 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Anticipating the Unseen Discrepancy for Vision and Language Navigation
Sep 10, 2022
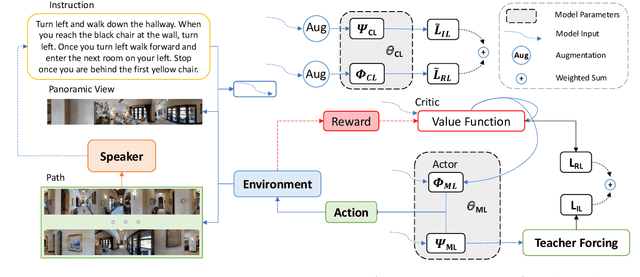
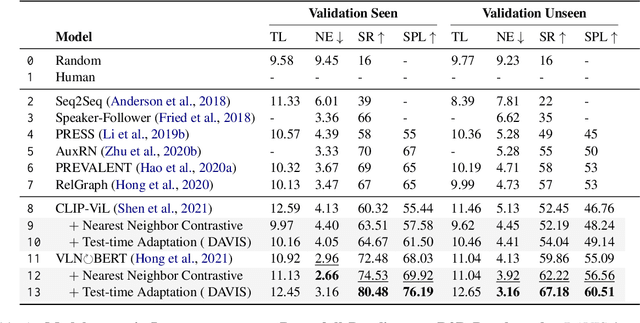
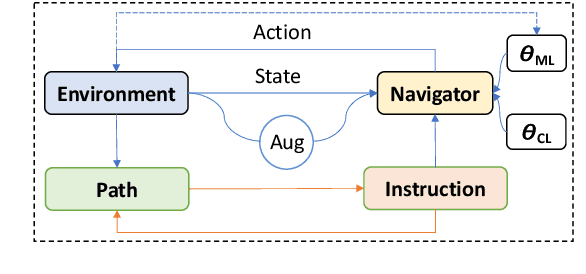
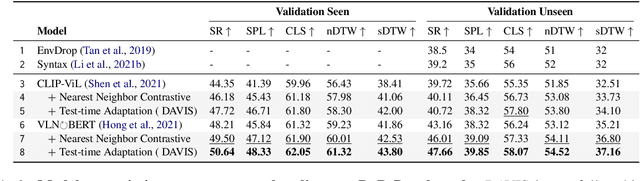
Vision-Language Navigation requires the agent to follow natural language instructions to reach a specific target. The large discrepancy between seen and unseen environments makes it challenging for the agent to generalize well. Previous studies propose data augmentation methods to mitigate the data bias explicitly or implicitly and provide improvements in generalization. However, they try to memorize augmented trajectories and ignore the distribution shifts under unseen environments at test time. In this paper, we propose an Unseen Discrepancy Anticipating Vision and Language Navigation (DAVIS) that learns to generalize to unseen environments via encouraging test-time visual consistency. Specifically, we devise: 1) a semi-supervised framework DAVIS that leverages visual consistency signals across similar semantic observations. 2) a two-stage learning procedure that encourages adaptation to test-time distribution. The framework enhances the basic mixture of imitation and reinforcement learning with Momentum Contrast to encourage stable decision-making on similar observations under a joint training stage and a test-time adaptation stage. Extensive experiments show that DAVIS achieves model-agnostic improvement over previous state-of-the-art VLN baselines on R2R and RxR benchmarks. Our source code and data are in supplemental materials.
Spatio-temporal Tendency Reasoning for Human Body Pose and Shape Estimation from Videos
Oct 10, 2022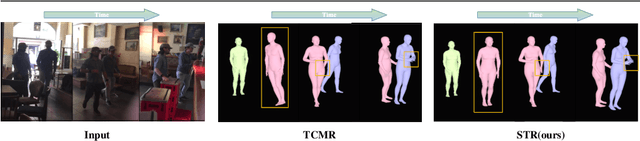
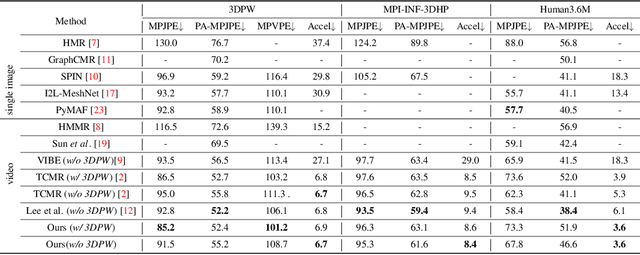
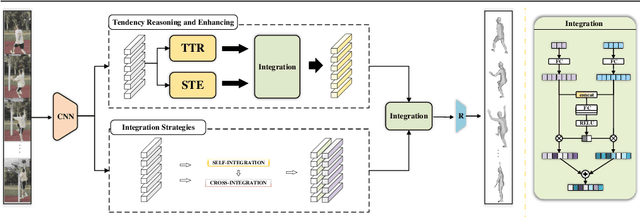
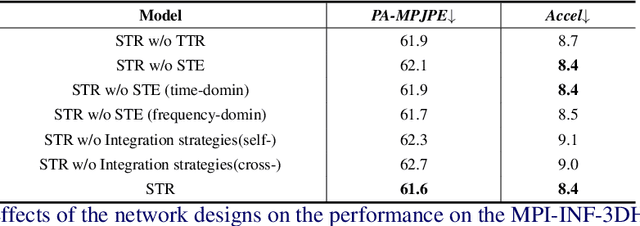
In this paper, we present a spatio-temporal tendency reasoning (STR) network for recovering human body pose and shape from videos. Previous approaches have focused on how to extend 3D human datasets and temporal-based learning to promote accuracy and temporal smoothing. Different from them, our STR aims to learn accurate and natural motion sequences in an unconstrained environment through temporal and spatial tendency and to fully excavate the spatio-temporal features of existing video data. To this end, our STR learns the representation of features in the temporal and spatial dimensions respectively, to concentrate on a more robust representation of spatio-temporal features. More specifically, for efficient temporal modeling, we first propose a temporal tendency reasoning (TTR) module. TTR constructs a time-dimensional hierarchical residual connection representation within a video sequence to effectively reason temporal sequences' tendencies and retain effective dissemination of human information. Meanwhile, for enhancing the spatial representation, we design a spatial tendency enhancing (STE) module to further learns to excite spatially time-frequency domain sensitive features in human motion information representations. Finally, we introduce integration strategies to integrate and refine the spatio-temporal feature representations. Extensive experimental findings on large-scale publically available datasets reveal that our STR remains competitive with the state-of-the-art on three datasets. Our code are available at https://github.com/Changboyang/STR.git.
Reading Between the Lines: Modeling User Behavior and Costs in AI-Assisted Programming
Oct 25, 2022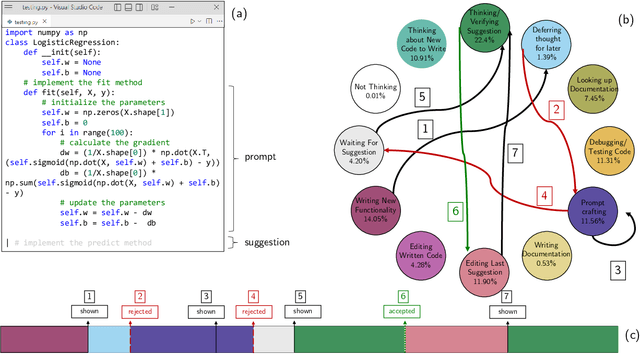



AI code-recommendation systems (CodeRec), such as Copilot, can assist programmers inside an IDE by suggesting and autocompleting arbitrary code; potentially improving their productivity. To understand how these AI improve programmers in a coding session, we need to understand how they affect programmers' behavior. To make progress, we studied GitHub Copilot, and developed CUPS -- a taxonomy of 12 programmer activities common to AI code completion systems. We then conducted a study with 21 programmers who completed coding tasks and used our labeling tool to retrospectively label their sessions with CUPS. We analyze over 3000 label instances, and visualize the results with timelines and state machines to profile programmer-CodeRec interaction. This reveals novel insights into the distribution and patterns of programmer behavior, as well as inefficiencies and time costs. Finally, we use these insights to inform future interventions to improve AI-assisted programming and human-AI interaction.
SPAD-Based Optical Wireless Communication with ACO-OFDM
Oct 25, 2022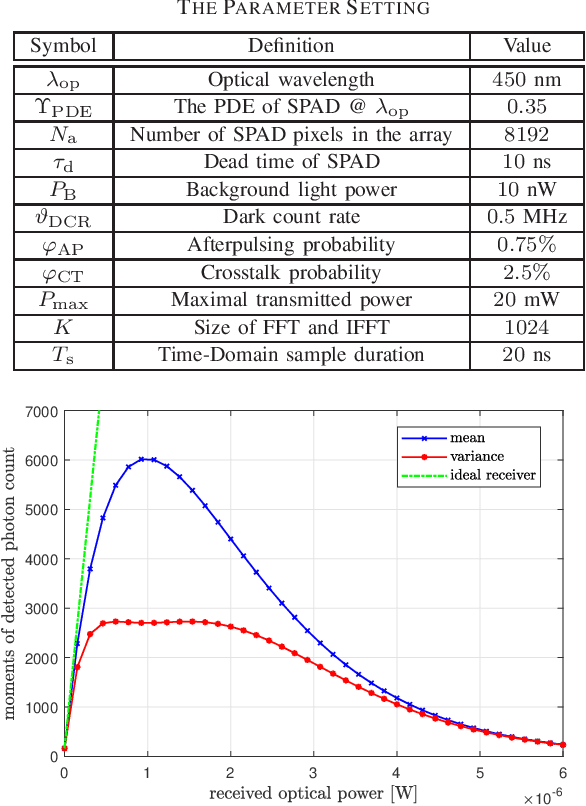
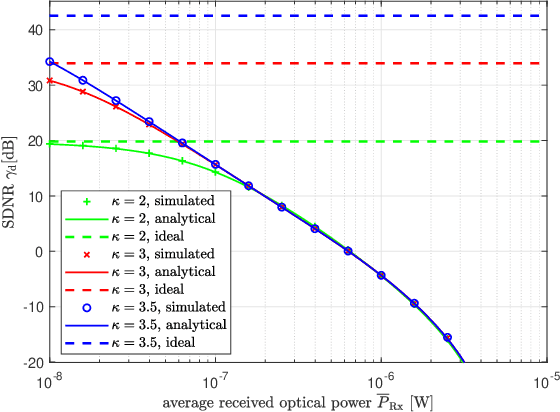
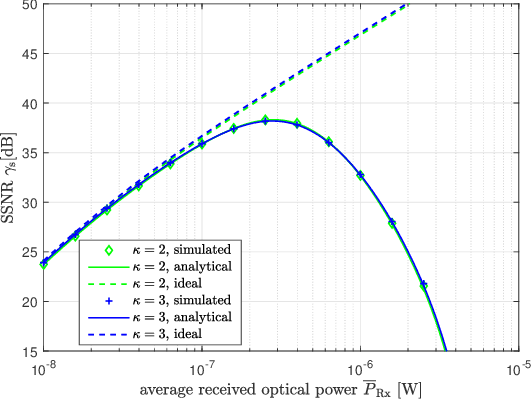
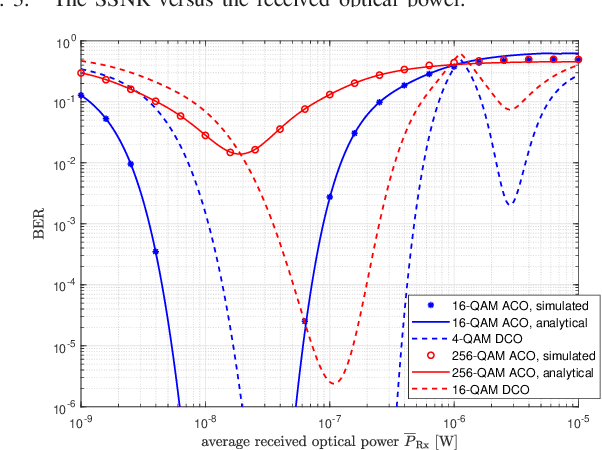
The sensitivity of the optical wireless communication (OWC) can be effectively improved by employing the highly sensitive single-photon avalanche diode (SPAD) arrays. However, the nonlinear distortion introduced by the dead time strongly limits the throughput of the SPAD-based OWC systems. Optical orthogonal frequency division multiplexing (OFDM) can be employed in the systems with SPAD arrays to improve the spectral efficiency. In this work, a theoretical performance analysis of SPAD-based OWC system with asymmetrically-clipped optical OFDM (ACO-OFDM) is presented. The impact of the SPAD nonlinearity on the system performance is investigated. In addition, the comparison of the considered scheme with direct-current-biased optical OFDM (DCO-OFDM) is presented showing the distinct reliable operation regimes of the two schemes. In the low power regimes, ACO-OFDM outperforms DCO-OFDM; whereas, the latter is more preferable in the high power regimes.
Quasistatic contact-rich manipulation via linear complementarity quadratic programming
Oct 25, 2022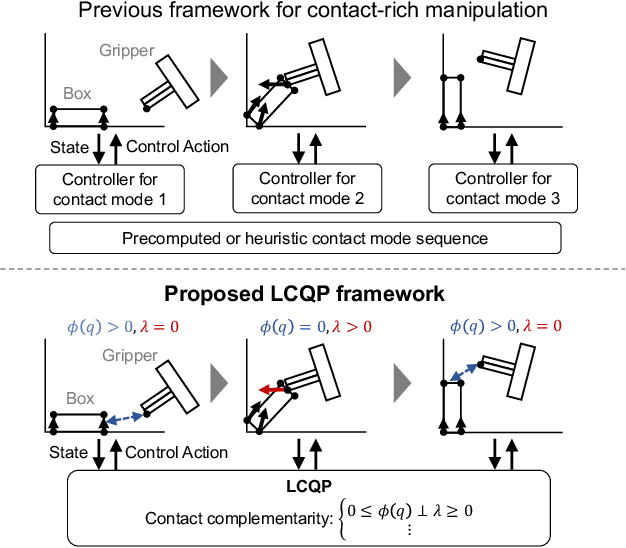
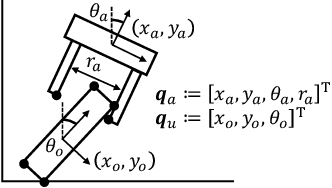
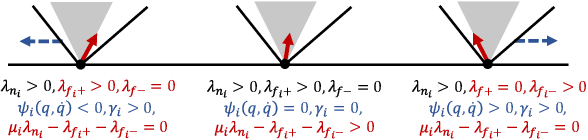
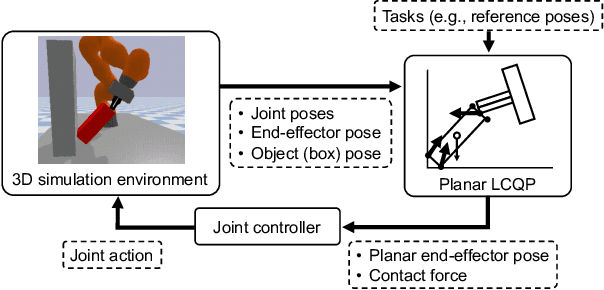
Contact-rich manipulation is challenging due to dynamically-changing physical constraints by the contact mode changes undergone during manipulation. This paper proposes a versatile local planning and control framework for contact-rich manipulation that determines the continuous control action under variable contact modes online. We model the physical characteristics of contact-rich manipulation by quasistatic dynamics and complementarity constraints. We then propose a linear complementarity quadratic program (LCQP) to efficiently determine the control action that implicitly includes the decisions on the contact modes under these constraints. In the LCQP, we relax the complementarity constraints to alleviate ill-conditioned problems that are typically caused by measure noises or model miss-matches. We conduct dynamical simulations on a 3D physical simulator and demonstrate that the proposed method can achieve various contact-rich manipulation tasks by determining the control action including the contact modes in real-time.
From colouring-in to pointillism: revisiting semantic segmentation supervision
Oct 25, 2022
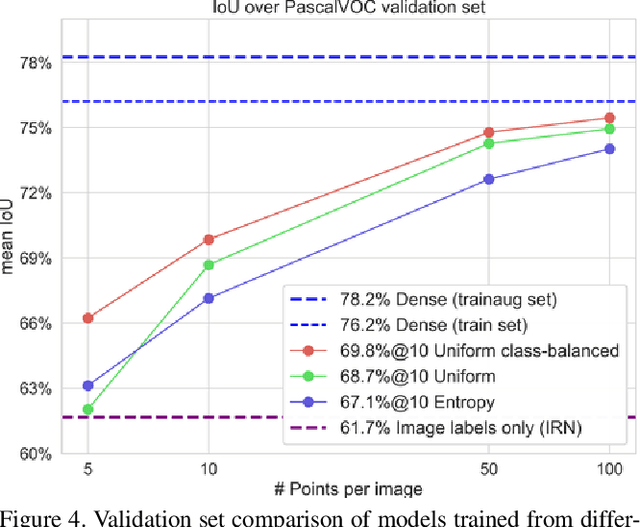
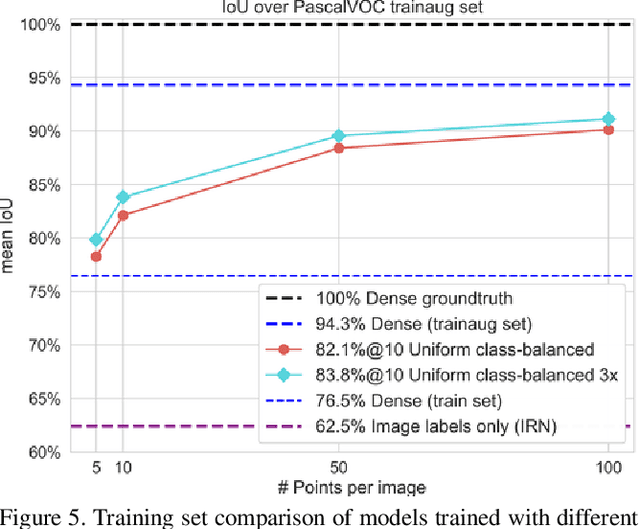
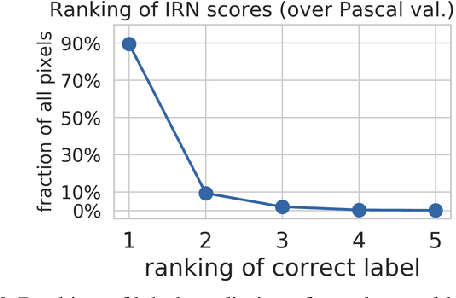
The prevailing paradigm for producing semantic segmentation training data relies on densely labelling each pixel of each image in the training set, akin to colouring-in books. This approach becomes a bottleneck when scaling up in the number of images, classes, and annotators. Here we propose instead a pointillist approach for semantic segmentation annotation, where only point-wise yes/no questions are answered. We explore design alternatives for such an active learning approach, measure the speed and consistency of human annotators on this task, show that this strategy enables training good segmentation models, and that it is suitable for evaluating models at test time. As concrete proof of the scalability of our method, we collected and released 22.6M point labels over 4,171 classes on the Open Images dataset. Our results enable to rethink the semantic segmentation pipeline of annotation, training, and evaluation from a pointillism point of view.
Relaxing the Feature Covariance Assumption: Time-Variant Bounds for Benign Overfitting in Linear Regression
Feb 12, 2022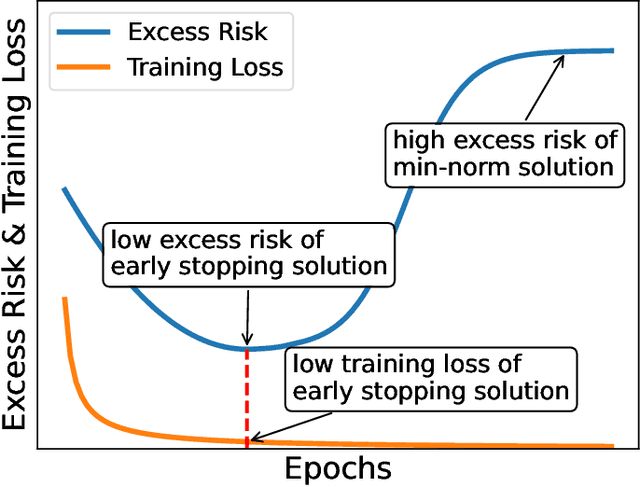
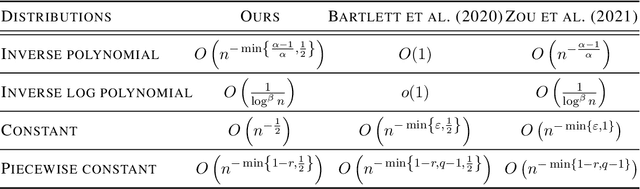
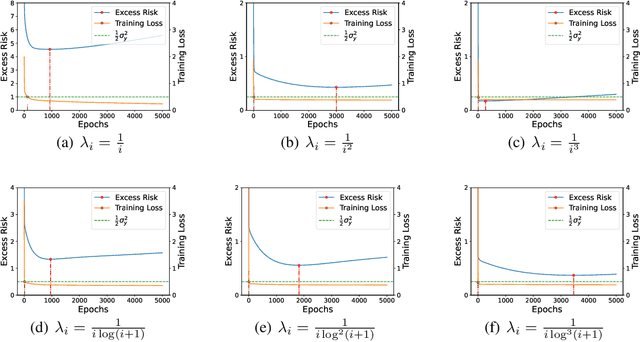
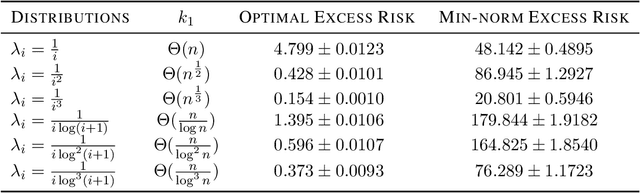
Benign overfitting demonstrates that overparameterized models can perform well on test data while fitting noisy training data. However, it only considers the final min-norm solution in linear regression, which ignores the algorithm information and the corresponding training procedure. In this paper, we generalize the idea of benign overfitting to the whole training trajectory instead of the min-norm solution and derive a time-variant bound based on the trajectory analysis. Starting from the time-variant bound, we further derive a time interval that suffices to guarantee a consistent generalization error for a given feature covariance. Unlike existing approaches, the newly proposed generalization bound is characterized by a time-variant effective dimension of feature covariance. By introducing the time factor, we relax the strict assumption on the feature covariance matrix required in previous benign overfitting under the regimes of overparameterized linear regression with gradient descent. This paper extends the scope of benign overfitting, and experiment results indicate that the proposed bound accords better with empirical evidence.
Closed-loop Control of Catalytic Janus Microrobots
Oct 20, 2022

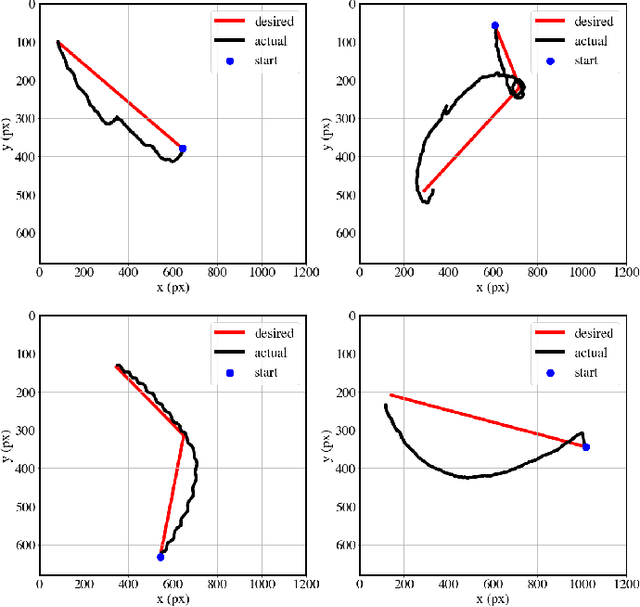
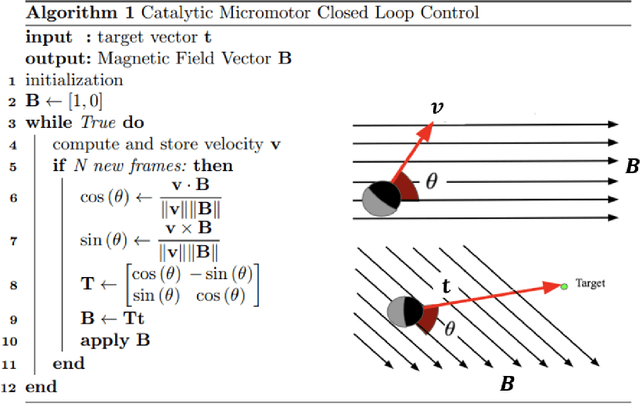
We report a closed-loop control system for paramagnetic catalytically self-propelled Janus microrobots. We achieve this control by employing electromagnetic coils that direct the magnetic field in a desired orientation to steer the microrobots. The microrobots move due to the catalytic decomposition of hydrogen peroxide, during which they align themselves to the magnetic torques applied to them. Because the angle between their direction of motion and their magnetic orientation is a priori unknown, an algorithm is used to determine this angular offset and adjust the magnetic field appropriately. The microrobots are located using real-time particle tracking that integrates with a video camera. A target location or desired trajectory can be drawn by the user for the microrobots to follow.
Play It Back: Iterative Attention for Audio Recognition
Oct 20, 2022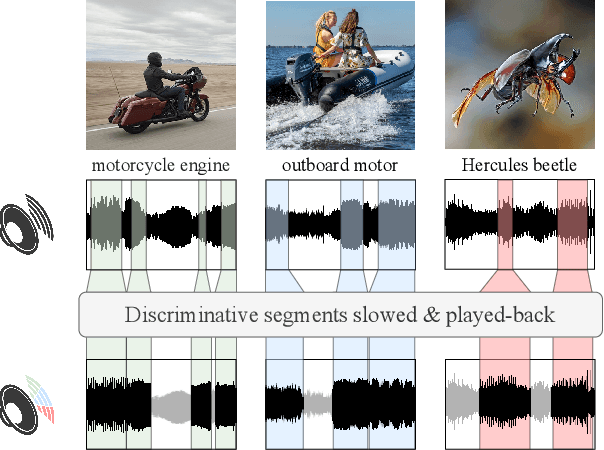
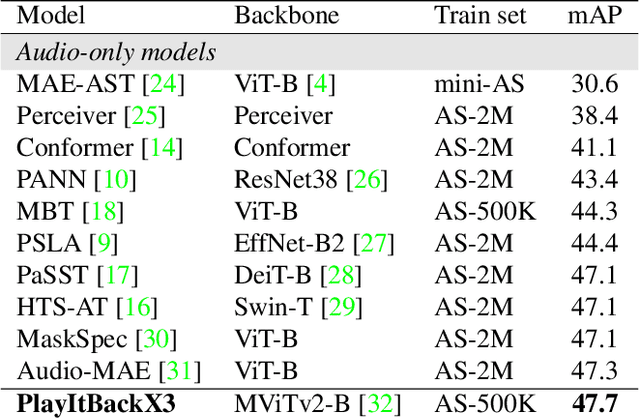
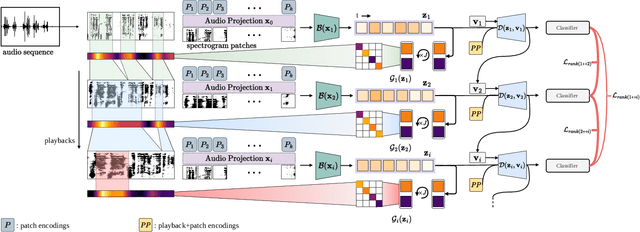
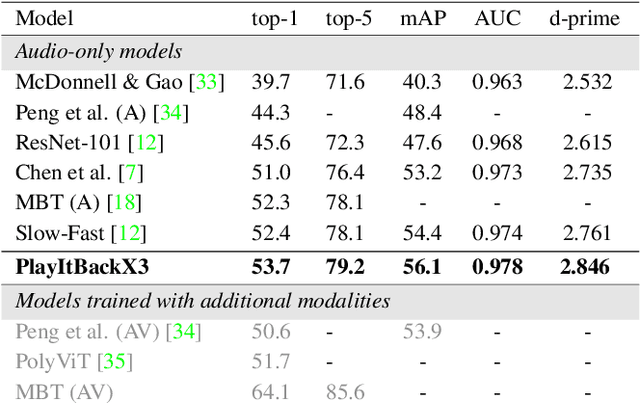
A key function of auditory cognition is the association of characteristic sounds with their corresponding semantics over time. Humans attempting to discriminate between fine-grained audio categories, often replay the same discriminative sounds to increase their prediction confidence. We propose an end-to-end attention-based architecture that through selective repetition attends over the most discriminative sounds across the audio sequence. Our model initially uses the full audio sequence and iteratively refines the temporal segments replayed based on slot attention. At each playback, the selected segments are replayed using a smaller hop length which represents higher resolution features within these segments. We show that our method can consistently achieve state-of-the-art performance across three audio-classification benchmarks: AudioSet, VGG-Sound, and EPIC-KITCHENS-100.
Soil moisture estimation from Sentinel-1 interferometric observations over arid regions
Oct 18, 2022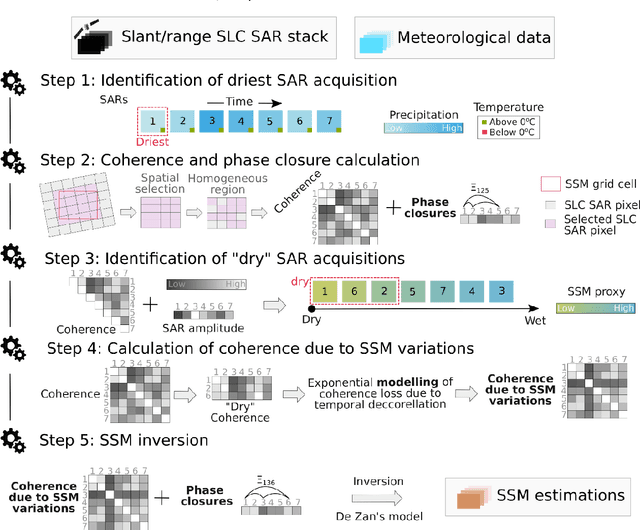
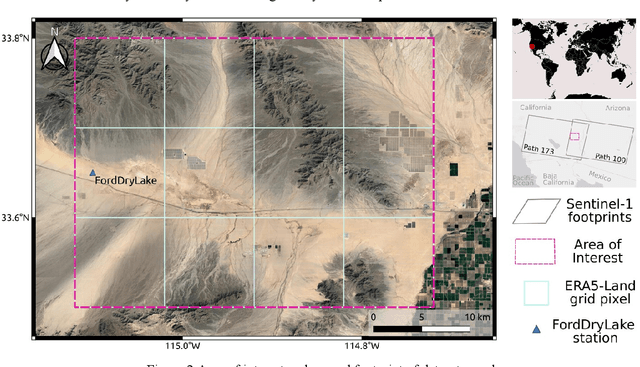
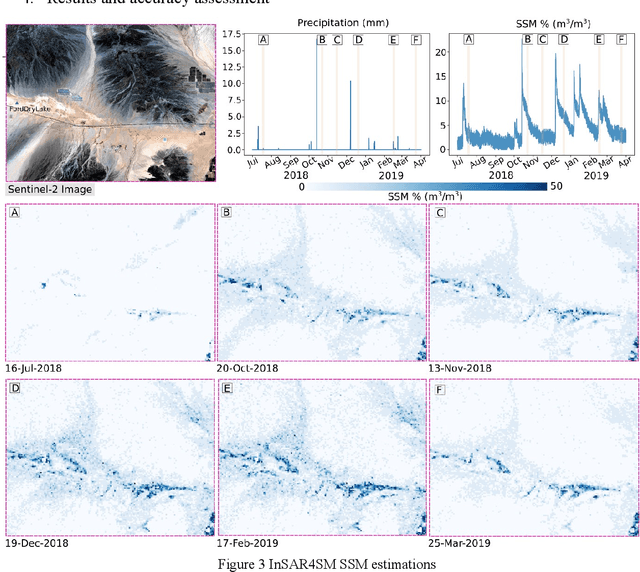
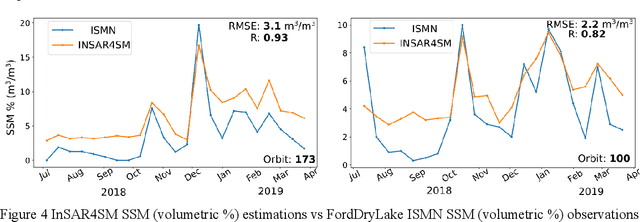
We present a methodology based on interferometric synthetic aperture radar (InSAR) time series analysis that can provide surface (top 5 cm) soil moisture (SSM) estimations. The InSAR time series analysis consists of five processing steps. A co-registered Single Look Complex (SLC) SAR stack as well as meteorological information are required as input of the proposed workflow. In the first step, ice/snow-free and zero-precipitation SAR images are identified using meteorological data. In the second step, construction and phase extraction of distributed scatterers (DSs) (over bare land) is performed. In the third step, for each DS the ordering of surface soil moisture (SSM) levels of SAR acquisitions based on interferometric coherence is calculated. In the fourth step, for each DS the coherence due to SSM variations is calculated. In the fifth step, SSM is estimated by a constrained inversion of an analytical interferometric model using coherence and phase closure information. The implementation of the proposed approach is provided as an open-source software toolbox (INSAR4SM) available at www.github.com/kleok/INSAR4SM. A case study over an arid region in California/Arizona is presented. The proposed workflow was applied in Sentinel- 1 (C-band) VV-polarized InSAR observations. The estimated SSM results were assessed with independent SSM observations from a station of the International Soil Moisture Network (ISMN) (RMSE: 0.027 $m^3/m^3$ R: 0.88) and ERA5-Land reanalysis model data (RMSE: 0.035 $m^3/m^3$ R: 0.71). The proposed methodology was able to provide accurate SSM estimations at high spatial resolution (~250 m). A discussion of the benefits and the limitations of the proposed methodology highlighted the potential of interferometric observables for SSM estimation over arid regions.