 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AI-assisted Tagging of Deepfake Audio Calls using Challenge-Response
Feb 28, 2024
Scammers are aggressively leveraging AI voice-cloning technology for social engineering attacks, a situation significantly worsened by the advent of audio Real-time Deepfakes (RTDFs). RTDFs can clone a target's voice in real-time over phone calls, making these interactions highly interactive and thus far more convincing. Our research confidently addresses the gap in the existing literature on deepfake detection, which has largely been ineffective against RTDF threats. We introduce a robust challenge-response-based method to detect deepfake audio calls, pioneering a comprehensive taxonomy of audio challenges. Our evaluation pitches 20 prospective challenges against a leading voice-cloning system. We have compiled a novel open-source challenge dataset with contributions from 100 smartphone and desktop users, yielding 18,600 original and 1.6 million deepfake samples. Through rigorous machine and human evaluations of this dataset, we achieved a deepfake detection rate of 86% and an 80% AUC score, respectively. Notably, utilizing a set of 11 challenges significantly enhances detection capabilities. Our findings reveal that combining human intuition with machine precision offers complementary advantages. Consequently, we have developed an innovative human-AI collaborative system that melds human discernment with algorithmic accuracy, boosting final joint accuracy to 82.9%. This system highlights the significant advantage of AI-assisted pre-screening in call verification processes. Samples can be heard at https://mittalgovind.github.io/autch-samples/
Enhancing Hyperspectral Images via Diffusion Model and Group-Autoencoder Super-resolution Network
Feb 27, 2024Existing hyperspectral image (HSI) super-resolution (SR) methods struggle to effectively capture the complex spectral-spatial relationships and low-level details, while diffusion models represent a promising generative model known for their exceptional performance in modeling complex relations and learning high and low-level visual features. The direct application of diffusion models to HSI SR is hampered by challenges such as difficulties in model convergence and protracted inference time. In this work, we introduce a novel Group-Autoencoder (GAE) framework that synergistically combines with the diffusion model to construct a highly effective HSI SR model (DMGASR). Our proposed GAE framework encodes high-dimensional HSI data into low-dimensional latent space where the diffusion model works, thereby alleviating the difficulty of training the diffusion model while maintaining band correlation and considerably reducing inference time. Experimental results on both natural and remote sensing hyperspectral datasets demonstrate that the proposed method is superior to other state-of-the-art methods both visually and metrically.
Emergency Caching: Coded Caching-based Reliable Map Transmission in Emergency Networks
Feb 27, 2024Many rescue missions demand effective perception and real-time decision making, which highly rely on effective data collection and processing. In this study, we propose a three-layer architecture of emergency caching networks focusing on data collection and reliable transmission, by leveraging efficient perception and edge caching technologies. Based on this architecture, we propose a disaster map collection framework that integrates coded caching technologies. Our framework strategically caches coded fragments of maps across unmanned aerial vehicles (UAVs), fostering collaborative uploading for augmented transmission reliability. Additionally, we establish a comprehensive probability model to assess the effective recovery area of disaster maps. Towards the goal of utility maximization, we propose a deep reinforcement learning (DRL) based algorithm that jointly makes decisions about cooperative UAVs selection, bandwidth allocation and coded caching parameter adjustment, accommodating the real-time map updates in a dynamic disaster situation. Our proposed scheme is more effective than the non-coding caching scheme, as validated by simulation.
Enhancing Programming Error Messages in Real Time with Generative AI
Feb 12, 2024Generative AI is changing the way that many disciplines are taught, including computer science. Researchers have shown that generative AI tools are capable of solving programming problems, writing extensive blocks of code, and explaining complex code in simple terms. Particular promise has been shown in using generative AI to enhance programming error messages. Both students and instructors have complained for decades that these messages are often cryptic and difficult to understand. Yet recent work has shown that students make fewer repeated errors when enhanced via GPT-4. We extend this work by implementing feedback from ChatGPT for all programs submitted to our automated assessment tool, Athene, providing help for compiler, run-time, and logic errors. Our results indicate that adding generative AI to an automated assessment tool does not necessarily make it better and that design of the interface matters greatly to the usability of the feedback that GPT-4 provided.
JMLR: Joint Medical LLM and Retrieval Training for Enhancing Reasoning and Professional Question Answering Capability
Mar 02, 2024With the explosive growth of medical data and the rapid development of artificial intelligence technology, precision medicine has emerged as a key to enhancing the quality and efficiency of healthcare services. In this context, Large Language Models (LLMs) play an increasingly vital role in medical knowledge acquisition and question-answering systems. To further improve the performance of these systems in the medical domain, we introduce an innovative method that jointly trains an Information Retrieval (IR) system and an LLM during the fine-tuning phase. This approach, which we call Joint Medical LLM and Retrieval Training (JMLR), is designed to overcome the challenges faced by traditional models in handling medical question-answering tasks. By employing a synchronized training mechanism, JMLR reduces the demand for computational resources and enhances the model's ability to leverage medical knowledge for reasoning and answering questions. Our experimental results demonstrate that JMLR-13B (81.2% on Amboos, 61.3% on MedQA) outperforms models using conventional pre-training and fine-tuning Meditron-70B (76.4% on AMBOSS, 60.3% on MedQA). For models of the same 7B scale, JMLR-7B(68.7% on Amboos, 51.7% on MedQA) significantly outperforms other public models (Meditron-7B: 50.1%, 47.9%), proving its superiority in terms of cost (our training time: 37 hours, traditional method: 144 hours), efficiency, and effectiveness in medical question-answering tasks. Through this work, we provide a new and efficient knowledge enhancement tool for healthcare, demonstrating the great potential of integrating IR and LLM training in precision medical information retrieval and question-answering systems.
REWIND Dataset: Privacy-preserving Speaking Status Segmentation from Multimodal Body Movement Signals in the Wild
Mar 02, 2024

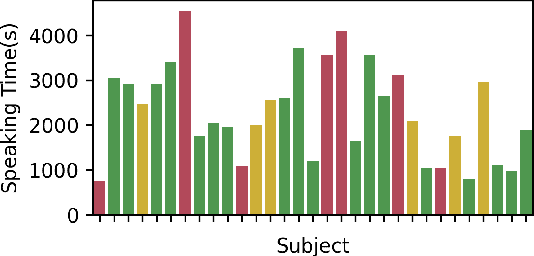

Recognizing speaking in humans is a central task towards understanding social interactions. Ideally, speaking would be detected from individual voice recordings, as done previously for meeting scenarios. However, individual voice recordings are hard to obtain in the wild, especially in crowded mingling scenarios due to cost, logistics, and privacy concerns. As an alternative, machine learning models trained on video and wearable sensor data make it possible to recognize speech by detecting its related gestures in an unobtrusive, privacy-preserving way. These models themselves should ideally be trained using labels obtained from the speech signal. However, existing mingling datasets do not contain high quality audio recordings. Instead, speaking status annotations have often been inferred by human annotators from video, without validation of this approach against audio-based ground truth. In this paper we revisit no-audio speaking status estimation by presenting the first publicly available multimodal dataset with high-quality individual speech recordings of 33 subjects in a professional networking event. We present three baselines for no-audio speaking status segmentation: a) from video, b) from body acceleration (chest-worn accelerometer), c) from body pose tracks. In all cases we predict a 20Hz binary speaking status signal extracted from the audio, a time resolution not available in previous datasets. In addition to providing the signals and ground truth necessary to evaluate a wide range of speaking status detection methods, the availability of audio in REWIND makes it suitable for cross-modality studies not feasible with previous mingling datasets. Finally, our flexible data consent setup creates new challenges for multimodal systems under missing modalities.
A comprehensive cross-language framework for harmful content detection with the aid of sentiment analysis
Mar 02, 2024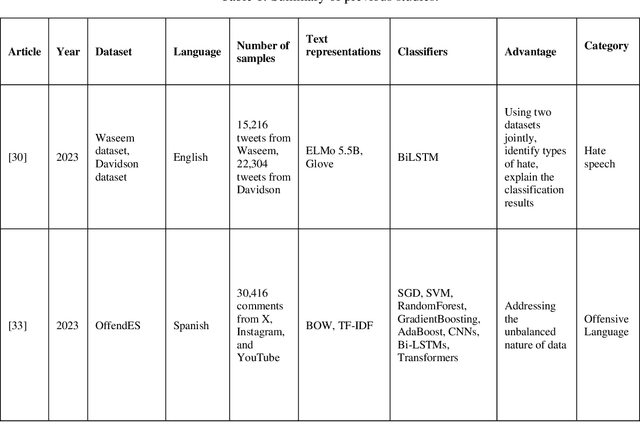
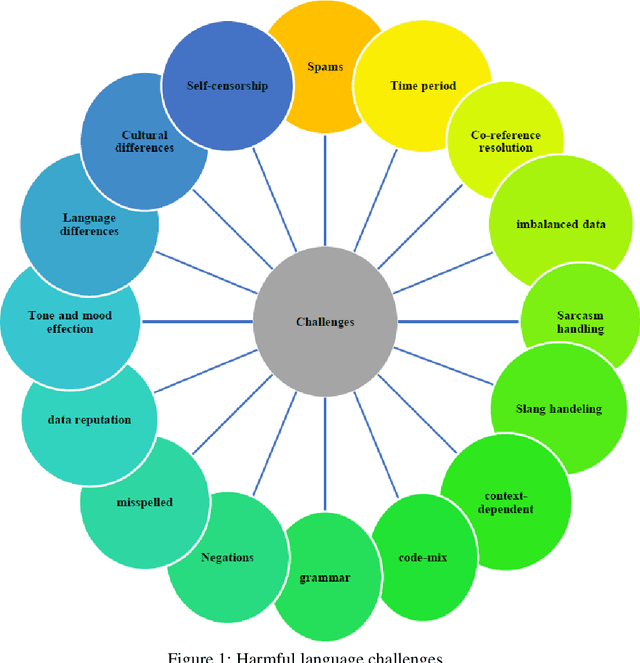
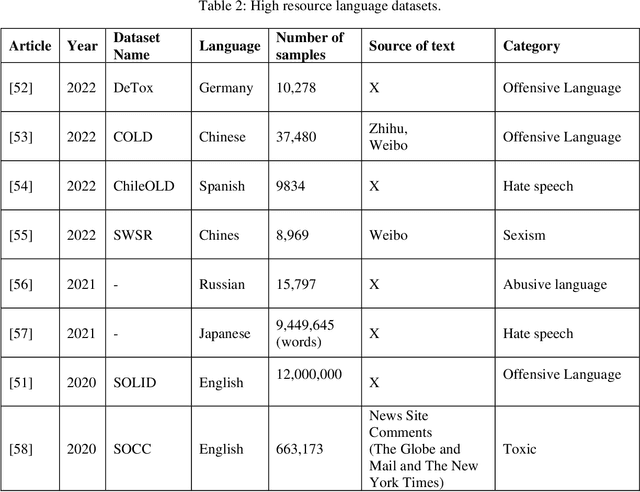
In today's digital world, social media plays a significant role in facilitating communication and content sharing. However, the exponential rise in user-generated content has led to challenges in maintaining a respectful online environment. In some cases, users have taken advantage of anonymity in order to use harmful language, which can negatively affect the user experience and pose serious social problems. Recognizing the limitations of manual moderation, automatic detection systems have been developed to tackle this problem. Nevertheless, several obstacles persist, including the absence of a universal definition for harmful language, inadequate datasets across languages, the need for detailed annotation guideline, and most importantly, a comprehensive framework. This study aims to address these challenges by introducing, for the first time, a detailed framework adaptable to any language. This framework encompasses various aspects of harmful language detection. A key component of the framework is the development of a general and detailed annotation guideline. Additionally, the integration of sentiment analysis represents a novel approach to enhancing harmful language detection. Also, a definition of harmful language based on the review of different related concepts is presented. To demonstrate the effectiveness of the proposed framework, its implementation in a challenging low-resource language is conducted. We collected a Persian dataset and applied the annotation guideline for harmful detection and sentiment analysis. Next, we present baseline experiments utilizing machine and deep learning methods to set benchmarks. Results prove the framework's high performance, achieving an accuracy of 99.4% in offensive language detection and 66.2% in sentiment analysis.
A Phase Transition in Diffusion Models Reveals the Hierarchical Nature of Data
Feb 26, 2024Understanding the structure of real data is paramount in advancing modern deep-learning methodologies. Natural data such as images are believed to be composed of features organised in a hierarchical and combinatorial manner, which neural networks capture during learning. Recent advancements show that diffusion models can generate high-quality images, hinting at their ability to capture this underlying structure. We study this phenomenon in a hierarchical generative model of data. We find that the backward diffusion process acting after a time $t$ is governed by a phase transition at some threshold time, where the probability of reconstructing high-level features, like the class of an image, suddenly drops. Instead, the reconstruction of low-level features, such as specific details of an image, evolves smoothly across the whole diffusion process. This result implies that at times beyond the transition, the class has changed but the generated sample may still be composed of low-level elements of the initial image. We validate these theoretical insights through numerical experiments on class-unconditional ImageNet diffusion models. Our analysis characterises the relationship between time and scale in diffusion models and puts forward generative models as powerful tools to model combinatorial data properties.
DCVSMNet: Double Cost Volume Stereo Matching Network
Feb 26, 2024We introduce Double Cost Volume Stereo Matching Network(DCVSMNet) which is a novel architecture characterised by by two small upper (group-wise) and lower (norm correlation) cost volumes. Each cost volume is processed separately, and a coupling module is proposed to fuse the geometry information extracted from the upper and lower cost volumes. DCVSMNet is a fast stereo matching network with a 67 ms inference time and strong generalization ability which can produce competitive results compared to state-of-the-art methods. The results on several bench mark datasets show that DCVSMNet achieves better accuracy than methods such as CGI-Stereo and BGNet at the cost of greater inference time.
Contextual Stochastic Vehicle Routing with Time Windows
Feb 10, 2024We study the vehicle routing problem with time windows (VRPTW) and stochastic travel times, in which the decision-maker observes related contextual information, represented as feature variables, before making routing decisions. Despite the extensive literature on stochastic VRPs, the integration of feature variables has received limited attention in this context. We introduce the contextual stochastic VRPTW, which minimizes the total transportation cost and expected late arrival penalties conditioned on the observed features. Since the joint distribution of travel times and features is unknown, we present novel data-driven prescriptive models that use historical data to provide an approximate solution to the problem. We distinguish the prescriptive models between point-based approximation, sample average approximation, and penalty-based approximation, each taking a different perspective on dealing with stochastic travel times and features. We develop specialized branch-price-and-cut algorithms to solve these data-driven prescriptive models. In our computational experiments, we compare the out-of-sample cost performance of different methods on instances with up to one hundred customers. Our results show that, surprisingly, a feature-dependent sample average approximation outperforms existing and novel methods in most settings.