 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporally Adjustable Longitudinal Fluid-Attenuated Inversion Recovery MRI Estimation / Synthesis for Multiple Sclerosis
Sep 09, 2022
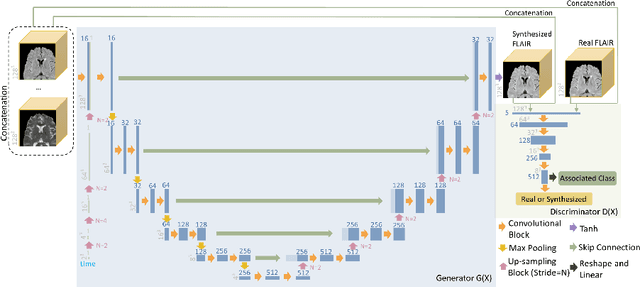
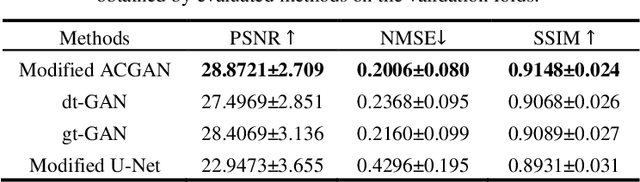
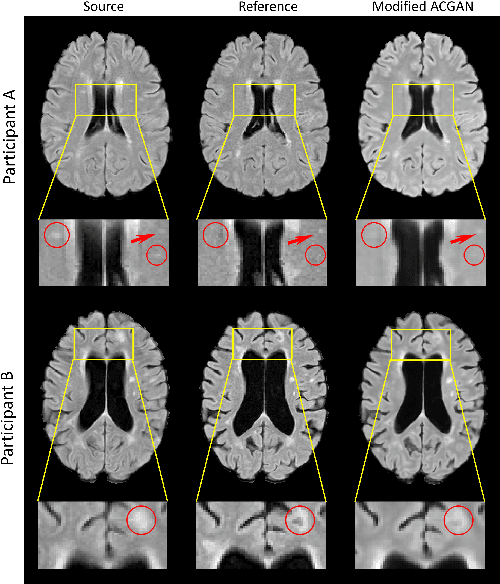
Multiple Sclerosis (MS) is a chronic progressive neurological disease characterized by the development of lesions in the white matter of the brain. T2-fluid-attenuated inversion recovery (FLAIR) brain magnetic resonance imaging (MRI) provides superior visualization and characterization of MS lesions, relative to other MRI modalities. Longitudinal brain FLAIR MRI in MS, involving repetitively imaging a patient over time, provides helpful information for clinicians towards monitoring disease progression. Predicting future whole brain MRI examinations with variable time lag has only been attempted in limited applications, such as healthy aging and structural degeneration in Alzheimer's Disease. In this article, we present novel modifications to deep learning architectures for MS FLAIR image synthesis, in order to support prediction of longitudinal images in a flexible continuous way. This is achieved with learned transposed convolutions, which support modelling time as a spatially distributed array with variable temporal properties at different spatial locations. Thus, this approach can theoretically model spatially-specific time-dependent brain development, supporting the modelling of more rapid growth at appropriate physical locations, such as the site of an MS brain lesion. This approach also supports the clinician user to define how far into the future a predicted examination should target. Accurate prediction of future rounds of imaging can inform clinicians of potentially poor patient outcomes, which may be able to contribute to earlier treatment and better prognoses. Four distinct deep learning architectures have been developed. The ISBI2015 longitudinal MS dataset was used to validate and compare our proposed approaches. Results demonstrate that a modified ACGAN achieves the best performance and reduces variability in model accuracy.
auton-survival: an Open-Source Package for Regression, Counterfactual Estimation, Evaluation and Phenotyping with Censored Time-to-Event Data
Apr 15, 2022
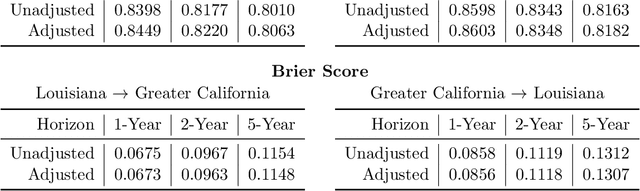
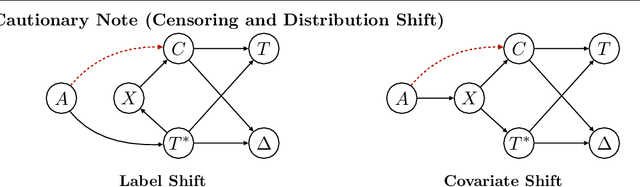
Applications of machine learning in healthcare often require working with time-to-event prediction tasks including prognostication of an adverse event, re-hospitalization or death. Such outcomes are typically subject to censoring due to loss of follow up. Standard machine learning methods cannot be applied in a straightforward manner to datasets with censored outcomes. In this paper, we present auton-survival, an open-source repository of tools to streamline working with censored time-to-event or survival data. auton-survival includes tools for survival regression, adjustment in the presence of domain shift, counterfactual estimation, phenotyping for risk stratification, evaluation, as well as estimation of treatment effects. Through real world case studies employing a large subset of the SEER oncology incidence data, we demonstrate the ability of auton-survival to rapidly support data scientists in answering complex health and epidemiological questions.
GliTr: Glimpse Transformers with Spatiotemporal Consistency for Online Action Prediction
Oct 24, 2022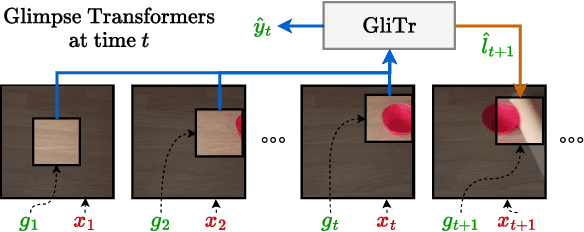
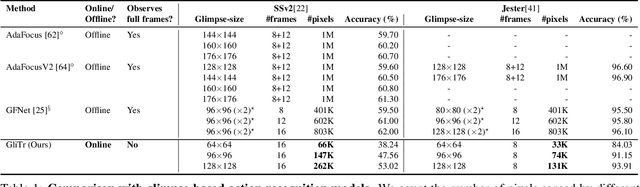
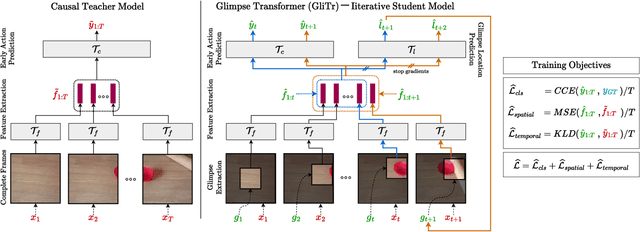

Many online action prediction models observe complete frames to locate and attend to informative subregions in the frames called glimpses and recognize an ongoing action based on global and local information. However, in applications with constrained resources, an agent may not be able to observe the complete frame, yet must still locate useful glimpses to predict an incomplete action based on local information only. In this paper, we develop Glimpse Transformers (GliTr), which observe only narrow glimpses at all times, thus predicting an ongoing action and the following most informative glimpse location based on the partial spatiotemporal information collected so far. In the absence of a ground truth for the optimal glimpse locations for action recognition, we train GliTr using a novel spatiotemporal consistency objective: We require GliTr to attend to the glimpses with features similar to the corresponding complete frames (i.e. spatial consistency) and the resultant class logits at time t equivalent to the ones predicted using whole frames up to t (i.e. temporal consistency). Inclusion of our proposed consistency objective yields ~10% higher accuracy on the Something-Something-v2 (SSv2) dataset than the baseline cross-entropy objective. Overall, despite observing only ~33% of the total area per frame, GliTr achieves 53.02%and 93.91% accuracy on the SSv2 and Jester datasets, respectively.
$\texttt{Mangrove}$: Learning Galaxy Properties from Merger Trees
Oct 24, 2022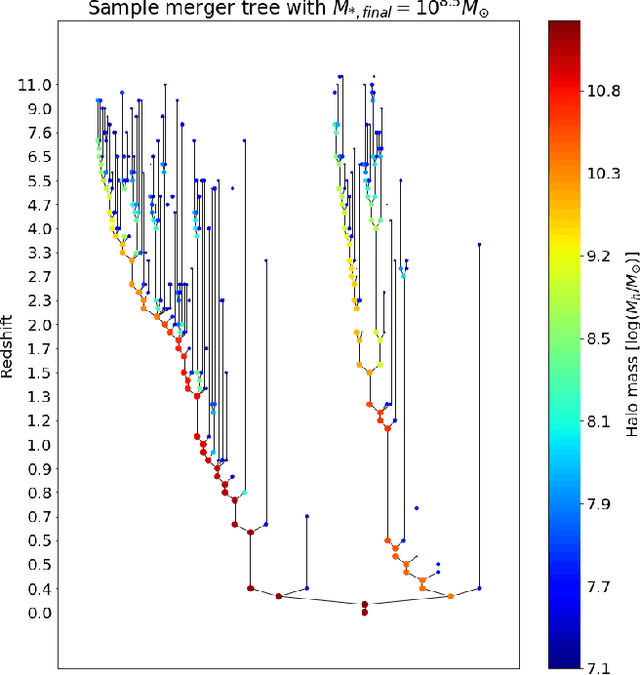
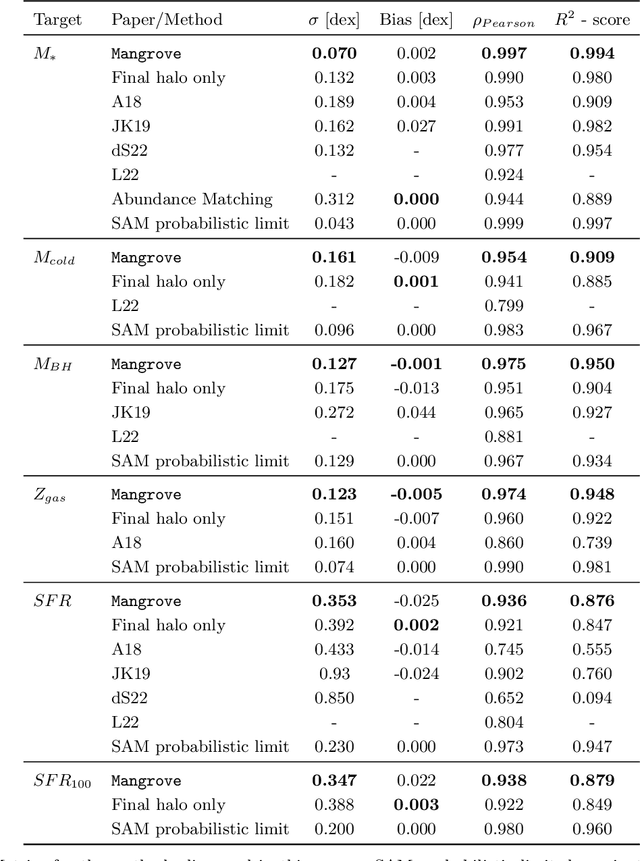
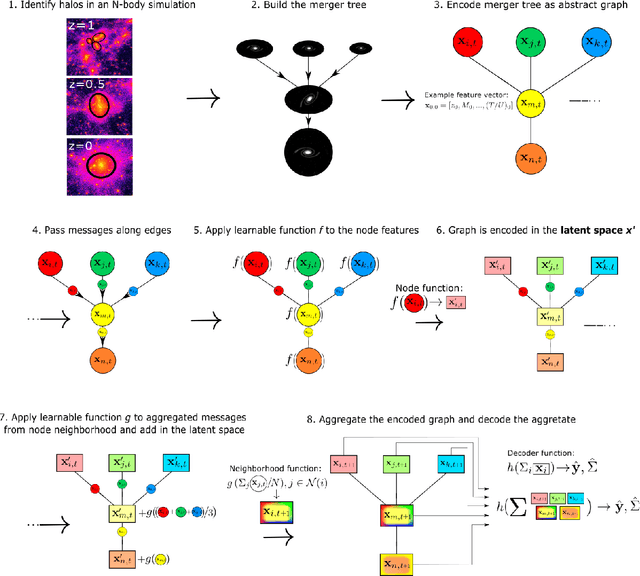
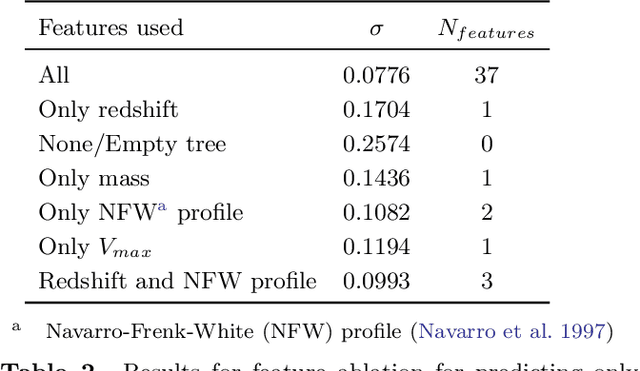
Efficiently mapping baryonic properties onto dark matter is a major challenge in astrophysics. Although semi-analytic models (SAMs) and hydrodynamical simulations have made impressive advances in reproducing galaxy observables across cosmologically significant volumes, these methods still require significant computation times, representing a barrier to many applications. Graph Neural Networks (GNNs) have recently proven to be the natural choice for learning physical relations. Among the most inherently graph-like structures found in astrophysics are the dark matter merger trees that encode the evolution of dark matter halos. In this paper we introduce a new, graph-based emulator framework, $\texttt{Mangrove}$, and show that it emulates the galactic stellar mass, cold gas mass and metallicity, instantaneous and time-averaged star formation rate, and black hole mass -- as predicted by a SAM -- with root mean squared error up to two times lower than other methods across a $(75 Mpc/h)^3$ simulation box in 40 seconds, 4 orders of magnitude faster than the SAM. We show that $\texttt{Mangrove}$ allows for quantification of the dependence of galaxy properties on merger history. We compare our results to the current state of the art in the field and show significant improvements for all target properties. $\texttt{Mangrove}$ is publicly available.
Unlocking the potential of two-point cells for energy-efficient training of deep nets
Oct 24, 2022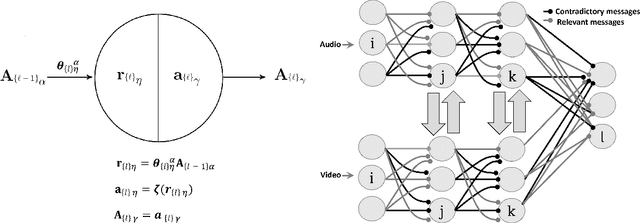
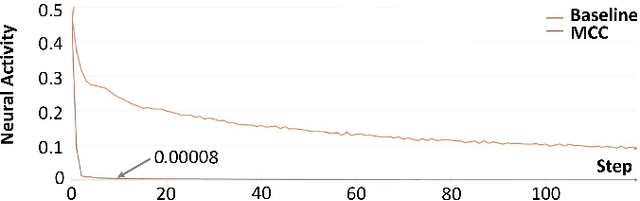
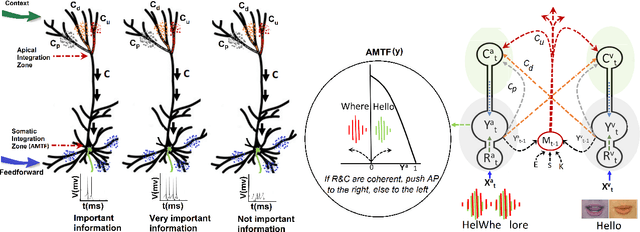
Context-sensitive two-point layer 5 pyramidal cells (L5PC) were discovered as long ago as 1999. However, the potential of this discovery to provide useful neural computation has yet to be demonstrated. Here we show for the first time how a transformative L5PC-driven deep neural network (DNN), termed the multisensory cooperative computing (MCC) architecture, can effectively process large amounts of heterogeneous real-world audio-visual (AV) data, using far less energy compared to best available `point' neuron-driven DNNs. A novel highly-distributed parallel implementation on a Xilinx UltraScale+ MPSoC device estimates energy savings up to $245759 \times 50000$ $\mu$J (i.e., $62\%$ less than the baseline model in a semi-supervised learning setup) where a single synapse consumes $8e^{-5}\mu$J. In a supervised learning setup, the energy-saving can potentially reach up to 1250x less (per feedforward transmission) than the baseline model. This remarkable performance in pilot experiments demonstrates the embodied neuromorphic intelligence of our proposed L5PC based MCC architecture that contextually selects the most salient and relevant information for onward transmission, from overwhelmingly large multimodal information utilised at the early stages of on-chip training. Our proposed approach opens new cross-disciplinary avenues for future on-chip DNN training implementations and posits a radical shift in current neuromorphic computing paradigms.
Is the Envelope Beneficial to Non-Orthogonal Multiple Access?
Oct 24, 2022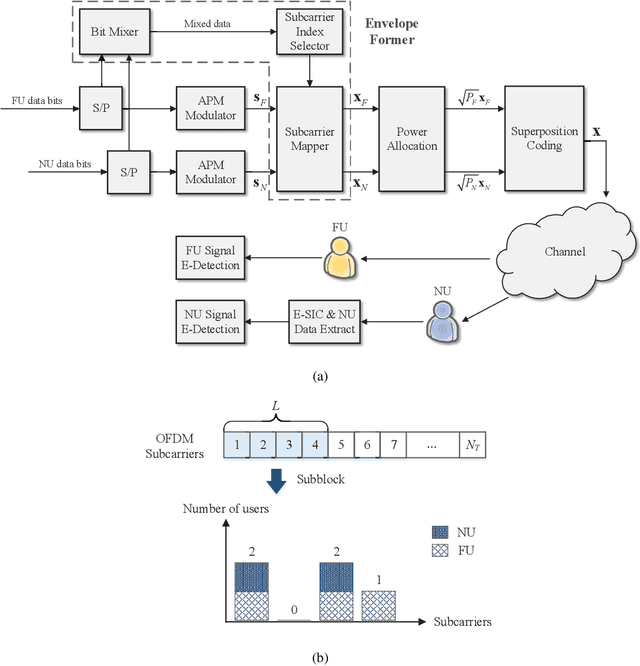
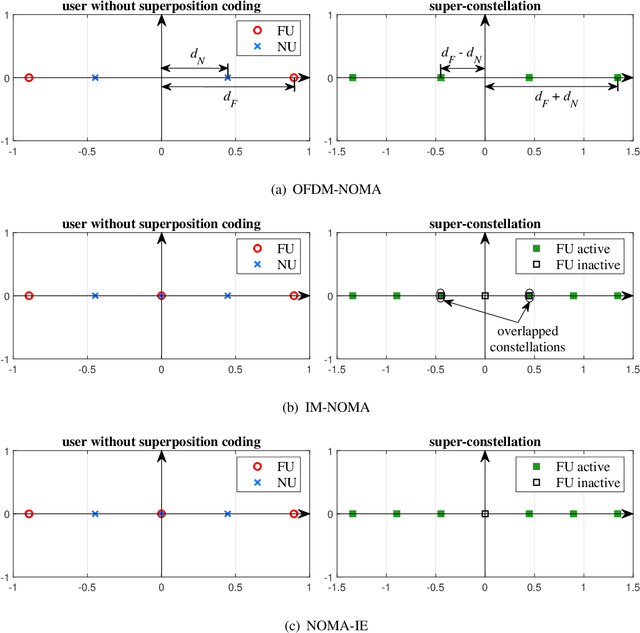
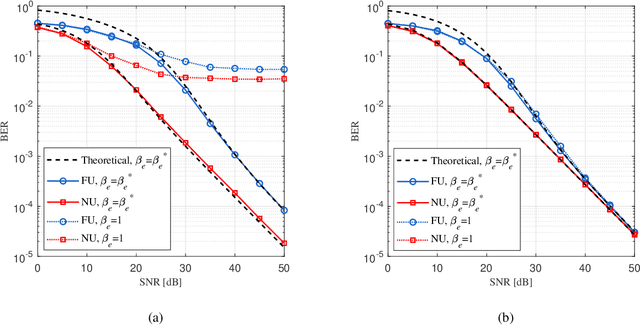
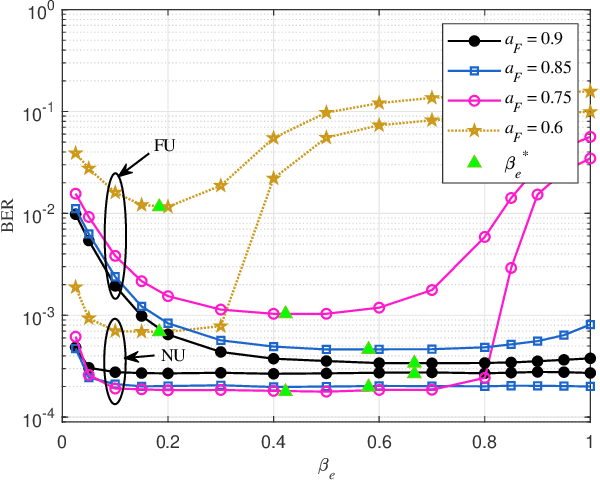
Non-orthogonal multiple access (NOMA) is capable of serving different numbers of users in the same time-frequency resource element, and this feature can be leveraged to carry additional information. In the orthogonal frequency division multiplexing (OFDM) system, we propose a novel enhanced NOMA scheme, called NOMA with informative envelope (NOMA-IE), to explore the flexibility of the envelope of NOMA signals. In this scheme, data bits are conveyed by the quantified signal envelope in addition to classic signal constellations. The subcarrier activation patterns of different users are jointly decided by the envelope former. At the receiver, successive interference cancellation (SIC) is employed, and we also introduce the envelope detection coefficient to eliminate the error floor. Theoretical expressions of spectral efficiency and energy efficiency are provided for the NOMA-IE. Then, considering the binary phase shift keying modulation, we derive the asymptotic bit error rate for the two-subcarrier OFDM subblock. Afterwards, the expressions are extended to the four-subcarrier case. The analytical results reveal that the imperfect SIC and the index error are the main factors degrading the error performance. The numerical results demonstrate the superiority of the NOMA-IE over the OFDM and OFDM-NOMA, especially in the high signal-to-noise ratio (SNR) regime.
NASA: Neural Architecture Search and Acceleration for Hardware Inspired Hybrid Networks
Oct 24, 2022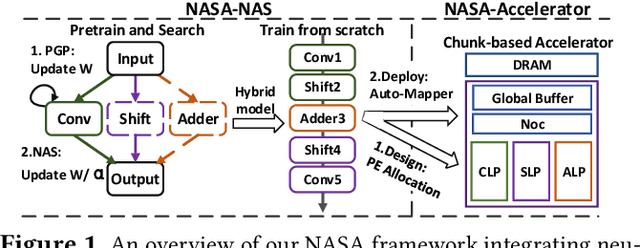
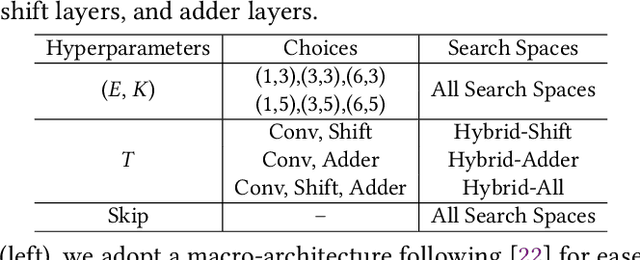
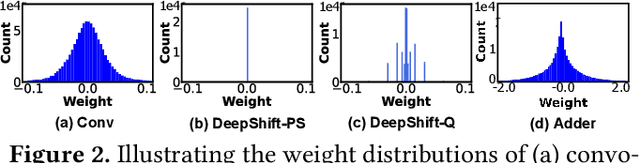
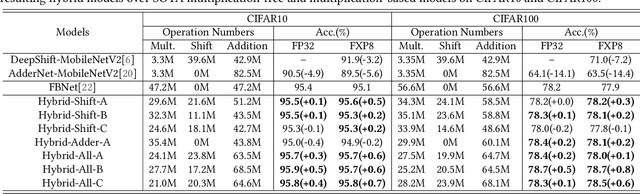
Multiplication is arguably the most cost-dominant operation in modern deep neural networks (DNNs), limiting their achievable efficiency and thus more extensive deployment in resource-constrained applications. To tackle this limitation, pioneering works have developed handcrafted multiplication-free DNNs, which require expert knowledge and time-consuming manual iteration, calling for fast development tools. To this end, we propose a Neural Architecture Search and Acceleration framework dubbed NASA, which enables automated multiplication-reduced DNN development and integrates a dedicated multiplication-reduced accelerator for boosting DNNs' achievable efficiency. Specifically, NASA adopts neural architecture search (NAS) spaces that augment the state-of-the-art one with hardware-inspired multiplication-free operators, such as shift and adder, armed with a novel progressive pretrain strategy (PGP) together with customized training recipes to automatically search for optimal multiplication-reduced DNNs; On top of that, NASA further develops a dedicated accelerator, which advocates a chunk-based template and auto-mapper dedicated for NASA-NAS resulting DNNs to better leverage their algorithmic properties for boosting hardware efficiency. Experimental results and ablation studies consistently validate the advantages of NASA's algorithm-hardware co-design framework in terms of achievable accuracy and efficiency tradeoffs. Codes are available at https://github.com/RICE-EIC/NASA.
Towards Time-Optimal Tunnel-Following for Quadrotors
Oct 07, 2021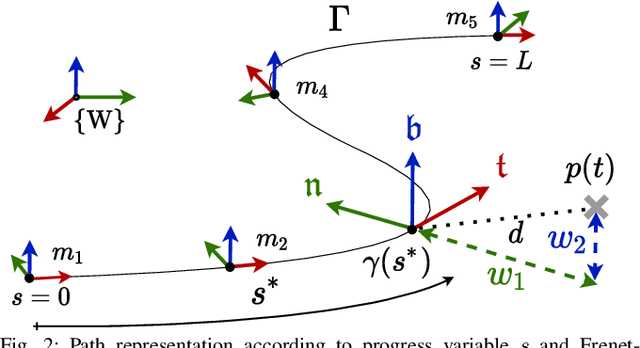
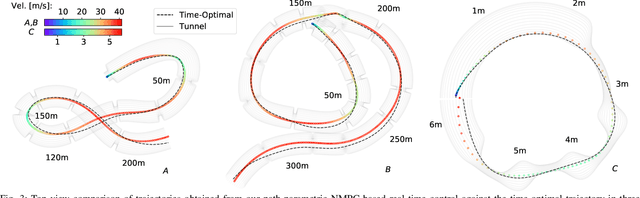
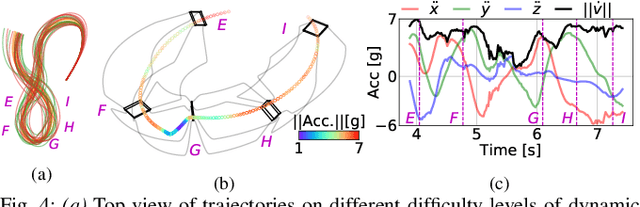
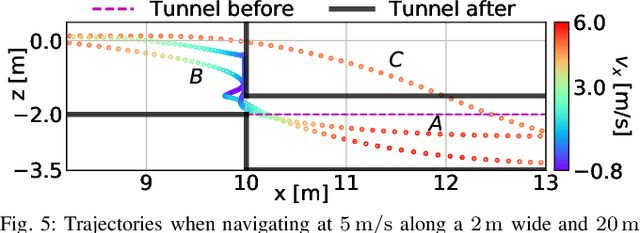
Minimum-time navigation within constrained and dynamic environments is of special relevance in robotics. Seeking time-optimality, while guaranteeing the integrity of time-varying spatial bounds, is an appealing trade-off for agile vehicles, such as quadrotors. State of the art approaches, either assume bounds to be static and generate time-optimal trajectories offline, or compromise time-optimality for constraint satisfaction. Leveraging nonlinear model predictive control and a path parametric reformulation of the quadrotor model, we present a real-time control that approximates time-optimal behavior and remains within dynamic corridors. The efficacy of the approach is evaluated according to simulated results, showing itself capable of performing extremely aggressive maneuvers as well as stop-and-go and backward motions.
Opportunities for Intelligent Reflecting Surfaces in 6G-Empowered V2X Communications
Oct 02, 2022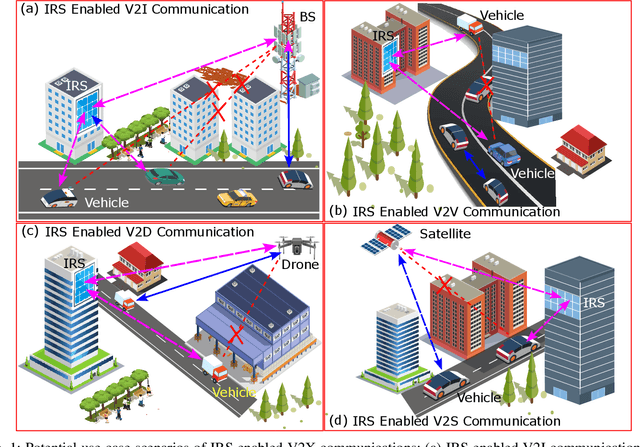
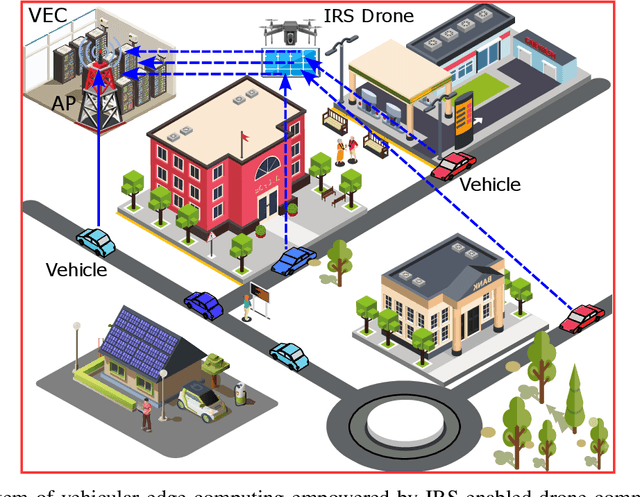
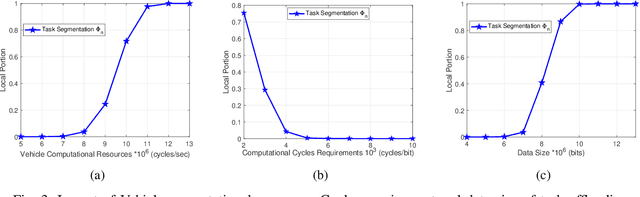
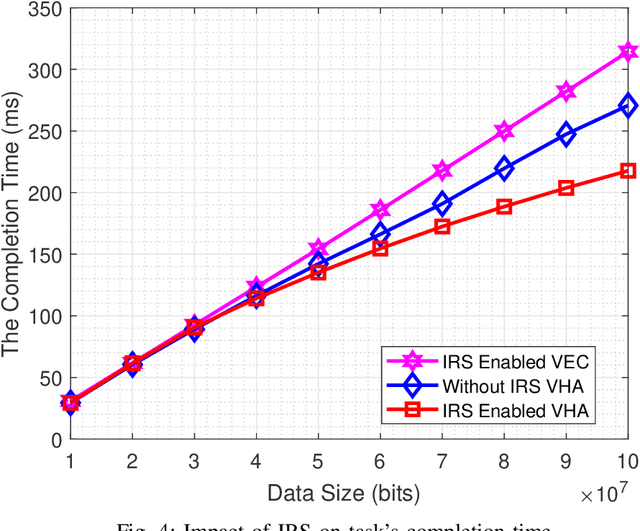
This paper first describes the introduction of 6G-empowered V2X communications and IRS technology. Then it discusses different use case scenarios of IRS enabled V2X communications and reports recent advances in the existing literature. Next, we focus our attention on the scenario of vehicular edge computing involving IRS enabled drone communications in order to reduce vehicle computational time via optimal computational and communication resource allocation. At the end, this paper highlights current challenges and discusses future perspectives of IRS enabled V2X communications in order to improve current work and spark new ideas.
SR-LIO: LiDAR-Inertial Odometry with Sweep Reconstruction
Oct 19, 2022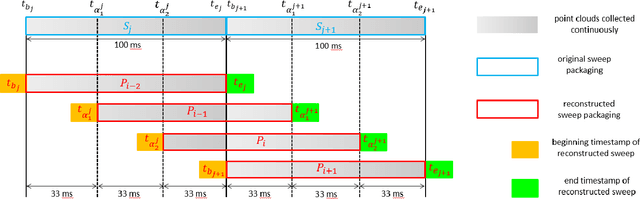
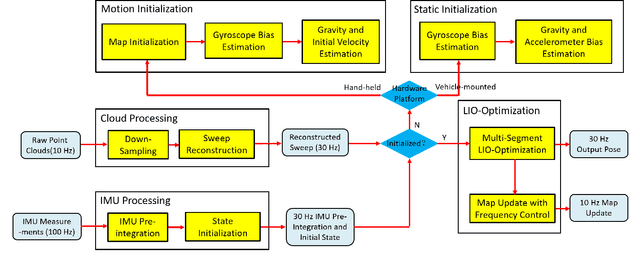
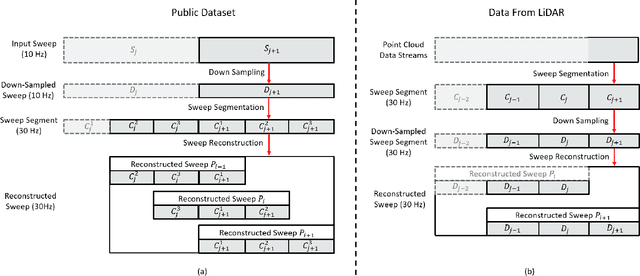
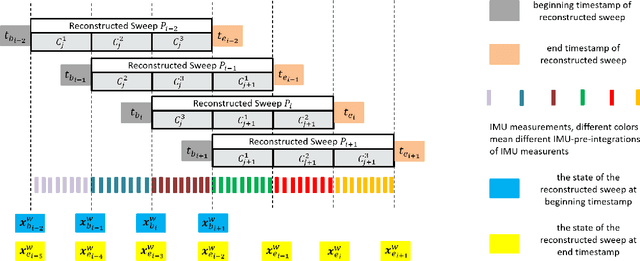
This paper proposes a novel LiDAR-inertial odometry (LIO), named SR-LIO, based on an improved bundle adjustment (BA) framework. The core of our SR-LIO is a novel sweep reconstruction method, which segments and reconstructs raw input sweeps from spinning LiDAR to obtain reconstructed sweeps with higher frequency. Such method can effectively reduce the time interval for each IMU pre-integration, reducing the IMU pre-integration error and enabling the usage of BA based LIO optimization. In order to make all the states during the period of a reconstructed sweep can be equally optimized, we further propose multi-segment joint LIO optimization, which allows the state of each sweep segment to be constrained from both LiDAR and IMU. Experimental results on three public datasets demonstrate that our SR-LIO outperforms all existing state-of-the-art methods on accuracy, and reducing the IMU pre-integration error via the proposed sweep reconstruction is very importance for the success of a BA based LIO framework. The source code of SR-LIO is publicly available for the development of the community.