 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Convex Optimization with Long Term Constraints for Predictable Sequences
Oct 30, 2022
In this paper, we investigate the framework of Online Convex Optimization (OCO) for online learning. OCO offers a very powerful online learning framework for many applications. In this context, we study a specific framework of OCO called {\it OCO with long term constraints}. Long term constraints are introduced typically as an alternative to reduce the complexity of the projection at every update step in online optimization. While many algorithmic advances have been made towards online optimization with long term constraints, these algorithms typically assume that the sequence of cost functions over a certain $T$ finite steps that determine the cost to the online learner are adversarially generated. In many circumstances, the sequence of cost functions may not be unrelated, and thus predictable from those observed till a point of time. In this paper, we study the setting where the sequences are predictable. We present a novel online optimization algorithm for online optimization with long term constraints that can leverage such predictability. We show that, with a predictor that can supply the gradient information of the next function in the sequence, our algorithm can achieve an overall regret and constraint violation rate that is strictly less than the rate that is achievable without prediction.
Progressive Denoising Model for Fine-Grained Text-to-Image Generation
Oct 05, 2022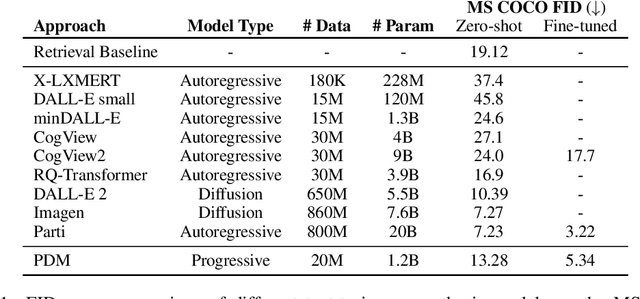

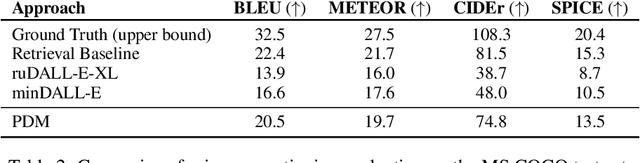
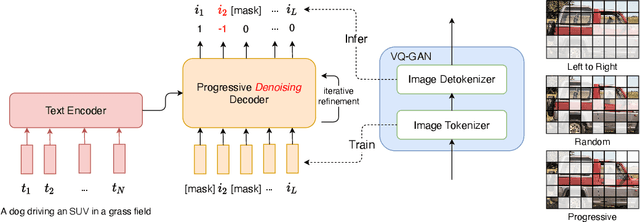
Recently, vector quantized autoregressive (VQ-AR) models have shown remarkable results in text-to-image synthesis by equally predicting discrete image tokens from the top left to bottom right in the latent space. Although the simple generative process surprisingly works well, is this the best way to generate the image? For instance, human creation is more inclined to the outline-to-fine of an image, while VQ-AR models themselves do not consider any relative importance of each component. In this paper, we present a progressive denoising model for high-fidelity text-to-image image generation. The proposed method takes effect by creating new image tokens from coarse to fine based on the existing context in a parallel manner and this procedure is recursively applied until an image sequence is completed. The resulting coarse-to-fine hierarchy makes the image generation process intuitive and interpretable. Extensive experiments demonstrate that the progressive model produces significantly better results when compared with the previous VQ-AR method in FID score across a wide variety of categories and aspects. Moreover, the text-to-image generation time of traditional AR increases linearly with the output image resolution and hence is quite time-consuming even for normal-size images. In contrast, our approach allows achieving a better trade-off between generation quality and speed.
Pruning's Effect on Generalization Through the Lens of Training and Regularization
Oct 25, 2022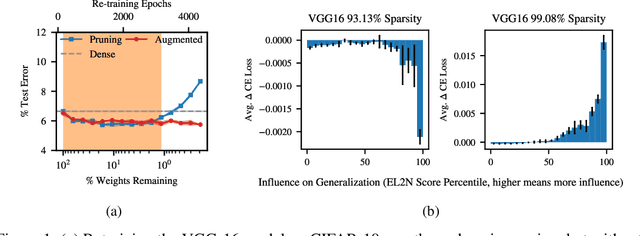
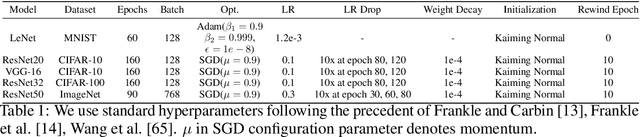
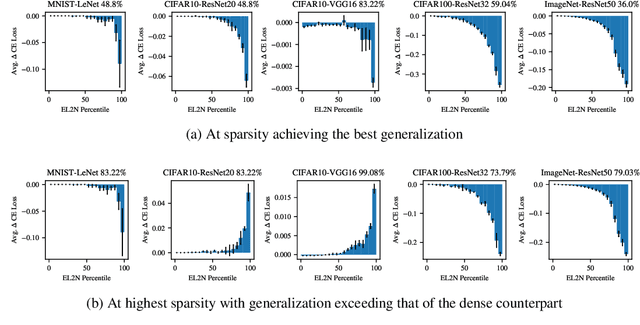
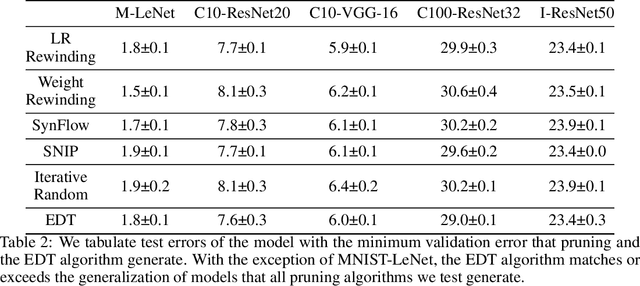
Practitioners frequently observe that pruning improves model generalization. A long-standing hypothesis based on bias-variance trade-off attributes this generalization improvement to model size reduction. However, recent studies on over-parameterization characterize a new model size regime, in which larger models achieve better generalization. Pruning models in this over-parameterized regime leads to a contradiction -- while theory predicts that reducing model size harms generalization, pruning to a range of sparsities nonetheless improves it. Motivated by this contradiction, we re-examine pruning's effect on generalization empirically. We show that size reduction cannot fully account for the generalization-improving effect of standard pruning algorithms. Instead, we find that pruning leads to better training at specific sparsities, improving the training loss over the dense model. We find that pruning also leads to additional regularization at other sparsities, reducing the accuracy degradation due to noisy examples over the dense model. Pruning extends model training time and reduces model size. These two factors improve training and add regularization respectively. We empirically demonstrate that both factors are essential to fully explaining pruning's impact on generalization.
* 49 pages, 20 figures
Recommendation with User Active Disclosing Willingness
Oct 25, 2022
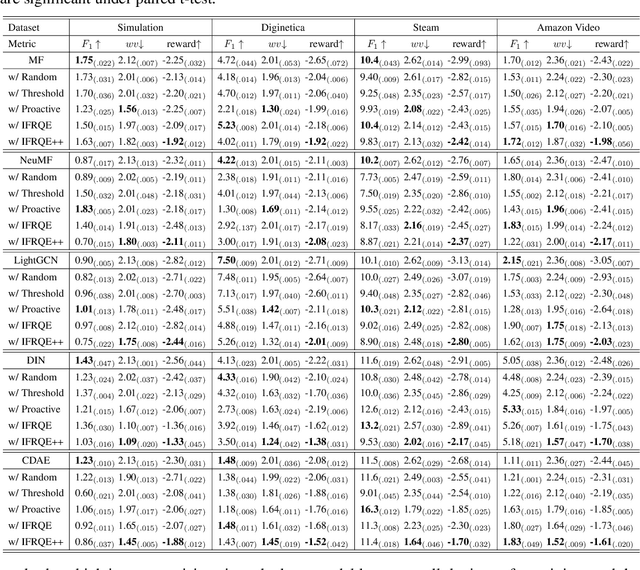
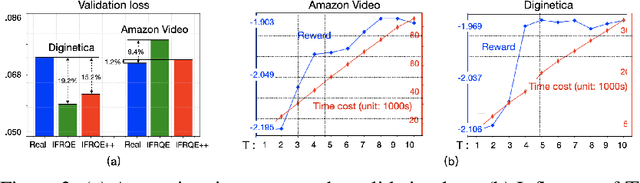
Recommender system has been deployed in a large amount of real-world applications, profoundly influencing people's daily life and production.Traditional recommender models mostly collect as comprehensive as possible user behaviors for accurate preference estimation. However, considering the privacy, preference shaping and other issues, the users may not want to disclose all their behaviors for training the model. In this paper, we study a novel recommendation paradigm, where the users are allowed to indicate their "willingness" on disclosing different behaviors, and the models are optimized by trading-off the recommendation quality as well as the violation of the user "willingness". More specifically, we formulate the recommendation problem as a multiplayer game, where the action is a selection vector representing whether the items are involved into the model training. For efficiently solving this game, we design a tailored algorithm based on influence function to lower the time cost for recommendation quality exploration, and also extend it with multiple anchor selection vectors.We conduct extensive experiments to demonstrate the effectiveness of our model on balancing the recommendation quality and user disclosing willingness.
Goal-Driven Context-Aware Next Service Recommendation for Mashup Composition
Oct 25, 2022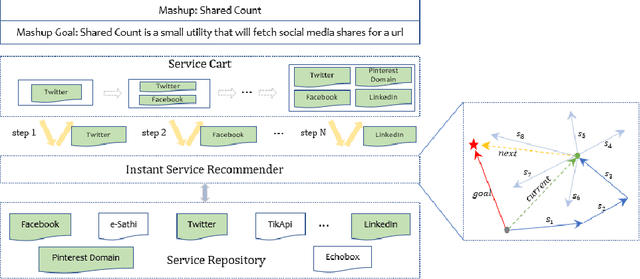

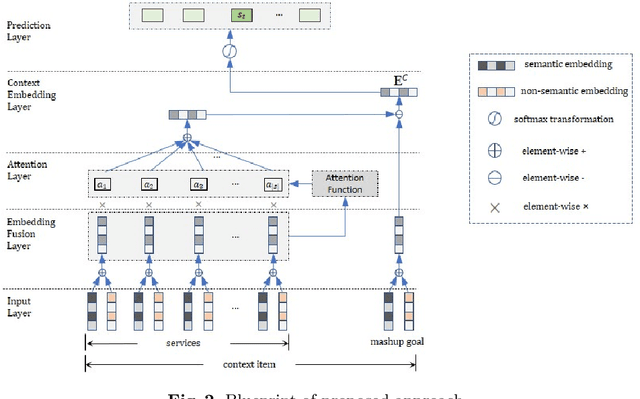
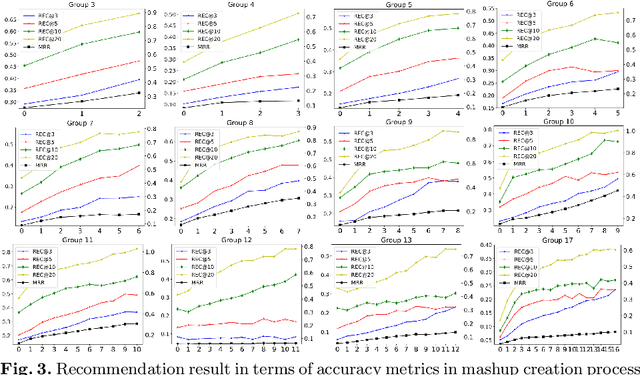
As service-oriented architecture becoming one of the most prevalent techniques to rapidly deliver functionalities to customers, increasingly more reusable software components have been published online in forms of web services. To create a mashup, it gets not only time-consuming but also error-prone for developers to find suitable services from such a sea of services. Service discovery and recommendation has thus attracted significant momentum in both academia and industry. This paper proposes a novel incremental recommend-as-you-go approach to recommending next potential service based on the context of a mashup under construction, considering services that have been selected to the current step as well as its mashup goal. The core technique is an algorithm of learning the embedding of services, which learns their past goal-driven context-aware decision making behaviors in addition to their semantic descriptions and co-occurrence history. A goal exclusionary negative sampling mechanism tailored for mashup development is also developed to improve training performance. Extensive experiments on a real-world dataset demonstrate the effectiveness of our approach.
Removing Radio Frequency Interference from Auroral Kilometric Radiation with Stacked Autoencoders
Oct 25, 2022
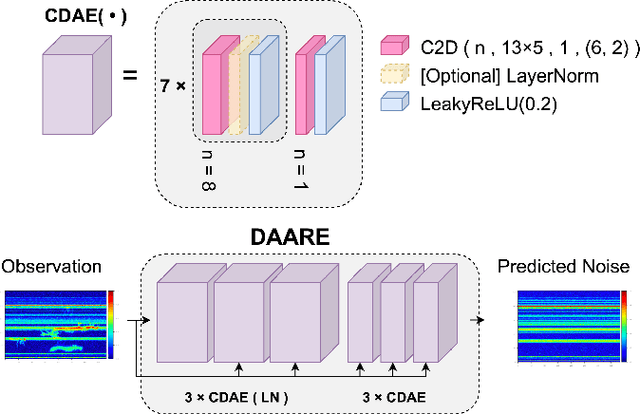


Radio frequency data in astronomy enable scientists to analyze astrophysical phenomena. However, these data can be corrupted by a host of radio frequency interference (RFI) sources that limit the ability to observe underlying natural processes. In this study, we extended recent work in image processing to remove RFI from time-frequency spectrograms containing auroral kilometric radiation (AKR), a coherent radio emission originating from the Earth's auroral zones that is used to study astrophysical plasmas. We present a Denoising Autoencoder for Auroral Radio Emissions (DAARE) trained with synthetic spectrograms to denoise AKR spectrograms collected at the South Pole Station. DAARE achieved 42.2 peak-signal-to-noise ratio (PSNR) and 0.981 structural similarity (SSIM) on synthesized AKR observations, improving PSNR by 3.9 and SSIM by 0.064 compared to state-of-the-art filtering and denoising networks. Qualitative comparisons demonstrate DAARE's denoising capability to effectively remove RFI from real AKR observations, despite being trained completely on a dataset of simulated AKR. The framework for simulating AKR, training DAARE, and employing DAARE can be accessed at https://github.com/Cylumn/daare.
Receiver Bandwidth Extension Beyond Nyquist Using Channel Bonding
Oct 14, 2022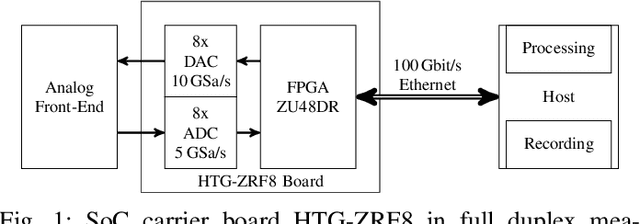
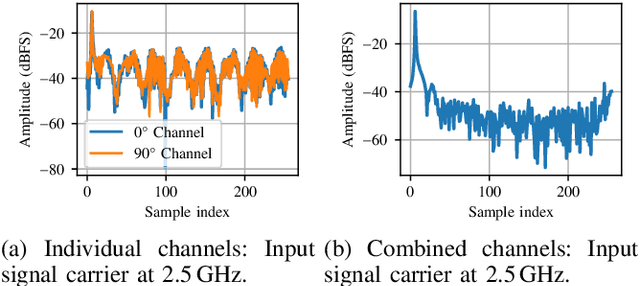
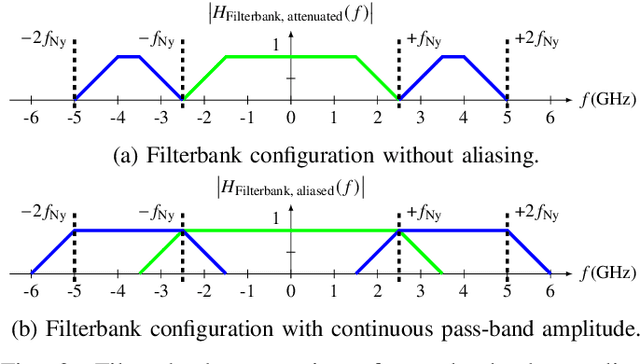
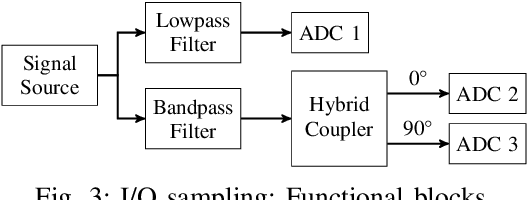
Current and upcoming communication and sensing technologies require ever larger bandwidths. Channel bonding can be utilized to extend a receiver's instantaneous bandwidth beyond a single converter's Nyquist limit. Two potential joint front-end and converter design approaches are theoretically introduced, realized and evaluated in this paper. The Xilinx RFSoC platform with its 5 GSa/s analog to digital converters (ADCs) is used to implement both a hybrid coupler based in-phase/quadrature (I/Q) sampling and a time-interleaved sampling approach along with channel bonding. Both realizations are demonstrated to be able to reconstruct instantaneous bandwidths of 5 GHz with up to 49 dB image rejection ratio (IRR) typically within 4 to 8 dB the front-ends' theoretical limits.
Learning Sparse and Continuous Graph Structures for Multivariate Time Series Forecasting
Jan 24, 2022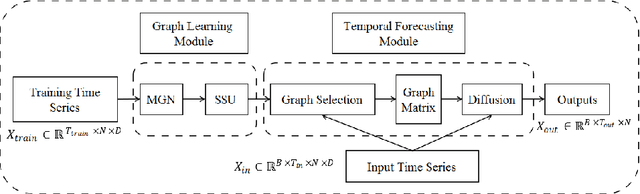

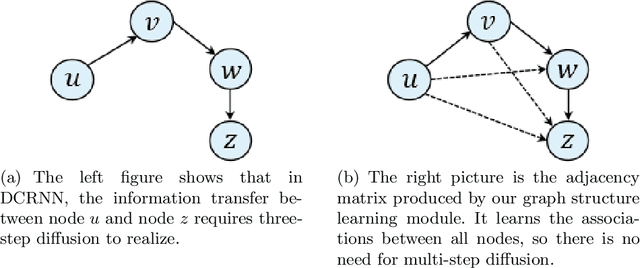
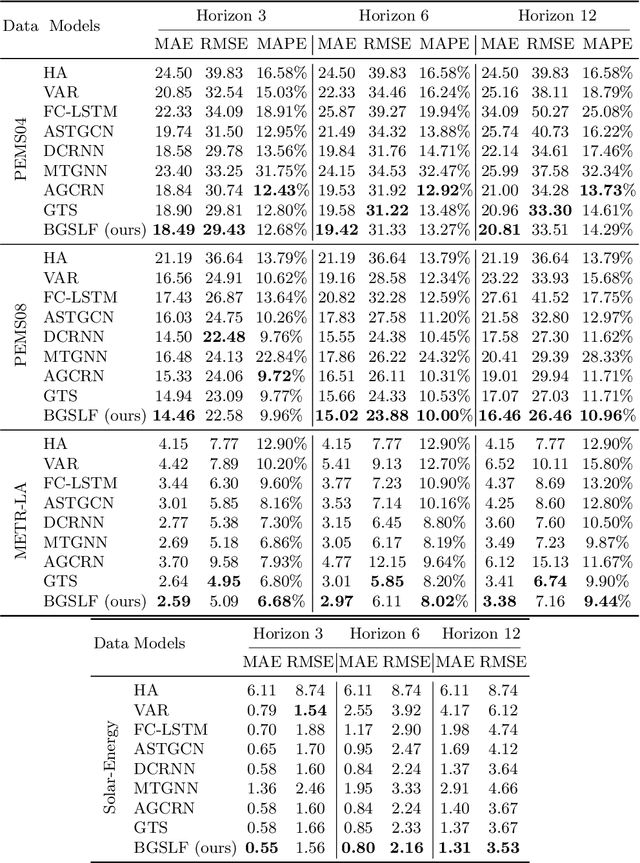
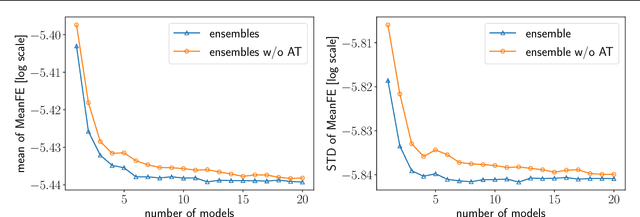
Accurate forecasting of multivariate time series is an extensively studied subject in finance, transportation, and computer science. Fully mining the correlation and causation between the variables in a multivariate time series exhibits noticeable results in improving the performance of a time series model. Recently, some models have explored the dependencies between variables through end-to-end graph structure learning without the need for pre-defined graphs. However, most current models do not incorporate the trade-off between effectiveness and flexibility and lack the guidance of domain knowledge in the design of graph learning algorithms. Besides, they have issues generating sparse graph structures, which pose challenges to end-to-end learning. In this paper, we propose Learning Sparse and Continuous Graphs for Forecasting (LSCGF), a novel deep learning model that joins graph learning and forecasting. Technically, LSCGF leverages the spatial information into convolutional operation and extracts temporal dynamics using the diffusion convolution recurrent network. At the same time, we propose a brand new method named Smooth Sparse Unit (SSU) to learn sparse and continuous graph adjacency matrix. Extensive experiments on three real-world datasets demonstrate that our model achieves state-of-the-art performances with minor trainable parameters.
Probabilistic Dalek -- Emulator framework with probabilistic prediction for supernova tomography
Sep 20, 2022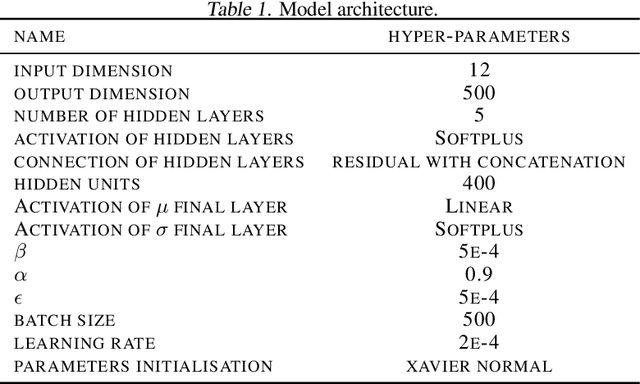
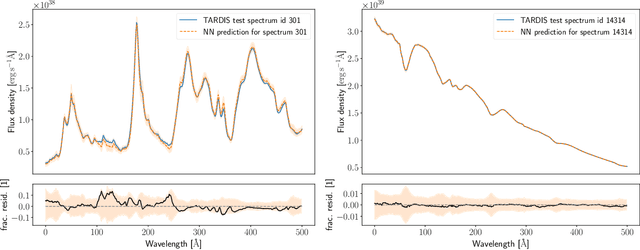
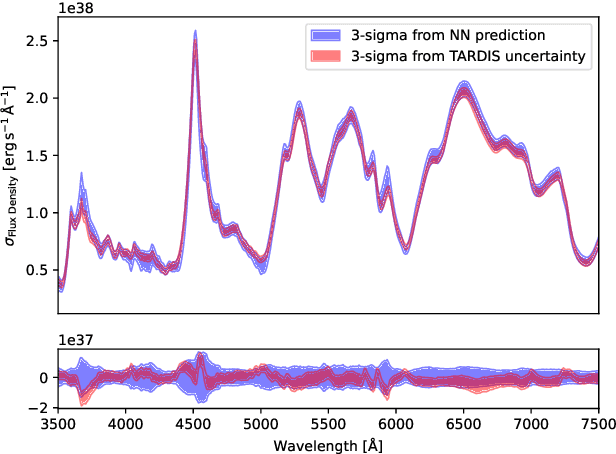
Supernova spectral time series can be used to reconstruct a spatially resolved explosion model known as supernova tomography. In addition to an observed spectral time series, a supernova tomography requires a radiative transfer model to perform the inverse problem with uncertainty quantification for a reconstruction. The smallest parametrizations of supernova tomography models are roughly a dozen parameters with a realistic one requiring more than 100. Realistic radiative transfer models require tens of CPU minutes for a single evaluation making the problem computationally intractable with traditional means requiring millions of MCMC samples for such a problem. A new method for accelerating simulations known as surrogate models or emulators using machine learning techniques offers a solution for such problems and a way to understand progenitors/explosions from spectral time series. There exist emulators for the TARDIS supernova radiative transfer code but they only perform well on simplistic low-dimensional models (roughly a dozen parameters) with a small number of applications for knowledge gain in the supernova field. In this work, we present a new emulator for the radiative transfer code TARDIS that not only outperforms existing emulators but also provides uncertainties in its prediction. It offers the foundation for a future active-learning-based machinery that will be able to emulate very high dimensional spaces of hundreds of parameters crucial for unraveling urgent questions in supernovae and related fields.
Toward Human-AI Co-creation to Accelerate Material Discovery
Nov 05, 2022


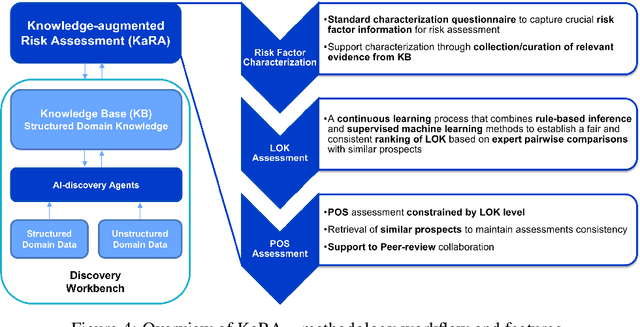
There is an increasing need in our society to achieve faster advances in Science to tackle urgent problems, such as climate changes, environmental hazards, sustainable energy systems, pandemics, among others. In certain domains like chemistry, scientific discovery carries the extra burden of assessing risks of the proposed novel solutions before moving to the experimental stage. Despite several recent advances in Machine Learning and AI to address some of these challenges, there is still a gap in technologies to support end-to-end discovery applications, integrating the myriad of available technologies into a coherent, orchestrated, yet flexible discovery process. Such applications need to handle complex knowledge management at scale, enabling knowledge consumption and production in a timely and efficient way for subject matter experts (SMEs). Furthermore, the discovery of novel functional materials strongly relies on the development of exploration strategies in the chemical space. For instance, generative models have gained attention within the scientific community due to their ability to generate enormous volumes of novel molecules across material domains. These models exhibit extreme creativity that often translates in low viability of the generated candidates. In this work, we propose a workbench framework that aims at enabling the human-AI co-creation to reduce the time until the first discovery and the opportunity costs involved. This framework relies on a knowledge base with domain and process knowledge, and user-interaction components to acquire knowledge and advise the SMEs. Currently,the framework supports four main activities: generative modeling, dataset triage, molecule adjudication, and risk assessment.