 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Block-Structured Optimization for Subgraph Detection in Interdependent Networks
Oct 06, 2022
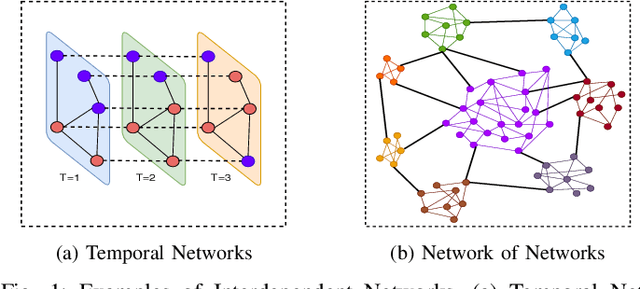
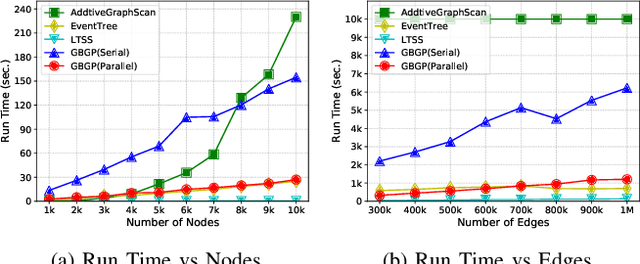
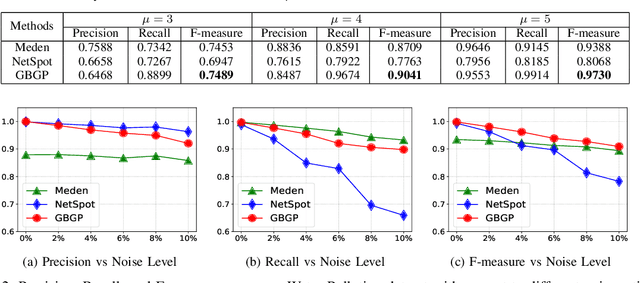
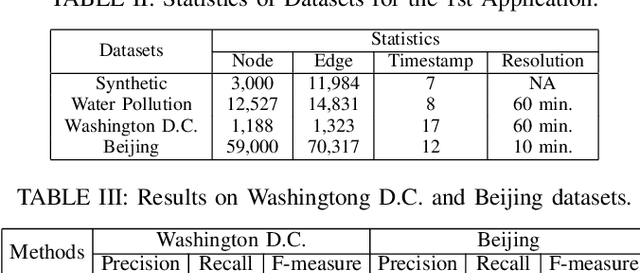
We propose a generalized framework for block-structured nonconvex optimization, which can be applied to structured subgraph detection in interdependent networks, such as multi-layer networks, temporal networks, networks of networks, and many others. Specifically, we design an effective, efficient, and parallelizable projection algorithm, namely Graph Block-structured Gradient Projection (GBGP), to optimize a general non-linear function subject to graph-structured constraints. We prove that our algorithm: 1) runs in nearly-linear time on the network size; 2) enjoys a theoretical approximation guarantee. Moreover, we demonstrate how our framework can be applied to two very practical applications and conduct comprehensive experiments to show the effectiveness and efficiency of our proposed algorithm.
RbX: Region-based explanations of prediction models
Oct 17, 2022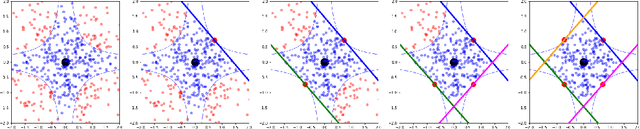

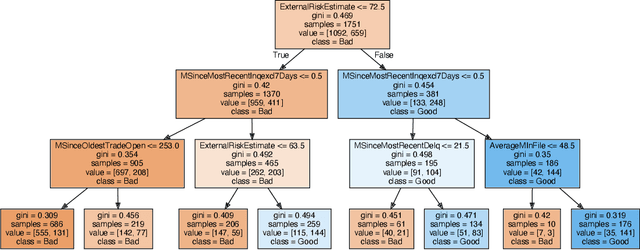

We introduce region-based explanations (RbX), a novel, model-agnostic method to generate local explanations of scalar outputs from a black-box prediction model using only query access. RbX is based on a greedy algorithm for building a convex polytope that approximates a region of feature space where model predictions are close to the prediction at some target point. This region is fully specified by the user on the scale of the predictions, rather than on the scale of the features. The geometry of this polytope - specifically the change in each coordinate necessary to escape the polytope - quantifies the local sensitivity of the predictions to each of the features. These "escape distances" can then be standardized to rank the features by local importance. RbX is guaranteed to satisfy a "sparsity axiom," which requires that features which do not enter into the prediction model are assigned zero importance. At the same time, real data examples and synthetic experiments show how RbX can more readily detect all locally relevant features than existing methods.
Transferring Knowledge via Neighborhood-Aware Optimal Transport for Low-Resource Hate Speech Detection
Oct 17, 2022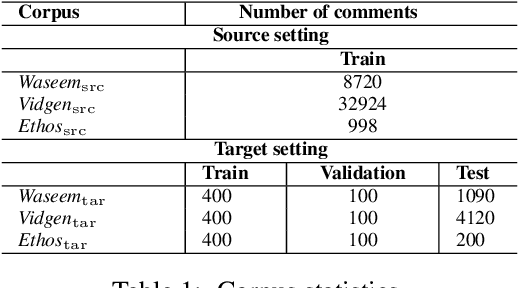
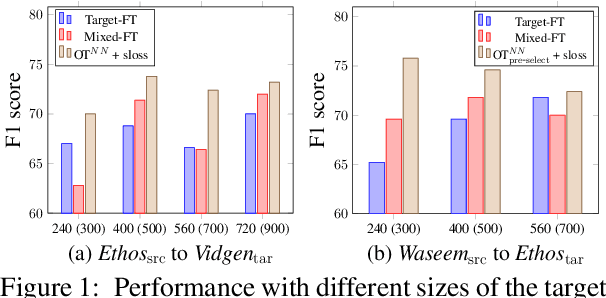

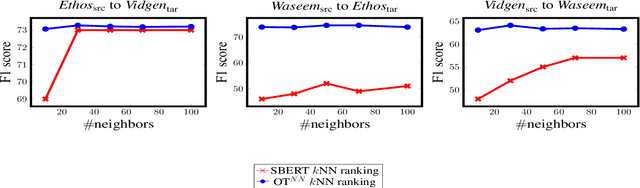
The concerning rise of hateful content on online platforms has increased the attention towards automatic hate speech detection, commonly formulated as a supervised classification task. State-of-the-art deep learning-based approaches usually require a substantial amount of labeled resources for training. However, annotating hate speech resources is expensive, time-consuming, and often harmful to the annotators. This creates a pressing need to transfer knowledge from the existing labeled resources to low-resource hate speech corpora with the goal of improving system performance. For this, neighborhood-based frameworks have been shown to be effective. However, they have limited flexibility. In our paper, we propose a novel training strategy that allows flexible modeling of the relative proximity of neighbors retrieved from a resource-rich corpus to learn the amount of transfer. In particular, we incorporate neighborhood information with Optimal Transport, which permits exploiting the geometry of the data embedding space. By aligning the joint embedding and label distributions of neighbors, we demonstrate substantial improvements over strong baselines, in low-resource scenarios, on different publicly available hate speech corpora.
Data-Driven Short-Term Daily Operational Sea Ice Regional Forecasting
Oct 17, 2022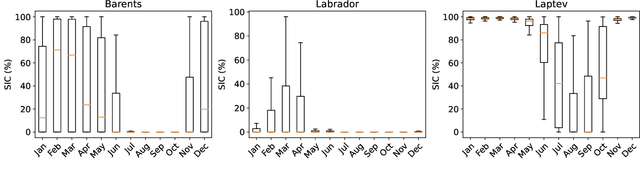
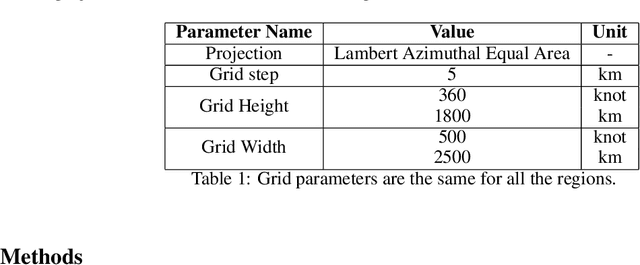
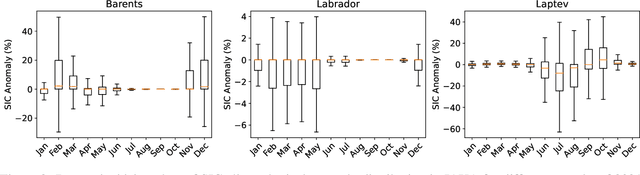

Global warming made the Arctic available for marine operations and created demand for reliable operational sea ice forecasts to make them safe. While ocean-ice numerical models are highly computationally intensive, relatively lightweight ML-based methods may be more efficient in this task. Many works have exploited different deep learning models alongside classical approaches for predicting sea ice concentration in the Arctic. However, only a few focus on daily operational forecasts and consider the real-time availability of data they need for operation. In this work, we aim to close this gap and investigate the performance of the U-Net model trained in two regimes for predicting sea ice for up to the next 10 days. We show that this deep learning model can outperform simple baselines by a significant margin and improve its quality by using additional weather data and training on multiple regions, ensuring its generalization abilities. As a practical outcome, we build a fast and flexible tool that produces operational sea ice forecasts in the Barents Sea, the Labrador Sea, and the Laptev Sea regions.
A Transfer Learning Based Approach for Classification of COVID-19 and Pneumonia in CT Scan Imaging
Oct 17, 2022
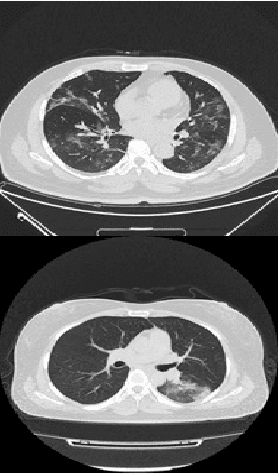
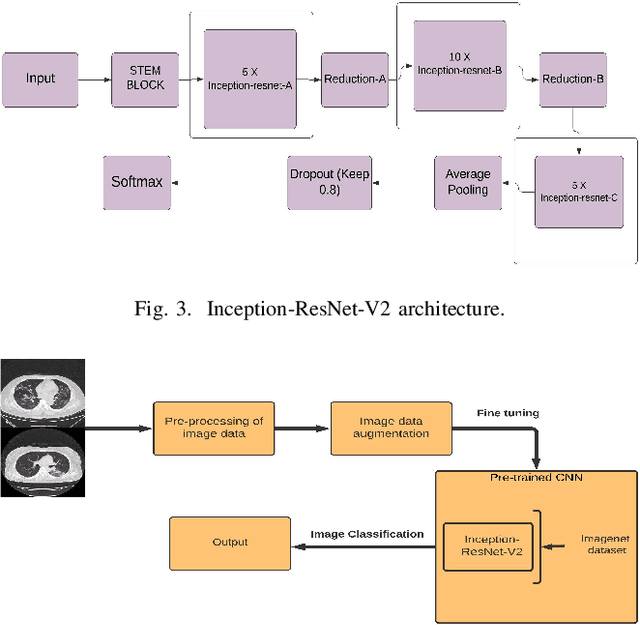
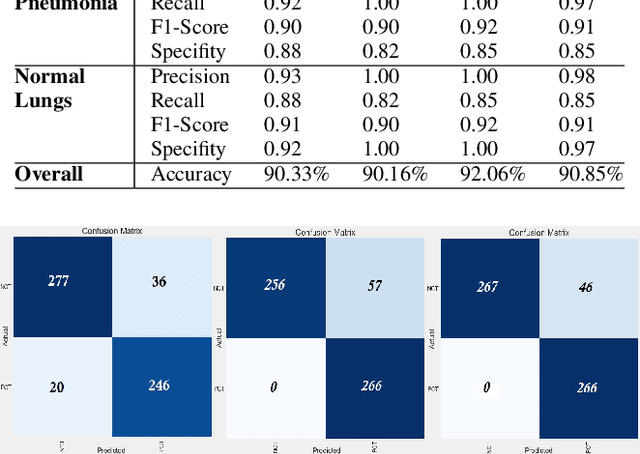
The world is still overwhelmed by the spread of the COVID-19 virus. With over 250 Million infected cases as of November 2021 and affecting 219 countries and territories, the world remains in the pandemic period. Detecting COVID-19 using the deep learning method on CT scan images can play a vital role in assisting medical professionals and decision authorities in controlling the spread of the disease and providing essential support for patients. The convolution neural network is widely used in the field of large-scale image recognition. The current method of RT-PCR to diagnose COVID-19 is time-consuming and universally limited. This research aims to propose a deep learning-based approach to classify COVID-19 pneumonia patients, bacterial pneumonia, viral pneumonia, and healthy (normal cases). This paper used deep transfer learning to classify the data via Inception-ResNet-V2 neural network architecture. The proposed model has been intentionally simplified to reduce the implementation cost so that it can be easily implemented and used in different geographical areas, especially rural and developing regions.
Towards Generating Adversarial Examples on Mixed-type Data
Oct 17, 2022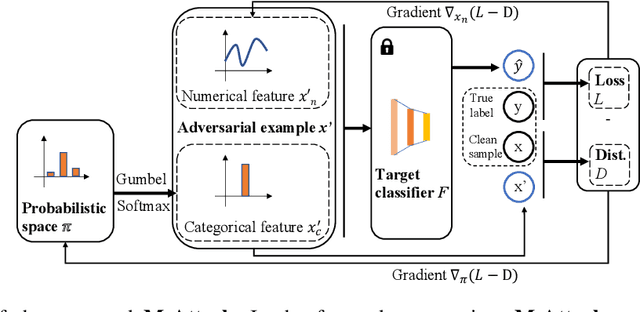
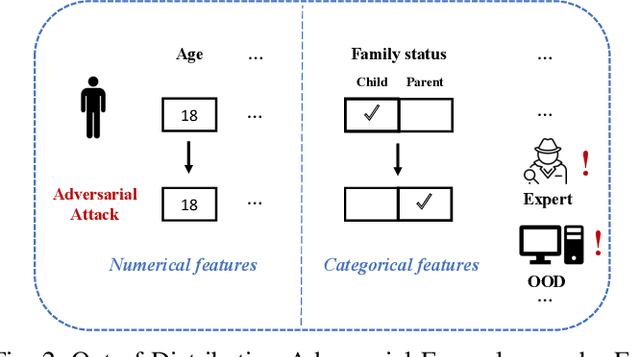
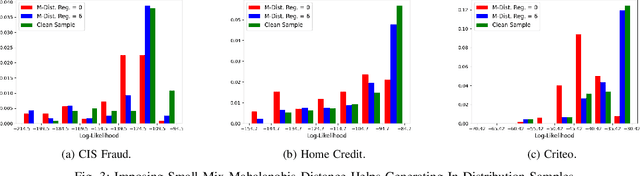
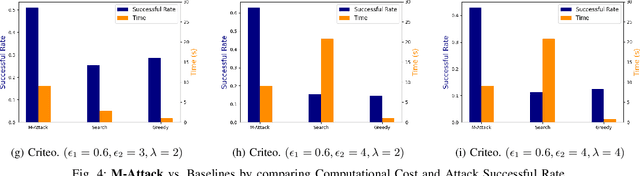
The existence of adversarial attacks (or adversarial examples) brings huge concern about the machine learning (ML) model's safety issues. For many safety-critical ML tasks, such as financial forecasting, fraudulent detection, and anomaly detection, the data samples are usually mixed-type, which contain plenty of numerical and categorical features at the same time. However, how to generate adversarial examples with mixed-type data is still seldom studied. In this paper, we propose a novel attack algorithm M-Attack, which can effectively generate adversarial examples in mixed-type data. Based on M-Attack, attackers can attempt to mislead the targeted classification model's prediction, by only slightly perturbing both the numerical and categorical features in the given data samples. More importantly, by adding designed regularizations, our generated adversarial examples can evade potential detection models, which makes the attack indeed insidious. Through extensive empirical studies, we validate the effectiveness and efficiency of our attack method and evaluate the robustness of existing classification models against our proposed attack. The experimental results highlight the feasibility of generating adversarial examples toward machine learning models in real-world applications.
Sufficient Exploration for Convex Q-learning
Oct 17, 2022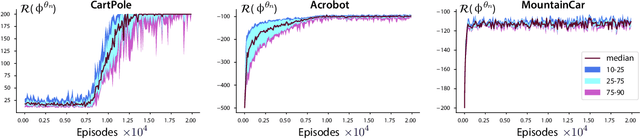
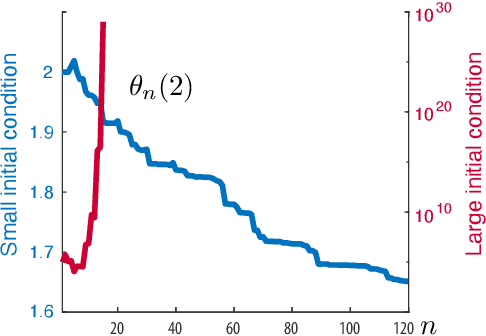
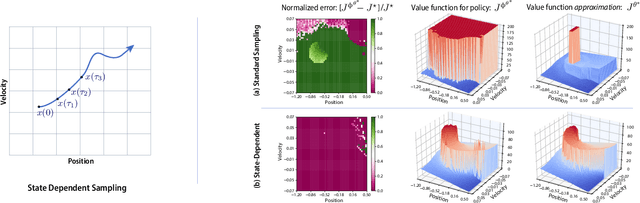

In recent years there has been a collective research effort to find new formulations of reinforcement learning that are simultaneously more efficient and more amenable to analysis. This paper concerns one approach that builds on the linear programming (LP) formulation of optimal control of Manne. A primal version is called logistic Q-learning, and a dual variant is convex Q-learning. This paper focuses on the latter, while building bridges with the former. The main contributions follow: (i) The dual of convex Q-learning is not precisely Manne's LP or a version of logistic Q-learning, but has similar structure that reveals the need for regularization to avoid over-fitting. (ii) A sufficient condition is obtained for a bounded solution to the Q-learning LP. (iii) Simulation studies reveal numerical challenges when addressing sampled-data systems based on a continuous time model. The challenge is addressed using state-dependent sampling. The theory is illustrated with applications to examples from OpenAI gym. It is shown that convex Q-learning is successful in cases where standard Q-learning diverges, such as the LQR problem.
Modelling matrix time series via a tensor CP-decomposition
Dec 31, 2021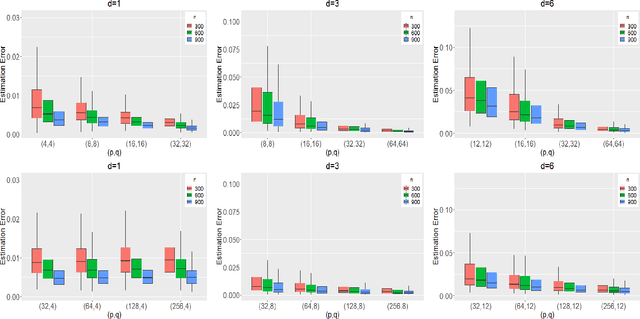
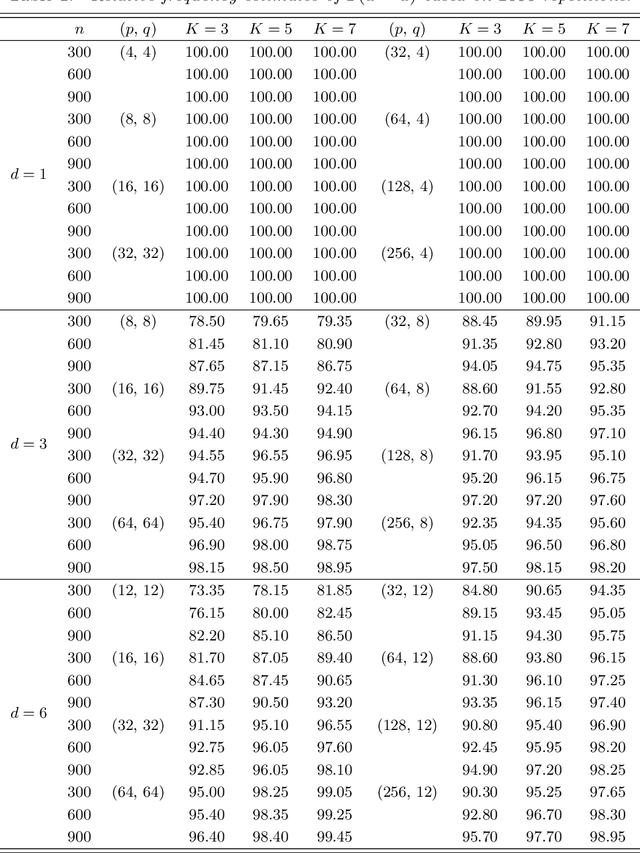
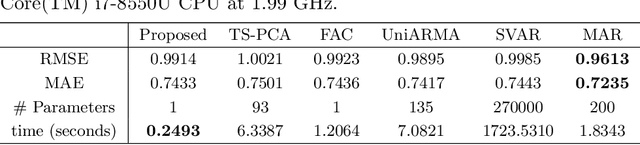
We propose to model matrix time series based on a tensor CP-decomposition. Instead of using an iterative algorithm which is the standard practice for estimating CP-decompositions, we propose a new and one-pass estimation procedure based on a generalized eigenanalysis constructed from the serial dependence structure of the underlying process. A key idea of the new procedure is to project a generalized eigenequation defined in terms of rank-reduced matrices to a lower-dimensional one with full-ranked matrices, to avoid the intricacy of the former of which the number of eigenvalues can be zero, finite and infinity. The asymptotic theory has been established under a general setting without the stationarity. It shows, for example, that all the component coefficient vectors in the CP-decomposition are estimated consistently with the different error rates, depending on the relative sizes between the dimensions of time series and the sample size. The proposed model and the estimation method are further illustrated with both simulated and real data; showing effective dimension-reduction in modelling and forecasting matrix time series.
Quality and Computation Time in Optimization Problems
Nov 20, 2021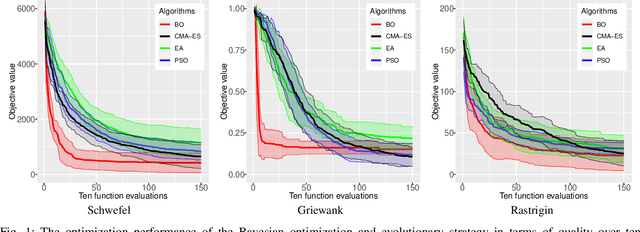
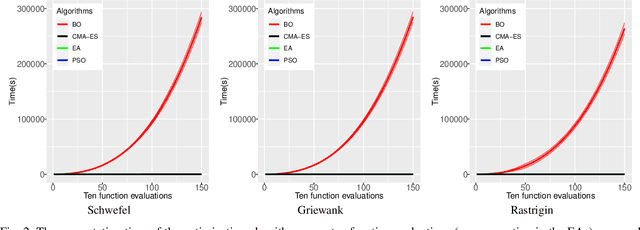
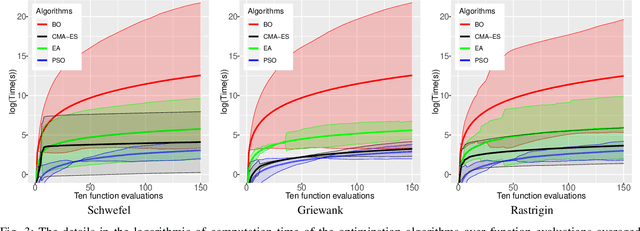

Optimization problems are crucial in artificial intelligence. Optimization algorithms are generally used to adjust the performance of artificial intelligence models to minimize the error of mapping inputs to outputs. Current evaluation methods on optimization algorithms generally consider the performance in terms of quality. However, not all optimization algorithms for all test cases are evaluated equal from quality, the computation time should be also considered for optimization tasks. In this paper, we investigate the quality and computation time of optimization algorithms in optimization problems, instead of the one-for-all evaluation of quality. We select the well-known optimization algorithms (Bayesian optimization and evolutionary algorithms) and evaluate them on the benchmark test functions in terms of quality and computation time. The results show that BO is suitable to be applied in the optimization tasks that are needed to obtain desired quality in the limited function evaluations, and the EAs are suitable to search the optimal of the tasks that are allowed to find the optimal solution with enough function evaluations. This paper provides the recommendation to select suitable optimization algorithms for optimization problems with different numbers of function evaluations, which contributes to the efficiency that obtains the desired quality with less computation time for optimization problems.
Spectrum of non-Hermitian deep-Hebbian neural networks
Aug 24, 2022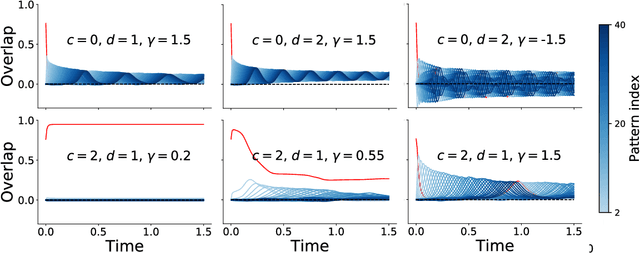
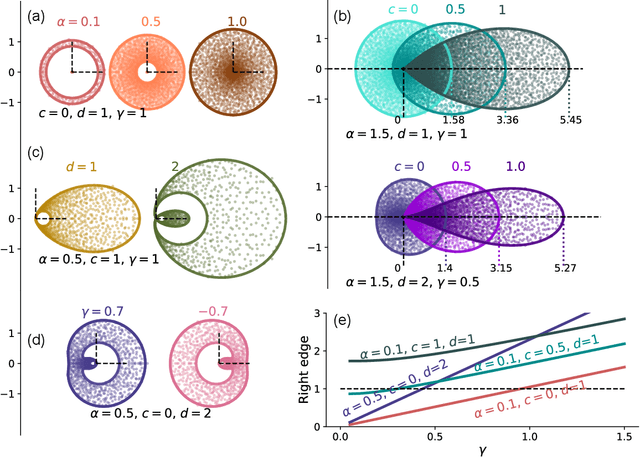
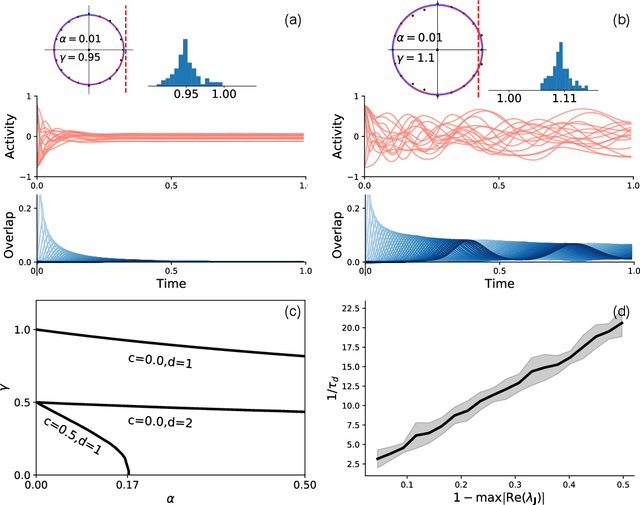
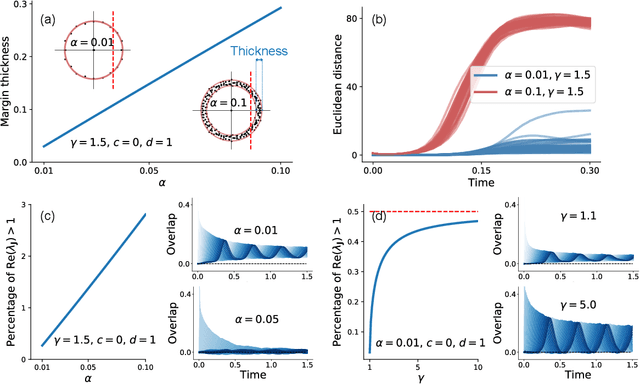
Neural networks with recurrent asymmetric couplings are important to understand how episodic memories are encoded in the brain. Here, we integrate the experimental observation of wide synaptic integration window into our model of sequence retrieval in the continuous time dynamics. The model with non-normal neuron-interactions is theoretically studied by deriving a random matrix theory of the Jacobian matrix in neural dynamics. The spectra bears several distinct features, such as breaking rotational symmetry about the origin, and the emergence of nested voids within the spectrum boundary. The spectral density is thus highly non-uniformly distributed in the complex plane. The random matrix theory also predicts a transition to chaos. In particular, the edge of chaos provides computational benefits for the sequential retrieval of memories. Our work provides a systematic study of time-lagged correlations with arbitrary time delays, and thus can inspire future studies of a broad class of memory models, and even big data analysis of biological time series.