 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Listen, Adapt, Better WER: Source-free Single-utterance Test-time Adaptation for Automatic Speech Recognition
Mar 27, 2022
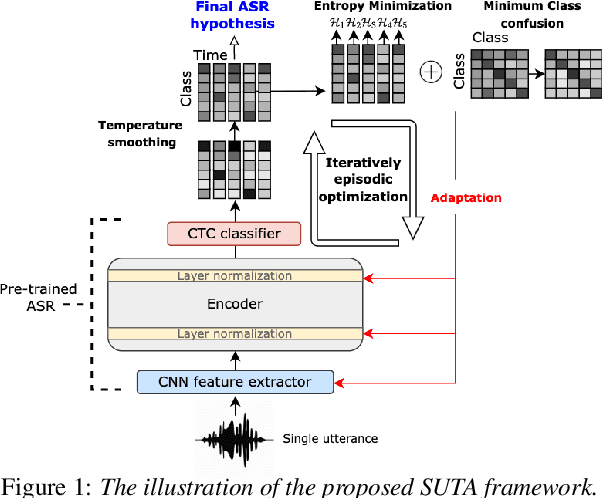

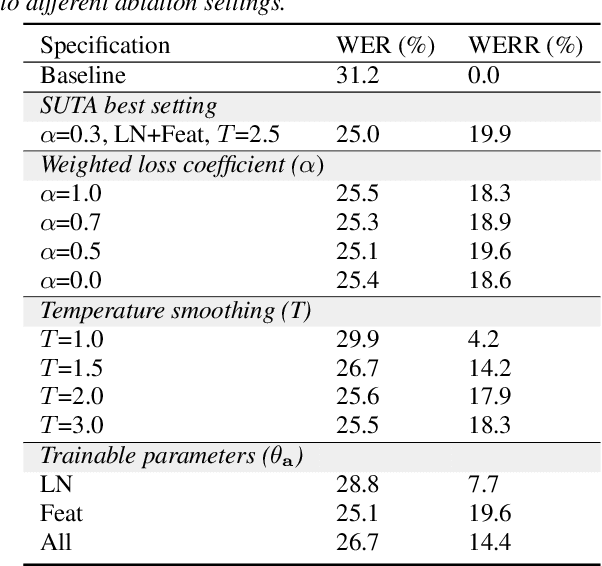
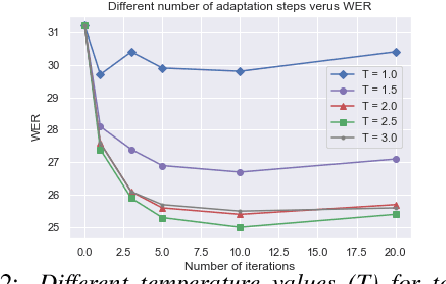
Although deep learning-based end-to-end Automatic Speech Recognition (ASR) has shown remarkable performance in recent years, it suffers severe performance regression on test samples drawn from different data distributions. Test-time Adaptation (TTA), previously explored in the computer vision area, aims to adapt the model trained on source domains to yield better predictions for test samples, often out-of-domain, without accessing the source data. Here, we propose the Single-Utterance Test-time Adaptation (SUTA) framework for ASR, which is the first TTA study in speech area to our best knowledge. The single-utterance TTA is a more realistic setting that does not assume test data are sampled from identical distribution and does not delay on-demand inference due to pre-collection for the batch of adaptation data. SUTA consists of unsupervised objectives with an efficient adaptation strategy. The empirical results demonstrate that SUTA effectively improves the performance of the source ASR model evaluated on multiple out-of-domain target corpora and in-domain test samples.
Centroid Distance Keypoint Detector for Colored Point Clouds
Oct 04, 2022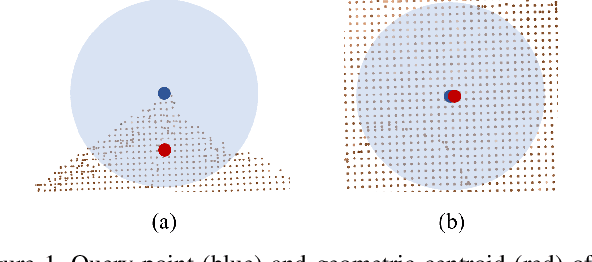
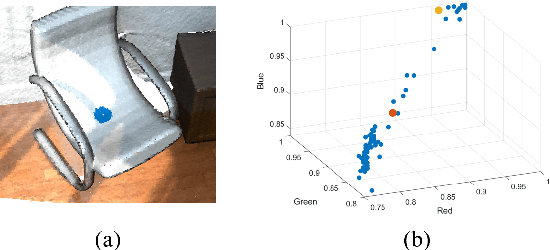
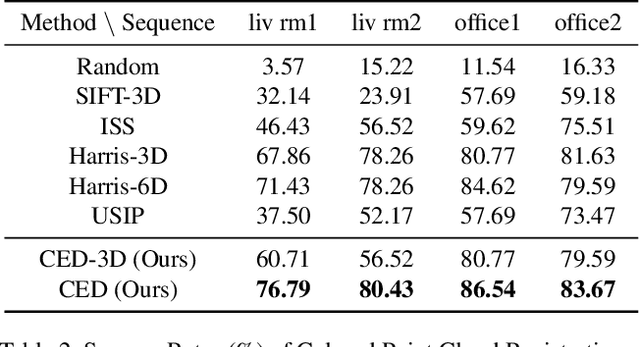
Keypoint detection serves as the basis for many computer vision and robotics applications. Despite the fact that colored point clouds can be readily obtained, most existing keypoint detectors extract only geometry-salient keypoints, which can impede the overall performance of systems that intend to (or have the potential to) leverage color information. To promote advances in such systems, we propose an efficient multi-modal keypoint detector that can extract both geometry-salient and color-salient keypoints in colored point clouds. The proposed CEntroid Distance (CED) keypoint detector comprises an intuitive and effective saliency measure, the centroid distance, that can be used in both 3D space and color space, and a multi-modal non-maximum suppression algorithm that can select keypoints with high saliency in two or more modalities. The proposed saliency measure leverages directly the distribution of points in a local neighborhood and does not require normal estimation or eigenvalue decomposition. We evaluate the proposed method in terms of repeatability and computational efficiency (i.e. running time) against state-of-the-art keypoint detectors on both synthetic and real-world datasets. Results demonstrate that our proposed CED keypoint detector requires minimal computational time while attaining high repeatability. To showcase one of the potential applications of the proposed method, we further investigate the task of colored point cloud registration. Results suggest that our proposed CED detector outperforms state-of-the-art handcrafted and learning-based keypoint detectors in the evaluated scenes. The C++ implementation of the proposed method is made publicly available at https://github.com/UCR-Robotics/CED_Detector.
PlaneDepth: Plane-Based Self-Supervised Monocular Depth Estimation
Oct 04, 2022
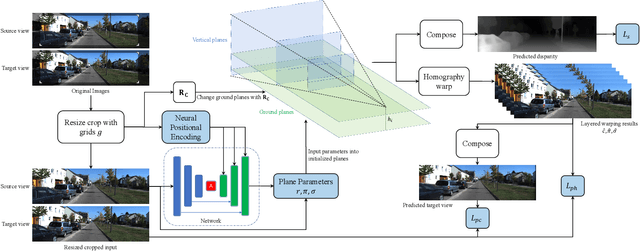


Self-supervised monocular depth estimation refers to training a monocular depth estimation (MDE) network using only RGB images to overcome the difficulty of collecting dense ground truth depth. Many previous works addressed this problem using depth classification or depth regression. However, depth classification tends to fall into local minima due to the bilinear interpolation search on the target view. Depth classification overcomes this problem using pre-divided depth bins, but those depth candidates lead to discontinuities in the final depth result, and using the same probability for weighted summation of color and depth is ambiguous. To overcome these limitations, we use some predefined planes that are parallel to the ground, allowing us to automatically segment the ground and predict continuous depth for it. We further model depth as a mixture Laplace distribution, which provides a more certain objective for optimization. Previous works have shown that MDE networks only use the vertical image position of objects to estimate the depth and ignore relative sizes. We address this problem for the first time in both stereo and monocular training using resize cropping data augmentation. Based on our analysis of resize cropping, we combine it with our plane definition and improve our training strategy so that the network could learn the relationship between depth and both the vertical image position and relative size of objects. We further combine the self-distillation stage with post-processing to provide more accurate supervision and save extra time in post-processing. We conduct extensive experiments to demonstrate the effectiveness of our analysis and improvements.
Opportunities for Intelligent Reflecting Surfaces in 6G-Empowered V2X Communications
Oct 02, 2022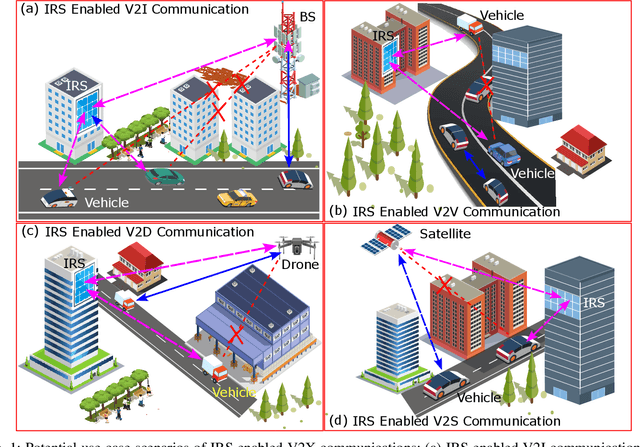
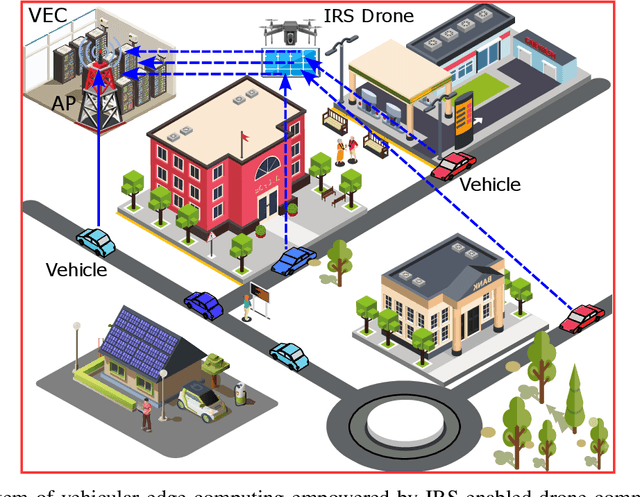
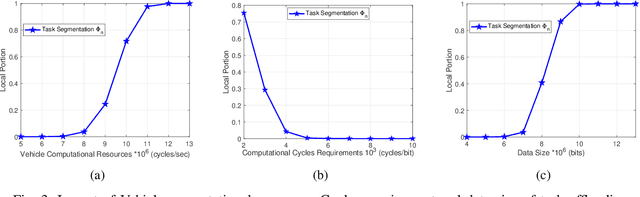
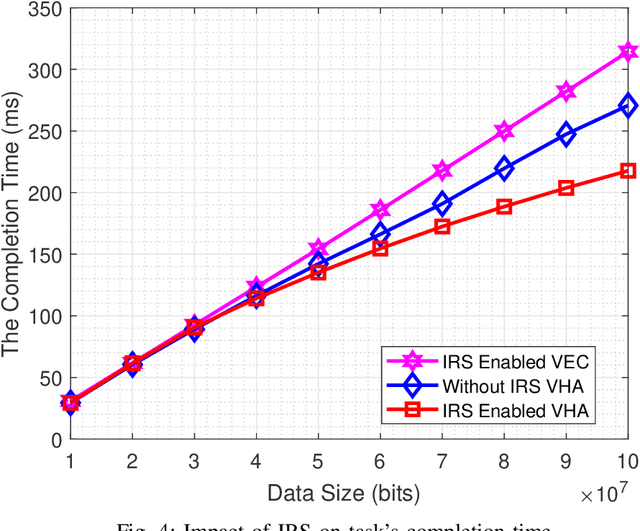
This paper first describes the introduction of 6G-empowered V2X communications and IRS technology. Then it discusses different use case scenarios of IRS enabled V2X communications and reports recent advances in the existing literature. Next, we focus our attention on the scenario of vehicular edge computing involving IRS enabled drone communications in order to reduce vehicle computational time via optimal computational and communication resource allocation. At the end, this paper highlights current challenges and discusses future perspectives of IRS enabled V2X communications in order to improve current work and spark new ideas.
Efficient Noise Filtration of Images by Low-Rank Singular Vector Approximations of Geodesics' Gramian Matrix
Sep 27, 2022
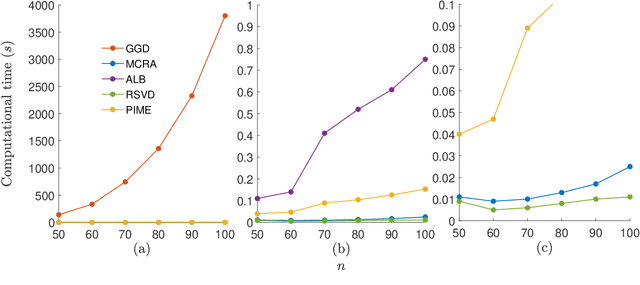

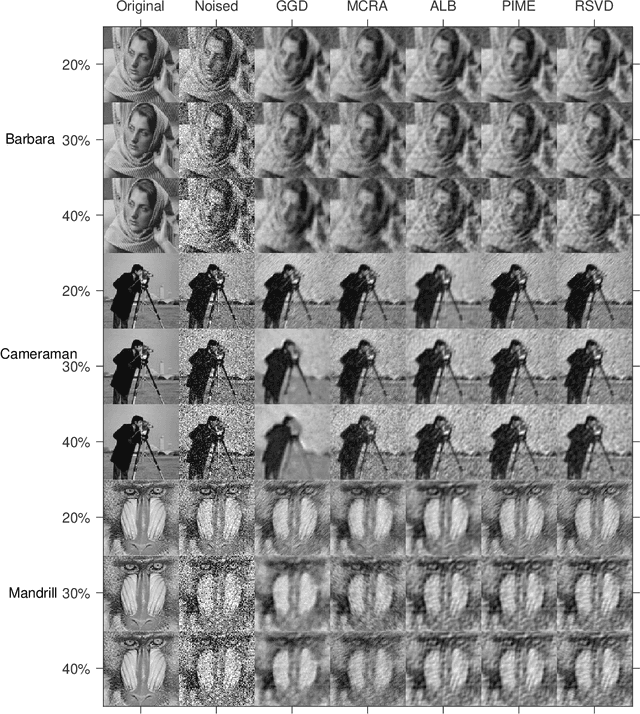
Modern society is interested in capturing high-resolution and fine-quality images due to the surge of sophisticated cameras. However, the noise contamination in the images not only inferior people's expectations but also conversely affects the subsequent processes if such images are utilized in computer vision tasks such as remote sensing, object tracking, etc. Even though noise filtration plays an essential role, real-time processing of a high-resolution image is limited by the hardware limitations of the image-capturing instruments. Geodesic Gramian Denoising (GGD) is a manifold-based noise filtering method that we introduced in our past research which utilizes a few prominent singular vectors of the geodesics' Gramian matrix for the noise filtering process. The applicability of GDD is limited as it encounters $\mathcal{O}(n^6)$ when denoising a given image of size $n\times n$ since GGD computes the prominent singular vectors of a $n^2 \times n^2$ data matrix that is implemented by singular value decomposition (SVD). In this research, we increase the efficiency of our GGD framework by replacing its SVD step with four diverse singular vector approximation techniques. Here, we compare both the computational time and the noise filtering performance between the four techniques integrated into GGD.
Development of an Ultrahigh Bandwidth Software-defined Radio Platform
Aug 25, 2022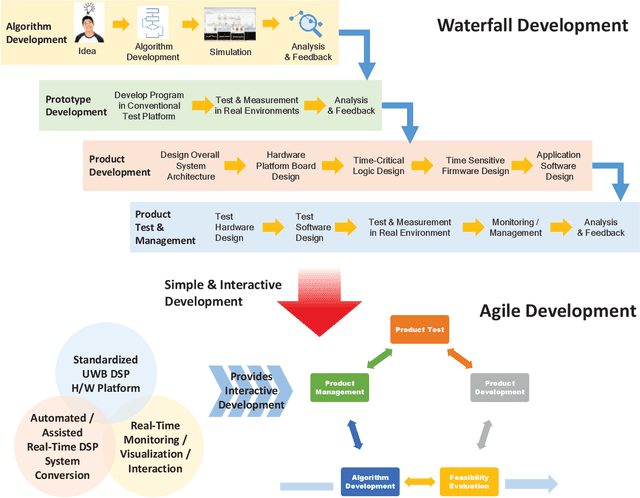
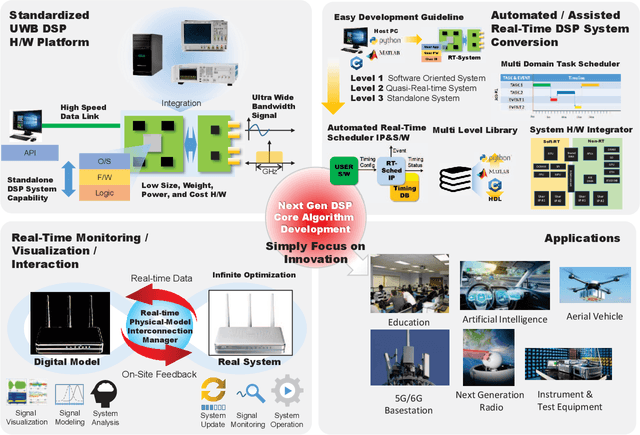
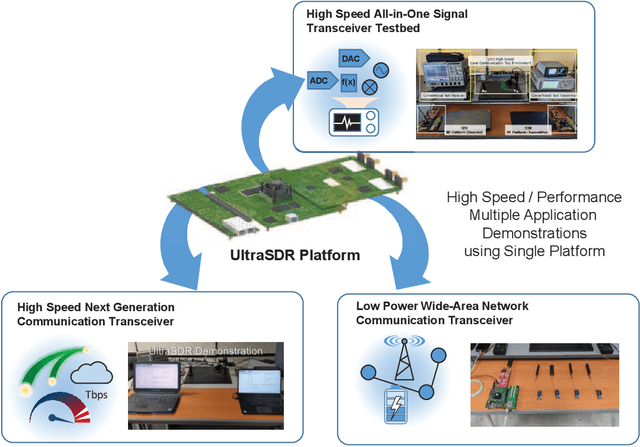
For the development of new digital signal processing systems and services, the rapid, easy, and convenient prototyping of ideas and the rapid time-to-market of products are becoming important with advances in technology. Conventionally, for the development stage, particularly when confirming the feasibility or performance of a new system or service, an idea is first confirmed through a computerbased software simulation after developing an accurate model of the operating environment. Next, this idea is validated and tested in the real operating environment. The new systems or services and their operating environments are becoming increasingly complicated. Hence, their development processes too are more complex cost- and time-intensive tasks that require engineers with skill and professional knowledge/experience. Furthermore, for ensuring fast time-to-market, all the development processes encompassing the (i) algorithm development, (ii) product prototyping, and (iii) final product development, must be closely linked such that they can be quickly completed. In this context, the aim of this paper is to propose an ultrahigh bandwidth software-defined radio platform that can prototype a quasi-real-time operating system without a developer having sophisticated hardware/software expertise. This platform allows the realization of a software-implemented digital signal processing system in minimal time with minimal efforts and without the need of a host computer.
SITA: Single Image Test-time Adaptation
Dec 08, 2021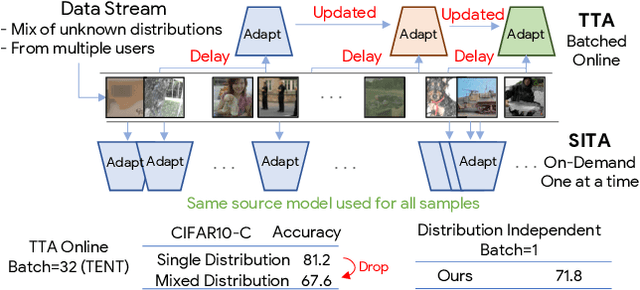


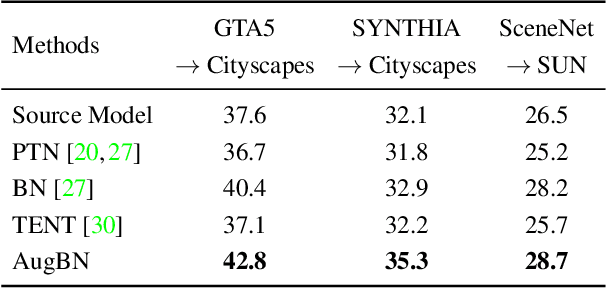
In Test-time Adaptation (TTA), given a model trained on some source data, the goal is to adapt it to make better predictions for test instances from a different distribution. Crucially, TTA assumes no access to the source data or even any additional labeled/unlabeled samples from the target distribution to finetune the source model. In this work, we consider TTA in a more pragmatic setting which we refer to as SITA (Single Image Test-time Adaptation). Here, when making each prediction, the model has access only to the given single test instance, rather than a batch of instances, as has typically been considered in the literature. This is motivated by the realistic scenarios where inference is needed in an on-demand fashion that may not be delayed to "batch-ify" incoming requests or the inference is happening on an edge device (like mobile phone) where there is no scope for batching. The entire adaptation process in SITA should be extremely fast as it happens at inference time. To address this, we propose a novel approach AugBN for the SITA setting that requires only forward propagation. The approach can adapt any off-the-shelf trained model to individual test instances for both classification and segmentation tasks. AugBN estimates normalisation statistics of the unseen test distribution from the given test image using only one forward pass with label-preserving transformations. Since AugBN does not involve any back-propagation, it is significantly faster compared to other recent methods. To the best of our knowledge, this is the first work that addresses this hard adaptation problem using only a single test image. Despite being very simple, our framework is able to achieve significant performance gains compared to directly applying the source model on the target instances, as reflected in our extensive experiments and ablation studies.
UTIL: An Ultra-wideband Time-difference-of-arrival Indoor Localization Dataset
Mar 28, 2022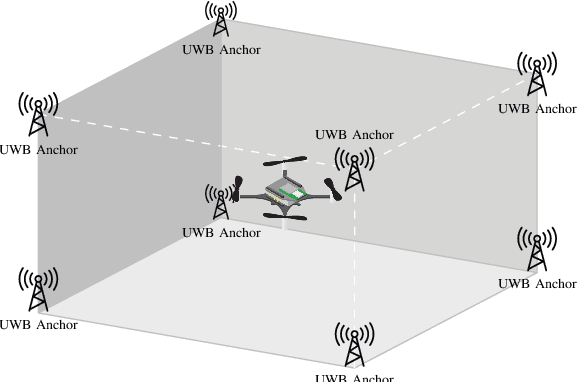
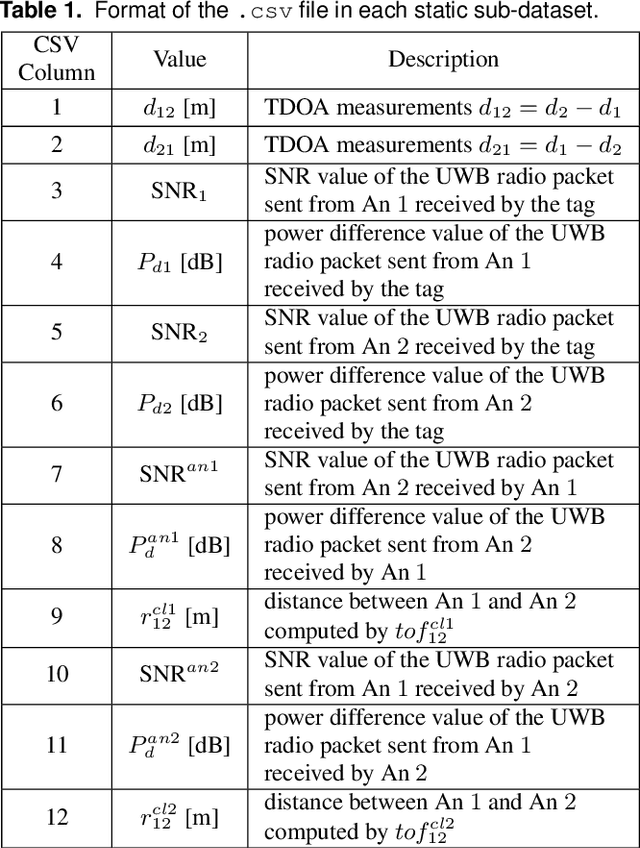
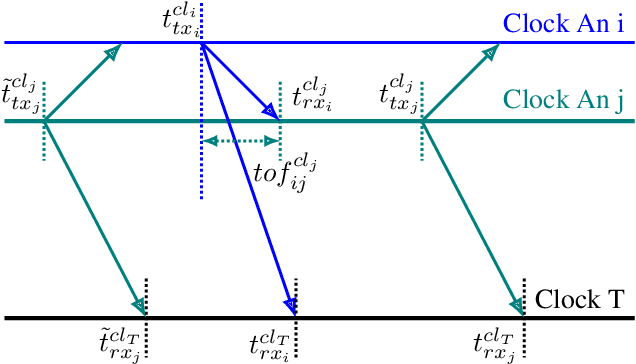
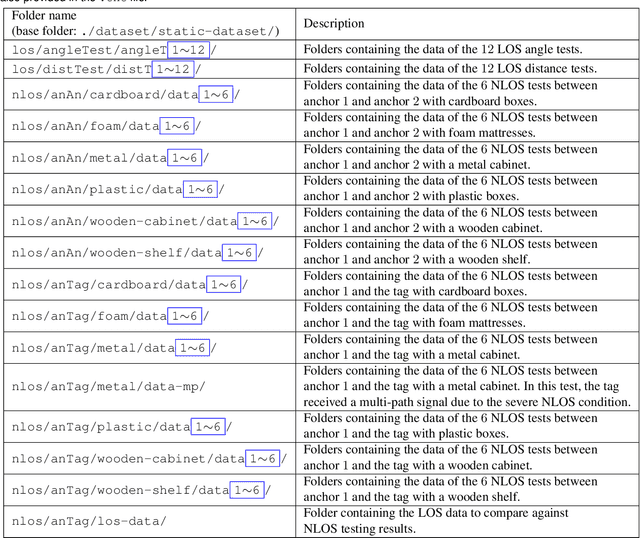
This paper presents an ultra-wideband (UWB) time-difference-of-arrival (TDOA) dataset collected from a quadrotor for research purposes. The dataset consists of low-level signal information from static experiments and UWB TDOA measurements and additional onboard sensor data from flight experiments on a quadrotor. The data collection process is discussed in detail, including the equipment used, measurement collection procedure, and the calibration of the quadrotor platform. All the data is made available as plain text files and we provide both Matlab and Python scripts to parse and analyze the data. We provide a thorough description of the data format and some pointers on the potential usage of each sub-dataset. The dataset is available for download at https://utiasdsl.github.io/util-uwb-dataset/. We hope this dataset will help researchers develop and compare reliable estimation methods for the emerging UWB TDOA-based indoor localization technology.
Fairness in Forecasting of Observations of Linear Dynamical Systems
Sep 12, 2022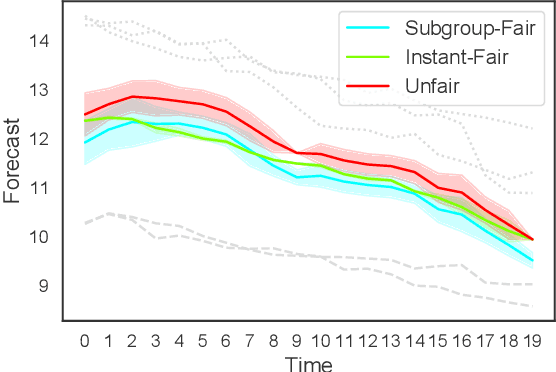
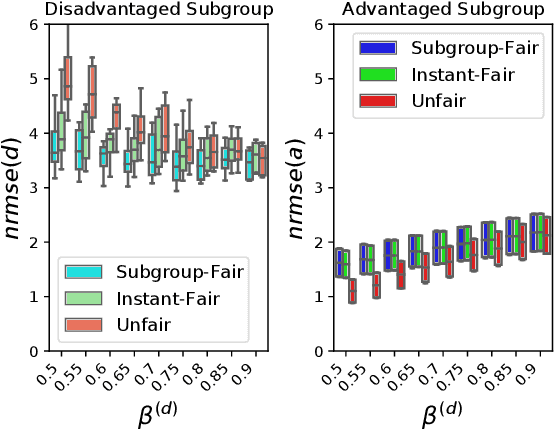
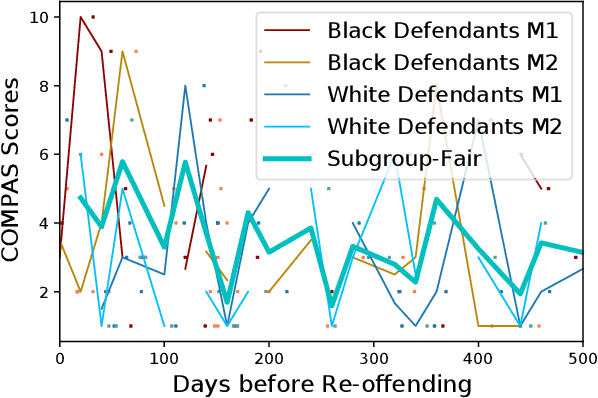
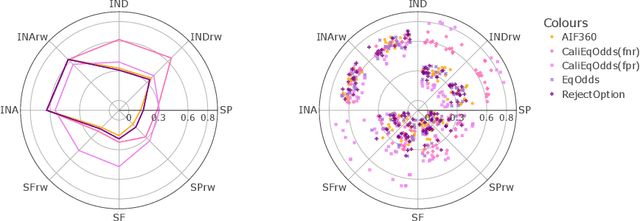
In machine learning, training data often capture the behaviour of multiple subgroups of some underlying human population. When the nature of training data for subgroups are not controlled carefully, under-representation bias arises. To counter this effect we introduce two natural notions of subgroup fairness and instantaneous fairness to address such under-representation bias in time-series forecasting problems. Here we show globally convergent methods for the fairness-constrained learning problems using hierarchies of convexifications of non-commutative polynomial optimisation problems. Our empirical results on a biased data set motivated by insurance applications and the well-known COMPAS data set demonstrate the efficacy of our methods. We also show that by exploiting sparsity in the convexifications, we can reduce the run time of our methods considerably.
No-Regret Learning in Time-Varying Zero-Sum Games
Jan 30, 2022
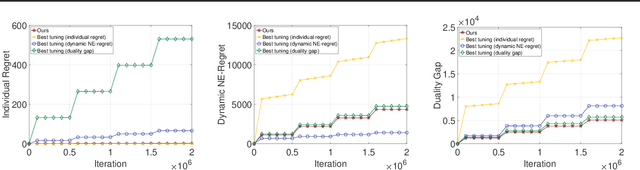
Learning from repeated play in a fixed two-player zero-sum game is a classic problem in game theory and online learning. We consider a variant of this problem where the game payoff matrix changes over time, possibly in an adversarial manner. We first present three performance measures to guide the algorithmic design for this problem: 1) the well-studied individual regret, 2) an extension of duality gap, and 3) a new measure called dynamic Nash Equilibrium regret, which quantifies the cumulative difference between the player's payoff and the minimax game value. Next, we develop a single parameter-free algorithm that simultaneously enjoys favorable guarantees under all these three performance measures. These guarantees are adaptive to different non-stationarity measures of the payoff matrices and, importantly, recover the best known results when the payoff matrix is fixed. Our algorithm is based on a two-layer structure with a meta-algorithm learning over a group of black-box base-learners satisfying a certain property, along with several novel ingredients specifically designed for the time-varying game setting. Empirical results further validate the effectiveness of our algorithm.