 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
One-shot, Offline and Production-Scalable PID Optimisation with Deep Reinforcement Learning
Oct 25, 2022

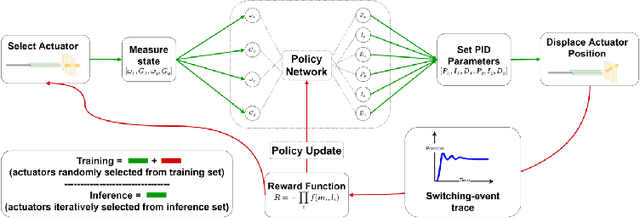
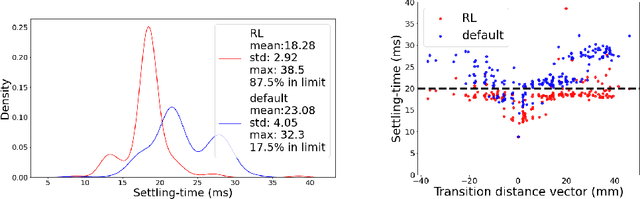
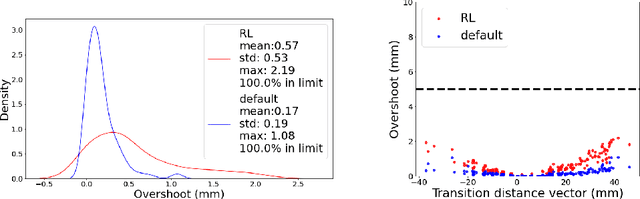
Proportional-integral-derivative (PID) control underlies more than $97\%$ of automated industrial processes. Controlling these processes effectively with respect to some specified set of performance goals requires finding an optimal set of PID parameters to moderate the PID loop. Tuning these parameters is a long and exhaustive process. A method (patent pending) based on deep reinforcement learning is presented that learns a relationship between generic system properties (e.g. resonance frequency), a multi-objective performance goal and optimal PID parameter values. Performance is demonstrated in the context of a real optical switching product of the foremost manufacturer of such devices globally. Switching is handled by piezoelectric actuators where switching time and optical loss are derived from the speed and stability of actuator-control processes respectively. The method achieves a $5\times$ improvement in the number of actuators that fall within the most challenging target switching speed, $\geq 20\%$ improvement in mean switching speed at the same optical loss and $\geq 75\%$ reduction in performance inconsistency when temperature varies between 5 and 73 degrees celcius. Furthermore, once trained (which takes $\mathcal{O}(hours)$), the model generates actuator-unique PID parameters in a one-shot inference process that takes $\mathcal{O}(ms)$ in comparison to up to $\mathcal{O}(week)$ required for conventional tuning methods, therefore accomplishing these performance improvements whilst achieving up to a $10^6\times$ speed-up. After training, the method can be applied entirely offline, incurring effectively zero optimisation-overhead in production.
Tree-Based Learning in RNNs for Power Consumption Forecasting
Sep 03, 2022
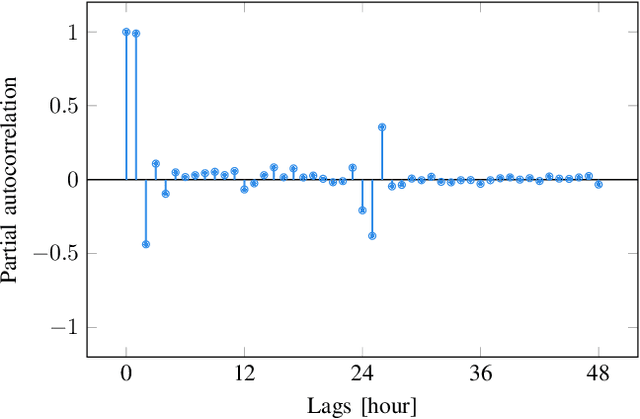
A Recurrent Neural Network that operates on several time lags, called an RNN(p), is the natural generalization of an Autoregressive ARX(p) model. It is a powerful forecasting tool when different time scales can influence a given phenomenon, as it happens in the energy sector where hourly, daily, weekly and yearly interactions coexist. The cost-effective BPTT is the industry standard as learning algorithm for RNNs. We prove that, when training RNN(p) models, other learning algorithms turn out to be much more efficient in terms of both time and space complexity. We also introduce a new learning algorithm, the Tree Recombined Recurrent Learning, that leverages on a tree representation of the unrolled network and appears to be even more effective. We present an application of RNN(p) models for power consumption forecasting on the hourly scale: experimental results demonstrate the efficiency of the proposed algorithm and the excellent predictive accuracy achieved by the selected model both in point and in probabilistic forecasting of the energy consumption.
Performance Analysis of Uplink Optical Wireless Communication System in Presence of STAR-RIS
Sep 20, 2022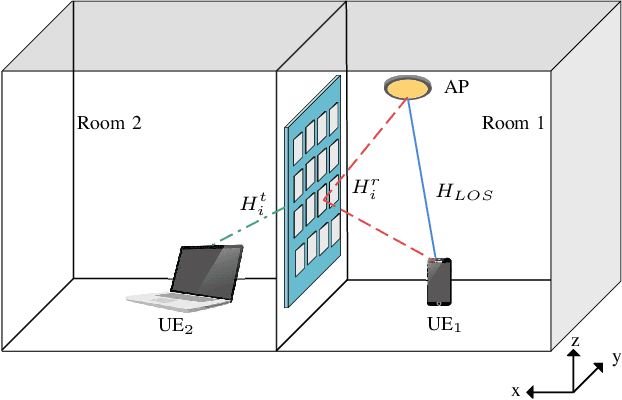
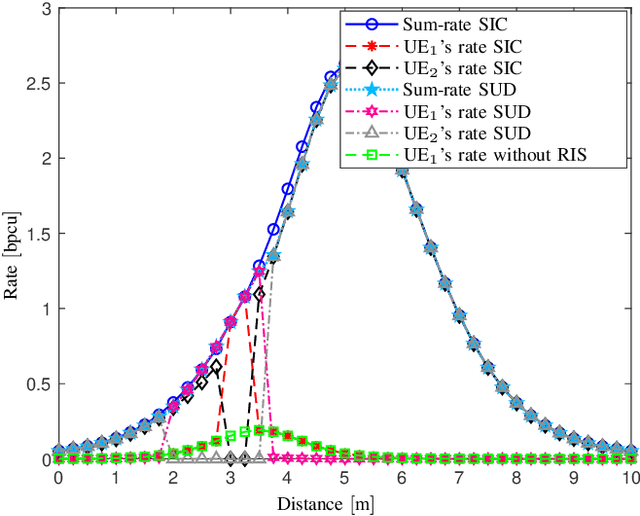
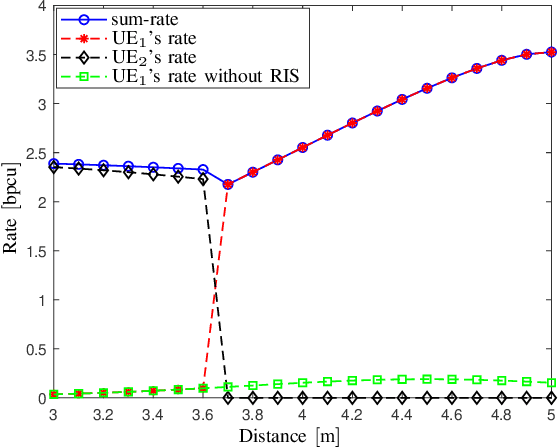
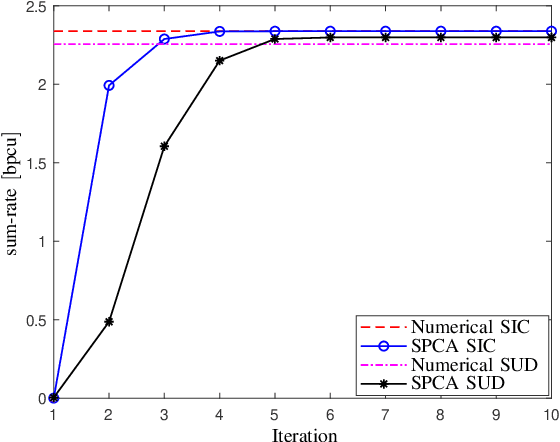
Recently, reconfigurable intelligent surface (RIS) has gained research and development interests to modify wireless channel characteristics in order to improve performance of wireless communications, especially when quality of the line-of-sight channel is not that good. In this work, for the first time in the literature, we have used simultaneously transmitting and reflecting RIS (STAR-RIS) in non-orthogonal multiple-access visible light communication system to improve performance of the system. Achievable rates of the users are derived for two data recovery schemes, single-user detection (SUD) and successive interference cancellation (SIC). Then, sum-rate optimization problem is formulated for two operating modes of STAR-RIS, namely energy-splitting and mode-switching cases. Moreover, a sequential parametric convex approximation method is used to solve the sum-rate optimization problems. We have also compared energy-splitting and mode-switching cases and showed that these two modes have the same performance. Finally, numerical results for SUD and SIC schemes and two benchmarking schemes, time-sharing and max-min fairness, are presented and spectral- and energy-efficiency, number of STAR-RIS elements, position of users and access point are discussed.
Deep Idempotent Network for Efficient Single Image Blind Deblurring
Oct 18, 2022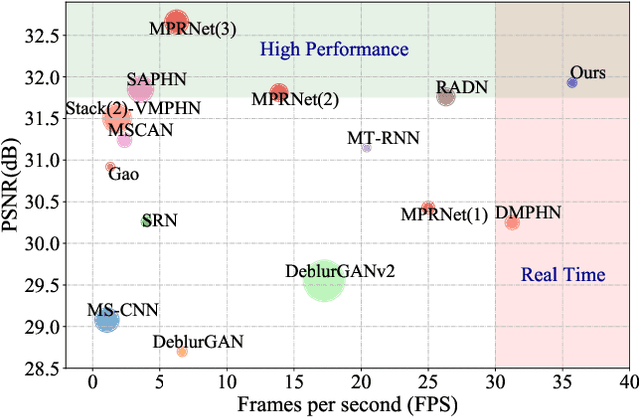


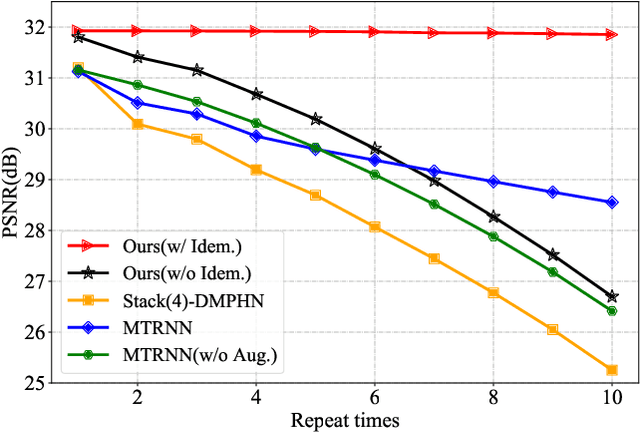
Single image blind deblurring is highly ill-posed as neither the latent sharp image nor the blur kernel is known. Even though considerable progress has been made, several major difficulties remain for blind deblurring, including the trade-off between high-performance deblurring and real-time processing. Besides, we observe that current single image blind deblurring networks cannot further improve or stabilize the performance but significantly degrades the performance when re-deblurring is repeatedly applied. This implies the limitation of these networks in modeling an ideal deblurring process. In this work, we make two contributions to tackle the above difficulties: (1) We introduce the idempotent constraint into the deblurring framework and present a deep idempotent network to achieve improved blind non-uniform deblurring performance with stable re-deblurring. (2) We propose a simple yet efficient deblurring network with lightweight encoder-decoder units and a recurrent structure that can deblur images in a progressive residual fashion. Extensive experiments on synthetic and realistic datasets prove the superiority of our proposed framework. Remarkably, our proposed network is nearly 6.5X smaller and 6.4X faster than the state-of-the-art while achieving comparable high performance.
No Pairs Left Behind: Improving Metric Learning with Regularized Triplet Objective
Oct 18, 2022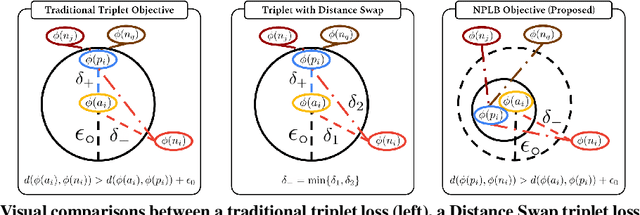

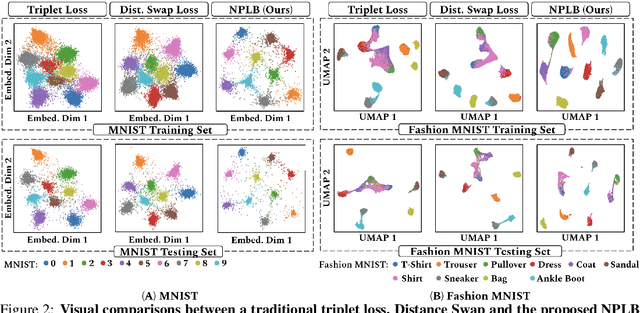
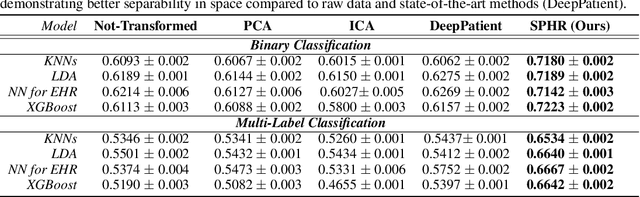
We propose a novel formulation of the triplet objective function that improves metric learning without additional sample mining or overhead costs. Our approach aims to explicitly regularize the distance between the positive and negative samples in a triplet with respect to the anchor-negative distance. As an initial validation, we show that our method (called No Pairs Left Behind [NPLB]) improves upon the traditional and current state-of-the-art triplet objective formulations on standard benchmark datasets. To show the effectiveness and potentials of NPLB on real-world complex data, we evaluate our approach on a large-scale healthcare dataset (UK Biobank), demonstrating that the embeddings learned by our model significantly outperform all other current representations on tested downstream tasks. Additionally, we provide a new model-agnostic single-time health risk definition that, when used in tandem with the learned representations, achieves the most accurate prediction of subjects' future health complications. Our results indicate that NPLB is a simple, yet effective framework for improving existing deep metric learning models, showcasing the potential implications of metric learning in more complex applications, especially in the biological and healthcare domains.
Improving Operational Efficiency In EV Ridepooling Fleets By Predictive Exploitation of Idle Times
Aug 30, 2022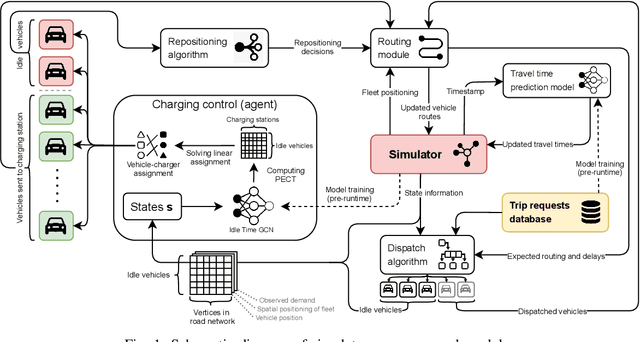
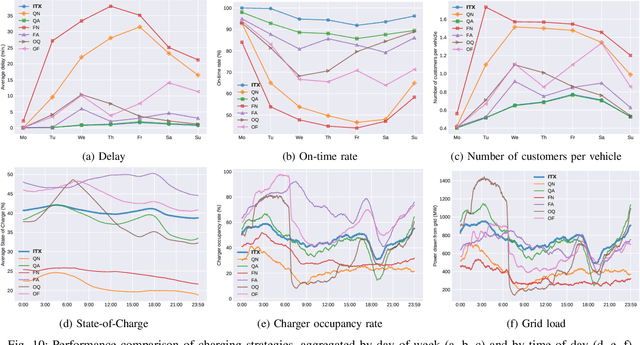
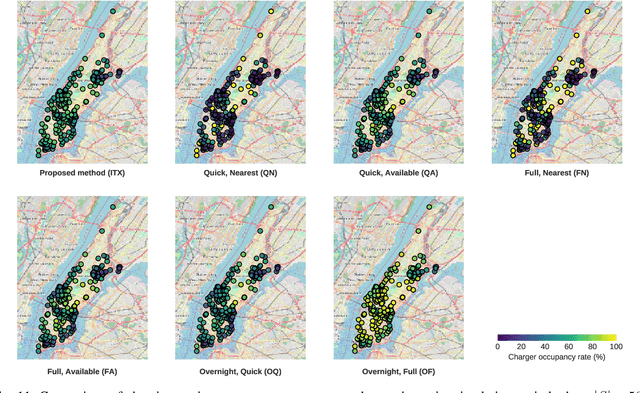
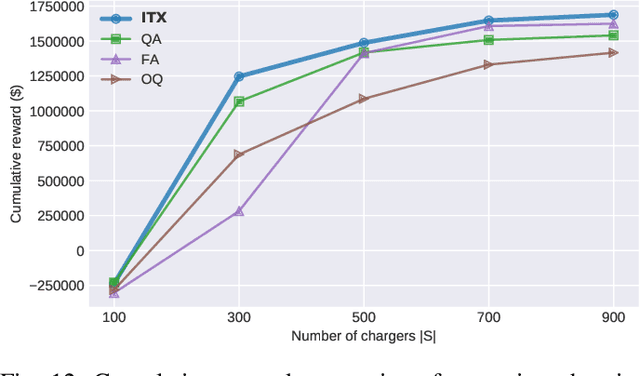
In ridepooling systems with electric fleets, charging is a complex decision-making process. Most electric vehicle (EV) taxi services require drivers to make egoistic decisions, leading to decentralized ad-hoc charging strategies. The current state of the mobility system is often lacking or not shared between vehicles, making it impossible to make a system-optimal decision. Most existing approaches do not combine time, location and duration into a comprehensive control algorithm or are unsuitable for real-time operation. We therefore present a real-time predictive charging method for ridepooling services with a single operator, called Idle Time Exploitation (ITX), which predicts the periods where vehicles are idle and exploits these periods to harvest energy. It relies on Graph Convolutional Networks and a linear assignment algorithm to devise an optimal pairing of vehicles and charging stations, in pursuance of maximizing the exploited idle time. We evaluated our approach through extensive simulation studies on real-world datasets from New York City. The results demonstrate that ITX outperforms all baseline methods by at least 5% (equivalent to $70,000 for a 6,000 vehicle operation) per week in terms of a monetary reward function which was modeled to replicate the profitability of a real-world ridepooling system. Moreover, ITX can reduce delays by at least 4.68% in comparison with baseline methods and generally increase passenger comfort by facilitating a better spread of customers across the fleet. Our results also demonstrate that ITX enables vehicles to harvest energy during the day, stabilizing battery levels and increasing resilience to unexpected surges in demand. Lastly, compared to the best-performing baseline strategy, peak loads are reduced by 17.39% which benefits grid operators and paves the way for more sustainable use of the electrical grid.
Schedule-Robust Online Continual Learning
Oct 11, 2022
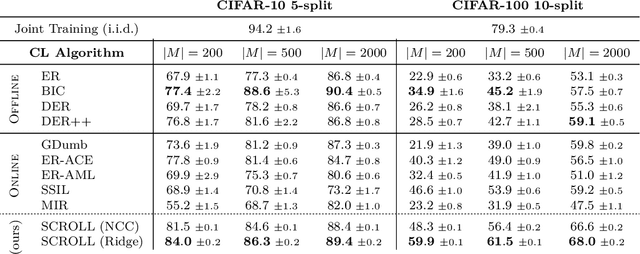
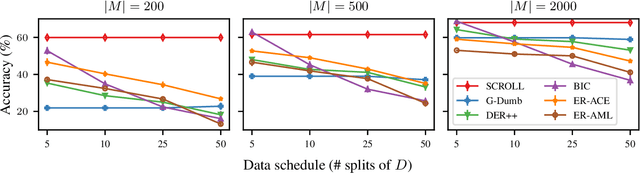
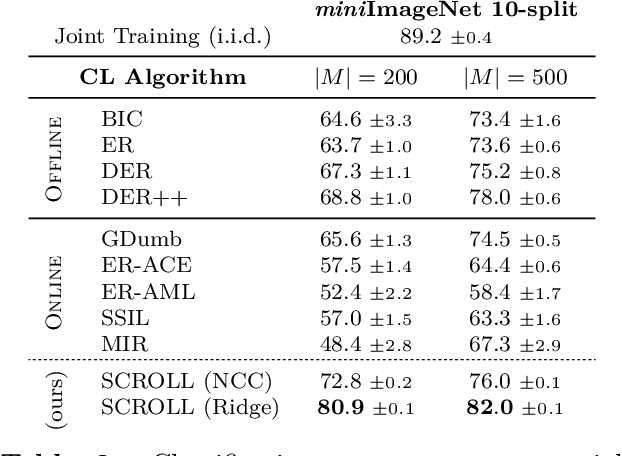
A continual learning (CL) algorithm learns from a non-stationary data stream. The non-stationarity is modeled by some schedule that determines how data is presented over time. Most current methods make strong assumptions on the schedule and have unpredictable performance when such requirements are not met. A key challenge in CL is thus to design methods robust against arbitrary schedules over the same underlying data, since in real-world scenarios schedules are often unknown and dynamic. In this work, we introduce the notion of schedule-robustness for CL and a novel approach satisfying this desirable property in the challenging online class-incremental setting. We also present a new perspective on CL, as the process of learning a schedule-robust predictor, followed by adapting the predictor using only replay data. Empirically, we demonstrate that our approach outperforms existing methods on CL benchmarks for image classification by a large margin.
Deep Spectro-temporal Artifacts for Detecting Synthesized Speech
Oct 11, 2022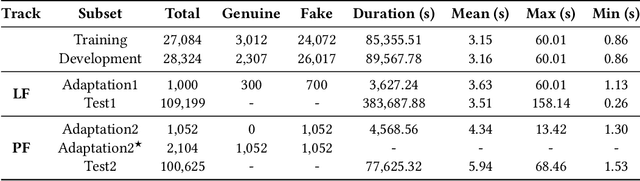
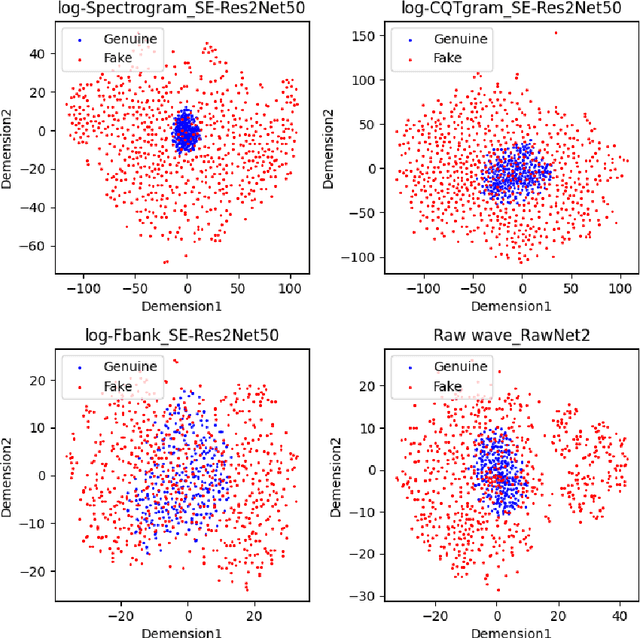
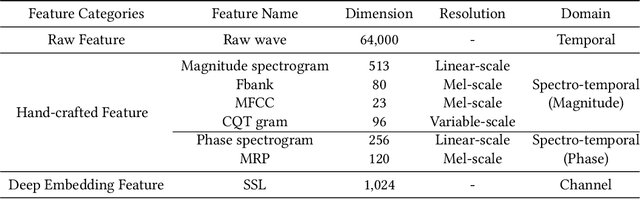

The Audio Deep Synthesis Detection (ADD) Challenge has been held to detect generated human-like speech. With our submitted system, this paper provides an overall assessment of track 1 (Low-quality Fake Audio Detection) and track 2 (Partially Fake Audio Detection). In this paper, spectro-temporal artifacts were detected using raw temporal signals, spectral features, as well as deep embedding features. To address track 1, low-quality data augmentation, domain adaptation via finetuning, and various complementary feature information fusion were aggregated in our system. Furthermore, we analyzed the clustering characteristics of subsystems with different features by visualization method and explained the effectiveness of our proposed greedy fusion strategy. As for track 2, frame transition and smoothing were detected using self-supervised learning structure to capture the manipulation of PF attacks in the time domain. We ranked 4th and 5th in track 1 and track 2, respectively.
A new perspective on Digital Twins: Imparting intelligence and agency to entities
Oct 11, 2022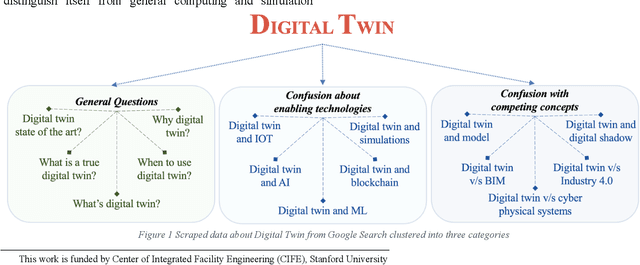
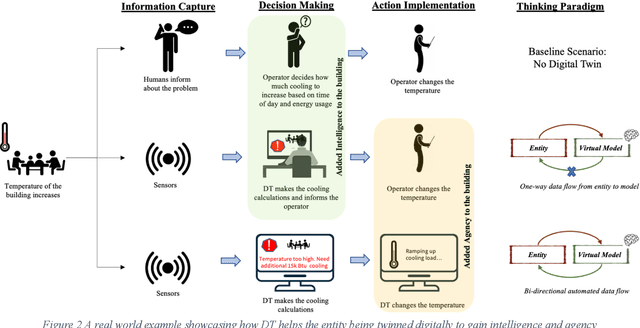
Despite the Digital Twin (DT) concept being in the industry for a long time, it remains ambiguous, unable to differentiate itself from information models, general computing, and simulation technologies. Part of this confusion stems from previous studies overlooking the DT's bidirectional nature, that enables the shift of agency (delegating control) from humans to physical elements, something that was not possible with earlier technologies. Thus, we present DTs in a new light by viewing them as a means of imparting intelligence and agency to entities, emphasizing that DTs are not just expert-centric tools but are active systems that extend the capabilities of the entities being twinned. This new perspective on DTs can help reduce confusion and humanize the concept by starting discussions about how intelligent a DT should be, and its roles and responsibilities, as well as setting a long-term direction for DTs.
Prompt Compression and Contrastive Conditioning for Controllability and Toxicity Reduction in Language Models
Oct 06, 2022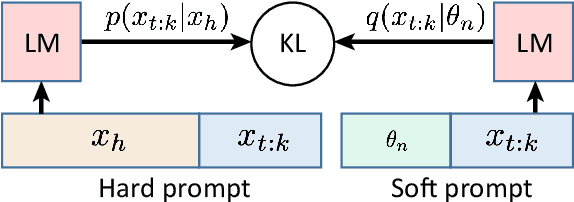

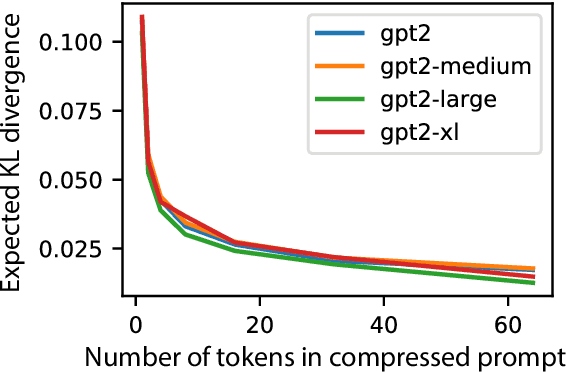
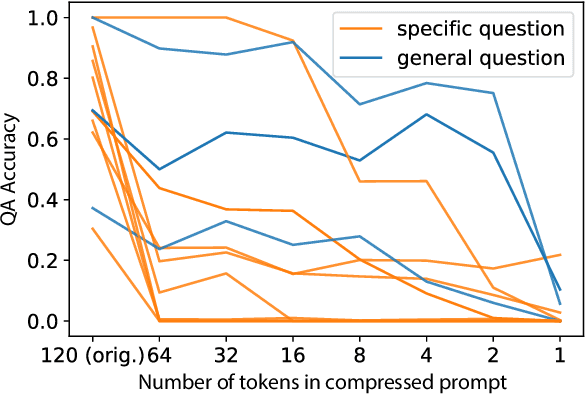
We explore the idea of compressing the prompts used to condition language models, and show that compressed prompts can retain a substantive amount of information about the original prompt. For severely compressed prompts, while fine-grained information is lost, abstract information and general sentiments can be retained with surprisingly few parameters, which can be useful in the context of decode-time algorithms for controllability and toxicity reduction. We explore contrastive conditioning to steer language model generation towards desirable text and away from undesirable text, and find that some complex prompts can be effectively compressed into a single token to guide generation. We also show that compressed prompts are largely compositional, and can be constructed such that they can be used to control independent aspects of generated text.