 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Visual Time-Series Representation Learning and Clustering
Nov 19, 2021


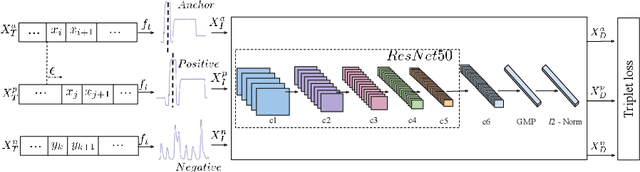

Time-series data is generated ubiquitously from Internet-of-Things (IoT) infrastructure, connected and wearable devices, remote sensing, autonomous driving research and, audio-video communications, in enormous volumes. This paper investigates the potential of unsupervised representation learning for these time-series. In this paper, we use a novel data transformation along with novel unsupervised learning regime to transfer the learning from other domains to time-series where the former have extensive models heavily trained on very large labelled datasets. We conduct extensive experiments to demonstrate the potential of the proposed approach through time-series clustering.
Multi-Hour Ahead Dst Index Prediction Using Multi-Fidelity Boosted Neural Networks
Sep 26, 2022



The Disturbance storm time (Dst) index has been widely used as a proxy for the ring current intensity, and therefore as a measure of geomagnetic activity. It is derived by measurements from four ground magnetometers in the geomagnetic equatorial regions. We present a new model for predicting $Dst$ with a lead time between 1 and 6 hours. The model is first developed using a Gated Recurrent Unit (GRU) network that is trained using solar wind parameters. The uncertainty of the $Dst$ model is then estimated by using the ACCRUE method [Camporeale et al. 2021]. Finally, a multi-fidelity boosting method is developed in order to enhance the accuracy of the model and reduce its associated uncertainty. It is shown that the developed model can predict $Dst$ 6 hours ahead with a root-mean-square-error (RMSE) of 13.54 $\mathrm{nT}$. This is significantly better than the persistence model and a simple GRU model.
Spline Sketches: An Efficient Approach for Photon Counting Lidar
Oct 13, 2022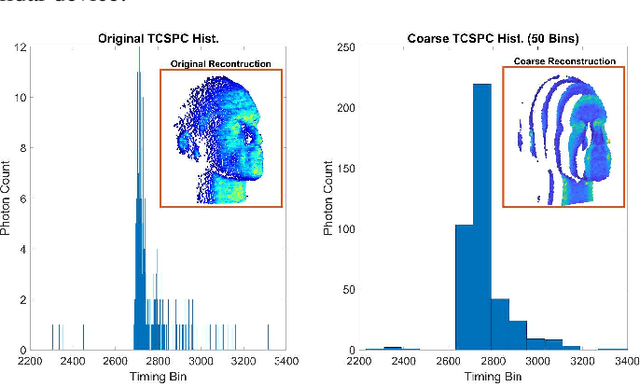

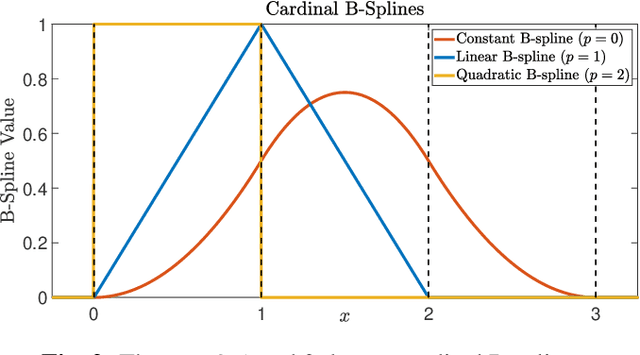

Photon counting lidar has become an invaluable tool for 3D depth imaging due to the fine-precision it can achieve over long ranges. However, high frame rate, high resolution lidar devices produce an enormous amount of time-of-flight (ToF) data which can cause a severe data processing bottleneck hindering the deployment of real-time systems. In this paper, an efficient photon counting approach is proposed that exploits the simplicity of piecewise polynomial splines to form a hardware-friendly compressed statistic, or a so-called spline sketch, of the ToF data without sacrificing the quality of the recovered image. As each piecewise polynomial spline is a simple function with limited support over the timing depth window, the spline sketch can be computed efficiently on-chip with minimal computational overhead. \MD{We show that a piecewise linear or quadratic spline sketch, requiring minimal on-chip arithmetic computation per photon detection, can reconstruct real-world depth images with negligible loss of resolution whilst achieving $95\%$ compression compared to the full ToF data, as well as offering multi-peak detection performance. These contrast with previously proposed coarse binning histograms that suffer from a highly nonuniform accuracy across depth and can fail catastrophically when associated with bright reflectors. Further, by building range-walk correction into the proposed estimation algorithms, it is demonstrated that the spline sketches can be made robust to photon pile-up effects.} The computational complexity of both the reconstruction and range walk correction algorithms scale only with the size of the spline sketch which is independent to both the photon count and temporal resolution of the lidar device.
Selective compression learning of latent representations for variable-rate image compression
Nov 08, 2022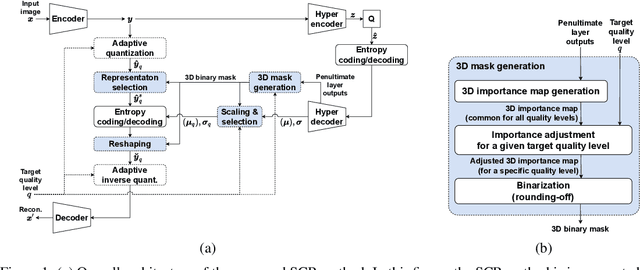
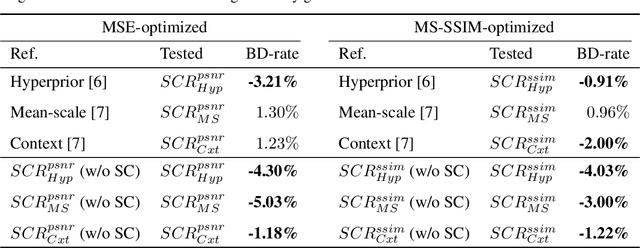

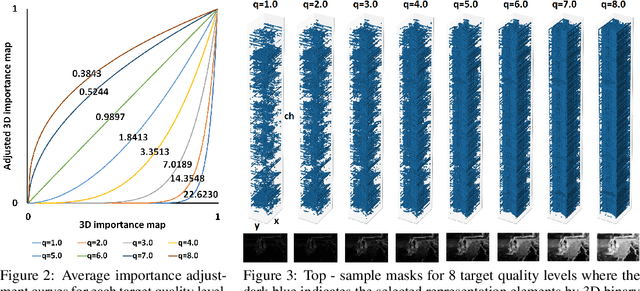
Recently, many neural network-based image compression methods have shown promising results superior to the existing tool-based conventional codecs. However, most of them are often trained as separate models for different target bit rates, thus increasing the model complexity. Therefore, several studies have been conducted for learned compression that supports variable rates with single models, but they require additional network modules, layers, or inputs that often lead to complexity overhead, or do not provide sufficient coding efficiency. In this paper, we firstly propose a selective compression method that partially encodes the latent representations in a fully generalized manner for deep learning-based variable-rate image compression. The proposed method adaptively determines essential representation elements for compression of different target quality levels. For this, we first generate a 3D importance map as the nature of input content to represent the underlying importance of the representation elements. The 3D importance map is then adjusted for different target quality levels using importance adjustment curves. The adjusted 3D importance map is finally converted into a 3D binary mask to determine the essential representation elements for compression. The proposed method can be easily integrated with the existing compression models with a negligible amount of overhead increase. Our method can also enable continuously variable-rate compression via simple interpolation of the importance adjustment curves among different quality levels. The extensive experimental results show that the proposed method can achieve comparable compression efficiency as those of the separately trained reference compression models and can reduce decoding time owing to the selective compression. The sample codes are publicly available at https://github.com/JooyoungLeeETRI/SCR.
Low-Stabilizer-Complexity Quantum States Are Not Pseudorandom
Sep 29, 2022We show that quantum states with "low stabilizer complexity" can be efficiently distinguished from Haar-random. Specifically, given an $n$-qubit pure state $|\psi\rangle$, we give an efficient algorithm that distinguishes whether $|\psi\rangle$ is (i) Haar-random or (ii) a state with stabilizer fidelity at least $\frac{1}{k}$ (i.e., has fidelity at least $\frac{1}{k}$ with some stabilizer state), promised that one of these is the case. With black-box access to $|\psi\rangle$, our algorithm uses $O\!\left( k^{12} \log(1/\delta)\right)$ copies of $|\psi\rangle$ and $O\!\left(n k^{12} \log(1/\delta)\right)$ time to succeed with probability at least $1-\delta$, and, with access to a state preparation unitary for $|\psi\rangle$ (and its inverse), $O\!\left( k^{3} \log(1/\delta)\right)$ queries and $O\!\left(n k^{3} \log(1/\delta)\right)$ time suffice. As a corollary, we prove that $\omega(\log(n))$ $T$-gates are necessary for any Clifford+$T$ circuit to prepare computationally pseudorandom quantum states, a first-of-its-kind lower bound.
Agent-Controller Representations: Principled Offline RL with Rich Exogenous Information
Oct 31, 2022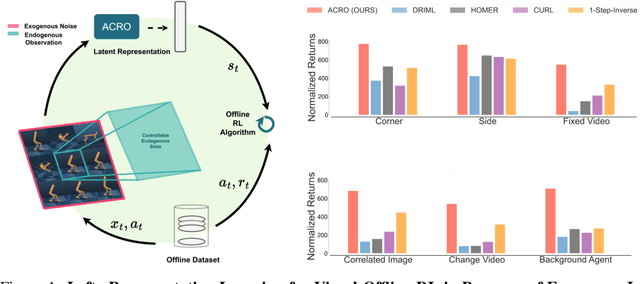

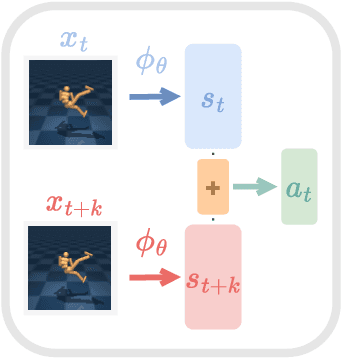
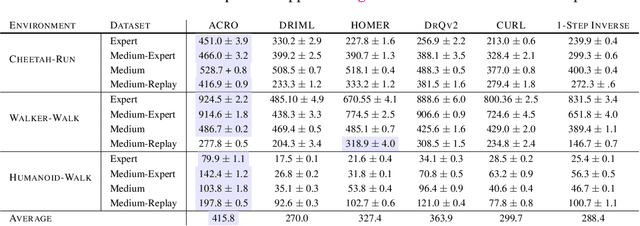
Learning to control an agent from data collected offline in a rich pixel-based visual observation space is vital for real-world applications of reinforcement learning (RL). A major challenge in this setting is the presence of input information that is hard to model and irrelevant to controlling the agent. This problem has been approached by the theoretical RL community through the lens of exogenous information, i.e, any control-irrelevant information contained in observations. For example, a robot navigating in busy streets needs to ignore irrelevant information, such as other people walking in the background, textures of objects, or birds in the sky. In this paper, we focus on the setting with visually detailed exogenous information, and introduce new offline RL benchmarks offering the ability to study this problem. We find that contemporary representation learning techniques can fail on datasets where the noise is a complex and time dependent process, which is prevalent in practical applications. To address these, we propose to use multi-step inverse models, which have seen a great deal of interest in the RL theory community, to learn Agent-Controller Representations for Offline-RL (ACRO). Despite being simple and requiring no reward, we show theoretically and empirically that the representation created by this objective greatly outperforms baselines.
Multi-Scale Structural-aware Exposure Correction for Endoscopic Imaging
Oct 26, 2022
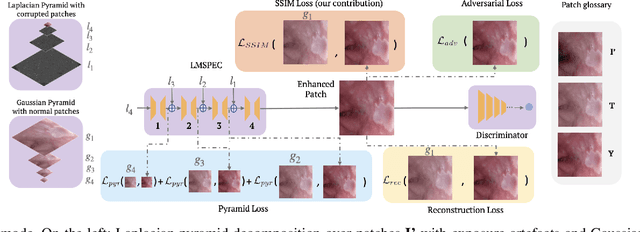
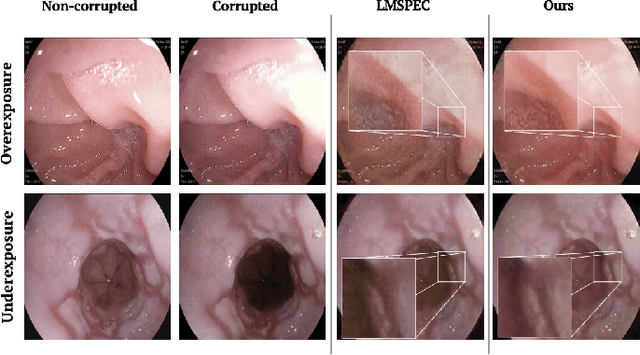
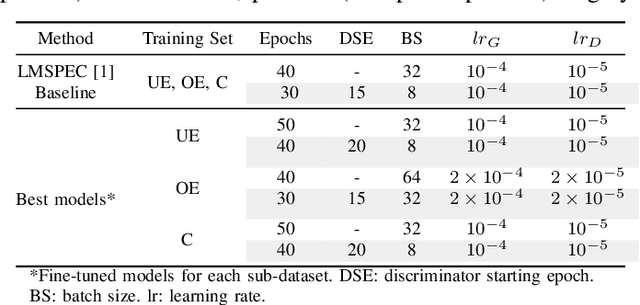
Endoscopy is the most widely used imaging technique for the diagnosis of cancerous lesions in hollow organs. However, endoscopic images are often affected by illumination artefacts: image parts may be over- or underexposed according to the light source pose and the tissue orientation. These artifacts have a strong negative impact on the performance of computer vision or AI-based diagnosis tools. Although endoscopic image enhancement methods are greatly required, little effort has been devoted to over- and under-exposition enhancement in real-time. This contribution presents an extension to the objective function of LMSPEC, a method originally introduced to enhance images from natural scenes. It is used here for the exposure correction in endoscopic imaging and the preservation of structural information. To the best of our knowledge, this contribution is the first one that addresses the enhancement of endoscopic images using deep learning (DL) methods. Tested on the Endo4IE dataset, the proposed implementation has yielded a significant improvement over LMSPEC reaching a SSIM increase of 4.40% and 4.21% for over- and underexposed images, respectively.
Trade-off between reconstruction loss and feature alignment for domain generalization
Oct 26, 2022
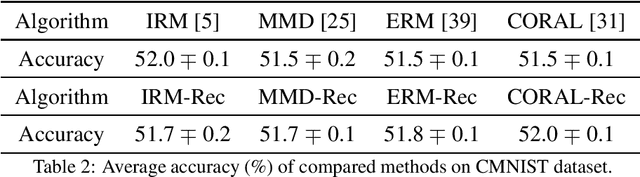
Domain generalization (DG) is a branch of transfer learning that aims to train the learning models on several seen domains and subsequently apply these pre-trained models to other unseen (unknown but related) domains. To deal with challenging settings in DG where both data and label of the unseen domain are not available at training time, the most common approach is to design the classifiers based on the domain-invariant representation features, i.e., the latent representations that are unchanged and transferable between domains. Contrary to popular belief, we show that designing classifiers based on invariant representation features alone is necessary but insufficient in DG. Our analysis indicates the necessity of imposing a constraint on the reconstruction loss induced by representation functions to preserve most of the relevant information about the label in the latent space. More importantly, we point out the trade-off between minimizing the reconstruction loss and achieving domain alignment in DG. Our theoretical results motivate a new DG framework that jointly optimizes the reconstruction loss and the domain discrepancy. Both theoretical and numerical results are provided to justify our approach.
* 13 pages, 2 tables
Learning on Large-scale Text-attributed Graphs via Variational Inference
Oct 26, 2022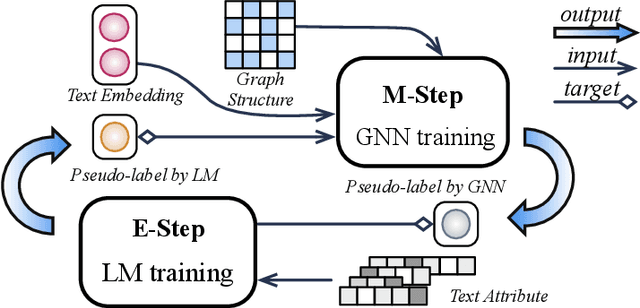

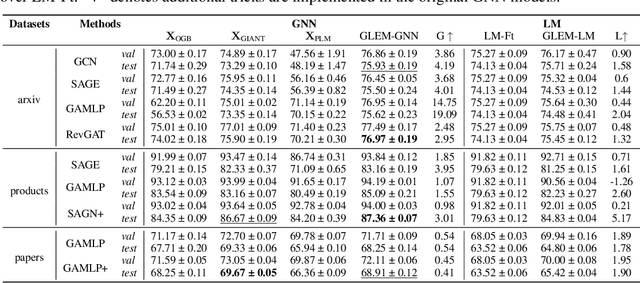
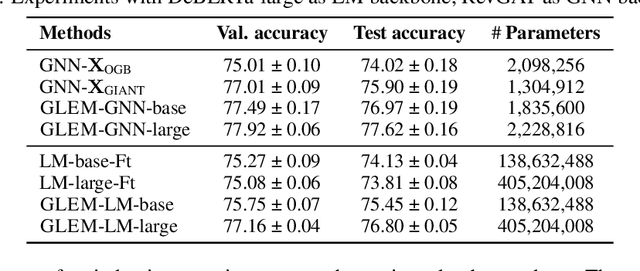
This paper studies learning on text-attributed graphs (TAGs), where each node is associated with a text description. An ideal solution for such a problem would be integrating both the text and graph structure information with large language models and graph neural networks (GNNs). However, the problem becomes very challenging when graphs are large due to the high computational complexity brought by large language models and training GNNs on big graphs. In this paper, we propose an efficient and effective solution to learning on large text-attributed graphs by fusing graph structure and language learning with a variational Expectation-Maximization (EM) framework, called GLEM. Instead of simultaneously training large language models and GNNs on big graphs, GLEM proposes to alternatively update the two modules in the E-step and M-step. Such a procedure allows to separately train the two modules but at the same time allows the two modules to interact and mutually enhance each other. Extensive experiments on multiple data sets demonstrate the efficiency and effectiveness of the proposed approach.
Unknown area exploration for robots with energy constraints using a modified Butterfly Optimization Algorithm
Oct 26, 2022Butterfly Optimization Algorithm (BOA) is a recent metaheuristic that has been used in several optimization problems. In this paper, we propose a new version of the algorithm (xBOA) based on the crossover operator and compare its results to the original BOA and 3 other variants recently introduced in the literature. We also proposed a framework for solving the unknown area exploration problem with energy constraints using metaheuristics in both single- and multi-robot scenarios. This framework allowed us to benchmark the performances of different metaheuristics for the robotics exploration problem. We conducted several experiments to validate this framework and used it to compare the effectiveness of xBOA with wellknown metaheuristics used in the literature through 5 evaluation criteria. Although BOA and xBOA are not optimal in all these criteria, we found that BOA can be a good alternative to many metaheuristics in terms of the exploration time, while xBOA is more robust to local optima; has better fitness convergence; and achieves better exploration rates than the original BOA and its other variants.