 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Monte Carlo EM for Deep Time Series Anomaly Detection
Dec 29, 2021
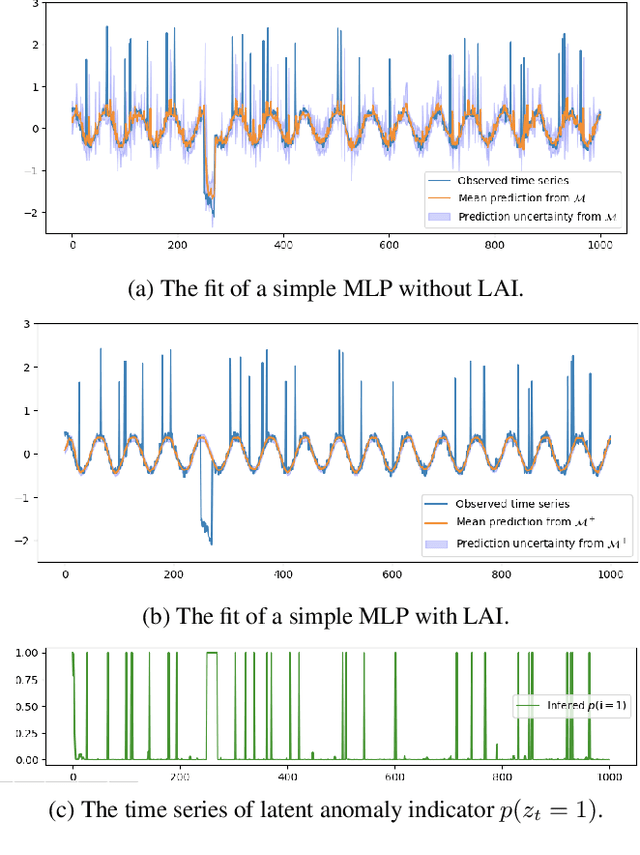


Time series data are often corrupted by outliers or other kinds of anomalies. Identifying the anomalous points can be a goal on its own (anomaly detection), or a means to improving performance of other time series tasks (e.g. forecasting). Recent deep-learning-based approaches to anomaly detection and forecasting commonly assume that the proportion of anomalies in the training data is small enough to ignore, and treat the unlabeled data as coming from the nominal data distribution. We present a simple yet effective technique for augmenting existing time series models so that they explicitly account for anomalies in the training data. By augmenting the training data with a latent anomaly indicator variable whose distribution is inferred while training the underlying model using Monte Carlo EM, our method simultaneously infers anomalous points while improving model performance on nominal data. We demonstrate the effectiveness of the approach by combining it with a simple feed-forward forecasting model. We investigate how anomalies in the train set affect the training of forecasting models, which are commonly used for time series anomaly detection, and show that our method improves the training of the model.
Bias and Extrapolation in Markovian Linear Stochastic Approximation with Constant Stepsizes
Oct 03, 2022
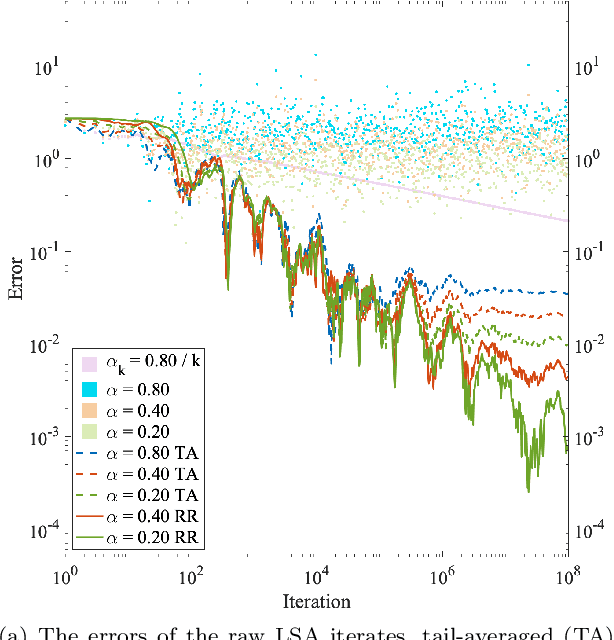
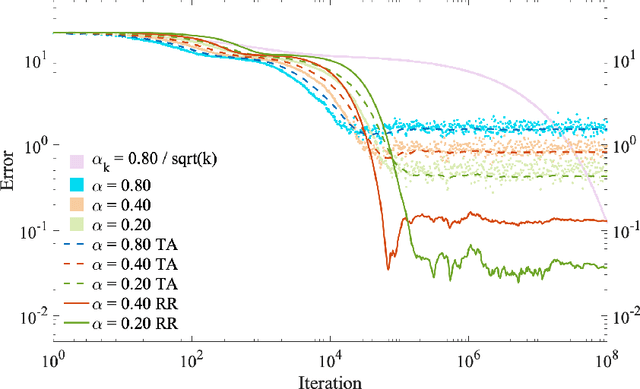
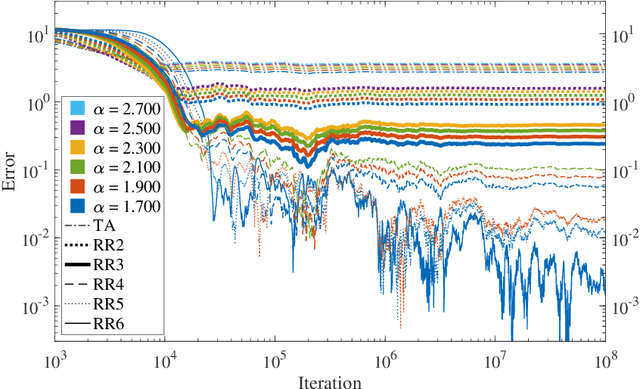
We consider Linear Stochastic Approximation (LSA) with a constant stepsize and Markovian data. Viewing the joint process of the data and LSA iterate as a time-homogeneous Markov chain, we prove its convergence to a unique limiting and stationary distribution in Wasserstein distance and establish non-asymptotic, geometric convergence rates. Furthermore, we show that the bias vector of this limit admits an infinite series expansion with respect to the stepsize. Consequently, the bias is proportional to the stepsize up to higher order terms. This result stands in contrast with LSA under i.i.d. data, for which the bias vanishes. In the reversible chain setting, we provide a general characterization of the relationship between the bias and the mixing time of the Markovian data, establishing that they are roughly proportional to each other. While Polyak-Ruppert tail-averaging reduces the variance of the LSA iterates, it does not affect the bias. The above characterization allows us to show that the bias can be reduced using Richardson-Romberg extrapolation with $m \ge 2$ stepsizes, which eliminates the $m - 1$ leading terms in the bias expansion. This extrapolation scheme leads to an exponentially smaller bias and an improved mean squared error, both in theory and empirically. Our results immediately apply to the Temporal Difference learning algorithm with linear function approximation, Markovian data and constant stepsizes.
LiteDepth: Digging into Fast and Accurate Depth Estimation on Mobile Devices
Sep 02, 2022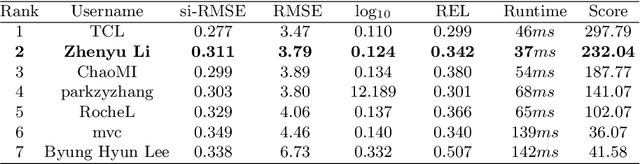
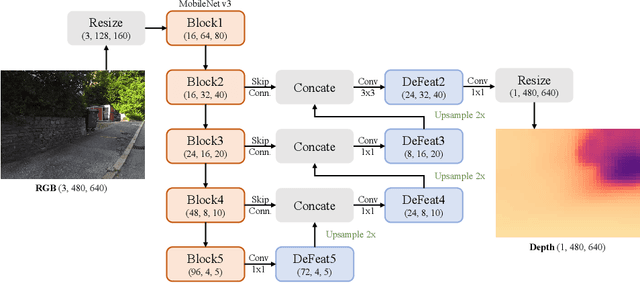


Monocular depth estimation is an essential task in the computer vision community. While tremendous successful methods have obtained excellent results, most of them are computationally expensive and not applicable for real-time on-device inference. In this paper, we aim to address more practical applications of monocular depth estimation, where the solution should consider not only the precision but also the inference time on mobile devices. To this end, we first develop an end-to-end learning-based model with a tiny weight size (1.4MB) and a short inference time (27FPS on Raspberry Pi 4). Then, we propose a simple yet effective data augmentation strategy, called R2 crop, to boost the model performance. Moreover, we observe that the simple lightweight model trained with only one single loss term will suffer from performance bottleneck. To alleviate this issue, we adopt multiple loss terms to provide sufficient constraints during the training stage. Furthermore, with a simple dynamic re-weight strategy, we can avoid the time-consuming hyper-parameter choice of loss terms. Finally, we adopt the structure-aware distillation to further improve the model performance. Notably, our solution named LiteDepth ranks 2nd in the MAI&AIM2022 Monocular Depth Estimation Challenge}, with a si-RMSE of 0.311, an RMSE of 3.79, and the inference time is 37$ms$ tested on the Raspberry Pi 4. Notably, we provide the fastest solution to the challenge. Codes and models will be released at \url{https://github.com/zhyever/LiteDepth}.
Estimating the HEVC Decoding Energy Using the Decoder Processing Time
Mar 03, 2022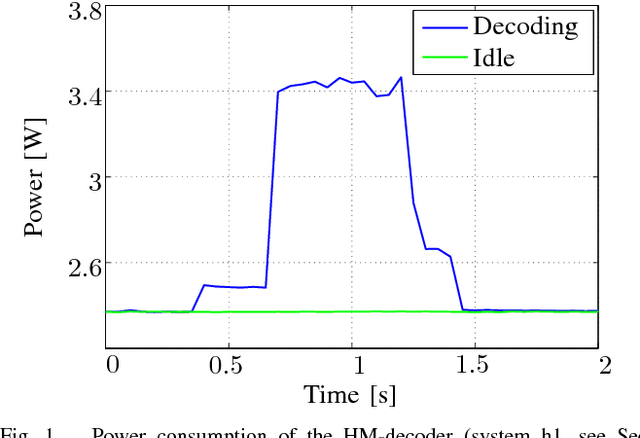
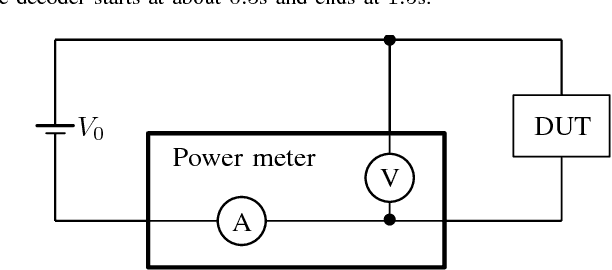
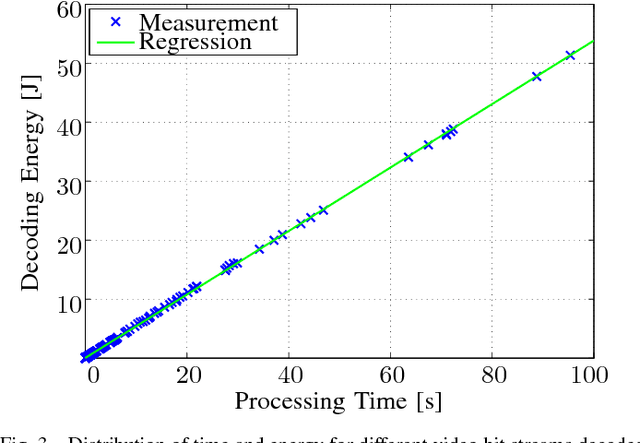
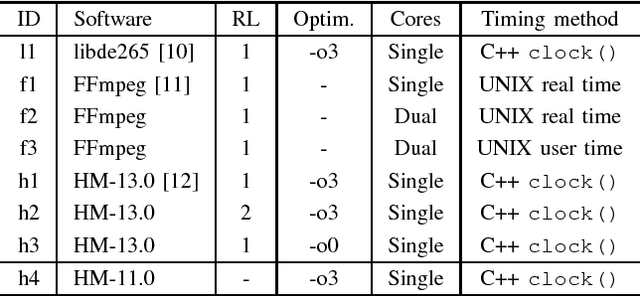
This paper presents a method to accurately estimate the required decoding energy for a given HEVC software decoding solution. We show that the decoder's processing time as returned by common C++ and UNIX functions is a highly suitable parameter to obtain valid estimations for the actual decoding energy. We verify this hypothesis by performing an exhaustive measurement series using different decoder setups and video bit streams. Our findings can be used by developers and researchers in the search for new energy saving video compression algorithms.
* 4 pages, 3 figures
Energy-Efficient D2D-Aided Fog Computing under Probabilistic Time Constraints
Jan 07, 2022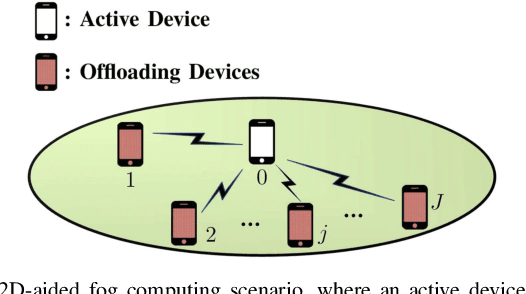
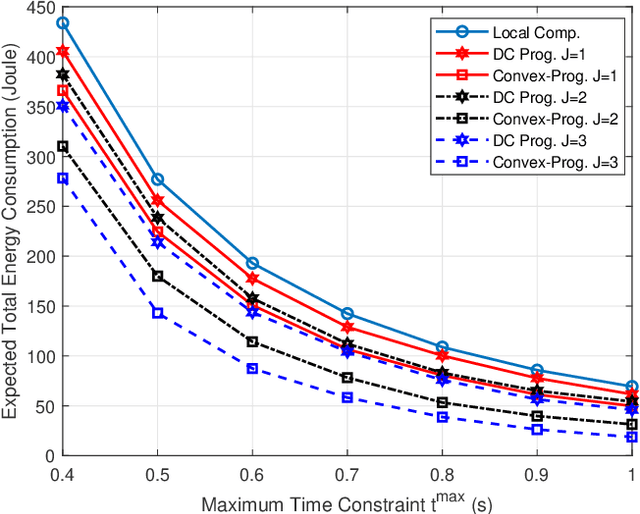
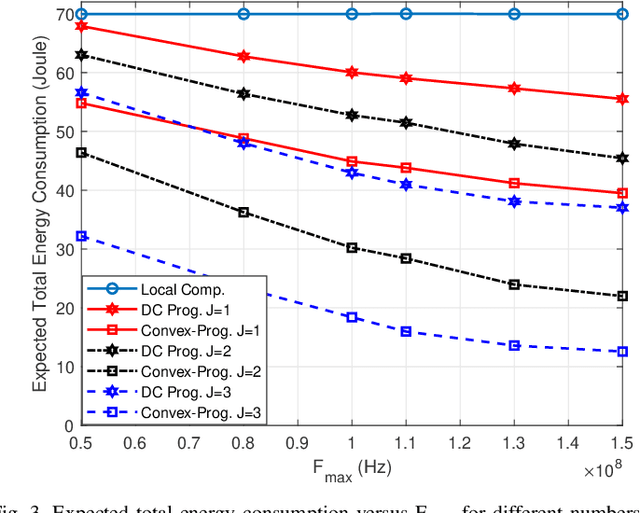
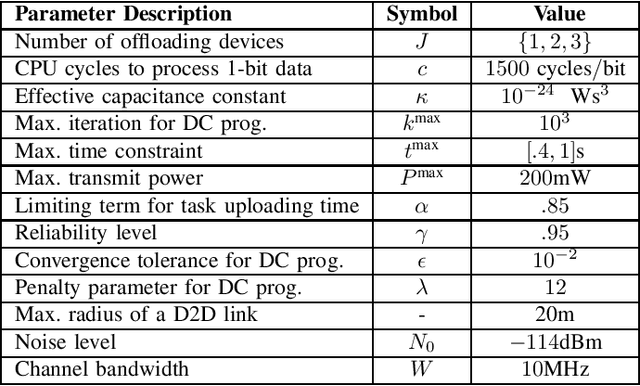
Device-to-device (D2D) communication is an enabling technology for fog computing by allowing the sharing of computation resources between mobile devices. However, temperature variations in the device CPUs affect the computation resources available for task offloading, which unpredictably alters the processing time and energy consumption. In this paper, we address the problem of resource allocation with respect to task partitioning, computation resources and transmit power in a D2D-aided fog computing scenario, aiming to minimize the expected total energy consumption under probabilistic constraints on the processing time. Since the formulated problem is non-convex, we propose two sub-optimal solution methods. The first method is based on difference of convex (DC) programming, which we combine with chance-constraint programming to handle the probabilistic time limitations. Considering that DC programming is dependent on a good initial point, we propose a second method that relies on only convex programming, which eliminates the dependence on user-defined initialization. Simulation results demonstrate that the latter method outperforms the former in terms of energy efficiency and run-time.
HTMOT : Hierarchical Topic Modelling Over Time
Nov 22, 2021
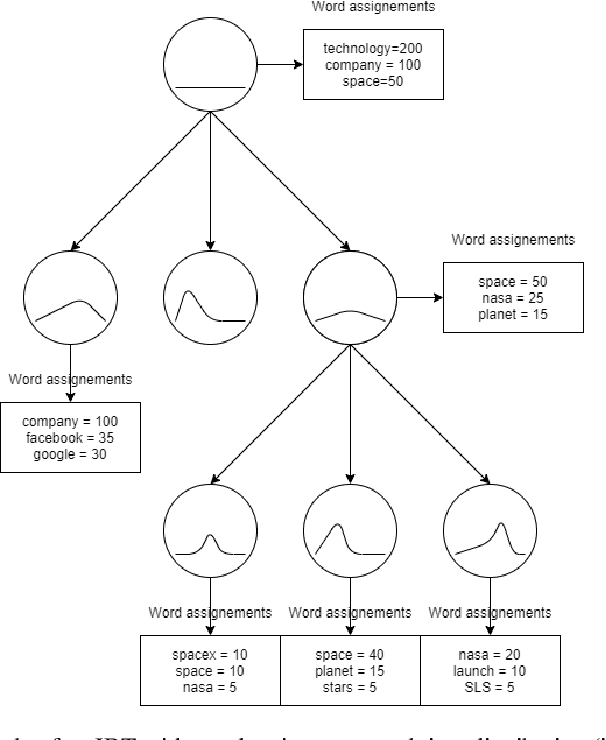
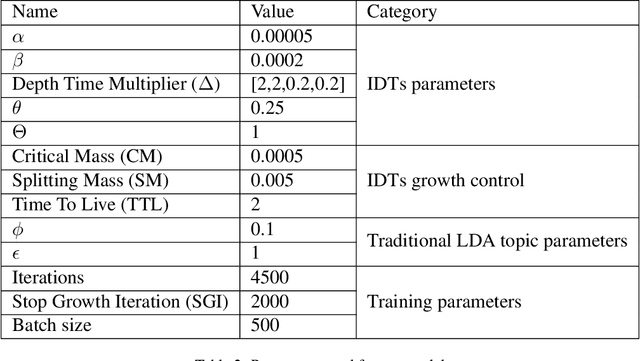
Over the years, topic models have provided an efficient way of extracting insights from text. However, while many models have been proposed, none are able to model topic temporality and hierarchy jointly. Modelling time provide more precise topics by separating lexically close but temporally distinct topics while modelling hierarchy provides a more detailed view of the content of a document corpus. In this study, we therefore propose a novel method, HTMOT, to perform Hierarchical Topic Modelling Over Time. We train HTMOT using a new implementation of Gibbs sampling, which is more efficient. Specifically, we show that only applying time modelling to deep sub-topics provides a way to extract specific stories or events while high level topics extract larger themes in the corpus. Our results show that our training procedure is fast and can extract accurate high-level topics and temporally precise sub-topics. We measured our model's performance using the Word Intrusion task and outlined some limitations of this evaluation method, especially for hierarchical models. As a case study, we focused on the various developments in the space industry in 2020.
Survival Mixture Density Networks
Aug 23, 2022
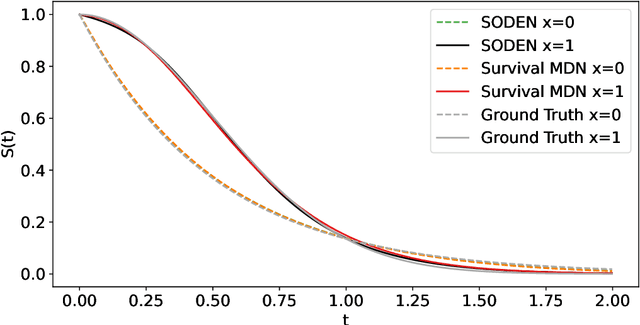
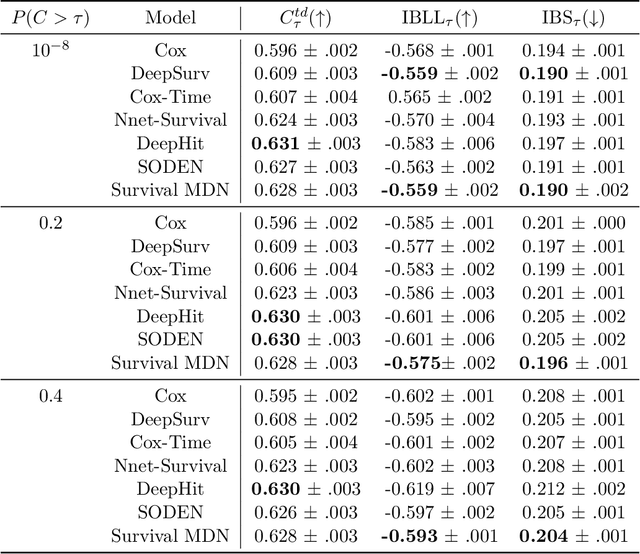
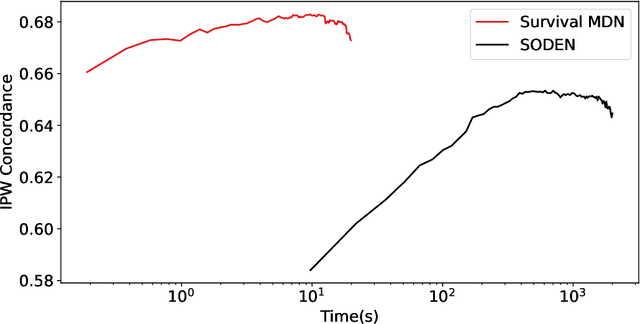
Survival analysis, the art of time-to-event modeling, plays an important role in clinical treatment decisions. Recently, continuous time models built from neural ODEs have been proposed for survival analysis. However, the training of neural ODEs is slow due to the high computational complexity of neural ODE solvers. Here, we propose an efficient alternative for flexible continuous time models, called Survival Mixture Density Networks (Survival MDNs). Survival MDN applies an invertible positive function to the output of Mixture Density Networks (MDNs). While MDNs produce flexible real-valued distributions, the invertible positive function maps the model into the time-domain while preserving a tractable density. Using four datasets, we show that Survival MDN performs better than, or similarly to continuous and discrete time baselines on concordance, integrated Brier score and integrated binomial log-likelihood. Meanwhile, Survival MDNs are also faster than ODE-based models and circumvent binning issues in discrete models.
A covariant, discrete time-frequency representation tailored for zero-based signal detection
Feb 08, 2022
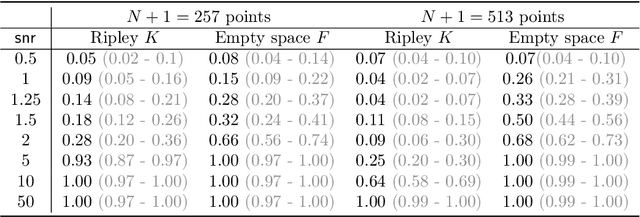

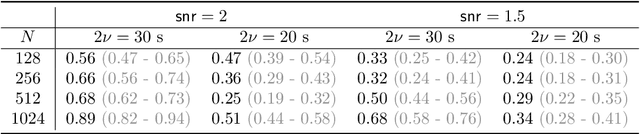
Recent work in time-frequency analysis proposed to switch the focus from the maxima of the spectrogram toward its zeros. The zeros of signals in white Gaussian noise indeed form a random point pattern with a very stable structure. Using modern spatial statistics tools on the pattern of zeros of a spectrogram has led to component disentanglement and signal detection procedures. The major bottlenecks of this approach are the discretization of the Short-Time Fourier Transform and the necessarily bounded observation window in the time-frequency plane. Both impact the estimation of summary statistics of the zeros, which are then used in standard statistical tests. To circumvent these limitations, we propose a generalized time-frequency representation, which we call the Kravchuk transform. It naturally applies to finite signals, i.e., finite-dimensional vectors. The corresponding phase space, instead of the whole time-frequency plane, is compact, and particularly amenable to spatial statistics. On top of this, the Kravchuk transform has several natural properties for signal processing, among which covariance under the action of SO(3), invertibility and symmetry with respect to complex conjugation. We further show that the point process of the zeros of the Kravchuk transform of discrete white Gaussian noise coincides in law with the zeros of the spherical Gaussian Analytic Function. This implies that the law of the zeros is invariant under isometries of the sphere. Elaborating on this theorem, we develop a procedure for signal detection based on the spatial statistics of the zeros of the Kravchuk spectrogram. The statistical power of this procedure is assessed by intensive numerical simulation, and compares favorably with respect to state-of-the-art zeros-based detection procedures. Furthermore it appears to be particularly robust to both low signal-to-noise ratio and small number of samples.
On the Interpolation of Contextualized Term-based Ranking with BM25 for Query-by-Example Retrieval
Oct 11, 2022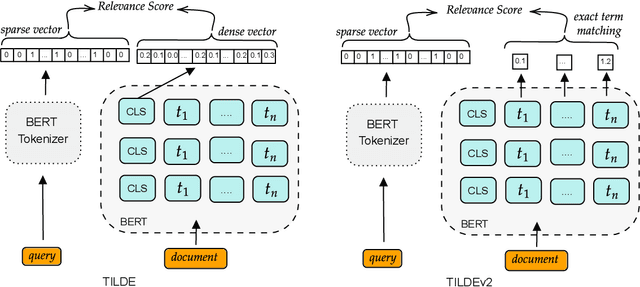
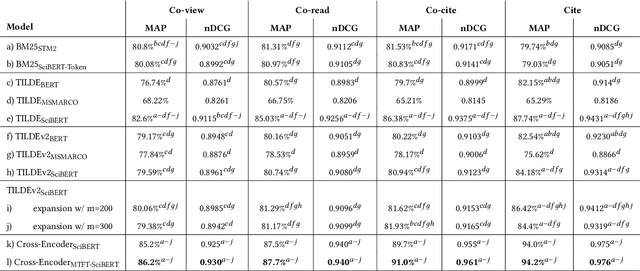
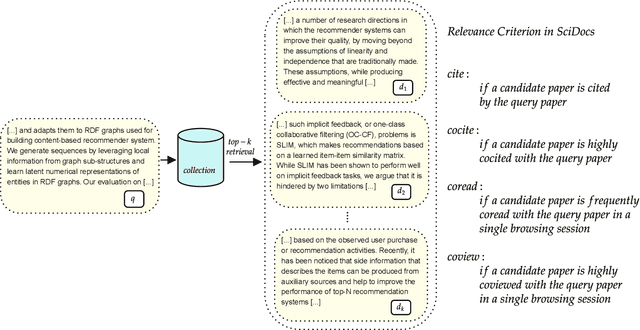
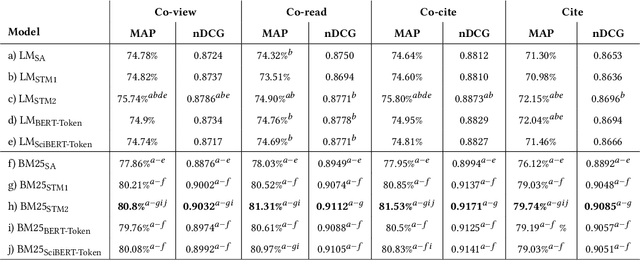
Term-based ranking with pre-trained transformer-based language models has recently gained attention as they bring the contextualization power of transformer models into the highly efficient term-based retrieval. In this work, we examine the generalizability of two of these deep contextualized term-based models in the context of query-by-example (QBE) retrieval in which a seed document acts as the query to find relevant documents. In this setting -- where queries are much longer than common keyword queries -- BERT inference at query time is problematic as it involves quadratic complexity. We investigate TILDE and TILDEv2, both of which leverage BERT tokenizer as their query encoder. With this approach, there is no need for BERT inference at query time, and also the query can be of any length. Our extensive evaluation on the four QBE tasks of SciDocs benchmark shows that in a query-by-example retrieval setting TILDE and TILDEv2 are still less effective than a cross-encoder BERT ranker. However, we observe that BM25 could show a competitive ranking quality compared to TILDE and TILDEv2 which is in contrast to the findings about the relative performance of these three models on retrieval for short queries reported in prior work. This result raises the question about the use of contextualized term-based ranking models being beneficial in QBE setting. We follow-up on our findings by studying the score interpolation between the relevance score from TILDE (TILDEv2) and BM25. We conclude that these two contextualized term-based ranking models capture different relevance signals than BM25 and combining the different term-based rankers results in statistically significant improvements in QBE retrieval. Our work sheds light on the challenges of retrieval settings different from the common evaluation benchmarks.
Mitigating Unintended Memorization in Language Models via Alternating Teaching
Oct 13, 2022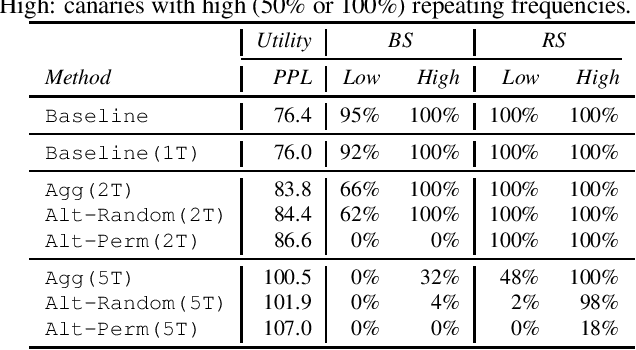
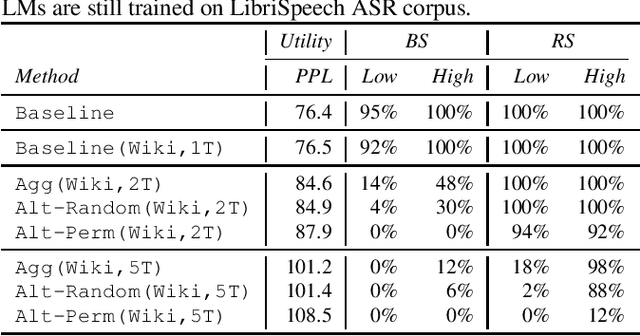
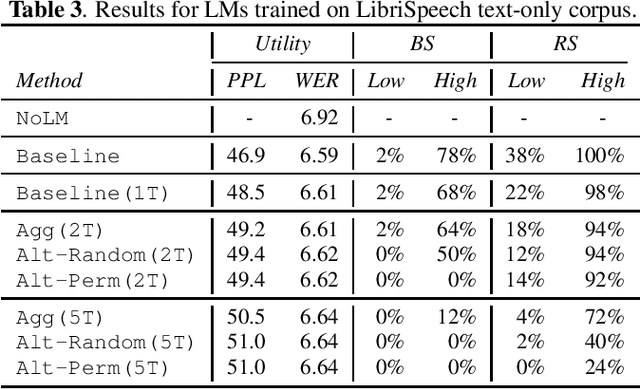
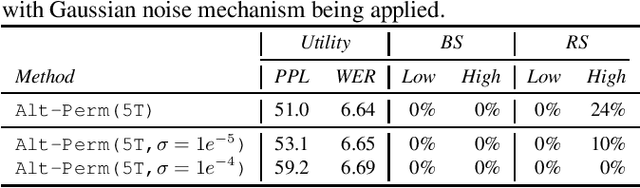
Recent research has shown that language models have a tendency to memorize rare or unique sequences in the training corpora which can thus leak sensitive attributes of user data. We employ a teacher-student framework and propose a novel approach called alternating teaching to mitigate unintended memorization in sequential modeling. In our method, multiple teachers are trained on disjoint training sets whose privacy one wishes to protect, and teachers' predictions supervise the training of a student model in an alternating manner at each time step. Experiments on LibriSpeech datasets show that the proposed method achieves superior privacy-preserving results than other counterparts. In comparison with no prevention for unintended memorization, the overall utility loss is small when training records are sufficient.