 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HTMOT : Hierarchical Topic Modelling Over Time
Nov 22, 2021
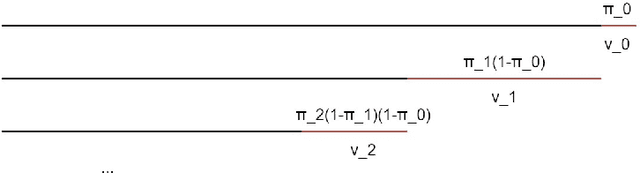
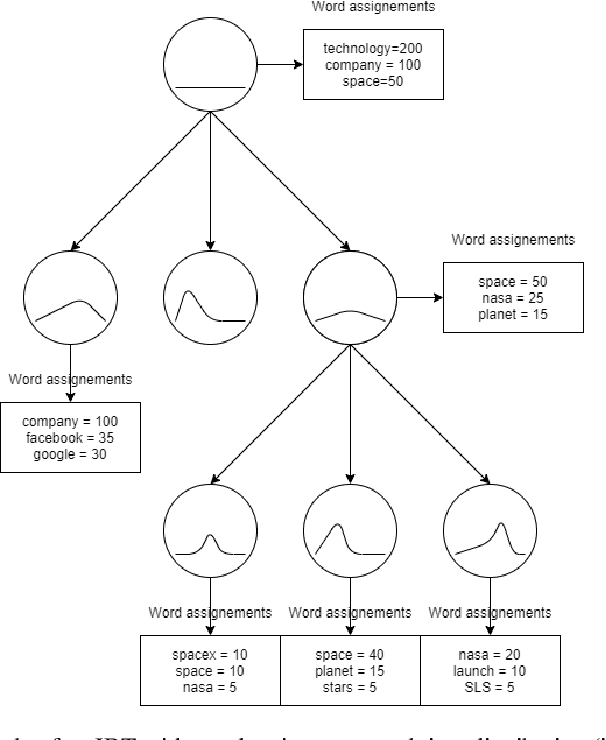
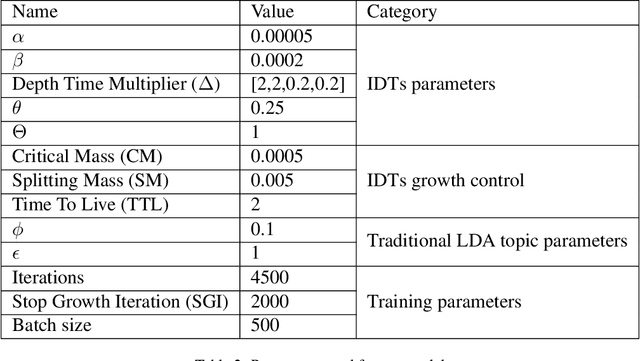
Over the years, topic models have provided an efficient way of extracting insights from text. However, while many models have been proposed, none are able to model topic temporality and hierarchy jointly. Modelling time provide more precise topics by separating lexically close but temporally distinct topics while modelling hierarchy provides a more detailed view of the content of a document corpus. In this study, we therefore propose a novel method, HTMOT, to perform Hierarchical Topic Modelling Over Time. We train HTMOT using a new implementation of Gibbs sampling, which is more efficient. Specifically, we show that only applying time modelling to deep sub-topics provides a way to extract specific stories or events while high level topics extract larger themes in the corpus. Our results show that our training procedure is fast and can extract accurate high-level topics and temporally precise sub-topics. We measured our model's performance using the Word Intrusion task and outlined some limitations of this evaluation method, especially for hierarchical models. As a case study, we focused on the various developments in the space industry in 2020.
Learning body models: from humans to humanoids
Nov 06, 2022
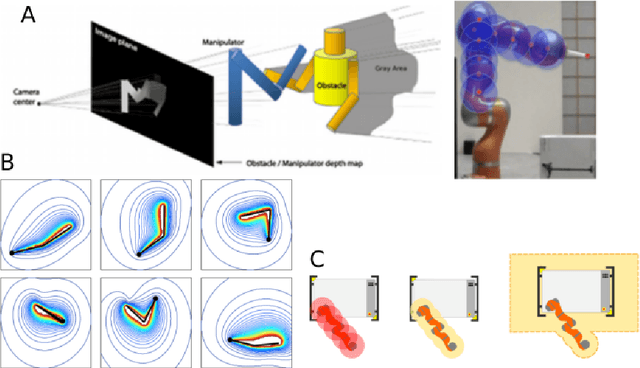
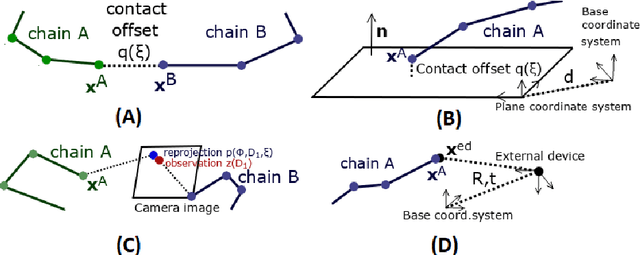
Humans and animals excel in combining information from multiple sensory modalities, controlling their complex bodies, adapting to growth, failures, or using tools. These capabilities are also highly desirable in robots. They are displayed by machines to some extent. Yet, the artificial creatures are lagging behind. The key foundation is an internal representation of the body that the agent - human, animal, or robot - has developed. The mechanisms of operation of body models in the brain are largely unknown and even less is known about how they are constructed from experience after birth. In collaboration with developmental psychologists, we conducted targeted experiments to understand how infants acquire first "sensorimotor body knowledge". These experiments inform our work in which we construct embodied computational models on humanoid robots that address the mechanisms behind learning, adaptation, and operation of multimodal body representations. At the same time, we assess which of the features of the "body in the brain" should be transferred to robots to give rise to more adaptive and resilient, self-calibrating machines. We extend traditional robot kinematic calibration focusing on self-contained approaches where no external metrology is needed: self-contact and self-observation. Problem formulation allowing to combine several ways of closing the kinematic chain simultaneously is presented, along with a calibration toolbox and experimental validation on several robot platforms. Finally, next to models of the body itself, we study peripersonal space - the space immediately surrounding the body. Again, embodied computational models are developed and subsequently, the possibility of turning these biologically inspired representations into safe human-robot collaboration is studied.
Wheel-SLAM: Simultaneous Localization and Terrain Mapping Using One Wheel-mounted IMU
Nov 06, 2022
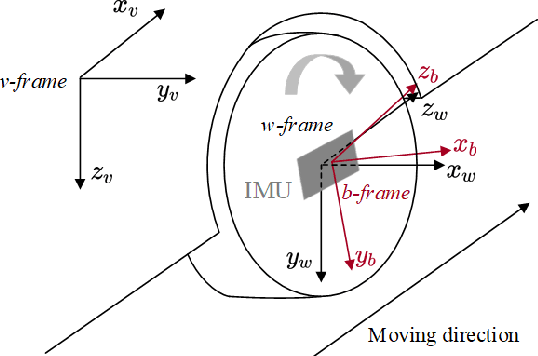
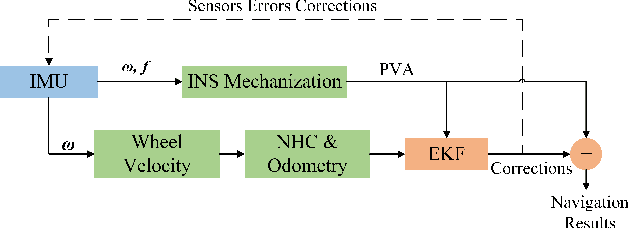

A reliable pose estimator robust to environmental disturbances is desirable for mobile robots. To this end, inertial measurement units (IMUs) play an important role because they can perceive the full motion state of the vehicle independently. However, it suffers from accumulative error due to inherent noise and bias instability, especially for low-cost sensors. In our previous studies on Wheel-INS \cite{niu2021, wu2021}, we proposed to limit the error drift of the pure inertial navigation system (INS) by mounting an IMU to the wheel of the robot to take advantage of rotation modulation. However, it still drifted over a long period of time due to the lack of external correction signals. In this letter, we propose to exploit the environmental perception ability of Wheel-INS to achieve simultaneous localization and mapping (SLAM) with only one IMU. To be specific, we use the road bank angles (mirrored by the robot roll angles estimated by Wheel-INS) as terrain features to enable the loop closure with a Rao-Blackwellized particle filter. The road bank angle is sampled and stored according to the robot position in the grid maps maintained by the particles. The weights of the particles are updated according to the difference between the currently estimated roll sequence and the terrain map. Field experiments suggest the feasibility of the idea to perform SLAM in Wheel-INS using the robot roll angle estimates. In addition, the positioning accuracy is improved significantly (more than 30\%) over Wheel-INS. Source code of our implementation is publicly available (https://github.com/i2Nav-WHU/Wheel-SLAM).
Just Another Method to Compute MTTF from Continuous Time Markov Chain
Feb 03, 2022
The Meantime to Failure is a statistic used to determine how much time a system spends to enter one of its absorption states. This statistic can be used in most areas of knowledge. In engineering, for example, can be used as a measure of equipment reliability, and in business, as a measure of processes performance. This work presents a method to obtain the Meantime to Failure from a Continuous Time Markov Chain models. The method is intuitive and is simpler to be implemented, since, it consists of solving a system of linear equations.
Analysis of the performance of U-Net neural networks for the segmentation of living cells
Oct 04, 2022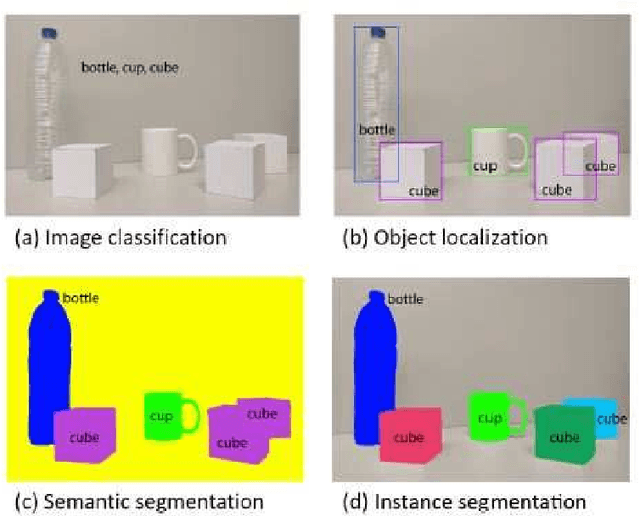
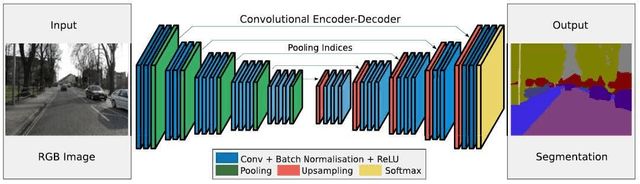
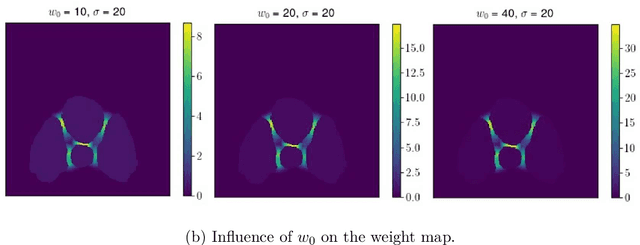
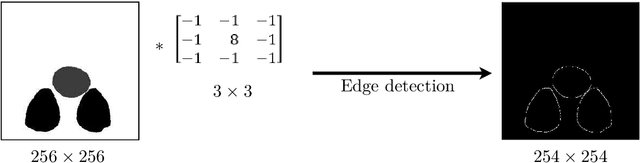
The automated analysis of microscopy images is a challenge in the context of single-cell tracking and quantification. This work has as goals the study of the performance of deep learning for segmenting microscopy images and the improvement of the previously available pipeline for tracking single cells. Deep learning techniques, mainly convolutional neural networks, have been applied to cell segmentation problems and have shown high accuracy and fast performance. To perform the image segmentation, an analysis of hyperparameters was done in order to implement a convolutional neural network with U-Net architecture. Furthermore, different models were built in order to optimize the size of the network and the number of learnable parameters. The trained network is then used in the pipeline that localizes the traps in a microfluidic device, performs the image segmentation on trap images, and evaluates the fluorescence intensity and the area of single cells over time. The tracking of the cells during an experiment is performed by image processing algorithms, such as centroid estimation and watershed. Finally, with all improvements in the neural network to segment single cells and in the pipeline, quasi-real-time image analysis was enabled, where 6.20GB of data was processed in 4 minutes.
Data-driven design of fault diagnosis for three-phase PWM rectifier using random forests technique with transient synthetic features
Nov 02, 2022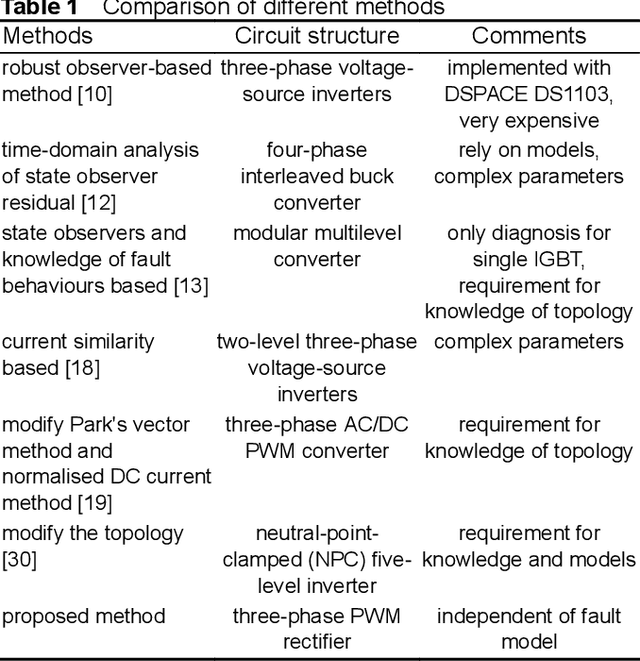
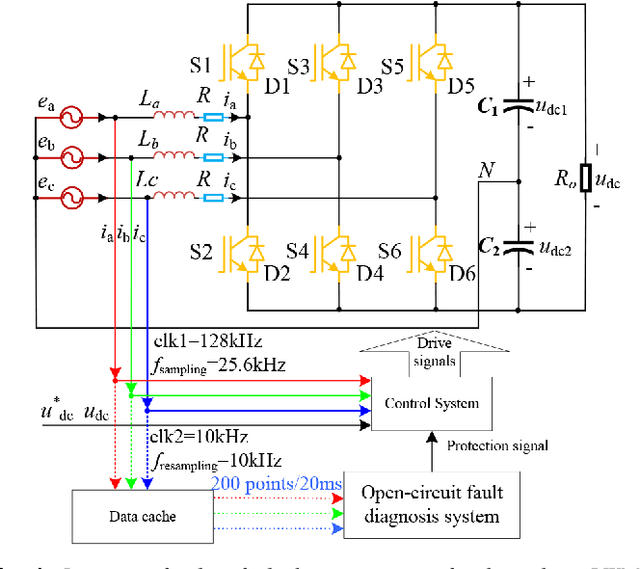
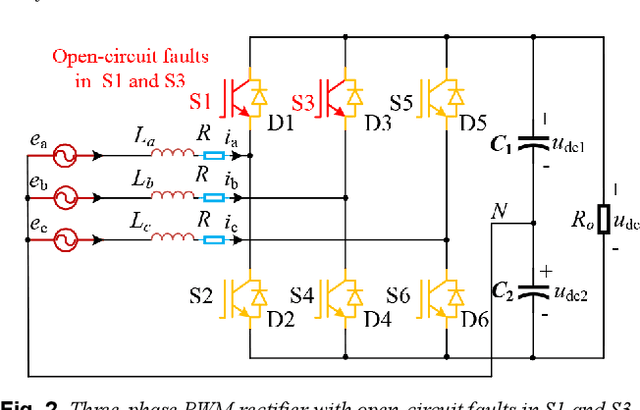
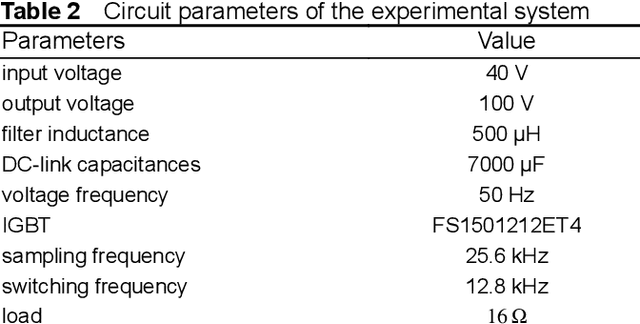
A three-phase pulse-width modulation (PWM) rectifier can usually maintain operation when open-circuit faults occur in insulated-gate bipolar transistors (IGBTs), which will lead the system to be unstable and unsafe. Aiming at this problem, based on random forests with transient synthetic features, a data-driven online fault diagnosis method is proposed to locate the open-circuit faults of IGBTs timely and effectively in this study. Firstly, by analysing the open-circuit fault features of IGBTs in the three-phase PWM rectifier, it is found that the occurrence of the fault features is related to the fault location and time, and the fault features do not always appear immediately with the occurrence of the fault. Secondly, different data-driven fault diagnosis methods are compared and evaluated, the performance of random forests algorithm is better than that of support vector machine or artificial neural networks. Meanwhile, the accuracy of fault diagnosis classifier trained by transient synthetic features is higher than that trained by original features. Also, the random forests fault diagnosis classifier trained by multiplicative features is the best with fault diagnosis accuracy can reach 98.32%. Finally, the online fault diagnosis experiments are carried out and the results demonstrate the effectiveness of the proposed method, which can accurately locate the open-circuit faults in IGBTs while ensuring system safety.
OPA-3D: Occlusion-Aware Pixel-Wise Aggregation for Monocular 3D Object Detection
Nov 02, 2022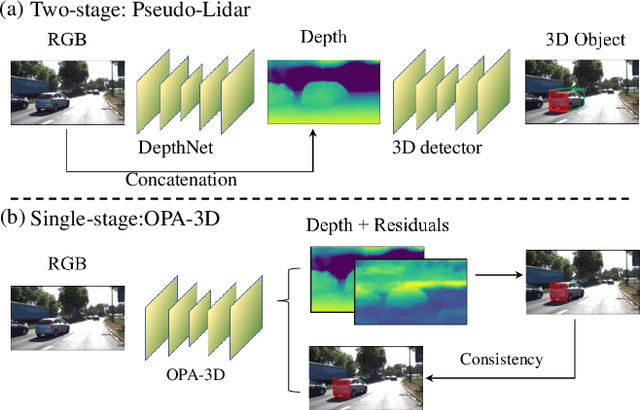
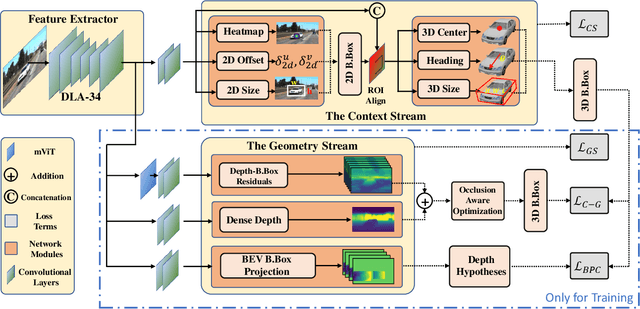
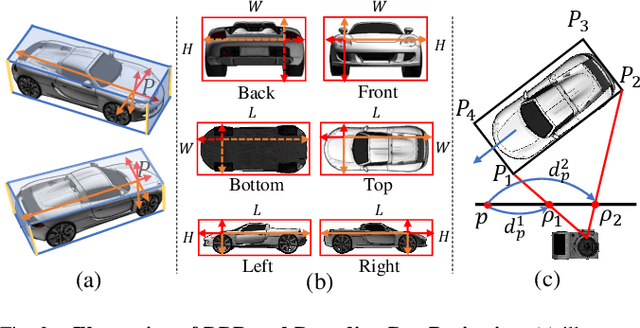

Despite monocular 3D object detection having recently made a significant leap forward thanks to the use of pre-trained depth estimators for pseudo-LiDAR recovery, such two-stage methods typically suffer from overfitting and are incapable of explicitly encapsulating the geometric relation between depth and object bounding box. To overcome this limitation, we instead propose OPA-3D, a single-stage, end-to-end, Occlusion-Aware Pixel-Wise Aggregation network that to jointly estimate dense scene depth with depth-bounding box residuals and object bounding boxes, allowing a two-stream detection of 3D objects, leading to significantly more robust detections. Thereby, the geometry stream denoted as the Geometry Stream, combines visible depth and depth-bounding box residuals to recover the object bounding box via explicit occlusion-aware optimization. In addition, a bounding box based geometry projection scheme is employed in an effort to enhance distance perception. The second stream, named as the Context Stream, directly regresses 3D object location and size. This novel two-stream representation further enables us to enforce cross-stream consistency terms which aligns the outputs of both streams, improving the overall performance. Extensive experiments on the public benchmark demonstrate that OPA-3D outperforms state-of-the-art methods on the main Car category, whilst keeping a real-time inference speed. We plan to release all codes and trained models soon.
Ambiguity-Aware Multi-Object Pose Optimization for Visually-Assisted Robot Manipulation
Nov 02, 2022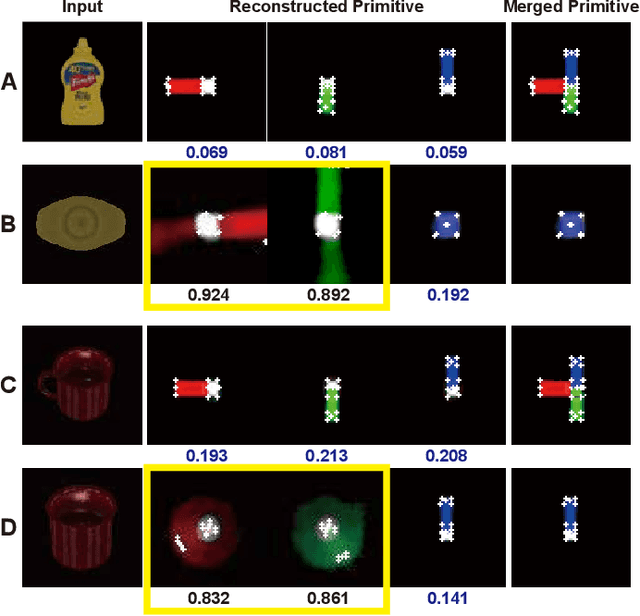
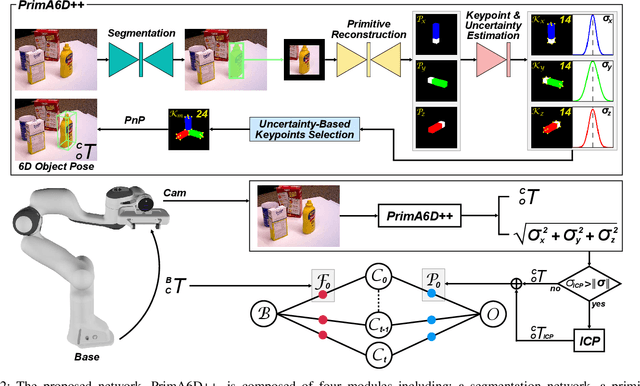
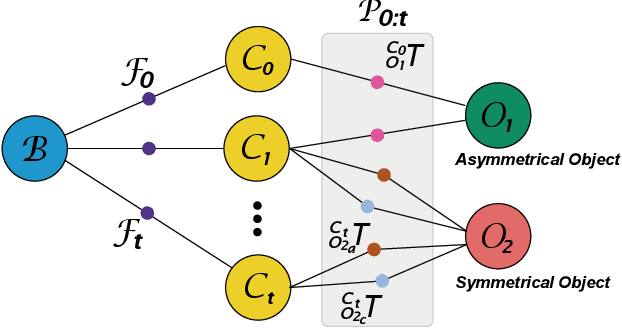
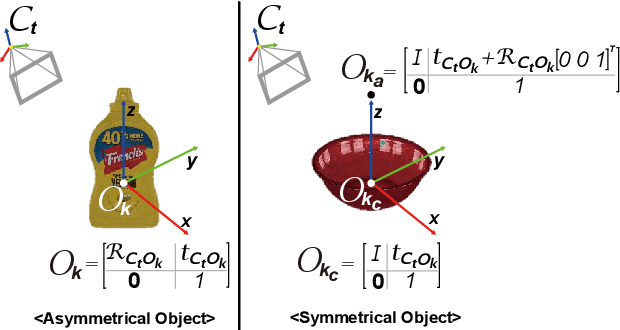
6D object pose estimation aims to infer the relative pose between the object and the camera using a single image or multiple images. Most works have focused on predicting the object pose without associated uncertainty under occlusion and structural ambiguity (symmetricity). However, these works demand prior information about shape attributes, and this condition is hardly satisfied in reality; even asymmetric objects may be symmetric under the viewpoint change. In addition, acquiring and fusing diverse sensor data is challenging when extending them to robotics applications. Tackling these limitations, we present an ambiguity-aware 6D object pose estimation network, PrimA6D++, as a generic uncertainty prediction method. The major challenges in pose estimation, such as occlusion and symmetry, can be handled in a generic manner based on the measured ambiguity of the prediction. Specifically, we devise a network to reconstruct the three rotation axis primitive images of a target object and predict the underlying uncertainty along each primitive axis. Leveraging the estimated uncertainty, we then optimize multi-object poses using visual measurements and camera poses by treating it as an object SLAM problem. The proposed method shows a significant performance improvement in T-LESS and YCB-Video datasets. We further demonstrate real-time scene recognition capability for visually-assisted robot manipulation. Our code and supplementary materials are available at https://github.com/rpmsnu/PrimA6D.
HAPI: A Large-scale Longitudinal Dataset of Commercial ML API Predictions
Sep 18, 2022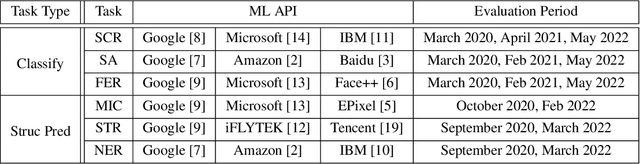
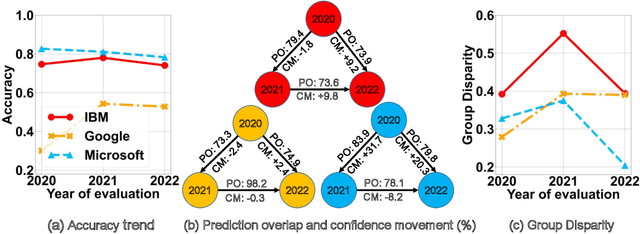
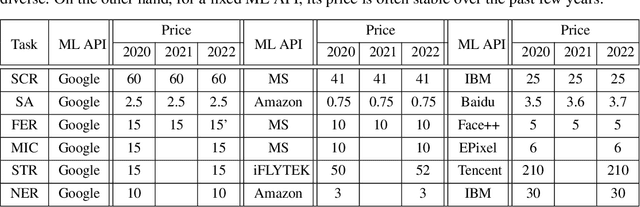
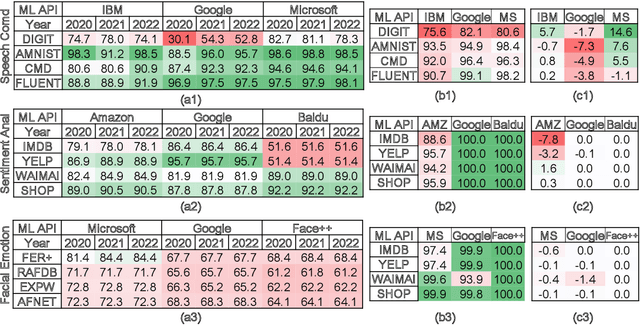
Commercial ML APIs offered by providers such as Google, Amazon and Microsoft have dramatically simplified ML adoption in many applications. Numerous companies and academics pay to use ML APIs for tasks such as object detection, OCR and sentiment analysis. Different ML APIs tackling the same task can have very heterogeneous performance. Moreover, the ML models underlying the APIs also evolve over time. As ML APIs rapidly become a valuable marketplace and a widespread way to consume machine learning, it is critical to systematically study and compare different APIs with each other and to characterize how APIs change over time. However, this topic is currently underexplored due to the lack of data. In this paper, we present HAPI (History of APIs), a longitudinal dataset of 1,761,417 instances of commercial ML API applications (involving APIs from Amazon, Google, IBM, Microsoft and other providers) across diverse tasks including image tagging, speech recognition and text mining from 2020 to 2022. Each instance consists of a query input for an API (e.g., an image or text) along with the API's output prediction/annotation and confidence scores. HAPI is the first large-scale dataset of ML API usages and is a unique resource for studying ML-as-a-service (MLaaS). As examples of the types of analyses that HAPI enables, we show that ML APIs' performance change substantially over time--several APIs' accuracies dropped on specific benchmark datasets. Even when the API's aggregate performance stays steady, its error modes can shift across different subtypes of data between 2020 and 2022. Such changes can substantially impact the entire analytics pipelines that use some ML API as a component. We further use HAPI to study commercial APIs' performance disparities across demographic subgroups over time. HAPI can stimulate more research in the growing field of MLaaS.
SC-wLS: Towards Interpretable Feed-forward Camera Re-localization
Oct 23, 2022Visual re-localization aims to recover camera poses in a known environment, which is vital for applications like robotics or augmented reality. Feed-forward absolute camera pose regression methods directly output poses by a network, but suffer from low accuracy. Meanwhile, scene coordinate based methods are accurate, but need iterative RANSAC post-processing, which brings challenges to efficient end-to-end training and inference. In order to have the best of both worlds, we propose a feed-forward method termed SC-wLS that exploits all scene coordinate estimates for weighted least squares pose regression. This differentiable formulation exploits a weight network imposed on 2D-3D correspondences, and requires pose supervision only. Qualitative results demonstrate the interpretability of learned weights. Evaluations on 7Scenes and Cambridge datasets show significantly promoted performance when compared with former feed-forward counterparts. Moreover, our SC-wLS method enables a new capability: self-supervised test-time adaptation on the weight network. Codes and models are publicly available.