 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning for Power Control in Next-Generation WiFi Network Systems
Nov 02, 2022
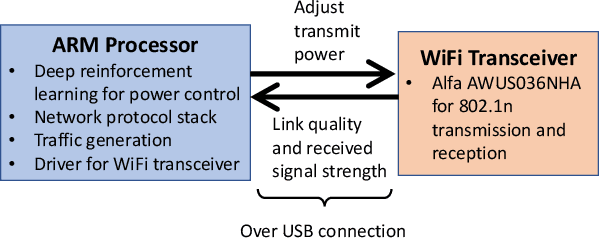
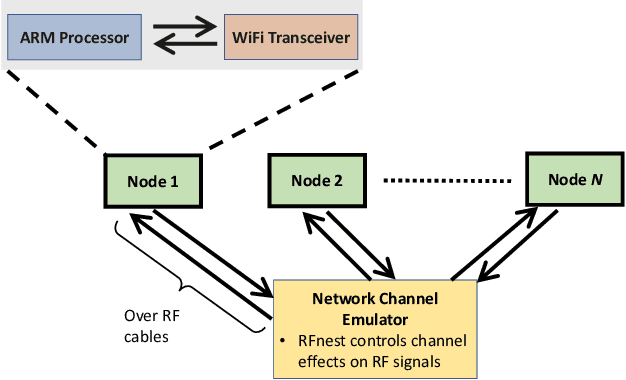
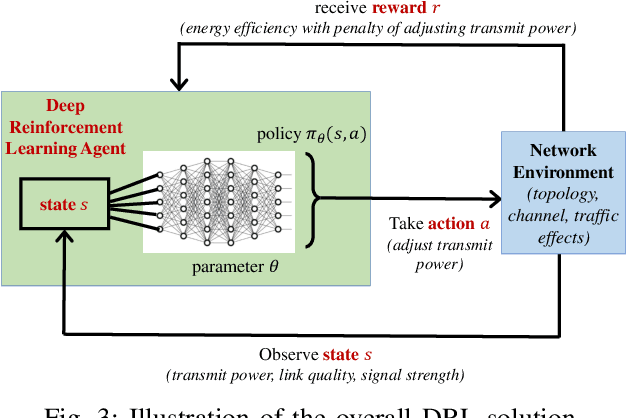
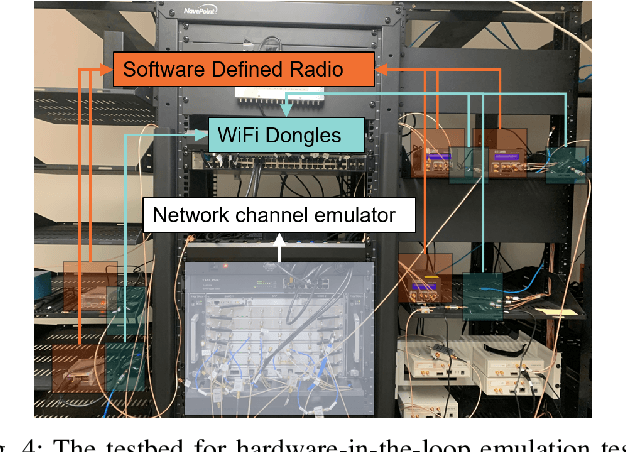
This paper presents a deep reinforcement learning (DRL) solution for power control in wireless communications, describes its embedded implementation with WiFi transceivers for a WiFi network system, and evaluates the performance with high-fidelity emulation tests. In a multi-hop wireless network, each mobile node measures its link quality and signal strength, and controls its transmit power. As a model-free solution, reinforcement learning allows nodes to adapt their actions by observing the states and maximize their cumulative rewards over time. For each node, the state consists of transmit power, link quality and signal strength; the action adjusts the transmit power; and the reward combines energy efficiency (throughput normalized by energy consumption) and penalty of changing the transmit power. As the state space is large, Q-learning is hard to implement on embedded platforms with limited memory and processing power. By approximating the Q-values with a DQN, DRL is implemented for the embedded platform of each node combining an ARM processor and a WiFi transceiver for 802.11n. Controllable and repeatable emulation tests are performed by inducing realistic channel effects on RF signals. Performance comparison with benchmark schemes of fixed and myopic power allocations shows that power control with DRL provides major improvements to energy efficiency and throughput in WiFi network systems.
* 5 pages, 6 figures, 1 table
An Exponentially Converging Particle Method for the Mixed Nash Equilibrium of Continuous Games
Nov 02, 2022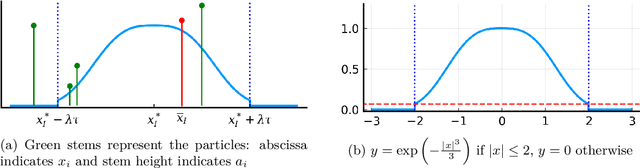
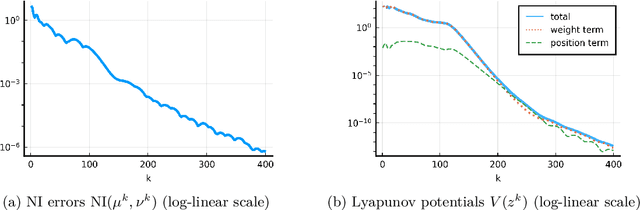
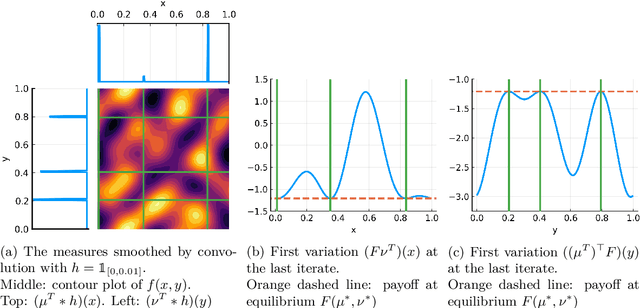
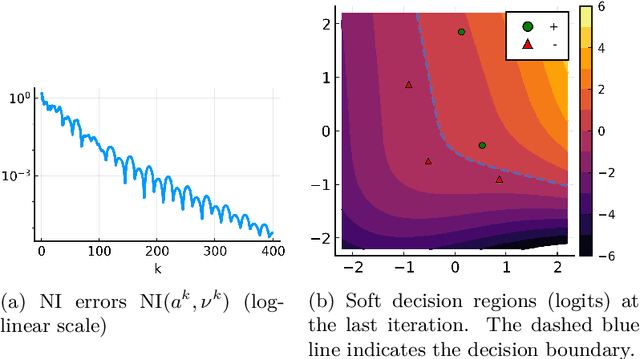
We consider the problem of computing mixed Nash equilibria of two-player zero-sum games with continuous sets of pure strategies and with first-order access to the payoff function. This problem arises for example in game-theory-inspired machine learning applications, such as distributionally-robust learning. In those applications, the strategy sets are high-dimensional and thus methods based on discretisation cannot tractably return high-accuracy solutions. In this paper, we introduce and analyze a particle-based method that enjoys guaranteed local convergence for this problem. This method consists in parametrizing the mixed strategies as atomic measures and applying proximal point updates to both the atoms' weights and positions. It can be interpreted as a time-implicit discretization of the "interacting" Wasserstein-Fisher-Rao gradient flow. We prove that, under non-degeneracy assumptions, this method converges at an exponential rate to the exact mixed Nash equilibrium from any initialization satisfying a natural notion of closeness to optimality. We illustrate our results with numerical experiments and discuss applications to max-margin and distributionally-robust classification using two-layer neural networks, where our method has a natural interpretation as a simultaneous training of the network's weights and of the adversarial distribution.
How Technology Impacts and Compares to Humans in Socially Consequential Arenas
Nov 02, 2022
One of the main promises of technology development is for it to be adopted by people, organizations, societies, and governments -- incorporated into their life, work stream, or processes. Often, this is socially beneficial as it automates mundane tasks, frees up more time for other more important things, or otherwise improves the lives of those who use the technology. However, these beneficial results do not apply in every scenario and may not impact everyone in a system the same way. Sometimes a technology is developed which produces both benefits and inflicts some harm. These harms may come at a higher cost to some people than others, raising the question: {\it how are benefits and harms weighed when deciding if and how a socially consequential technology gets developed?} The most natural way to answer this question, and in fact how people first approach it, is to compare the new technology to what used to exist. As such, in this work, I make comparative analyses between humans and machines in three scenarios and seek to understand how sentiment about a technology, performance of that technology, and the impacts of that technology combine to influence how one decides to answer my main research question.
Vox-Fusion: Dense Tracking and Mapping with Voxel-based Neural Implicit Representation
Oct 28, 2022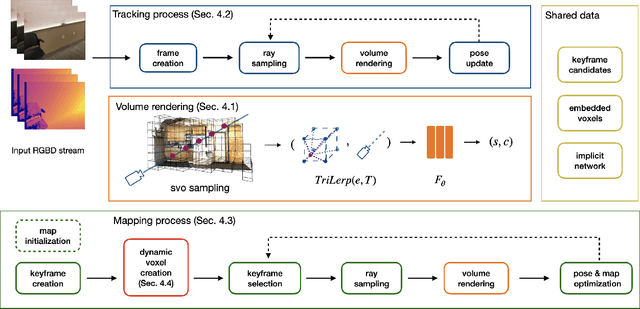
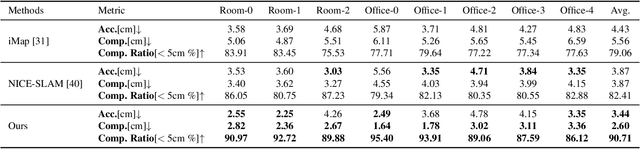
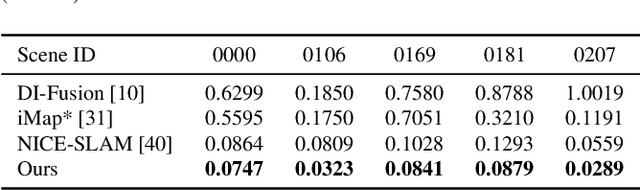
In this work, we present a dense tracking and mapping system named Vox-Fusion, which seamlessly fuses neural implicit representations with traditional volumetric fusion methods. Our approach is inspired by the recently developed implicit mapping and positioning system and further extends the idea so that it can be freely applied to practical scenarios. Specifically, we leverage a voxel-based neural implicit surface representation to encode and optimize the scene inside each voxel. Furthermore, we adopt an octree-based structure to divide the scene and support dynamic expansion, enabling our system to track and map arbitrary scenes without knowing the environment like in previous works. Moreover, we proposed a high-performance multi-process framework to speed up the method, thus supporting some applications that require real-time performance. The evaluation results show that our methods can achieve better accuracy and completeness than previous methods. We also show that our Vox-Fusion can be used in augmented reality and virtual reality applications. Our source code is publicly available at https://github.com/zju3dv/Vox-Fusion.
A Functional-Space Mean-Field Theory of Partially-Trained Three-Layer Neural Networks
Oct 28, 2022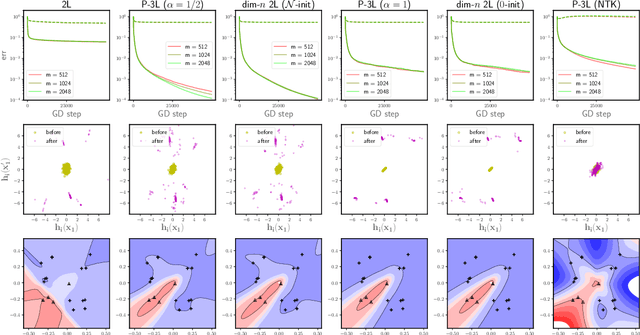
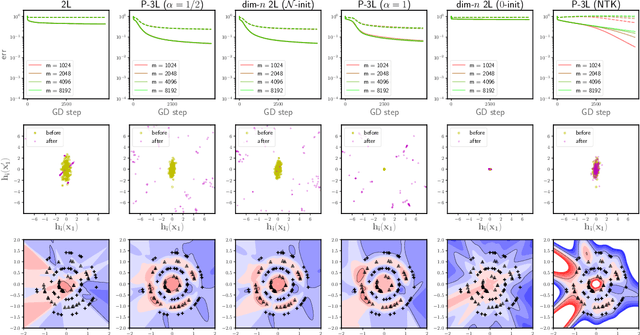
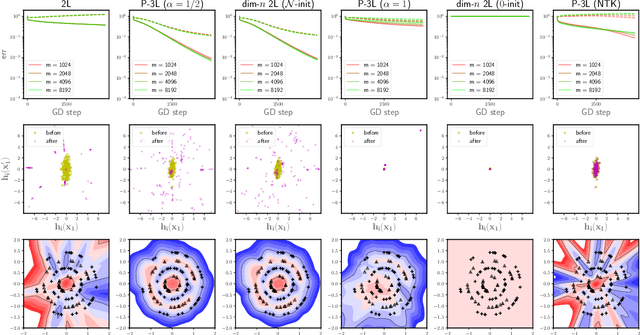
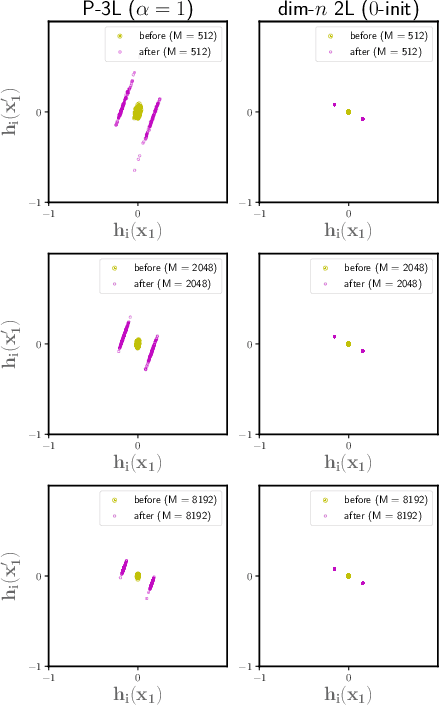
To understand the training dynamics of neural networks (NNs), prior studies have considered the infinite-width mean-field (MF) limit of two-layer NN, establishing theoretical guarantees of its convergence under gradient flow training as well as its approximation and generalization capabilities. In this work, we study the infinite-width limit of a type of three-layer NN model whose first layer is random and fixed. To define the limiting model rigorously, we generalize the MF theory of two-layer NNs by treating the neurons as belonging to functional spaces. Then, by writing the MF training dynamics as a kernel gradient flow with a time-varying kernel that remains positive-definite, we prove that its training loss in $L_2$ regression decays to zero at a linear rate. Furthermore, we define function spaces that include the solutions obtainable through the MF training dynamics and prove Rademacher complexity bounds for these spaces. Our theory accommodates different scaling choices of the model, resulting in two regimes of the MF limit that demonstrate distinctive behaviors while both exhibiting feature learning.
TripletTrack: 3D Object Tracking using Triplet Embeddings and LSTM
Oct 28, 2022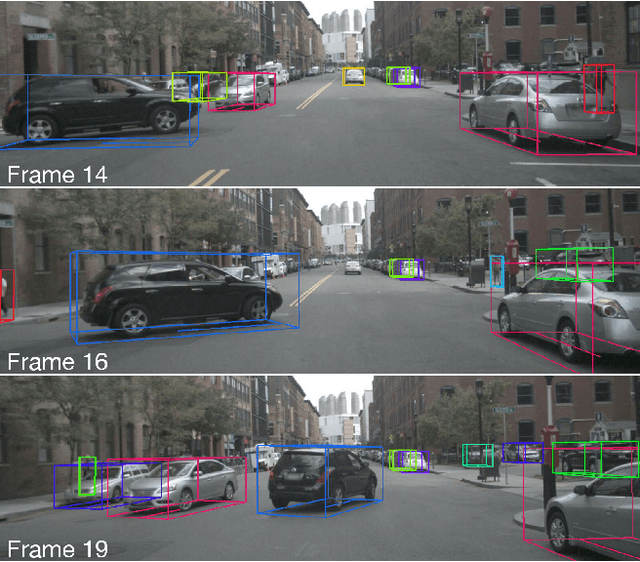

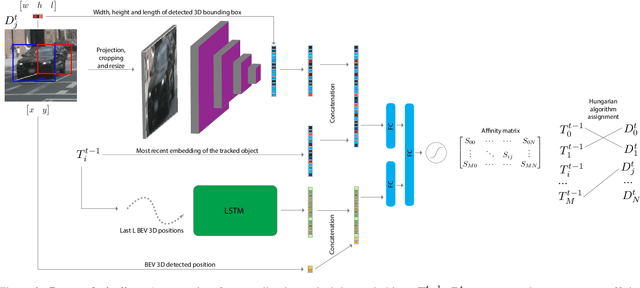

3D object tracking is a critical task in autonomous driving systems. It plays an essential role for the system's awareness about the surrounding environment. At the same time there is an increasing interest in algorithms for autonomous cars that solely rely on inexpensive sensors, such as cameras. In this paper we investigate the use of triplet embeddings in combination with motion representations for 3D object tracking. We start from an off-the-shelf 3D object detector, and apply a tracking mechanism where objects are matched by an affinity score computed on local object feature embeddings and motion descriptors. The feature embeddings are trained to include information about the visual appearance and monocular 3D object characteristics, while motion descriptors provide a strong representation of object trajectories. We will show that our approach effectively re-identifies objects, and also behaves reliably and accurately in case of occlusions, missed detections and can detect re-appearance across different field of views. Experimental evaluation shows that our approach outperforms state-of-the-art on nuScenes by a large margin. We also obtain competitive results on KITTI.
* Accepted to CVPR 2022 Workshop on Autonomous Driving
Visual Answer Localization with Cross-modal Mutual Knowledge Transfer
Oct 28, 2022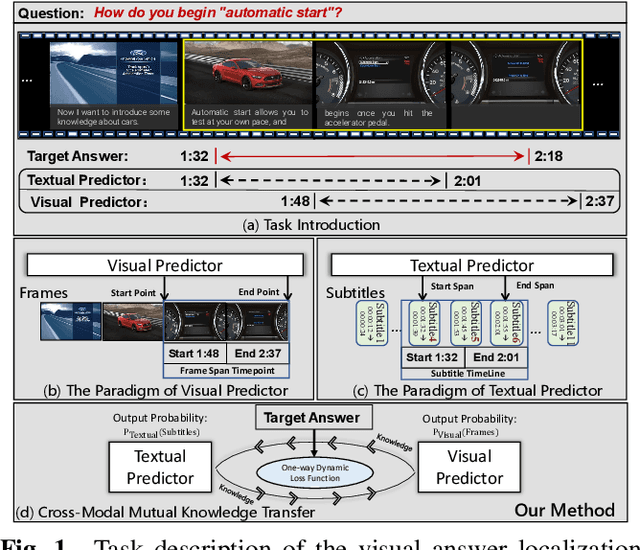
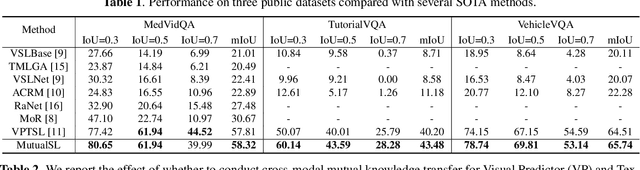
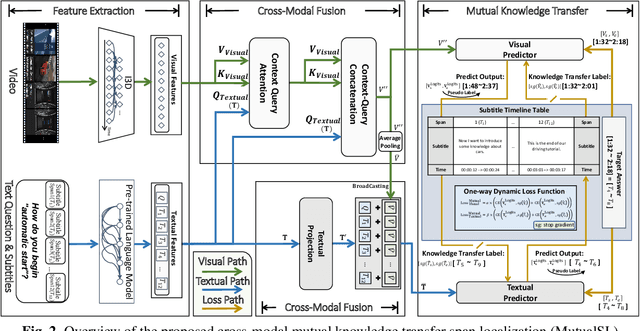
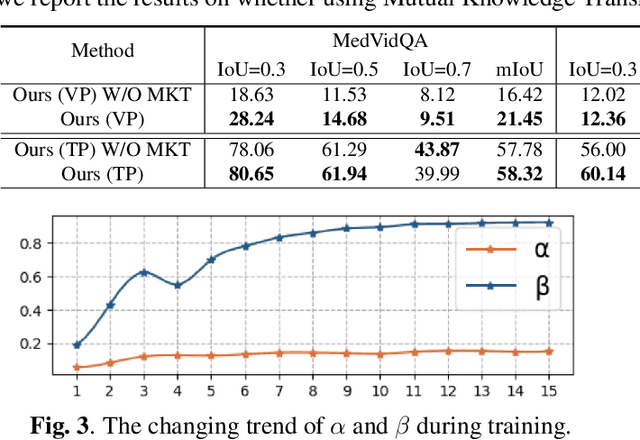
The goal of visual answering localization (VAL) in the video is to obtain a relevant and concise time clip from a video as the answer to the given natural language question. Early methods are based on the interaction modelling between video and text to predict the visual answer by the visual predictor. Later, using the textual predictor with subtitles for the VAL proves to be more precise. However, these existing methods still have cross-modal knowledge deviations from visual frames or textual subtitles. In this paper, we propose a cross-modal mutual knowledge transfer span localization (MutualSL) method to reduce the knowledge deviation. MutualSL has both visual predictor and textual predictor, where we expect the prediction results of these both to be consistent, so as to promote semantic knowledge understanding between cross-modalities. On this basis, we design a one-way dynamic loss function to dynamically adjust the proportion of knowledge transfer. We have conducted extensive experiments on three public datasets for evaluation. The experimental results show that our method outperforms other competitive state-of-the-art (SOTA) methods, demonstrating its effectiveness.
Domain Adaptation for Time-Series Classification to Mitigate Covariate Shift
Apr 07, 2022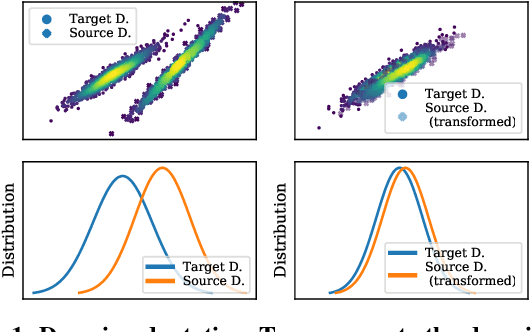
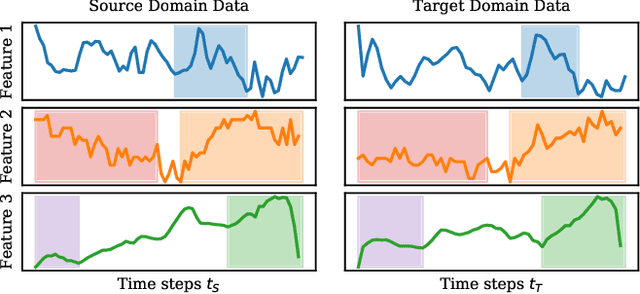
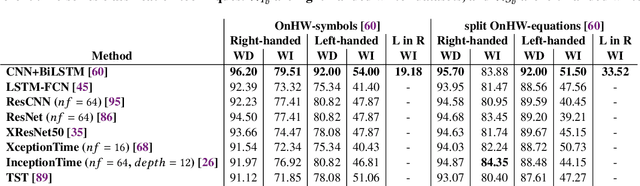
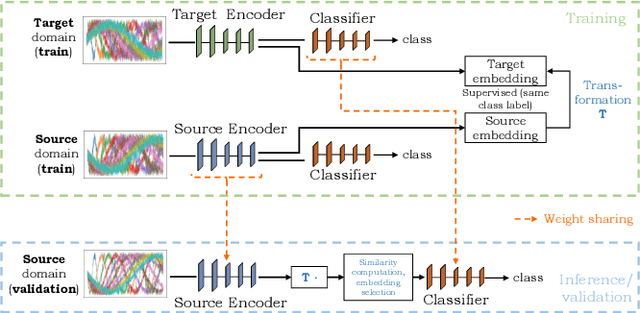
The performance of a machine learning model degrades when it is applied to data from a similar but different domain than the data it has initially been trained on. To mitigate this domain shift problem, domain adaptation (DA) techniques search for an optimal transformation that converts the (current) input data from a source domain to a target domain to learn a domain-invariant representations that reduces domain discrepancy. This paper proposes a novel supervised domain adaptation based on two steps. First, we search for an optimal class-dependent transformation from the source to the target domain from a few samples. We consider optimal transport methods such as the earth mover distance with Laplacian regularization, Sinkhorn transport and correlation alignment. Second, we use embedding similarity techniques to select the corresponding transformation at inference. We use correlation metrics and maximum mean discrepancy with higher-order moment matching techniques. We conduct an extensive evaluation on time-series datasets with domain shift including simulated and various online handwriting datasets to demonstrate the performance.
Forecasting Sensor Values in Waste-To-Fuel Plants: a Case Study
Sep 28, 2022
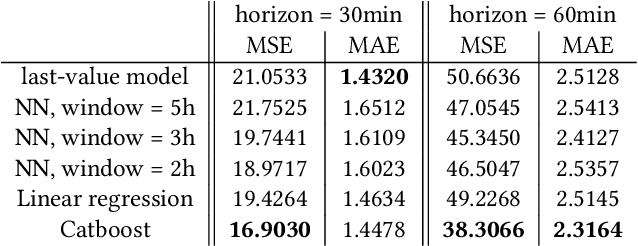
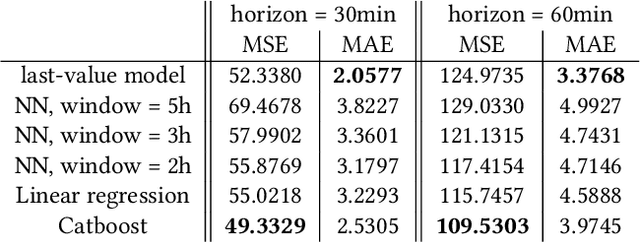
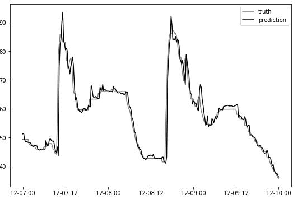
In this research, we develop machine learning models to predict future sensor readings of a waste-to-fuel plant, which would enable proactive control of the plant's operations. We developed models that predict sensor readings for 30 and 60 minutes into the future. The models were trained using historical data, and predictions were made based on sensor readings taken at a specific time. We compare three types of models: (a) a n\"aive prediction that considers only the last predicted value, (b) neural networks that make predictions based on past sensor data (we consider different time window sizes for making a prediction), and (c) a gradient boosted tree regressor created with a set of features that we developed. We developed and tested our models on a real-world use case at a waste-to-fuel plant in Canada. We found that approach (c) provided the best results, while approach (b) provided mixed results and was not able to outperform the n\"aive consistently.
A study on the ephemeral nature of knowledge shared within multiagent systems
Nov 08, 2022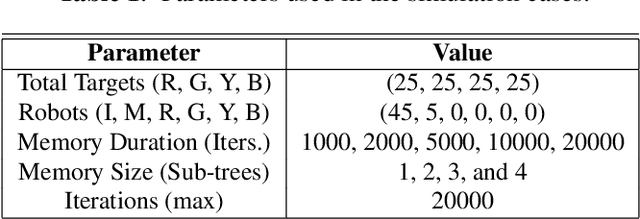
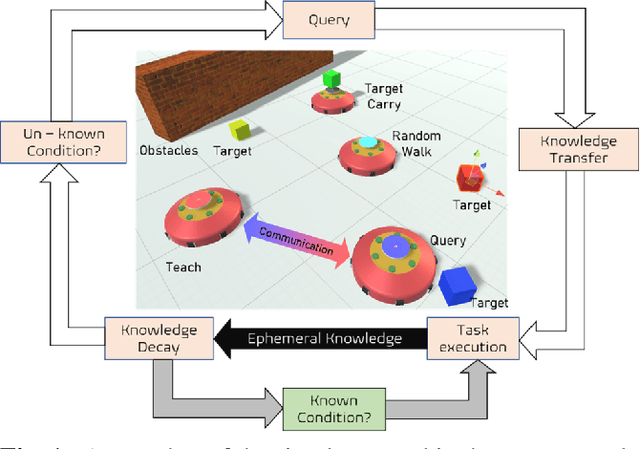
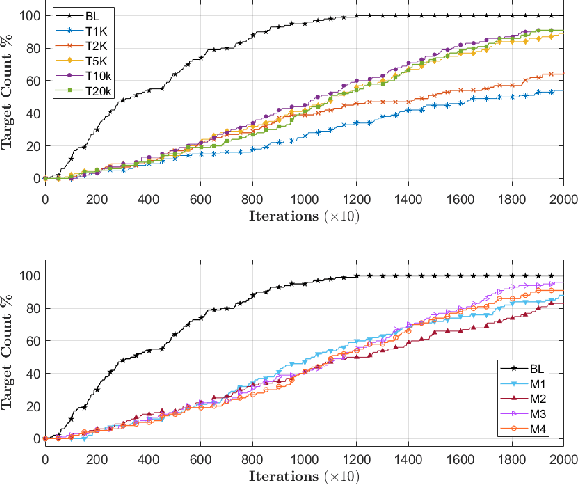
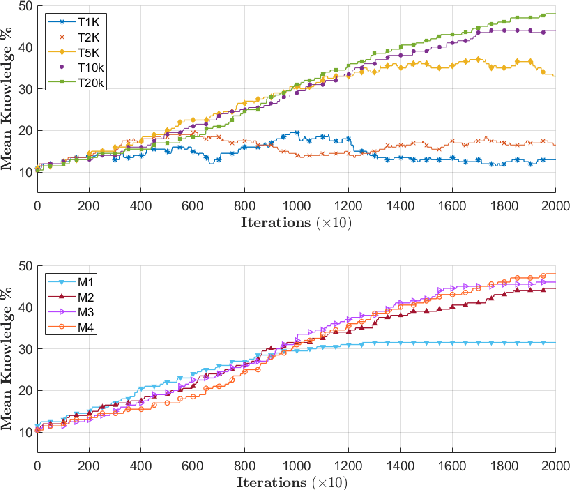
Achieving knowledge sharing within an artificial swarm system could lead to significant development in autonomous multiagent and robotic systems research and realize collective intelligence. However, this is difficult to achieve since there is no generic framework to transfer skills between agents other than a query-response-based approach. Moreover, natural living systems have a "forgetfulness" property for everything they learn. Analyzing such ephemeral nature (temporal memory properties of new knowledge gained) in artificial systems has never been studied in the literature. We propose a behavior tree-based framework to realize a query-response mechanism for transferring skills encoded as the condition-action control sub-flow of that portion of the knowledge between agents to fill this gap. We simulate a multiagent group with different initial knowledge on a foraging mission. While performing basic operations, each robot queries other robots to respond to an unknown condition. The responding robot shares the control actions by sharing a portion of the behavior tree that addresses the queries. Specifically, we investigate the ephemeral nature of the new knowledge gained through such a framework, where the knowledge gained by the agent is either limited due to memory or is forgotten over time. Our investigations show that knowledge grows proportionally with the duration of remembrance, which is trivial. However, we found minimal impact on knowledge growth due to memory. We compare these cases against a baseline that involved full knowledge pre-coded on all agents. We found that knowledge-sharing strived to match the baseline condition by sharing and achieving knowledge growth as a collective system.