 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Oct 31, 2022
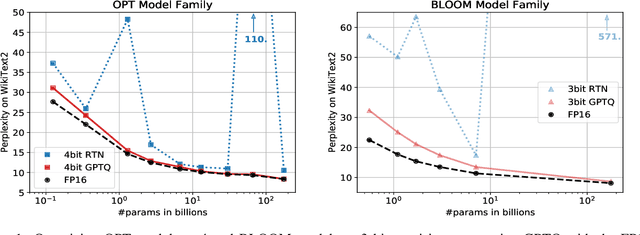

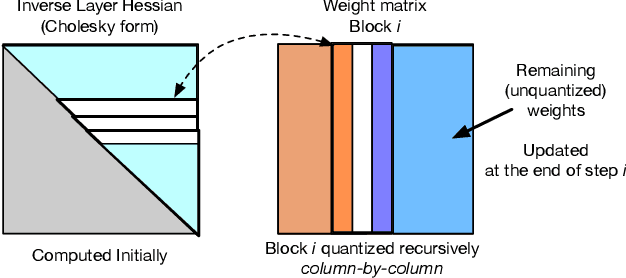
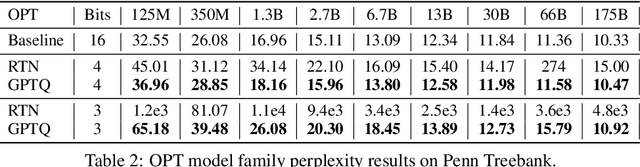
Generative Pre-trained Transformer (GPT) models set themselves apart through breakthrough performance across complex language modelling tasks, but also by their extremely high computational and storage costs. Specifically, due to their massive size, even inference for large, highly-accurate GPT models may require multiple performant GPUs to execute, which limits the usability of such models. While there is emerging work on relieving this pressure via model compression, the applicability and performance of existing compression techniques is limited by the scale and complexity of GPT models. In this paper, we address this challenge, and propose GPTQ, a new one-shot weight quantization method based on approximate second-order information, that is both highly-accurate and highly-efficient. Specifically, GPTQ can quantize GPT models with 175 billion parameters in approximately four GPU hours, reducing the bitwidth down to 3 or 4 bits per weight, with negligible accuracy degradation relative to the uncompressed baseline. Our method more than doubles the compression gains relative to previously-proposed one-shot quantization methods, preserving accuracy, allowing us for the first time to execute an 175 billion-parameter model inside a single GPU. We show experimentally that these improvements can be leveraged for end-to-end inference speedups over FP16, of around 2x when using high-end GPUs (NVIDIA A100) and 4x when using more cost-effective ones (NVIDIA A6000). The implementation is available at https://github.com/IST-DASLab/gptq.
FusionFormer: Fusing Operations in Transformer for Efficient Streaming Speech Recognition
Oct 31, 2022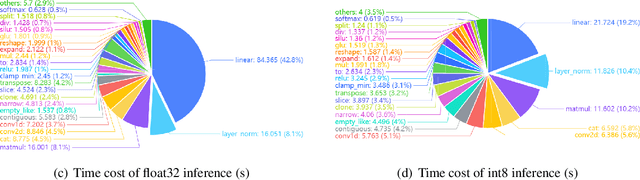

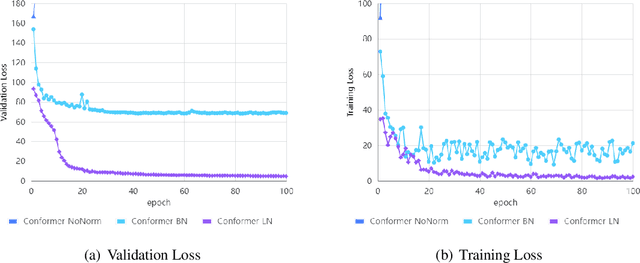
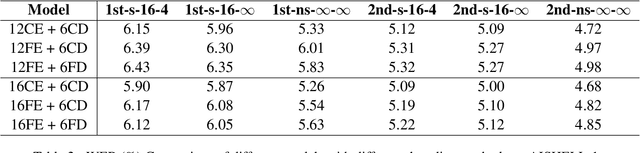
The recently proposed Conformer architecture which combines convolution with attention to capture both local and global dependencies has become the \textit{de facto} backbone model for Automatic Speech Recognition~(ASR). Inherited from the Natural Language Processing (NLP) tasks, the architecture takes Layer Normalization~(LN) as a default normalization technique. However, through a series of systematic studies, we find that LN might take 10\% of the inference time despite that it only contributes to 0.1\% of the FLOPs. This motivates us to replace LN with other normalization techniques, e.g., Batch Normalization~(BN), to speed up inference with the help of operator fusion methods and the avoidance of calculating the mean and variance statistics during inference. After examining several plain attempts which directly remove all LN layers or replace them with BN in the same place, we find that the divergence issue is mainly caused by the unstable layer output. We therefore propose to append a BN layer to each linear or convolution layer where stabilized training results are observed. We also propose to simplify the activations in Conformer, such as Swish and GLU, by replacing them with ReLU. All these exchanged modules can be fused into the weights of the adjacent linear/convolution layers and hence have zero inference cost. Therefore, we name it FusionFormer. Our experiments indicate that FusionFormer is as effective as the LN-based Conformer and is about 10\% faster.
FastPacket: Towards Pre-trained Packets Embedding based on FastText for next-generation NIDS
Sep 29, 2022
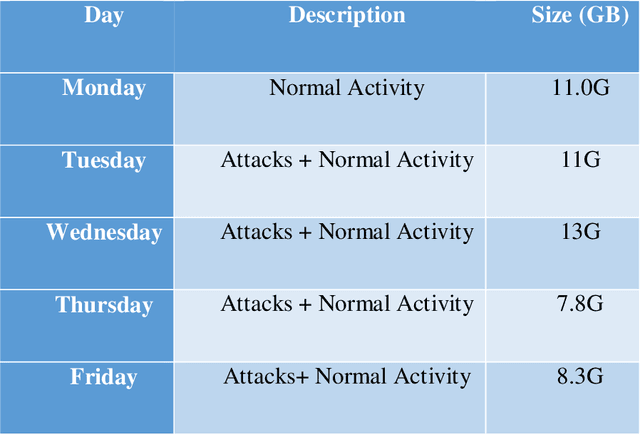
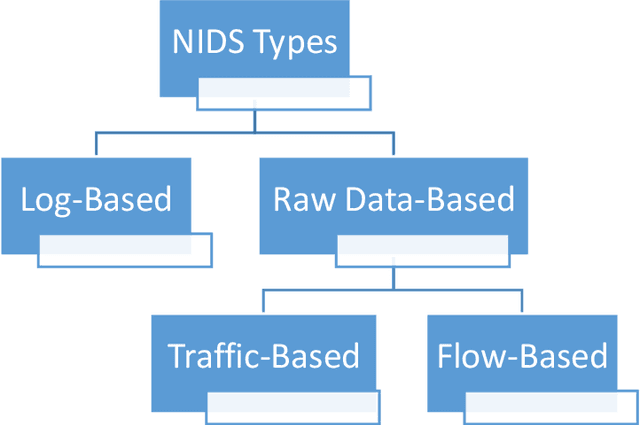
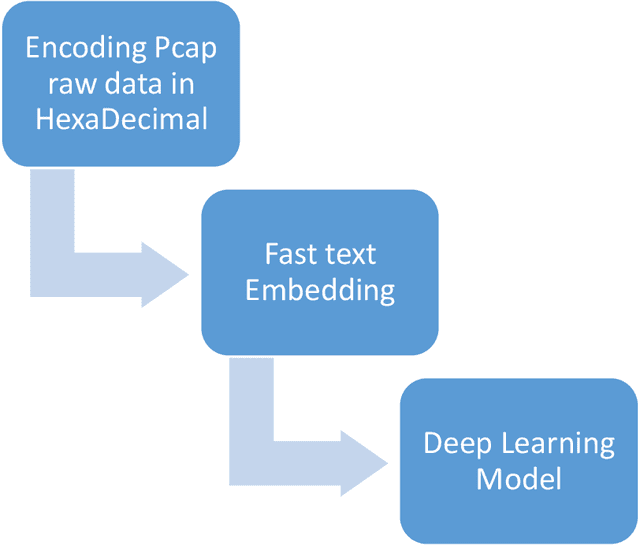
New Attacks are increasingly used by attackers everyday but many of them are not detected by Intrusion Detection Systems as most IDS ignore raw packet information and only care about some basic statistical information extracted from PCAP files. Using networking programs to extract fixed statistical features from packets is good, but may not enough to detect nowadays challenges. We think that it is time to utilize big data and deep learning for automatic dynamic feature extraction from packets. It is time to get inspired by deep learning pre-trained models in computer vision and natural language processing, so security deep learning solutions will have its pre-trained models on big datasets to be used in future researches. In this paper, we proposed a new approach for embedding packets based on character-level embeddings, inspired by FastText success on text data. We called this approach FastPacket. Results are measured on subsets of CIC-IDS-2017 dataset, but we expect promising results on big data pre-trained models. We suggest building pre-trained FastPacket on MAWI big dataset and make it available to community, similar to FastText. To be able to outperform currently used NIDS, to start a new era of packet-level NIDS that can better detect complex attacks.
On Compressing Sequences for Self-Supervised Speech Models
Oct 14, 2022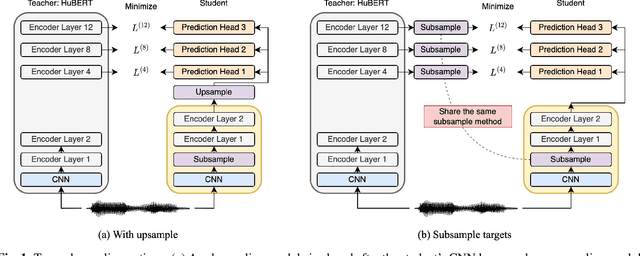
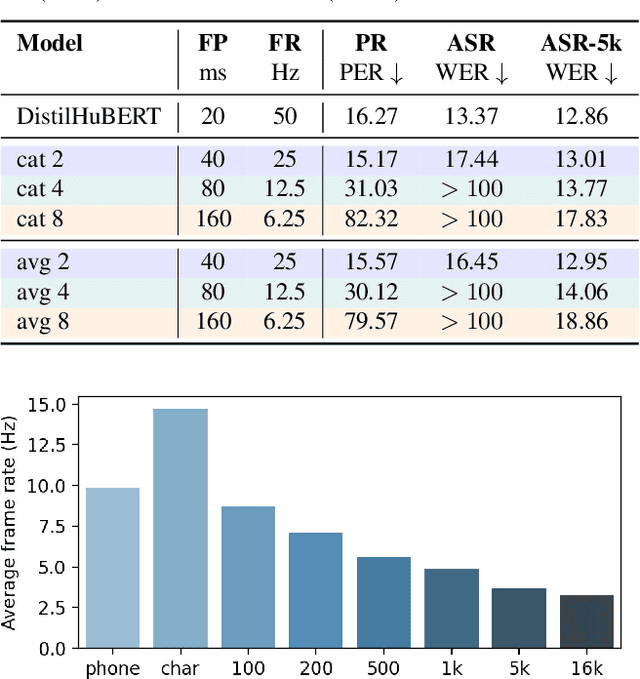
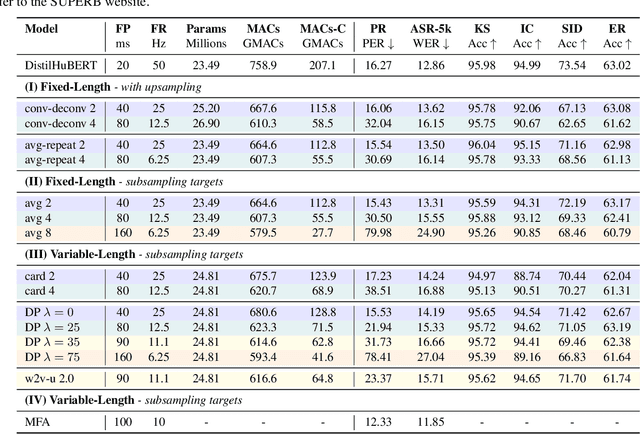
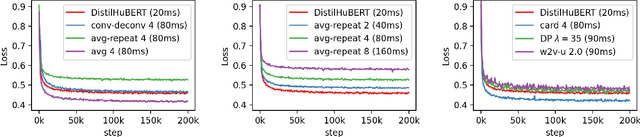
Compressing self-supervised models has become increasingly necessary, as self-supervised models become larger. While previous approaches have primarily focused on compressing the model size, shortening sequences is also effective in reducing the computational cost. In this work, we study fixed-length and variable-length subsampling along the time axis in self-supervised learning. We explore how individual downstream tasks are sensitive to input frame rates. Subsampling while training self-supervised models not only improves the overall performance on downstream tasks under certain frame rates, but also brings significant speed-up in inference. Variable-length subsampling performs particularly well under low frame rates. In addition, if we have access to phonetic boundaries, we find no degradation in performance for an average frame rate as low as 10 Hz.
Performance Evaluation of Wireless Multi-Carrier (MC) Communication Systems
Oct 14, 2022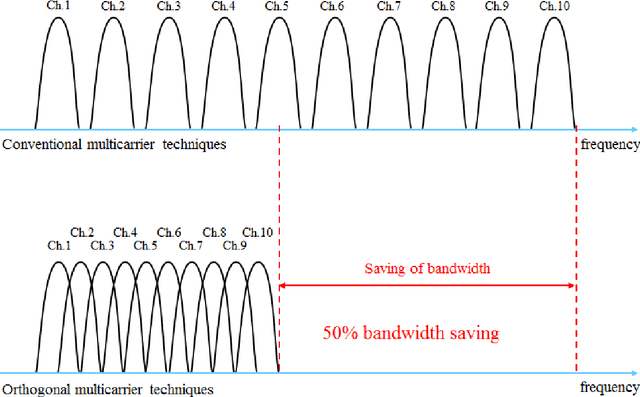
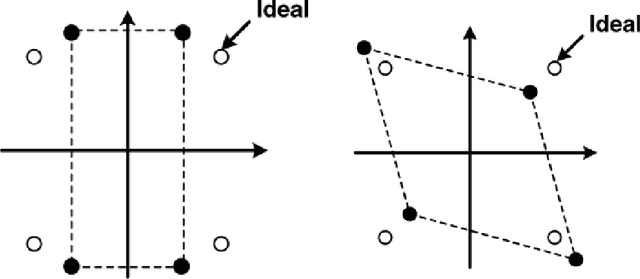
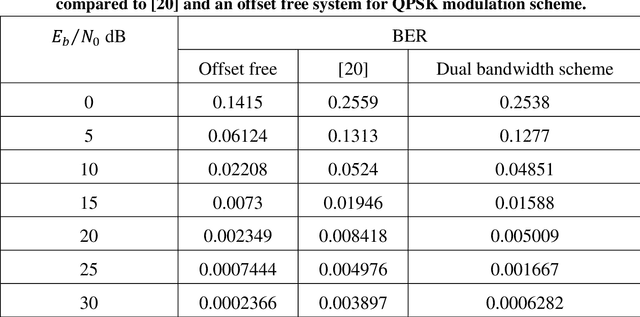
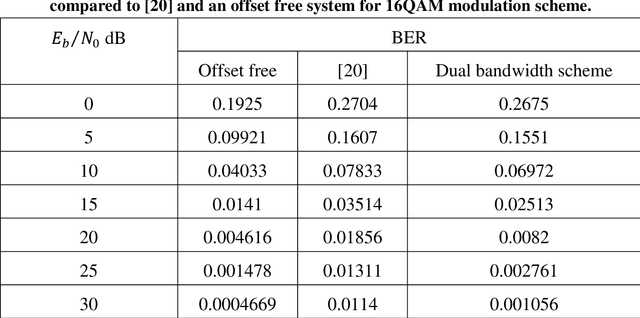
This thesis is concerned with data-aided (DA) scheme and CFO tracking for OFDM system. OFDM system model is developed first without CFO and then with CFO. The system performance is evaluated via simulation. The bit error rate (BER), constellation diagram, the phase output and phase error were taken as performance measures. The performance is evaluated for different types of modulation over different channel conditions. In this thesis, a dual bandwidth for CFO tracking based on type-2 control loop to reduce the acquisition time of PLL is proposed. It is proved that the proposed scheme is significantly faster than, and improves the system BER. Also, further refinement to the dual bandwidth scheme is improved by using clustered pilot tones. The improved dual bandwidth scheme is better than the dual bandwidth scheme.
Convolutional Neural Networks: Basic Concepts and Applications in Manufacturing
Oct 14, 2022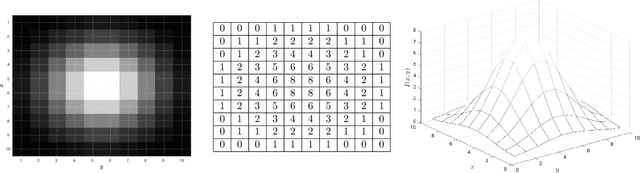

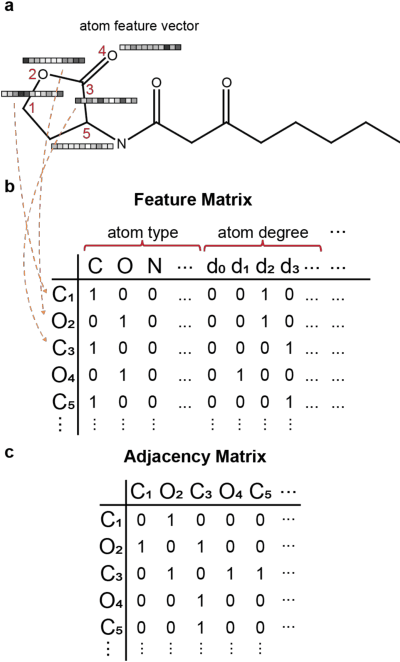
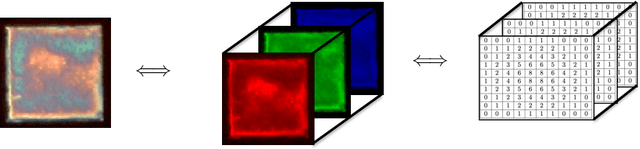
We discuss basic concepts of convolutional neural networks (CNNs) and outline uses in manufacturing. We begin by discussing how different types of data objects commonly encountered in manufacturing (e.g., time series, images, micrographs, videos, spectra, molecular structures) can be represented in a flexible manner using tensors and graphs. We then discuss how CNNs use convolution operations to extract informative features (e.g., geometric patterns and textures) from the such representations to predict emergent properties and phenomena and/or to identify anomalies. We also discuss how CNNs can exploit color as a key source of information, which enables the use of modern computer vision hardware (e.g., infrared, thermal, and hyperspectral cameras). We illustrate the concepts using diverse case studies arising in spectral analysis, molecule design, sensor design, image-based control, and multivariate process monitoring.
Probably Approximately Correct Nonlinear Model Predictive Control (PAC-NMPC)
Oct 14, 2022
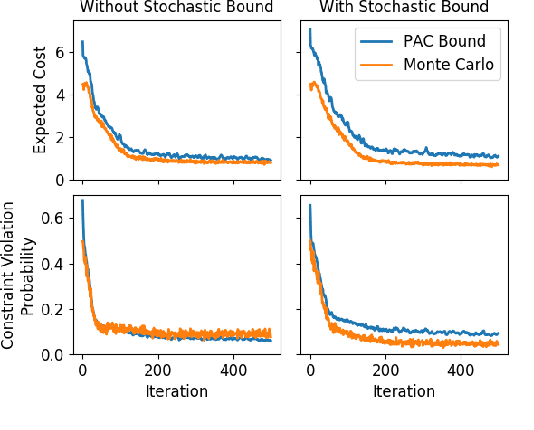
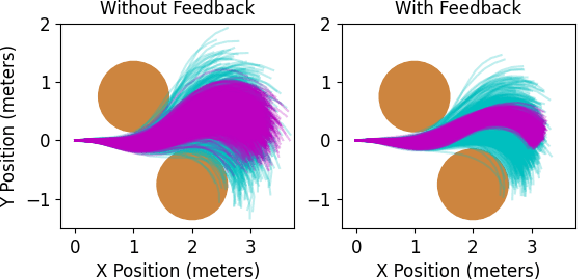
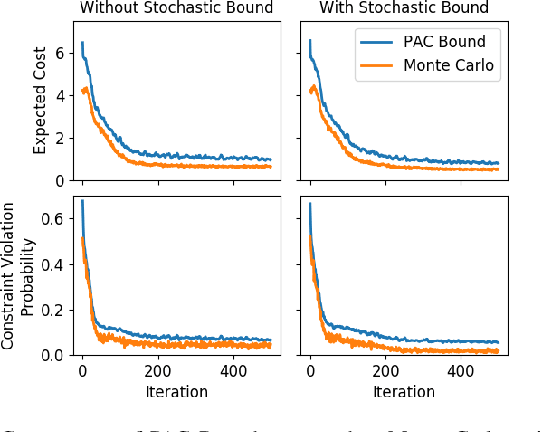
Approaches for stochastic nonlinear model predictive control (SNMPC) typically make restrictive assumptions about the system dynamics and rely on approximations to characterize the evolution of the underlying uncertainty distributions. For this reason, they are often unable to capture more complex distributions (e.g., non-Gaussian or multi-modal) and cannot provide accurate guarantees of performance. In this paper, we present a sampling-based SNMPC approach that leverages recently derived sample complexity bounds to certify the performance of a feedback policy without making assumptions about the system dynamics or underlying uncertainty distributions. By parallelizing our approach, we are able to demonstrate real-time receding-horizon SNMPC with statistical safety guarantees in simulation on a 24-inch wingspan fixed-wing UAV and on hardware using a 1/10th scale rally car.
GAMEOPT: Optimal Real-time Multi-Agent Planning and Control at Dynamic Intersections
Feb 25, 2022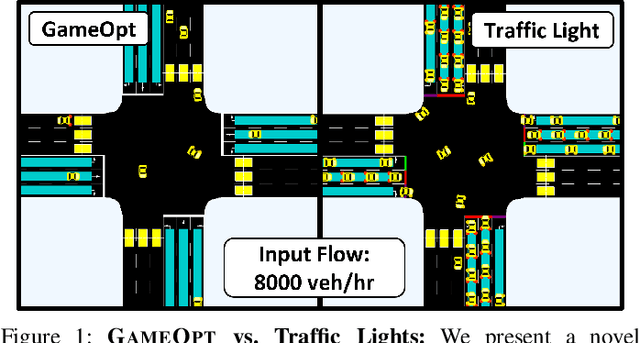
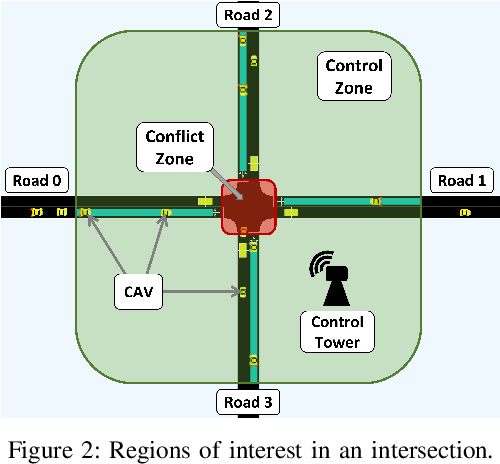
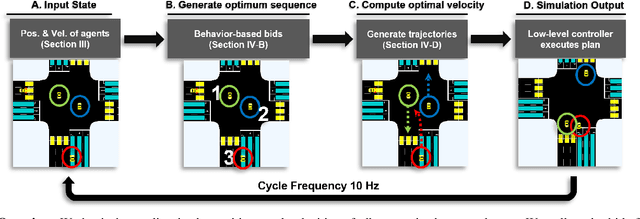
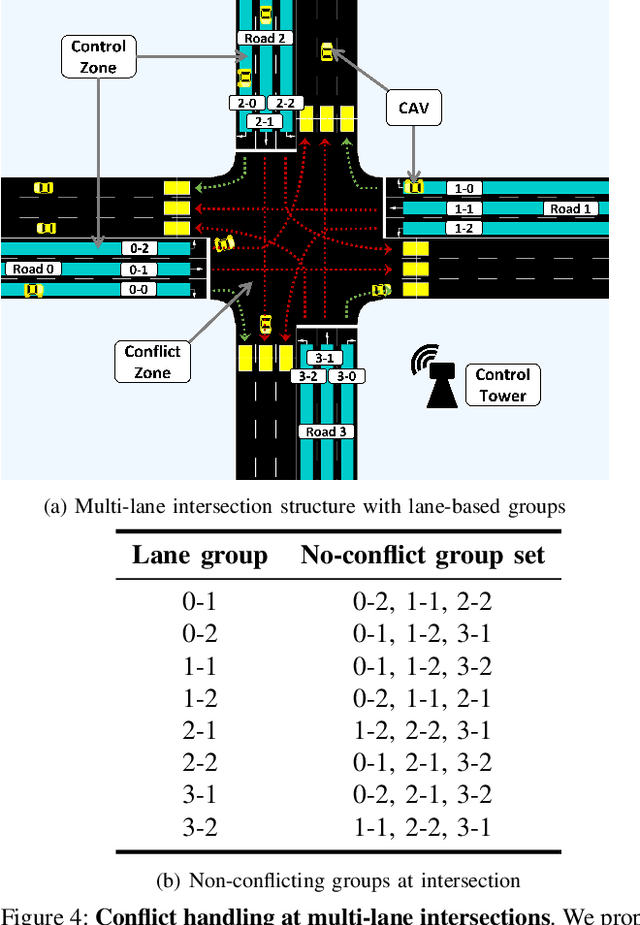
We propose GameOpt: a novel hybrid approach to cooperative intersection control for dynamic, multi-lane, unsignalized intersections. Safely navigating these complex and accident prone intersections requires simultaneous trajectory planning and negotiation among drivers. GameOpt is a hybrid formulation that first uses an auction mechanism to generate a priority entrance sequence for every agent, followed by an optimization-based trajectory planner that computes velocity controls that satisfy the priority sequence. This coupling operates at real-time speeds of less than $10$ milliseconds in high density traffic of more than $10,000$ vehicles/hr, $100\times$ faster than other fully optimization-based methods, while providing guarantees in terms of fairness, safety, and efficiency. Tested on the SUMO simulator, our algorithm improves throughput by at least $25\%$, time taken to reach the goal by $75\%$, and fuel consumption by $33\%$ compared to auction-based approaches and signaled approaches using traffic-lights and stop signs.
Preformer: Predictive Transformer with Multi-Scale Segment-wise Correlations for Long-Term Time Series Forecasting
Feb 23, 2022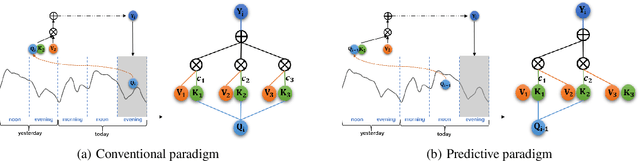
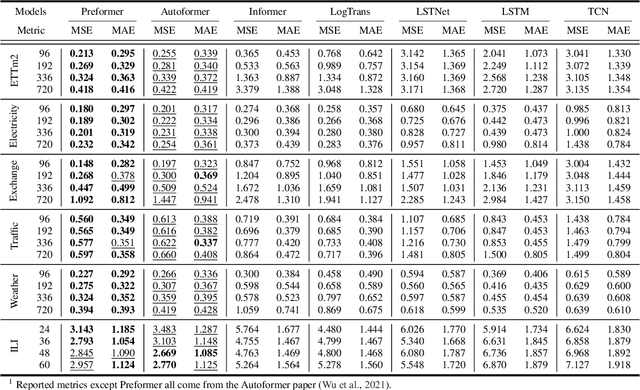
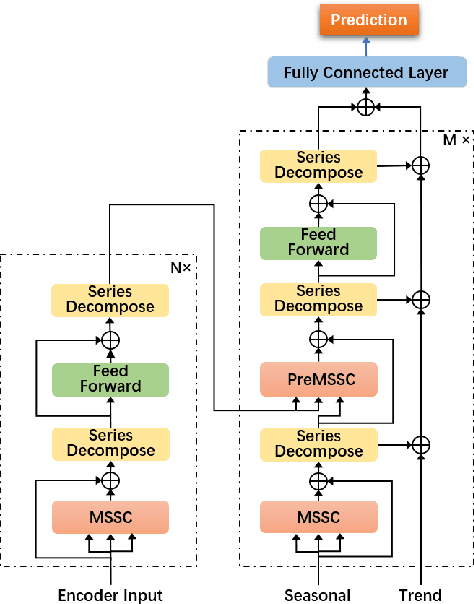
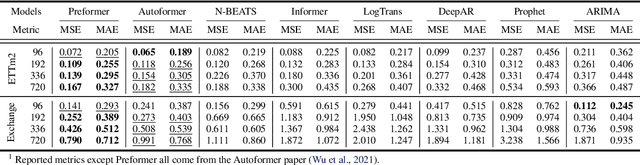
Transformer-based methods have shown great potential in long-term time series forecasting. However, most of these methods adopt the standard point-wise self-attention mechanism, which not only becomes intractable for long-term forecasting since its complexity increases quadratically with the length of time series, but also cannot explicitly capture the predictive dependencies from contexts since the corresponding key and value are transformed from the same point. This paper proposes a predictive Transformer-based model called {\em Preformer}. Preformer introduces a novel efficient {\em Multi-Scale Segment-Correlation} mechanism that divides time series into segments and utilizes segment-wise correlation-based attention for encoding time series. A multi-scale structure is developed to aggregate dependencies at different temporal scales and facilitate the selection of segment length. Preformer further designs a predictive paradigm for decoding, where the key and value come from two successive segments rather than the same segment. In this way, if a key segment has a high correlation score with the query segment, its successive segment contributes more to the prediction of the query segment. Extensive experiments demonstrate that our Preformer outperforms other Transformer-based methods.
Movement Analytics: Current Status, Application to Manufacturing, and Future Prospects from an AI Perspective
Oct 04, 2022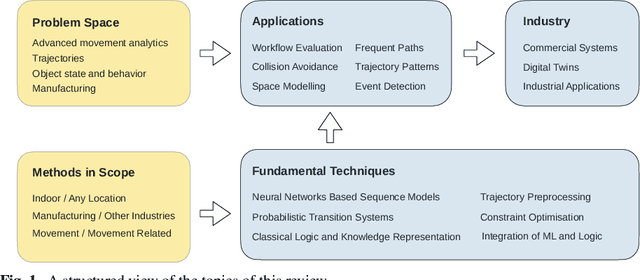
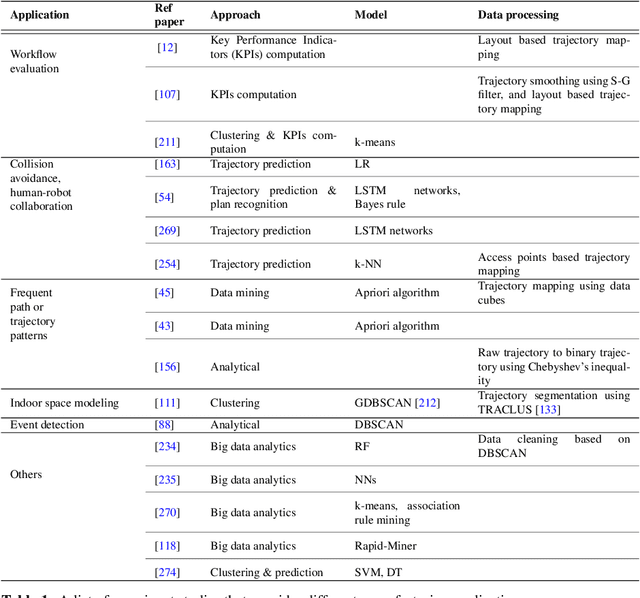
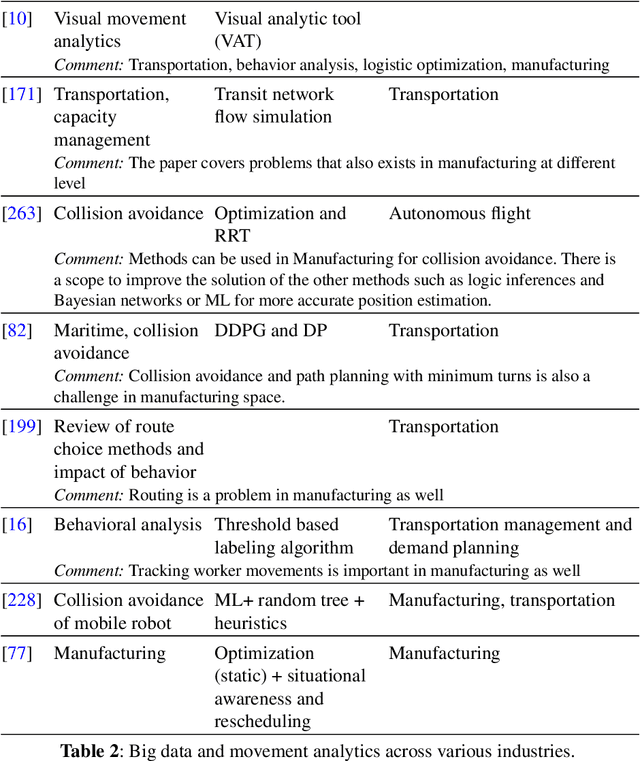
Data-driven decision making is becoming an integral part of manufacturing companies. Data is collected and commonly used to improve efficiency and produce high quality items for the customers. IoT-based and other forms of object tracking are an emerging tool for collecting movement data of objects/entities (e.g. human workers, moving vehicles, trolleys etc.) over space and time. Movement data can provide valuable insights like process bottlenecks, resource utilization, effective working time etc. that can be used for decision making and improving efficiency. Turning movement data into valuable information for industrial management and decision making requires analysis methods. We refer to this process as movement analytics. The purpose of this document is to review the current state of work for movement analytics both in manufacturing and more broadly. We survey relevant work from both a theoretical perspective and an application perspective. From the theoretical perspective, we put an emphasis on useful methods from two research areas: machine learning, and logic-based knowledge representation. We also review their combinations in view of movement analytics, and we discuss promising areas for future development and application. Furthermore, we touch on constraint optimization. From an application perspective, we review applications of these methods to movement analytics in a general sense and across various industries. We also describe currently available commercial off-the-shelf products for tracking in manufacturing, and we overview main concepts of digital twins and their applications.