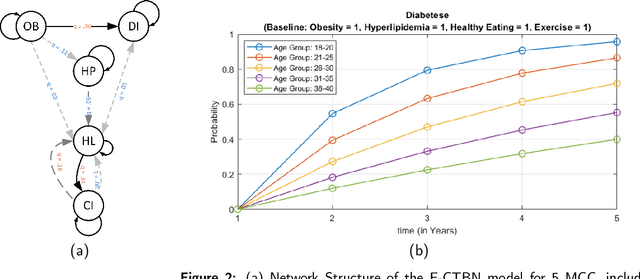
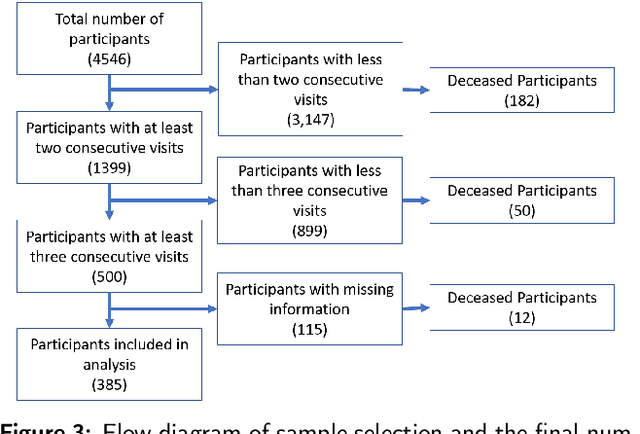
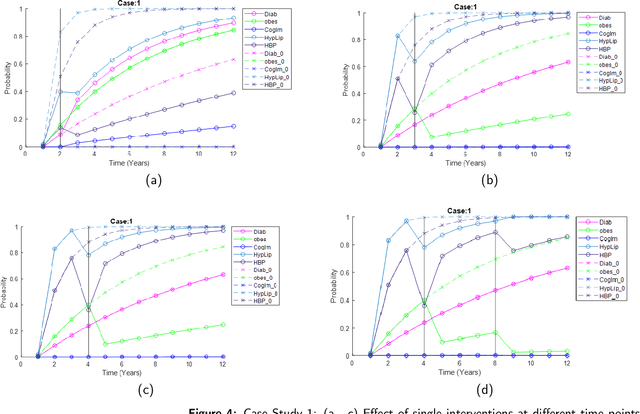
Multiple chronic conditions (MCC) are one of the biggest challenges of modern times. The evolution of MCC follows a complex stochastic process that is influenced by a variety of risk factors, ranging from pre-existing conditions to modifiable lifestyle behavioral factors (e.g. diet, exercise habits, tobacco use, alcohol use, etc.) to non-modifiable socio-demographic factors (e.g., age, gender, education, marital status, etc.). People with MCC are at an increased risk of new chronic conditions and mortality. This paper proposes a model predictive control functional continuous time Bayesian network, an online recursive method to examine the impact of various lifestyle behavioral changes on the emergence trajectories of MCC and generate strategies to minimize the risk of progression of chronic conditions in individual patients. The proposed method is validated based on the Cameron county Hispanic cohort (CCHC) dataset, which has a total of 385 patients. The dataset examines the emergence of 5 chronic conditions (diabetes, obesity, cognitive impairment, hyperlipidemia, and hypertension) based on four modifiable risk factors representing lifestyle behaviors (diet, exercise habits, tobacco use, alcohol use) and four non-modifiable risk factors, including socio-demographic information (age, gender, education, marital status). The proposed method is tested under different scenarios (e.g., age group, the prior existence of MCC), demonstrating the effective intervention strategies for improving the lifestyle behavioral risk factors to offset MCC evolution.
Structured Optimal Variational Inference for Dynamic Latent Space Models
Sep 29, 2022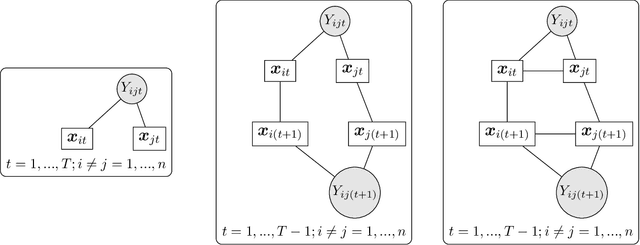
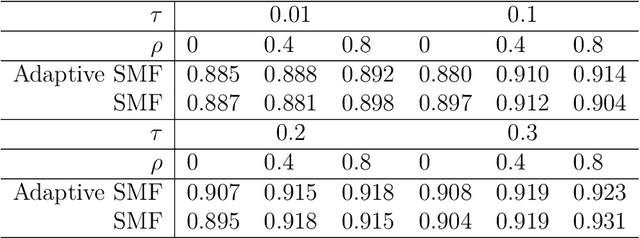
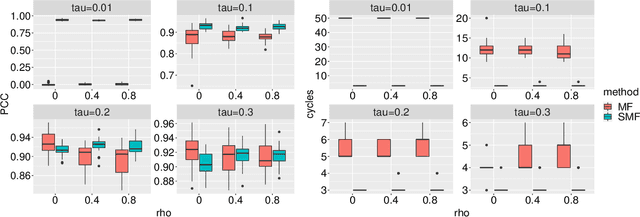

We consider a latent space model for dynamic networks, where our objective is to estimate the pairwise inner products of the latent positions. To balance posterior inference and computational scalability, we present a structured mean-field variational inference framework, where the time-dependent properties of the dynamic networks are exploited to facilitate computation and inference. Additionally, an easy-to-implement block coordinate ascent algorithm is developed with message-passing type updates in each block, whereas the complexity per iteration is linear with the number of nodes and time points. To facilitate learning of the pairwise latent distances, we adopt a Gamma prior for the transition variance different from the literature. To certify the optimality, we demonstrate that the variational risk of the proposed variational inference approach attains the minimax optimal rate under certain conditions. En route, we derive the minimax lower bound, which might be of independent interest. To best of our knowledge, this is the first such exercise for dynamic latent space models. Simulations and real data analysis demonstrate the efficacy of our methodology and the efficiency of our algorithm. Finally, our proposed methodology can be readily extended to the case where the scales of the latent nodes are learned in a nodewise manner.
Don't Waste Data: Transfer Learning to Leverage All Data for Machine-Learnt Climate Model Emulation
Oct 08, 2022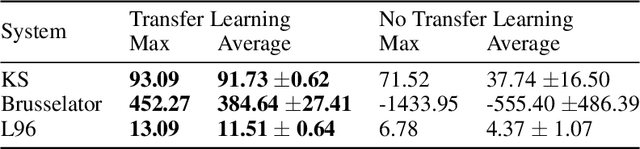
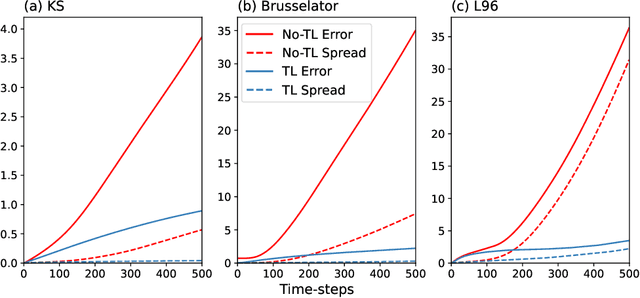
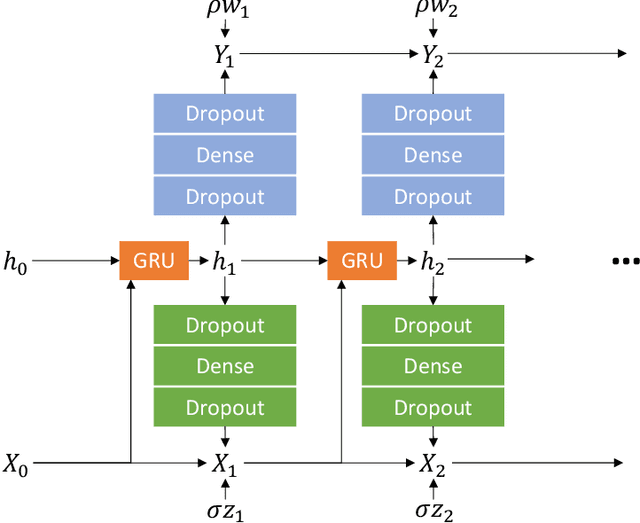

How can we learn from all available data when training machine-learnt climate models, without incurring any extra cost at simulation time? Typically, the training data comprises coarse-grained high-resolution data. But only keeping this coarse-grained data means the rest of the high-resolution data is thrown out. We use a transfer learning approach, which can be applied to a range of machine learning models, to leverage all the high-resolution data. We use three chaotic systems to show it stabilises training, gives improved generalisation performance and results in better forecasting skill. Our anonymised code is at https://www.dropbox.com/sh/0o1pks1i90mix3q/AAAMGfyD7EyOkdnA_Hp5ZpiWa?dl=0
Least-squares methods for nonnegative matrix factorization over rational functions
Sep 26, 2022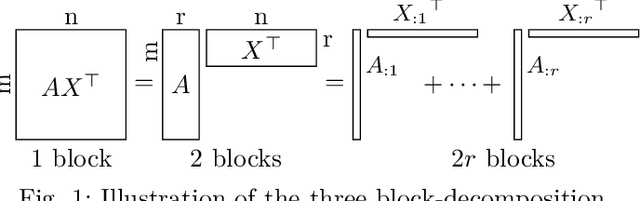
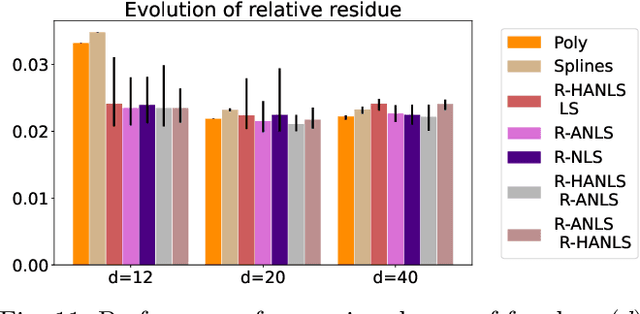
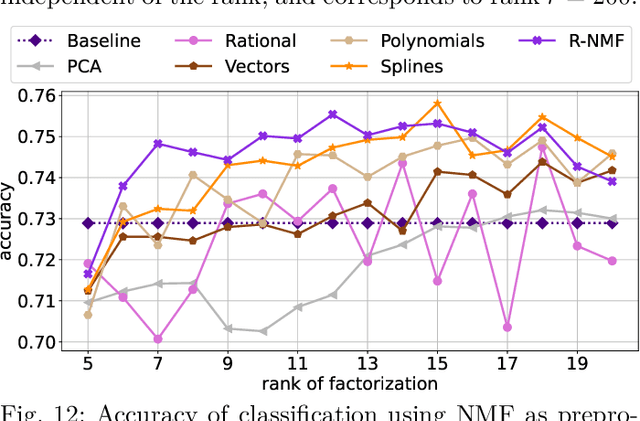
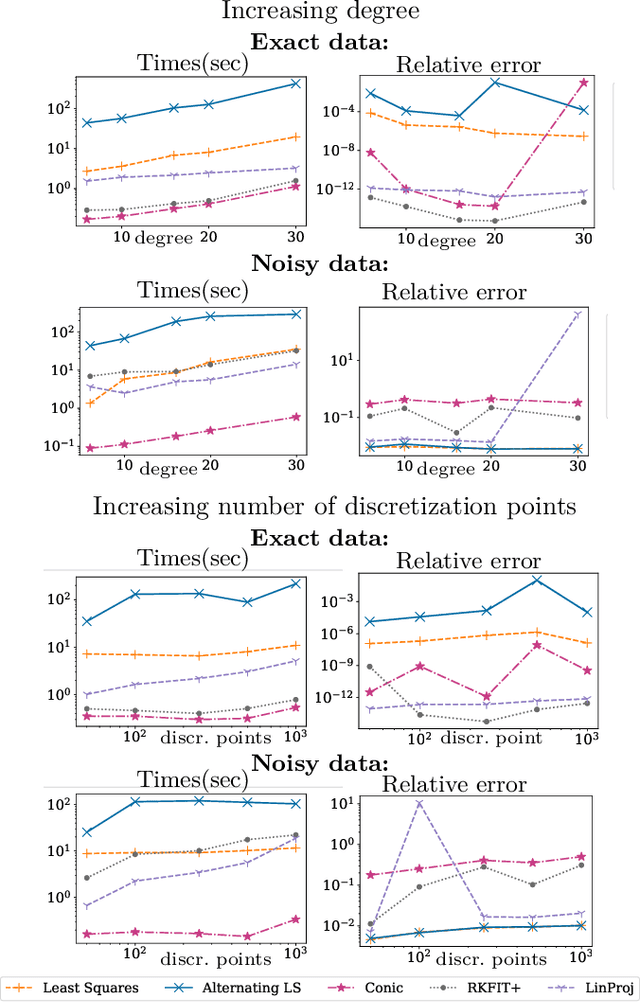
Nonnegative Matrix Factorization (NMF) models are widely used to recover linearly mixed nonnegative data. When the data is made of samplings of continuous signals, the factors in NMF can be constrained to be samples of nonnegative rational functions, which allow fairly general models; this is referred to as NMF using rational functions (R-NMF). We first show that, under mild assumptions, R-NMF has an essentially unique factorization unlike NMF, which is crucial in applications where ground-truth factors need to be recovered such as blind source separation problems. Then we present different approaches to solve R-NMF: the R-HANLS, R-ANLS and R-NLS methods. From our tests, no method significantly outperforms the others, and a trade-off should be done between time and accuracy. Indeed, R-HANLS is fast and accurate for large problems, while R-ANLS is more accurate, but also more resources demanding, both in time and memory. R-NLS is very accurate but only for small problems. Moreover, we show that R-NMF outperforms NMF in various tasks including the recovery of semi-synthetic continuous signals, and a classification problem of real hyperspectral signals.
Fast Yet Effective Speech Emotion Recognition with Self-distillation
Oct 26, 2022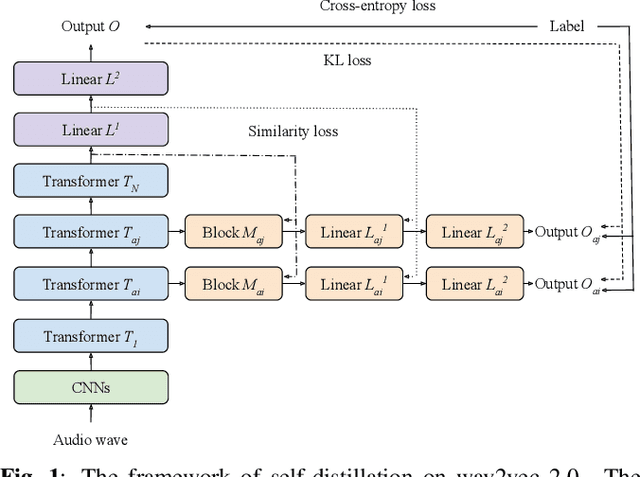
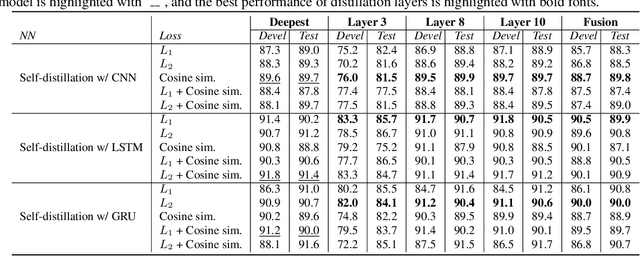
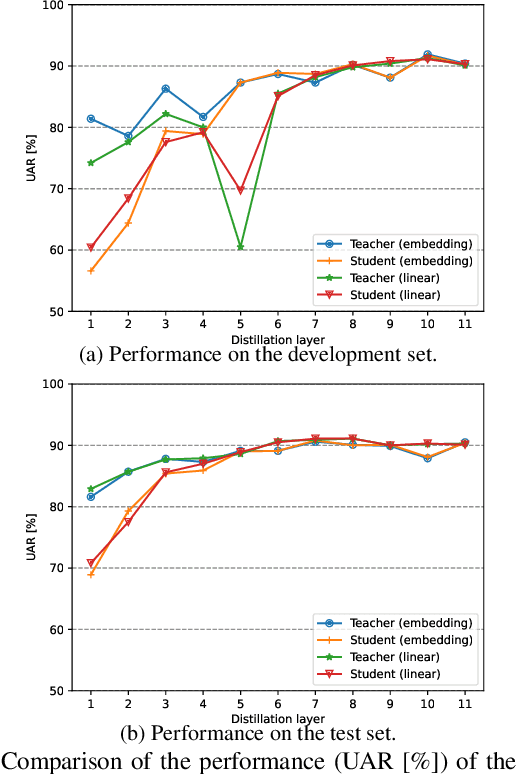
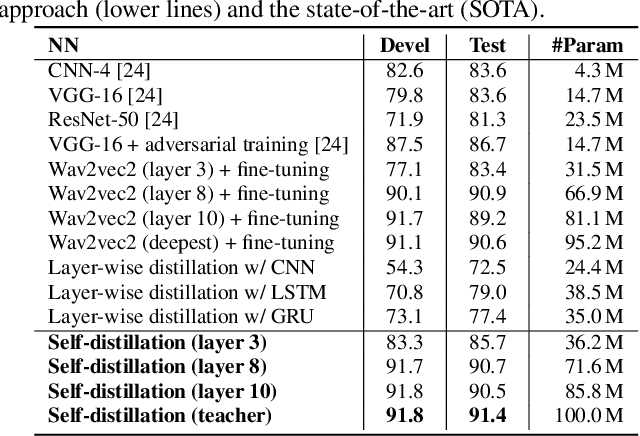
Speech emotion recognition (SER) is the task of recognising human's emotional states from speech. SER is extremely prevalent in helping dialogue systems to truly understand our emotions and become a trustworthy human conversational partner. Due to the lengthy nature of speech, SER also suffers from the lack of abundant labelled data for powerful models like deep neural networks. Pre-trained complex models on large-scale speech datasets have been successfully applied to SER via transfer learning. However, fine-tuning complex models still requires large memory space and results in low inference efficiency. In this paper, we argue achieving a fast yet effective SER is possible with self-distillation, a method of simultaneously fine-tuning a pretrained model and training shallower versions of itself. The benefits of our self-distillation framework are threefold: (1) the adoption of self-distillation method upon the acoustic modality breaks through the limited ground-truth of speech data, and outperforms the existing models' performance on an SER dataset; (2) executing powerful models at different depth can achieve adaptive accuracy-efficiency trade-offs on resource-limited edge devices; (3) a new fine-tuning process rather than training from scratch for self-distillation leads to faster learning time and the state-of-the-art accuracy on data with small quantities of label information.
Disentangling Past-Future Modeling in Sequential Recommendation via Dual Networks
Oct 26, 2022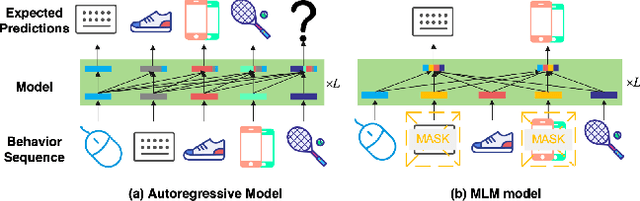
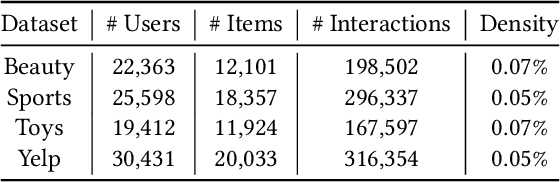
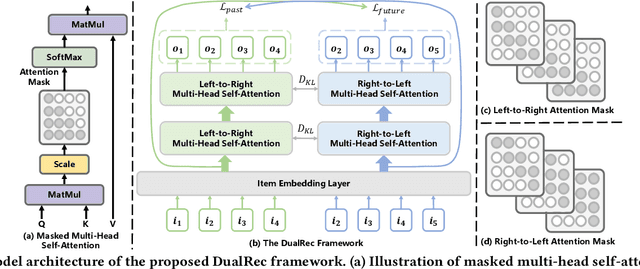
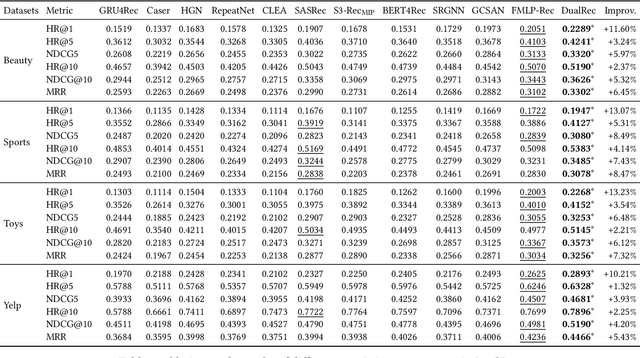
Sequential recommendation (SR) plays an important role in personalized recommender systems because it captures dynamic and diverse preferences from users' real-time increasing behaviors. Unlike the standard autoregressive training strategy, future data (also available during training) has been used to facilitate model training as it provides richer signals about user's current interests and can be used to improve the recommendation quality. However, these methods suffer from a severe training-inference gap, i.e., both past and future contexts are modeled by the same encoder when training, while only historical behaviors are available during inference. This discrepancy leads to potential performance degradation. To alleviate the training-inference gap, we propose a new framework DualRec, which achieves past-future disentanglement and past-future mutual enhancement by a novel dual network. Specifically, a dual network structure is exploited to model the past and future context separately. And a bi-directional knowledge transferring mechanism enhances the knowledge learnt by the dual network. Extensive experiments on four real-world datasets demonstrate the superiority of our approach over baseline methods. Besides, we demonstrate the compatibility of DualRec by instantiating using RNN, Transformer, and filter-MLP as backbones. Further empirical analysis verifies the high utility of modeling future contexts under our DualRec framework.
Adaptive deep density approximation for fractional Fokker-Planck equations
Oct 26, 2022
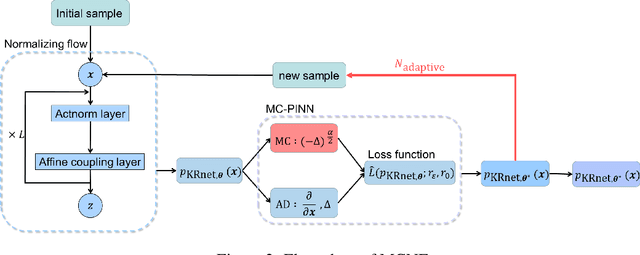
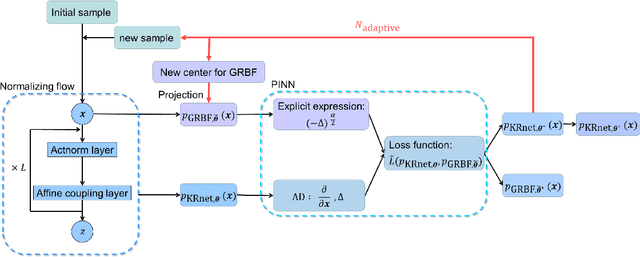
In this work, we propose adaptive deep learning approaches based on normalizing flows for solving fractional Fokker-Planck equations (FPEs). The solution of a FPE is a probability density function (PDF). Traditional mesh-based methods are ineffective because of the unbounded computation domain, a large number of dimensions and the nonlocal fractional operator. To this end, we represent the solution with an explicit PDF model induced by a flow-based deep generative model, simplified KRnet, which constructs a transport map from a simple distribution to the target distribution. We consider two methods to approximate the fractional Laplacian. One method is the Monte Carlo approximation. The other method is to construct an auxiliary model with Gaussian radial basis functions (GRBFs) to approximate the solution such that we may take advantage of the fact that the fractional Laplacian of a Gaussian is known analytically. Based on these two different ways for the approximation of the fractional Laplacian, we propose two models, MCNF and GRBFNF, to approximate stationary FPEs and MCTNF to approximate time-dependent FPEs. To further improve the accuracy, we refine the training set and the approximate solution alternately. A variety of numerical examples is presented to demonstrate the effectiveness of our adaptive deep density approaches.
Piloting Copilot and Codex: Hot Temperature, Cold Prompts, or Black Magic?
Oct 26, 2022
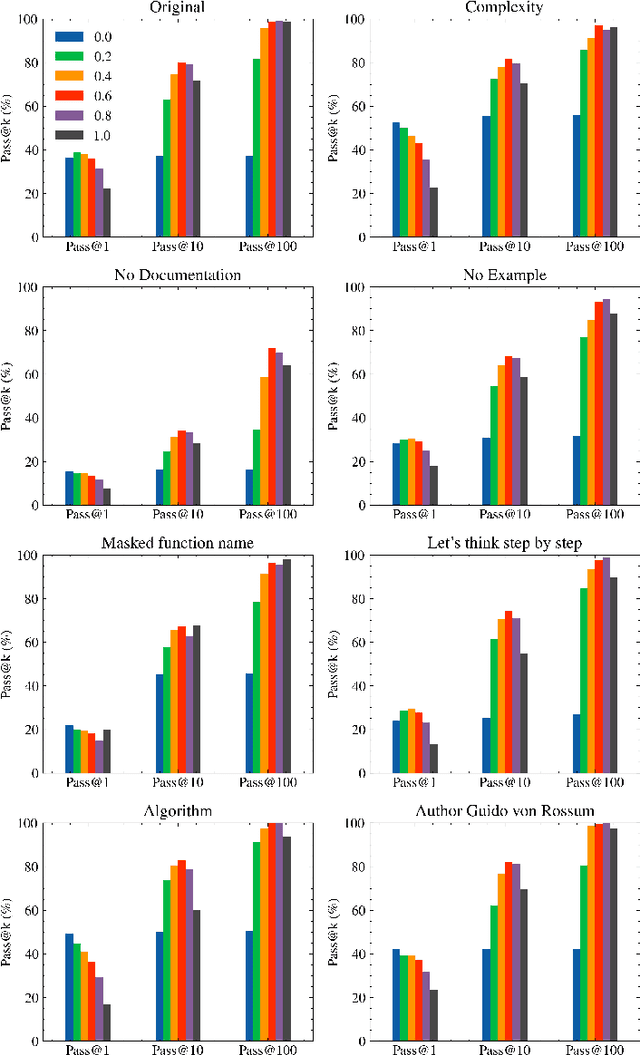
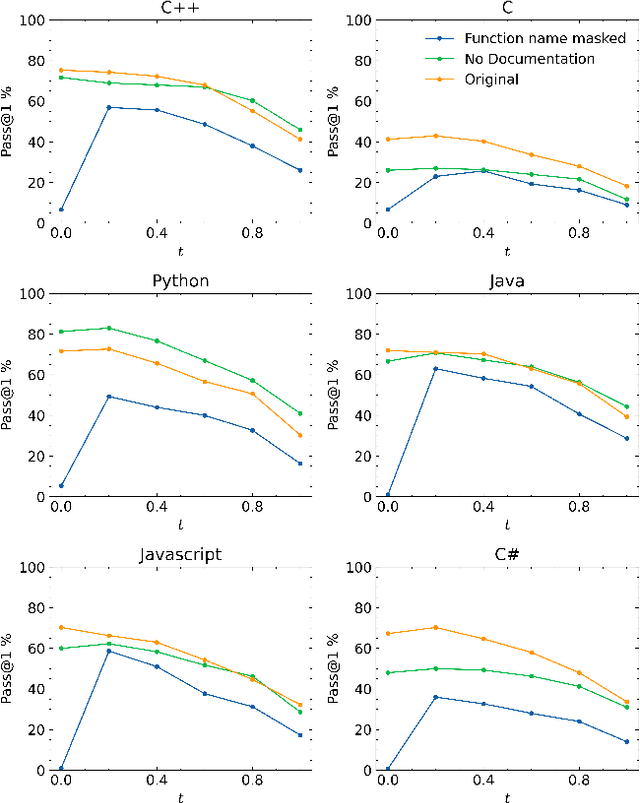

Language models are promising solutions for tackling increasing complex problems. In software engineering, they recently attracted attention in code assistants, with programs automatically written in a given programming language from a programming task description in natural language. They have the potential to save time and effort when writing code. However, these systems are currently poorly understood, preventing them from being used optimally. In this paper, we investigate the various input parameters of two language models, and conduct a study to understand if variations of these input parameters (e.g. programming task description and the surrounding context, creativity of the language model, number of generated solutions) can have a significant impact on the quality of the generated programs. We design specific operators for varying input parameters and apply them over two code assistants (Copilot and Codex) and two benchmarks representing algorithmic problems (HumanEval and LeetCode). Our results showed that varying the input parameters can significantly improve the performance of language models. However, there is a tight dependency when varying the temperature, the prompt and the number of generated solutions, making potentially hard for developers to properly control the parameters to obtain an optimal result. This work opens opportunities to propose (automated) strategies for improving performance.
Graph-Regularized Tensor Regression: A Domain-Aware Framework for Interpretable Multi-Way Financial Modelling
Oct 26, 2022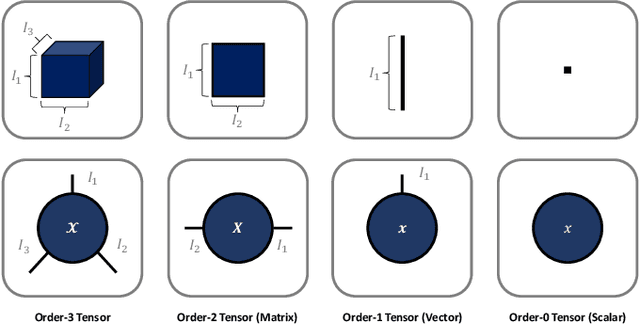
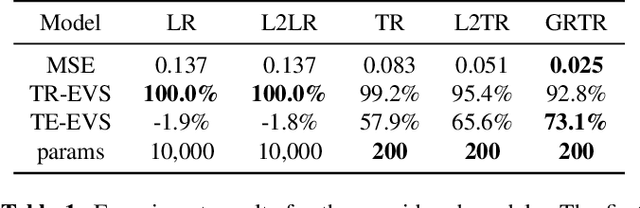
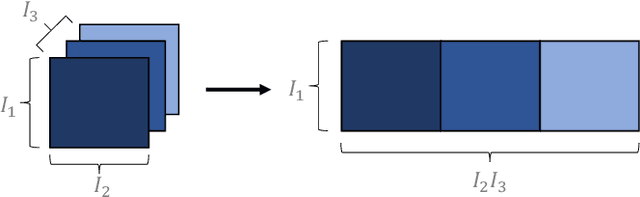
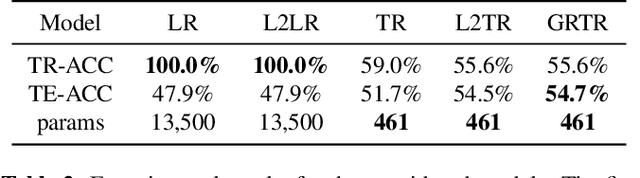
Analytics of financial data is inherently a Big Data paradigm, as such data are collected over many assets, asset classes, countries, and time periods. This represents a challenge for modern machine learning models, as the number of model parameters needed to process such data grows exponentially with the data dimensions; an effect known as the Curse-of-Dimensionality. Recently, Tensor Decomposition (TD) techniques have shown promising results in reducing the computational costs associated with large-dimensional financial models while achieving comparable performance. However, tensor models are often unable to incorporate the underlying economic domain knowledge. To this end, we develop a novel Graph-Regularized Tensor Regression (GRTR) framework, whereby knowledge about cross-asset relations is incorporated into the model in the form of a graph Laplacian matrix. This is then used as a regularization tool to promote an economically meaningful structure within the model parameters. By virtue of tensor algebra, the proposed framework is shown to be fully interpretable, both coefficient-wise and dimension-wise. The GRTR model is validated in a multi-way financial forecasting setting and compared against competing models, and is shown to achieve improved performance at reduced computational costs. Detailed visualizations are provided to help the reader gain an intuitive understanding of the employed tensor operations.
HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
Oct 26, 2022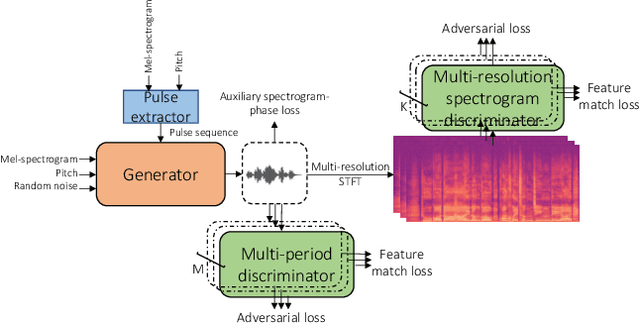
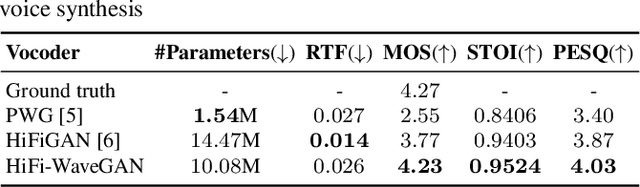
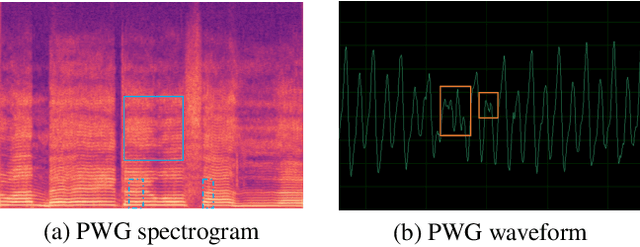
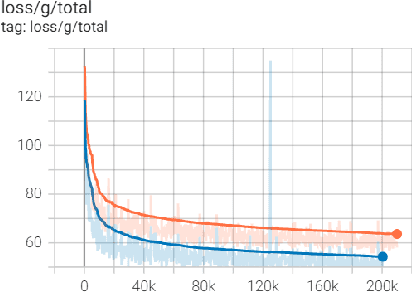
Entertainment-oriented singing voice synthesis (SVS) requires a vocoder to generate high-fidelity (e.g. 48kHz) audio. However, most text-to-speech (TTS) vocoders cannot work well in this scenario even if the neural vocoder for TTS has achieved significant progress. In this paper, we propose HiFi-WaveGAN which is designed for synthesizing the 48kHz high-quality singing voices from the full-band mel-spectrogram in real-time. Specifically, it consists of a generator improved from WaveNet, a multi-period discriminator same to HiFiGAN, and a multi-resolution spectrogram discriminator borrowed from UnivNet. To better reconstruct the high-frequency part from the full-band mel-spectrogram, we design a novel auxiliary spectrogram-phase loss to train the neural network, which can also accelerate the training process. The experimental result shows that our proposed HiFi-WaveGAN significantly outperforms other neural vocoders such as Parallel WaveGAN (PWG) and HiFiGAN in the mean opinion score (MOS) metric for the 48kHz SVS task. And a comparative study of HiFi-WaveGAN with/without phase loss term proves that phase loss indeed improves the training speed. Besides, we also compare the spectrogram generated by our HiFi-WaveGAN and PWG, which shows our HiFi-WaveGAN has a more powerful ability to model the high-frequency parts.