 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
S3E: A Large-scale Multimodal Dataset for Collaborative SLAM
Oct 25, 2022

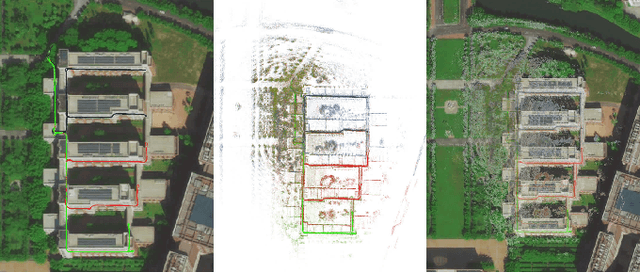
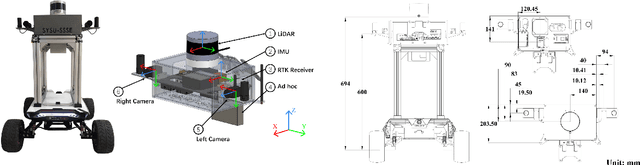
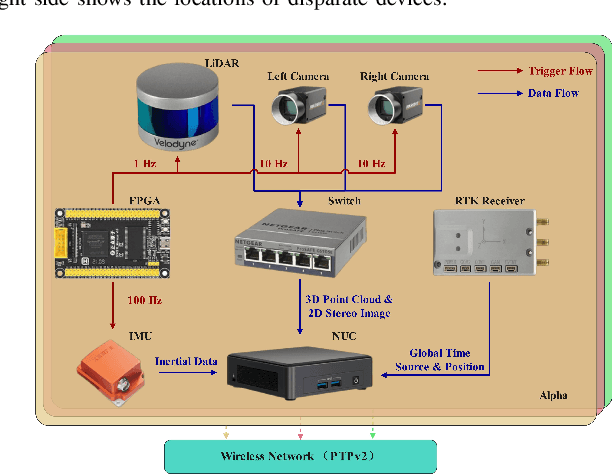
With the advanced request to employ a team of robots to perform a task collaboratively, the research community has become increasingly interested in collaborative simultaneous localization and mapping. Unfortunately, existing datasets are limited in the scale and variation of the collaborative trajectories they capture, even though generalization between inter-trajectories among different agents is crucial to the overall viability of collaborative tasks. To help align the research community's contributions with real-world multiagent ordinated SLAM problems, we introduce S3E, a novel large-scale multimodal dataset captured by a fleet of unmanned ground vehicles along four designed collaborative trajectory paradigms. S3E consists of 7 outdoor and 5 indoor scenes that each exceed 200 seconds, consisting of well synchronized and calibrated high-quality stereo camera, LiDAR, and high-frequency IMU data. Crucially, our effort exceeds previous attempts regarding dataset size, scene variability, and complexity. It has 4x as much average recording time as the pioneering EuRoC dataset. We also provide careful dataset analysis as well as baselines for collaborative SLAM and single counterparts. Find data, code, and more up-to-date information at https://github.com/PengYu-Team/S3E.
A Dynamical System View of Langevin-Based Non-Convex Sampling
Oct 25, 2022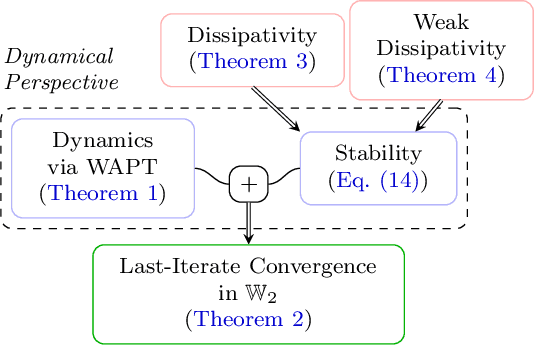
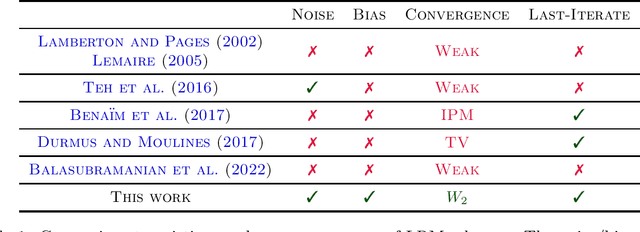
Non-convex sampling is a key challenge in machine learning, central to non-convex optimization in deep learning as well as to approximate probabilistic inference. Despite its significance, theoretically there remain many important challenges: Existing guarantees (1) typically only hold for the averaged iterates rather than the more desirable last iterates, (2) lack convergence metrics that capture the scales of the variables such as Wasserstein distances, and (3) mainly apply to elementary schemes such as stochastic gradient Langevin dynamics. In this paper, we develop a new framework that lifts the above issues by harnessing several tools from the theory of dynamical systems. Our key result is that, for a large class of state-of-the-art sampling schemes, their last-iterate convergence in Wasserstein distances can be reduced to the study of their continuous-time counterparts, which is much better understood. Coupled with standard assumptions of MCMC sampling, our theory immediately yields the last-iterate Wasserstein convergence of many advanced sampling schemes such as proximal, randomized mid-point, and Runge-Kutta integrators. Beyond existing methods, our framework also motivates more efficient schemes that enjoy the same rigorous guarantees.
Bridging the Training-Inference Gap for Dense Phrase Retrieval
Oct 25, 2022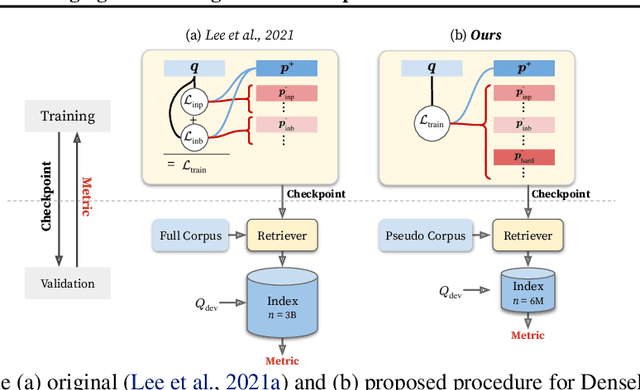
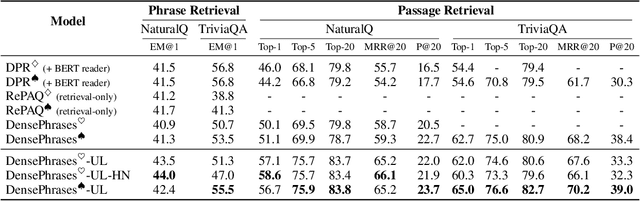
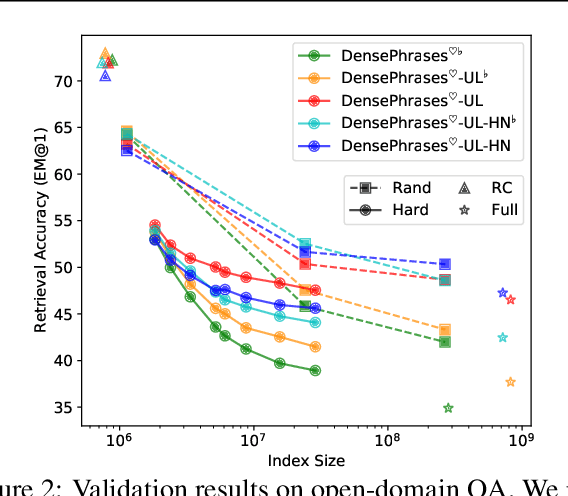
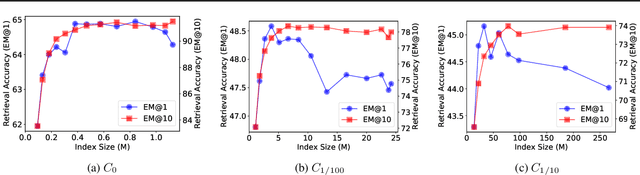
Building dense retrievers requires a series of standard procedures, including training and validating neural models and creating indexes for efficient search. However, these procedures are often misaligned in that training objectives do not exactly reflect the retrieval scenario at inference time. In this paper, we explore how the gap between training and inference in dense retrieval can be reduced, focusing on dense phrase retrieval (Lee et al., 2021) where billions of representations are indexed at inference. Since validating every dense retriever with a large-scale index is practically infeasible, we propose an efficient way of validating dense retrievers using a small subset of the entire corpus. This allows us to validate various training strategies including unifying contrastive loss terms and using hard negatives for phrase retrieval, which largely reduces the training-inference discrepancy. As a result, we improve top-1 phrase retrieval accuracy by 2~3 points and top-20 passage retrieval accuracy by 2~4 points for open-domain question answering. Our work urges modeling dense retrievers with careful consideration of training and inference via efficient validation while advancing phrase retrieval as a general solution for dense retrieval.
WeakIdent: Weak formulation for Identifying Differential Equations using Narrow-fit and Trimming
Nov 06, 2022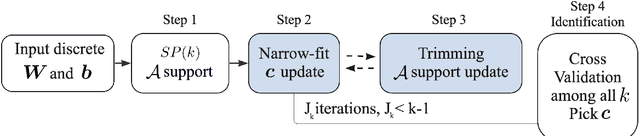


Data-driven identification of differential equations is an interesting but challenging problem, especially when the given data are corrupted by noise. When the governing differential equation is a linear combination of various differential terms, the identification problem can be formulated as solving a linear system, with the feature matrix consisting of linear and nonlinear terms multiplied by a coefficient vector. This product is equal to the time derivative term, and thus generates dynamical behaviors. The goal is to identify the correct terms that form the equation to capture the dynamics of the given data. We propose a general and robust framework to recover differential equations using a weak formulation, for both ordinary and partial differential equations (ODEs and PDEs). The weak formulation facilitates an efficient and robust way to handle noise. For a robust recovery against noise and the choice of hyper-parameters, we introduce two new mechanisms, narrow-fit and trimming, for the coefficient support and value recovery, respectively. For each sparsity level, Subspace Pursuit is utilized to find an initial set of support from the large dictionary. Then, we focus on highly dynamic regions (rows of the feature matrix), and error normalize the feature matrix in the narrow-fit step. The support is further updated via trimming of the terms that contribute the least. Finally, the support set of features with the smallest Cross-Validation error is chosen as the result. A comprehensive set of numerical experiments are presented for both systems of ODEs and PDEs with various noise levels. The proposed method gives a robust recovery of the coefficients, and a significant denoising effect which can handle up to $100\%$ noise-to-signal ratio for some equations. We compare the proposed method with several state-of-the-art algorithms for the recovery of differential equations.
A Greedy Algorithm for Building Compact Binary Activated Neural Networks
Sep 07, 2022
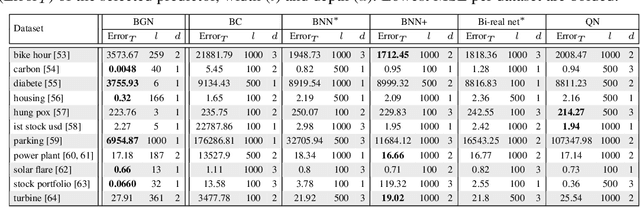
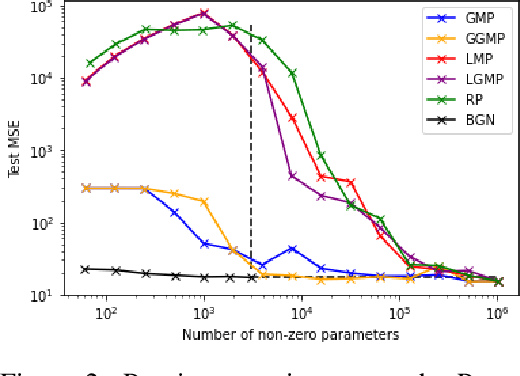
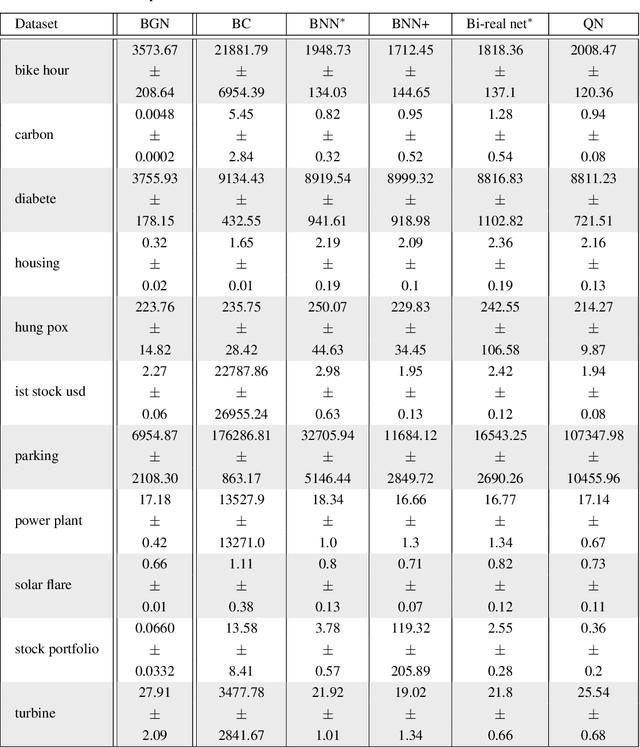
We study binary activated neural networks in the context of regression tasks, provide guarantees on the expressiveness of these particular networks and propose a greedy algorithm for building such networks. Aiming for predictors having small resources needs, the greedy approach does not need to fix in advance an architecture for the network: this one is built one layer at a time, one neuron at a time, leading to predictors that aren't needlessly wide and deep for a given task. Similarly to boosting algorithms, our approach guarantees a training loss reduction every time a neuron is added to a layer. This greatly differs from most binary activated neural networks training schemes that rely on stochastic gradient descent (circumventing the 0-almost-everywhere derivative problem of the binary activation function by surrogates such as the straight through estimator or continuous binarization). We show that our method provides compact and sparse predictors while obtaining similar performances to state-of-the-art methods for training binary activated networks.
On the Interpolation of Contextualized Term-based Ranking with BM25 for Query-by-Example Retrieval
Oct 11, 2022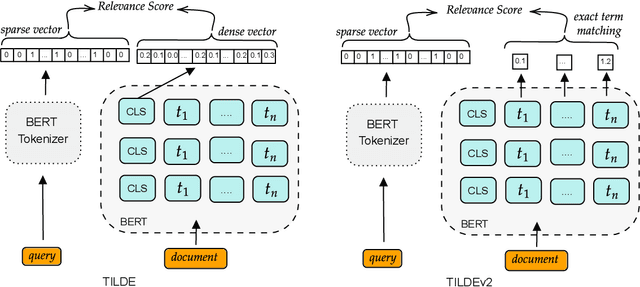
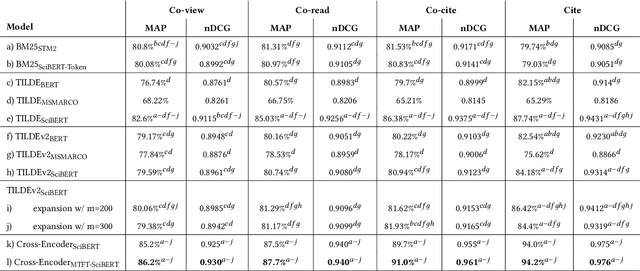
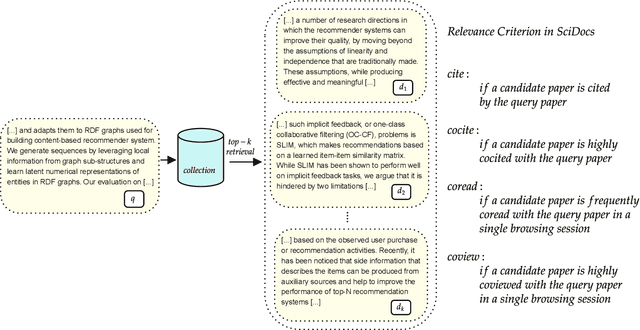
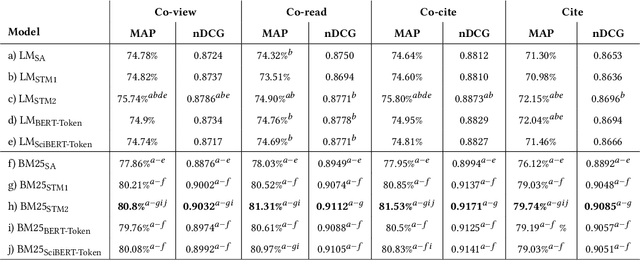
Term-based ranking with pre-trained transformer-based language models has recently gained attention as they bring the contextualization power of transformer models into the highly efficient term-based retrieval. In this work, we examine the generalizability of two of these deep contextualized term-based models in the context of query-by-example (QBE) retrieval in which a seed document acts as the query to find relevant documents. In this setting -- where queries are much longer than common keyword queries -- BERT inference at query time is problematic as it involves quadratic complexity. We investigate TILDE and TILDEv2, both of which leverage BERT tokenizer as their query encoder. With this approach, there is no need for BERT inference at query time, and also the query can be of any length. Our extensive evaluation on the four QBE tasks of SciDocs benchmark shows that in a query-by-example retrieval setting TILDE and TILDEv2 are still less effective than a cross-encoder BERT ranker. However, we observe that BM25 could show a competitive ranking quality compared to TILDE and TILDEv2 which is in contrast to the findings about the relative performance of these three models on retrieval for short queries reported in prior work. This result raises the question about the use of contextualized term-based ranking models being beneficial in QBE setting. We follow-up on our findings by studying the score interpolation between the relevance score from TILDE (TILDEv2) and BM25. We conclude that these two contextualized term-based ranking models capture different relevance signals than BM25 and combining the different term-based rankers results in statistically significant improvements in QBE retrieval. Our work sheds light on the challenges of retrieval settings different from the common evaluation benchmarks.
Mitigating Unintended Memorization in Language Models via Alternating Teaching
Oct 13, 2022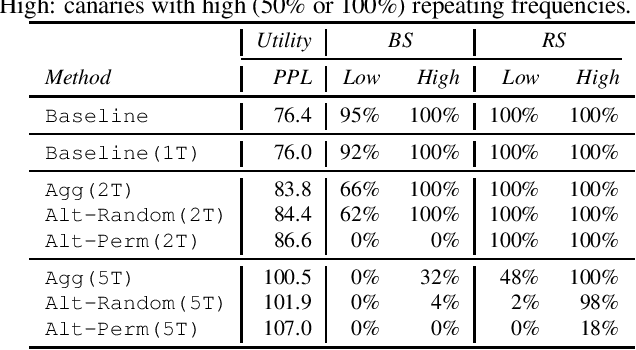
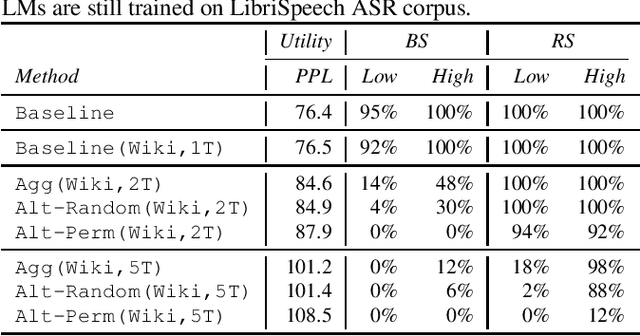
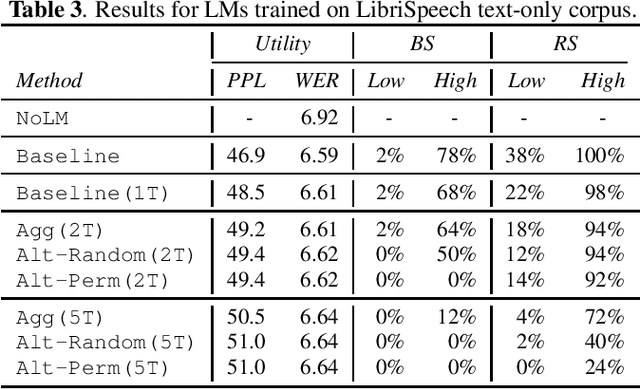
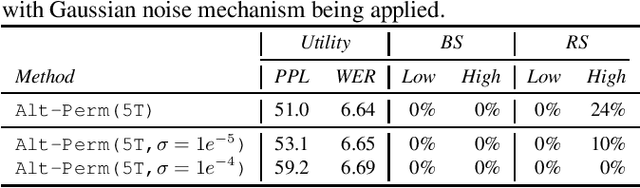
Recent research has shown that language models have a tendency to memorize rare or unique sequences in the training corpora which can thus leak sensitive attributes of user data. We employ a teacher-student framework and propose a novel approach called alternating teaching to mitigate unintended memorization in sequential modeling. In our method, multiple teachers are trained on disjoint training sets whose privacy one wishes to protect, and teachers' predictions supervise the training of a student model in an alternating manner at each time step. Experiments on LibriSpeech datasets show that the proposed method achieves superior privacy-preserving results than other counterparts. In comparison with no prevention for unintended memorization, the overall utility loss is small when training records are sufficient.
Fourier PlenOctrees for Dynamic Radiance Field Rendering in Real-time
Feb 22, 2022
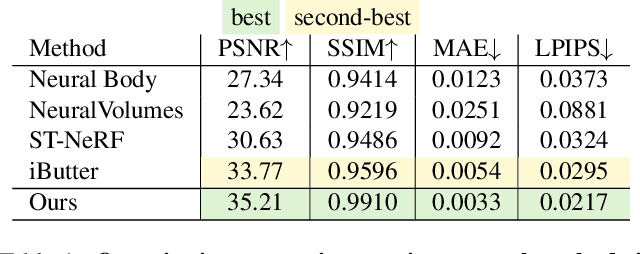
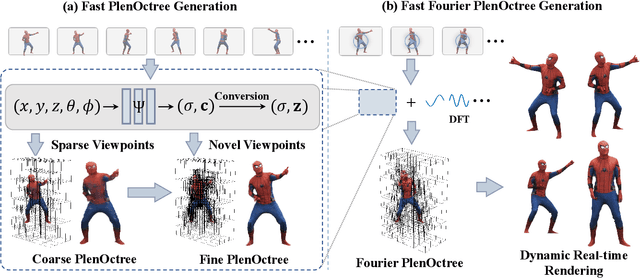

Implicit neural representations such as Neural Radiance Field (NeRF) have focused mainly on modeling static objects captured under multi-view settings where real-time rendering can be achieved with smart data structures, e.g., PlenOctree. In this paper, we present a novel Fourier PlenOctree (FPO) technique to tackle efficient neural modeling and real-time rendering of dynamic scenes captured under the free-view video (FVV) setting. The key idea in our FPO is a novel combination of generalized NeRF, PlenOctree representation, volumetric fusion and Fourier transform. To accelerate FPO construction, we present a novel coarse-to-fine fusion scheme that leverages the generalizable NeRF technique to generate the tree via spatial blending. To tackle dynamic scenes, we tailor the implicit network to model the Fourier coefficients of timevarying density and color attributes. Finally, we construct the FPO and train the Fourier coefficients directly on the leaves of a union PlenOctree structure of the dynamic sequence. We show that the resulting FPO enables compact memory overload to handle dynamic objects and supports efficient fine-tuning. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF and achieves over an order of magnitude acceleration over SOTA while preserving high visual quality for the free-viewpoint rendering of unseen dynamic scenes.
Broad-persistent Advice for Interactive Reinforcement Learning Scenarios
Oct 11, 2022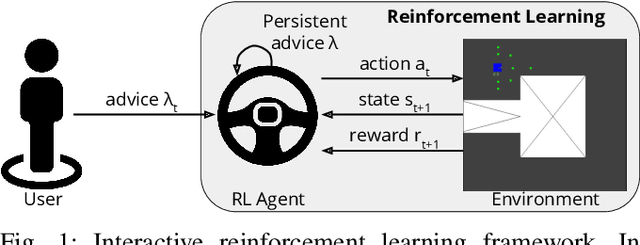
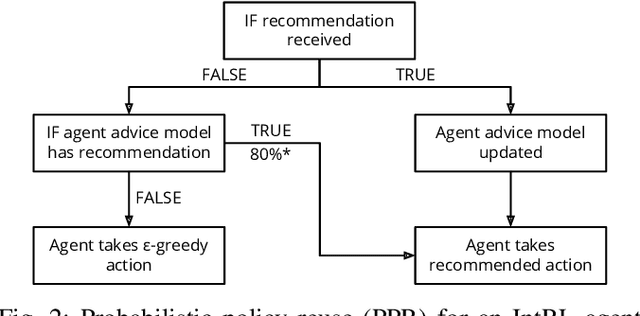

The use of interactive advice in reinforcement learning scenarios allows for speeding up the learning process for autonomous agents. Current interactive reinforcement learning research has been limited to real-time interactions that offer relevant user advice to the current state only. Moreover, the information provided by each interaction is not retained and instead discarded by the agent after a single use. In this paper, we present a method for retaining and reusing provided knowledge, allowing trainers to give general advice relevant to more than just the current state. Results obtained show that the use of broad-persistent advice substantially improves the performance of the agent while reducing the number of interactions required for the trainer.
EgoSpeed-Net: Forecasting Speed-Control in Driver Behavior from Egocentric Video Data
Sep 27, 2022
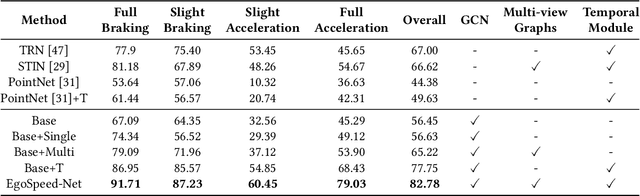
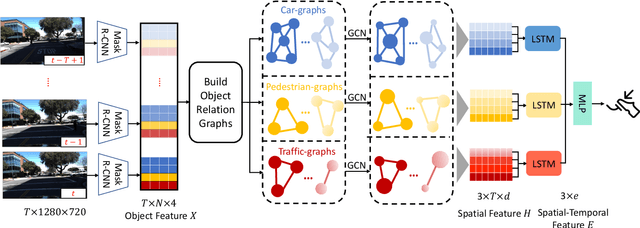
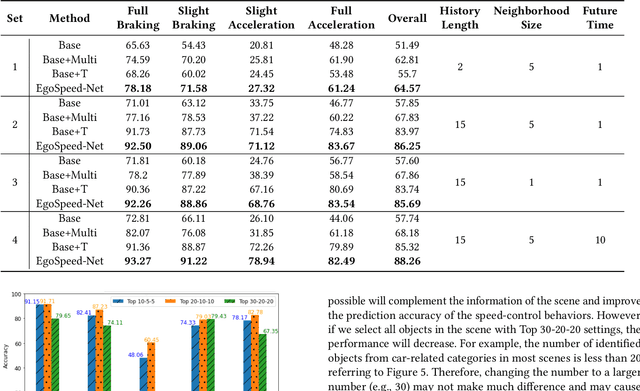
Speed-control forecasting, a challenging problem in driver behavior analysis, aims to predict the future actions of a driver in controlling vehicle speed such as braking or acceleration. In this paper, we try to address this challenge solely using egocentric video data, in contrast to the majority of works in the literature using either third-person view data or extra vehicle sensor data such as GPS, or both. To this end, we propose a novel graph convolutional network (GCN) based network, namely, EgoSpeed-Net. We are motivated by the fact that the position changes of objects over time can provide us very useful clues for forecasting the speed change in future. We first model the spatial relations among the objects from each class, frame by frame, using fully-connected graphs, on top of which GCNs are applied for feature extraction. Then we utilize a long short-term memory network to fuse such features per class over time into a vector, concatenate such vectors and forecast a speed-control action using a multilayer perceptron classifier. We conduct extensive experiments on the Honda Research Institute Driving Dataset and demonstrate the superior performance of EgoSpeed-Net.