 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AutoTS: Automatic Time Series Forecasting Model Design Based on Two-Stage Pruning
Mar 26, 2022
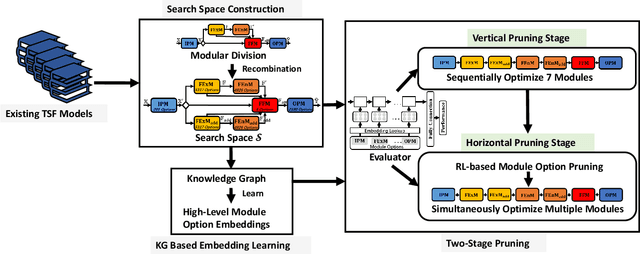
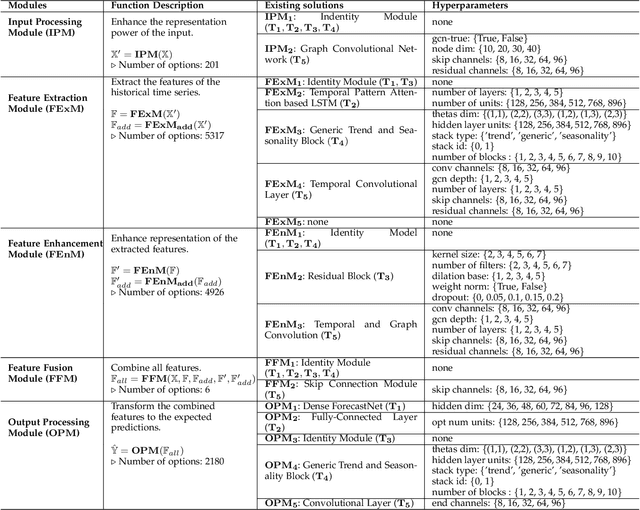
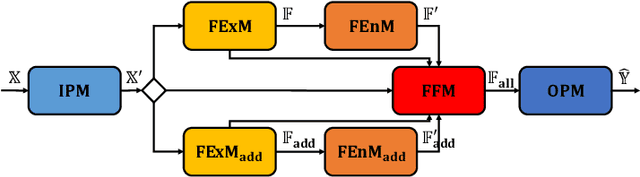

Automatic Time Series Forecasting (TSF) model design which aims to help users to efficiently design suitable forecasting model for the given time series data scenarios, is a novel research topic to be urgently solved. In this paper, we propose AutoTS algorithm trying to utilize the existing design skills and design efficient search methods to effectively solve this problem. In AutoTS, we extract effective design experience from the existing TSF works. We allow the effective combination of design experience from different sources, so as to create an effective search space containing a variety of TSF models to support different TSF tasks. Considering the huge search space, in AutoTS, we propose a two-stage pruning strategy to reduce the search difficulty and improve the search efficiency. In addition, in AutoTS, we introduce the knowledge graph to reveal associations between module options. We make full use of these relational information to learn higher-level features of each module option, so as to further improve the search quality. Extensive experimental results show that AutoTS is well-suited for the TSF area. It is more efficient than the existing neural architecture search algorithms, and can quickly design powerful TSF model better than the manually designed ones.
Deep Multi-Branch Aggregation Network for Real-Time Semantic Segmentation in Street Scenes
Mar 08, 2022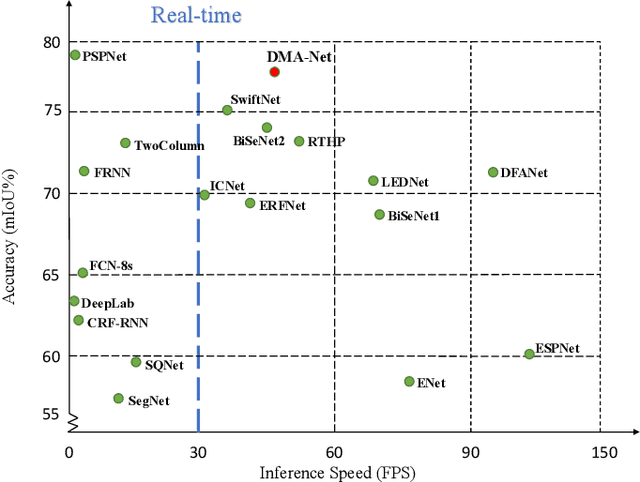


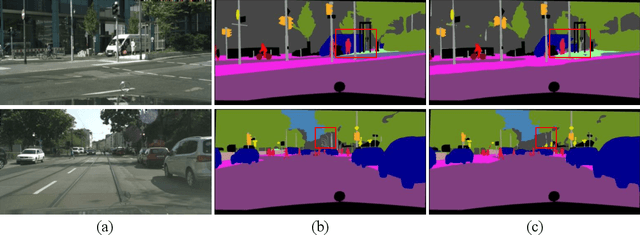
Real-time semantic segmentation, which aims to achieve high segmentation accuracy at real-time inference speed, has received substantial attention over the past few years. However, many state-of-the-art real-time semantic segmentation methods tend to sacrifice some spatial details or contextual information for fast inference, thus leading to degradation in segmentation quality. In this paper, we propose a novel Deep Multi-branch Aggregation Network (called DMA-Net) based on the encoder-decoder structure to perform real-time semantic segmentation in street scenes. Specifically, we first adopt ResNet-18 as the encoder to efficiently generate various levels of feature maps from different stages of convolutions. Then, we develop a Multi-branch Aggregation Network (MAN) as the decoder to effectively aggregate different levels of feature maps and capture the multi-scale information. In MAN, a lattice enhanced residual block is designed to enhance feature representations of the network by taking advantage of the lattice structure. Meanwhile, a feature transformation block is introduced to explicitly transform the feature map from the neighboring branch before feature aggregation. Moreover, a global context block is used to exploit the global contextual information. These key components are tightly combined and jointly optimized in a unified network. Extensive experimental results on the challenging Cityscapes and CamVid datasets demonstrate that our proposed DMA-Net respectively obtains 77.0% and 73.6% mean Intersection over Union (mIoU) at the inference speed of 46.7 FPS and 119.8 FPS by only using a single NVIDIA GTX 1080Ti GPU. This shows that DMA-Net provides a good tradeoff between segmentation quality and speed for semantic segmentation in street scenes.
LongShortNet: Exploring Temporal and Semantic Features Fusion in Streaming Perception
Oct 27, 2022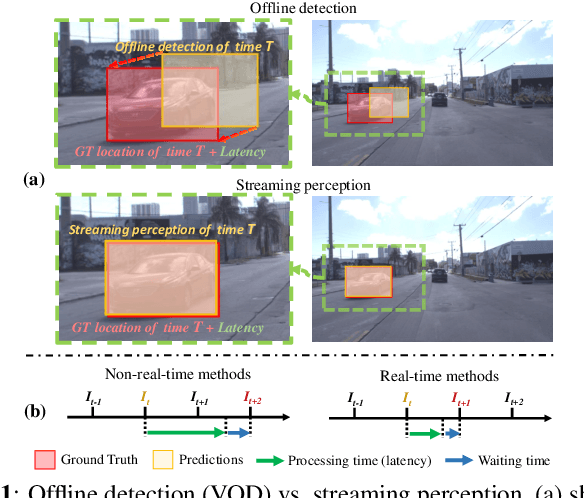

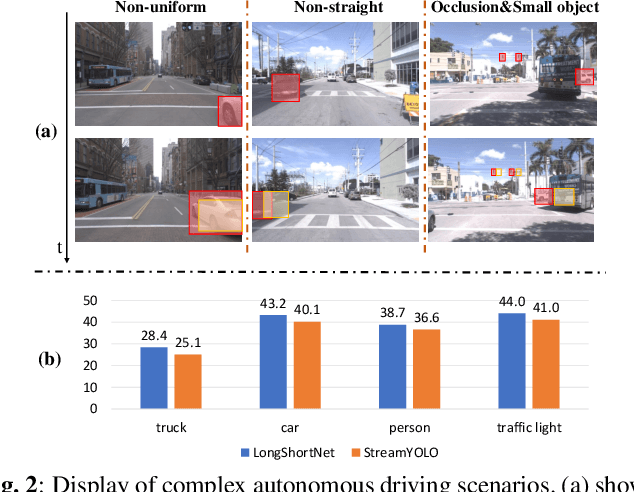
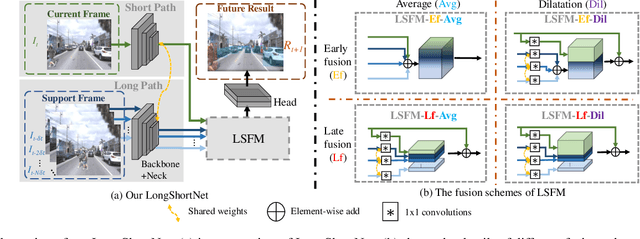
Streaming perception is a task of reporting the current state of autonomous driving, which coherently considers the latency and accuracy of autopilot systems. However, the existing streaming perception only uses the current and adjacent two frames as input for learning the movement patterns, which cannot model actual complex scenes, resulting in failed detection results. To solve this problem, we propose an end-to-end dual-path network dubbed LongShortNet, which captures long-term temporal motion and calibrates it with short-term spatial semantics for real-time perception. Moreover, we investigate a Long-Short Fusion Module (LSFM) to explore spatiotemporal feature fusion, which is the first work to extend long-term temporal in streaming perception. We evaluate the proposed LongShortNet and compare it with existing methods on the benchmark dataset Argoverse-HD. The results demonstrate that the proposed LongShortNet outperforms the other state-of-the-art methods with almost no extra computational cost.
TRScore: A Novel GPT-based Readability Scorer for ASR Segmentation and Punctuation model evaluation and selection
Oct 27, 2022
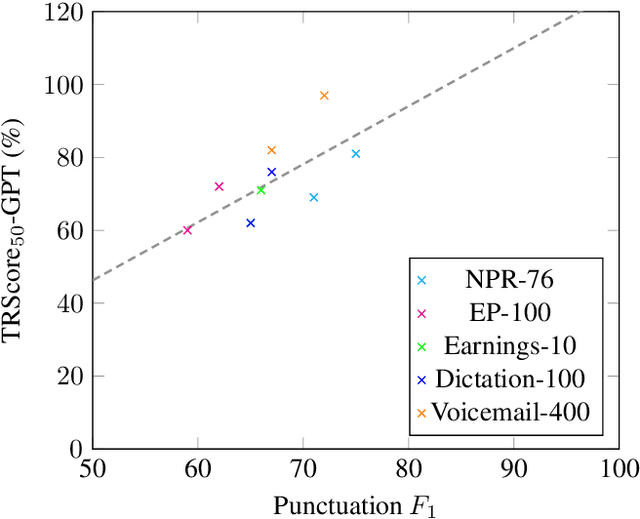
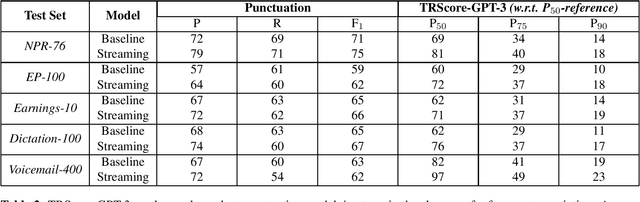
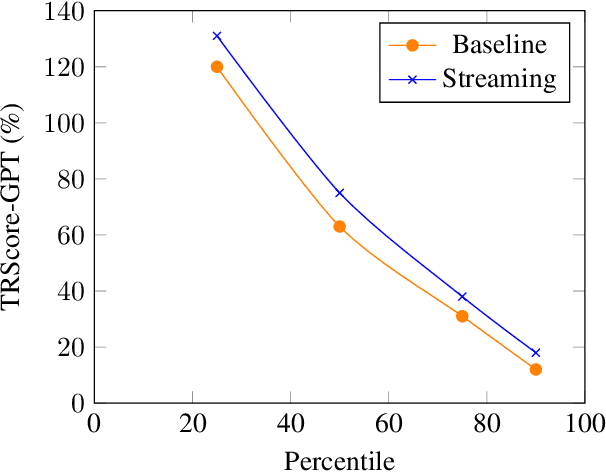
Punctuation and Segmentation are key to readability in Automatic Speech Recognition (ASR), often evaluated using F1 scores that require high-quality human transcripts and do not reflect readability well. Human evaluation is expensive, time-consuming, and suffers from large inter-observer variability, especially in conversational speech devoid of strict grammatical structures. Large pre-trained models capture a notion of grammatical structure. We present TRScore, a novel readability measure using the GPT model to evaluate different segmentation and punctuation systems. We validate our approach with human experts. Additionally, our approach enables quantitative assessment of text post-processing techniques such as capitalization, inverse text normalization (ITN), and disfluency on overall readability, which traditional word error rate (WER) and slot error rate (SER) metrics fail to capture. TRScore is strongly correlated to traditional F1 and human readability scores, with Pearson's correlation coefficients of 0.67 and 0.98, respectively. It also eliminates the need for human transcriptions for model selection.
Private and Reliable Neural Network Inference
Oct 27, 2022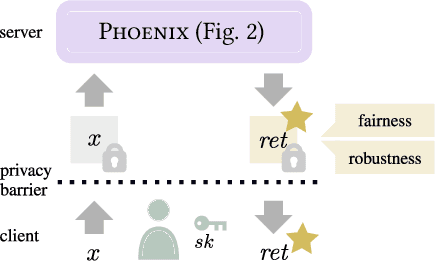
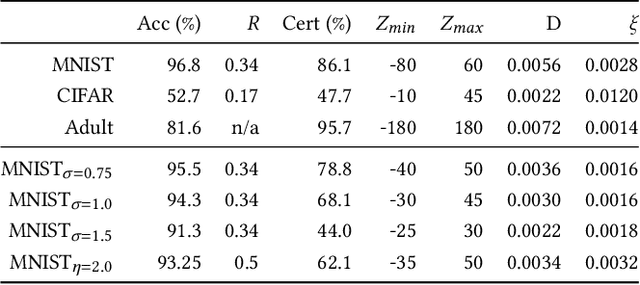
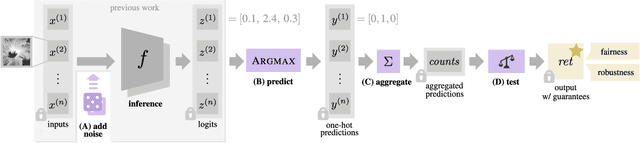
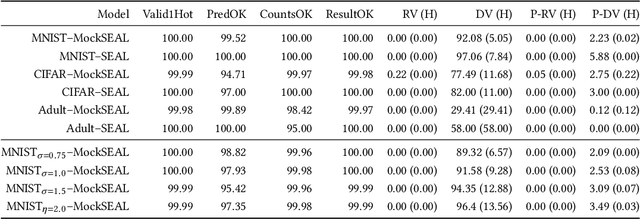
Reliable neural networks (NNs) provide important inference-time reliability guarantees such as fairness and robustness. Complementarily, privacy-preserving NN inference protects the privacy of client data. So far these two emerging areas have been largely disconnected, yet their combination will be increasingly important. In this work, we present the first system which enables privacy-preserving inference on reliable NNs. Our key idea is to design efficient fully homomorphic encryption (FHE) counterparts for the core algorithmic building blocks of randomized smoothing, a state-of-the-art technique for obtaining reliable models. The lack of required control flow in FHE makes this a demanding task, as na\"ive solutions lead to unacceptable runtime. We employ these building blocks to enable privacy-preserving NN inference with robustness and fairness guarantees in a system called Phoenix. Experimentally, we demonstrate that Phoenix achieves its goals without incurring prohibitive latencies. To our knowledge, this is the first work which bridges the areas of client data privacy and reliability guarantees for NNs.
Streaming Voice Conversion Via Intermediate Bottleneck Features And Non-streaming Teacher Guidance
Oct 27, 2022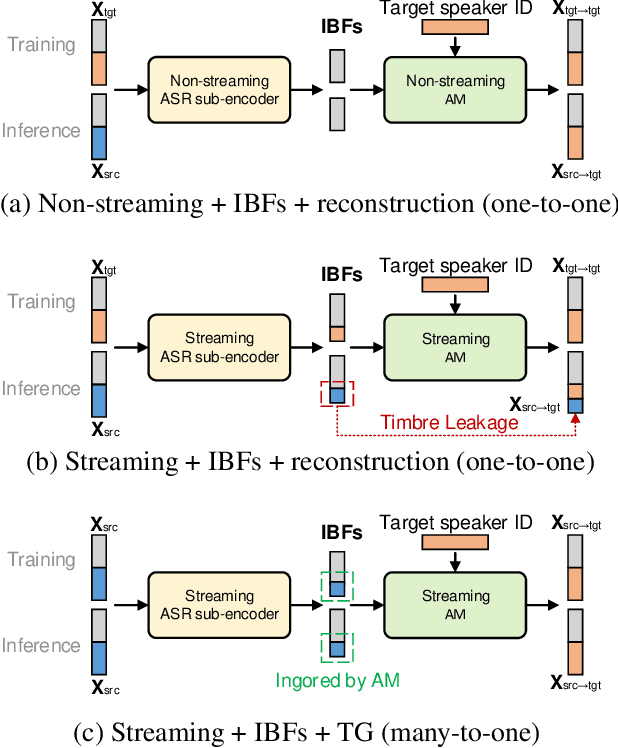
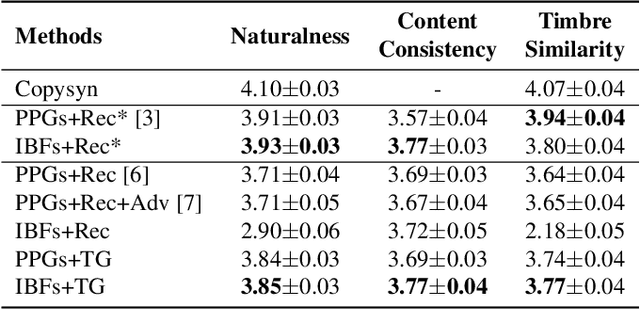
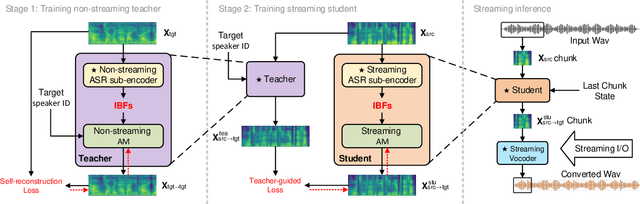
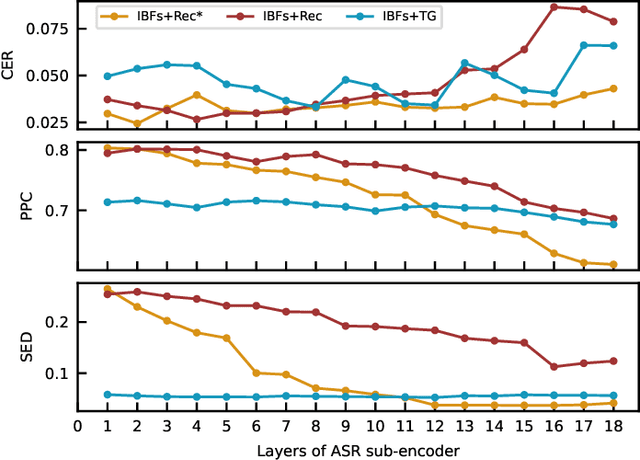
Streaming voice conversion (VC) is the task of converting the voice of one person to another in real-time. Previous streaming VC methods use phonetic posteriorgrams (PPGs) extracted from automatic speech recognition (ASR) systems to represent speaker-independent information. However, PPGs lack the prosody and vocalization information of the source speaker, and streaming PPGs contain undesired leaked timbre of the source speaker. In this paper, we propose to use intermediate bottleneck features (IBFs) to replace PPGs. VC systems trained with IBFs retain more prosody and vocalization information of the source speaker. Furthermore, we propose a non-streaming teacher guidance (TG) framework that addresses the timbre leakage problem. Experiments show that our proposed IBFs and the TG framework achieve a state-of-the-art streaming VC naturalness of 3.85, a content consistency of 3.77, and a timbre similarity of 3.77 under a future receptive field of 160 ms which significantly outperform previous streaming VC systems.
A Meta-Learning Based Gradient Descent Algorithm for MU-MIMO Beamforming
Oct 27, 2022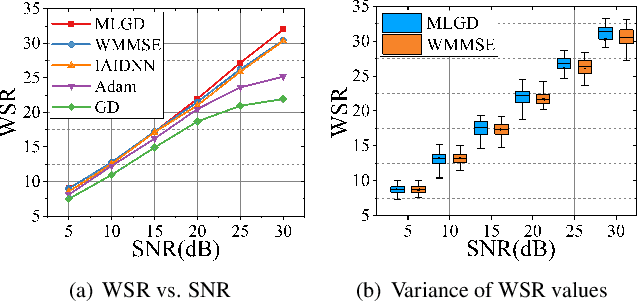

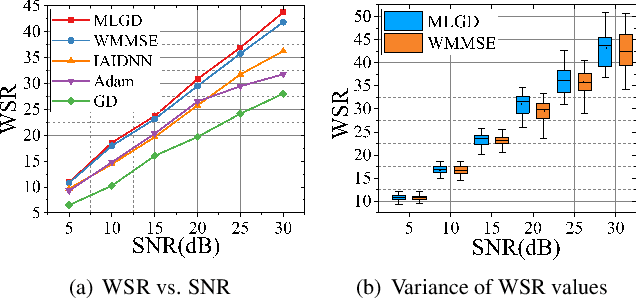
Multi-user multiple-input multiple-output (MU-MIMO) beamforming design is typically formulated as a non-convex weighted sum rate (WSR) maximization problem that is known to be NP-hard. This problem is solved either by iterative algorithms, which suffer from slow convergence, or more recently by using deep learning tools, which require time-consuming pre-training process. In this paper, we propose a low-complexity meta-learning based gradient descent algorithm. A meta network with lightweight architecture is applied to learn an adaptive gradient descent update rule to directly optimize the beamformer. This lightweight network is trained during the iterative optimization process, which we refer to as \emph{training while solving}, which removes both the training process and the data-dependency of existing deep learning based solutions.Extensive simulations show that the proposed method achieves superior WSR performance compared to existing learning-based approaches as well as the conventional WMMSE algorithm, while enjoying much lower computational load.
Local learning through propagation delays in spiking neural networks
Oct 27, 2022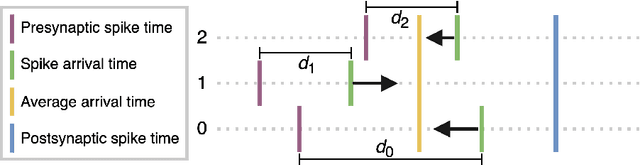

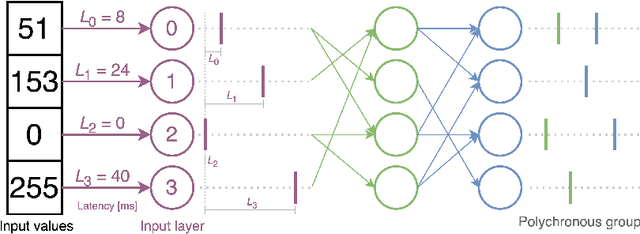
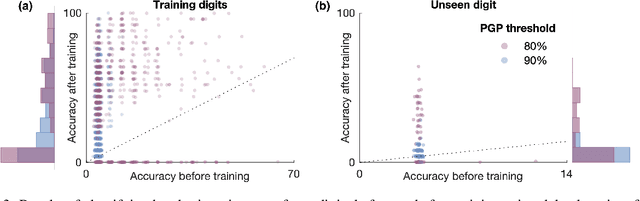
We propose a novel local learning rule for spiking neural networks in which spike propagation times undergo activity-dependent plasticity. Our plasticity rule aligns pre-synaptic spike times to produce a stronger and more rapid response. Inputs are encoded by latency coding and outputs decoded by matching similar patterns of output spiking activity. We demonstrate the use of this method in a three-layer feedfoward network with inputs from a database of handwritten digits. Networks consistently improve their classification accuracy after training, and training with this method also allowed networks to generalize to an input class unseen during training. Our proposed method takes advantage of the ability of spiking neurons to support many different time-locked sequences of spikes, each of which can be activated by different input activations. The proof-of-concept shown here demonstrates the great potential for local delay learning to expand the memory capacity and generalizability of spiking neural networks.
Exploiting spatial information with the informed complex-valued spatial autoencoder for target speaker extraction
Oct 27, 2022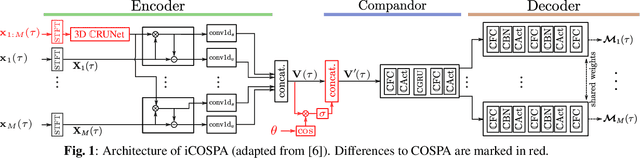
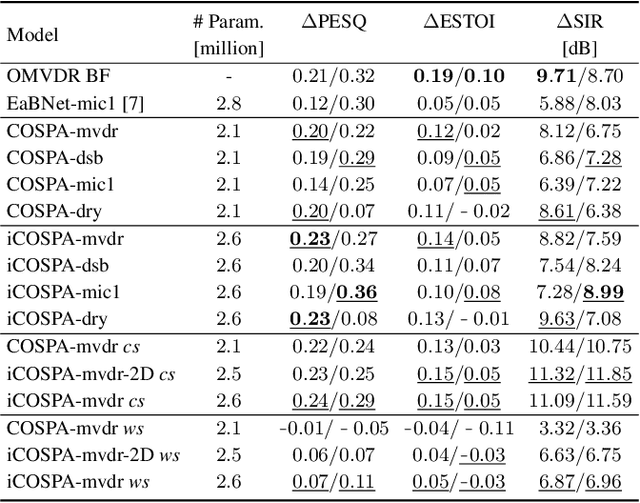
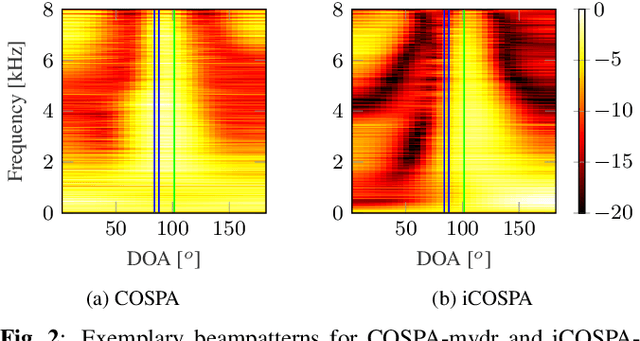
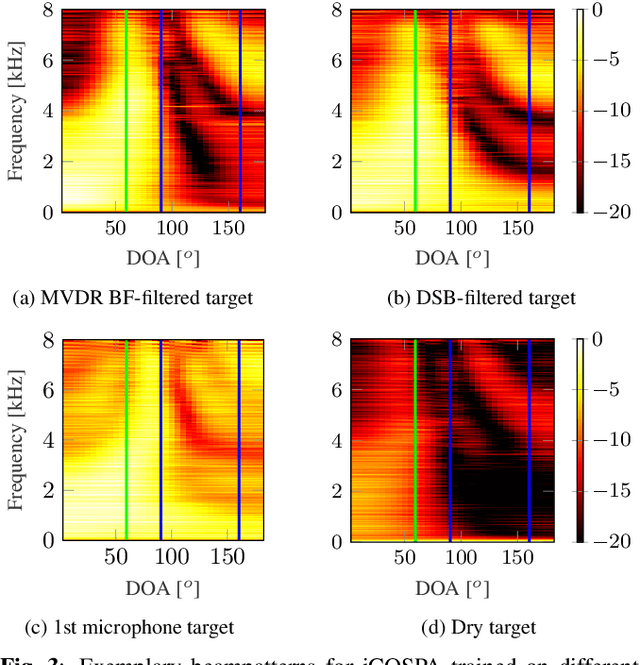
In conventional multichannel audio signal enhancement, spatial and spectral filtering are often performed sequentially. In contrast, it has been shown that for neural spatial filtering a joint approach of spectro-spatial filtering is more beneficial. In this contribution, we investigate the influence of the training target on the spatial selectivity of such a time-varying spectro-spatial filter. We extend the recently proposed complex-valued spatial autoencoder (COSPA) for target speaker extraction by leveraging its interpretable structure and purposefully informing the network of the target speaker's position. Consequently, this approach uses a multichannel complex-valued neural network architecture that is capable of processing spatial and spectral information rendering informed COSPA (iCOSPA) an effective neural spatial filtering method. We train iCOSPA for several training targets that enforce different amounts of spatial processing and analyze the network's spatial filtering capacity. We find that the proposed architecture is indeed capable of learning different spatial selectivity patterns to attain the different training targets.
CasNet: Investigating Channel Robustness for Speech Separation
Oct 27, 2022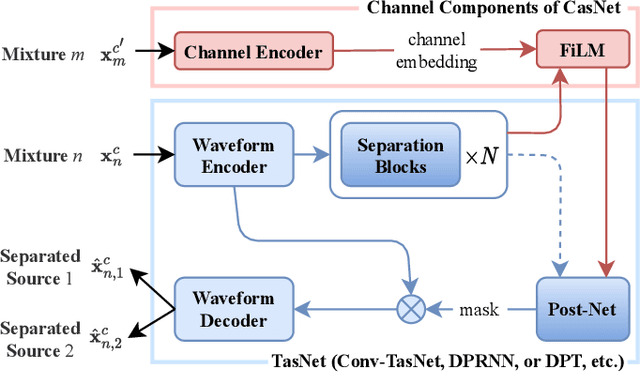
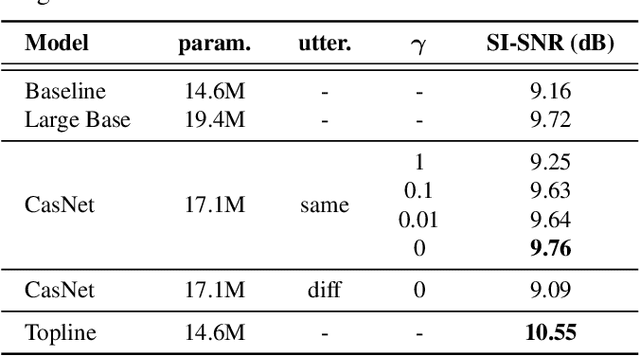
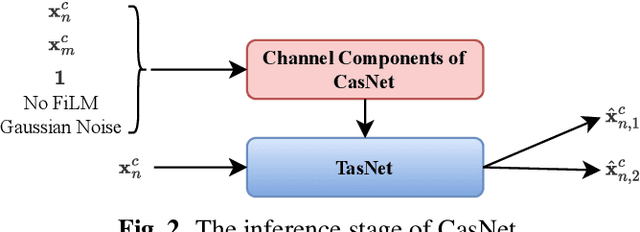
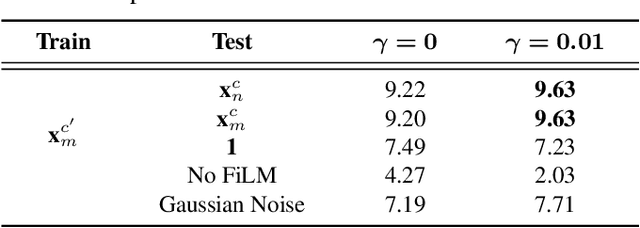
Recording channel mismatch between training and testing conditions has been shown to be a serious problem for speech separation. This situation greatly reduces the separation performance, and cannot meet the requirement of daily use. In this study, inheriting the use of our previously constructed TAT-2mix corpus, we address the channel mismatch problem by proposing a channel-aware audio separation network (CasNet), a deep learning framework for end-to-end time-domain speech separation. CasNet is implemented on top of TasNet. Channel embedding (characterizing channel information in a mixture of multiple utterances) generated by Channel Encoder is introduced into the separation module by the FiLM technique. Through two training strategies, we explore two roles that channel embedding may play: 1) a real-life noise disturbance, making the model more robust, or 2) a guide, instructing the separation model to retain the desired channel information. Experimental results on TAT-2mix show that CasNet trained with both training strategies outperforms the TasNet baseline, which does not use channel embeddings.