 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DyCSC: Modeling the Evolutionary Process of Dynamic Networks Based on Cluster Structure
Oct 23, 2022
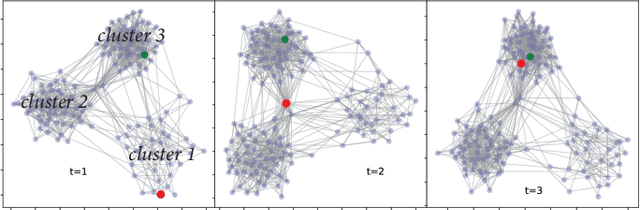
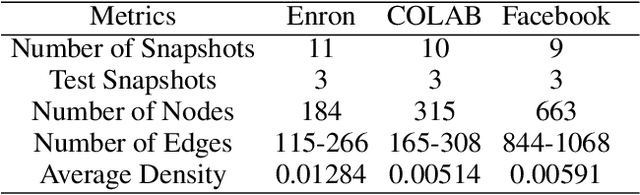
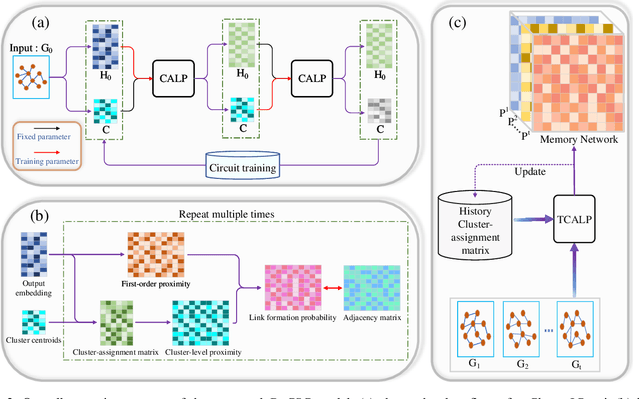
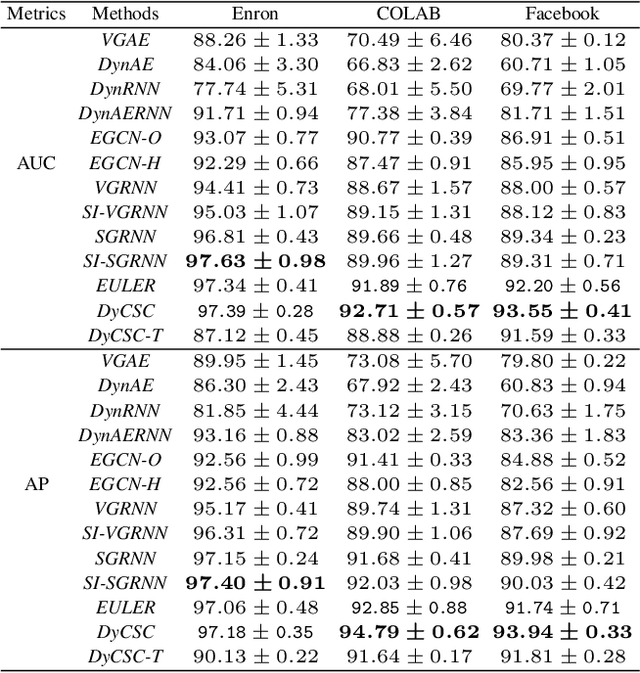
Temporal networks are an important type of network whose topological structure changes over time. Compared with methods on static networks, temporal network embedding (TNE) methods are facing three challenges: 1) it cannot describe the temporal dependence across network snapshots; 2) the node embedding in the latent space fails to indicate changes in the network topology; and 3) it cannot avoid a lot of redundant computation via parameter inheritance on a series of snapshots. To this end, we propose a novel temporal network embedding method named Dynamic Cluster Structure Constraint model (DyCSC), whose core idea is to capture the evolution of temporal networks by imposing a temporal constraint on the tendency of the nodes in the network to a given number of clusters. It not only generates low-dimensional embedding vectors for nodes but also preserves the dynamic nonlinear features of temporal networks. Experimental results on multiple realworld datasets have demonstrated the superiority of DyCSC for temporal graph embedding, as it consistently outperforms competing methods by significant margins in multiple temporal link prediction tasks. Moreover, the ablation study further validates the effectiveness of the proposed temporal constraint.
Asynchronous Actor-Critic for Multi-Agent Reinforcement Learning
Sep 20, 2022



Synchronizing decisions across multiple agents in realistic settings is problematic since it requires agents to wait for other agents to terminate and communicate about termination reliably. Ideally, agents should learn and execute asynchronously instead. Such asynchronous methods also allow temporally extended actions that can take different amounts of time based on the situation and action executed. Unfortunately, current policy gradient methods are not applicable in asynchronous settings, as they assume that agents synchronously reason about action selection at every time step. To allow asynchronous learning and decision-making, we formulate a set of asynchronous multi-agent actor-critic methods that allow agents to directly optimize asynchronous policies in three standard training paradigms: decentralized learning, centralized learning, and centralized training for decentralized execution. Empirical results (in simulation and hardware) in a variety of realistic domains demonstrate the superiority of our approaches in large multi-agent problems and validate the effectiveness of our algorithms for learning high-quality and asynchronous solutions.
AskYourDB: An end-to-end system for querying and visualizing relational databases using natural language
Oct 16, 2022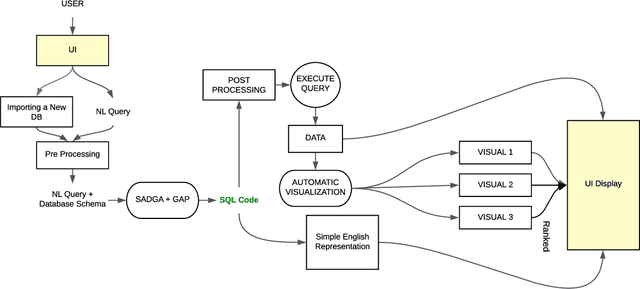
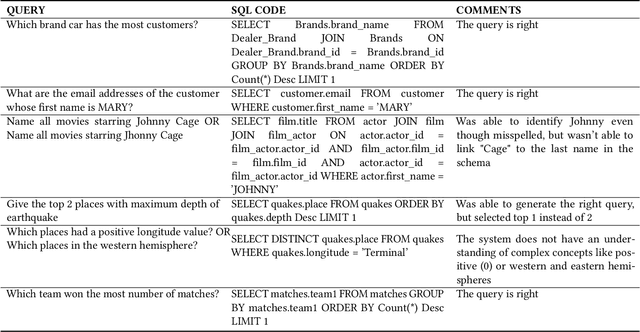
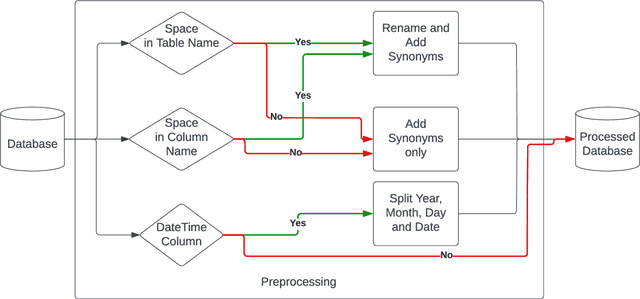
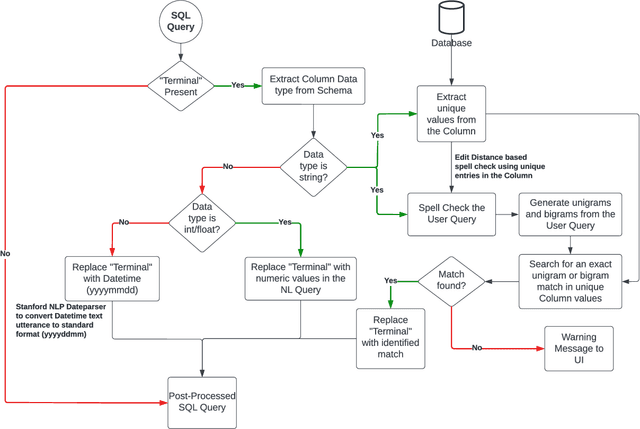
Querying databases for the right information is a time consuming and error-prone task and often requires experienced professionals for the job. Furthermore, the user needs to have some prior knowledge about the database. There have been various efforts to develop an intelligence which can help business users to query databases directly. However, there has been some successes, but very little in terms of testing and deploying those for real world users. In this paper, we propose a semantic parsing approach to address the challenge of converting complex natural language into SQL and institute a product out of it. For this purpose, we modified state-of-the-art models, by various pre and post processing steps which make the significant part when a model is deployed in production. To make the product serviceable to businesses we added an automatic visualization framework over the queried results.
Efficient Spiking Transformer Enabled By Partial Information
Oct 03, 2022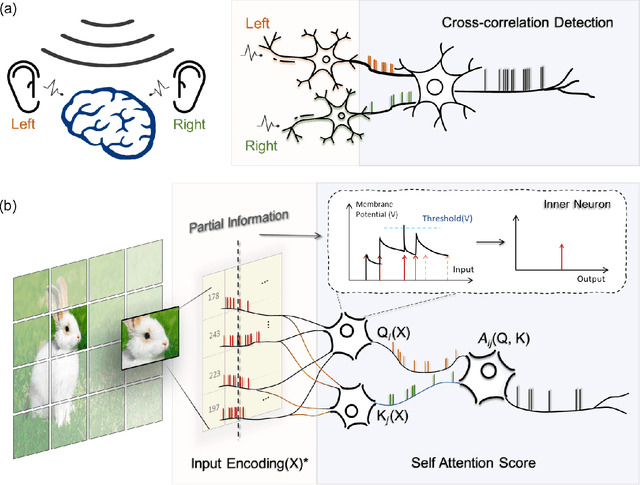
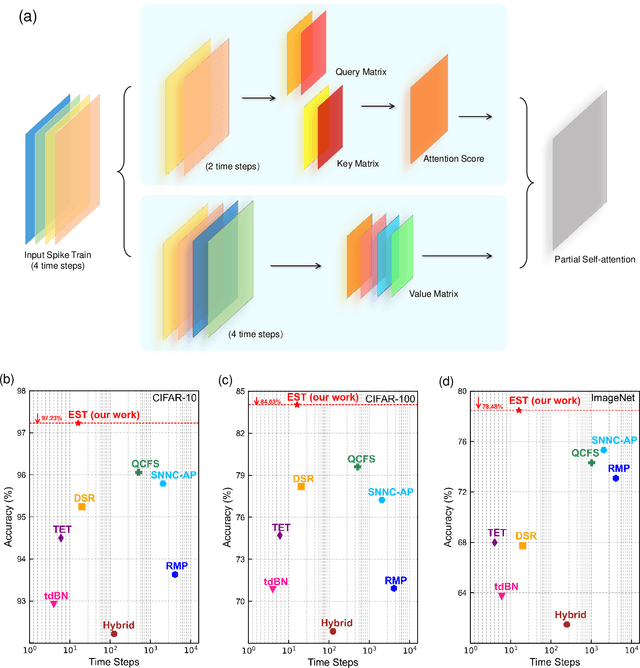
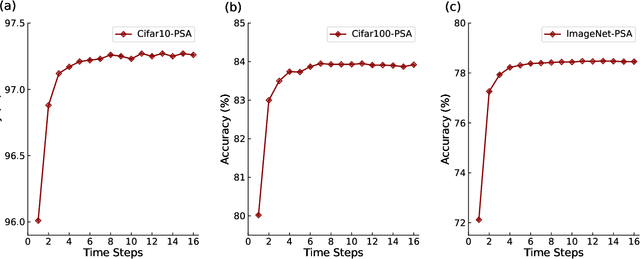
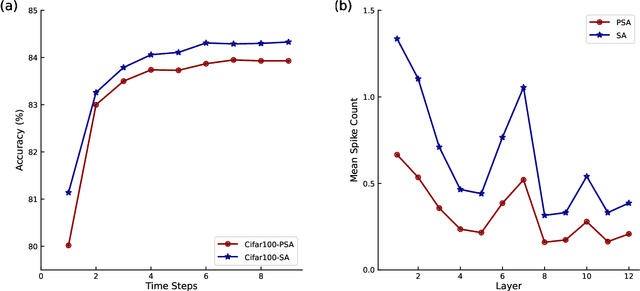
Spiking neural networks (SNNs) have received substantial attention in recent years due to their sparse and asynchronous communication nature, and thus can be deployed in neuromorphic hardware and achieve extremely high energy efficiency. However, SNNs currently can hardly realize a comparable performance to that of artificial neural networks (ANNs) because their limited scalability does not allow for large-scale networks. Especially for Transformer, as a model of ANNs that has accomplished remarkable performance in various machine learning tasks, its implementation in SNNs by conventional methods requires a large number of neurons, notably in the self-attention module. Inspired by the mechanisms in the nervous system, we propose an efficient spiking Transformer (EST) framework enabled by partial information to address the above problem. In this model, we not only implemented the self-attention module with a reasonable number of neurons, but also introduced partial-information self-attention (PSA), which utilizes only partial input signals, further reducing computational resources compared to conventional methods. The experimental results show that our EST can outperform the state-of-the-art SNN model in terms of accuracy and the number of time steps on both Cifar-10/100 and ImageNet datasets. In particular, the proposed EST model achieves 78.48% top-1 accuracy on the ImageNet dataset with only 16 time steps. In addition, our proposed PSA reduces flops by 49.8% with negligible performance loss compared to a self-attention module with full information.
Event-based Temporally Dense Optical Flow Estimation with Sequential Neural Networks
Oct 03, 2022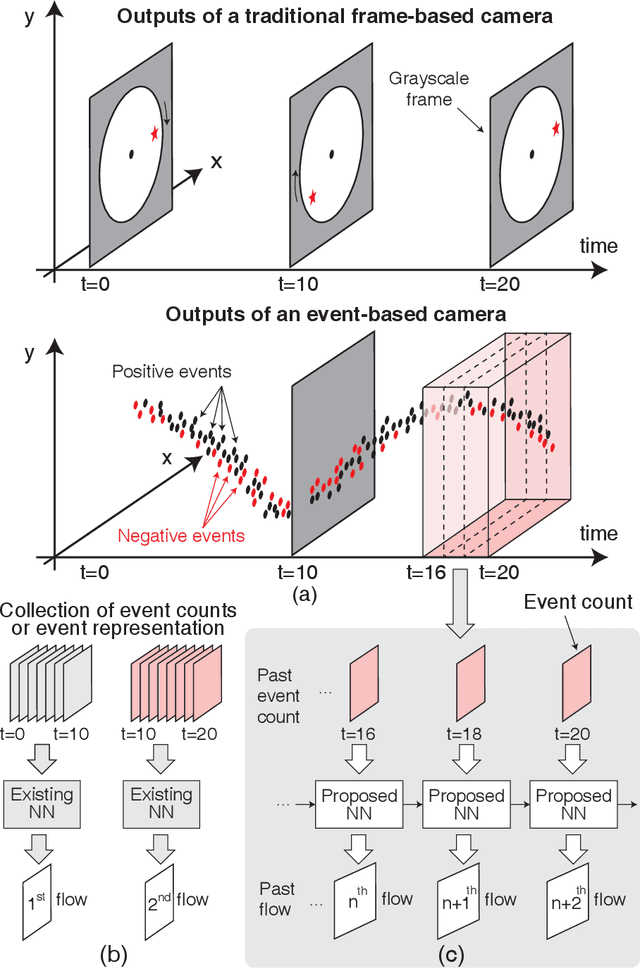
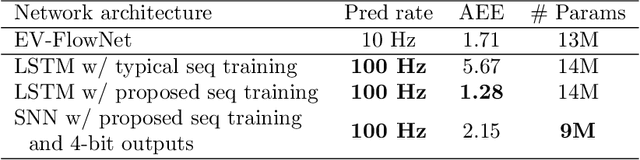
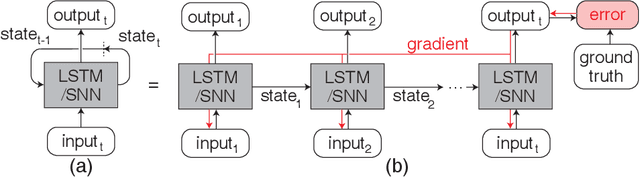
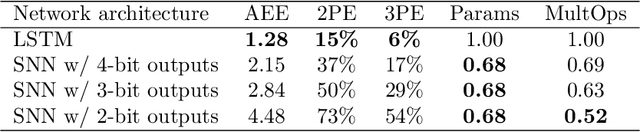
Prior works on event-based optical flow estimation have investigated several gradient-based learning methods to train neural networks for predicting optical flow. However, they do not utilize the fast data rate of event data streams and rely on a spatio-temporal representation constructed from a collection of events over a fixed period of time (often between two grayscale frames). As a result, optical flow is only evaluated at a frequency much lower than the rate data is produced by an event-based camera, leading to a temporally sparse optical flow estimation. To predict temporally dense optical flow, we cast the problem as a sequential learning task and propose a training methodology to train sequential networks for continuous prediction on an event stream. We propose two types of networks: one focused on performance and another focused on compute efficiency. We first train long-short term memory networks (LSTMs) on the DSEC dataset and demonstrated 10x temporally dense optical flow estimation over existing flow estimation approaches. The additional benefit of having a memory to draw long temporal correlations back in time results in a 19.7% improvement in flow prediction accuracy of LSTMs over similar networks with no memory elements. We subsequently show that the inherent recurrence of spiking neural networks (SNNs) enables them to learn and estimate temporally dense optical flow with 31.8% lesser parameters than LSTM, but with a slightly increased error. This demonstrates potential for energy-efficient implementation of fast optical flow prediction using SNNs.
How Much Does It Cost to Train a Machine Learning Model over Distributed Data Sources?
Sep 15, 2022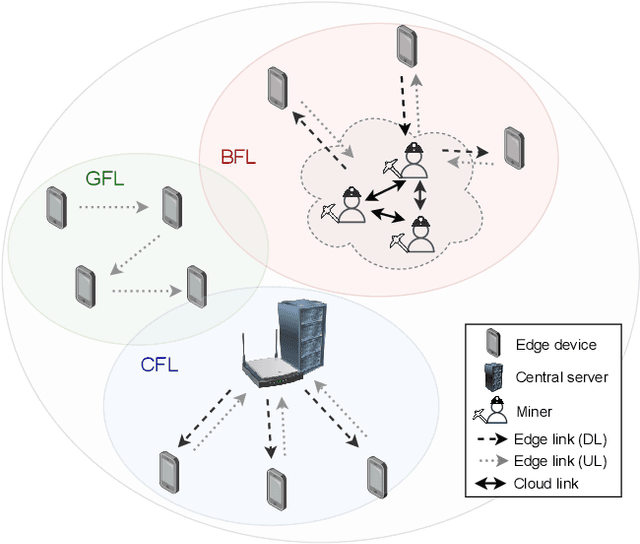
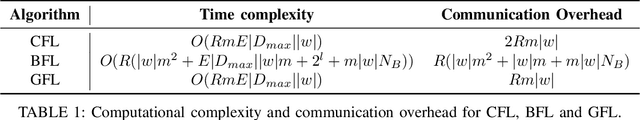
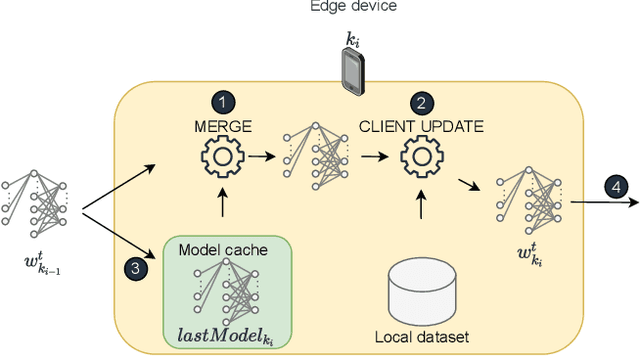
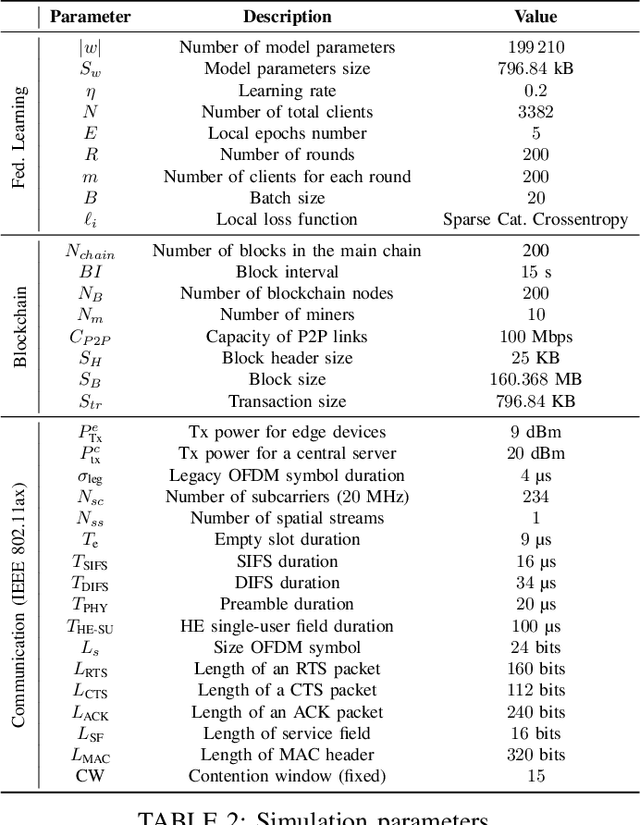
Federated learning (FL) is one of the most appealing alternatives to the standard centralized learning paradigm, allowing heterogeneous set of devices to train a machine learning model without sharing their raw data. However, FL requires a central server to coordinate the learning process, thus introducing potential scalability and security issues. In the literature, server-less FL approaches like gossip federated learning (GFL) and blockchain-enabled federated learning (BFL) have been proposed to mitigate these issues. In this work, we propose a complete overview of these three techniques proposing a comparison according to an integral set of performance indicators, including model accuracy, time complexity, communication overhead, convergence time and energy consumption. An extensive simulation campaign permits to draw a quantitative analysis. In particular, GFL is able to save the 18% of training time, the 68% of energy and the 51% of data to be shared with respect to the CFL solution, but it is not able to reach the level of accuracy of CFL. On the other hand, BFL represents a viable solution for implementing decentralized learning with a higher level of security, at the cost of an extra energy usage and data sharing. Finally, we identify open issues on the two decentralized federated learning implementations and provide insights on potential extensions and possible research directions on this new research field.
A Learning-Based Estimation and Control Framework for Contact-Intensive Tight-Tolerance Tasks
Oct 11, 2022

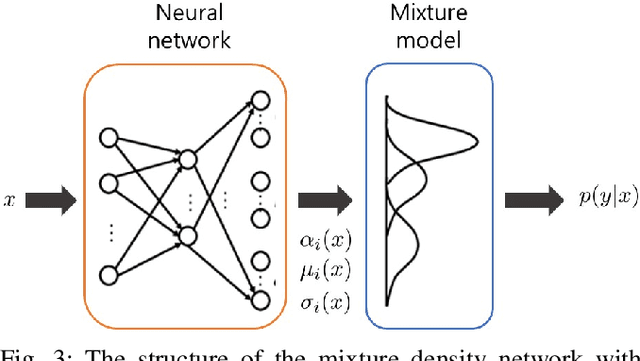
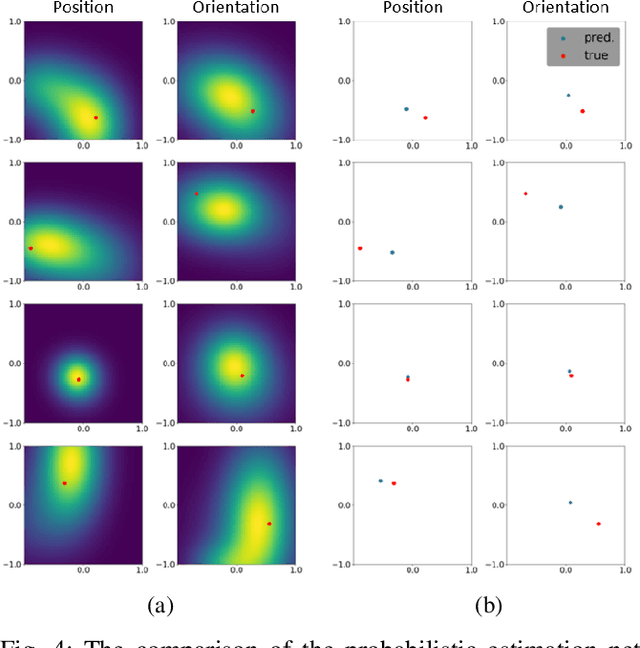
We propose a novel data-driven estimation and control framework for contact-rich tight tolerance tasks, which estimates the pose of the object precisely using data-driven methods and compensates for the remaining error via reinforcement learning (RL). First, the sequential particle filter estimator updates with the mixture density network (MDN), which is to represent the general non-injective conditional probability and thus is suitable for finding out the pose from the measurements including relatively low-dimensional contact wrench sensing. We further develop the RL-based fastening controller that adapts to the remaining error by optimizing the admittance gain to complete the task. The proposed framework is evaluated using an accurate real-time simulator on the bolting task and successfully transferred to an experimental environment.
A Robust and Explainable Data-Driven Anomaly Detection Approach For Power Electronics
Sep 23, 2022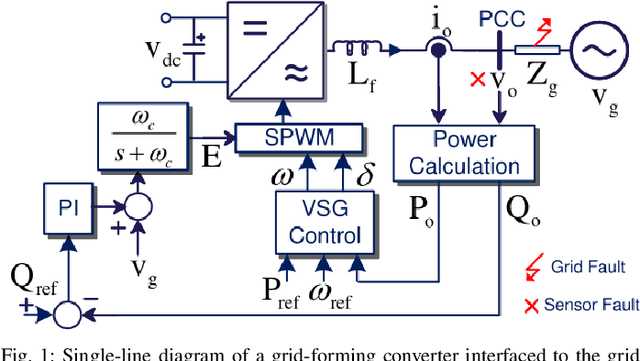
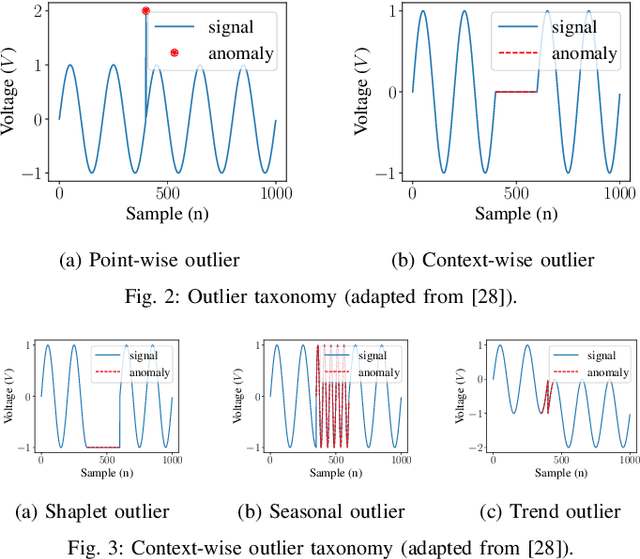
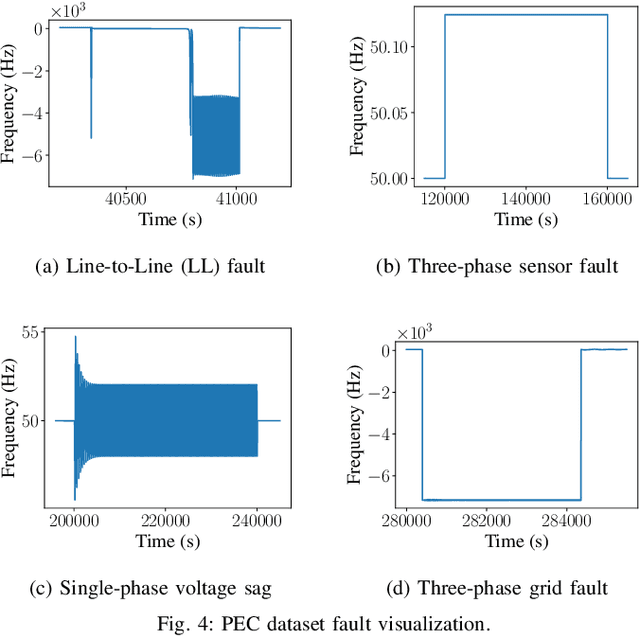
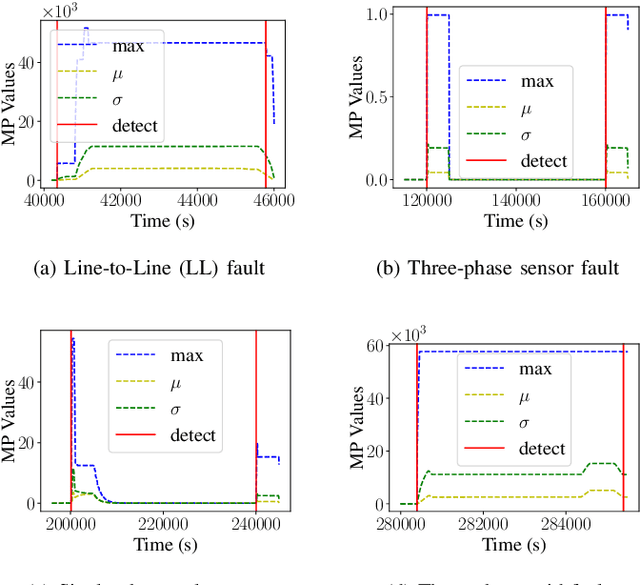
Timely and accurate detection of anomalies in power electronics is becoming increasingly critical for maintaining complex production systems. Robust and explainable strategies help decrease system downtime and preempt or mitigate infrastructure cyberattacks. This work begins by explaining the types of uncertainty present in current datasets and machine learning algorithm outputs. Three techniques for combating these uncertainties are then introduced and analyzed. We further present two anomaly detection and classification approaches, namely the Matrix Profile algorithm and anomaly transformer, which are applied in the context of a power electronic converter dataset. Specifically, the Matrix Profile algorithm is shown to be well suited as a generalizable approach for detecting real-time anomalies in streaming time-series data. The STUMPY python library implementation of the iterative Matrix Profile is used for the creation of the detector. A series of custom filters is created and added to the detector to tune its sensitivity, recall, and detection accuracy. Our numerical results show that, with simple parameter tuning, the detector provides high accuracy and performance in a variety of fault scenarios.
SkiM: Skipping Memory LSTM for Low-Latency Real-Time Continuous Speech Separation
Feb 10, 2022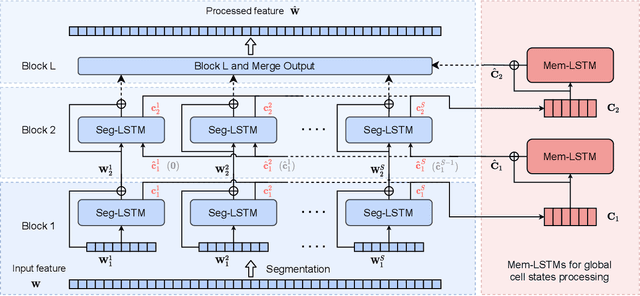
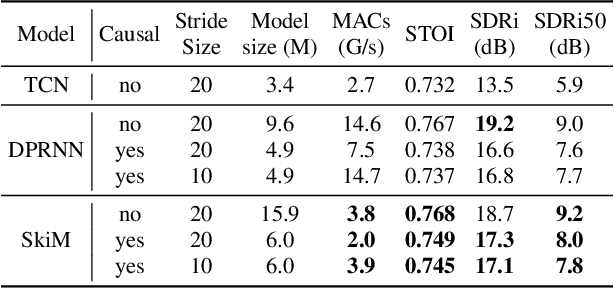
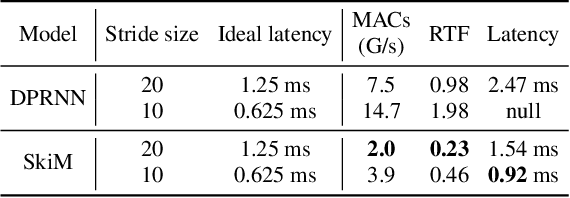
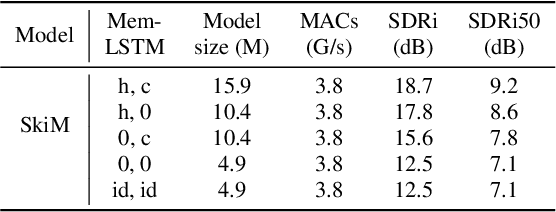
Continuous speech separation for meeting pre-processing has recently become a focused research topic. Compared to the data in utterance-level speech separation, the meeting-style audio stream lasts longer, has an uncertain number of speakers. We adopt the time-domain speech separation method and the recently proposed Graph-PIT to build a super low-latency online speech separation model, which is very important for the real application. The low-latency time-domain encoder with a small stride leads to an extremely long feature sequence. We proposed a simple yet efficient model named Skipping Memory (SkiM) for the long sequence modeling. Experimental results show that SkiM achieves on par or even better separation performance than DPRNN. Meanwhile, the computational cost of SkiM is reduced by 75% compared to DPRNN. The strong long sequence modeling capability and low computational cost make SkiM a suitable model for online CSS applications. Our fastest real-time model gets 17.1 dB signal-to-distortion (SDR) improvement with less than 1-millisecond latency in the simulated meeting-style evaluation.
Online Search-based Collision-inclusive Motion Planning and Control for Impact-resilient Mobile Robots
Oct 05, 2022

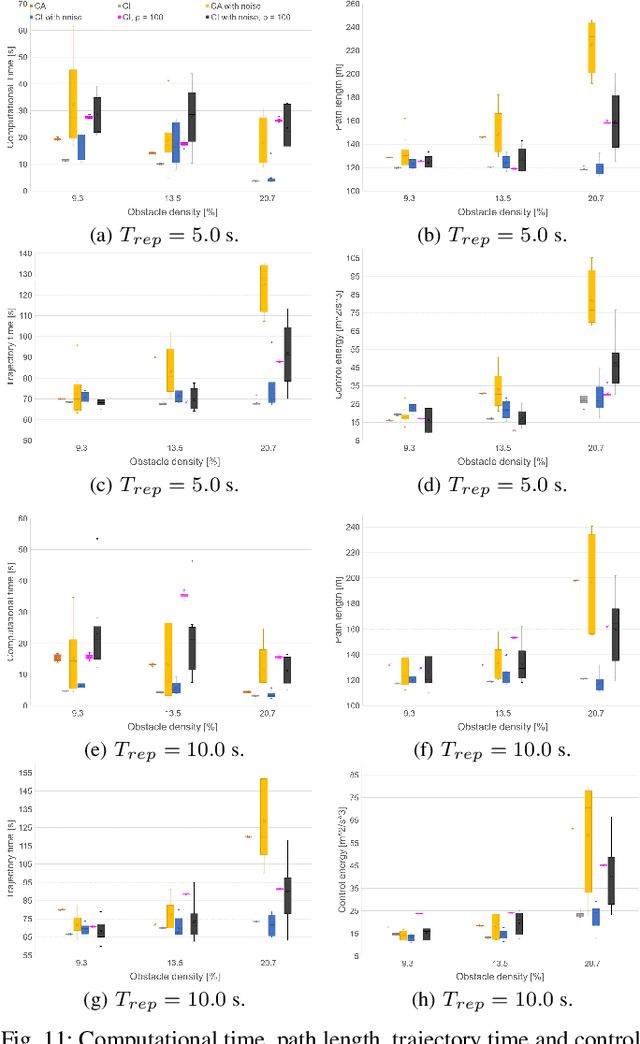
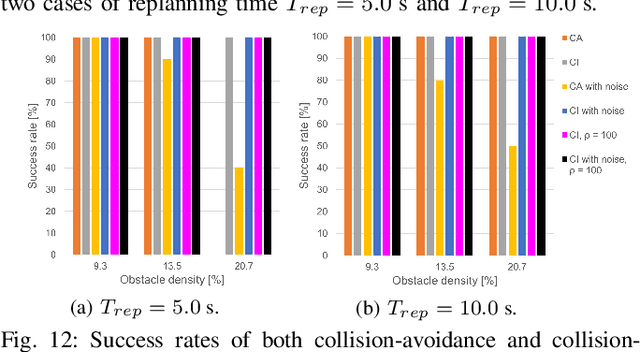
This paper focuses on the emerging paradigm shift of collision-inclusive motion planning and control for impact-resilient mobile robots, and develops a unified hierarchical framework for navigation in unknown and partially-observable cluttered spaces. At the lower-level, we develop a deformation recovery control and trajectory replanning strategy that handles collisions that may occur at run-time, locally. The low-level system actively detects collisions (via embedded Hall effect sensors on a mobile robot built in-house), enables the robot to recover from them, and locally adjusts the post-impact trajectory. Then, at the higher-level, we propose a search-based planning algorithm to determine how to best utilize potential collisions to improve certain metrics, such as control energy and computational time. Our method builds upon A* with jump points. We generate a novel heuristic function, and a collision checking and adjustment technique, thus making the A* algorithm converge faster to reach the goal by exploiting and utilizing possible collisions. The overall hierarchical framework generated by combining the global A* algorithm and the local deformation recovery and replanning strategy, as well as individual components of this framework, are tested extensively both in simulation and experimentally. An ablation study draws links to related state-of-the-art search-based collision-avoidance planners (for the overall framework), as well as search-based collision-avoidance and sampling-based collision-inclusive global planners (for the higher level). Results demonstrate our method's efficacy for collision-inclusive motion planning and control in unknown environments with isolated obstacles for a class of impact-resilient robots operating in 2D.