 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Spatial and Tonal Data Optimisation for Homogeneous Diffusion Inpainting
Aug 30, 2022
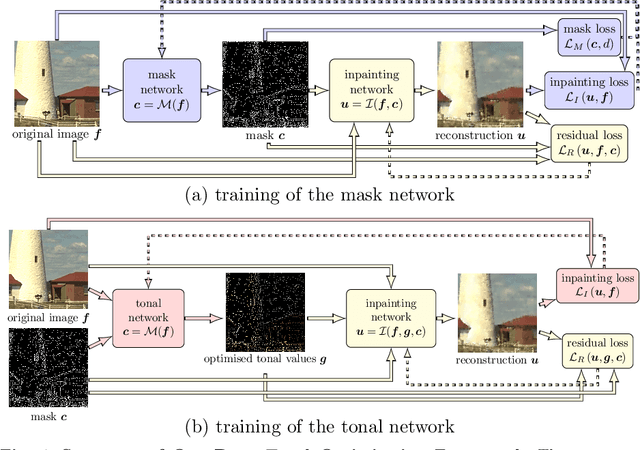
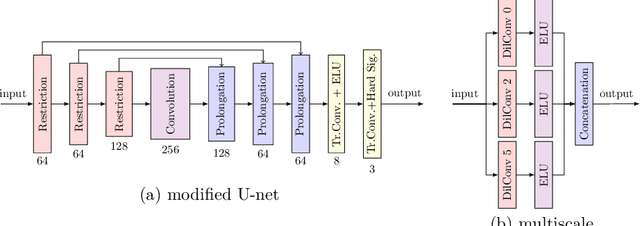
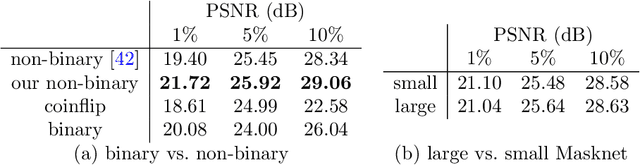
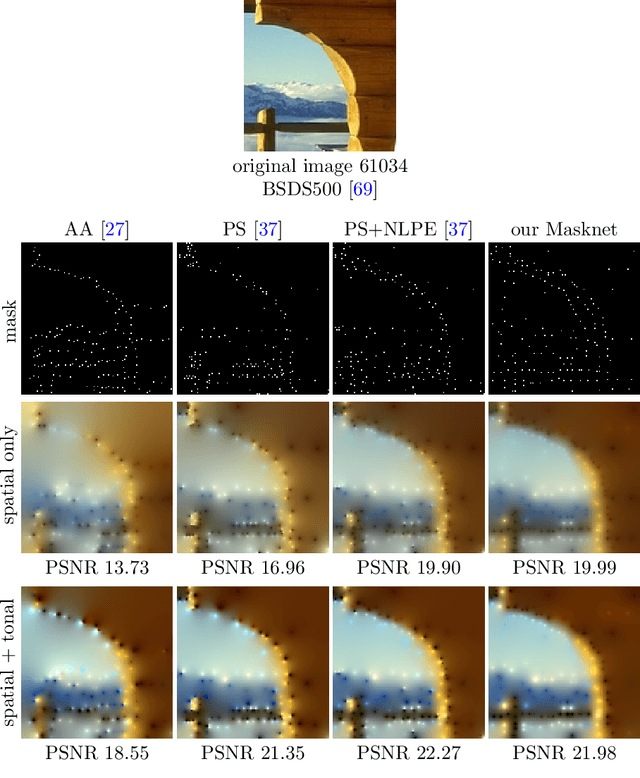
Diffusion-based inpainting can reconstruct missing image areas with high quality from sparse data, provided that their location and their values are well optimised. This is particularly useful for applications such as image compression, where the original image is known. Selecting the known data constitutes a challenging optimisation problem, that has so far been only investigated with model-based approaches. So far, these methods require a choice between either high quality or high speed since qualitatively convincing algorithms rely on many time-consuming inpaintings. We propose the first neural network architecture that allows fast optimisation of pixel positions and pixel values for homogeneous diffusion inpainting. During training, we combine two optimisation networks with a neural network-based surrogate solver for diffusion inpainting. This novel concept allows us to perform backpropagation based on inpainting results that approximate the solution of the inpainting equation. Without the need for a single inpainting during test time, our deep optimisation combines the high quality of model-based approaches with real-time performance.
Modeling Regime Shifts in Multiple Time Series
Sep 20, 2021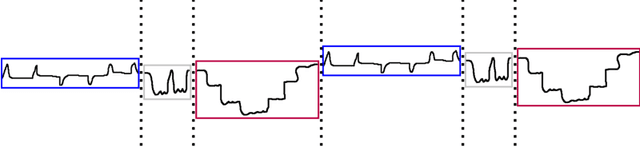
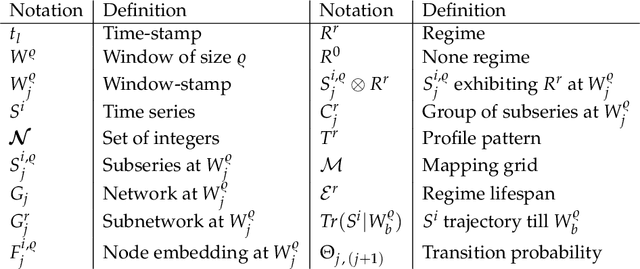

We investigate the problem of discovering and modeling regime shifts in an ecosystem comprising multiple time series known as co-evolving time series. Regime shifts refer to the changing behaviors exhibited by series at different time intervals. Learning these changing behaviors is a key step toward time series forecasting. While advances have been made, existing methods suffer from one or more of the following shortcomings: (1) failure to take relationships between time series into consideration for discovering regimes in multiple time series; (2) lack of an effective approach that models time-dependent behaviors exhibited by series; (3) difficulties in handling data discontinuities which may be informative. Most of the existing methods are unable to handle all of these three issues in a unified framework. This, therefore, motivates our effort to devise a principled approach for modeling interactions and time-dependency in co-evolving time series. Specifically, we model an ecosystem of multiple time series by summarizing the heavy ensemble of time series into a lighter and more meaningful structure called a \textit{mapping grid}. By using the mapping grid, our model first learns time series behavioral dependencies through a dynamic network representation, then learns the regime transition mechanism via a full time-dependent Cox regression model. The originality of our approach lies in modeling interactions between time series in regime identification and in modeling time-dependent regime transition probabilities, usually assumed to be static in existing work.
Uncovering Regions of Maximum Dissimilarity on Random Process Data
Sep 12, 2022
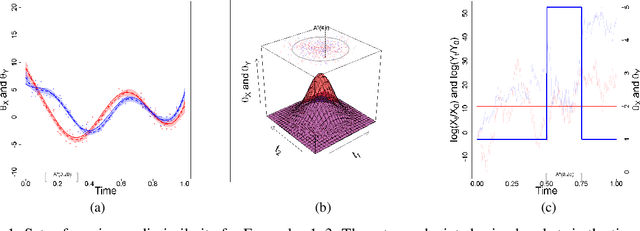
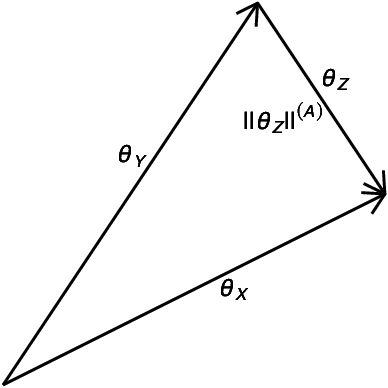
The comparison of local characteristics of two random processes can shed light on periods of time or space at which the processes differ the most. This paper proposes a method that learns about regions with a certain volume, where the marginal attributes of two processes are less similar. The proposed methods are devised in full generality for the setting where the data of interest are themselves stochastic processes, and thus the proposed method can be used for pointing out the regions of maximum dissimilarity with a certain volume, in the contexts of functional data, time series, and point processes. The parameter functions underlying both stochastic processes of interest are modeled via a basis representation, and Bayesian inference is conducted via an integrated nested Laplace approximation. The numerical studies validate the proposed methods, and we showcase their application with case studies on criminology, finance, and medicine.
On the Impact of Temporal Concept Drift on Model Explanations
Oct 17, 2022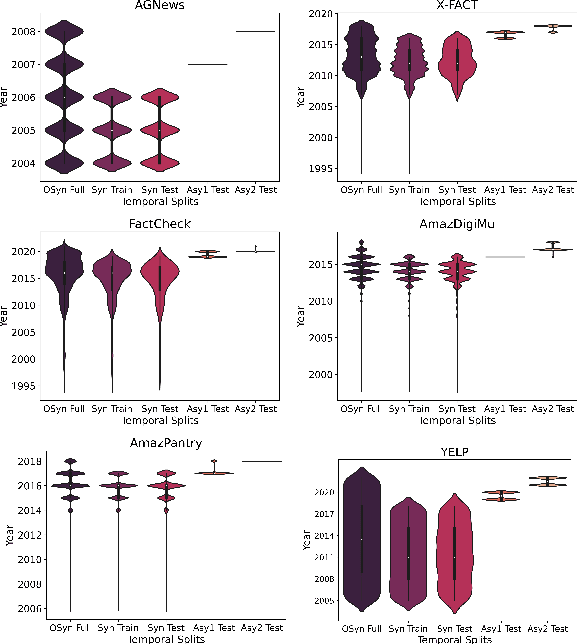
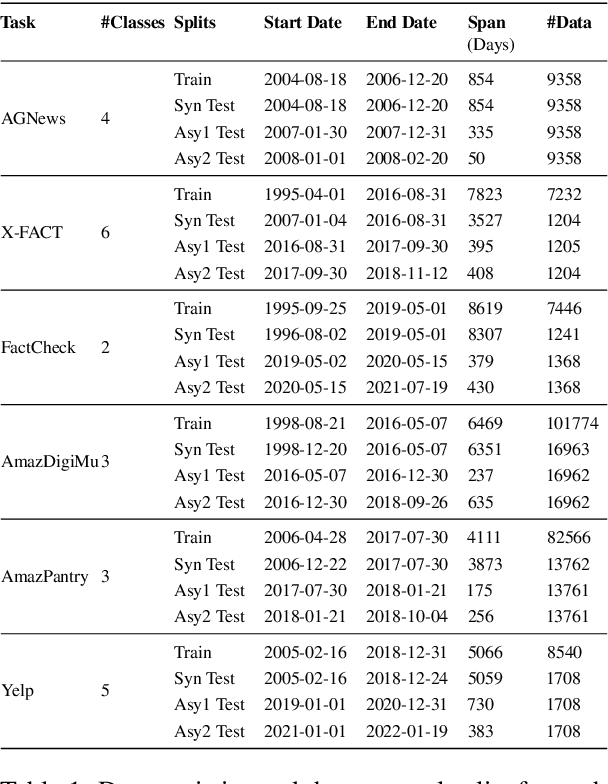
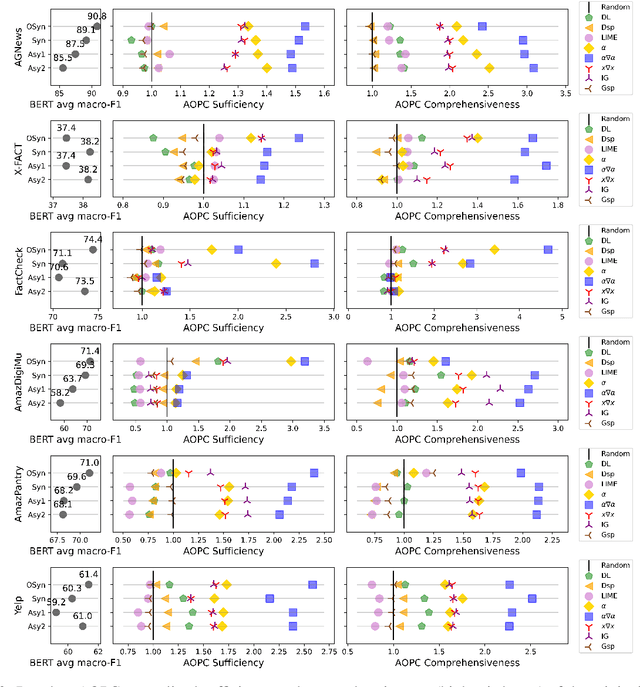
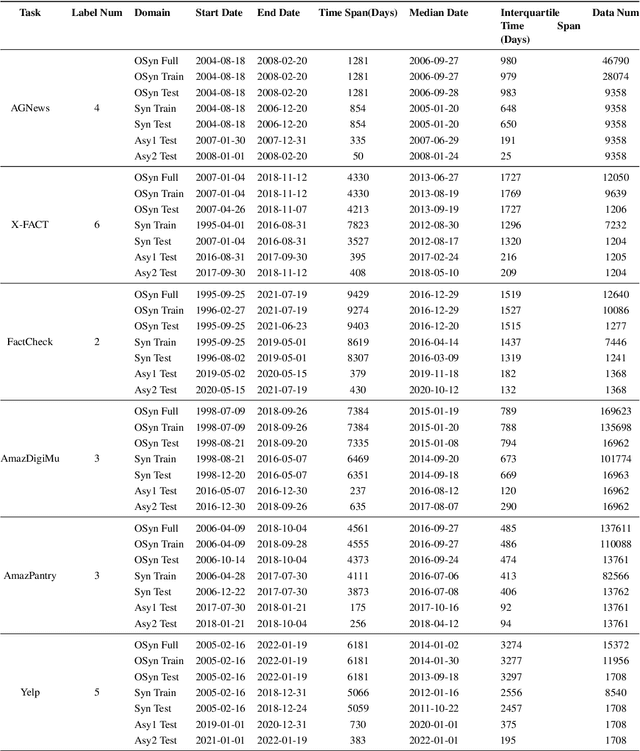
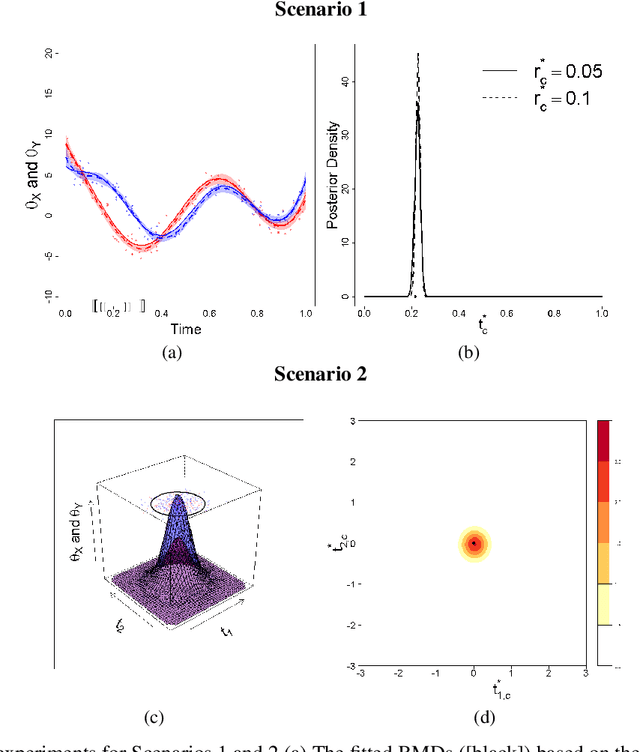
Explanation faithfulness of model predictions in natural language processing is typically evaluated on held-out data from the same temporal distribution as the training data (i.e. synchronous settings). While model performance often deteriorates due to temporal variation (i.e. temporal concept drift), it is currently unknown how explanation faithfulness is impacted when the time span of the target data is different from the data used to train the model (i.e. asynchronous settings). For this purpose, we examine the impact of temporal variation on model explanations extracted by eight feature attribution methods and three select-then-predict models across six text classification tasks. Our experiments show that (i)faithfulness is not consistent under temporal variations across feature attribution methods (e.g. it decreases or increases depending on the method), with an attention-based method demonstrating the most robust faithfulness scores across datasets; and (ii) select-then-predict models are mostly robust in asynchronous settings with only small degradation in predictive performance. Finally, feature attribution methods show conflicting behavior when used in FRESH (i.e. a select-and-predict model) and for measuring sufficiency/comprehensiveness (i.e. as post-hoc methods), suggesting that we need more robust metrics to evaluate post-hoc explanation faithfulness.
Boosting Offline Reinforcement Learning via Data Rebalancing
Oct 17, 2022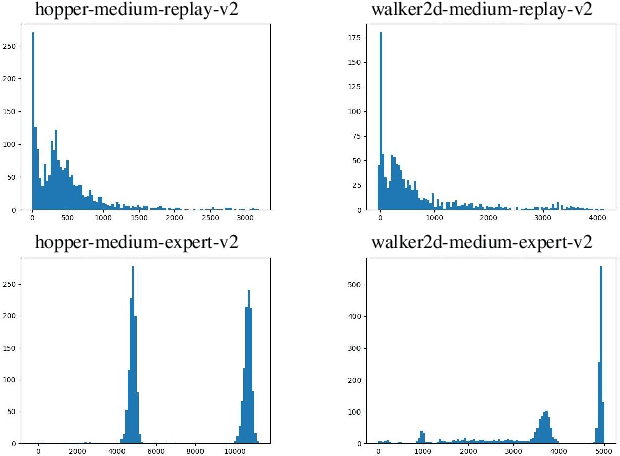
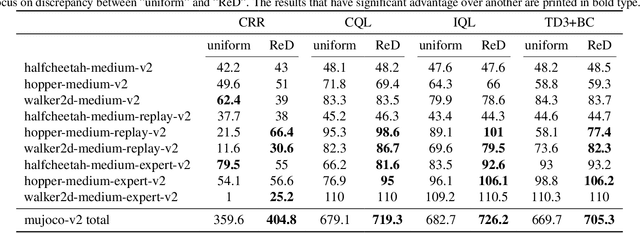
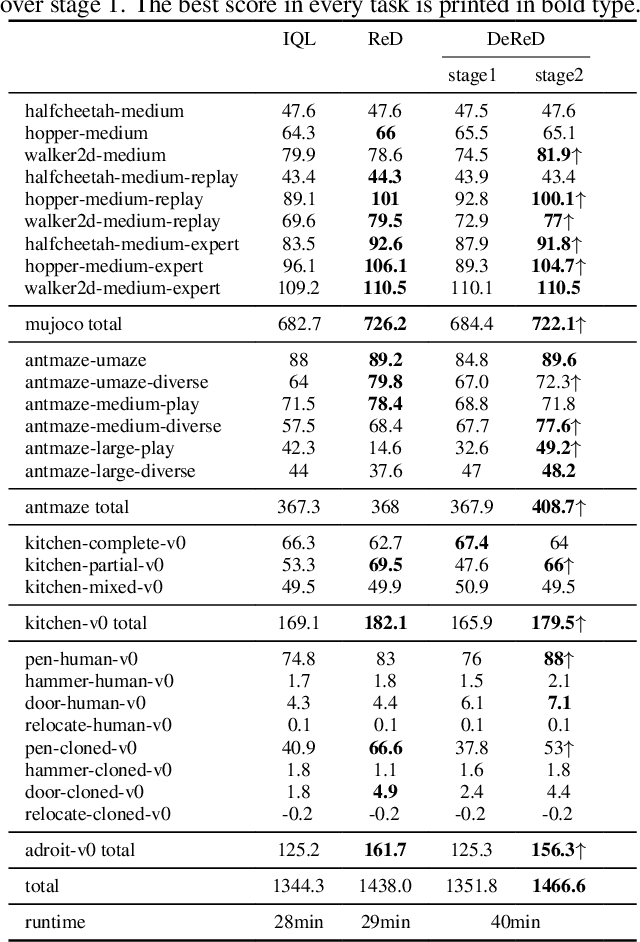
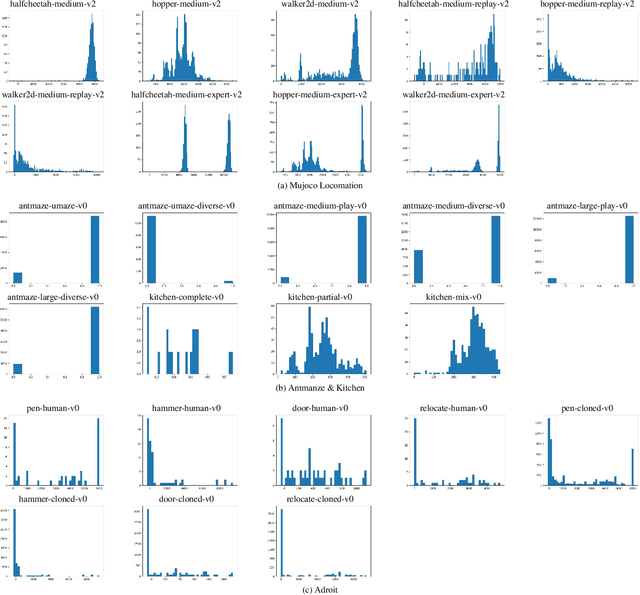
Offline reinforcement learning (RL) is challenged by the distributional shift between learning policies and datasets. To address this problem, existing works mainly focus on designing sophisticated algorithms to explicitly or implicitly constrain the learned policy to be close to the behavior policy. The constraint applies not only to well-performing actions but also to inferior ones, which limits the performance upper bound of the learned policy. Instead of aligning the densities of two distributions, aligning the supports gives a relaxed constraint while still being able to avoid out-of-distribution actions. Therefore, we propose a simple yet effective method to boost offline RL algorithms based on the observation that resampling a dataset keeps the distribution support unchanged. More specifically, we construct a better behavior policy by resampling each transition in an old dataset according to its episodic return. We dub our method ReD (Return-based Data Rebalance), which can be implemented with less than 10 lines of code change and adds negligible running time. Extensive experiments demonstrate that ReD is effective at boosting offline RL performance and orthogonal to decoupling strategies in long-tailed classification. New state-of-the-arts are achieved on the D4RL benchmark.
Risk-Sensitive Markov Decision Processes with Long-Run CVaR Criterion
Oct 17, 2022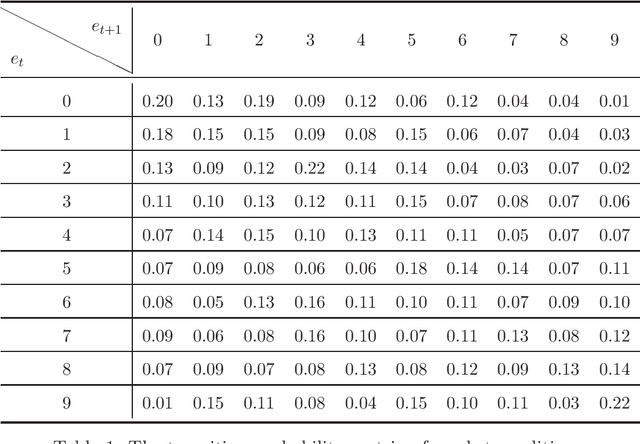
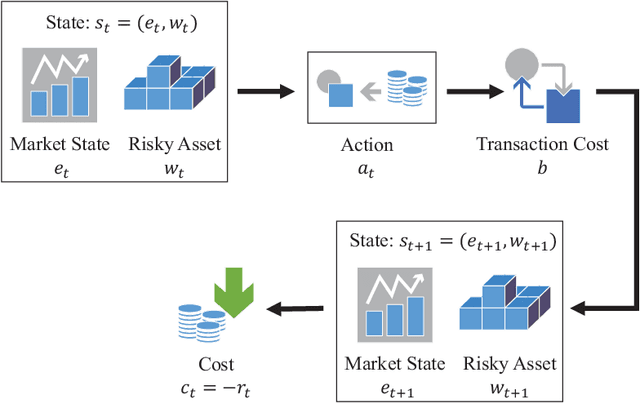

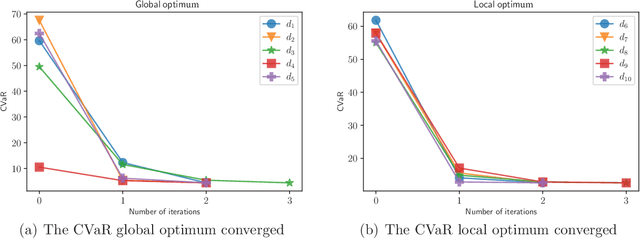
CVaR (Conditional Value at Risk) is a risk metric widely used in finance. However, dynamically optimizing CVaR is difficult since it is not a standard Markov decision process (MDP) and the principle of dynamic programming fails. In this paper, we study the infinite-horizon discrete-time MDP with a long-run CVaR criterion, from the view of sensitivity-based optimization. By introducing a pseudo CVaR metric, we derive a CVaR difference formula which quantifies the difference of long-run CVaR under any two policies. The optimality of deterministic policies is derived. We obtain a so-called Bellman local optimality equation for CVaR, which is a necessary and sufficient condition for local optimal policies and only necessary for global optimal policies. A CVaR derivative formula is also derived for providing more sensitivity information. Then we develop a policy iteration type algorithm to efficiently optimize CVaR, which is shown to converge to local optima in the mixed policy space. We further discuss some extensions including the mean-CVaR optimization and the maximization of CVaR. Finally, we conduct numerical experiments relating to portfolio management to demonstrate the main results. Our work may shed light on dynamically optimizing CVaR from a sensitivity viewpoint.
Gated Recurrent Unit for Video Denoising
Oct 17, 2022
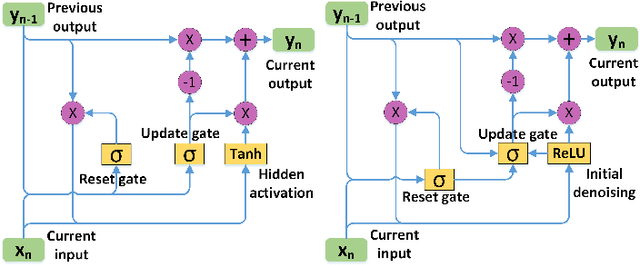
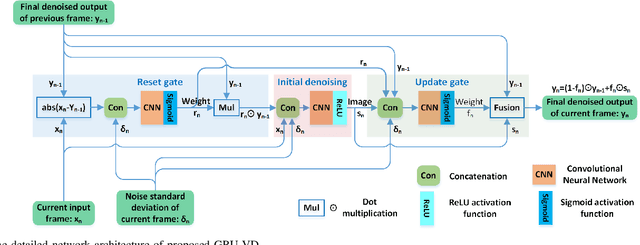

Current video denoising methods perform temporal fusion by designing convolutional neural networks (CNN) or combine spatial denoising with temporal fusion into basic recurrent neural networks (RNNs). However, there have not yet been works which adapt gated recurrent unit (GRU) mechanisms for video denoising. In this letter, we propose a new video denoising model based on GRU, namely GRU-VD. First, the reset gate is employed to mark the content related to the current frame in the previous frame output. Then the hidden activation works as an initial spatial-temporal denoising with the help from the marked relevant content. Finally, the update gate recursively fuses the initial denoised result with previous frame output to further increase accuracy. To handle various light conditions adaptively, the noise standard deviation of the current frame is also fed to these three modules. A weighted loss is adopted to regulate initial denoising and final fusion at the same time. The experimental results show that the GRU-VD network not only can achieve better quality than state of the arts objectively and subjectively, but also can obtain satisfied subjective quality on real video.
On the convergence of policy gradient methods to Nash equilibria in general stochastic games
Oct 17, 2022Learning in stochastic games is a notoriously difficult problem because, in addition to each other's strategic decisions, the players must also contend with the fact that the game itself evolves over time, possibly in a very complicated manner. Because of this, the convergence properties of popular learning algorithms - like policy gradient and its variants - are poorly understood, except in specific classes of games (such as potential or two-player, zero-sum games). In view of this, we examine the long-run behavior of policy gradient methods with respect to Nash equilibrium policies that are second-order stationary (SOS) in a sense similar to the type of sufficiency conditions used in optimization. Our first result is that SOS policies are locally attracting with high probability, and we show that policy gradient trajectories with gradient estimates provided by the REINFORCE algorithm achieve an $\mathcal{O}(1/\sqrt{n})$ distance-squared convergence rate if the method's step-size is chosen appropriately. Subsequently, specializing to the class of deterministic Nash policies, we show that this rate can be improved dramatically and, in fact, policy gradient methods converge within a finite number of iterations in that case.
Protein Sequence and Structure Co-Design with Equivariant Translation
Oct 17, 2022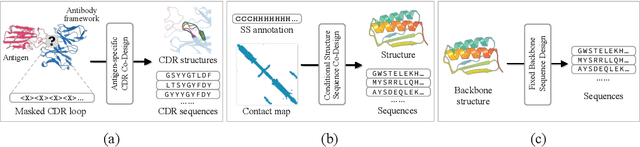

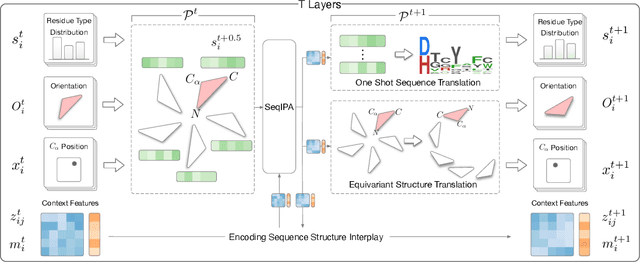
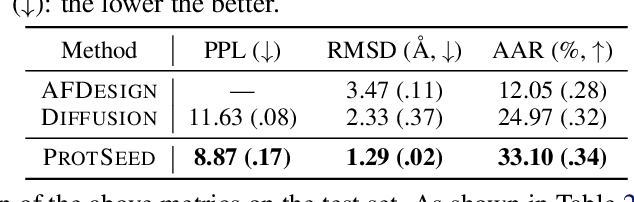
Proteins are macromolecules that perform essential functions in all living organisms. Designing novel proteins with specific structures and desired functions has been a long-standing challenge in the field of bioengineering. Existing approaches generate both protein sequence and structure using either autoregressive models or diffusion models, both of which suffer from high inference costs. In this paper, we propose a new approach capable of protein sequence and structure co-design, which iteratively translates both protein sequence and structure into the desired state from random initialization, based on context features given a priori. Our model consists of a trigonometry-aware encoder that reasons geometrical constraints and interactions from context features, and a roto-translation equivariant decoder that translates protein sequence and structure interdependently. Notably, all protein amino acids are updated in one shot in each translation step, which significantly accelerates the inference process. Experimental results across multiple tasks show that our model outperforms previous state-of-the-art baselines by a large margin, and is able to design proteins of high fidelity as regards both sequence and structure, with running time orders of magnitude less than sampling-based methods.
A Unified Positive-Unlabeled Learning Framework for Document-Level Relation Extraction with Different Levels of Labeling
Oct 17, 2022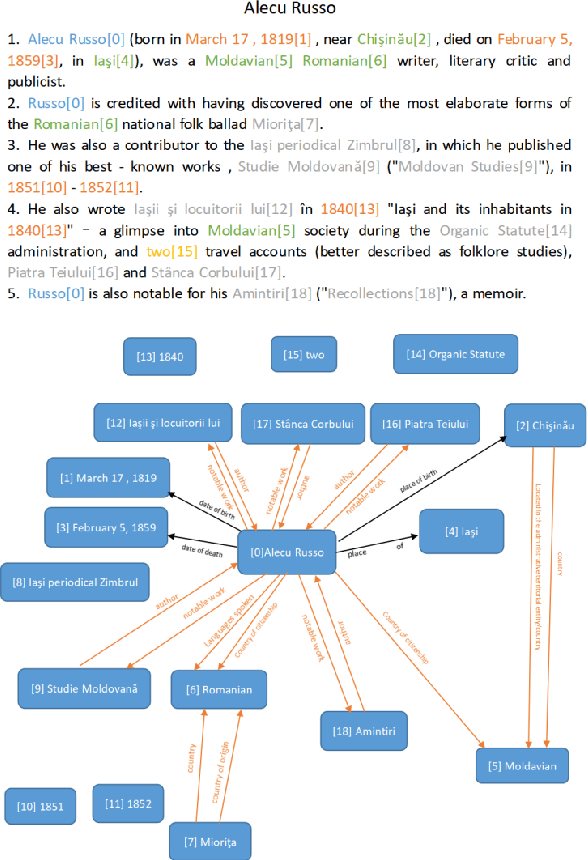
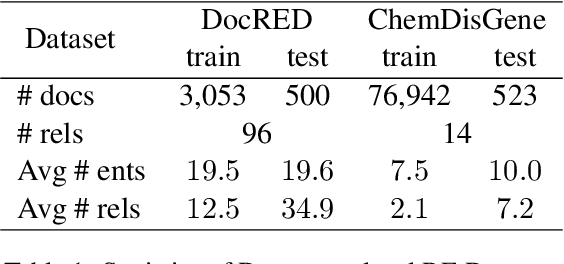
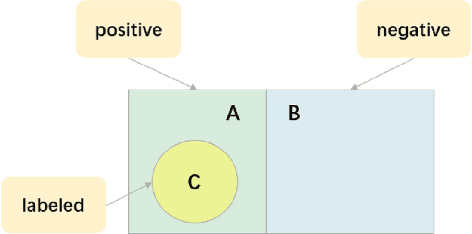
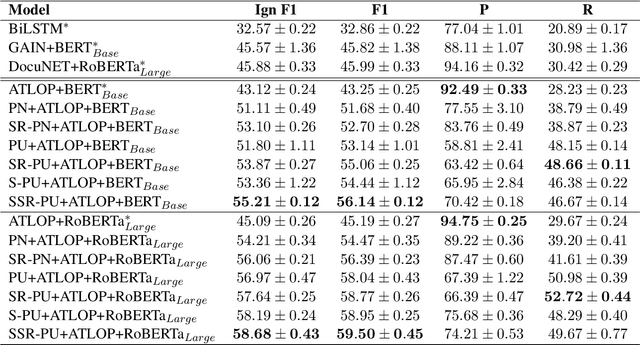
Document-level relation extraction (RE) aims to identify relations between entities across multiple sentences. Most previous methods focused on document-level RE under full supervision. However, in real-world scenario, it is expensive and difficult to completely label all relations in a document because the number of entity pairs in document-level RE grows quadratically with the number of entities. To solve the common incomplete labeling problem, we propose a unified positive-unlabeled learning framework - shift and squared ranking loss positive-unlabeled (SSR-PU) learning. We use positive-unlabeled (PU) learning on document-level RE for the first time. Considering that labeled data of a dataset may lead to prior shift of unlabeled data, we introduce a PU learning under prior shift of training data. Also, using none-class score as an adaptive threshold, we propose squared ranking loss and prove its Bayesian consistency with multi-label ranking metrics. Extensive experiments demonstrate that our method achieves an improvement of about 14 F1 points relative to the previous baseline with incomplete labeling. In addition, it outperforms previous state-of-the-art results under both fully supervised and extremely unlabeled settings as well.