 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Otsu based Differential Evolution Method for Image Segmentation
Oct 18, 2022




This paper proposes an OTSU based differential evolution method for satellite image segmentation and compares it with four other methods such as Modified Artificial Bee Colony Optimizer (MABC), Artificial Bee Colony (ABC), Genetic Algorithm (GA), and Particle Swarm Optimization (PSO) using the objective function proposed by Otsu for optimal multilevel thresholding. The experiments conducted and their results illustrate that our proposed DE and OTSU algorithm segmentation can effectively and precisely segment the input image, close to results obtained by the other methods. In the proposed DE and OTSU algorithm, instead of passing the fitness function variables, the entire image is passed as an input to the DE algorithm after obtaining the threshold values for the input number of levels in the OTSU algorithm. The image segmentation results are obtained after learning about the image instead of learning about the fitness variables. In comparison to other segmentation methods examined, the proposed DE and OTSU algorithm yields promising results with minimized computational time compared to some algorithms.
Data-Model-Circuit Tri-Design for Ultra-Light Video Intelligence on Edge Devices
Oct 18, 2022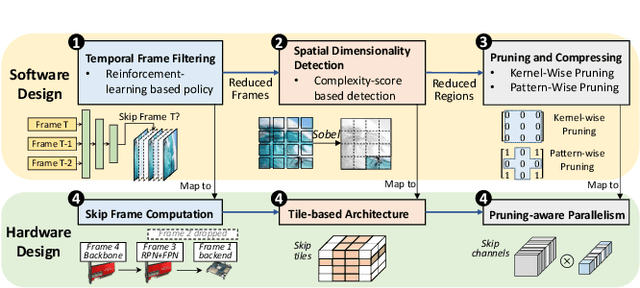
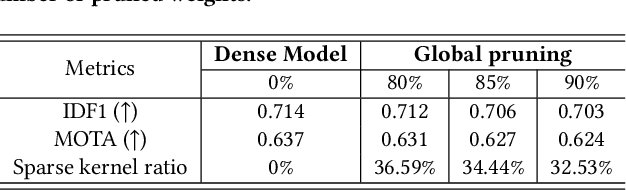


In this paper, we propose a data-model-hardware tri-design framework for high-throughput, low-cost, and high-accuracy multi-object tracking (MOT) on High-Definition (HD) video stream. First, to enable ultra-light video intelligence, we propose temporal frame-filtering and spatial saliency-focusing approaches to reduce the complexity of massive video data. Second, we exploit structure-aware weight sparsity to design a hardware-friendly model compression method. Third, assisted with data and model complexity reduction, we propose a sparsity-aware, scalable, and low-power accelerator design, aiming to deliver real-time performance with high energy efficiency. Different from existing works, we make a solid step towards the synergized software/hardware co-optimization for realistic MOT model implementation. Compared to the state-of-the-art MOT baseline, our tri-design approach can achieve 12.5x latency reduction, 20.9x effective frame rate improvement, 5.83x lower power, and 9.78x better energy efficiency, without much accuracy drop.
Least-squares methods for nonnegative matrix factorization over rational functions
Sep 26, 2022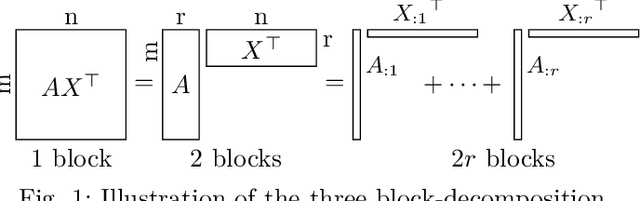
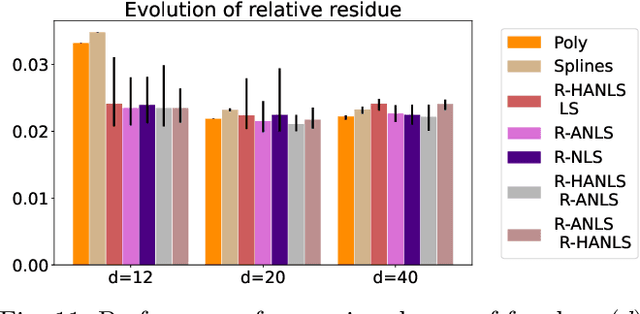
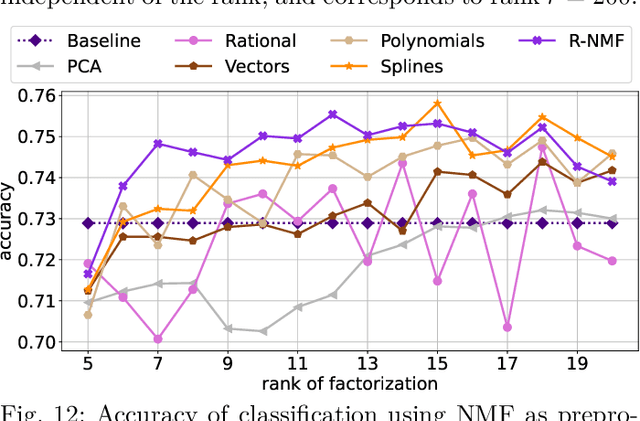
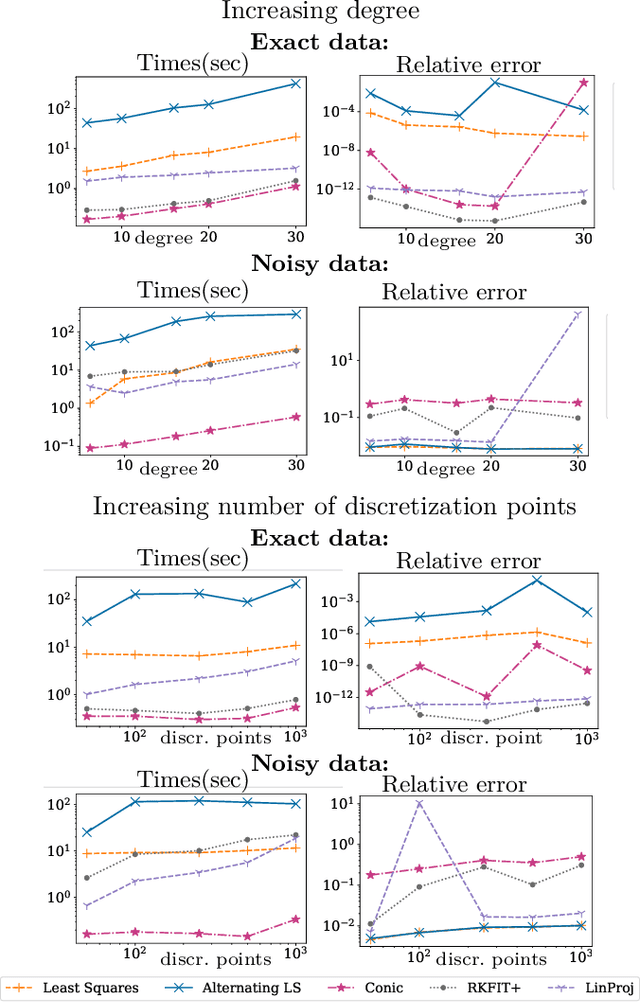
Nonnegative Matrix Factorization (NMF) models are widely used to recover linearly mixed nonnegative data. When the data is made of samplings of continuous signals, the factors in NMF can be constrained to be samples of nonnegative rational functions, which allow fairly general models; this is referred to as NMF using rational functions (R-NMF). We first show that, under mild assumptions, R-NMF has an essentially unique factorization unlike NMF, which is crucial in applications where ground-truth factors need to be recovered such as blind source separation problems. Then we present different approaches to solve R-NMF: the R-HANLS, R-ANLS and R-NLS methods. From our tests, no method significantly outperforms the others, and a trade-off should be done between time and accuracy. Indeed, R-HANLS is fast and accurate for large problems, while R-ANLS is more accurate, but also more resources demanding, both in time and memory. R-NLS is very accurate but only for small problems. Moreover, we show that R-NMF outperforms NMF in various tasks including the recovery of semi-synthetic continuous signals, and a classification problem of real hyperspectral signals.
Temporal Analysis on Topics Using Word2Vec
Sep 23, 2022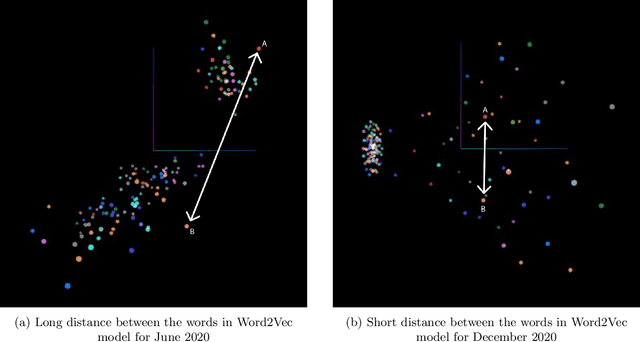

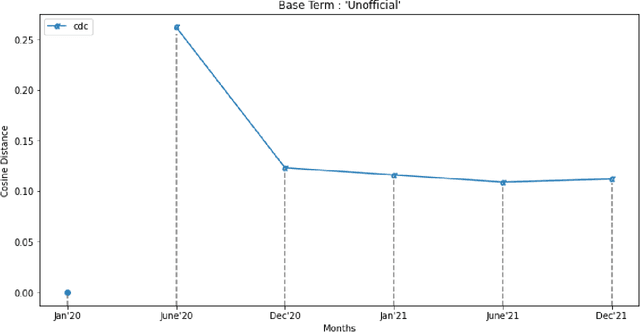
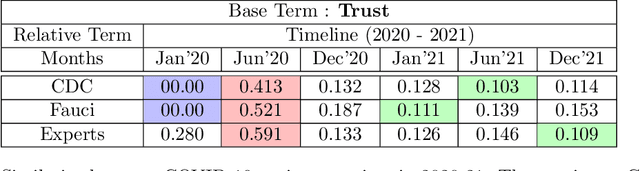
The present study proposes a novel method of trend detection and visualization - more specifically, modeling the change in a topic over time. Where current models used for the identification and visualization of trends only convey the popularity of a singular word based on stochastic counting of usage, the approach in the present study illustrates the popularity and direction that a topic is moving in. The direction in this case is a distinct subtopic within the selected corpus. Such trends are generated by modeling the movement of a topic by using k-means clustering and cosine similarity to group the distances between clusters over time. In a convergent scenario, it can be inferred that the topics as a whole are meshing (tokens between topics, becoming interchangeable). On the contrary, a divergent scenario would imply that each topics' respective tokens would not be found in the same context (the words are increasingly different to each other). The methodology was tested on a group of articles from various media houses present in the 20 Newsgroups dataset.
SECOE: Alleviating Sensors Failure in Machine Learning-Coupled IoT Systems
Oct 05, 2022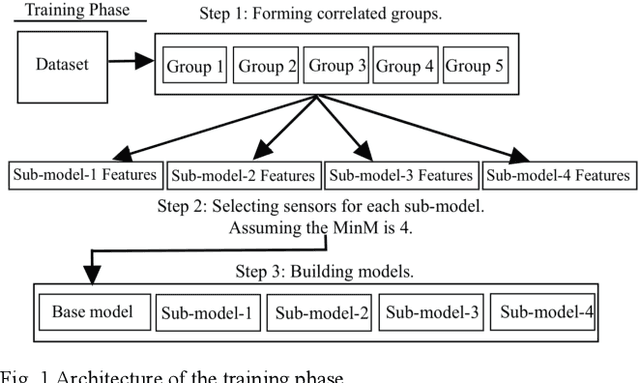
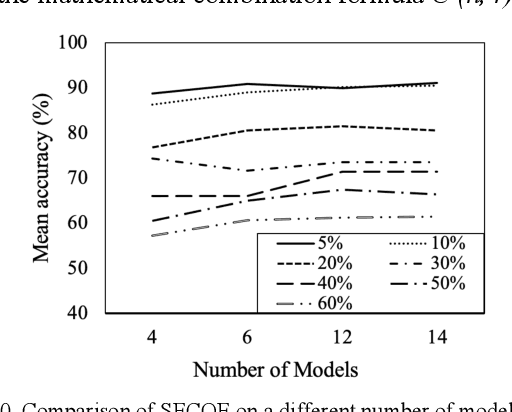
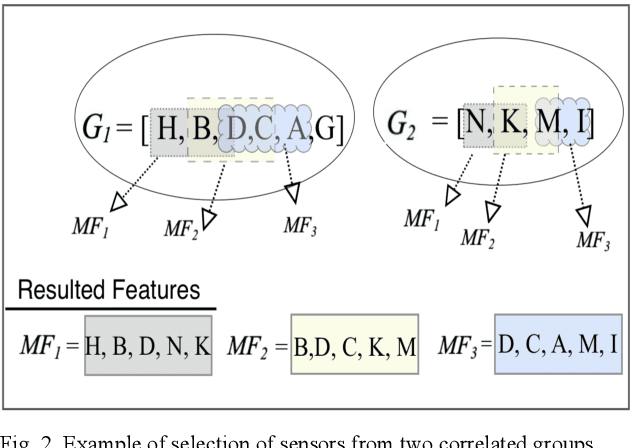
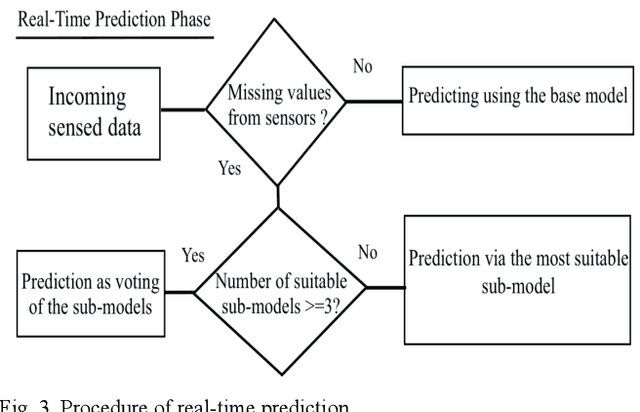
Machine learning (ML) applications continue to revolutionize many domains. In recent years, there has been considerable research interest in building novel ML applications for a variety of Internet of Things (IoT) domains, such as precision agriculture, smart cities, and smart manufacturing. IoT domains are characterized by continuous streams of data originating from diverse, geographically distributed sensors, and they often require a real-time or semi-real-time response. IoT characteristics pose several fundamental challenges to designing and implementing effective ML applications. Sensor/network failures that result in data stream interruptions is one such challenge. Unfortunately, the performance of many ML applications quickly degrades when faced with data incompleteness. Current techniques to handle data incompleteness are based upon data imputation ( i.e., they try to fill-in missing data). Unfortunately, these techniques may fail, especially when multiple sensors' data streams become concurrently unavailable (due to simultaneous sensor failures). With the aim of building robust IoT-coupled ML applications, this paper proposes SECOE, a unique, proactive approach for alleviating potentially simultaneous sensor failures. The fundamental idea behind SECOE is to create a carefully chosen ensemble of ML models in which each model is trained assuming a set of failed sensors (i.e., the training set omits corresponding values). SECOE includes a novel technique to minimize the number of models in the ensemble by harnessing the correlations among sensors. We demonstrate the efficacy of the SECOE approach through a series of experiments involving three distinct datasets. The experimental findings reveal that SECOE effectively preserves prediction accuracy in the presence of sensor failures.
Exact conservation laws for neural network integrators of dynamical systems
Sep 23, 2022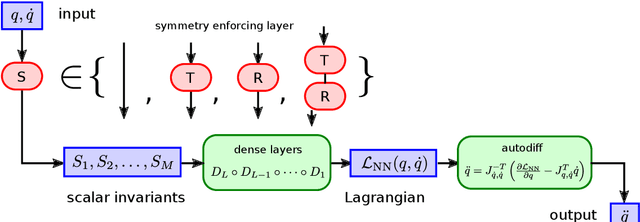

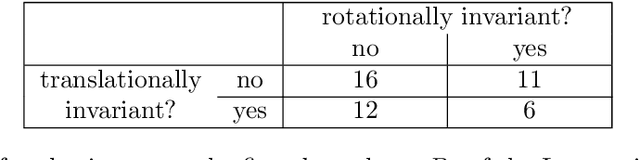
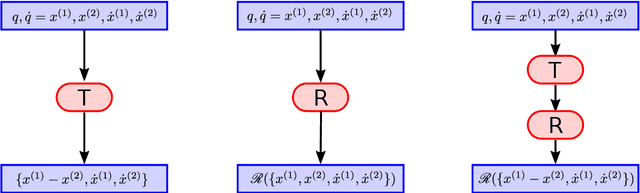
The solution of time dependent differential equations with neural networks has attracted a lot of attention recently. The central idea is to learn the laws that govern the evolution of the solution from data, which might be polluted with random noise. However, in contrast to other machine learning applications, usually a lot is known about the system at hand. For example, for many dynamical systems physical quantities such as energy or (angular) momentum are exactly conserved. Hence, the neural network has to learn these conservation laws from data and they will only be satisfied approximately due to finite training time and random noise. In this paper we present an alternative approach which uses Noether's Theorem to inherently incorporate conservation laws into the architecture of the neural network. We demonstrate that this leads to better predictions for three model systems: the motion of a non-relativistic particle in a three-dimensional Newtonian gravitational potential, the motion of a massive relativistic particle in the Schwarzschild metric and a system of two interacting particles in four dimensions.
Deep Reinforcement Learning for Task Offloading in UAV-Aided Smart Farm Networks
Sep 15, 2022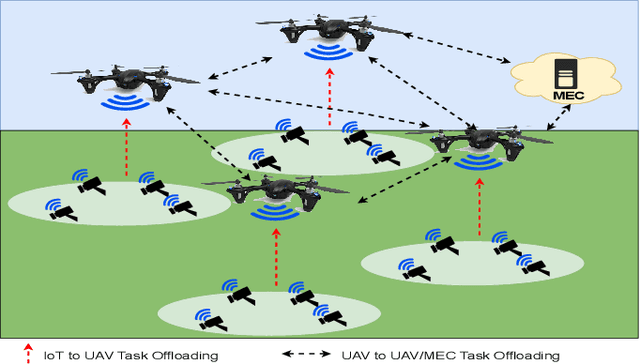
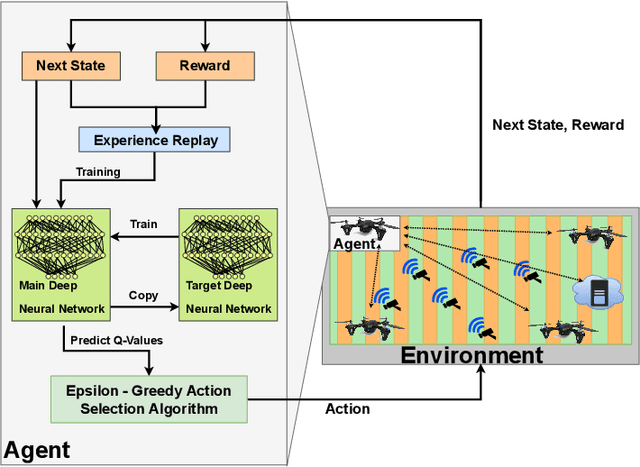
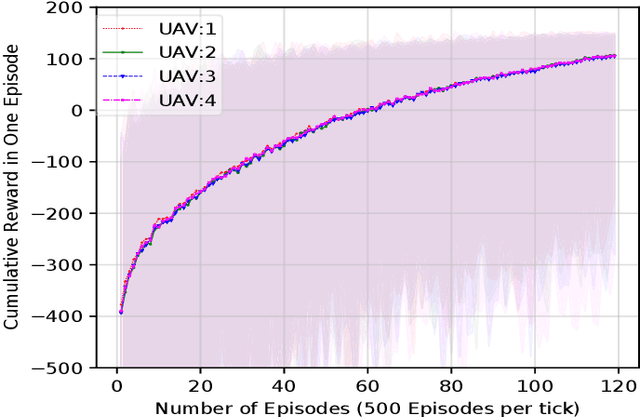
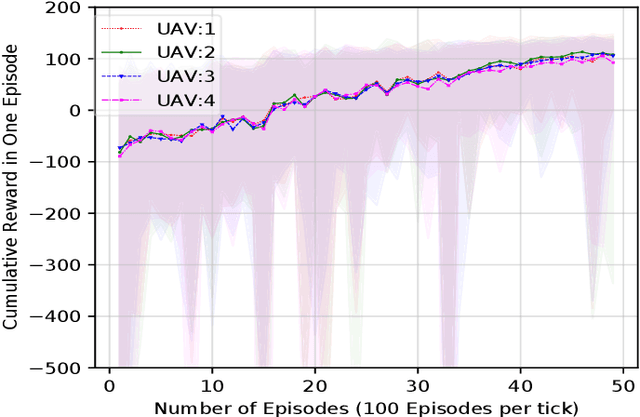
The fifth and sixth generations of wireless communication networks are enabling tools such as internet of things devices, unmanned aerial vehicles (UAVs), and artificial intelligence, to improve the agricultural landscape using a network of devices to automatically monitor farmlands. Surveying a large area requires performing a lot of image classification tasks within a specific period of time in order to prevent damage to the farm in case of an incident, such as fire or flood. UAVs have limited energy and computing power, and may not be able to perform all of the intense image classification tasks locally and within an appropriate amount of time. Hence, it is assumed that the UAVs are able to partially offload their workload to nearby multi-access edge computing devices. The UAVs need a decision-making algorithm that will decide where the tasks will be performed, while also considering the time constraints and energy level of the other UAVs in the network. In this paper, we introduce a Deep Q-Learning (DQL) approach to solve this multi-objective problem. The proposed method is compared with Q-Learning and three heuristic baselines, and the simulation results show that our proposed DQL-based method achieves comparable results when it comes to the UAVs' remaining battery levels and percentage of deadline violations. In addition, our method is able to reach convergence 13 times faster than Q-Learning.
SkiM: Skipping Memory LSTM for Low-Latency Real-Time Continuous Speech Separation
Feb 10, 2022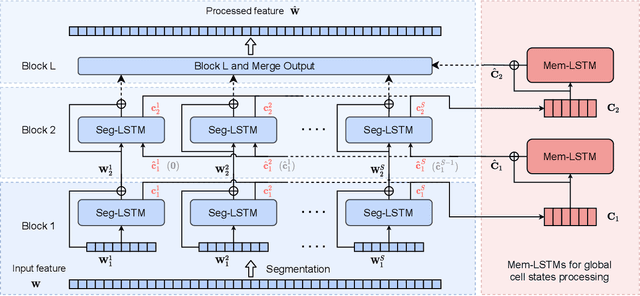
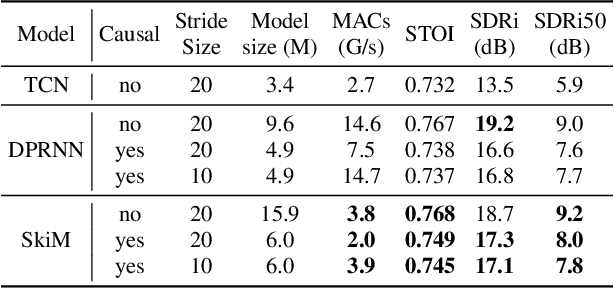
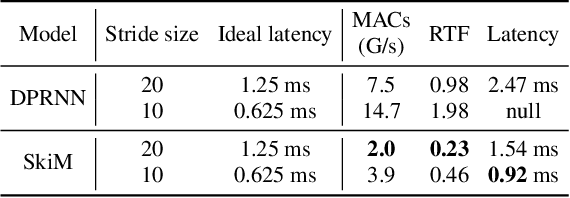
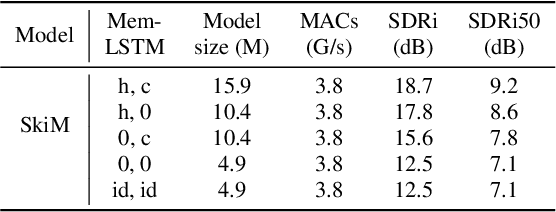
Continuous speech separation for meeting pre-processing has recently become a focused research topic. Compared to the data in utterance-level speech separation, the meeting-style audio stream lasts longer, has an uncertain number of speakers. We adopt the time-domain speech separation method and the recently proposed Graph-PIT to build a super low-latency online speech separation model, which is very important for the real application. The low-latency time-domain encoder with a small stride leads to an extremely long feature sequence. We proposed a simple yet efficient model named Skipping Memory (SkiM) for the long sequence modeling. Experimental results show that SkiM achieves on par or even better separation performance than DPRNN. Meanwhile, the computational cost of SkiM is reduced by 75% compared to DPRNN. The strong long sequence modeling capability and low computational cost make SkiM a suitable model for online CSS applications. Our fastest real-time model gets 17.1 dB signal-to-distortion (SDR) improvement with less than 1-millisecond latency in the simulated meeting-style evaluation.
Searching for Better Database Queries in the Outputs of Semantic Parsers
Oct 13, 2022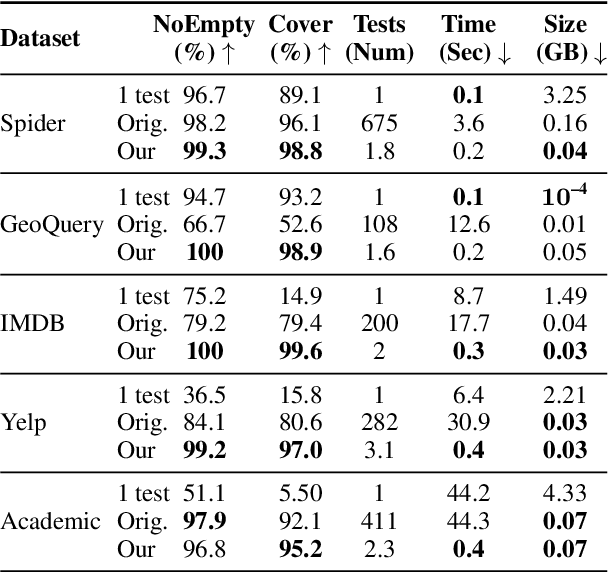
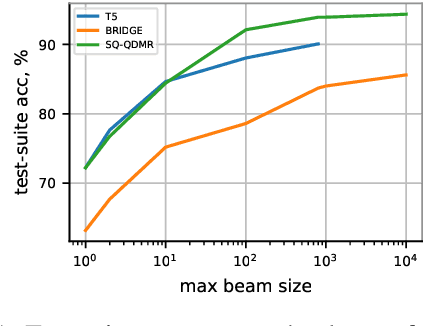
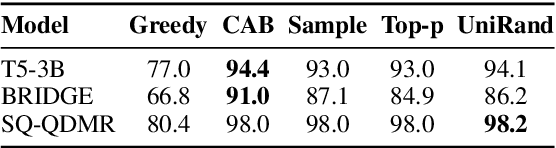
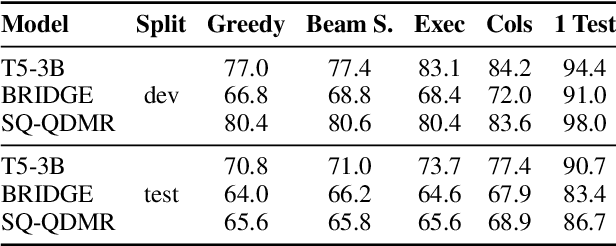
The task of generating a database query from a question in natural language suffers from ambiguity and insufficiently precise description of the goal. The problem is amplified when the system needs to generalize to databases unseen at training. In this paper, we consider the case when, at the test time, the system has access to an external criterion that evaluates the generated queries. The criterion can vary from checking that a query executes without errors to verifying the query on a set of tests. In this setting, we augment neural autoregressive models with a search algorithm that looks for a query satisfying the criterion. We apply our approach to the state-of-the-art semantic parsers and report that it allows us to find many queries passing all the tests on different datasets.
Asynchronous Actor-Critic for Multi-Agent Reinforcement Learning
Sep 20, 2022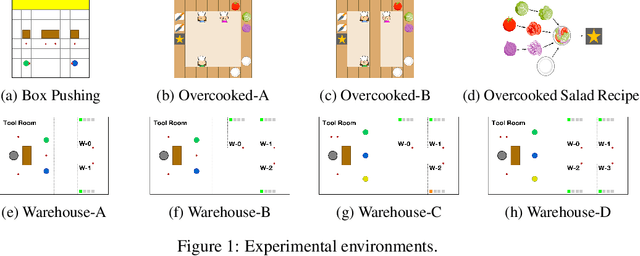



Synchronizing decisions across multiple agents in realistic settings is problematic since it requires agents to wait for other agents to terminate and communicate about termination reliably. Ideally, agents should learn and execute asynchronously instead. Such asynchronous methods also allow temporally extended actions that can take different amounts of time based on the situation and action executed. Unfortunately, current policy gradient methods are not applicable in asynchronous settings, as they assume that agents synchronously reason about action selection at every time step. To allow asynchronous learning and decision-making, we formulate a set of asynchronous multi-agent actor-critic methods that allow agents to directly optimize asynchronous policies in three standard training paradigms: decentralized learning, centralized learning, and centralized training for decentralized execution. Empirical results (in simulation and hardware) in a variety of realistic domains demonstrate the superiority of our approaches in large multi-agent problems and validate the effectiveness of our algorithms for learning high-quality and asynchronous solutions.