 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TransVisDrone: Spatio-Temporal Transformer for Vision-based Drone-to-Drone Detection in Aerial Videos
Oct 16, 2022

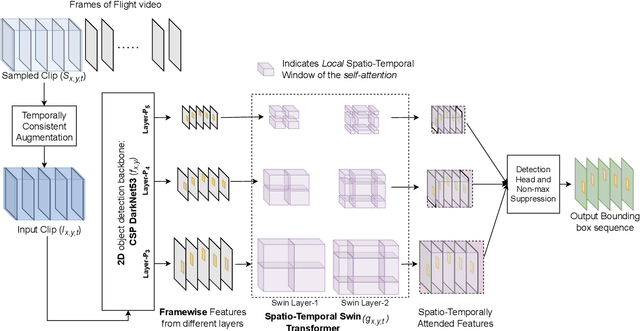
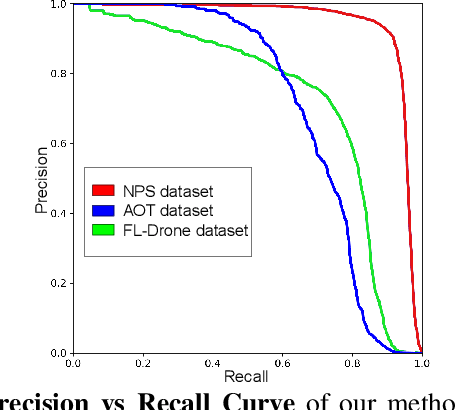
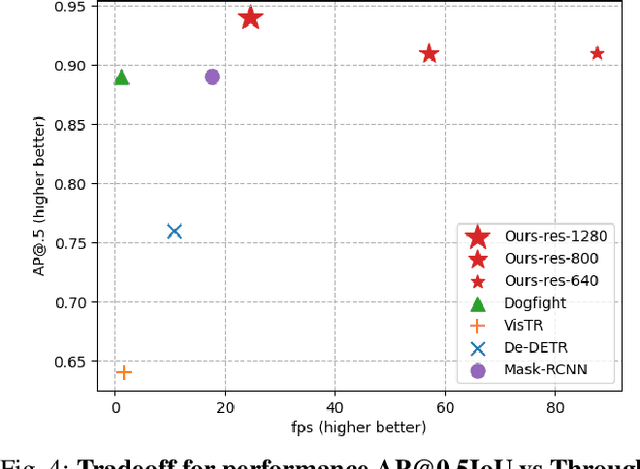
Drone-to-drone detection using visual feed has crucial applications like avoiding collision with other drones/airborne objects, tackling a drone attack or coordinating flight with other drones. However, the existing methods are computationally costly, follow a non-end-to-end optimization and have complex multi-stage pipeline, which make them less suitable to deploy on edge devices for real-time drone flight. In this work, we propose a simple-yet-effective framework TransVisDrone, which provides end-to-end solution with higher computational efficiency. We utilize CSPDarkNet-53 network to learn object-related spatial features and VideoSwin model to learn the spatio-temporal dependencies of drone motion which improves drone detection in challenging scenarios. Our method obtains state-of-the-art performance on three challenging real-world datasets (Average Precision@0.5IOU): NPS 0.95, FLDrones 0.75 and AOT 0.80. Apart from its superior performance, it achieves higher throughput than the prior work. We also demonstrate its deployment capability on edge-computing devices and usefulness in applications like drone-collision (encounter) detection. Code: \url{https://github.com/tusharsangam/TransVisDrone}.
Automatic Emergency Dust-Free solution on-board International Space Station with Bi-GRU (AED-ISS)
Oct 16, 2022
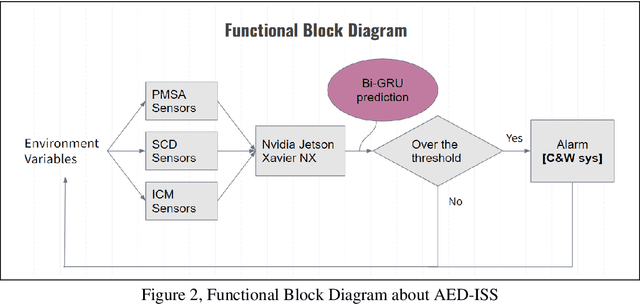
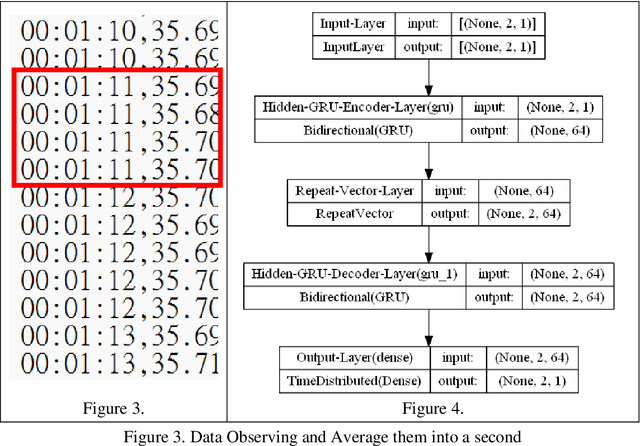
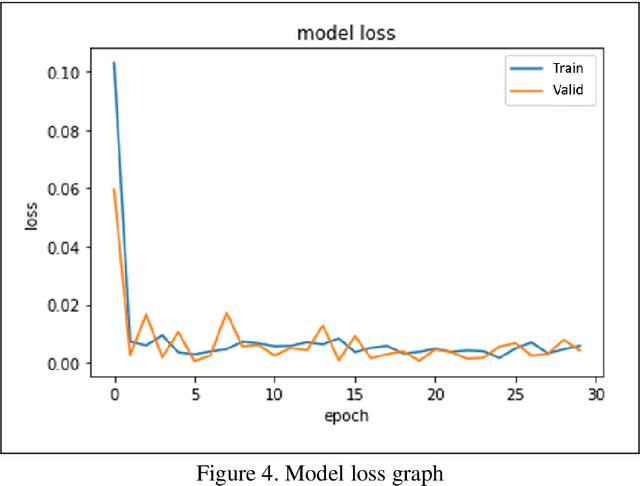
With a rising attention for the issue of PM2.5 or PM0.3, particulate matters have become not only a potential threat to both the environment and human, but also a harming existence to instruments onboard International Space Station (ISS). Our team is aiming to relate various concentration of particulate matters to magnetic fields, humidity, acceleration, temperature, pressure and CO2 concentration. Our goal is to establish an early warning system (EWS), which is able to forecast the levels of particulate matters and provides ample reaction time for astronauts to protect their instruments in some experiments or increase the accuracy of the measurements; In addition, the constructed model can be further developed into a prototype of a remote-sensing smoke alarm for applications related to fires. In this article, we will implement the Bi-GRU (Bidirectional Gated Recurrent Unit) algorithms that collect data for past 90 minutes and predict the levels of particulates which over 2.5 micrometer per 0.1 liter for the next 1 minute, which is classified as an early warning
Deep object detection for waterbird monitoring using aerial imagery
Oct 10, 2022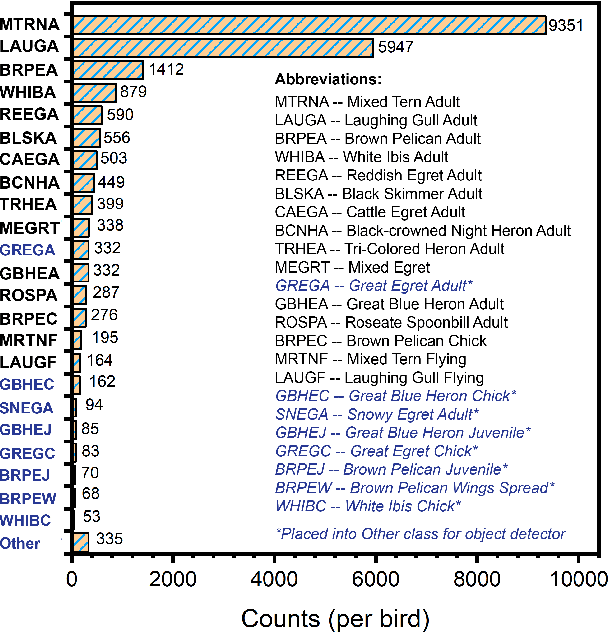
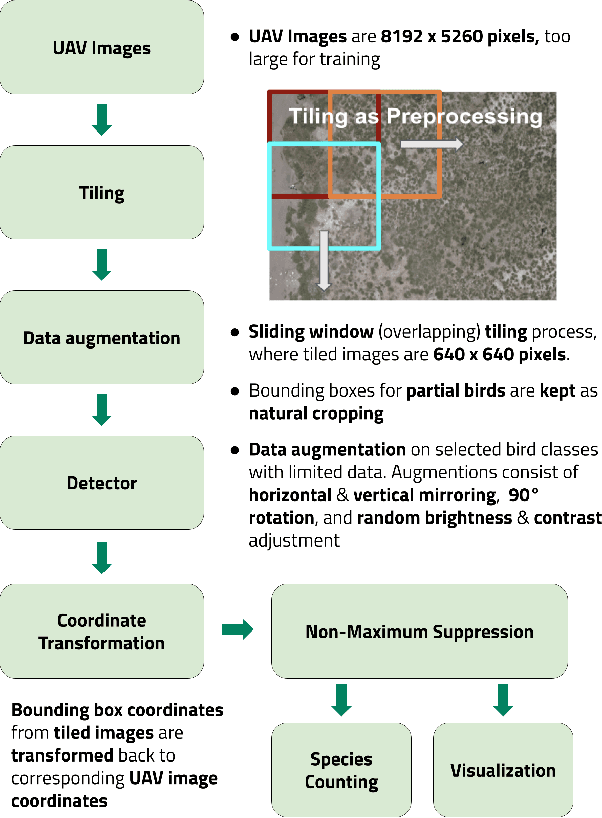
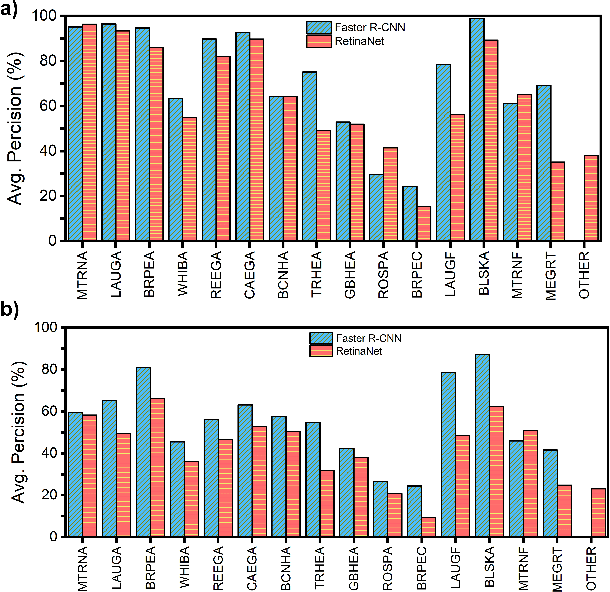
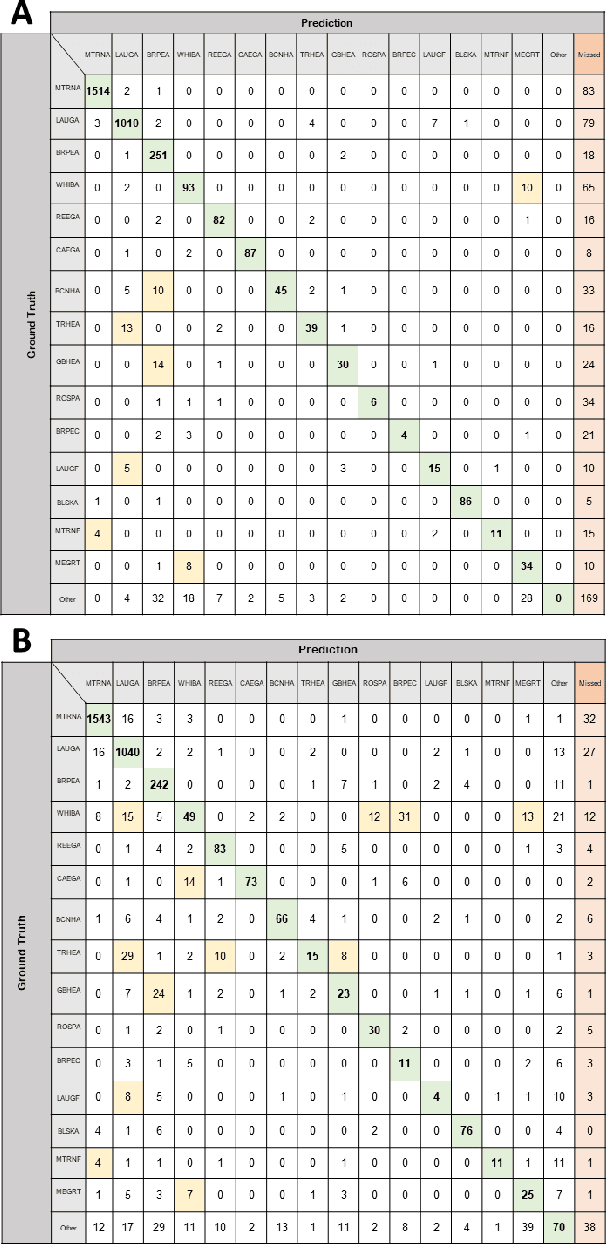
Monitoring of colonial waterbird nesting islands is essential to tracking waterbird population trends, which are used for evaluating ecosystem health and informing conservation management decisions. Recently, unmanned aerial vehicles, or drones, have emerged as a viable technology to precisely monitor waterbird colonies. However, manually counting waterbirds from hundreds, or potentially thousands, of aerial images is both difficult and time-consuming. In this work, we present a deep learning pipeline that can be used to precisely detect, count, and monitor waterbirds using aerial imagery collected by a commercial drone. By utilizing convolutional neural network-based object detectors, we show that we can detect 16 classes of waterbird species that are commonly found in colonial nesting islands along the Texas coast. Our experiments using Faster R-CNN and RetinaNet object detectors give mean interpolated average precision scores of 67.9% and 63.1% respectively.
Multi-Robot Localization and Target Tracking with Connectivity Maintenance and Collision Avoidance
Oct 10, 2022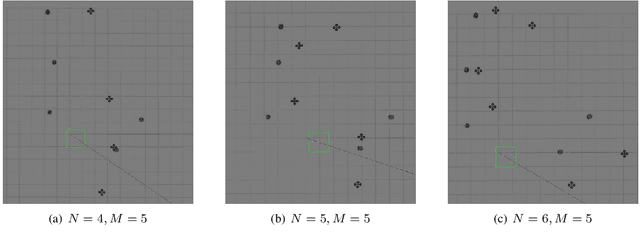
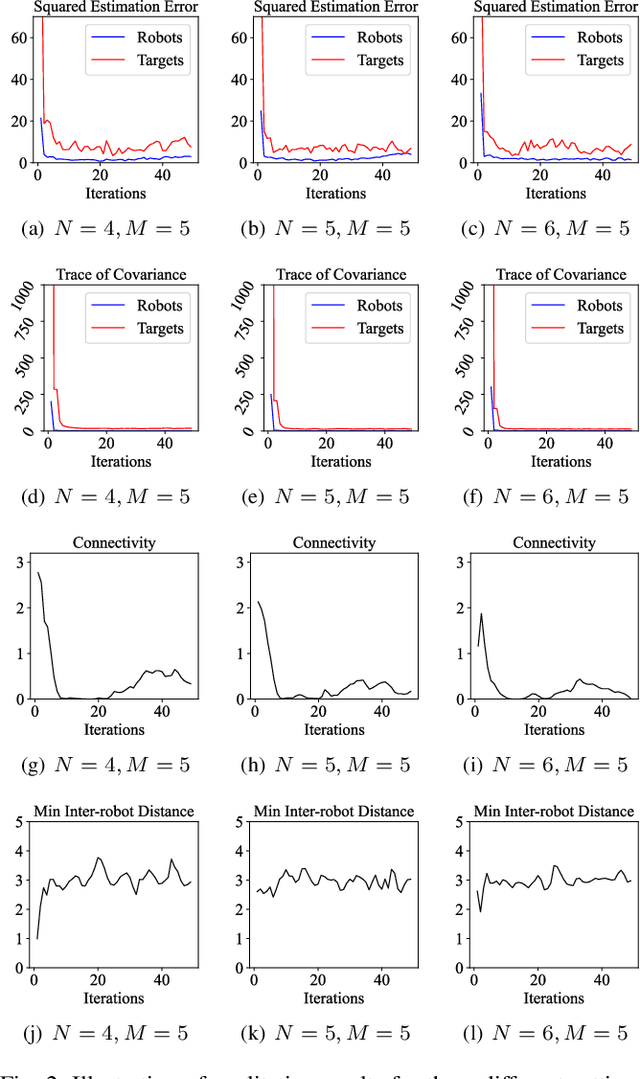
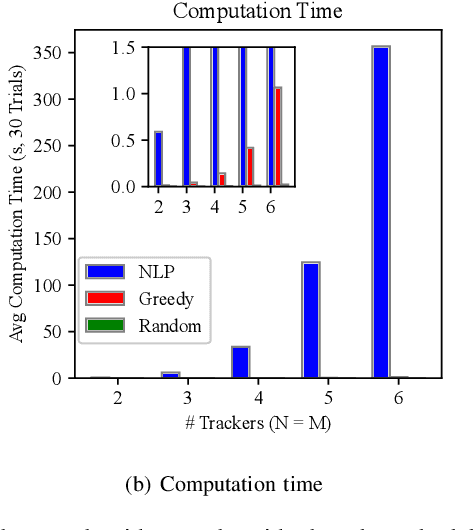
We study the problem that requires a team of robots to perform joint localization and target tracking task while ensuring team connectivity and collision avoidance. The problem can be formalized as a nonlinear, non-convex optimization program, which is typically hard to solve. To this end, we design a two-staged approach that utilizes a greedy algorithm to optimize the joint localization and target tracking performance and applies control barrier functions to ensure safety constraints, i.e., maintaining connectivity of the robot team and preventing inter-robot collisions. Simulated Gazebo experiments verify the effectiveness of the proposed approach. We further compare our greedy algorithm to a non-linear optimization solver and a random algorithm, in terms of the joint localization and tracking quality as well as the computation time. The results demonstrate that our greedy algorithm achieves high task quality and runs efficiently.
ASAP: Adaptive Scheme for Asynchronous Processing of Event-based Vision Algorithms
Sep 18, 2022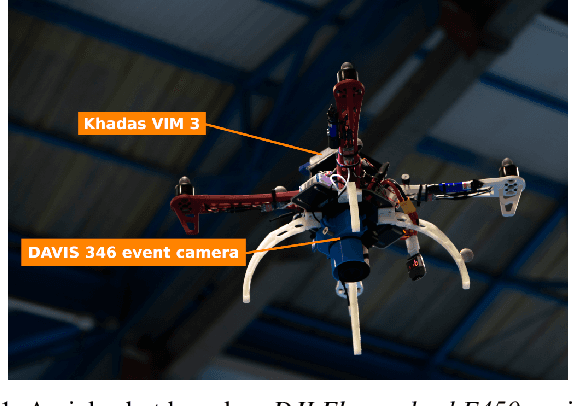
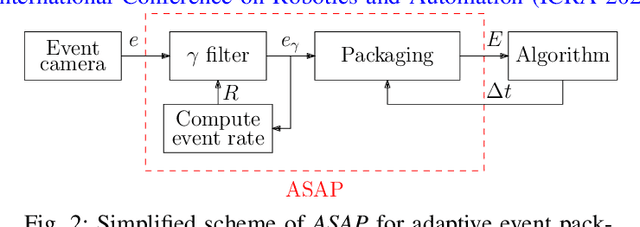

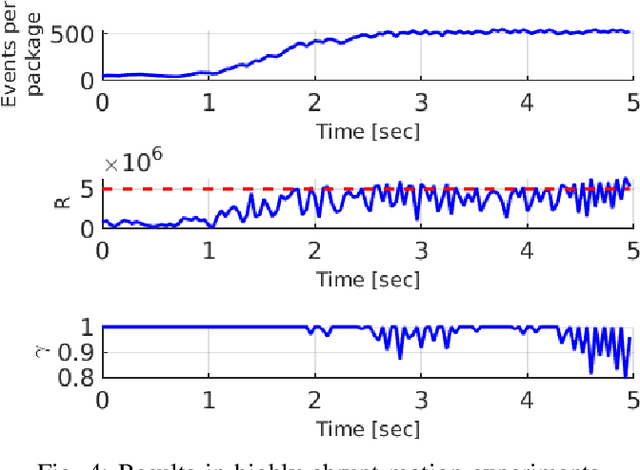
Event cameras can capture pixel-level illumination changes with very high temporal resolution and dynamic range. They have received increasing research interest due to their robustness to lighting conditions and motion blur. Two main approaches exist in the literature to feed the event-based processing algorithms: packaging the triggered events in event packages and sending them one-by-one as single events. These approaches suffer limitations from either processing overflow or lack of responsivity. Processing overflow is caused by high event generation rates when the algorithm cannot process all the events in real-time. Conversely, lack of responsivity happens in cases of low event generation rates when the event packages are sent at too low frequencies. This paper presents ASAP, an adaptive scheme to manage the event stream through variable-size packages that accommodate to the event package processing times. The experimental results show that ASAP is capable of feeding an asynchronous event-by-event clustering algorithm in a responsive and efficient manner and at the same time prevents overflow.
Deep Counterfactual Estimation with Categorical Background Variables
Oct 13, 2022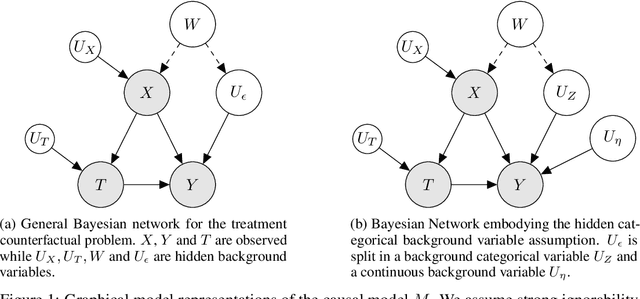
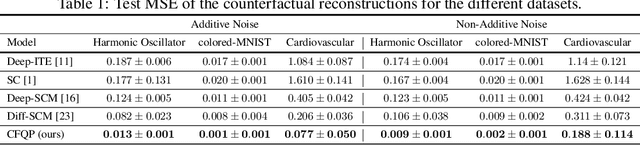
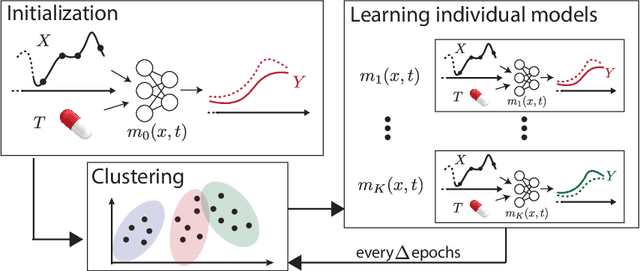
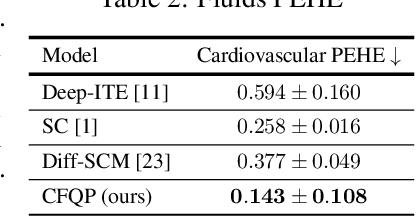
Referred to as the third rung of the causal inference ladder, counterfactual queries typically ask the "What if ?" question retrospectively. The standard approach to estimate counterfactuals resides in using a structural equation model that accurately reflects the underlying data generating process. However, such models are seldom available in practice and one usually wishes to infer them from observational data alone. Unfortunately, the correct structural equation model is in general not identifiable from the observed factual distribution. Nevertheless, in this work, we show that under the assumption that the main latent contributors to the treatment responses are categorical, the counterfactuals can be still reliably predicted. Building upon this assumption, we introduce CounterFactual Query Prediction (CFQP), a novel method to infer counterfactuals from continuous observations when the background variables are categorical. We show that our method significantly outperforms previously available deep-learning-based counterfactual methods, both theoretically and empirically on time series and image data. Our code is available at https://github.com/edebrouwer/cfqp.
Pre-Avatar: An Automatic Presentation Generation Framework Leveraging Talking Avatar
Oct 13, 2022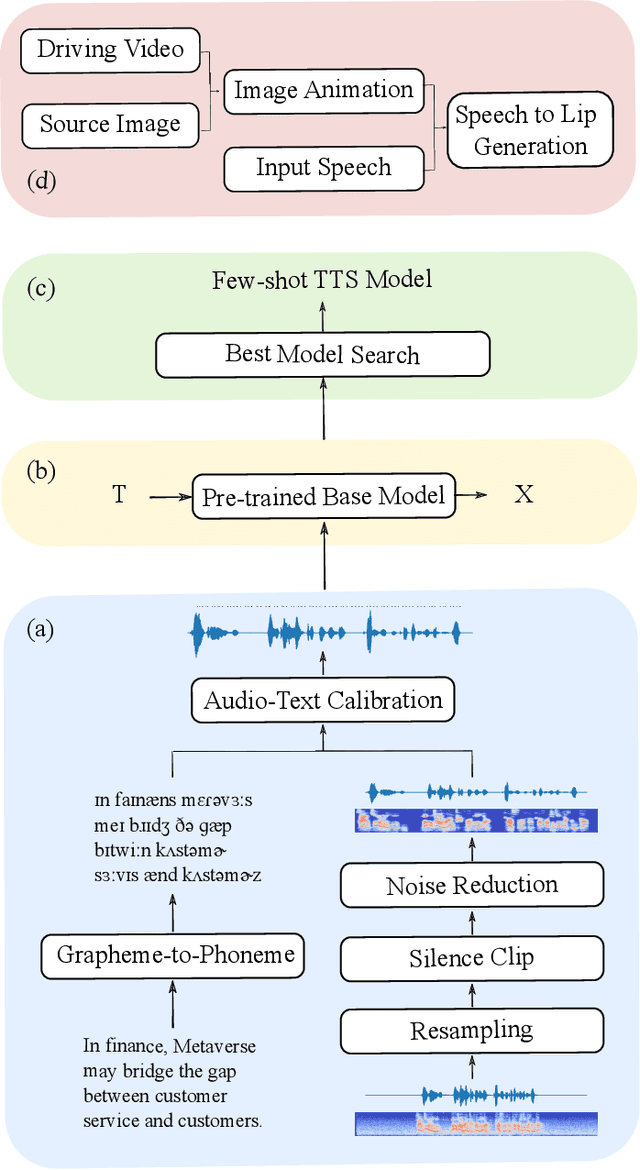
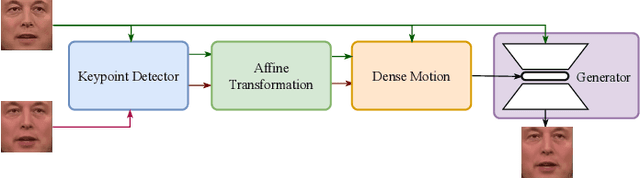

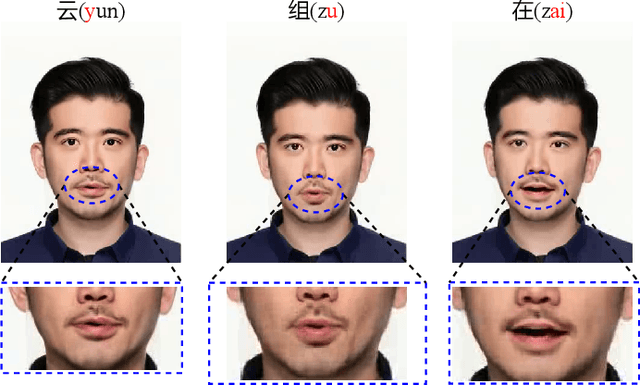
Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous applications aim to save the commuting cost with real-time interactions. However, our application is going to lower the production and reproduction costs when preparing the communication materials. This paper proposes a system called Pre-Avatar, generating a presentation video with a talking face of a target speaker with 1 front-face photo and a 3-minute voice recording. Technically, the system consists of three main modules, user experience interface (UEI), talking face module and few-shot text-to-speech (TTS) module. The system firstly clones the target speaker's voice, and then generates the speech, and finally generate an avatar with appropriate lip and head movements. Under any scenario, users only need to replace slides with different notes to generate another new video. The demo has been released here and will be published as free software for use.
Multiplane NeRF-Supervised Disentanglement of Depth and Camera Pose from Videos
Oct 13, 2022

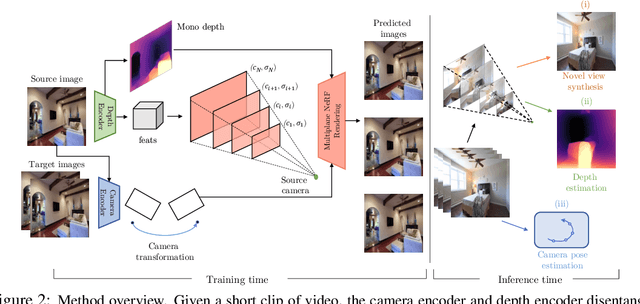
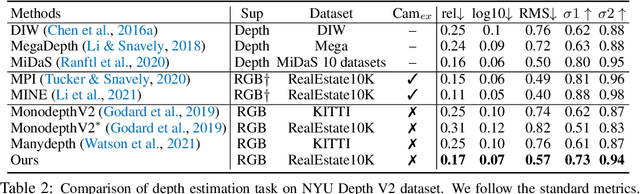
We propose to perform self-supervised disentanglement of depth and camera pose from large-scale videos. We introduce an Autoencoder-based method to reconstruct the input video frames for training, without using any ground-truth annotations of depth and camera. The model encoders estimate the monocular depth and the camera pose. The decoder then constructs a Multiplane NeRF representation based on the depth encoder feature, and renders the input frames with the estimated camera. The learning is supervised by the reconstruction error, based on the assumption that the scene structure does not change in short periods of time in videos. Once the model is learned, it can be applied to multiple applications including depth estimation, camera pose estimation, and single image novel view synthesis. We show substantial improvements over previous self-supervised approaches on all tasks and even better results than counterparts trained with camera ground-truths in some applications. Our code will be made publicly available. Our project page is: https://oasisyang.github.io/self-mpinerf .
An Analysis Method for Metric-Level Switching in Beat Tracking
Oct 13, 2022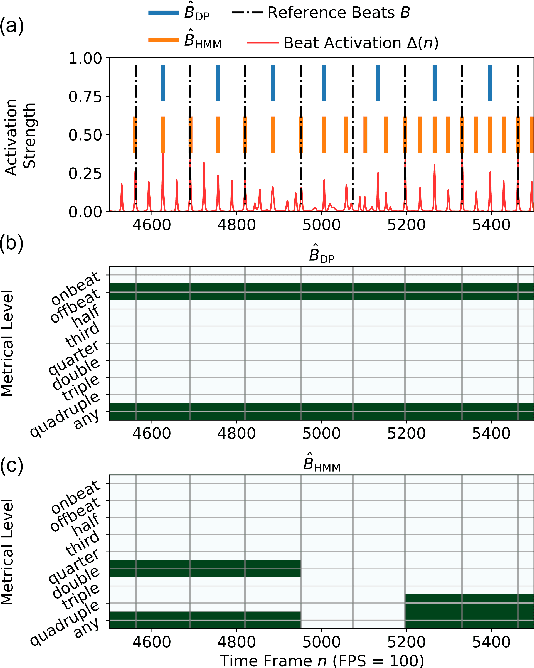
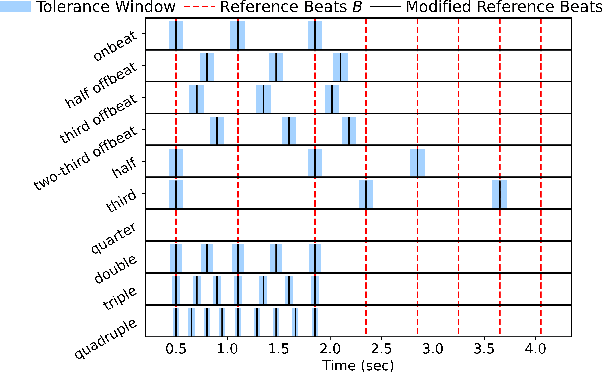
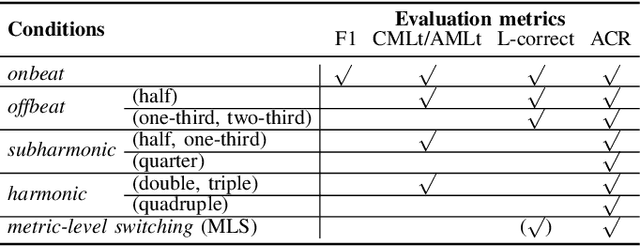
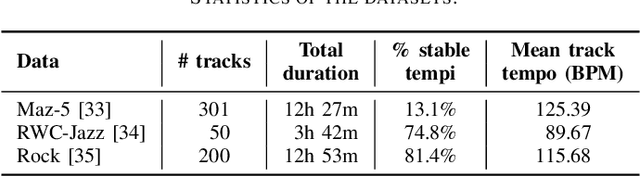
For expressive music, the tempo may change over time, posing challenges to tracking the beats by an automatic model. The model may first tap to the correct tempo, but then may fail to adapt to a tempo change, or switch between several incorrect but perceptually plausible ones (e.g., half- or double-tempo). Existing evaluation metrics for beat tracking do not reflect such behaviors, as they typically assume a fixed relationship between the reference beats and estimated beats. In this paper, we propose a new performance analysis method, called annotation coverage ratio (ACR), that accounts for a variety of possible metric-level switching behaviors of beat trackers. The idea is to derive sequences of modified reference beats of all metrical levels for every two consecutive reference beats, and compare every sequence of modified reference beats to the subsequences of estimated beats. We show via experiments on three datasets of different genres the usefulness of ACR when utilized alongside existing metrics, and discuss the new insights to be gained.
Transfer Deep Reinforcement Learning-based Large-scale V2G Continuous Charging Coordination with Renewable Energy Sources
Oct 13, 2022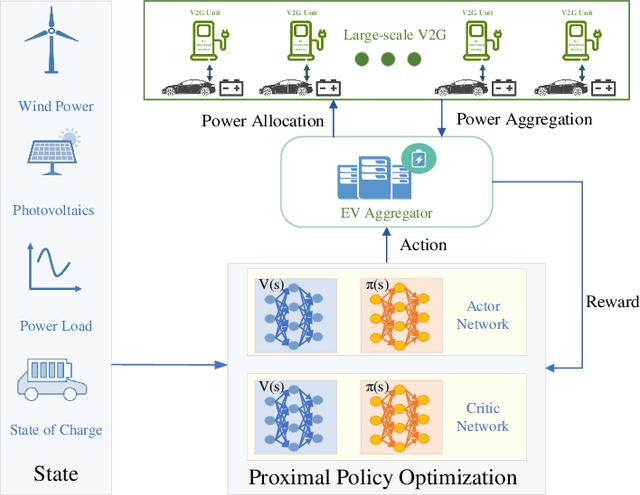
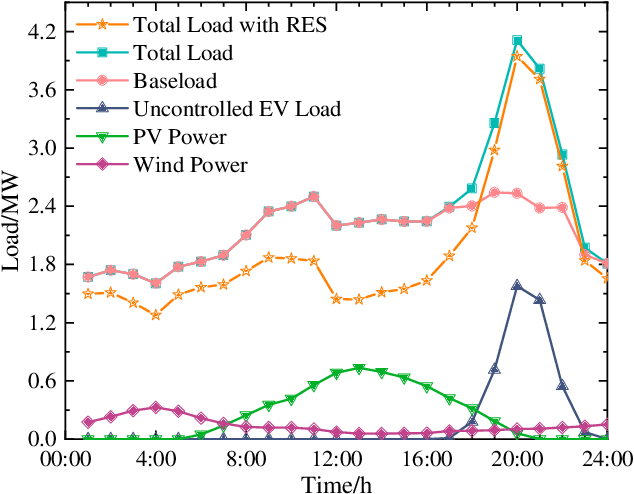
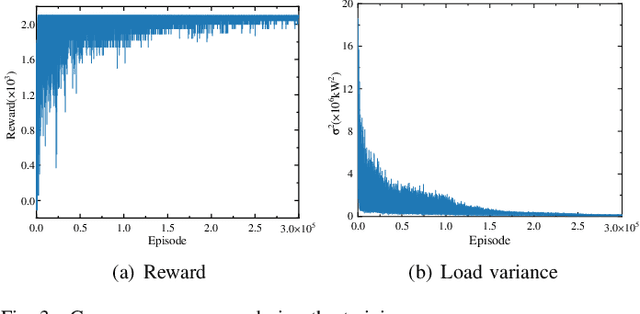

Due to the increasing popularity of electric vehicles (EVs) and the technological advancement of EV electronics, the vehicle-to-grid (V2G) technique and large-scale scheduling algorithms have been developed to achieve a high level of renewable energy and power grid stability. This paper proposes a deep reinforcement learning (DRL) method for the continuous charging/discharging coordination strategy in aggregating large-scale EVs in V2G mode with renewable energy sources (RES). The DRL coordination strategy can efficiently optimize the electric vehicle aggregator's (EVA's) real-time charging/discharging power with the state of charge (SOC) constraints of the EVA and the individual EV. Compared with uncontrolled charging, the load variance is reduced by 97.37$\%$ and the charging cost by 76.56$\%$. The DRL coordination strategy further demonstrates outstanding transfer learning ability to microgrids with RES and large-scale EVA, as well as the complicated weekly scheduling. The DRL coordination strategy demonstrates flexible, adaptable, and scalable performance for the large-scale V2G under realistic operating conditions.