 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Dynamic Effective Connectivity Estimation from Multivariate Time Series
Feb 04, 2022
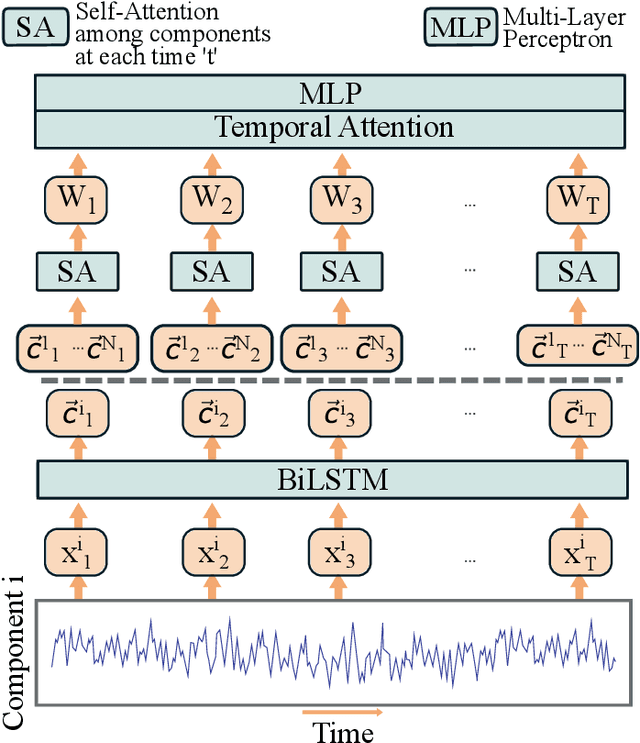
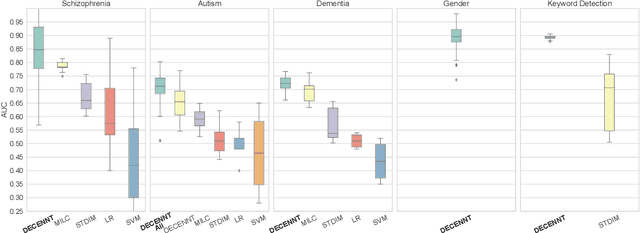
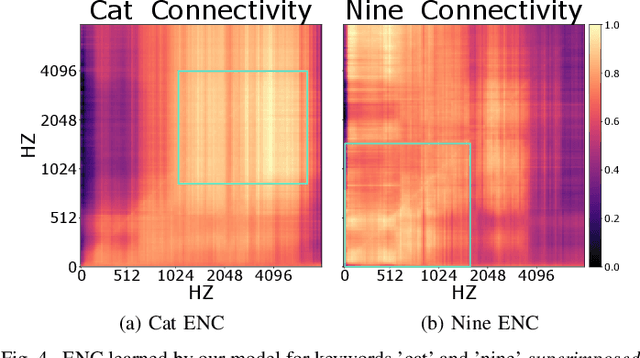
Recently, methods that represent data as a graph, such as graph neural networks (GNNs) have been successfully used to learn data representations and structures to solve classification and link prediction problems. The applications of such methods are vast and diverse, but most of the current work relies on the assumption of a static graph. This assumption does not hold for many highly dynamic systems, where the underlying connectivity structure is non-stationary and is mostly unobserved. Using a static model in these situations may result in sub-optimal performance. In contrast, modeling changes in graph structure with time can provide information about the system whose applications go beyond classification. Most work of this type does not learn effective connectivity and focuses on cross-correlation between nodes to generate undirected graphs. An undirected graph is unable to capture direction of an interaction which is vital in many fields, including neuroscience. To bridge this gap, we developed dynamic effective connectivity estimation via neural network training (DECENNT), a novel model to learn an interpretable directed and dynamic graph induced by the downstream classification/prediction task. DECENNT outperforms state-of-the-art (SOTA) methods on five different tasks and infers interpretable task-specific dynamic graphs. The dynamic graphs inferred from functional neuroimaging data align well with the existing literature and provide additional information. Additionally, the temporal attention module of DECENNT identifies time-intervals crucial for predictive downstream task from multivariate time series data.
Facial De-occlusion Network for Virtual Telepresence Systems
Oct 23, 2022
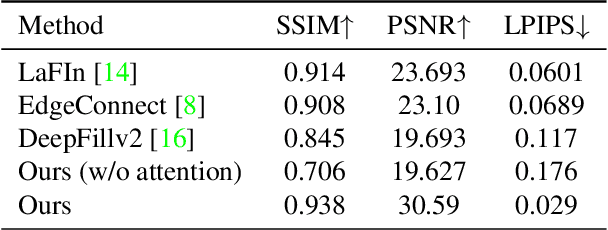
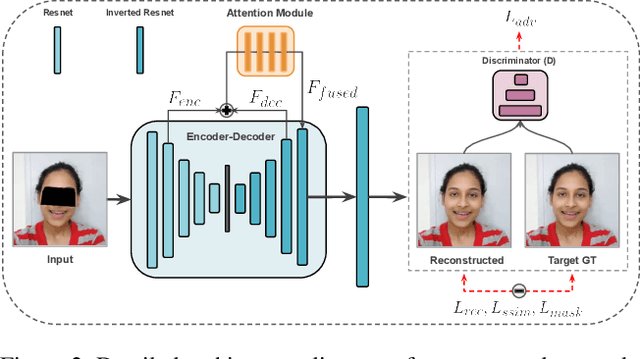
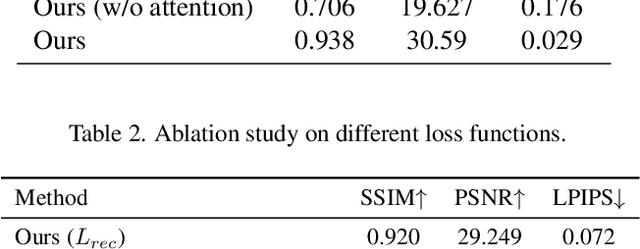
To see what is not in the image is one of the broader missions of computer vision. Technology to inpaint images has made significant progress with the coming of deep learning. This paper proposes a method to tackle occlusion specific to human faces. Virtual presence is a promising direction in communication and recreation for the future. However, Virtual Reality (VR) headsets occlude a significant portion of the face, hindering the photo-realistic appearance of the face in the virtual world. State-of-the-art image inpainting methods for de-occluding the eye region does not give usable results. To this end, we propose a working solution that gives usable results to tackle this problem enabling the use of the real-time photo-realistic de-occluded face of the user in VR settings.
ARMA Cell: A Modular and Effective Approach for Neural Autoregressive Modeling
Aug 31, 2022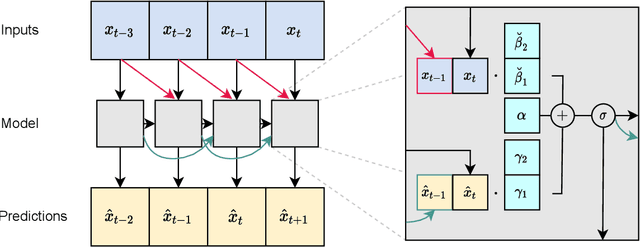
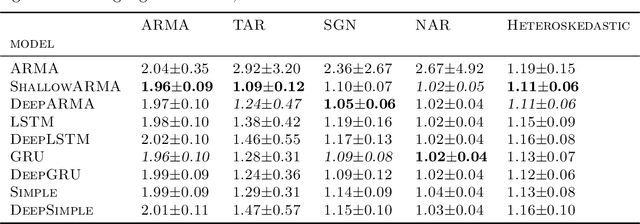
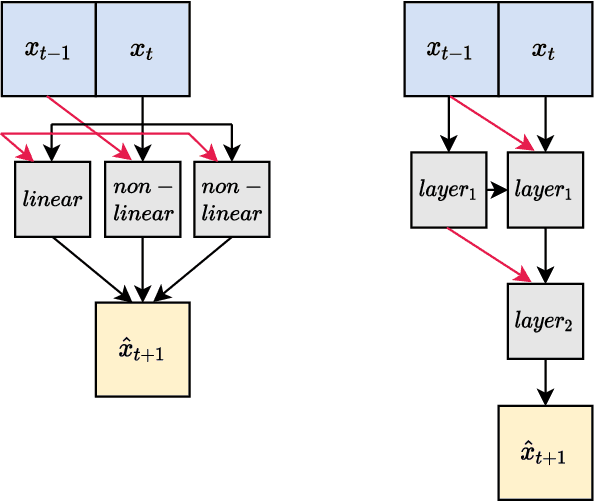
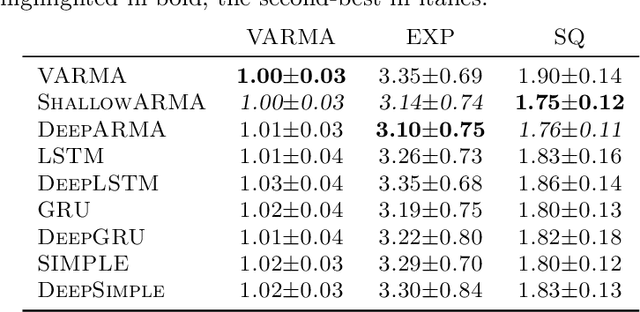
The autoregressive moving average (ARMA) model is a classical, and arguably one of the most studied approaches to model time series data. It has compelling theoretical properties and is widely used among practitioners. More recent deep learning approaches popularize recurrent neural networks (RNNs) and, in particular, long short-term memory (LSTM) cells that have become one of the best performing and most common building blocks in neural time series modeling. While advantageous for time series data or sequences with long-term effects, complex RNN cells are not always a must and can sometimes even be inferior to simpler recurrent approaches. In this work, we introduce the ARMA cell, a simpler, modular, and effective approach for time series modeling in neural networks. This cell can be used in any neural network architecture where recurrent structures are present and naturally handles multivariate time series using vector autoregression. We also introduce the ConvARMA cell as a natural successor for spatially-correlated time series. Our experiments show that the proposed methodology is competitive with popular alternatives in terms of performance while being more robust and compelling due to its simplicity.
Auto Lead Extraction and Digitization of ECG Paper Records using cGAN
Nov 12, 2022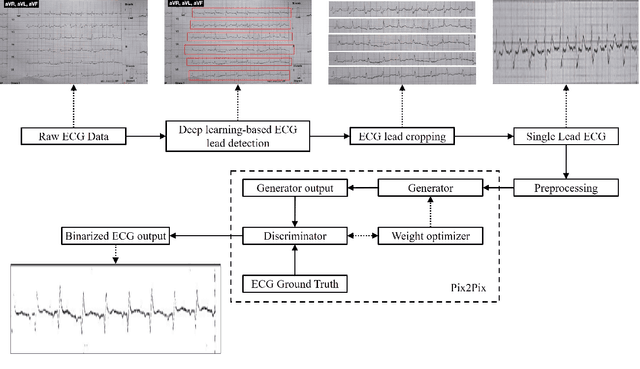
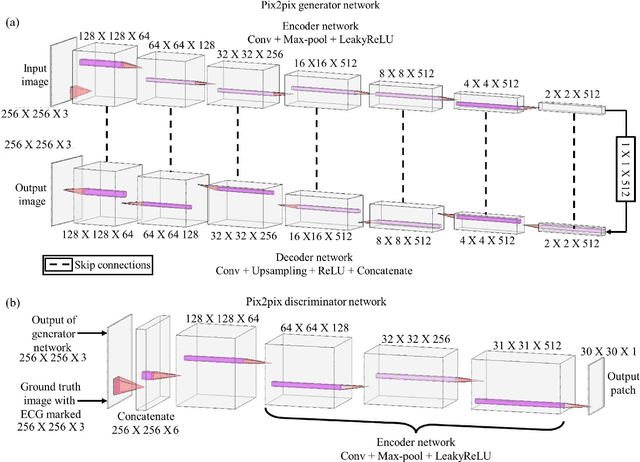
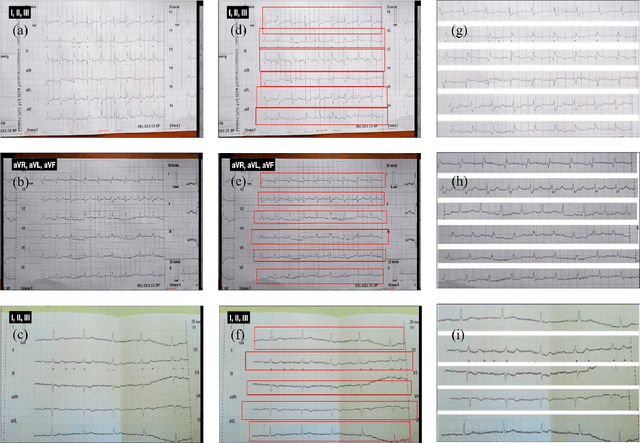
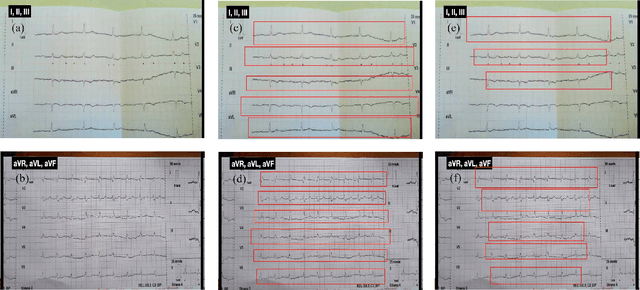
Purpose: An Electrocardiogram (ECG) is the simplest and fastest bio-medical test that is used to detect any heart-related disease. ECG signals are generally stored in paper form, which makes it difficult to store and analyze the data. While capturing ECG leads from paper ECG records, a lot of background information is also captured, which results in incorrect data interpretation. Methods: We propose a deep learning-based model for individually extracting all 12 leads from 12-lead ECG images captured using a camera. To simplify the analysis of the ECG and the calculation of complex parameters, we also propose a method to convert the paper ECG format into a storable digital format. The You Only Look Once, Version 3 (YOLOv3) algorithm has been used to extract the leads present in the image. These leads are then passed on to another deep learning model which separates the ECG signal and background from the single-lead image. After that, vertical scanning is performed on the ECG signal to convert it into a 1-Dimensional (1D) digital form. To perform the task of digitalization, we used the pix-2-pix deep learning model and binarized the ECG signals. Results: Our proposed method was able to achieve an accuracy of 97.4 %. Conclusion: The information on the paper ECG fades away over time. Hence, the digitized ECG signals make it possible to store the records and access them anytime. This proves highly beneficial for heart patients who require frequent ECG reports. The stored data can also be useful for research purposes, as this data can be used to develop computer algorithms that are capable of analyzing the data.
Self-Supervised Graph Structure Refinement for Graph Neural Networks
Nov 12, 2022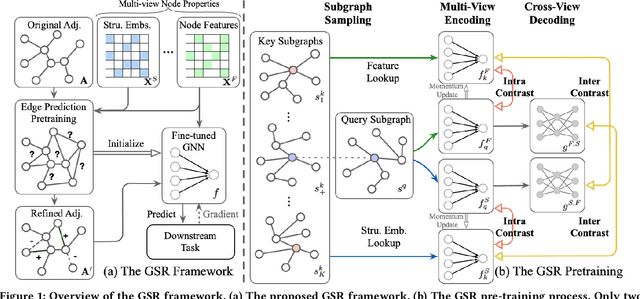
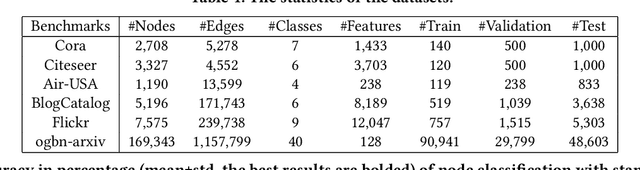
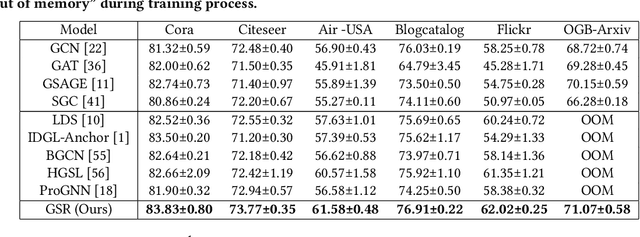

Graph structure learning (GSL), which aims to learn the adjacency matrix for graph neural networks (GNNs), has shown great potential in boosting the performance of GNNs. Most existing GSL works apply a joint learning framework where the estimated adjacency matrix and GNN parameters are optimized for downstream tasks. However, as GSL is essentially a link prediction task, whose goal may largely differ from the goal of the downstream task. The inconsistency of these two goals limits the GSL methods to learn the potential optimal graph structure. Moreover, the joint learning framework suffers from scalability issues in terms of time and space during the process of estimation and optimization of the adjacency matrix. To mitigate these issues, we propose a graph structure refinement (GSR) framework with a pretrain-finetune pipeline. Specifically, The pre-training phase aims to comprehensively estimate the underlying graph structure by a multi-view contrastive learning framework with both intra- and inter-view link prediction tasks. Then, the graph structure is refined by adding and removing edges according to the edge probabilities estimated by the pre-trained model. Finally, the fine-tuning GNN is initialized by the pre-trained model and optimized toward downstream tasks. With the refined graph structure remaining static in the fine-tuning space, GSR avoids estimating and optimizing graph structure in the fine-tuning phase which enjoys great scalability and efficiency. Moreover, the fine-tuning GNN is boosted by both migrating knowledge and refining graphs. Extensive experiments are conducted to evaluate the effectiveness (best performance on six benchmark datasets), efficiency, and scalability (13.8x faster using 32.8% GPU memory compared to the best GSL baseline on Cora) of the proposed model.
Privacy-preserving Automatic Speaker Diarization
Oct 26, 2022
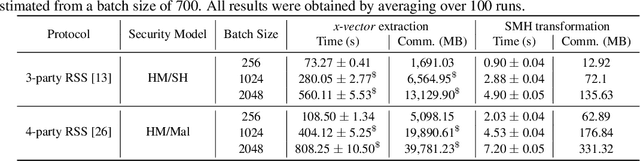
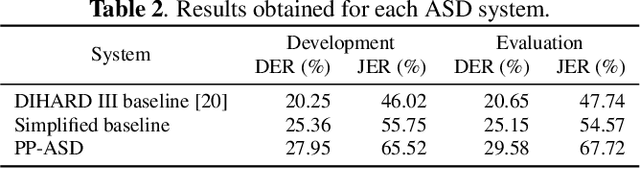
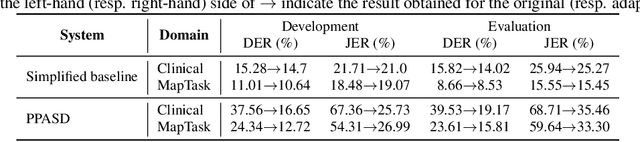
Automatic Speaker Diarization (ASD) is an enabling technology with numerous applications, which deals with recordings of multiple speakers, raising special concerns in terms of privacy. In fact, in remote settings, where recordings are shared with a server, clients relinquish not only the privacy of their conversation, but also of all the information that can be inferred from their voices. However, to the best of our knowledge, the development of privacy-preserving ASD systems has been overlooked thus far. In this work, we tackle this problem using a combination of two cryptographic techniques, Secure Multiparty Computation (SMC) and Secure Modular Hashing, and apply them to the two main steps of a cascaded ASD system: speaker embedding extraction and agglomerative hierarchical clustering. Our system is able to achieve a reasonable trade-off between performance and efficiency, presenting real-time factors of 1.1 and 1.6, for two different SMC security settings.
Counterfactual Phenotyping with Censored Time-to-Events
Feb 22, 2022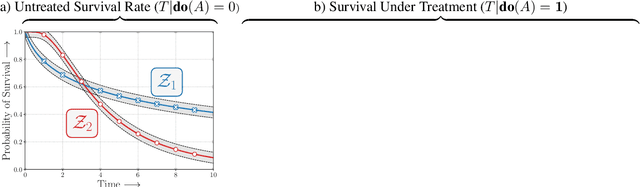
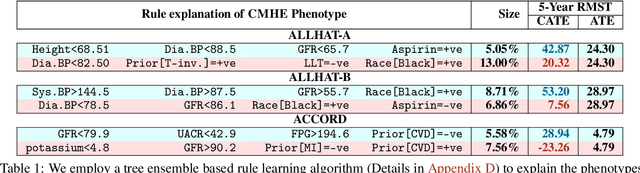
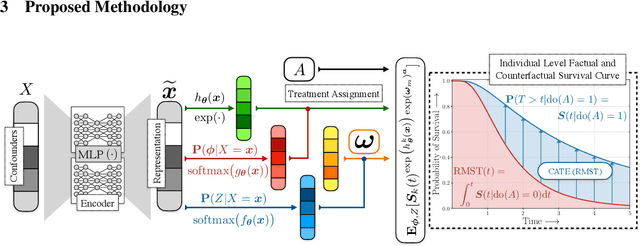
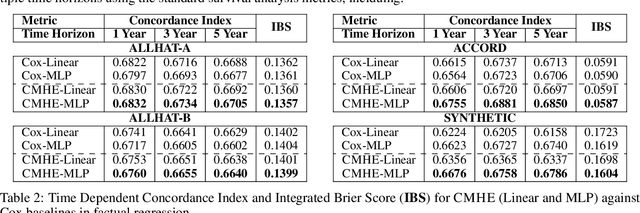
Estimation of treatment efficacy of real-world clinical interventions involves working with continuous outcomes such as time-to-death, re-hospitalization, or a composite event that may be subject to censoring. Causal reasoning in such scenarios requires decoupling the effects of confounding physiological characteristics that affect baseline survival rates from the effects of the interventions being assessed. In this paper, we present a latent variable approach to model heterogeneous treatment effects by proposing that an individual can belong to one of latent clusters with distinct response characteristics. We show that this latent structure can mediate the base survival rates and helps determine the effects of an intervention. We demonstrate the ability of our approach to discover actionable phenotypes of individuals based on their treatment response on multiple large randomized clinical trials originally conducted to assess appropriate treatments to reduce cardiovascular risk.
Semi-Supervised Domain Adaptation for Cross-Survey Galaxy Morphology Classification and Anomaly Detection
Nov 04, 2022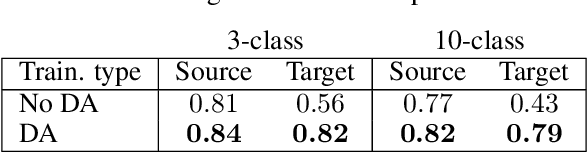

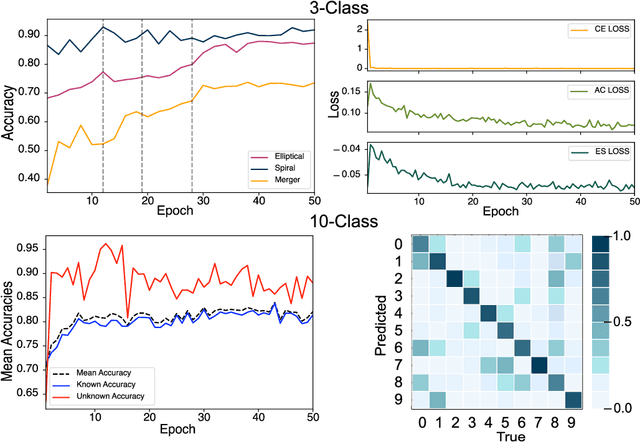
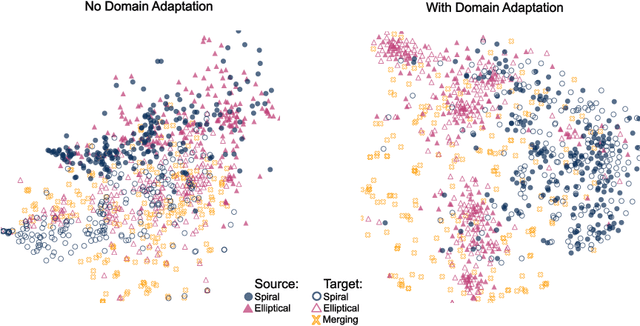
In the era of big astronomical surveys, our ability to leverage artificial intelligence algorithms simultaneously for multiple datasets will open new avenues for scientific discovery. Unfortunately, simply training a deep neural network on images from one data domain often leads to very poor performance on any other dataset. Here we develop a Universal Domain Adaptation method DeepAstroUDA, capable of performing semi-supervised domain alignment that can be applied to datasets with different types of class overlap. Extra classes can be present in any of the two datasets, and the method can even be used in the presence of unknown classes. For the first time, we demonstrate the successful use of domain adaptation on two very different observational datasets (from SDSS and DECaLS). We show that our method is capable of bridging the gap between two astronomical surveys, and also performs well for anomaly detection and clustering of unknown data in the unlabeled dataset. We apply our model to two examples of galaxy morphology classification tasks with anomaly detection: 1) classifying spiral and elliptical galaxies with detection of merging galaxies (three classes including one unknown anomaly class); 2) a more granular problem where the classes describe more detailed morphological properties of galaxies, with the detection of gravitational lenses (ten classes including one unknown anomaly class).
SPEAKER VGG CCT: Cross-corpus Speech Emotion Recognition with Speaker Embedding and Vision Transformers
Nov 04, 2022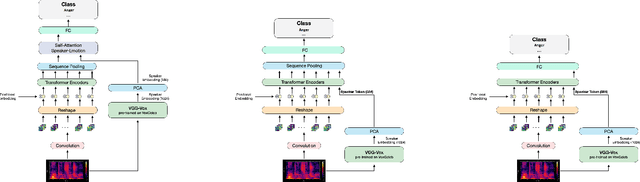

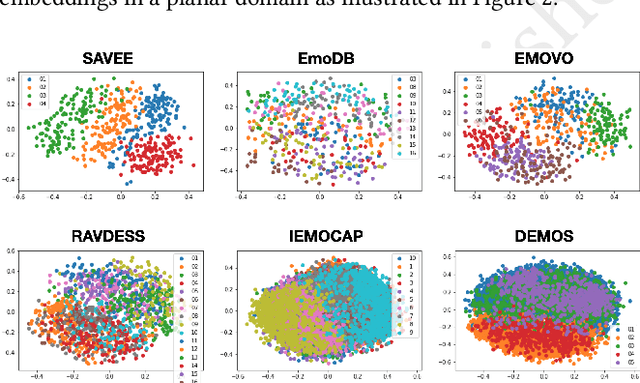
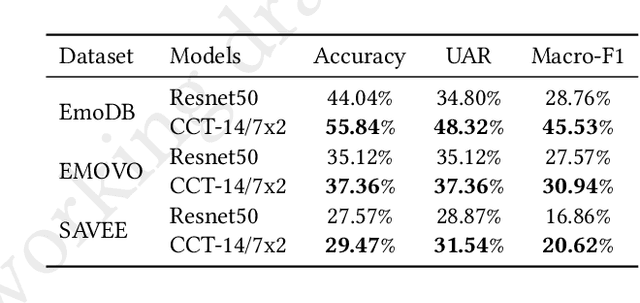
In recent years, Speech Emotion Recognition (SER) has been investigated mainly transforming the speech signal into spectrograms that are then classified using Convolutional Neural Networks pretrained on generic images and fine tuned with spectrograms. In this paper, we start from the general idea above and develop a new learning solution for SER, which is based on Compact Convolutional Transformers (CCTs) combined with a speaker embedding. With CCTs, the learning power of Vision Transformers (ViT) is combined with a diminished need for large volume of data as made possible by the convolution. This is important in SER, where large corpora of data are usually not available. The speaker embedding allows the network to extract an identity representation of the speaker, which is then integrated by means of a self-attention mechanism with the features that the CCT extracts from the spectrogram. Overall, the solution is capable of operating in real-time showing promising results in a cross-corpus scenario, where training and test datasets are kept separate. Experiments have been performed on several benchmarks in a cross-corpus setting as rarely used in the literature, with results that are comparable or superior to those obtained with state-of-the-art network architectures. Our code is available at https://github.com/JabuMlDev/Speaker-VGG-CCT.
Towards federated multivariate statistical process control (FedMSPC)
Nov 04, 2022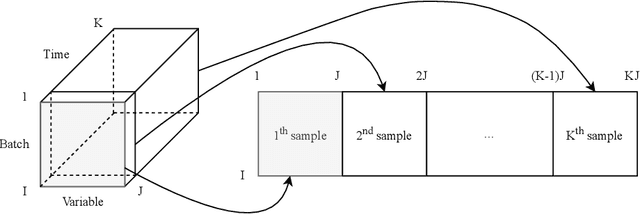
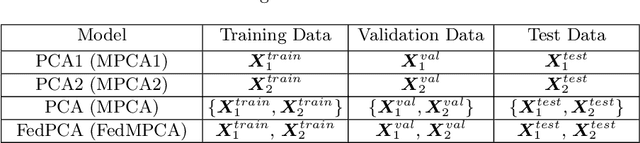
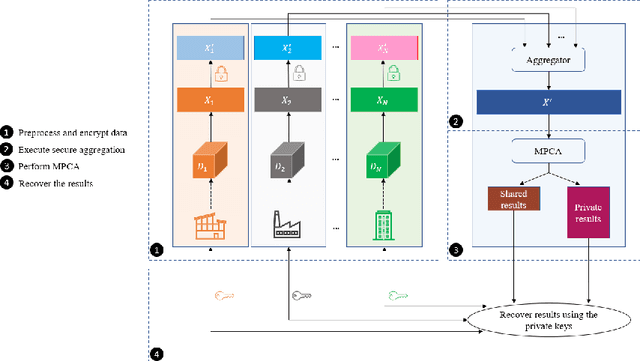

The ongoing transition from a linear (produce-use-dispose) to a circular economy poses significant challenges to current state-of-the-art information and communication technologies. In particular, the derivation of integrated, high-level views on material, process, and product streams from (real-time) data produced along value chains is challenging for several reasons. Most importantly, sufficiently rich data is often available yet not shared across company borders because of privacy concerns which make it impossible to build integrated process models that capture the interrelations between input materials, process parameters, and key performance indicators along value chains. In the current contribution, we propose a privacy-preserving, federated multivariate statistical process control (FedMSPC) framework based on Federated Principal Component Analysis (PCA) and Secure Multiparty Computation to foster the incentive for closer collaboration of stakeholders along value chains. We tested our approach on two industrial benchmark data sets - SECOM and ST-AWFD. Our empirical results demonstrate the superior fault detection capability of the proposed approach compared to standard, single-party (multiway) PCA. Furthermore, we showcase the possibility of our framework to provide privacy-preserving fault diagnosis to each data holder in the value chain to underpin the benefits of secure data sharing and federated process modeling.