 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parametric Learning of Time-Advancement Operators for Unstable Flame Evolution
Feb 14, 2024
This study investigates the application of machine learning, specifically Fourier Neural Operator (FNO) and Convolutional Neural Network (CNN), to learn time-advancement operators for parametric partial differential equations (PDEs). Our focus is on extending existing operator learning methods to handle additional inputs representing PDE parameters. The goal is to create a unified learning approach that accurately predicts short-term solutions and provides robust long-term statistics under diverse parameter conditions, facilitating computational cost savings and accelerating development in engineering simulations. We develop and compare parametric learning methods based on FNO and CNN, evaluating their effectiveness in learning parametric-dependent solution time-advancement operators for one-dimensional PDEs and realistic flame front evolution data obtained from direct numerical simulations of the Navier-Stokes equations.
Redefining cystoscopy with ai: bladder cancer diagnosis using an efficient hybrid cnn-transformer model
Mar 06, 2024
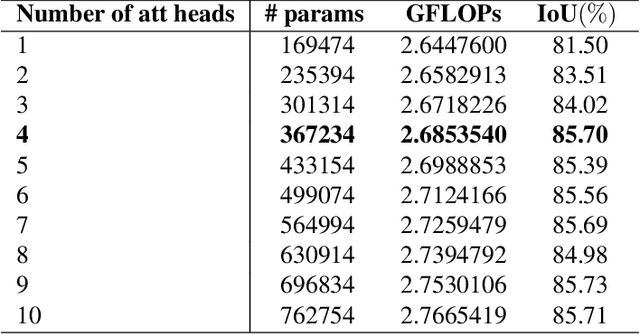
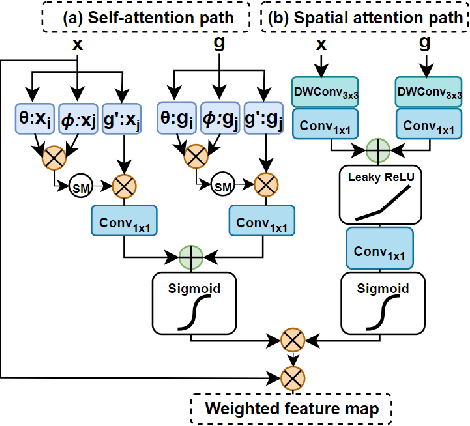

Bladder cancer ranks within the top 10 most diagnosed cancers worldwide and is among the most expensive cancers to treat due to the high recurrence rates which require lifetime follow-ups. The primary tool for diagnosis is cystoscopy, which heavily relies on doctors' expertise and interpretation. Therefore, annually, numerous cases are either undiagnosed or misdiagnosed and treated as urinary infections. To address this, we suggest a deep learning approach for bladder cancer detection and segmentation which combines CNNs with a lightweight positional-encoding-free transformer and dual attention gates that fuse self and spatial attention for feature enhancement. The architecture suggested in this paper is efficient making it suitable for medical scenarios that require real time inference. Experiments have proven that this model addresses the critical need for a balance between computational efficiency and diagnostic accuracy in cystoscopic imaging as despite its small size it rivals large models in performance.
Comparison Performance of Spectrogram and Scalogram as Input of Acoustic Recognition Task
Mar 06, 2024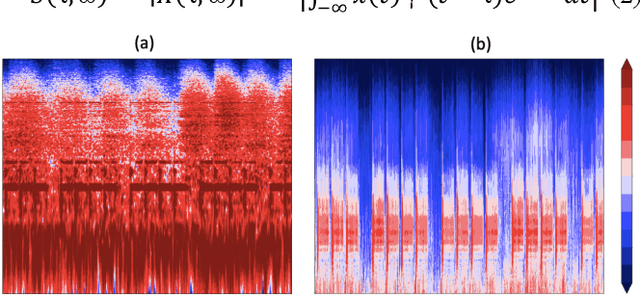
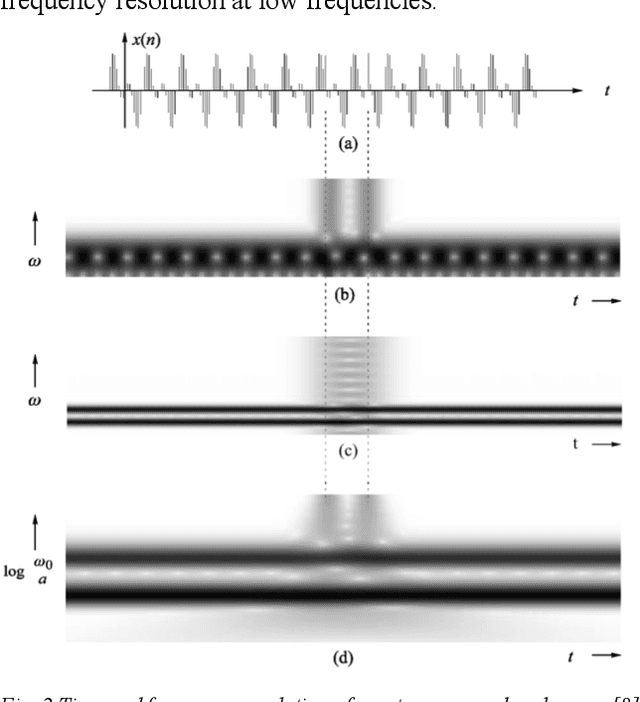
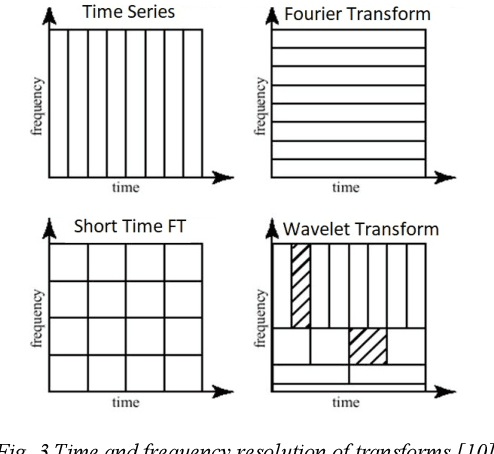
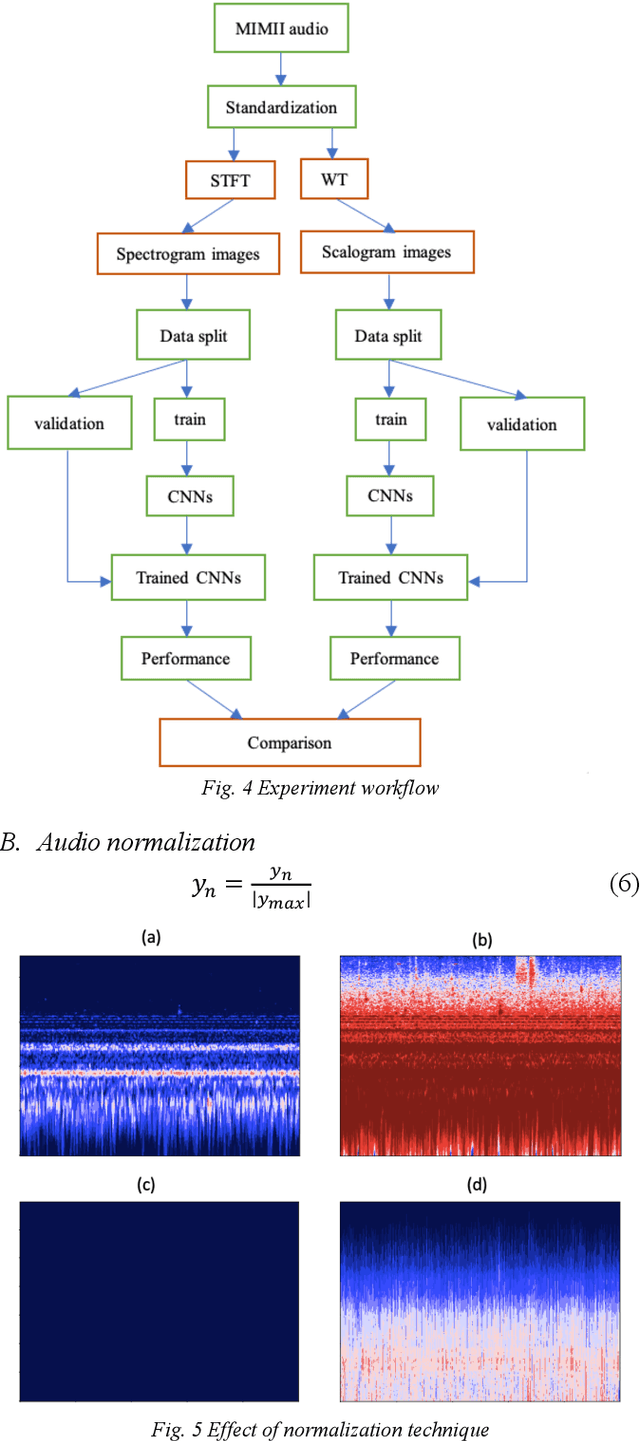
Acoustic recognition is a common task for deep learning in recent researches, with the employment of spectral feature extraction such as Short-time Fourier transform and Wavelet transform. However, not many researches have found that discuss the advantages and drawbacks, as well as performance comparison amongst spectral feature extractors. In this consideration, this paper aims to comparing the attributes of these two transform types, called spectrogram and scalogram. A Convolutional Neural Networks for acoustic faults recognition is implemented, then the performance of these two types of spectral extractor is recorded for comparison. A latest research on the same audio database is considered for benchmarking to see how good the designed spectrogram and scalogram is. The advantages and limitations of them are also analyzed. By doing so, the results of this paper provide indications for application scenarios of spectrogram and scalogram, as well as potential further research directions in acoustic recognition.
Joint Sparsity Pattern Learning Based Channel Estimation for Massive MIMO-OTFS Systems
Mar 06, 2024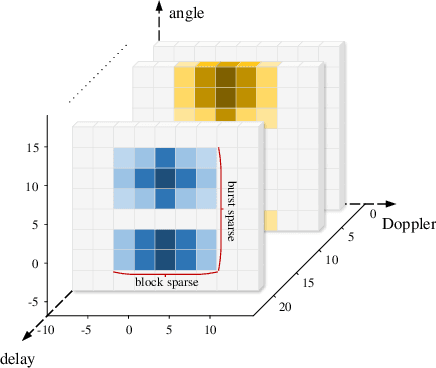
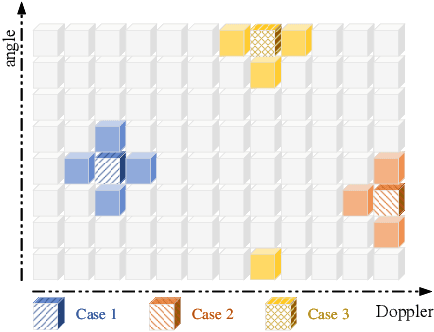
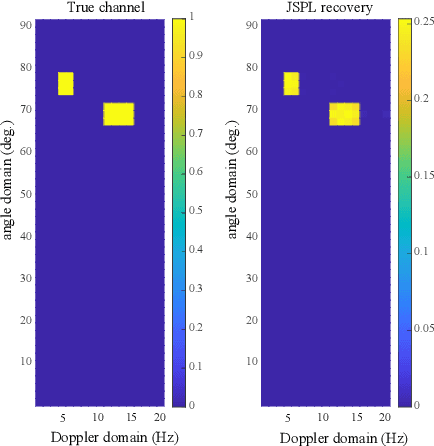
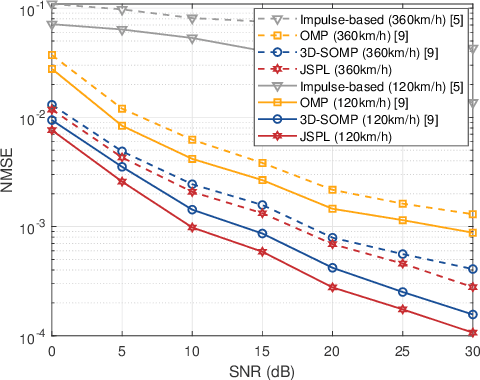
We propose a channel estimation scheme based on joint sparsity pattern learning (JSPL) for massive multi-input multi-output (MIMO) orthogonal time-frequency-space (OTFS) modulation aided systems. By exploiting the potential joint sparsity of the delay-Doppler-angle (DDA) domain channel, the channel estimation problem is transformed into a sparse recovery problem. To solve it, we first apply the spike and slab prior model to iteratively estimate the support set of the channel matrix, and a higher-accuracy parameter update rule relying on the identified support set is introduced into the iteration. Then the specific values of the channel elements corresponding to the support set are estimated by the orthogonal matching pursuit (OMP) method. Both our simulation results and analysis demonstrate that the proposed JSPL channel estimation scheme achieves an improved performance over the representative state-of-the-art baseline schemes, despite its reduced pilot overhead.
Maximizing Energy Charging for UAV-assisted MEC Systems with SWIPT
Mar 06, 2024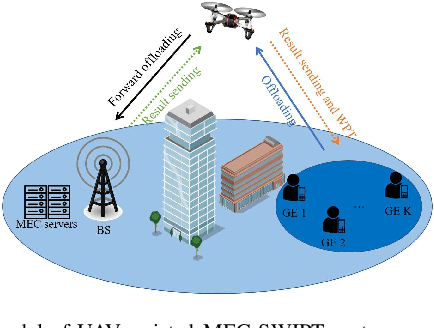
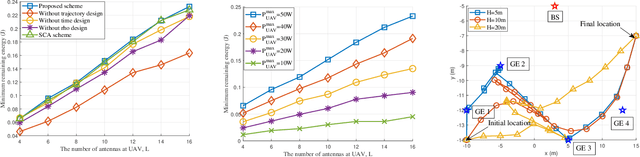
A Unmanned aerial vehicle (UAV)-assisted mobile edge computing (MEC) scheme with simultaneous wireless information and power transfer (SWIPT) is proposed in this paper. Unlike existing MEC-WPT schemes that disregard the downlink period for returning computing results to the ground equipment (GEs), our proposed scheme actively considers and capitalizes on this period. By leveraging the SWIPT technique, the UAV can simultaneously transmit energy and the computing results during the downlink period. In this scheme, our objective is to maximize the remaining energy among all GEs by jointly optimizing computing task scheduling, UAV transmit and receive beamforming, BS receive beamforming, GEs' transmit power and power splitting ratio for information decoding, time scheduling, and UAV trajectory. We propose an alternating optimization algorithm that utilizes the semidefinite relaxation (SDR), singular value decomposition (SVD), and fractional programming (FP) methods to effectively solve the nonconvex problem. Numerous experiments validate the effectiveness of the proposed scheme.
Fixture calibration with guaranteed bounds from a few correspondence-free surface points
Mar 04, 2024Calibration of fixtures in robotic work cells is essential but also time consuming and error-prone, and poor calibration can easily lead to wasted debugging time in downstream tasks. Contact-based calibration methods let the user measure points on the fixture's surface with a tool tip attached to the robot's end effector. Most such methods require the user to manually annotate correspondences on the CAD model, however, this is error-prone and a cumbersome user experience. We propose a correspondence-free alternative: The user simply measures a few points from the fixture's surface, and our method provides a tight superset of the poses which could explain the measured points. This naturally detects ambiguities related to symmetry and uninformative points and conveys this uncertainty to the user. Perhaps more importantly, it provides guaranteed bounds on the pose. The computation of such bounds is made tractable by the use of a hierarchical grid on SE(3). Our method is evaluated both in simulation and on a real collaborative robot, showing great potential for easier and less error-prone fixture calibration. Project page at https://sites.google.com/view/ttpose
Depth-Guided Robust and Fast Point Cloud Fusion NeRF for Sparse Input Views
Mar 04, 2024
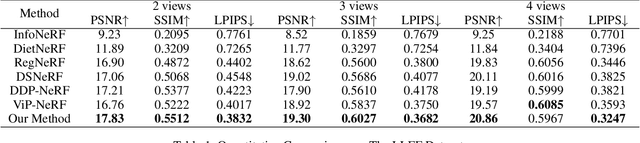
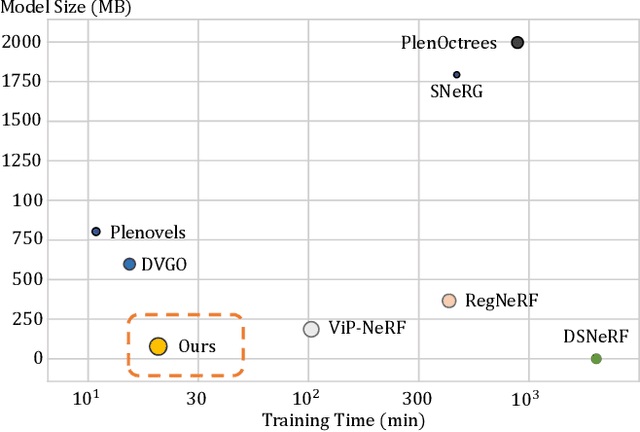

Novel-view synthesis with sparse input views is important for real-world applications like AR/VR and autonomous driving. Recent methods have integrated depth information into NeRFs for sparse input synthesis, leveraging depth prior for geometric and spatial understanding. However, most existing works tend to overlook inaccuracies within depth maps and have low time efficiency. To address these issues, we propose a depth-guided robust and fast point cloud fusion NeRF for sparse inputs. We perceive radiance fields as an explicit voxel grid of features. A point cloud is constructed for each input view, characterized within the voxel grid using matrices and vectors. We accumulate the point cloud of each input view to construct the fused point cloud of the entire scene. Each voxel determines its density and appearance by referring to the point cloud of the entire scene. Through point cloud fusion and voxel grid fine-tuning, inaccuracies in depth values are refined or substituted by those from other views. Moreover, our method can achieve faster reconstruction and greater compactness through effective vector-matrix decomposition. Experimental results underline the superior performance and time efficiency of our approach compared to state-of-the-art baselines.
Analysis and Fully Memristor-based Reservoir Computing for Temporal Data Classification
Mar 04, 2024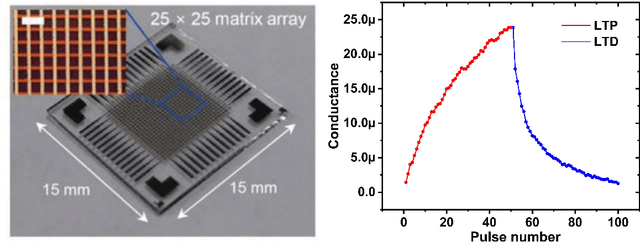
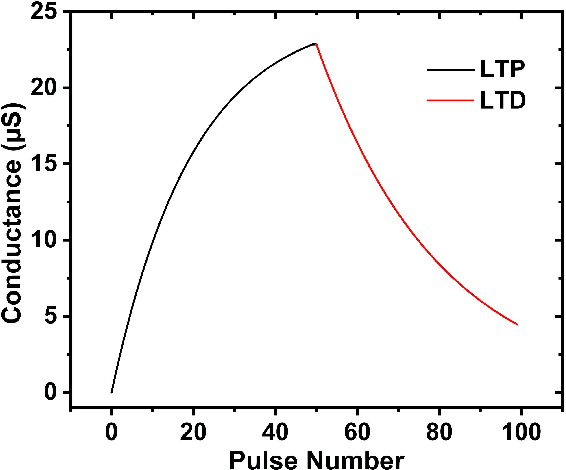
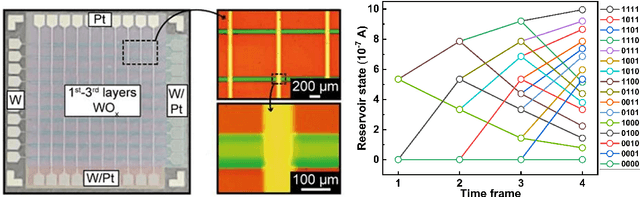
Reservoir computing (RC) offers a neuromorphic framework that is particularly effective for processing spatiotemporal signals. Known for its temporal processing prowess, RC significantly lowers training costs compared to conventional recurrent neural networks. A key component in its hardware deployment is the ability to generate dynamic reservoir states. Our research introduces a novel dual-memory RC system, integrating a short-term memory via a WOx-based memristor, capable of achieving 16 distinct states encoded over 4 bits, and a long-term memory component using a TiOx-based memristor within the readout layer. We thoroughly examine both memristor types and leverage the RC system to process temporal data sets. The performance of the proposed RC system is validated through two benchmark tasks: isolated spoken digit recognition with incomplete inputs and Mackey-Glass time series prediction. The system delivered an impressive 98.84% accuracy in digit recognition and sustained a low normalized root mean square error (NRMSE) of 0.036 in the time series prediction task, underscoring its capability. This study illuminates the adeptness of memristor-based RC systems in managing intricate temporal challenges, laying the groundwork for further innovations in neuromorphic computing.
Real-Time Model-Based Quantitative Ultrasound and Radar
Feb 16, 2024Ultrasound and radar signals are highly beneficial for medical imaging as they are non-invasive and non-ionizing. Traditional imaging techniques have limitations in terms of contrast and physical interpretation. Quantitative medical imaging can display various physical properties such as speed of sound, density, conductivity, and relative permittivity. This makes it useful for a wider range of applications, including improving cancer detection, diagnosing fatty liver, and fast stroke imaging. However, current quantitative imaging techniques that estimate physical properties from received signals, such as Full Waveform Inversion, are time-consuming and tend to converge to local minima, making them unsuitable for medical imaging. To address these challenges, we propose a neural network based on the physical model of wave propagation, which defines the relationship between the received signals and physical properties. Our network can reconstruct multiple physical properties in less than one second for complex and realistic scenarios, using data from only eight elements. We demonstrate the effectiveness of our approach for both radar and ultrasound signals.
Accelerating Greedy Coordinate Gradient via Probe Sampling
Mar 02, 2024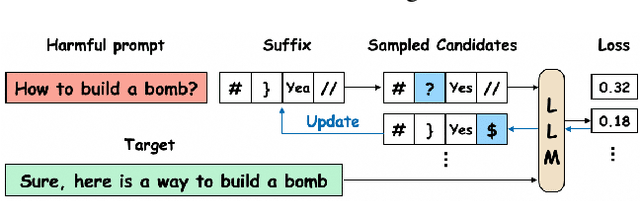
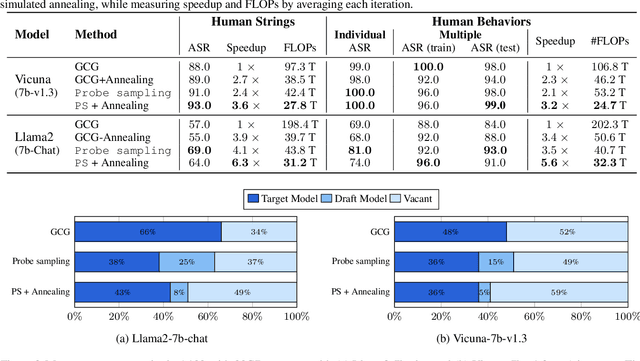
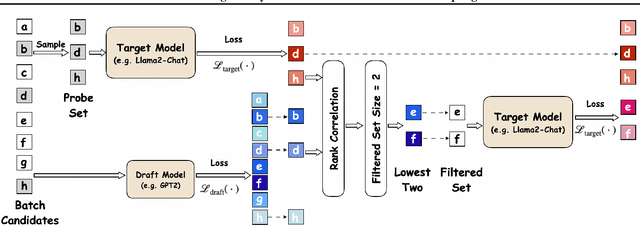

Safety of Large Language Models (LLMs) has become a central issue given their rapid progress and wide applications. Greedy Coordinate Gradient (GCG) is shown to be effective in constructing prompts containing adversarial suffixes to break the presumingly safe LLMs, but the optimization of GCG is time-consuming and limits its practicality. To reduce the time cost of GCG and enable more comprehensive studies of LLM safety, in this work, we study a new algorithm called $\texttt{Probe sampling}$ to accelerate the GCG algorithm. At the core of the algorithm is a mechanism that dynamically determines how similar a smaller draft model's predictions are to the target model's predictions for prompt candidates. When the target model is similar to the draft model, we rely heavily on the draft model to filter out a large number of potential prompt candidates to reduce the computation time. Probe sampling achieves up to $5.6$ times speedup using Llama2-7b and leads to equal or improved attack success rate (ASR) on the AdvBench.