 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model Criticism for Long-Form Text Generation
Oct 16, 2022
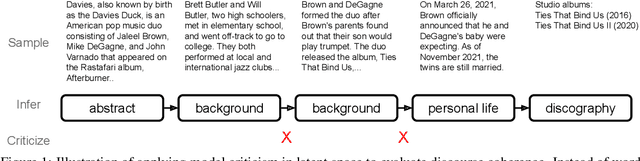
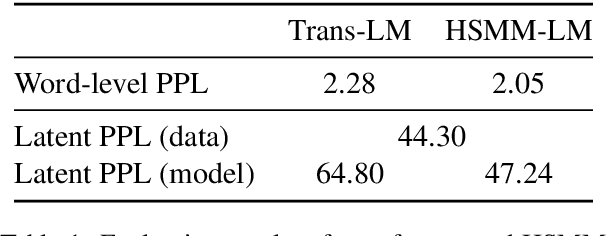
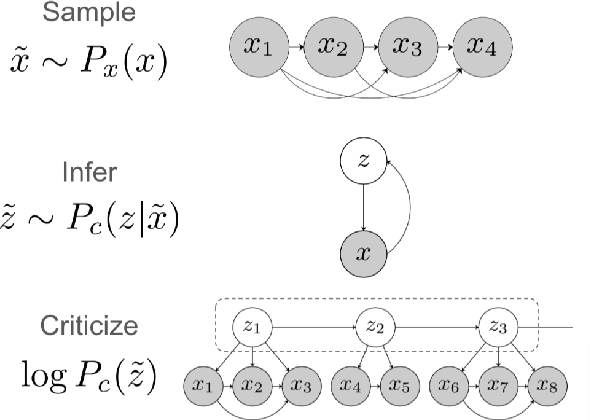
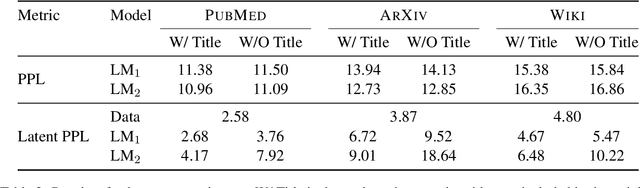
Language models have demonstrated the ability to generate highly fluent text; however, it remains unclear whether their output retains coherent high-level structure (e.g., story progression). Here, we propose to apply a statistical tool, model criticism in latent space, to evaluate the high-level structure of the generated text. Model criticism compares the distributions between real and generated data in a latent space obtained according to an assumptive generative process. Different generative processes identify specific failure modes of the underlying model. We perform experiments on three representative aspects of high-level discourse -- coherence, coreference, and topicality -- and find that transformer-based language models are able to capture topical structures but have a harder time maintaining structural coherence or modeling coreference.
Modeling and Mining Multi-Aspect Graphs With Scalable Streaming Tensor Decomposition
Oct 10, 2022Graphs emerge in almost every real-world application domain, ranging from online social networks all the way to health data and movie viewership patterns. Typically, such real-world graphs are big and dynamic, in the sense that they evolve over time. Furthermore, graphs usually contain multi-aspect information i.e. in a social network, we can have the "means of communication" between nodes, such as who messages whom, who calls whom, and who comments on whose timeline and so on. How can we model and mine useful patterns, such as communities of nodes in that graph, from such multi-aspect graphs? How can we identify dynamic patterns in those graphs, and how can we deal with streaming data, when the volume of data to be processed is very large? In order to answer those questions, in this thesis, we propose novel tensor-based methods for mining static and dynamic multi-aspect graphs. In general, a tensor is a higher-order generalization of a matrix that can represent high-dimensional multi-aspect data such as time-evolving networks, collaboration networks, and spatio-temporal data like Electroencephalography (EEG) brain measurements. The thesis is organized in two synergistic thrusts: First, we focus on static multi-aspect graphs, where the goal is to identify coherent communities and patterns between nodes by leveraging the tensor structure in the data. Second, as our graphs evolve dynamically, we focus on handling such streaming updates in the data without having to re-compute the decomposition, but incrementally update the existing results.
Energy-Efficient D2D-Aided Fog Computing under Probabilistic Time Constraints
Jan 07, 2022
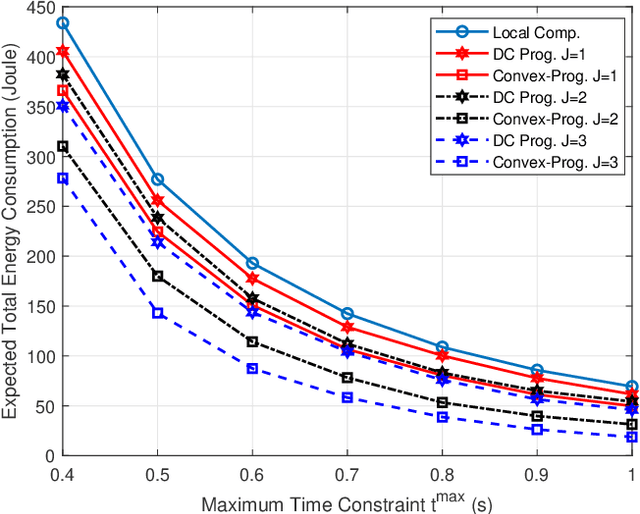
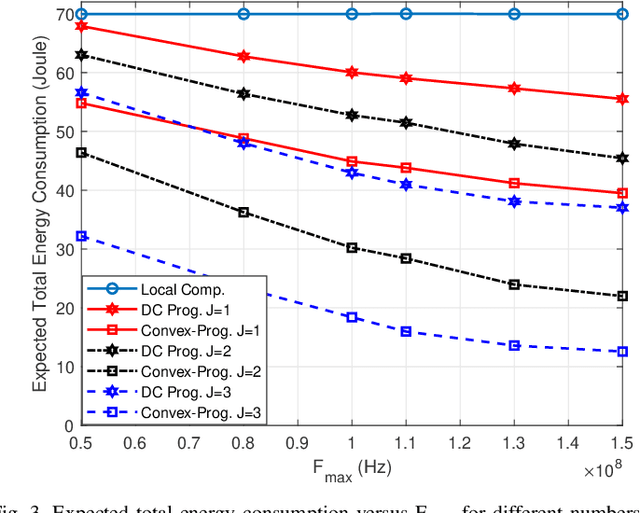
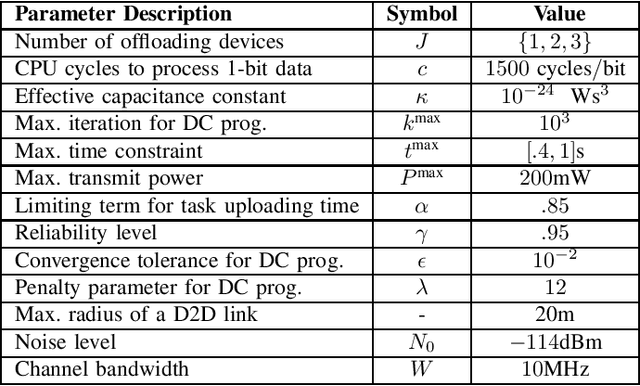
Device-to-device (D2D) communication is an enabling technology for fog computing by allowing the sharing of computation resources between mobile devices. However, temperature variations in the device CPUs affect the computation resources available for task offloading, which unpredictably alters the processing time and energy consumption. In this paper, we address the problem of resource allocation with respect to task partitioning, computation resources and transmit power in a D2D-aided fog computing scenario, aiming to minimize the expected total energy consumption under probabilistic constraints on the processing time. Since the formulated problem is non-convex, we propose two sub-optimal solution methods. The first method is based on difference of convex (DC) programming, which we combine with chance-constraint programming to handle the probabilistic time limitations. Considering that DC programming is dependent on a good initial point, we propose a second method that relies on only convex programming, which eliminates the dependence on user-defined initialization. Simulation results demonstrate that the latter method outperforms the former in terms of energy efficiency and run-time.
TLP: A Deep Learning-based Cost Model for Tensor Program Tuning
Nov 07, 2022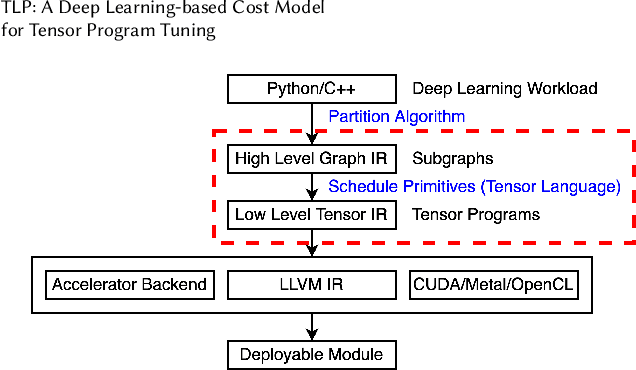


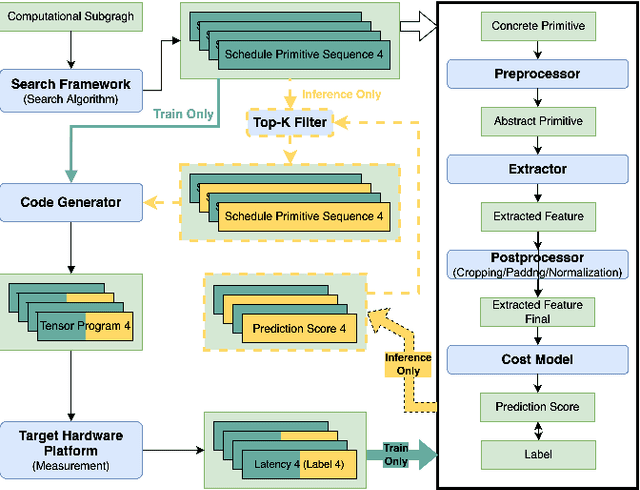
Tensor program tuning is a non-convex objective optimization problem, to which search-based approaches have proven to be effective. At the core of the search-based approaches lies the design of the cost model. Though deep learning-based cost models perform significantly better than other methods, they still fall short and suffer from the following problems. First, their feature extraction heavily relies on expert-level domain knowledge in hardware architectures. Even so, the extracted features are often unsatisfactory and require separate considerations for CPUs and GPUs. Second, a cost model trained on one hardware platform usually performs poorly on another, a problem we call cross-hardware unavailability. In order to address these problems, we propose TLP and MTLTLP. TLP is a deep learning-based cost model that facilitates tensor program tuning. Instead of extracting features from the tensor program itself, TLP extracts features from the schedule primitives. We treat schedule primitives as tensor languages. TLP is thus a Tensor Language Processing task. In this way, the task of predicting the tensor program latency through the cost model is transformed into a natural language processing (NLP) regression task. MTL-TLP combines Multi-Task Learning and TLP to cope with the cross-hardware unavailability problem. We incorporate these techniques into the Ansor framework and conduct detailed experiments. Results show that TLP can speed up the average search time by 9.1X and 3.0X on CPU and GPU workloads, respectively, compared to the state-of-the-art implementation. MTL-TLP can achieve a speed-up of 4.7X and 2.9X on CPU and GPU workloads, respectively, using only 7% of the target hardware data.
Probabilistic Dalek -- Emulator framework with probabilistic prediction for supernova tomography
Sep 20, 2022
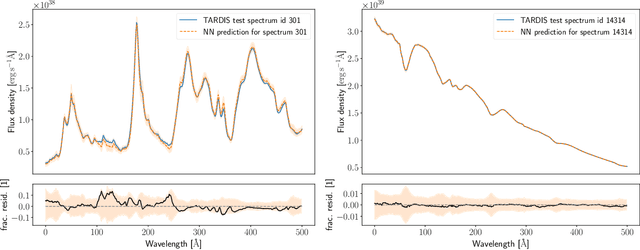
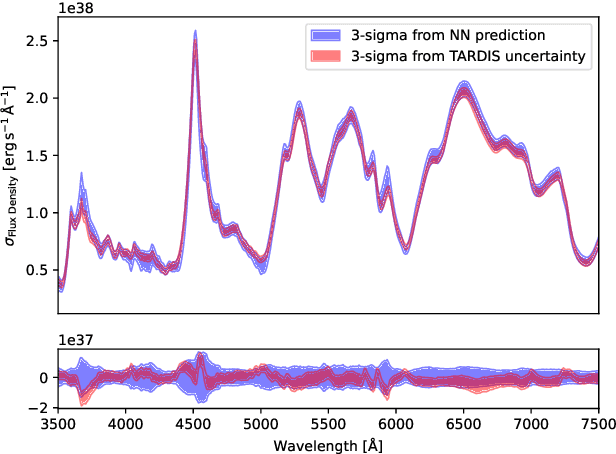
Supernova spectral time series can be used to reconstruct a spatially resolved explosion model known as supernova tomography. In addition to an observed spectral time series, a supernova tomography requires a radiative transfer model to perform the inverse problem with uncertainty quantification for a reconstruction. The smallest parametrizations of supernova tomography models are roughly a dozen parameters with a realistic one requiring more than 100. Realistic radiative transfer models require tens of CPU minutes for a single evaluation making the problem computationally intractable with traditional means requiring millions of MCMC samples for such a problem. A new method for accelerating simulations known as surrogate models or emulators using machine learning techniques offers a solution for such problems and a way to understand progenitors/explosions from spectral time series. There exist emulators for the TARDIS supernova radiative transfer code but they only perform well on simplistic low-dimensional models (roughly a dozen parameters) with a small number of applications for knowledge gain in the supernova field. In this work, we present a new emulator for the radiative transfer code TARDIS that not only outperforms existing emulators but also provides uncertainties in its prediction. It offers the foundation for a future active-learning-based machinery that will be able to emulate very high dimensional spaces of hundreds of parameters crucial for unraveling urgent questions in supernovae and related fields.
Progressive Denoising Model for Fine-Grained Text-to-Image Generation
Oct 05, 2022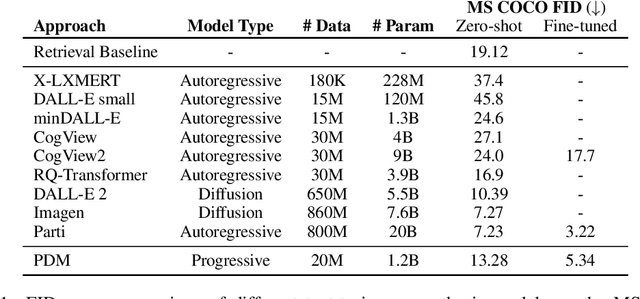

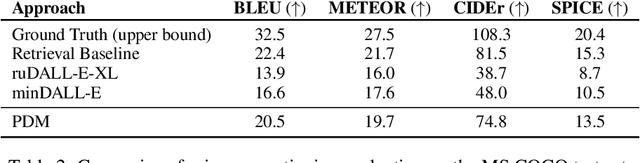
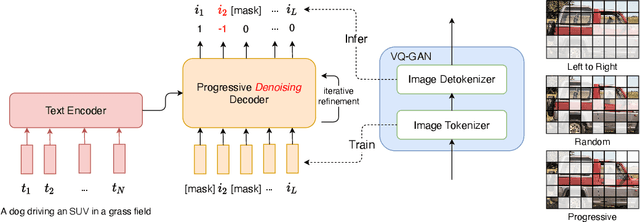
Recently, vector quantized autoregressive (VQ-AR) models have shown remarkable results in text-to-image synthesis by equally predicting discrete image tokens from the top left to bottom right in the latent space. Although the simple generative process surprisingly works well, is this the best way to generate the image? For instance, human creation is more inclined to the outline-to-fine of an image, while VQ-AR models themselves do not consider any relative importance of each component. In this paper, we present a progressive denoising model for high-fidelity text-to-image image generation. The proposed method takes effect by creating new image tokens from coarse to fine based on the existing context in a parallel manner and this procedure is recursively applied until an image sequence is completed. The resulting coarse-to-fine hierarchy makes the image generation process intuitive and interpretable. Extensive experiments demonstrate that the progressive model produces significantly better results when compared with the previous VQ-AR method in FID score across a wide variety of categories and aspects. Moreover, the text-to-image generation time of traditional AR increases linearly with the output image resolution and hence is quite time-consuming even for normal-size images. In contrast, our approach allows achieving a better trade-off between generation quality and speed.
Online Convex Optimization with Long Term Constraints for Predictable Sequences
Oct 30, 2022In this paper, we investigate the framework of Online Convex Optimization (OCO) for online learning. OCO offers a very powerful online learning framework for many applications. In this context, we study a specific framework of OCO called {\it OCO with long term constraints}. Long term constraints are introduced typically as an alternative to reduce the complexity of the projection at every update step in online optimization. While many algorithmic advances have been made towards online optimization with long term constraints, these algorithms typically assume that the sequence of cost functions over a certain $T$ finite steps that determine the cost to the online learner are adversarially generated. In many circumstances, the sequence of cost functions may not be unrelated, and thus predictable from those observed till a point of time. In this paper, we study the setting where the sequences are predictable. We present a novel online optimization algorithm for online optimization with long term constraints that can leverage such predictability. We show that, with a predictor that can supply the gradient information of the next function in the sequence, our algorithm can achieve an overall regret and constraint violation rate that is strictly less than the rate that is achievable without prediction.
Receiver Bandwidth Extension Beyond Nyquist Using Channel Bonding
Oct 14, 2022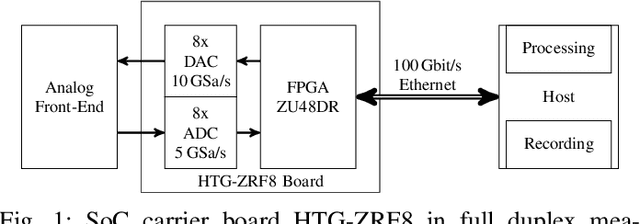
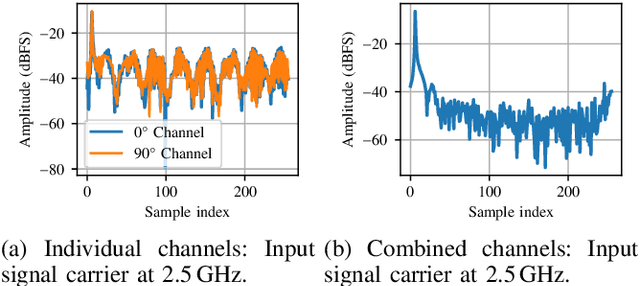
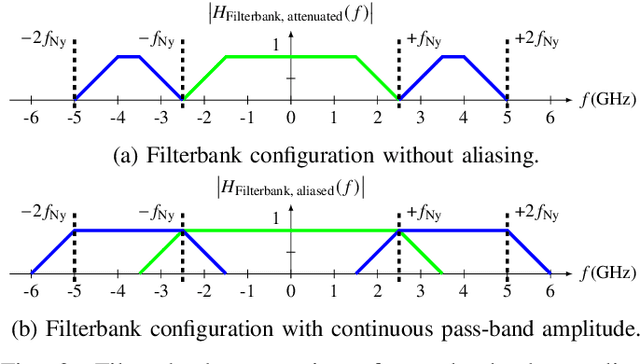
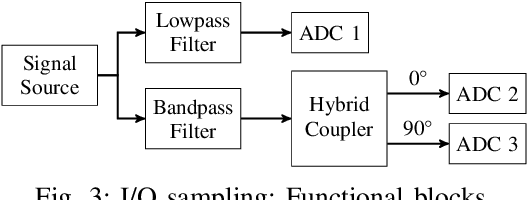
Current and upcoming communication and sensing technologies require ever larger bandwidths. Channel bonding can be utilized to extend a receiver's instantaneous bandwidth beyond a single converter's Nyquist limit. Two potential joint front-end and converter design approaches are theoretically introduced, realized and evaluated in this paper. The Xilinx RFSoC platform with its 5 GSa/s analog to digital converters (ADCs) is used to implement both a hybrid coupler based in-phase/quadrature (I/Q) sampling and a time-interleaved sampling approach along with channel bonding. Both realizations are demonstrated to be able to reconstruct instantaneous bandwidths of 5 GHz with up to 49 dB image rejection ratio (IRR) typically within 4 to 8 dB the front-ends' theoretical limits.
SkIn: Skimming-Intensive Long-Text Classification Based on BERT and Application to Medical Corpus
Sep 13, 2022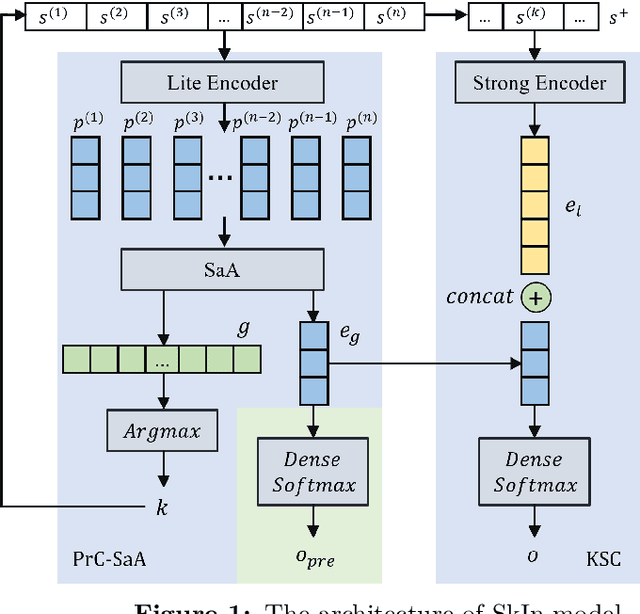
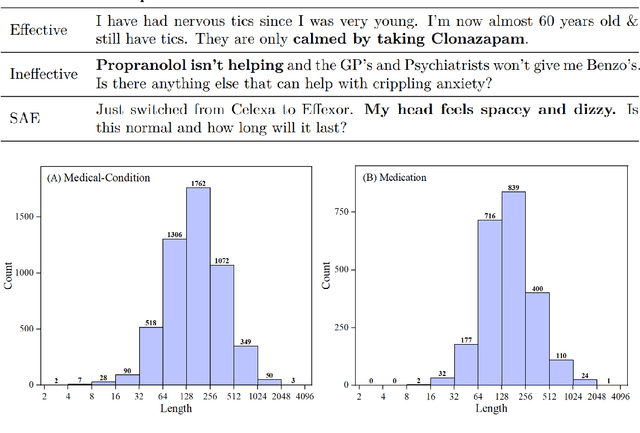
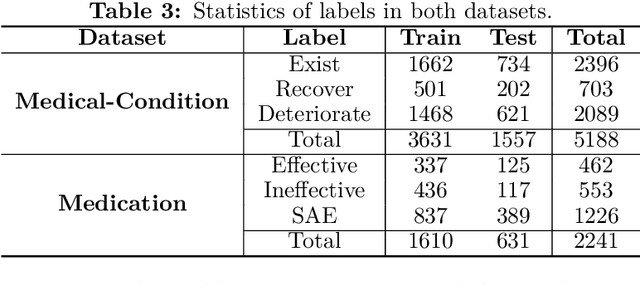
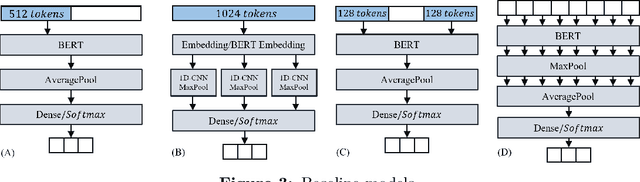
BERT is a widely used pre-trained model in natural language processing. However, because its time and space requirements increase with a quadratic level of the text length, the BERT model is difficult to use directly on the long-text corpus. The collected text data is usually quite long in some fields, such as health care. Therefore, to apply the pre-trained language knowledge of BERT to long text, in this paper, imitating the skimming-intensive reading method used by humans when reading a long paragraph, the Skimming-Intensive Model (SkIn) is proposed. It can dynamically select the critical information in the text so that the length of the input into the BERT-Base model is significantly reduced, which can effectively save the cost of the classification algorithm. Experiments show that the SkIn method has achieved better results than the baselines on long-text classification datasets in the medical field, while its time and space requirements increase linearly with the text length, alleviating the time and space overflow problem of BERT on long-text data.
Pruning's Effect on Generalization Through the Lens of Training and Regularization
Oct 25, 2022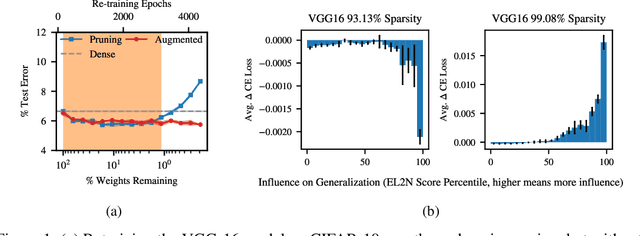
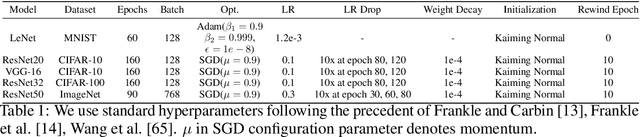
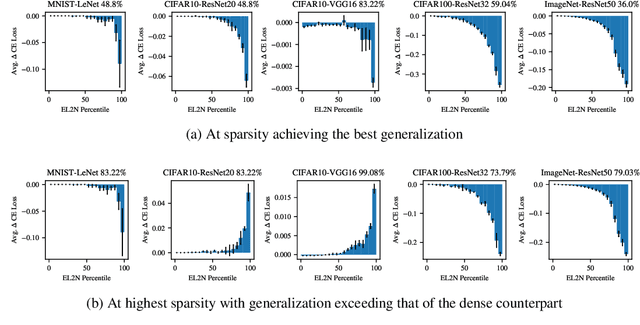
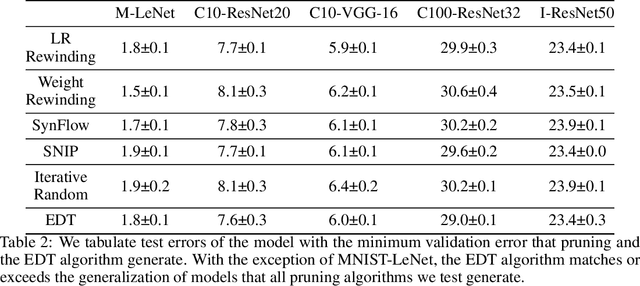
Practitioners frequently observe that pruning improves model generalization. A long-standing hypothesis based on bias-variance trade-off attributes this generalization improvement to model size reduction. However, recent studies on over-parameterization characterize a new model size regime, in which larger models achieve better generalization. Pruning models in this over-parameterized regime leads to a contradiction -- while theory predicts that reducing model size harms generalization, pruning to a range of sparsities nonetheless improves it. Motivated by this contradiction, we re-examine pruning's effect on generalization empirically. We show that size reduction cannot fully account for the generalization-improving effect of standard pruning algorithms. Instead, we find that pruning leads to better training at specific sparsities, improving the training loss over the dense model. We find that pruning also leads to additional regularization at other sparsities, reducing the accuracy degradation due to noisy examples over the dense model. Pruning extends model training time and reduces model size. These two factors improve training and add regularization respectively. We empirically demonstrate that both factors are essential to fully explaining pruning's impact on generalization.
* 49 pages, 20 figures