 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Short-time Fourier transform based on stimulated Brillouin scattering
Nov 26, 2021
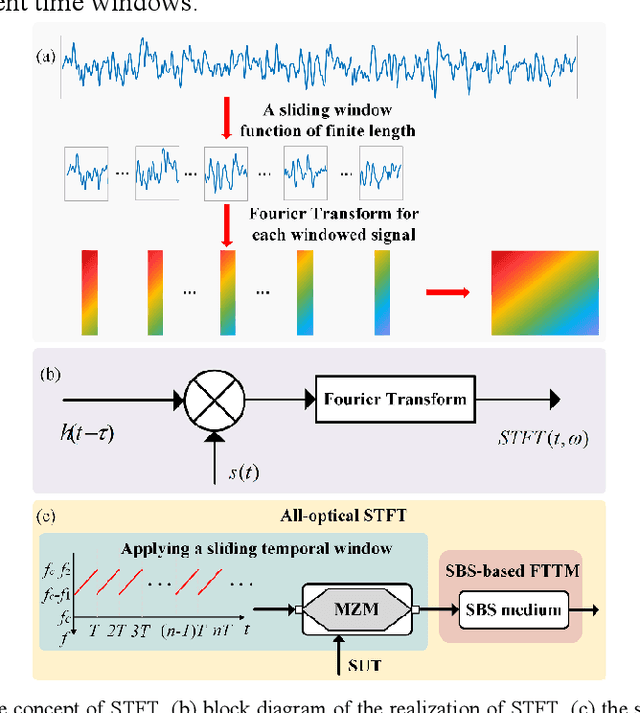
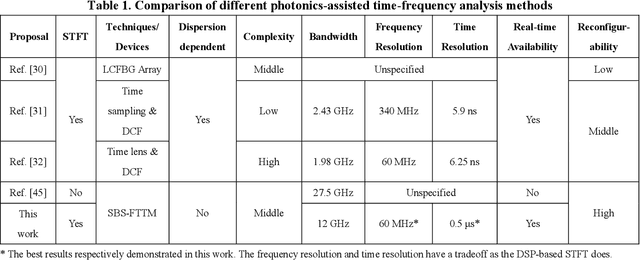
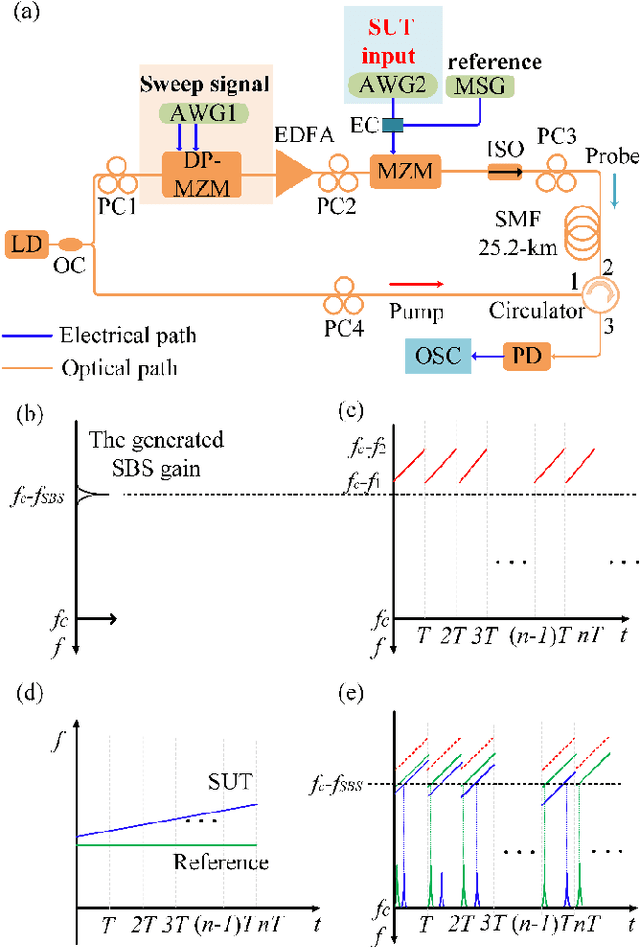
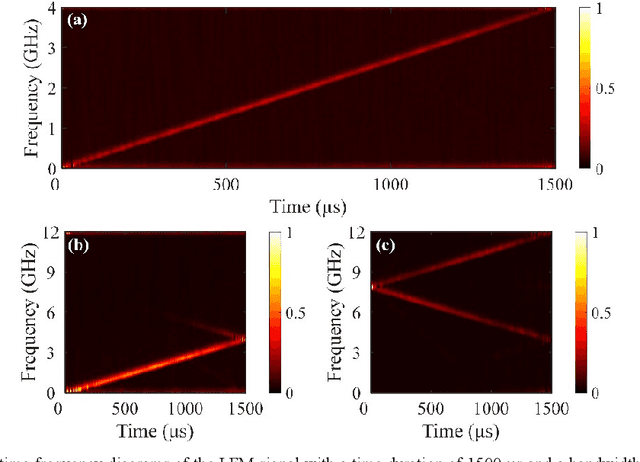
In this paper, all-optical short-time Fourier transform (STFT) based on stimulated Brillouin scattering (SBS) is proposed and further used for real-time time-frequency analysis of different radio frequency (RF) signals. In the proposed all-optical STFT system, SBS not only provides a band-pass filter for implementing the window function in conjunction with a periodic frequency-sweep optical signal but also obtains the frequency domain information in different time windows through the generated waveform via frequency-to-time mapping (FTTM). A periodic frequency-sweep optical signal is generated and then modulated at a Mach-Zehnder modulator by the electrical signal under test (SUT). During different sweep periods, the fixed Brillouin gain functions as a bandpass filter to select a specific range of the spectrum, which is equivalent to applying a sliding window function to the corresponding section of the temporal signal with the help of the sweep optical signal. At the same time, after the optical signal is selectively amplified by the SBS gain and converted back to the electrical domain, SBS also implements the real-time FTTM, which can be utilized to obtain the frequency domain information corresponding to different time windows through the generated waveforms via the FTTM. The frequency domain information corresponding to different time windows is formed and spliced to analyze the time-frequency relationship of the SUT in real-time. An experiment is performed. STFTs of a variety of RF signals are carried out in a 12-GHz bandwidth limited only by the equipment, and the dynamic frequency resolution is better than 60 MHz.
Regularized Bilinear Discriminant Analysis for Multivariate Time Series Data
Feb 26, 2022
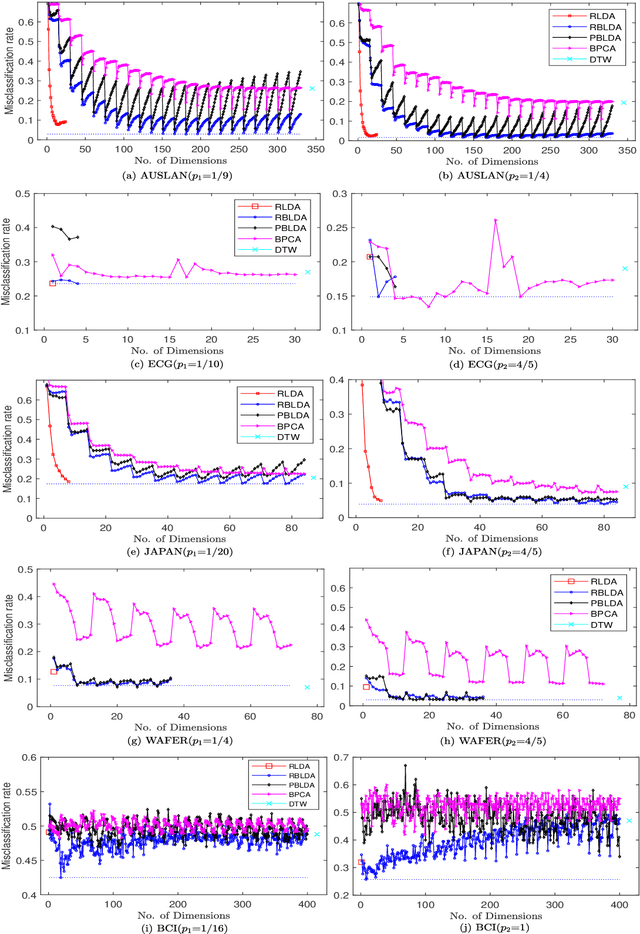
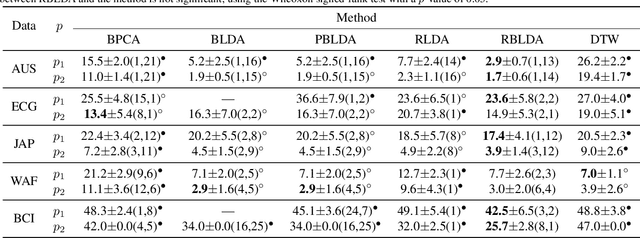
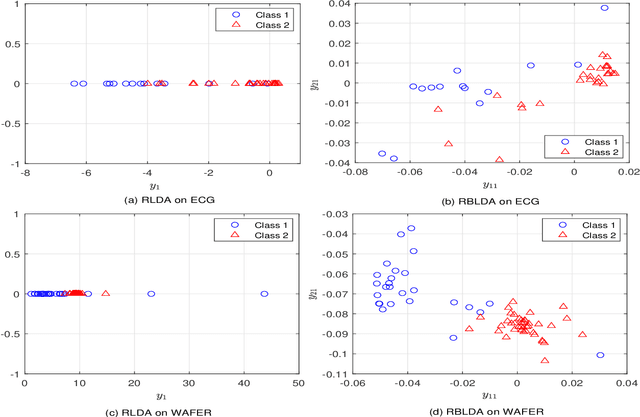
In recent years, the methods on matrix-based or bilinear discriminant analysis (BLDA) have received much attention. Despite their advantages, it has been reported that the traditional vector-based regularized LDA (RLDA) is still quite competitive and could outperform BLDA on some benchmark datasets. Nevertheless, it is also noted that this finding is mainly limited to image data. In this paper, we propose regularized BLDA (RBLDA) and further explore the comparison between RLDA and RBLDA on another type of matrix data, namely multivariate time series (MTS). Unlike image data, MTS typically consists of multiple variables measured at different time points. Although many methods for MTS data classification exist within the literature, there is relatively little work in exploring the matrix data structure of MTS data. Moreover, the existing BLDA can not be performed when one of its within-class matrices is singular. To address the two problems, we propose RBLDA for MTS data classification, where each of the two within-class matrices is regularized via one parameter. We develop an efficient implementation of RBLDA and an efficient model selection algorithm with which the cross validation procedure for RBLDA can be performed efficiently. Experiments on a number of real MTS data sets are conducted to evaluate the proposed algorithm and compare RBLDA with several closely related methods, including RLDA and BLDA. The results reveal that RBLDA achieves the best overall recognition performance and the proposed model selection algorithm is efficient; Moreover, RBLDA can produce better visualization of MTS data than RLDA.
Less is More: Simplifying Feature Extractors Prevents Overfitting for Neural Discourse Parsing Models
Oct 18, 2022
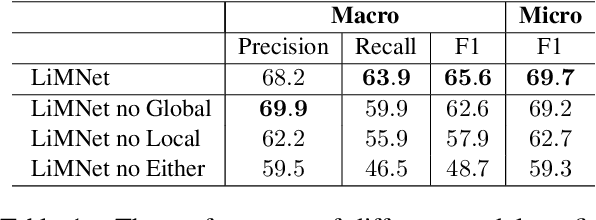
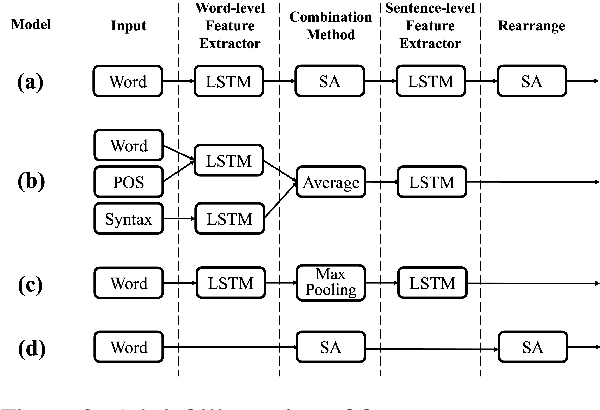
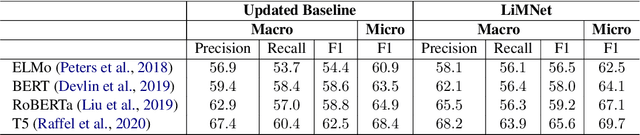
Complex feature extractors are widely employed for text representation building. However, these complex feature extractors can lead to severe overfitting problems especially when the training datasets are small, which is especially the case for several discourse parsing tasks. Thus, we propose to remove additional feature extractors and only utilize self-attention mechanism to exploit pretrained neural language models in order to mitigate the overfitting problem. Experiments on three common discourse parsing tasks (News Discourse Profiling, Rhetorical Structure Theory based Discourse Parsing and Penn Discourse Treebank based Discourse Parsing) show that powered by recent pretrained language models, our simplied feature extractors obtain better generalizabilities and meanwhile achieve comparable or even better system performance. The simplified feature extractors have fewer learnable parameters and less processing time. Codes will be released and this simple yet effective model can serve as a better baseline for future research.
CNT (Conditioning on Noisy Targets): A new Algorithm for Leveraging Top-Down Feedback
Oct 18, 2022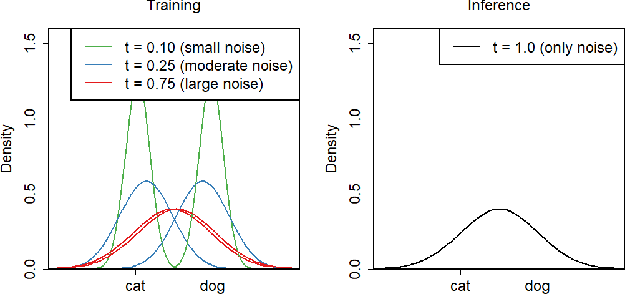
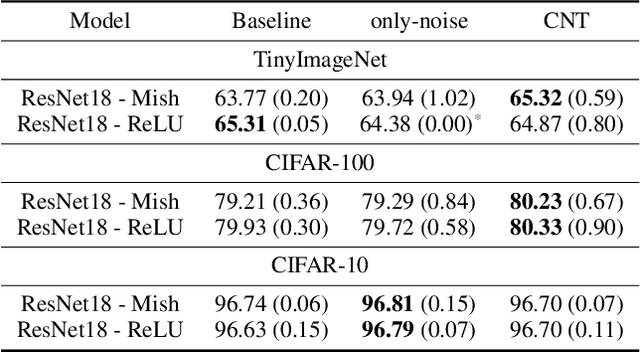
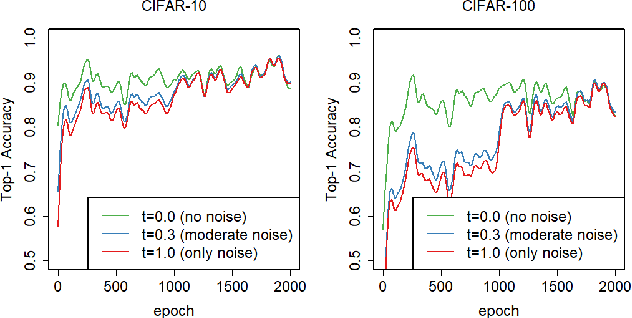
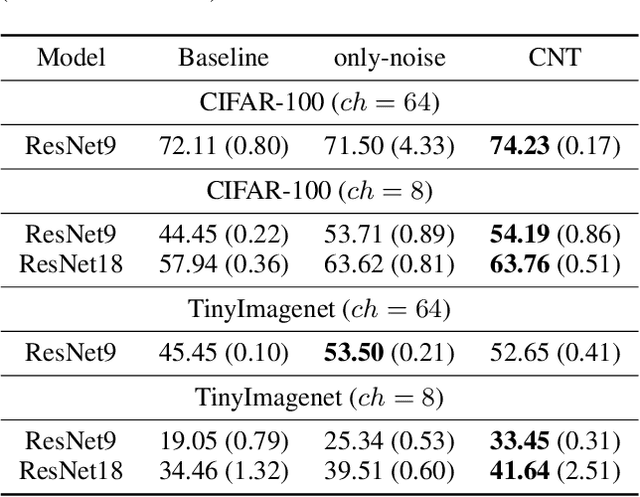
We propose a novel regularizer for supervised learning called Conditioning on Noisy Targets (CNT). This approach consists in conditioning the model on a noisy version of the target(s) (e.g., actions in imitation learning or labels in classification) at a random noise level (from small to large noise). At inference time, since we do not know the target, we run the network with only noise in place of the noisy target. CNT provides hints through the noisy label (with less noise, we can more easily infer the true target). This give two main benefits: 1) the top-down feedback allows the model to focus on simpler and more digestible sub-problems and 2) rather than learning to solve the task from scratch, the model will first learn to master easy examples (with less noise), while slowly progressing toward harder examples (with more noise).
Parameter-Conditioned Reachable Sets for Updating Safety Assurances Online
Sep 29, 2022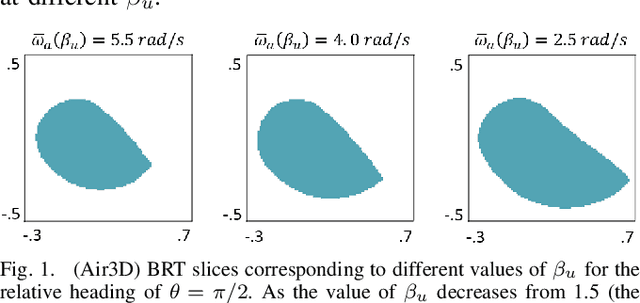
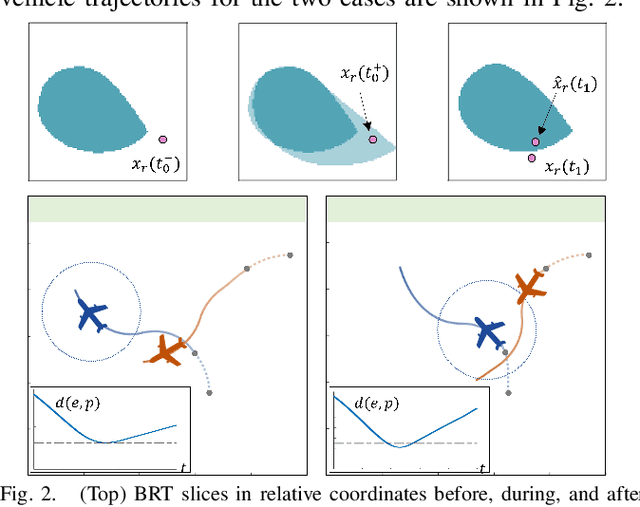
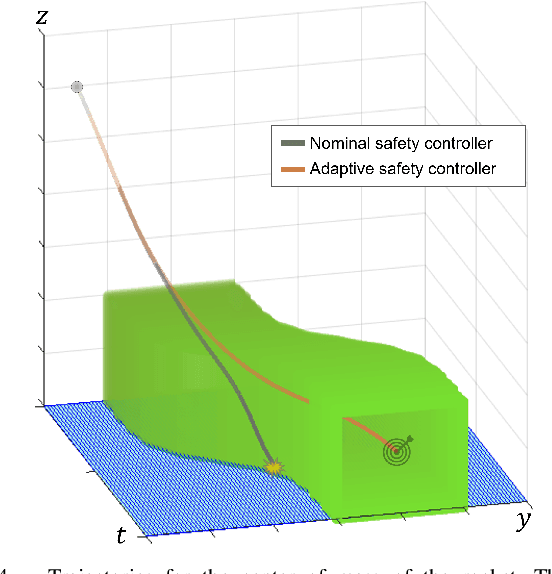
Hamilton-Jacobi (HJ) reachability analysis is a powerful tool for analyzing the safety of autonomous systems. However, the provided safety assurances are often predicated on the assumption that once deployed, the system or its environment does not evolve. Online, however, an autonomous system might experience changes in system dynamics, control authority, external disturbances, and/or the surrounding environment, requiring updated safety assurances. Rather than restarting the safety analysis from scratch, which can be time-consuming and often intractable to perform online, we propose to compute \textit{parameter-conditioned} reachable sets. Assuming expected system and environment changes can be parameterized, we treat these parameters as virtual states in the system and leverage recent advances in high-dimensional reachability analysis to solve the corresponding reachability problem offline. This results in a family of reachable sets that is parameterized by the environment and system factors. Online, as these factors change, the system can simply query the corresponding safety function from this family to ensure system safety, enabling a real-time update of the safety assurances. Through various simulation studies, we demonstrate the capability of our approach in maintaining system safety despite the system and environment evolution.
Fine-Tuning Pre-trained Transformers into Decaying Fast Weights
Oct 09, 2022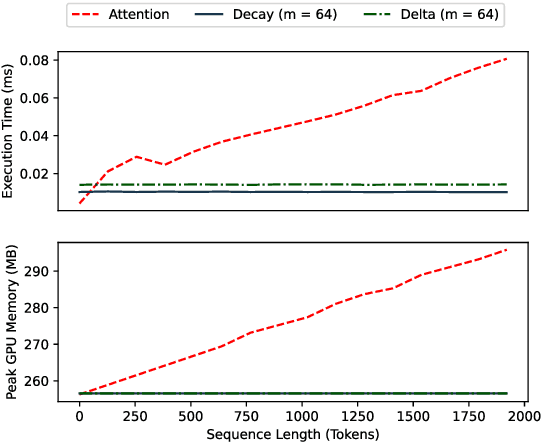

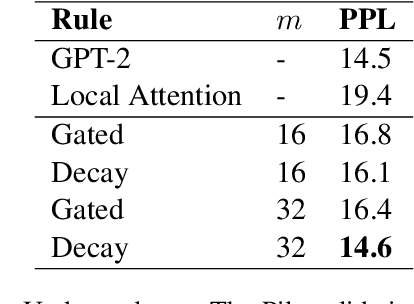
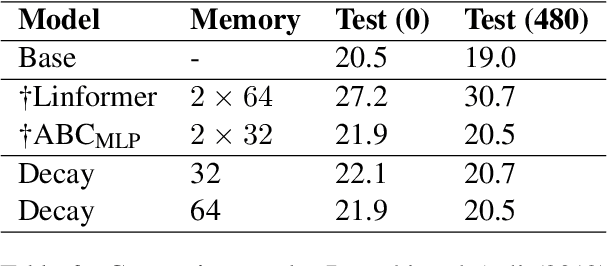
Autoregressive Transformers are strong language models but incur O(T) complexity during per-token generation due to the self-attention mechanism. Recent work proposes kernel-based methods to approximate causal self-attention by replacing it with recurrent formulations with various update rules and feature maps to achieve O(1) time and memory complexity. We explore these approaches and find that they are unnecessarily complex, and propose a simple alternative - decaying fast weights - that runs fast on GPU, outperforms prior methods, and retains 99% of attention's performance for GPT-2. We also show competitive performance on WikiText-103 against more complex attention substitutes.
A case study of spatiotemporal forecasting techniques for weather forecasting
Sep 29, 2022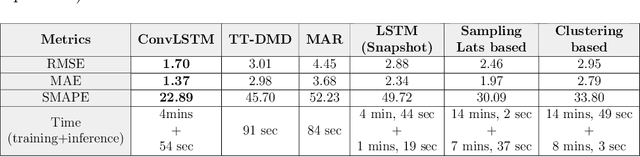
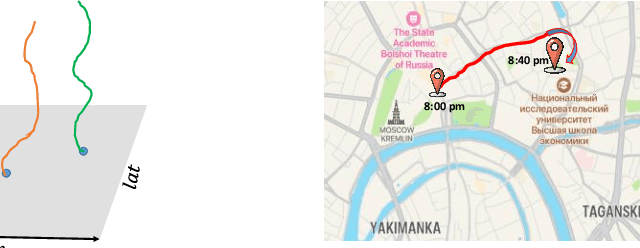

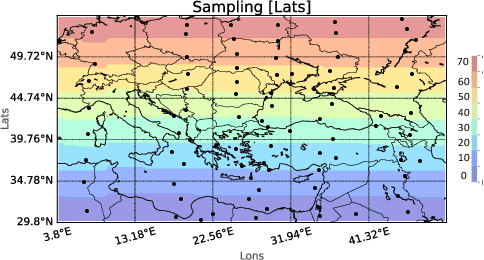
The majority of real-world processes are spatiotemporal, and the data generated by them exhibits both spatial and temporal evolution. Weather is one of the most important processes that fall under this domain, and forecasting it has become a crucial part of our daily routine. Weather data analysis is considered the most complex and challenging task. Although numerical weather prediction models are currently state-of-the-art, they are resource intensive and time-consuming. Numerous studies have proposed time-series-based models as a viable alternative to numerical forecasts. Recent research has primarily focused on forecasting weather at a specific location. Therefore, models can only capture temporal correlations. This self-contained paper explores various methods for regional data-driven weather forecasting, i.e., forecasting over multiple latitude-longitude points to capture spatiotemporal correlations. The results showed that spatiotemporal prediction models reduced computational cost while improving accuracy; in particular, the proposed tensor train dynamic mode decomposition-based forecasting model has comparable accuracy to ConvLSTM without the need for training. We use the NASA POWER meteorological dataset to evaluate the models and compare them with the current state of the art.
Joint PMD Tracking and Nonlinearity Compensation with Deep Neural Networks
Sep 21, 2022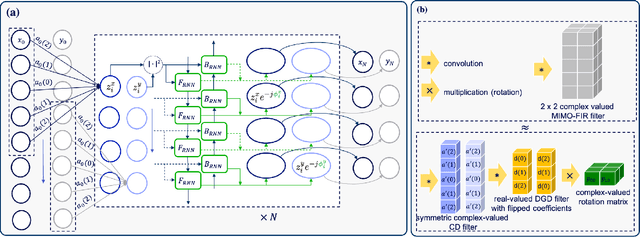

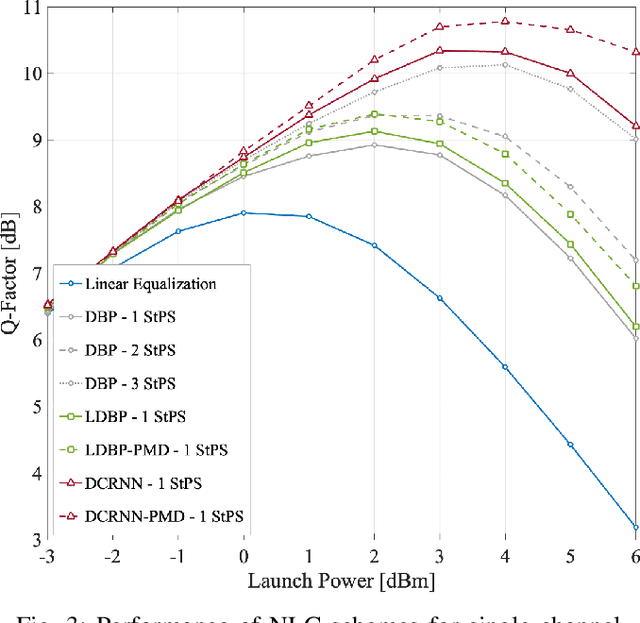
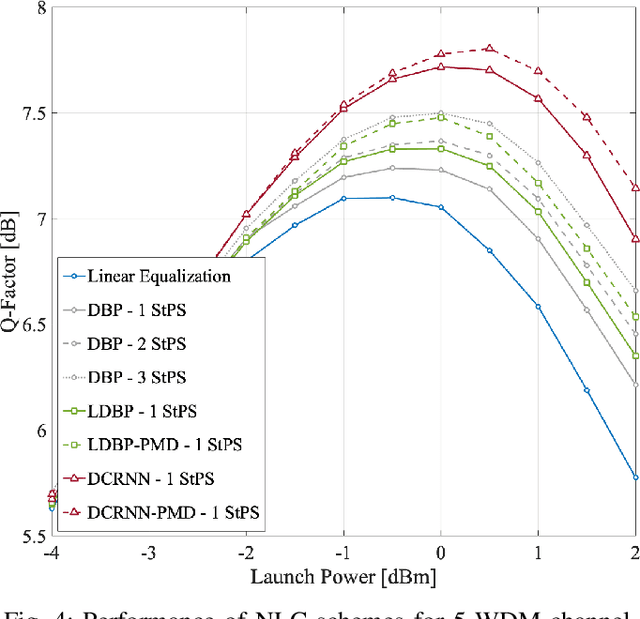
Overcoming fiber nonlinearity is one of the core challenges limiting the capacity of optical fiber communication systems. Machine learning based solutions such as learned digital backpropagation (LDBP) and the recently proposed deep convolutional recurrent neural network (DCRNN) have been shown to be effective for fiber nonlinearity compensation (NLC). Incorporating distributed compensation of polarization mode dispersion (PMD) within the learned models can improve their performance even further but at the same time, it also couples the compensation of nonlinearity and PMD. Consequently, it is important to consider the time variation of PMD for such a joint compensation scheme. In this paper, we investigate the impact of PMD drift on the DCRNN model with distributed compensation of PMD. We propose a transfer learning based selective training scheme to adapt the learned neural network model to changes in PMD. We demonstrate that fine-tuning only a small subset of weights as per the proposed method is sufficient for adapting the model to PMD drift. Using decision directed feedback for online learning, we track continuous PMD drift resulting from a time-varying rotation of the state of polarization (SOP). We show that transferring knowledge from a pre-trained base model using the proposed scheme significantly reduces the re-training efforts for different PMD realizations. Applying the hinge model for SOP rotation, our simulation results show that the learned models maintain their performance gains while tracking the PMD.
Age of Information in Federated Learning over Wireless Networks
Sep 14, 2022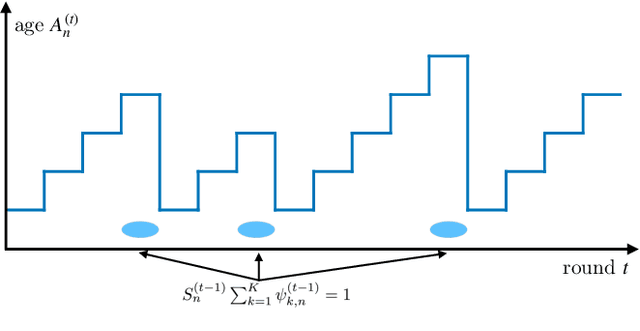
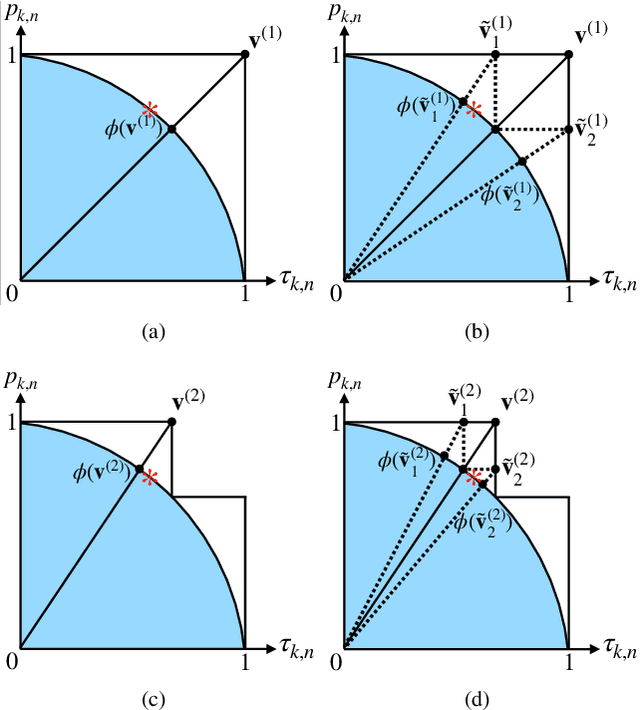
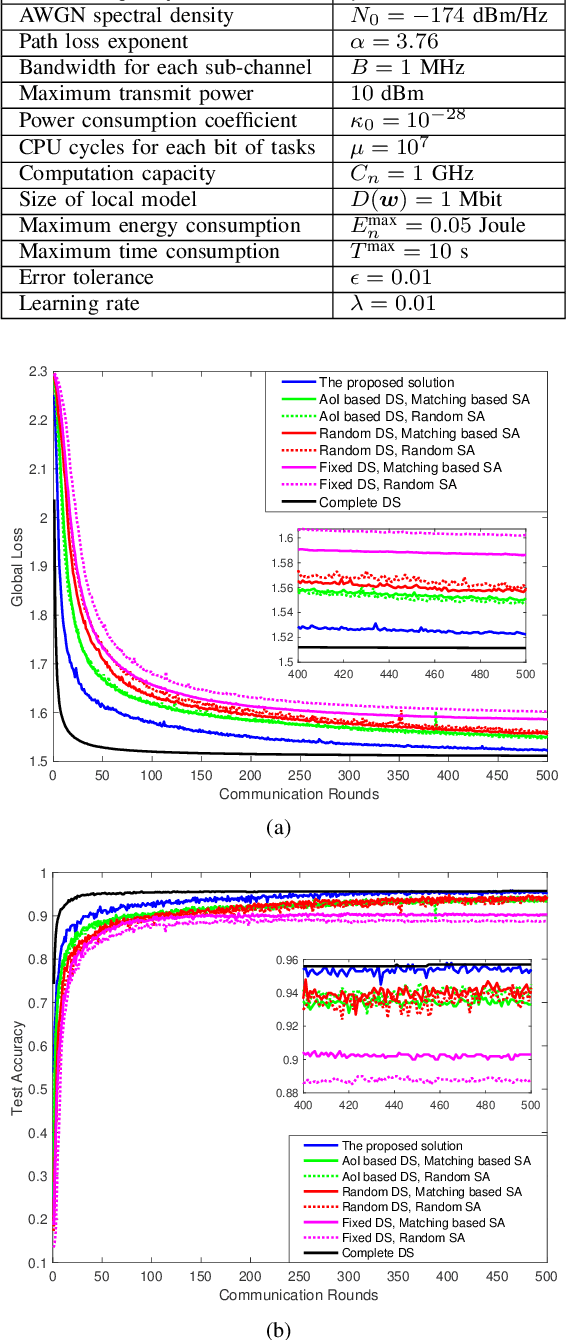
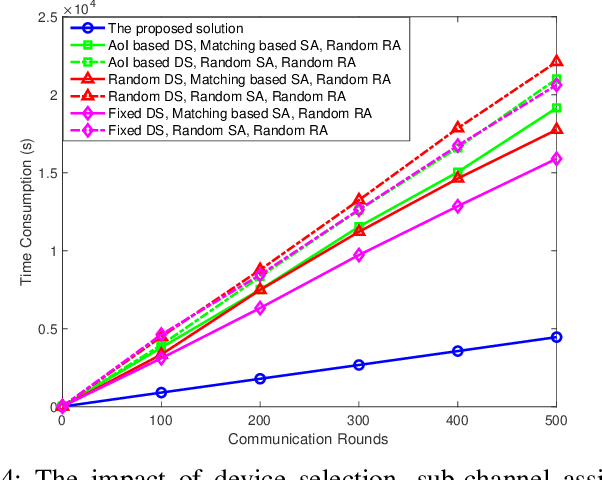
In this paper, federated learning (FL) over wireless networks is investigated. In each communication round, a subset of devices is selected to participate in the aggregation with limited time and energy. In order to minimize the convergence time, global loss and latency are jointly considered in a Stackelberg game based framework. Specifically, age of information (AoI) based device selection is considered at leader-level as a global loss minimization problem, while sub-channel assignment, computational resource allocation, and power allocation are considered at follower-level as a latency minimization problem. By dividing the follower-level problem into two sub-problems, the best response of the follower is obtained by a monotonic optimization based resource allocation algorithm and a matching based sub-channel assignment algorithm. By deriving the upper bound of convergence rate, the leader-level problem is reformulated, and then a list based device selection algorithm is proposed to achieve Stackelberg equilibrium. Simulation results indicate that the proposed device selection scheme outperforms other schemes in terms of the global loss, and the developed algorithms can significantly decrease the time consumption of computation and communication.
End-to-end Tracking with a Multi-query Transformer
Oct 26, 2022

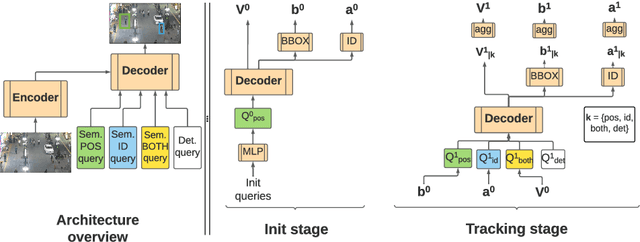

Multiple-object tracking (MOT) is a challenging task that requires simultaneous reasoning about location, appearance, and identity of the objects in the scene over time. Our aim in this paper is to move beyond tracking-by-detection approaches, that perform well on datasets where the object classes are known, to class-agnostic tracking that performs well also for unknown object classes.To this end, we make the following three contributions: first, we introduce {\em semantic detector queries} that enable an object to be localized by specifying its approximate position, or its appearance, or both; second, we use these queries within an auto-regressive framework for tracking, and propose a multi-query tracking transformer (\textit{MQT}) model for simultaneous tracking and appearance-based re-identification (reID) based on the transformer architecture with deformable attention. This formulation allows the tracker to operate in a class-agnostic manner, and the model can be trained end-to-end; finally, we demonstrate that \textit{MQT} performs competitively on standard MOT benchmarks, outperforms all baselines on generalised-MOT, and generalises well to a much harder tracking problems such as tracking any object on the TAO dataset.