 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
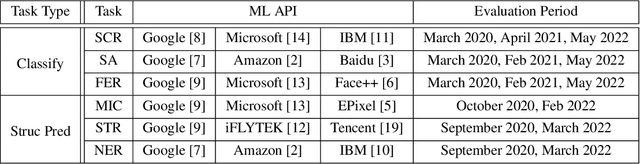
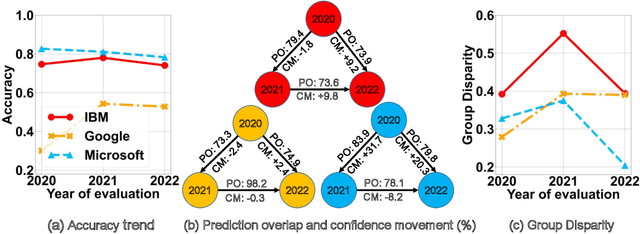
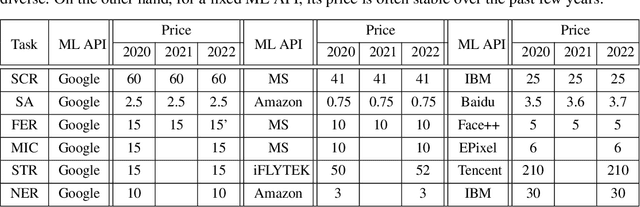
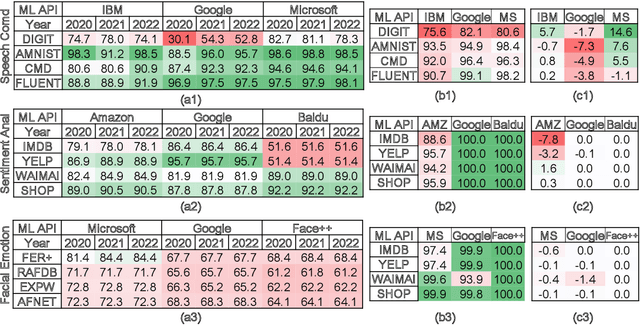
HAPI: A Large-scale Longitudinal Dataset of Commercial ML API Predictions
Sep 18, 2022
Commercial ML APIs offered by providers such as Google, Amazon and Microsoft have dramatically simplified ML adoption in many applications. Numerous companies and academics pay to use ML APIs for tasks such as object detection, OCR and sentiment analysis. Different ML APIs tackling the same task can have very heterogeneous performance. Moreover, the ML models underlying the APIs also evolve over time. As ML APIs rapidly become a valuable marketplace and a widespread way to consume machine learning, it is critical to systematically study and compare different APIs with each other and to characterize how APIs change over time. However, this topic is currently underexplored due to the lack of data. In this paper, we present HAPI (History of APIs), a longitudinal dataset of 1,761,417 instances of commercial ML API applications (involving APIs from Amazon, Google, IBM, Microsoft and other providers) across diverse tasks including image tagging, speech recognition and text mining from 2020 to 2022. Each instance consists of a query input for an API (e.g., an image or text) along with the API's output prediction/annotation and confidence scores. HAPI is the first large-scale dataset of ML API usages and is a unique resource for studying ML-as-a-service (MLaaS). As examples of the types of analyses that HAPI enables, we show that ML APIs' performance change substantially over time--several APIs' accuracies dropped on specific benchmark datasets. Even when the API's aggregate performance stays steady, its error modes can shift across different subtypes of data between 2020 and 2022. Such changes can substantially impact the entire analytics pipelines that use some ML API as a component. We further use HAPI to study commercial APIs' performance disparities across demographic subgroups over time. HAPI can stimulate more research in the growing field of MLaaS.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022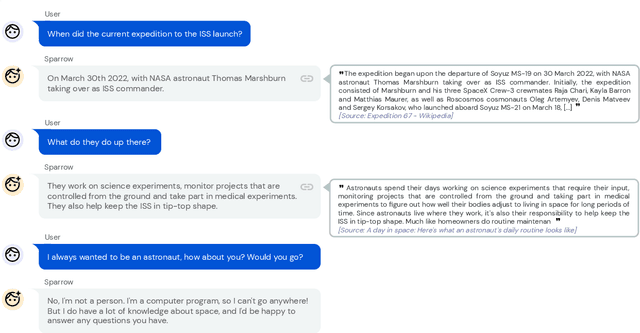

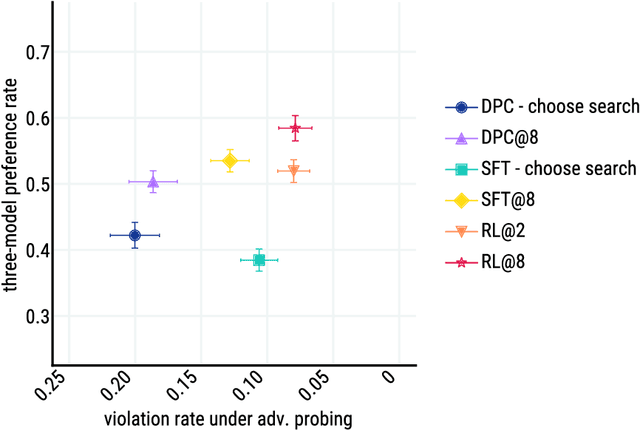
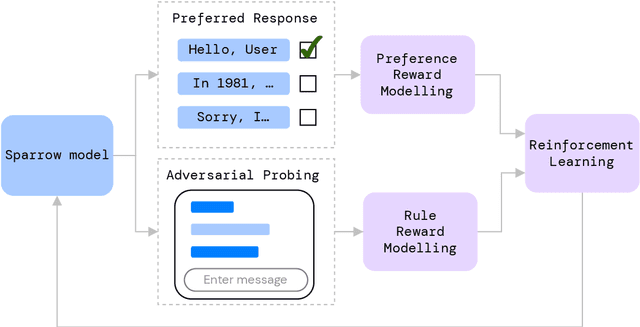
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Deep Generative model with Hierarchical Latent Factors for Time Series Anomaly Detection
Feb 15, 2022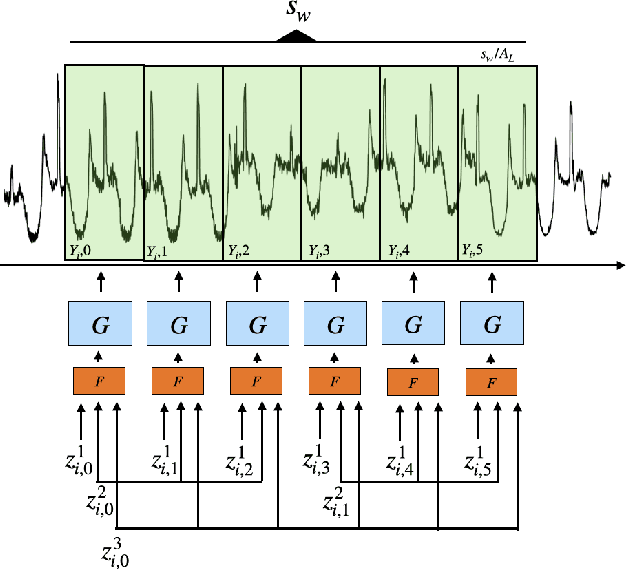
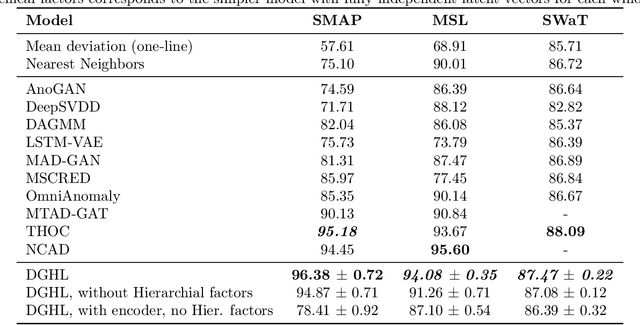
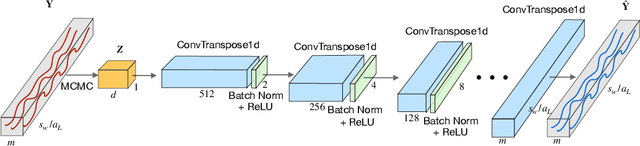
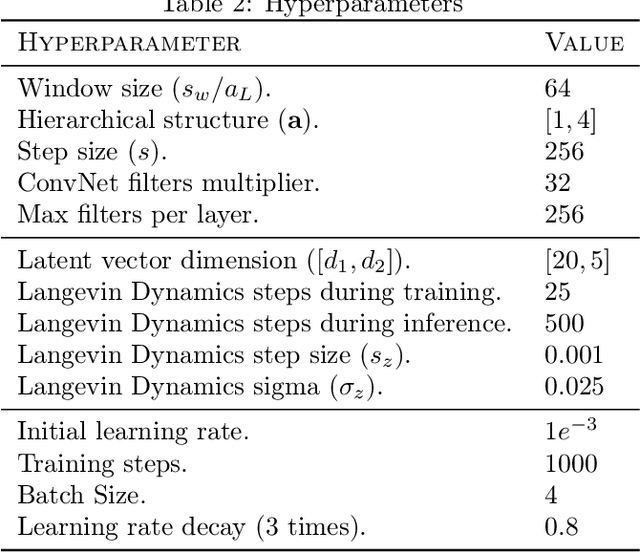
Multivariate time series anomaly detection has become an active area of research in recent years, with Deep Learning models outperforming previous approaches on benchmark datasets. Among reconstruction-based models, most previous work has focused on Variational Autoencoders and Generative Adversarial Networks. This work presents DGHL, a new family of generative models for time series anomaly detection, trained by maximizing the observed likelihood by posterior sampling and alternating back-propagation. A top-down Convolution Network maps a novel hierarchical latent space to time series windows, exploiting temporal dynamics to encode information efficiently. Despite relying on posterior sampling, it is computationally more efficient than current approaches, with up to 10x shorter training times than RNN based models. Our method outperformed current state-of-the-art models on four popular benchmark datasets. Finally, DGHL is robust to variable features between entities and accurate even with large proportions of missing values, settings with increasing relevance with the advent of IoT. We demonstrate the superior robustness of DGHL with novel occlusion experiments in this literature. Our code is available at https://github.com/cchallu/dghl.
iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
Mar 04, 2022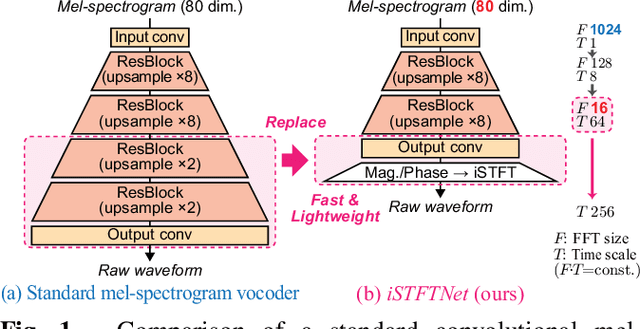
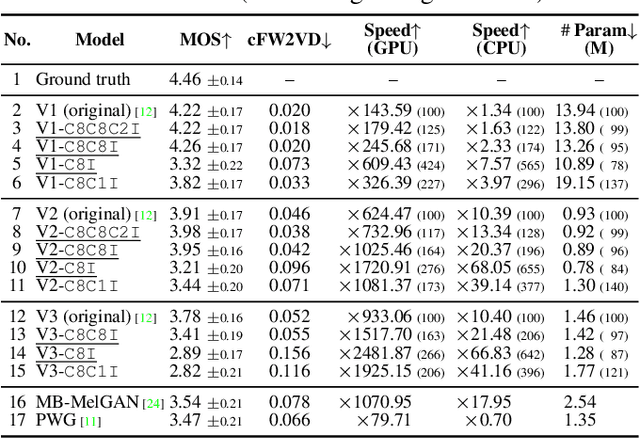
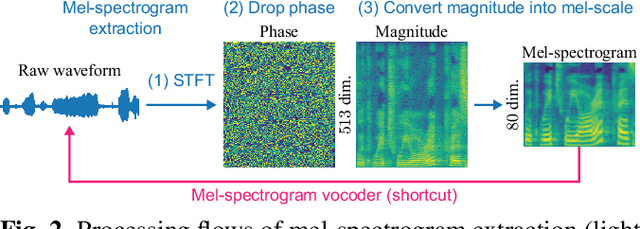

In recent text-to-speech synthesis and voice conversion systems, a mel-spectrogram is commonly applied as an intermediate representation, and the necessity for a mel-spectrogram vocoder is increasing. A mel-spectrogram vocoder must solve three inverse problems: recovery of the original-scale magnitude spectrogram, phase reconstruction, and frequency-to-time conversion. A typical convolutional mel-spectrogram vocoder solves these problems jointly and implicitly using a convolutional neural network, including temporal upsampling layers, when directly calculating a raw waveform. Such an approach allows skipping redundant processes during waveform synthesis (e.g., the direct reconstruction of high-dimensional original-scale spectrograms). By contrast, the approach solves all problems in a black box and cannot effectively employ the time-frequency structures existing in a mel-spectrogram. We thus propose iSTFTNet, which replaces some output-side layers of the mel-spectrogram vocoder with the inverse short-time Fourier transform (iSTFT) after sufficiently reducing the frequency dimension using upsampling layers, reducing the computational cost from black-box modeling and avoiding redundant estimations of high-dimensional spectrograms. During our experiments, we applied our ideas to three HiFi-GAN variants and made the models faster and more lightweight with a reasonable speech quality. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/istftnet/.
Domain Adaptation in 3D Object Detection with Gradual Batch Alternation Training
Oct 18, 2022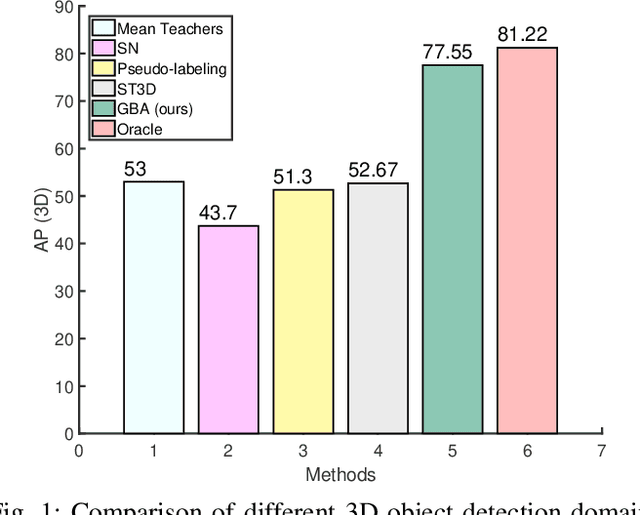
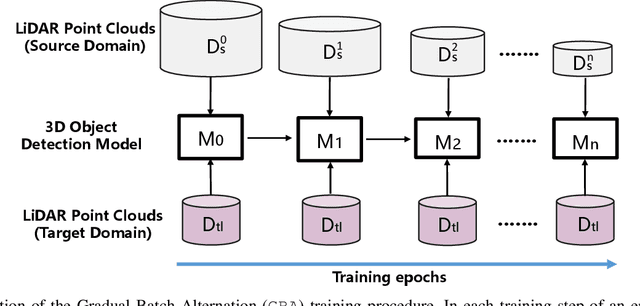
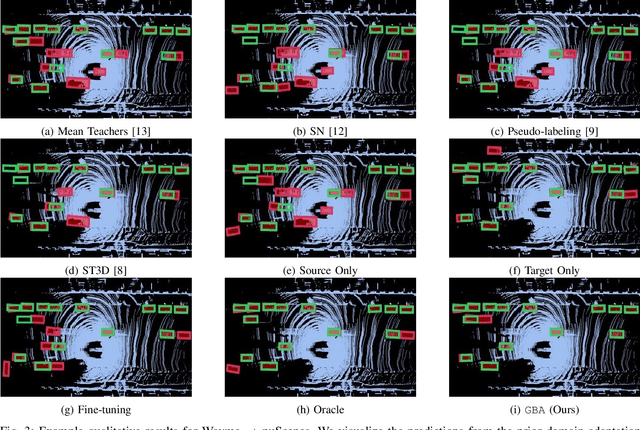
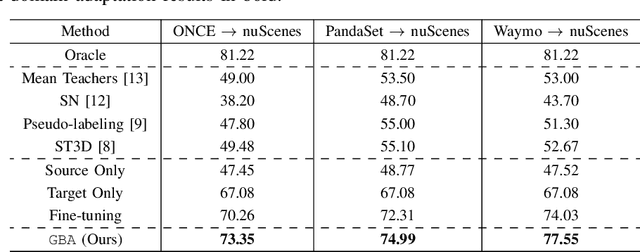
We consider the problem of domain adaptation in LiDAR-based 3D object detection. Towards this, we propose a simple yet effective training strategy called Gradual Batch Alternation that can adapt from a large labeled source domain to an insufficiently labeled target domain. The idea is to initiate the training with the batch of samples from the source and target domain data in an alternate fashion, but then gradually reduce the amount of the source domain data over time as the training progresses. This way the model slowly shifts towards the target domain and eventually better adapt to it. The domain adaptation experiments for 3D object detection on four benchmark autonomous driving datasets, namely ONCE, PandaSet, Waymo, and nuScenes, demonstrate significant performance gains over prior arts and strong baselines.
EISeg: An Efficient Interactive Segmentation Tool based on PaddlePaddle
Oct 18, 2022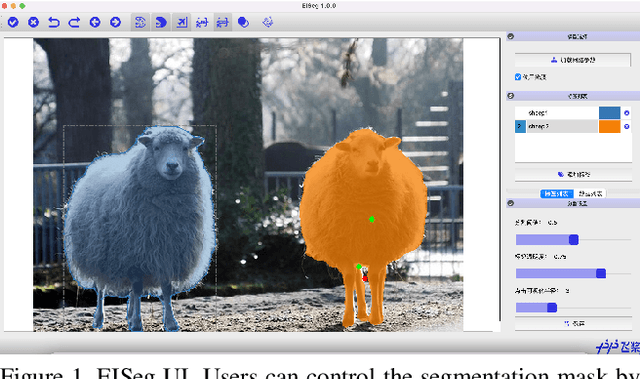

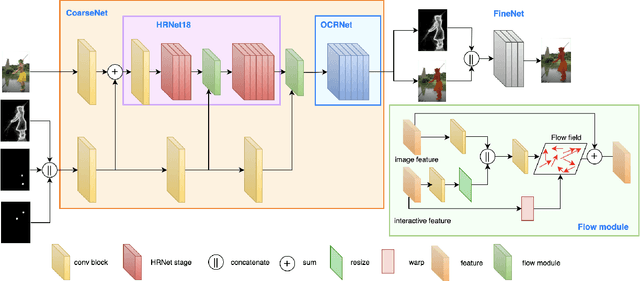
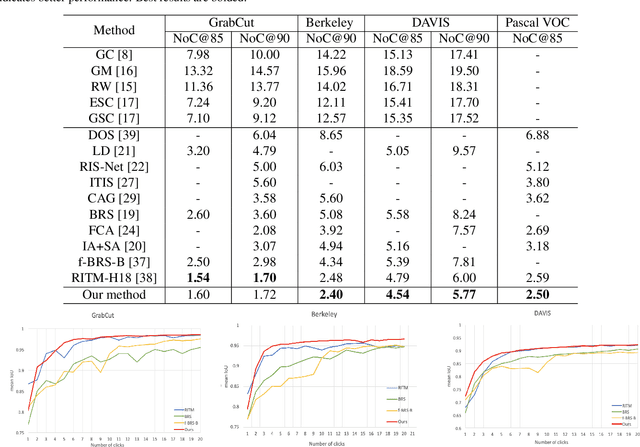
In recent years, the rapid development of deep learning has brought great advancements to image and video segmentation methods based on neural networks. However, to unleash the full potential of such models, large numbers of high-quality annotated images are necessary for model training. Currently, many widely used open-source image segmentation software relies heavily on manual annotation which is tedious and time-consuming. In this work, we introduce EISeg, an Efficient Interactive SEGmentation annotation tool that can drastically improve image segmentation annotation efficiency, generating highly accurate segmentation masks with only a few clicks. We also provide various domain-specific models for remote sensing, medical imaging, industrial quality inspections, human segmentation, and temporal aware models for video segmentation. The source code for our algorithm and user interface are available at: https://github.com/PaddlePaddle/PaddleSeg.
Just Another Method to Compute MTTF from Continuous Time Markov Chain
Feb 03, 2022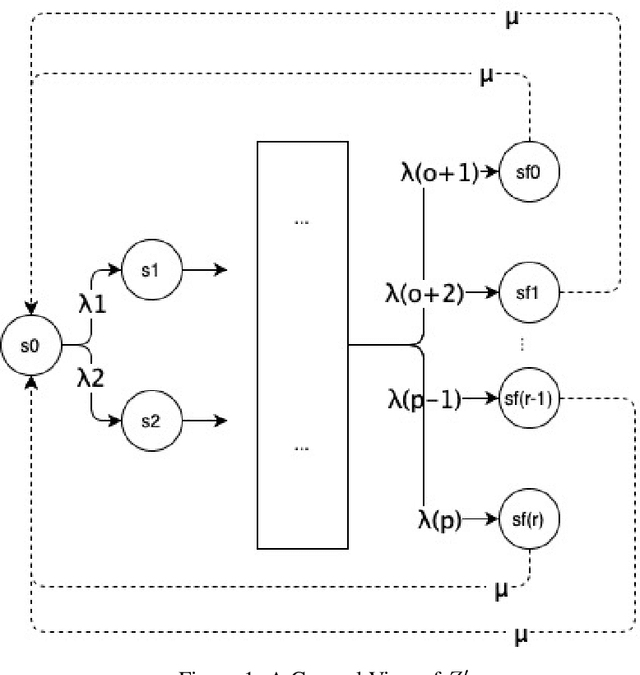
The Meantime to Failure is a statistic used to determine how much time a system spends to enter one of its absorption states. This statistic can be used in most areas of knowledge. In engineering, for example, can be used as a measure of equipment reliability, and in business, as a measure of processes performance. This work presents a method to obtain the Meantime to Failure from a Continuous Time Markov Chain models. The method is intuitive and is simpler to be implemented, since, it consists of solving a system of linear equations.
Neural inhibition during speech planning contributes to contrastive hyperarticulation
Sep 25, 2022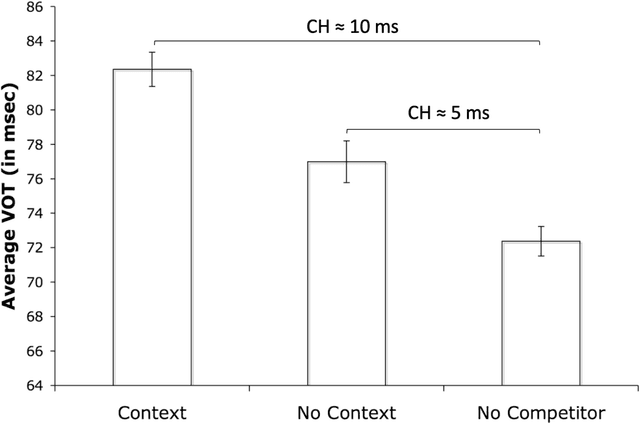
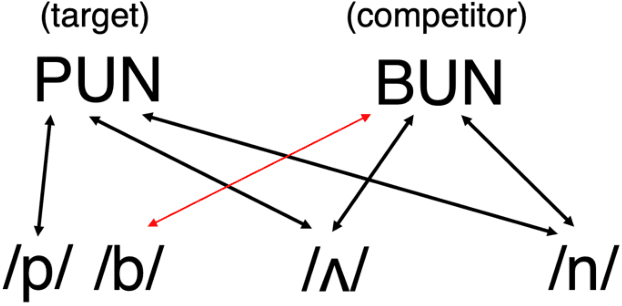
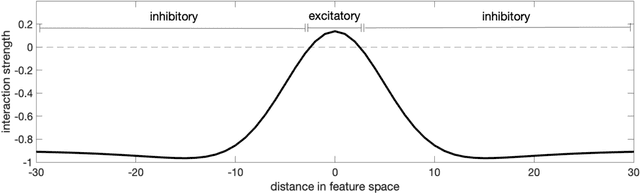
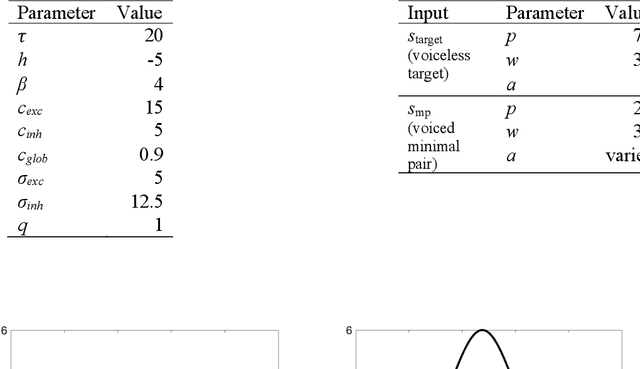
Previous work has demonstrated that words are hyperarticulated on dimensions of speech that differentiate them from a minimal pair competitor. This phenomenon has been termed contrastive hyperarticulation (CH). We present a dynamic neural field (DNF) model of voice onset time (VOT) planning that derives CH from an inhibitory influence of the minimal pair competitor during planning. We test some predictions of the model with a novel experiment investigating CH of voiceless stop consonant VOT in pseudowords. The results demonstrate a CH effect in pseudowords, consistent with a basis for the effect in the real-time planning and production of speech. The scope and magnitude of CH in pseudowords was reduced compared to CH in real words, consistent with a role for interactive activation between lexical and phonological levels of planning. We discuss the potential of our model to unify an apparently disparate set of phenomena, from CH to phonological neighborhood effects to phonetic trace effects in speech errors.
HTMOT : Hierarchical Topic Modelling Over Time
Nov 22, 2021
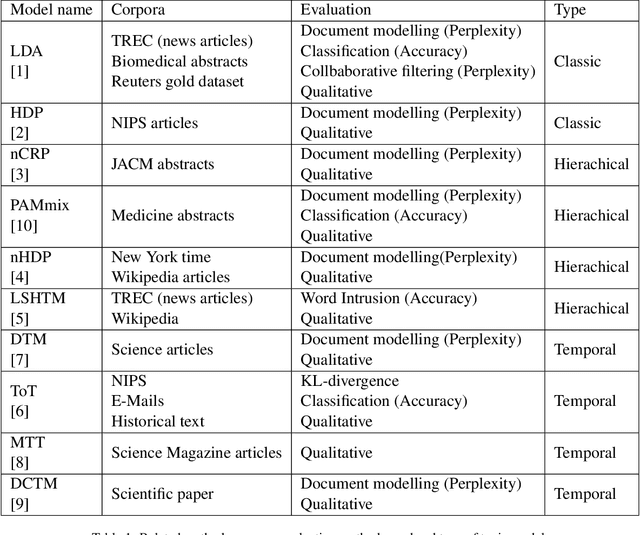
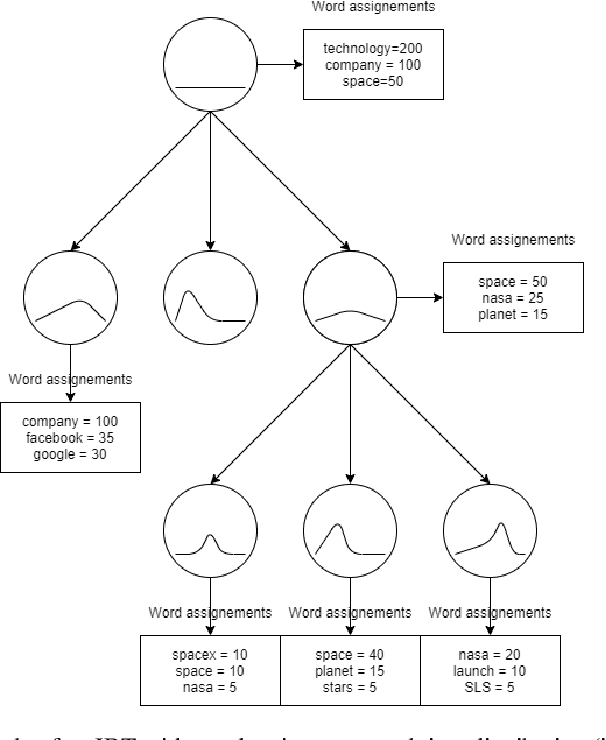
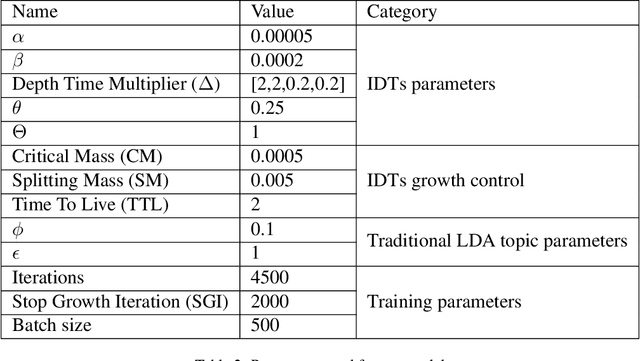
Over the years, topic models have provided an efficient way of extracting insights from text. However, while many models have been proposed, none are able to model topic temporality and hierarchy jointly. Modelling time provide more precise topics by separating lexically close but temporally distinct topics while modelling hierarchy provides a more detailed view of the content of a document corpus. In this study, we therefore propose a novel method, HTMOT, to perform Hierarchical Topic Modelling Over Time. We train HTMOT using a new implementation of Gibbs sampling, which is more efficient. Specifically, we show that only applying time modelling to deep sub-topics provides a way to extract specific stories or events while high level topics extract larger themes in the corpus. Our results show that our training procedure is fast and can extract accurate high-level topics and temporally precise sub-topics. We measured our model's performance using the Word Intrusion task and outlined some limitations of this evaluation method, especially for hierarchical models. As a case study, we focused on the various developments in the space industry in 2020.
QuerySnout: Automating the Discovery of Attribute Inference Attacks against Query-Based Systems
Nov 09, 2022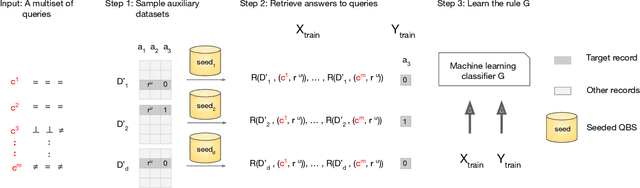
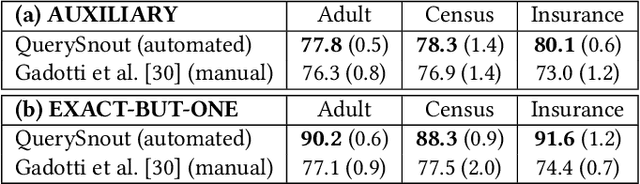
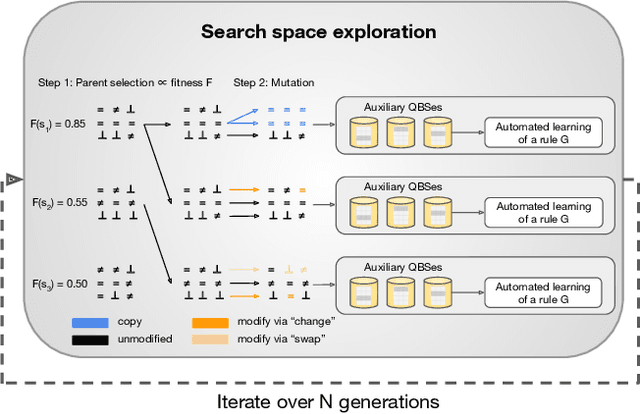
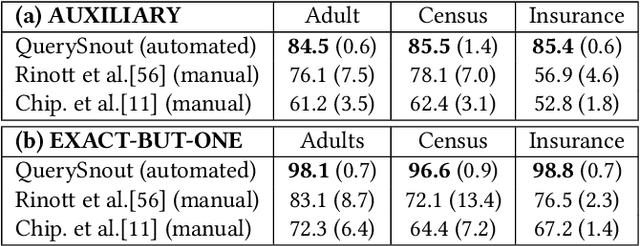
Although query-based systems (QBS) have become one of the main solutions to share data anonymously, building QBSes that robustly protect the privacy of individuals contributing to the dataset is a hard problem. Theoretical solutions relying on differential privacy guarantees are difficult to implement correctly with reasonable accuracy, while ad-hoc solutions might contain unknown vulnerabilities. Evaluating the privacy provided by QBSes must thus be done by evaluating the accuracy of a wide range of privacy attacks. However, existing attacks require time and expertise to develop, need to be manually tailored to the specific systems attacked, and are limited in scope. In this paper, we develop QuerySnout (QS), the first method to automatically discover vulnerabilities in QBSes. QS takes as input a target record and the QBS as a black box, analyzes its behavior on one or more datasets, and outputs a multiset of queries together with a rule to combine answers to them in order to reveal the sensitive attribute of the target record. QS uses evolutionary search techniques based on a novel mutation operator to find a multiset of queries susceptible to lead to an attack, and a machine learning classifier to infer the sensitive attribute from answers to the queries selected. We showcase the versatility of QS by applying it to two attack scenarios, three real-world datasets, and a variety of protection mechanisms. We show the attacks found by QS to consistently equate or outperform, sometimes by a large margin, the best attacks from the literature. We finally show how QS can be extended to QBSes that require a budget, and apply QS to a simple QBS based on the Laplace mechanism. Taken together, our results show how powerful and accurate attacks against QBSes can already be found by an automated system, allowing for highly complex QBSes to be automatically tested "at the pressing of a button".