 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-Efficient Strategies for Expanding Hate Speech Detection into Under-Resourced Languages
Oct 20, 2022
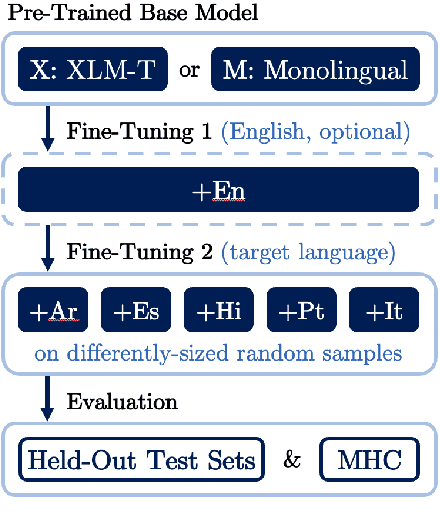
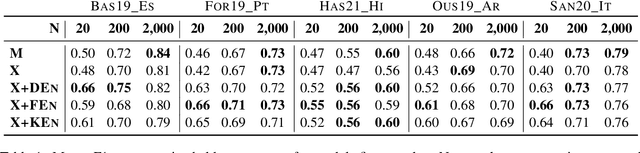
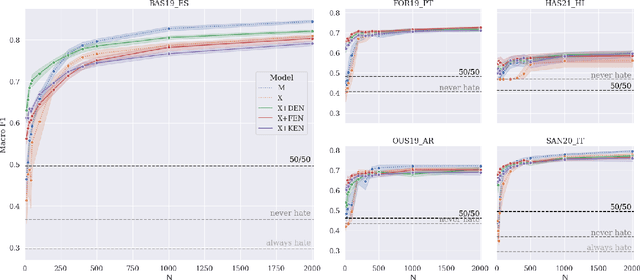
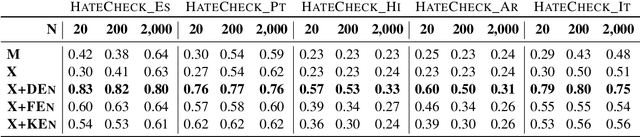
Hate speech is a global phenomenon, but most hate speech datasets so far focus on English-language content. This hinders the development of more effective hate speech detection models in hundreds of languages spoken by billions across the world. More data is needed, but annotating hateful content is expensive, time-consuming and potentially harmful to annotators. To mitigate these issues, we explore data-efficient strategies for expanding hate speech detection into under-resourced languages. In a series of experiments with mono- and multilingual models across five non-English languages, we find that 1) a small amount of target-language fine-tuning data is needed to achieve strong performance, 2) the benefits of using more such data decrease exponentially, and 3) initial fine-tuning on readily-available English data can partially substitute target-language data and improve model generalisability. Based on these findings, we formulate actionable recommendations for hate speech detection in low-resource language settings.
On Representations of Mean-Field Variational Inference
Oct 20, 2022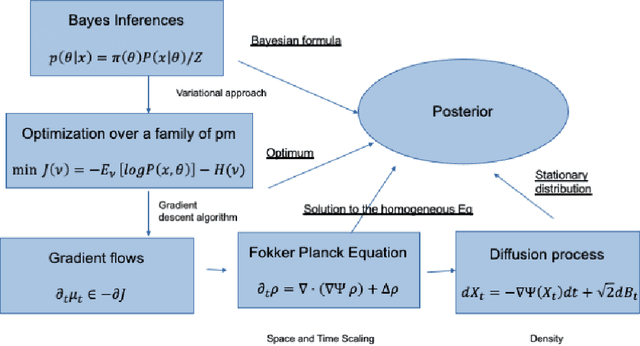
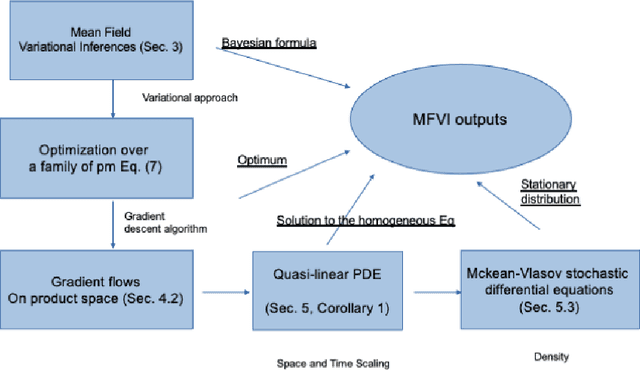
The mean field variational inference (MFVI) formulation restricts the general Bayesian inference problem to the subspace of product measures. We present a framework to analyze MFVI algorithms, which is inspired by a similar development for general variational Bayesian formulations. Our approach enables the MFVI problem to be represented in three different manners: a gradient flow on Wasserstein space, a system of Fokker-Planck-like equations and a diffusion process. Rigorous guarantees are established to show that a time-discretized implementation of the coordinate ascent variational inference algorithm in the product Wasserstein space of measures yields a gradient flow in the limit. A similar result is obtained for their associated densities, with the limit being given by a quasi-linear partial differential equation. A popular class of practical algorithms falls in this framework, which provides tools to establish convergence. We hope this framework could be used to guarantee convergence of algorithms in a variety of approaches, old and new, to solve variational inference problems.
Speech Enhancement with Perceptually-motivated Optimization and Dual Transformations
Sep 24, 2022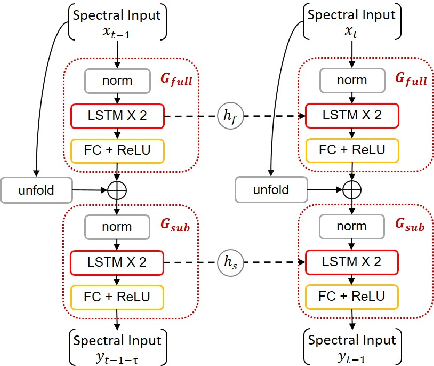
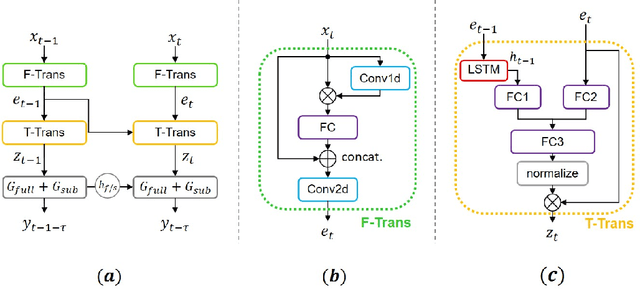
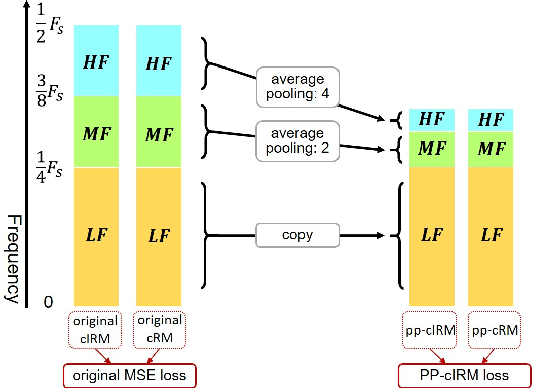
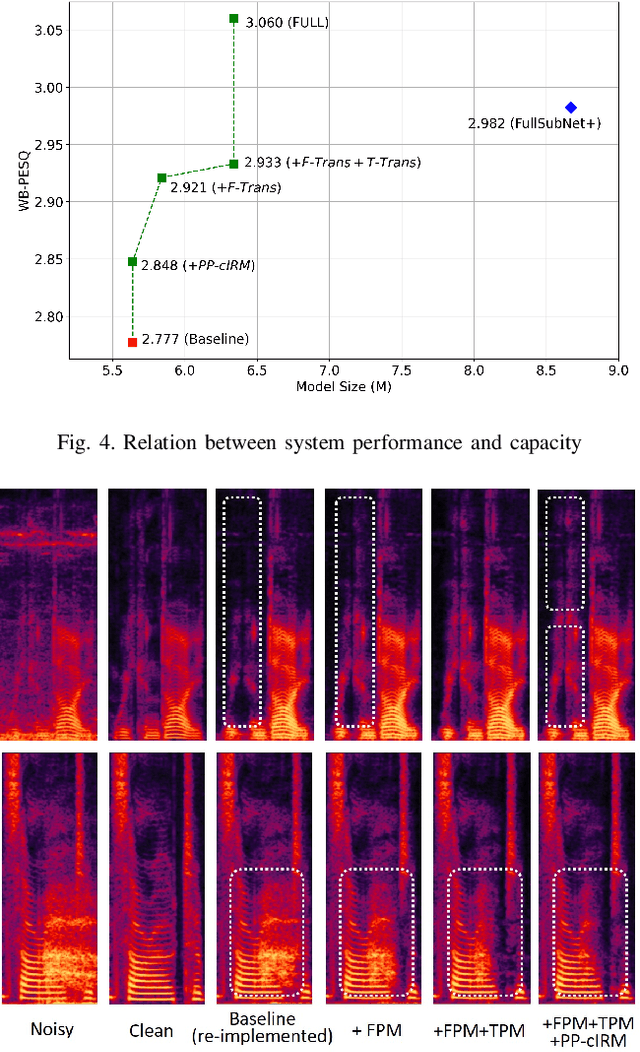
To address the monaural speech enhancement problem, numerous research studies have been conducted to enhance speech via operations either in time-domain on the inner-domain learned from the speech mixture or in time--frequency domain on the fixed full-band short time Fourier transform (STFT) spectrograms. Very recently, a few studies on sub-band based speech enhancement have been proposed. By enhancing speech via operations on sub-band spectrograms, those studies demonstrated competitive performances on the benchmark dataset of DNS2020. Despite attractive, this new research direction has not been fully explored and there is still room for improvement. As such, in this study, we delve into the latest research direction and propose a sub-band based speech enhancement system with perceptually-motivated optimization and dual transformations, called PT-FSE. Specially, our proposed PT-FSE model improves its backbone, a full-band and sub-band fusion model, by three efforts. First, we design a frequency transformation module that aims to strengthen the global frequency correlation. Then a temporal transformation is introduced to capture long range temporal contexts. Lastly, a novel loss, with leverage of properties of human auditory perception, is proposed to facilitate the model to focus on low frequency enhancement. To validate the effectiveness of our proposed model, extensive experiments are conducted on the DNS2020 dataset. Experimental results show that our PT-FSE system achieves substantial improvements over its backbone, but also outperforms the current state-of-the-art while being 27\% smaller than the SOTA. With average NB-PESQ of 3.57 on the benchmark dataset, our system offers the best speech enhancement results reported till date.
Panoptic-PHNet: Towards Real-Time and High-Precision LiDAR Panoptic Segmentation via Clustering Pseudo Heatmap
May 14, 2022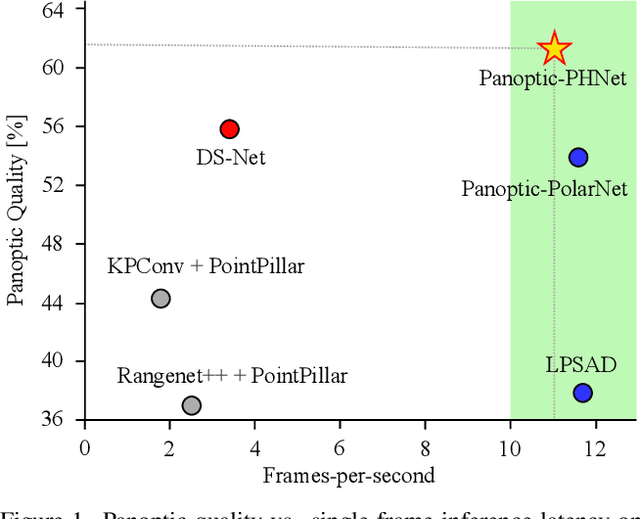
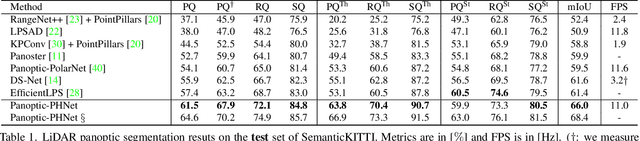
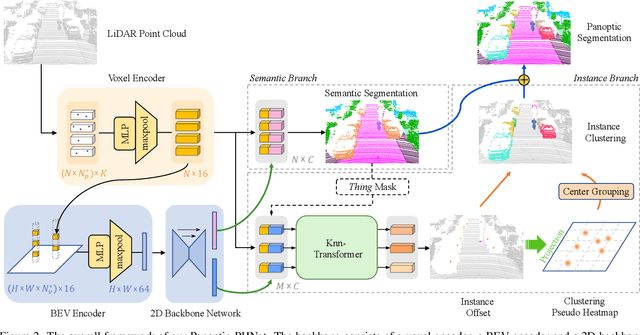
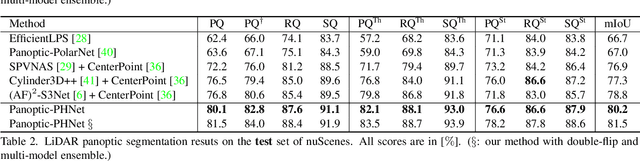
As a rising task, panoptic segmentation is faced with challenges in both semantic segmentation and instance segmentation. However, in terms of speed and accuracy, existing LiDAR methods in the field are still limited. In this paper, we propose a fast and high-performance LiDAR-based framework, referred to as Panoptic-PHNet, with three attractive aspects: 1) We introduce a clustering pseudo heatmap as a new paradigm, which, followed by a center grouping module, yields instance centers for efficient clustering without object-level learning tasks. 2) A knn-transformer module is proposed to model the interaction among foreground points for accurate offset regression. 3) For backbone design, we fuse the fine-grained voxel features and the 2D Bird's Eye View (BEV) features with different receptive fields to utilize both detailed and global information. Extensive experiments on both SemanticKITTI dataset and nuScenes dataset show that our Panoptic-PHNet surpasses state-of-the-art methods by remarkable margins with a real-time speed. We achieve the 1st place on the public leaderboard of SemanticKITTI and leading performance on the recently released leaderboard of nuScenes.
HTMOT : Hierarchical Topic Modelling Over Time
Nov 22, 2021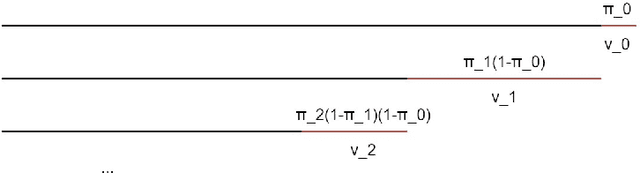
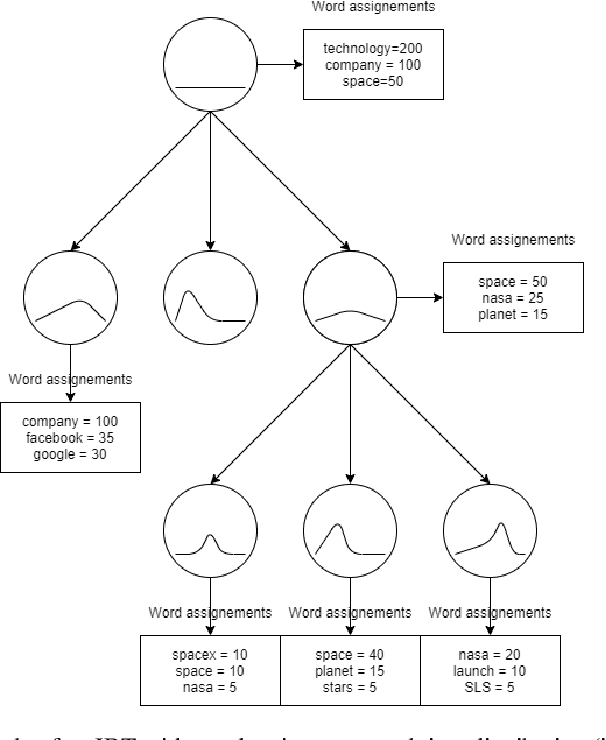
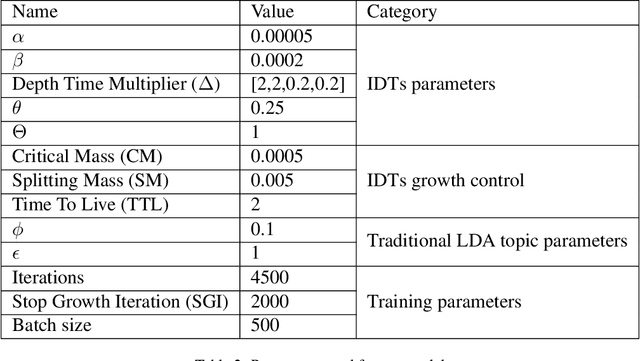
Over the years, topic models have provided an efficient way of extracting insights from text. However, while many models have been proposed, none are able to model topic temporality and hierarchy jointly. Modelling time provide more precise topics by separating lexically close but temporally distinct topics while modelling hierarchy provides a more detailed view of the content of a document corpus. In this study, we therefore propose a novel method, HTMOT, to perform Hierarchical Topic Modelling Over Time. We train HTMOT using a new implementation of Gibbs sampling, which is more efficient. Specifically, we show that only applying time modelling to deep sub-topics provides a way to extract specific stories or events while high level topics extract larger themes in the corpus. Our results show that our training procedure is fast and can extract accurate high-level topics and temporally precise sub-topics. We measured our model's performance using the Word Intrusion task and outlined some limitations of this evaluation method, especially for hierarchical models. As a case study, we focused on the various developments in the space industry in 2020.
Centerpoints Are All You Need in Overhead Imagery
Oct 04, 2022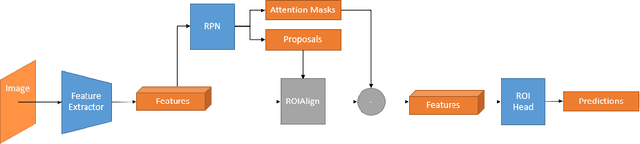
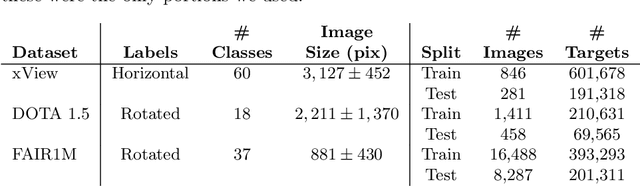

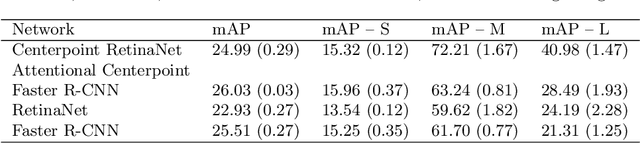
Labeling data to use for training object detectors is expensive and time consuming. Publicly available overhead datasets for object detection are labeled with image-aligned bounding boxes, object-aligned bounding boxes, or object masks, but it is not clear whether such detailed labeling is necessary. To test the idea, we developed novel single- and two-stage network architectures that use centerpoints for labeling. In this paper we show that these architectures achieve nearly equivalent performance to approaches using more detailed labeling on three overhead object detection datasets.
Energy-Efficient D2D-Aided Fog Computing under Probabilistic Time Constraints
Jan 07, 2022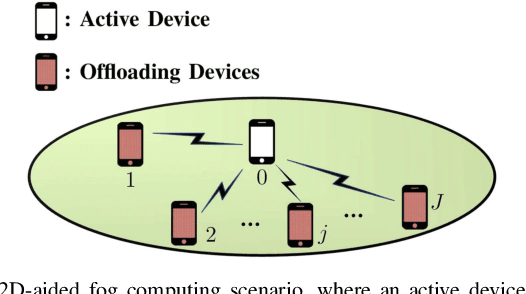
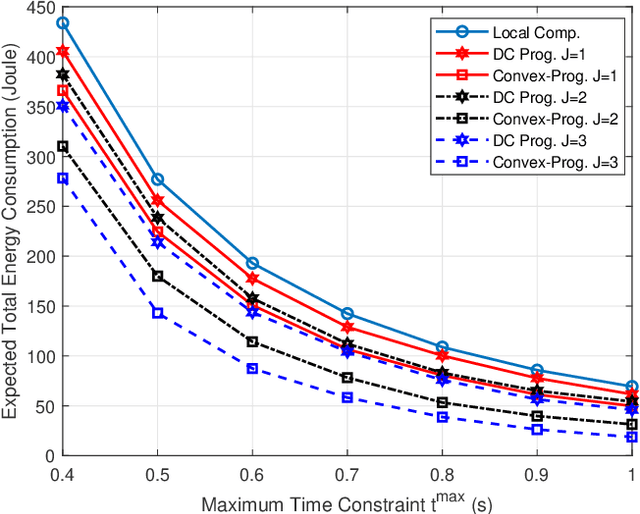
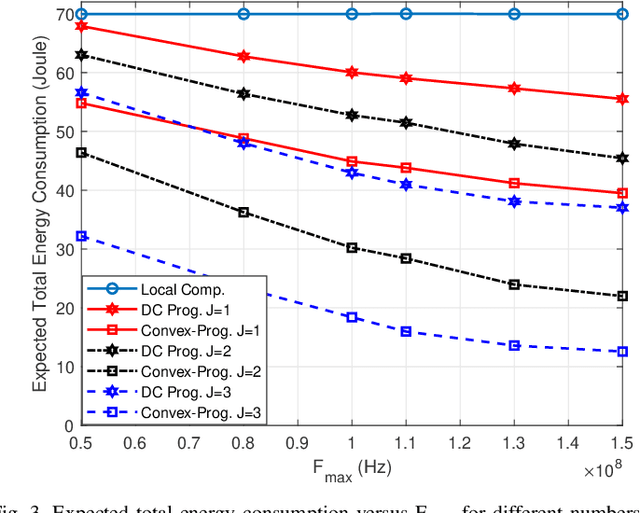
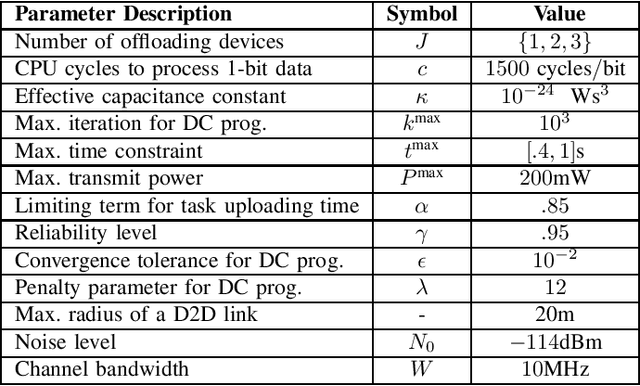
Device-to-device (D2D) communication is an enabling technology for fog computing by allowing the sharing of computation resources between mobile devices. However, temperature variations in the device CPUs affect the computation resources available for task offloading, which unpredictably alters the processing time and energy consumption. In this paper, we address the problem of resource allocation with respect to task partitioning, computation resources and transmit power in a D2D-aided fog computing scenario, aiming to minimize the expected total energy consumption under probabilistic constraints on the processing time. Since the formulated problem is non-convex, we propose two sub-optimal solution methods. The first method is based on difference of convex (DC) programming, which we combine with chance-constraint programming to handle the probabilistic time limitations. Considering that DC programming is dependent on a good initial point, we propose a second method that relies on only convex programming, which eliminates the dependence on user-defined initialization. Simulation results demonstrate that the latter method outperforms the former in terms of energy efficiency and run-time.
Estimating the HEVC Decoding Energy Using the Decoder Processing Time
Mar 03, 2022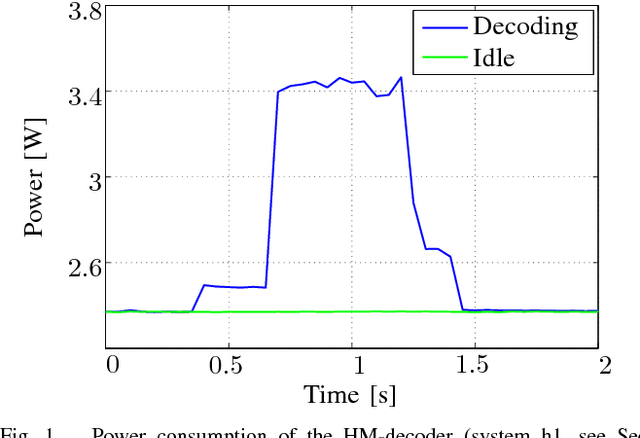
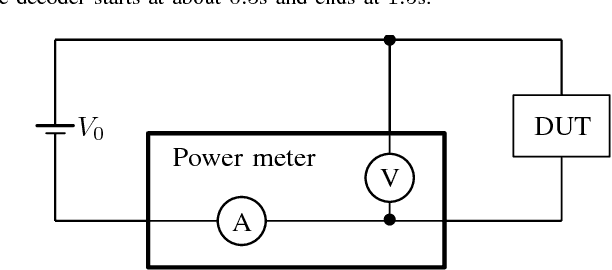
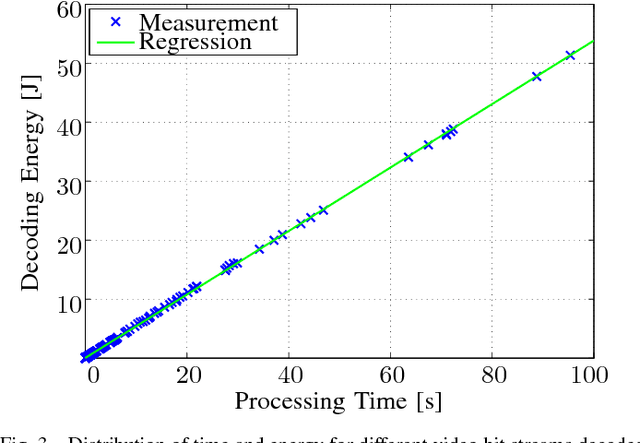
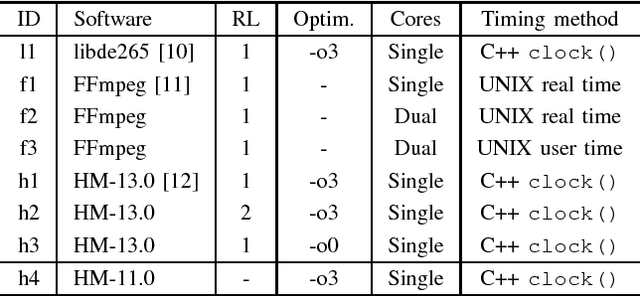
This paper presents a method to accurately estimate the required decoding energy for a given HEVC software decoding solution. We show that the decoder's processing time as returned by common C++ and UNIX functions is a highly suitable parameter to obtain valid estimations for the actual decoding energy. We verify this hypothesis by performing an exhaustive measurement series using different decoder setups and video bit streams. Our findings can be used by developers and researchers in the search for new energy saving video compression algorithms.
* 4 pages, 3 figures
A covariant, discrete time-frequency representation tailored for zero-based signal detection
Feb 08, 2022
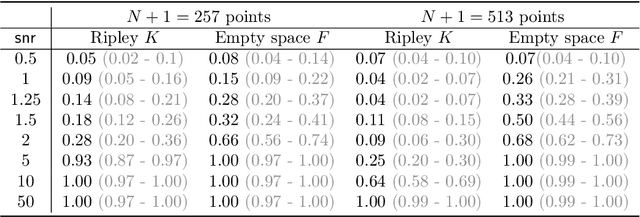

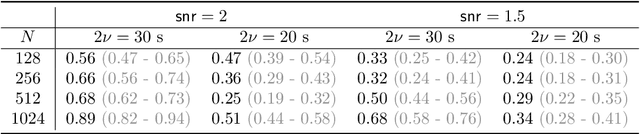
Recent work in time-frequency analysis proposed to switch the focus from the maxima of the spectrogram toward its zeros. The zeros of signals in white Gaussian noise indeed form a random point pattern with a very stable structure. Using modern spatial statistics tools on the pattern of zeros of a spectrogram has led to component disentanglement and signal detection procedures. The major bottlenecks of this approach are the discretization of the Short-Time Fourier Transform and the necessarily bounded observation window in the time-frequency plane. Both impact the estimation of summary statistics of the zeros, which are then used in standard statistical tests. To circumvent these limitations, we propose a generalized time-frequency representation, which we call the Kravchuk transform. It naturally applies to finite signals, i.e., finite-dimensional vectors. The corresponding phase space, instead of the whole time-frequency plane, is compact, and particularly amenable to spatial statistics. On top of this, the Kravchuk transform has several natural properties for signal processing, among which covariance under the action of SO(3), invertibility and symmetry with respect to complex conjugation. We further show that the point process of the zeros of the Kravchuk transform of discrete white Gaussian noise coincides in law with the zeros of the spherical Gaussian Analytic Function. This implies that the law of the zeros is invariant under isometries of the sphere. Elaborating on this theorem, we develop a procedure for signal detection based on the spatial statistics of the zeros of the Kravchuk spectrogram. The statistical power of this procedure is assessed by intensive numerical simulation, and compares favorably with respect to state-of-the-art zeros-based detection procedures. Furthermore it appears to be particularly robust to both low signal-to-noise ratio and small number of samples.
WeakIdent: Weak formulation for Identifying Differential Equations using Narrow-fit and Trimming
Nov 06, 2022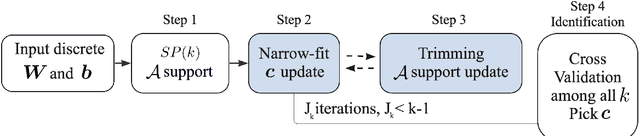


Data-driven identification of differential equations is an interesting but challenging problem, especially when the given data are corrupted by noise. When the governing differential equation is a linear combination of various differential terms, the identification problem can be formulated as solving a linear system, with the feature matrix consisting of linear and nonlinear terms multiplied by a coefficient vector. This product is equal to the time derivative term, and thus generates dynamical behaviors. The goal is to identify the correct terms that form the equation to capture the dynamics of the given data. We propose a general and robust framework to recover differential equations using a weak formulation, for both ordinary and partial differential equations (ODEs and PDEs). The weak formulation facilitates an efficient and robust way to handle noise. For a robust recovery against noise and the choice of hyper-parameters, we introduce two new mechanisms, narrow-fit and trimming, for the coefficient support and value recovery, respectively. For each sparsity level, Subspace Pursuit is utilized to find an initial set of support from the large dictionary. Then, we focus on highly dynamic regions (rows of the feature matrix), and error normalize the feature matrix in the narrow-fit step. The support is further updated via trimming of the terms that contribute the least. Finally, the support set of features with the smallest Cross-Validation error is chosen as the result. A comprehensive set of numerical experiments are presented for both systems of ODEs and PDEs with various noise levels. The proposed method gives a robust recovery of the coefficients, and a significant denoising effect which can handle up to $100\%$ noise-to-signal ratio for some equations. We compare the proposed method with several state-of-the-art algorithms for the recovery of differential equations.