 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Immediate-Access Dynamic Indexing
Nov 11, 2022
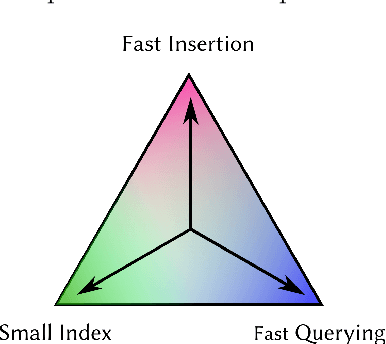

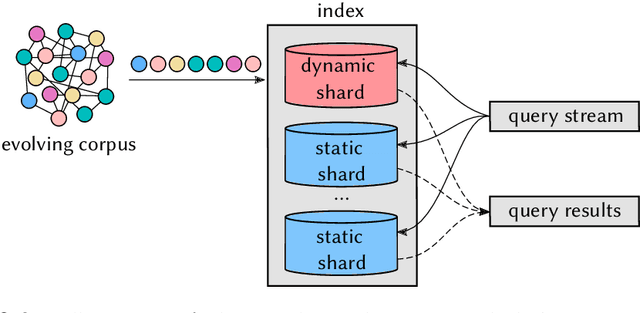
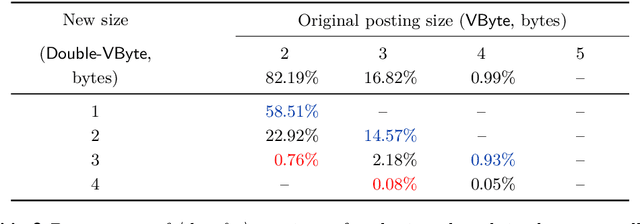
In a dynamic retrieval system, documents must be ingested as they arrive, and be immediately findable by queries. Our purpose in this paper is to describe an index structure and processing regime that accommodates that requirement for immediate access, seeking to make the ingestion process as streamlined as possible, while at the same time seeking to make the growing index as small as possible, and seeking to make term-based querying via the index as efficient as possible. We describe a new compression operation and a novel approach to extensible lists which together facilitate that triple goal. In particular, the structure we describe provides incremental document-level indexing using as little as two bytes per posting and only a small amount more for word-level indexing; provides fast document insertion; supports immediate and continuous queryability; provides support for fast conjunctive queries and similarity score-based ranked queries; and facilitates fast conversion of the dynamic index to a "normal" static compressed inverted index structure. Measurement of our new mechanism confirms that in-memory dynamic document-level indexes for collections into the gigabyte range can be constructed at a rate of two gigabytes/minute using a typical server architecture, that multi-term conjunctive Boolean queries can be resolved in just a few milliseconds each on average even while new documents are being concurrently ingested, and that the net memory space required for all of the required data structures amounts to an average of as little as two bytes per stored posting.
HGARN: Hierarchical Graph Attention Recurrent Network for Human Mobility Prediction
Oct 14, 2022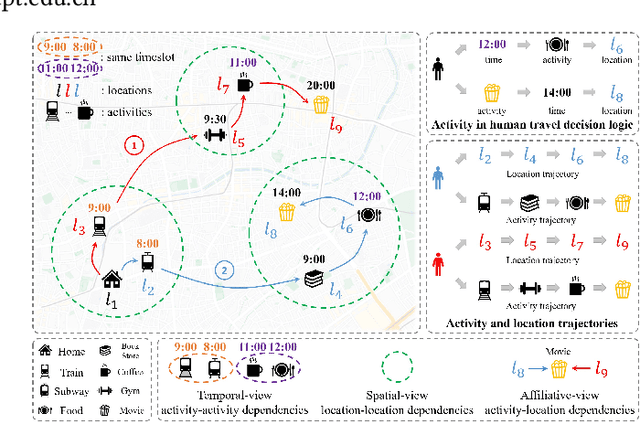

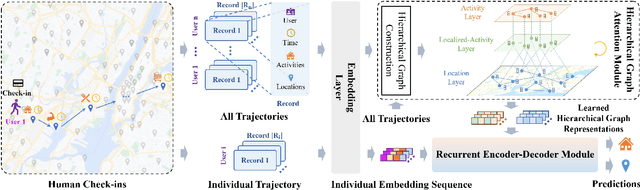
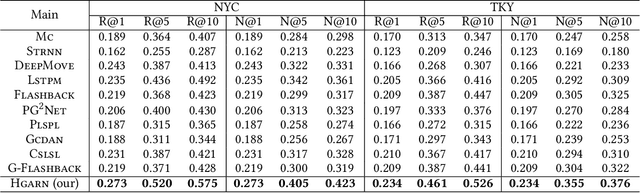
Human mobility prediction is a fundamental task essential for various applications, including urban planning, transportation services, and location recommendation. Existing approaches often ignore activity information crucial for reasoning human preferences and routines, or adopt a simplified representation of the dependencies between time, activities and locations. To address these issues, we present Hierarchical Graph Attention Recurrent Network (HGARN) for human mobility prediction. Specifically, we construct a hierarchical graph based on all users' history mobility records and employ a Hierarchical Graph Attention Module to capture complex time-activity-location dependencies. This way, HGARN can learn representations with rich contextual semantics to model user preferences at the global level. We also propose a model-agnostic history-enhanced confidence (MaHec) label to focus our model on each user's individual-level preferences. Finally, we introduce a Recurrent Encoder-Decoder Module, which employs recurrent structures to jointly predict users' next activities (as an auxiliary task) and locations. For model evaluation, we test the performances of our Hgarn against existing SOTAs in recurring and explorative settings. The recurring setting focuses more on assessing models' capabilities to capture users' individual-level preferences. In contrast, the results in the explorative setting tend to reflect the power of different models to learn users' global-level preferences. Overall, our model outperforms other baselines significantly in the main, recurring, and explorative settings based on two real-world human mobility data benchmarks. Source codes of HGARN are available at https://github.com/YihongT/HGARN.
Latent Temporal Flows for Multivariate Analysis of Wearables Data
Oct 14, 2022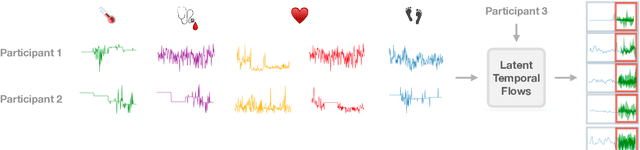

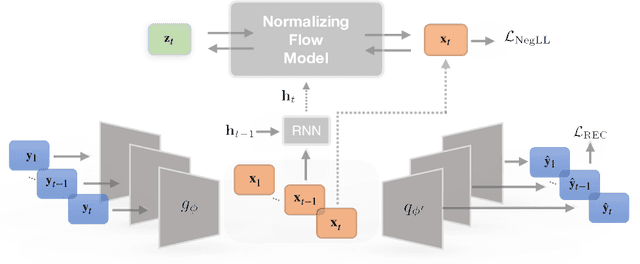
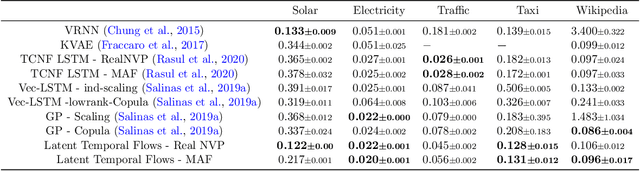
Increased use of sensor signals from wearable devices as rich sources of physiological data has sparked growing interest in developing health monitoring systems to identify changes in an individual's health profile. Indeed, machine learning models for sensor signals have enabled a diverse range of healthcare related applications including early detection of abnormalities, fertility tracking, and adverse drug effect prediction. However, these models can fail to account for the dependent high-dimensional nature of the underlying sensor signals. In this paper, we introduce Latent Temporal Flows, a method for multivariate time-series modeling tailored to this setting. We assume that a set of sequences is generated from a multivariate probabilistic model of an unobserved time-varying low-dimensional latent vector. Latent Temporal Flows simultaneously recovers a transformation of the observed sequences into lower-dimensional latent representations via deep autoencoder mappings, and estimates a temporally-conditioned probabilistic model via normalizing flows. Using data from the Apple Heart and Movement Study (AH&MS), we illustrate promising forecasting performance on these challenging signals. Additionally, by analyzing two and three dimensional representations learned by our model, we show that we can identify participants' $\text{VO}_2\text{max}$, a main indicator and summary of cardio-respiratory fitness, using only lower-level signals. Finally, we show that the proposed method consistently outperforms the state-of-the-art in multi-step forecasting benchmarks (achieving at least a $10\%$ performance improvement) on several real-world datasets, while enjoying increased computational efficiency.
Automatic Subspace Evoking for Efficient Neural Architecture Search
Oct 31, 2022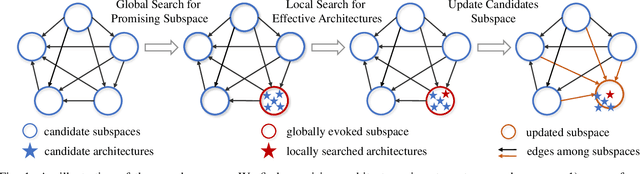
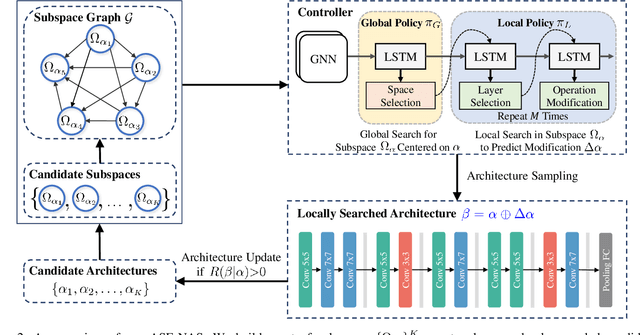
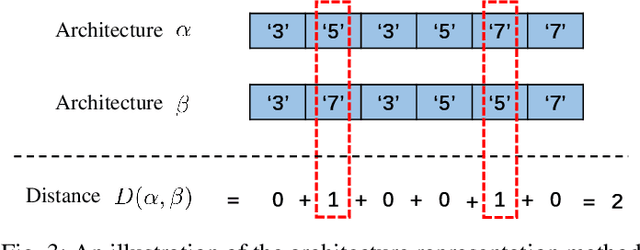
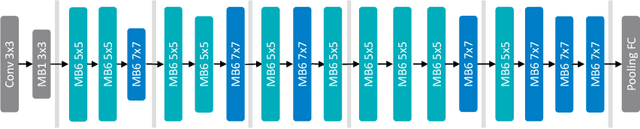
Neural Architecture Search (NAS) aims to automatically find effective architectures from a predefined search space. However, the search space is often extremely large. As a result, directly searching in such a large search space is non-trivial and also very time-consuming. To address the above issues, in each search step, we seek to limit the search space to a small but effective subspace to boost both the search performance and search efficiency. To this end, we propose a novel Neural Architecture Search method via Automatic Subspace Evoking (ASE-NAS) that finds promising architectures in automatically evoked subspaces. Specifically, we first perform a global search, i.e., automatic subspace evoking, to evoke/find a good subspace from a set of candidates. Then, we perform a local search within the evoked subspace to find an effective architecture. More critically, we further boost search performance by taking well-designed/searched architectures as the initial candidate subspaces. Extensive experiments show that our ASE-NAS not only greatly reduces the search cost but also finds better architectures than state-of-the-art methods in various benchmark search spaces.
SeaDroneSim: Simulation of Aerial Images for Detection of Objects Above Water
Oct 31, 2022



Unmanned Aerial Vehicles (UAVs) are known for their fast and versatile applicability. With UAVs' growth in availability and applications, they are now of vital importance in serving as technological support in search-and-rescue(SAR) operations in marine environments. High-resolution cameras and GPUs can be equipped on the UAVs to provide effective and efficient aid to emergency rescue operations. With modern computer vision algorithms, we can detect objects for aiming such rescue missions. However, these modern computer vision algorithms are dependent on numerous amounts of training data from UAVs, which is time-consuming and labor-intensive for maritime environments. To this end, we present a new benchmark suite, SeaDroneSim, that can be used to create photo-realistic aerial image datasets with the ground truth for segmentation masks of any given object. Utilizing only the synthetic data generated from SeaDroneSim, we obtain 71 mAP on real aerial images for detecting BlueROV as a feasibility study. This result from the new simulation suit also serves as a baseline for the detection of BlueROV.
Ensemble transport smoothing -- Part 1: unified framework
Oct 31, 2022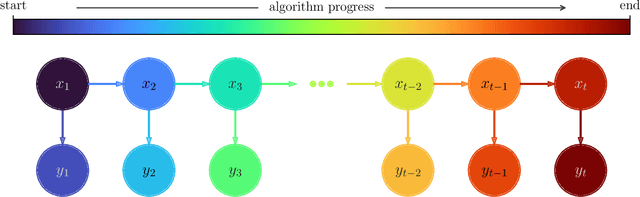
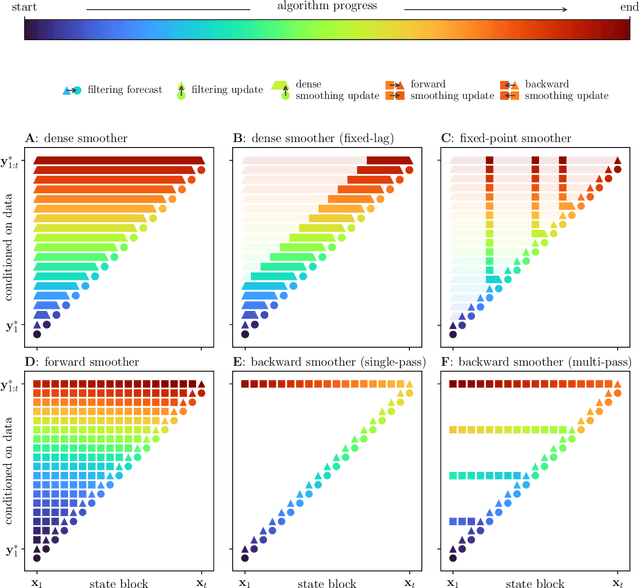
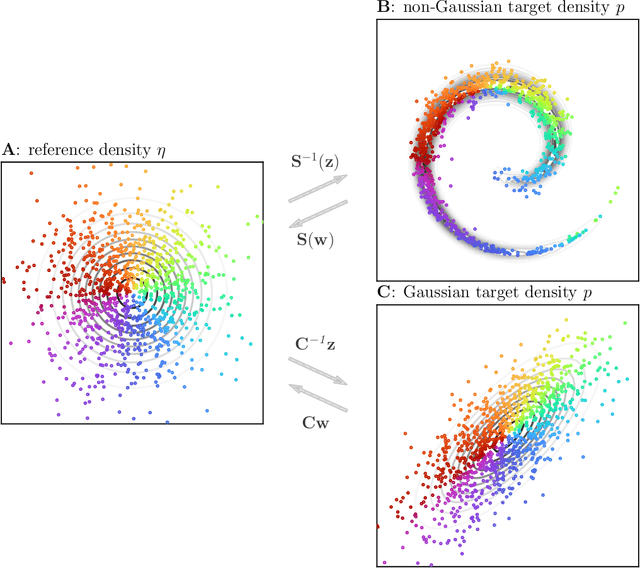
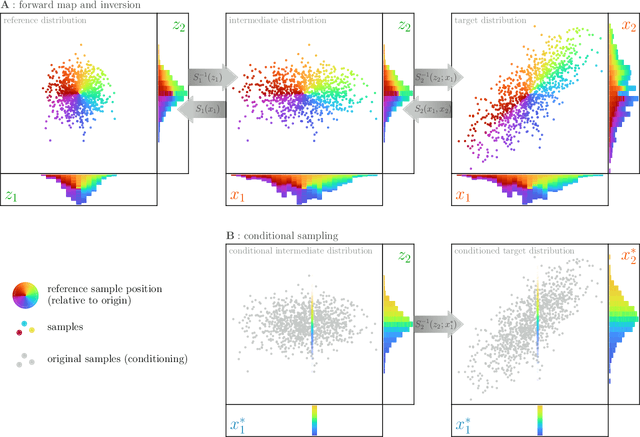
Smoothers are algorithms for Bayesian time series re-analysis. Most operational smoothers rely either on affine Kalman-type transformations or on sequential importance sampling. These strategies occupy opposite ends of a spectrum that trades computational efficiency and scalability for statistical generality and consistency: non-Gaussianity renders affine Kalman updates inconsistent with the true Bayesian solution, while the ensemble size required for successful importance sampling can be prohibitive. This paper revisits the smoothing problem from the perspective of measure transport, which offers the prospect of consistent prior-to-posterior transformations for Bayesian inference. We leverage this capacity by proposing a general ensemble framework for transport-based smoothing. Within this framework, we derive a comprehensive set of smoothing recursions based on nonlinear transport maps and detail how they exploit the structure of state-space models in fully non-Gaussian settings. We also describe how many standard Kalman-type smoothing algorithms emerge as special cases of our framework. A companion paper explores the implementation of nonlinear ensemble transport smoothers in greater depth.
Guided Conditional Diffusion for Controllable Traffic Simulation
Oct 31, 2022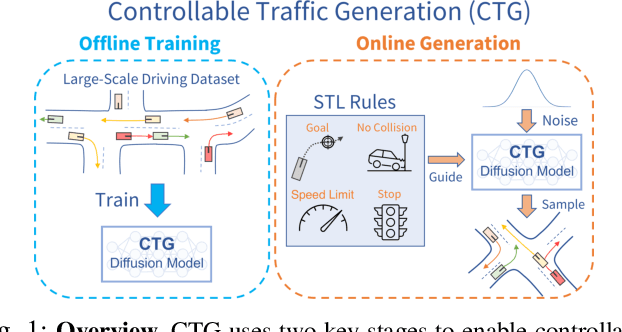
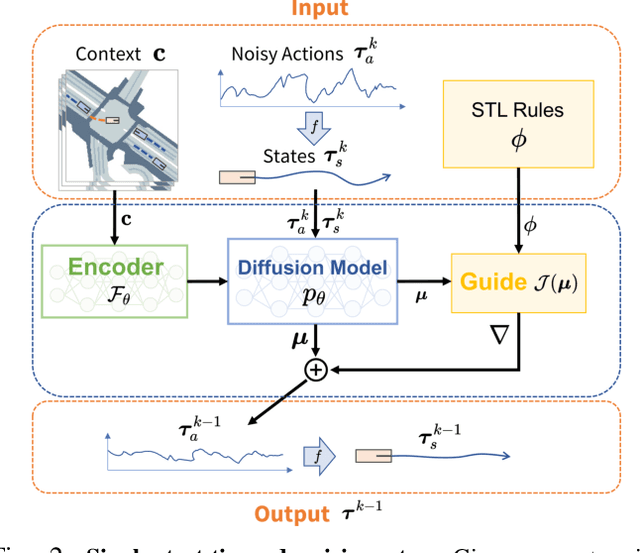
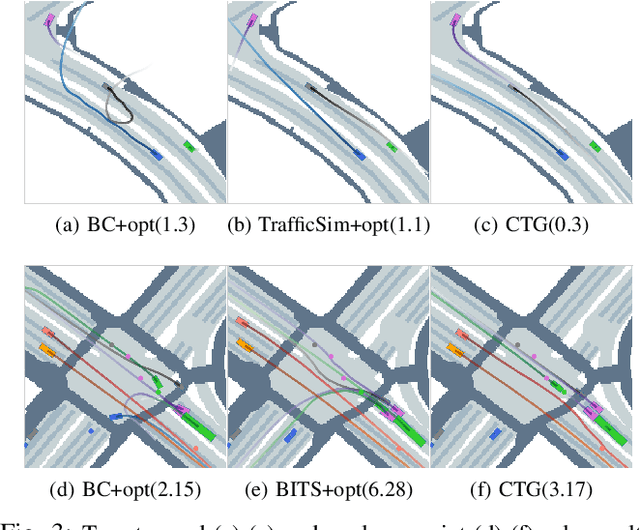

Controllable and realistic traffic simulation is critical for developing and verifying autonomous vehicles. Typical heuristic-based traffic models offer flexible control to make vehicles follow specific trajectories and traffic rules. On the other hand, data-driven approaches generate realistic and human-like behaviors, improving transfer from simulated to real-world traffic. However, to the best of our knowledge, no traffic model offers both controllability and realism. In this work, we develop a conditional diffusion model for controllable traffic generation (CTG) that allows users to control desired properties of trajectories at test time (e.g., reach a goal or follow a speed limit) while maintaining realism and physical feasibility through enforced dynamics. The key technical idea is to leverage recent advances from diffusion modeling and differentiable logic to guide generated trajectories to meet rules defined using signal temporal logic (STL). We further extend guidance to multi-agent settings and enable interaction-based rules like collision avoidance. CTG is extensively evaluated on the nuScenes dataset for diverse and composite rules, demonstrating improvement over strong baselines in terms of the controllability-realism tradeoff.
One-Shot Acoustic Matching Of Audio Signals -- Learning to Hear Music In Any Room/ Concert Hall
Oct 31, 2022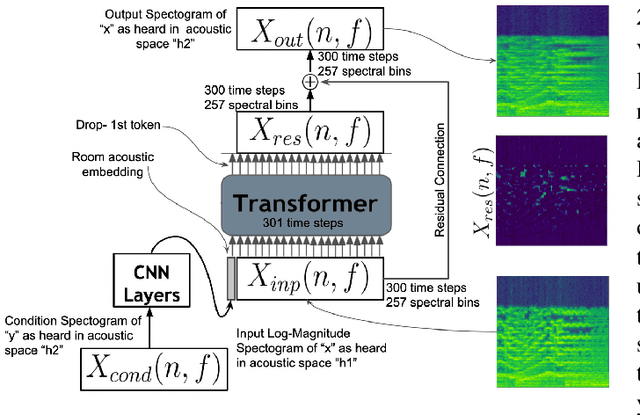
The acoustic space in which a sound is created and heard plays an essential role in how that sound is perceived by affording a unique sense of \textit{presence}. Every sound we hear results from successive convolution operations intrinsic to the sound source and external factors such as microphone characteristics and room impulse responses. Typically, researchers use an excitation such as a pistol shot or balloon pop as an impulse signal with which an auralization can be created. The room "impulse" responses convolved with the signal of interest can transform the input sound into the sound played in the acoustic space of interest. Here we propose a novel architecture that can transform a sound of interest into any other acoustic space(room or hall) of interest by using arbitrary audio recorded as a proxy for a balloon pop. The architecture is grounded in simple signal processing ideas to learn residual signals from a learned acoustic signature and the input signal. Our framework allows a neural network to adjust gains of every point in the time-frequency representation, giving sound qualitative and quantitative results.
Contact-Implicit Planning and Control for Non-Prehensile Manipulation Using State-Triggered Constraints
Oct 18, 2022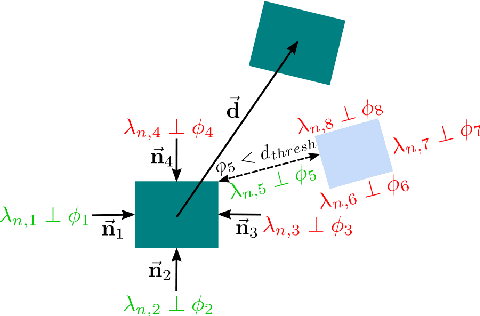
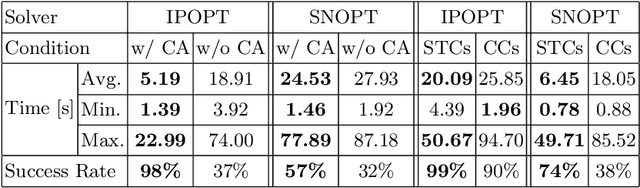
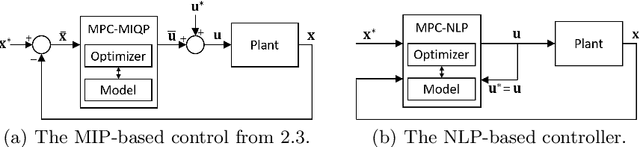
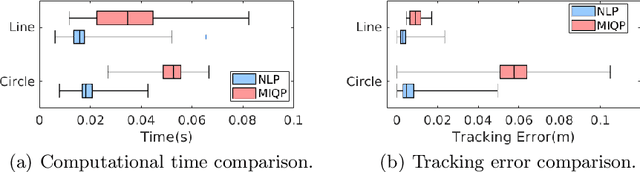
We present a contact-implicit planning approach that can generate contact-interaction trajectories for non-prehensile manipulation problems without tuning or a tailored initial guess and with high success rates. This is achieved by leveraging the concept of state-triggered constraints (STCs) to capture the hybrid dynamics induced by discrete contact modes without explicitly reasoning about the combinatorics. STCs enable triggering arbitrary constraints by a strict inequality condition in a continuous way. We first use STCs to develop an automatic contact constraint activation method to minimize the effective constraint space based on the utility of contact candidates for a given task. Then, we introduce a re-formulation of the Coulomb friction model based on STCs that is more efficient for the discovery of tangential forces than the well-studied complementarity constraints-based approach. Last, we include the proposed friction model in the planning and control of quasi-static planar pushing. The performance of the STC-based contact activation and friction methods is evaluated by extensive simulation experiments in a dynamic pushing scenario. The results demonstrate that our methods outperform the baselines based on complementarity constraints with a significant decrease in the planning time and a higher success rate. We then compare the proposed quasi-static pushing controller against a mixed-integer programming-based approach in simulation and find that our method is computationally more efficient and provides a better tracking accuracy, with the added benefit of not requiring an initial control trajectory. Finally, we present hardware experiments demonstrating the usability of our framework in executing complex trajectories in real-time even with a low-accuracy tracking system.
Real-Time Siamese Multiple Object Tracker with Enhanced Proposals
Feb 10, 2022
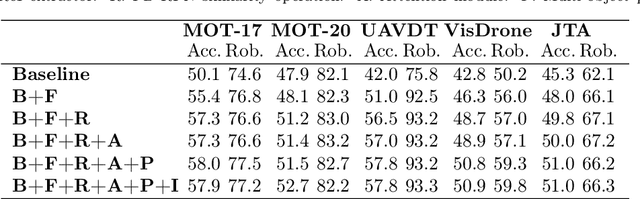
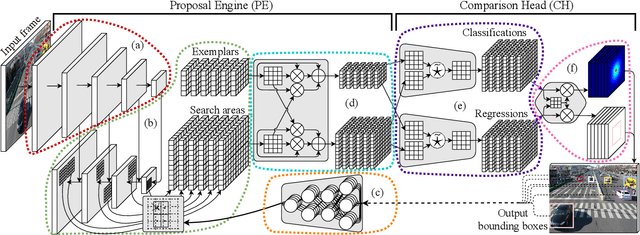
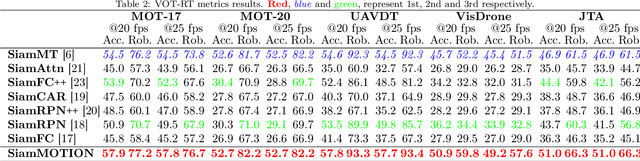
Maintaining the identity of multiple objects in real-time video is a challenging task, as it is not always possible to run a detector on every frame. Thus, motion estimation systems are often employed, which either do not scale well with the number of targets or produce features with limited semantic information. To solve the aforementioned problems and allow the tracking of dozens of arbitrary objects in real-time, we propose SiamMOTION. SiamMOTION includes a novel proposal engine that produces quality features through an attention mechanism and a region-of-interest extractor fed by an inertia module and powered by a feature pyramid network. Finally, the extracted tensors enter a comparison head that efficiently matches pairs of exemplars and search areas, generating quality predictions via a pairwise depthwise region proposal network and a multi-object penalization module. SiamMOTION has been validated on five public benchmarks, achieving leading performance against current state-of-the-art trackers.