 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Koopman-based spectral clustering of directed and time-evolving graphs
Apr 06, 2022
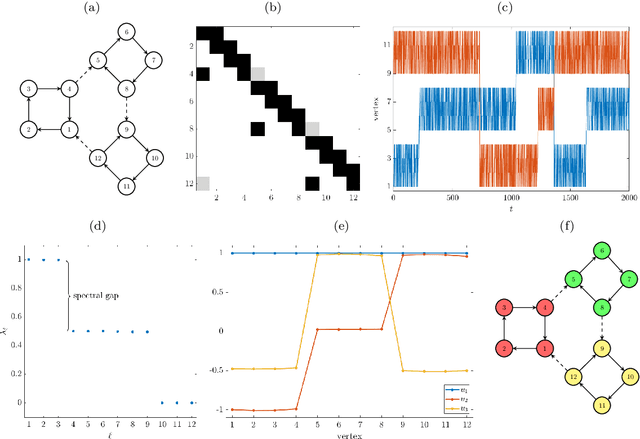
While spectral clustering algorithms for undirected graphs are well established and have been successfully applied to unsupervised machine learning problems ranging from image segmentation and genome sequencing to signal processing and social network analysis, clustering directed graphs remains notoriously difficult. Two of the main challenges are that the eigenvalues and eigenvectors of graph Laplacians associated with directed graphs are in general complex-valued and that there is no universally accepted definition of clusters in directed graphs. We first exploit relationships between the graph Laplacian and transfer operators and in particular between clusters in undirected graphs and metastable sets in stochastic dynamical systems and then use a generalization of the notion of metastability to derive clustering algorithms for directed and time-evolving graphs. The resulting clusters can be interpreted as coherent sets, which play an important role in the analysis of transport and mixing processes in fluid flows.
Optimization-Based Motion Planning for Autonomous Parking Considering Dynamic Obstacle: A Hierarchical Framework
Oct 24, 2022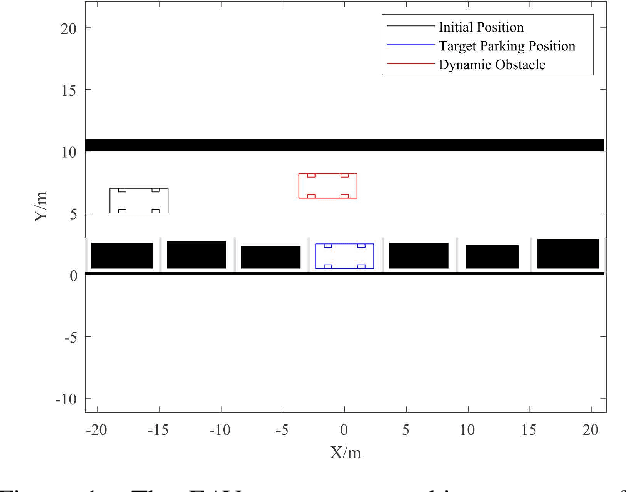
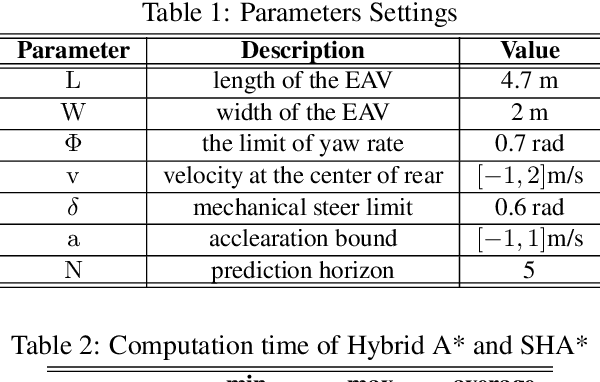
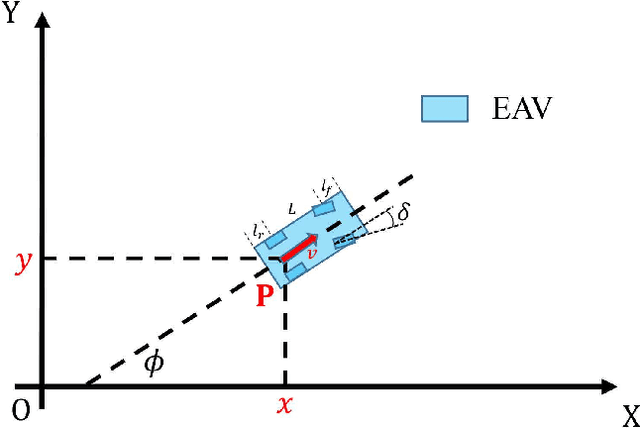
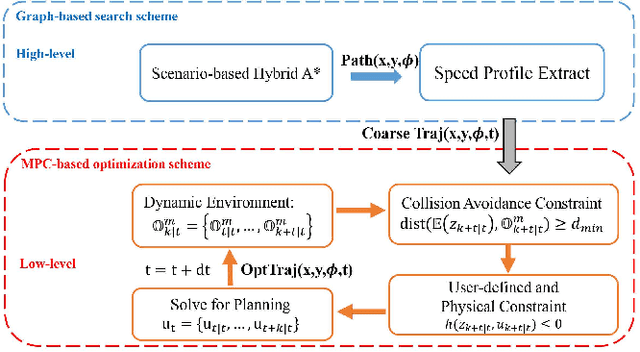
We present a hierarchical framework based on graph search and model predictive control (MPC) for electric autonomous vehicle (EAV) parking maneuvers in a tight environment. At high-level, only static obstacles are considered, and the scenario-based hybrid A* (SHA*), which is faster than the traditional hybrid A*, is designed to provide an initial guess (also known as a global path) for the parking task. To extract the velocity and acceleration profile from an initial guess, an optimal control problem (OCP) is built. At the low level, an NMPC-based strategy is used to avoid dynamic obstacles (also known as local planning). The efficacy of SHA* is evaluated through 148 different simulation schemes and the proposed hierarchical parking framework is demonstrated through a real-time parallel parking simulation.
A Data Cube of Big Satellite Image Time-Series for Agriculture Monitoring
May 16, 2022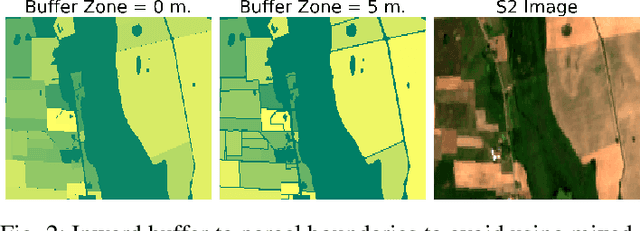

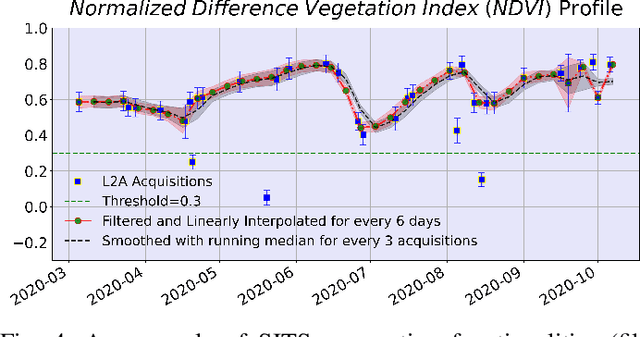
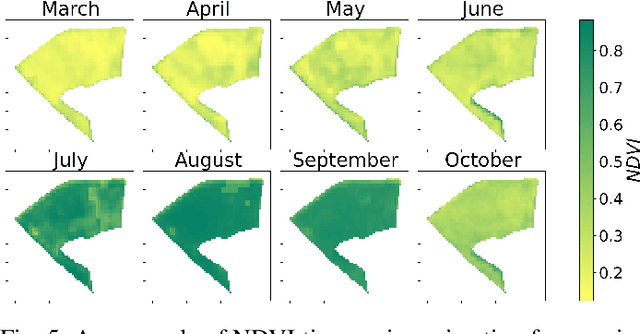
The modernization of the Common Agricultural Policy (CAP) requires the large scale and frequent monitoring of agricultural land. Towards this direction, the free and open satellite data (i.e., Sentinel missions) have been extensively used as the sources for the required high spatial and temporal resolution Earth observations. Nevertheless, monitoring the CAP at large scales constitutes a big data problem and puts a strain on CAP paying agencies that need to adapt fast in terms of infrastructure and know-how. Hence, there is a need for efficient and easy-to-use tools for the acquisition, storage, processing and exploitation of big satellite data. In this work, we present the Agriculture monitoring Data Cube (ADC), which is an automated, modular, end-to-end framework for discovering, pre-processing and indexing optical and Synthetic Aperture Radar (SAR) images into a multidimensional cube. We also offer a set of powerful tools on top of the ADC, including i) the generation of analysis-ready feature spaces of big satellite data to feed downstream machine learning tasks and ii) the support of Satellite Image Time-Series (SITS) analysis via services pertinent to the monitoring of the CAP (e.g., detecting trends and events, monitoring the growth status etc.). The knowledge extracted from the SITS analyses and the machine learning tasks returns to the data cube, building scalable country-specific knowledge bases that can efficiently answer complex and multi-faceted geospatial queries.
AutoCTS: Automated Correlated Time Series Forecasting -- Extended Version
Dec 21, 2021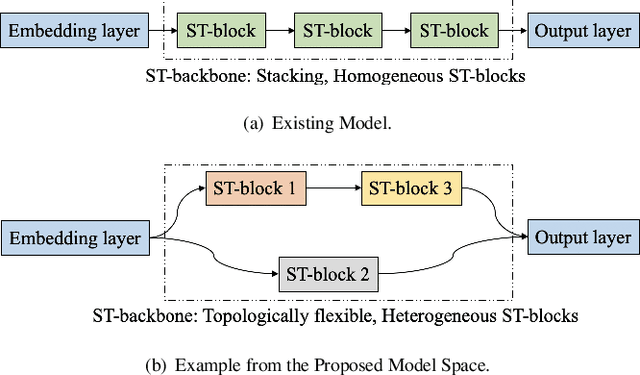
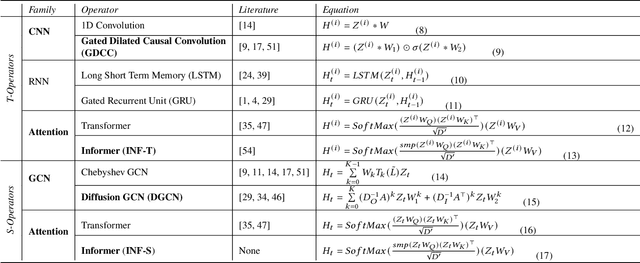
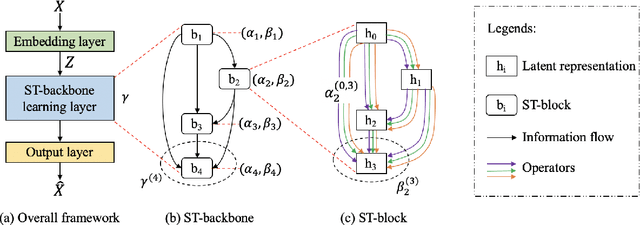

Correlated time series (CTS) forecasting plays an essential role in many cyber-physical systems, where multiple sensors emit time series that capture interconnected processes. Solutions based on deep learning that deliver state-of-the-art CTS forecasting performance employ a variety of spatio-temporal (ST) blocks that are able to model temporal dependencies and spatial correlations among time series. However, two challenges remain. First, ST-blocks are designed manually, which is time consuming and costly. Second, existing forecasting models simply stack the same ST-blocks multiple times, which limits the model potential. To address these challenges, we propose AutoCTS that is able to automatically identify highly competitive ST-blocks as well as forecasting models with heterogeneous ST-blocks connected using diverse topologies, as opposed to the same ST-blocks connected using simple stacking. Specifically, we design both a micro and a macro search space to model possible architectures of ST-blocks and the connections among heterogeneous ST-blocks, and we provide a search strategy that is able to jointly explore the search spaces to identify optimal forecasting models. Extensive experiments on eight commonly used CTS forecasting benchmark datasets justify our design choices and demonstrate that AutoCTS is capable of automatically discovering forecasting models that outperform state-of-the-art human-designed models. This is an extended version of ``AutoCTS: Automated Correlated Time Series Forecasting'', to appear in PVLDB 2022.
Conversion-Based Dynamic-Creative-Optimization in Native Advertising
Nov 13, 2022
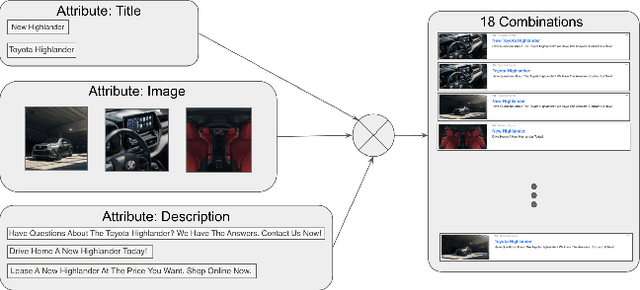

Yahoo Gemini native advertising marketplace serves billions of impressions daily, to hundreds millions of unique users, and reaches a yearly revenue of many hundreds of millions USDs. Powering Gemini native models for predicting advertise (ad) event probabilities, such as conversions and clicks, is OFFSET - a feature enhanced collaborative-filtering (CF) based event prediction algorithm. The predicted probabilities are then used in Gemini native auctions to determine which ads to present for every serving event (impression). Dynamic creative optimization (DCO) is a recent Gemini native product that was launched two years ago and is increasingly gaining more attention from advertisers. The DCO product enables advertisers to issue several assets per each native ad attribute, creating multiple combinations for each DCO ad. Since different combinations may appeal to different crowds, it may be beneficial to present certain combinations more frequently than others to maximize revenue while keeping advertisers and users satisfied. The initial DCO offer was to optimize click-through rates (CTR), however as the marketplace shifts more towards conversion based campaigns, advertisers also ask for a {conversion based solution. To accommodate this request, we present a post-auction solution, where DCO ads combinations are favored according to their predicted conversion rate (CVR). The predictions are provided by an auxiliary OFFSET based combination CVR prediction model, and used to generate the combination distributions for DCO ad rendering during serving time. An online evaluation of this explore-exploit solution, via online bucket A/B testing, serving Gemini native DCO traffic, showed a 53.5% CVR lift, when compared to a control bucket serving all combinations uniformly at random.
Towards Reliable Zero Shot Classification in Self-Supervised Models with Conformal Prediction
Oct 27, 2022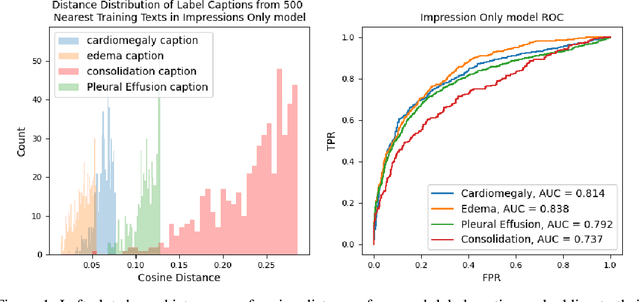
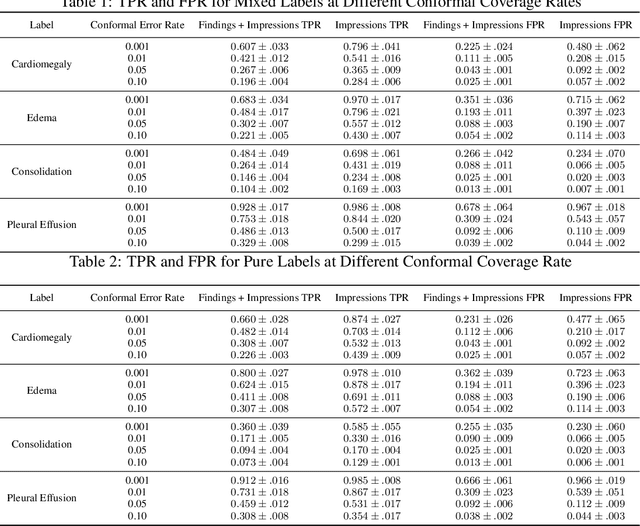
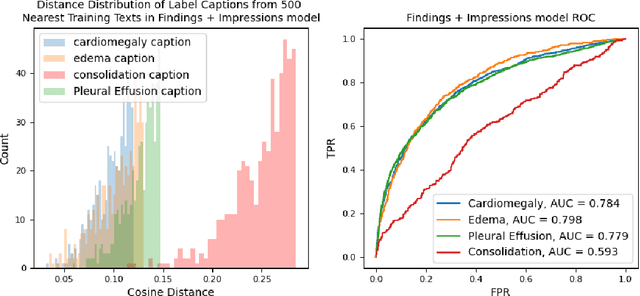

Self-supervised models trained with a contrastive loss such as CLIP have shown to be very powerful in zero-shot classification settings. However, to be used as a zero-shot classifier these models require the user to provide new captions over a fixed set of labels at test time. In many settings, it is hard or impossible to know if a new query caption is compatible with the source captions used to train the model. We address these limitations by framing the zero-shot classification task as an outlier detection problem and develop a conformal prediction procedure to assess when a given test caption may be reliably used. On a real-world medical example, we show that our proposed conformal procedure improves the reliability of CLIP-style models in the zero-shot classification setting, and we provide an empirical analysis of the factors that may affect its performance.
Pseudo Polynomial-Time Top-k Algorithms for d-DNNF Circuits
Feb 11, 2022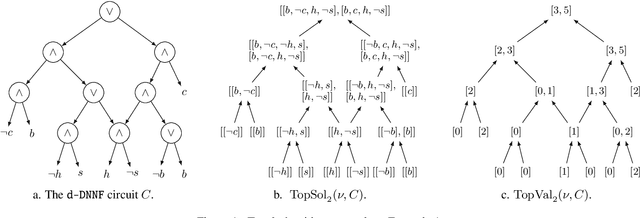

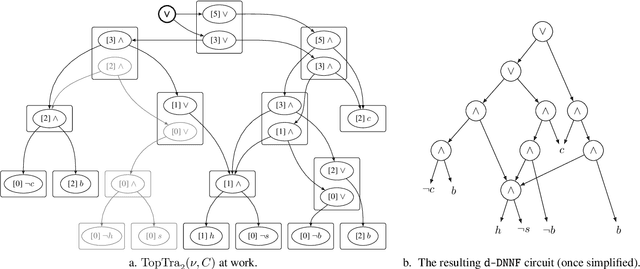
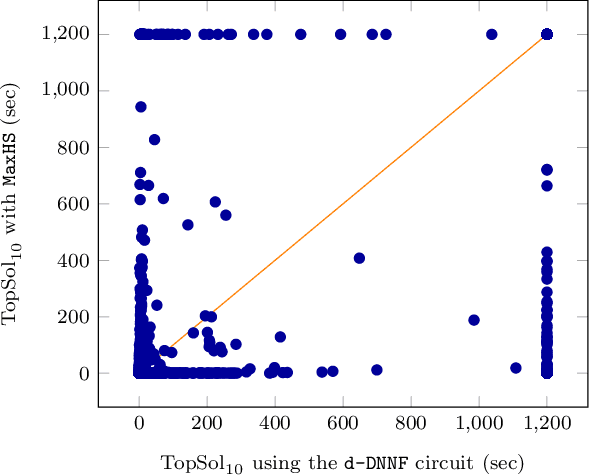
We are interested in computing $k$ most preferred models of a given d-DNNF circuit $C$, where the preference relation is based on an algebraic structure called a monotone, totally ordered, semigroup $(K, \otimes, <)$. In our setting, every literal in $C$ has a value in $K$ and the value of an assignment is an element of $K$ obtained by aggregating using $\otimes$ the values of the corresponding literals. We present an algorithm that computes $k$ models of $C$ among those having the largest values w.r.t. $<$, and show that this algorithm runs in time polynomial in $k$ and in the size of $C$. We also present a pseudo polynomial-time algorithm for deriving the top-$k$ values that can be reached, provided that an additional (but not very demanding) requirement on the semigroup is satisfied. Under the same assumption, we present a pseudo polynomial-time algorithm that transforms $C$ into a d-DNNF circuit $C'$ satisfied exactly by the models of $C$ having a value among the top-$k$ ones. Finally, focusing on the semigroup $(\mathbb{N}, +, <)$, we compare on a large number of instances the performances of our compilation-based algorithm for computing $k$ top solutions with those of an algorithm tackling the same problem, but based on a partial weighted MaxSAT solver.
Deep Learning for Rapid Landslide Detection using Synthetic Aperture Radar (SAR) Datacubes
Nov 05, 2022

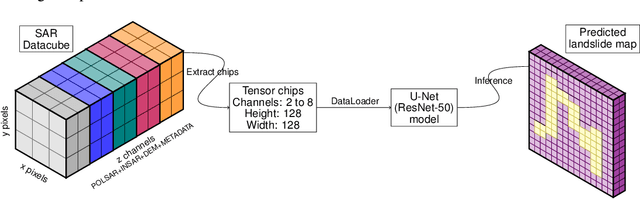
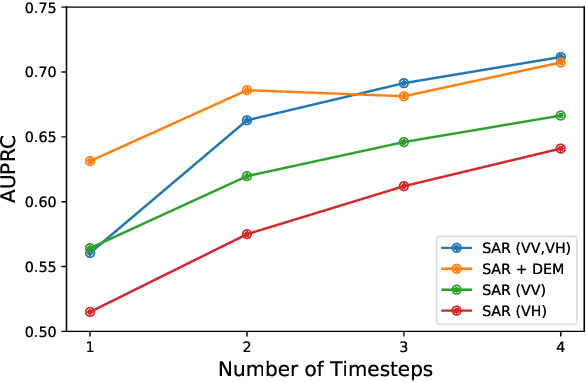
With climate change predicted to increase the likelihood of landslide events, there is a growing need for rapid landslide detection technologies that help inform emergency responses. Synthetic Aperture Radar (SAR) is a remote sensing technique that can provide measurements of affected areas independent of weather or lighting conditions. Usage of SAR, however, is hindered by domain knowledge that is necessary for the pre-processing steps and its interpretation requires expert knowledge. We provide simplified, pre-processed, machine-learning ready SAR datacubes for four globally located landslide events obtained from several Sentinel-1 satellite passes before and after a landslide triggering event together with segmentation maps of the landslides. From this dataset, using the Hokkaido, Japan datacube, we study the feasibility of SAR-based landslide detection with supervised deep learning (DL). Our results demonstrate that DL models can be used to detect landslides from SAR data, achieving an Area under the Precision-Recall curve exceeding 0.7. We find that additional satellite visits enhance detection performance, but that early detection is possible when SAR data is combined with terrain information from a digital elevation model. This can be especially useful for time-critical emergency interventions. Code is made publicly available at https://github.com/iprapas/landslide-sar-unet.
Liquid Structural State-Space Models
Sep 26, 2022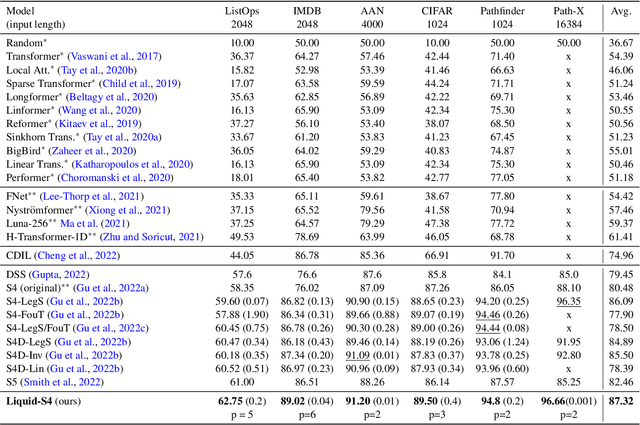
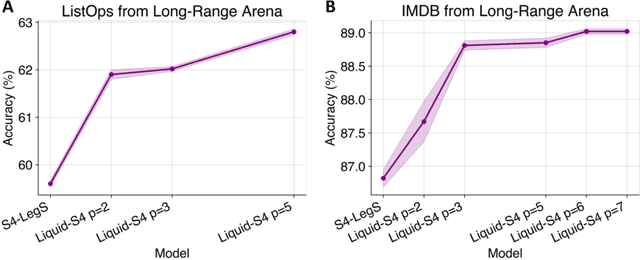
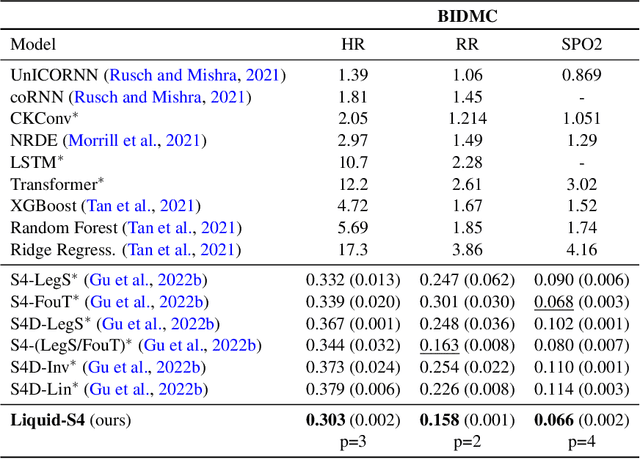
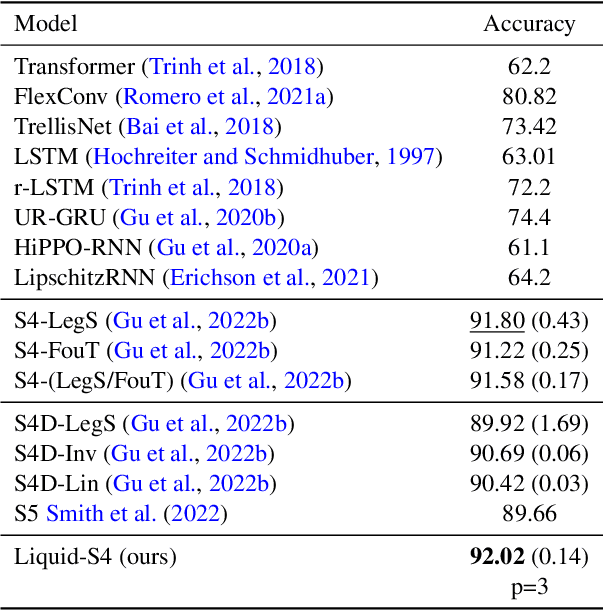
A proper parametrization of state transition matrices of linear state-space models (SSMs) followed by standard nonlinearities enables them to efficiently learn representations from sequential data, establishing the state-of-the-art on a large series of long-range sequence modeling benchmarks. In this paper, we show that we can improve further when the structural SSM such as S4 is given by a linear liquid time-constant (LTC) state-space model. LTC neural networks are causal continuous-time neural networks with an input-dependent state transition module, which makes them learn to adapt to incoming inputs at inference. We show that by using a diagonal plus low-rank decomposition of the state transition matrix introduced in S4, and a few simplifications, the LTC-based structural state-space model, dubbed Liquid-S4, achieves the new state-of-the-art generalization across sequence modeling tasks with long-term dependencies such as image, text, audio, and medical time-series, with an average performance of 87.32% on the Long-Range Arena benchmark. On the full raw Speech Command recognition, dataset Liquid-S4 achieves 96.78% accuracy with a 30% reduction in parameter counts compared to S4. The additional gain in performance is the direct result of the Liquid-S4's kernel structure that takes into account the similarities of the input sequence samples during training and inference.
GENIUS: A Novel Solution for Subteam Replacement with Clustering-based Graph Neural Network
Nov 11, 2022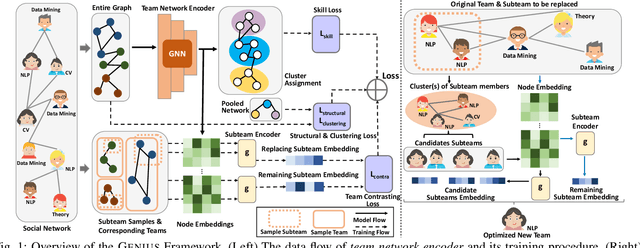
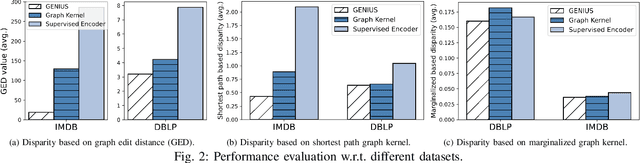
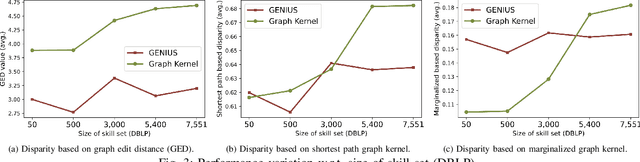
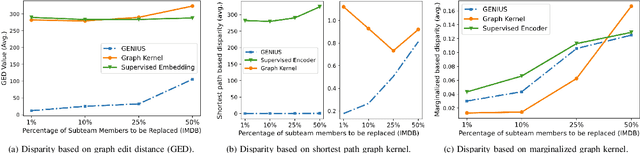
Subteam replacement is defined as finding the optimal candidate set of people who can best function as an unavailable subset of members (i.e., subteam) for certain reasons (e.g., conflicts of interests, employee churn), given a team of people embedded in a social network working on the same task. Prior investigations on this problem incorporate graph kernel as the optimal criteria for measuring the similarity between the new optimized team and the original team. However, the increasingly abundant social networks reveal fundamental limitations of existing methods, including (1) the graph kernel-based approaches are powerless to capture the key intrinsic correlations among node features, (2) they generally search over the entire network for every member to be replaced, making it extremely inefficient as the network grows, and (3) the requirement of equal-sized replacement for the unavailable subteam can be inapplicable due to limited hiring budget. In this work, we address the limitations in the state-of-the-art for subteam replacement by (1) proposing GENIUS, a novel clustering-based graph neural network (GNN) framework that can capture team network knowledge for flexible subteam replacement, and (2) equipping the proposed GENIUS with self-supervised positive team contrasting training scheme to improve the team-level representation learning and unsupervised node clusters to prune candidates for fast computation. Through extensive empirical evaluations, we demonstrate the efficacy of the proposed method (1) effectiveness: being able to select better candidate members that significantly increase the similarity between the optimized and original teams, and (2) efficiency: achieving more than 600 times speed-up in average running time.