 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LiDAR-guided object search and detection in Subterranean Environments
Oct 26, 2022

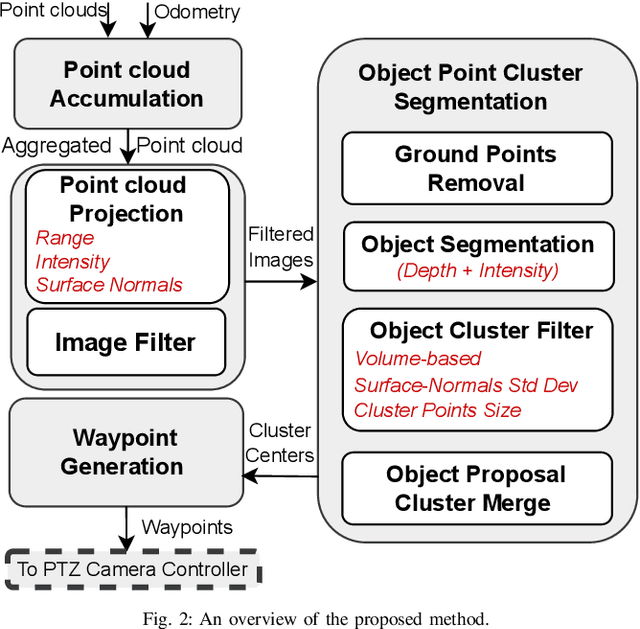

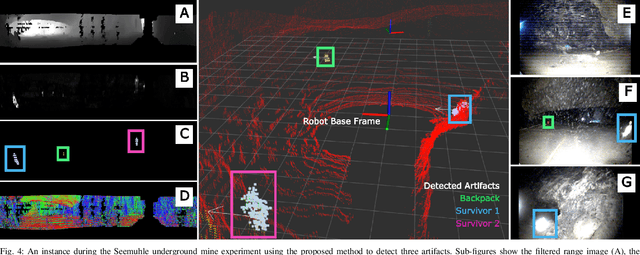
Detecting objects of interest, such as human survivors, safety equipment, and structure access points, is critical to any search-and-rescue operation. Robots deployed for such time-sensitive efforts rely on their onboard sensors to perform their designated tasks. However, as disaster response operations are predominantly conducted under perceptually degraded conditions, commonly utilized sensors such as visual cameras and LiDARs suffer in terms of performance degradation. In response, this work presents a method that utilizes the complementary nature of vision and depth sensors to leverage multi-modal information to aid object detection at longer distances. In particular, depth and intensity values from sparse LiDAR returns are used to generate proposals for objects present in the environment. These proposals are then utilized by a Pan-Tilt-Zoom (PTZ) camera system to perform a directed search by adjusting its pose and zoom level for performing object detection and classification in difficult environments. The proposed work has been thoroughly verified using an ANYmal quadruped robot in underground settings and on datasets collected during the DARPA Subterranean Challenge finals.
HyperEF: Spectral Hypergraph Coarsening by Effective-Resistance Clustering
Oct 26, 2022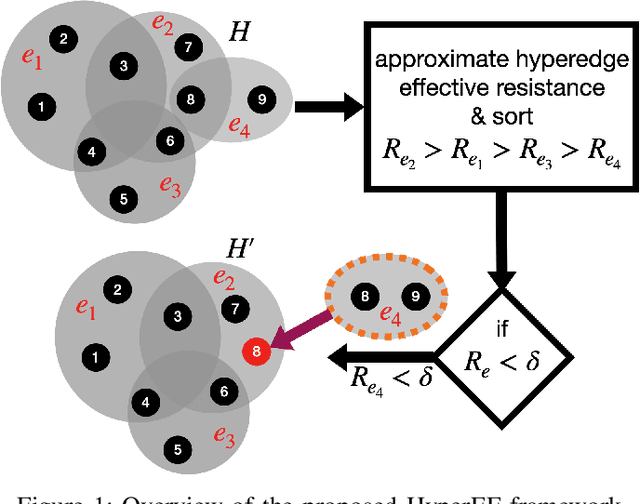
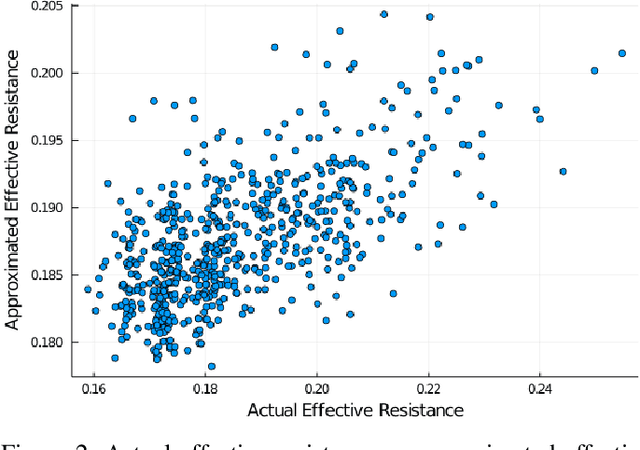
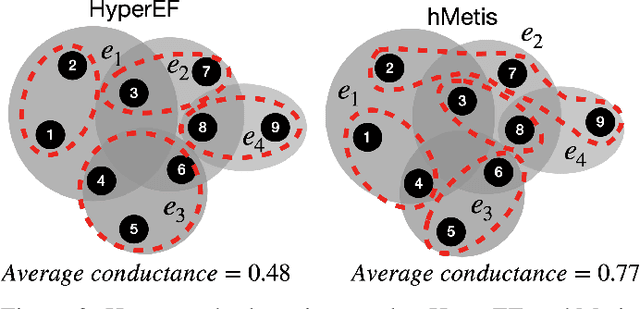
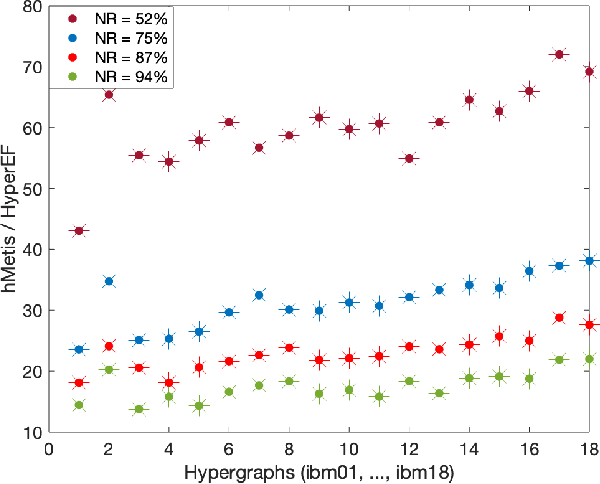
This paper introduces a scalable algorithmic framework (HyperEF) for spectral coarsening (decomposition) of large-scale hypergraphs by exploiting hyperedge effective resistances. Motivated by the latest theoretical framework for low-resistance-diameter decomposition of simple graphs, HyperEF aims at decomposing large hypergraphs into multiple node clusters with only a few inter-cluster hyperedges. The key component in HyperEF is a nearly-linear time algorithm for estimating hyperedge effective resistances, which allows incorporating the latest diffusion-based non-linear quadratic operators defined on hypergraphs. To achieve good runtime scalability, HyperEF searches within the Krylov subspace (or approximate eigensubspace) for identifying the nearly-optimal vectors for approximating the hyperedge effective resistances. In addition, a node weight propagation scheme for multilevel spectral hypergraph decomposition has been introduced for achieving even greater node coarsening ratios. When compared with state-of-the-art hypergraph partitioning (clustering) methods, extensive experiment results on real-world VLSI designs show that HyperEF can more effectively coarsen (decompose) hypergraphs without losing key structural (spectral) properties of the original hypergraphs, while achieving over $70\times$ runtime speedups over hMetis and $20\times$ speedups over HyperSF.
Text-to-speech synthesis from dark data with evaluation-in-the-loop data selection
Oct 26, 2022This paper proposes a method for selecting training data for text-to-speech (TTS) synthesis from dark data. TTS models are typically trained on high-quality speech corpora that cost much time and money for data collection, which makes it very challenging to increase speaker variation. In contrast, there is a large amount of data whose availability is unknown (a.k.a, "dark data"), such as YouTube videos. To utilize data other than TTS corpora, previous studies have selected speech data from the corpora on the basis of acoustic quality. However, considering that TTS models robust to data noise have been proposed, we should select data on the basis of its importance as training data to the given TTS model, not the quality of speech itself. Our method with a loop of training and evaluation selects training data on the basis of the automatically predicted quality of synthetic speech of a given TTS model. Results of evaluations using YouTube data reveal that our method outperforms the conventional acoustic-quality-based method.
Trade-off between reconstruction loss and feature alignment for domain generalization
Oct 26, 2022
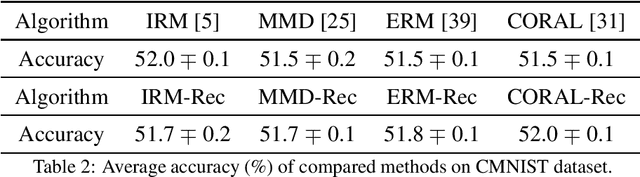
Domain generalization (DG) is a branch of transfer learning that aims to train the learning models on several seen domains and subsequently apply these pre-trained models to other unseen (unknown but related) domains. To deal with challenging settings in DG where both data and label of the unseen domain are not available at training time, the most common approach is to design the classifiers based on the domain-invariant representation features, i.e., the latent representations that are unchanged and transferable between domains. Contrary to popular belief, we show that designing classifiers based on invariant representation features alone is necessary but insufficient in DG. Our analysis indicates the necessity of imposing a constraint on the reconstruction loss induced by representation functions to preserve most of the relevant information about the label in the latent space. More importantly, we point out the trade-off between minimizing the reconstruction loss and achieving domain alignment in DG. Our theoretical results motivate a new DG framework that jointly optimizes the reconstruction loss and the domain discrepancy. Both theoretical and numerical results are provided to justify our approach.
* 13 pages, 2 tables
Extended Reality over 3GPP 5G-Advanced New Radio: Link Adaptation Enhancements
Oct 26, 2022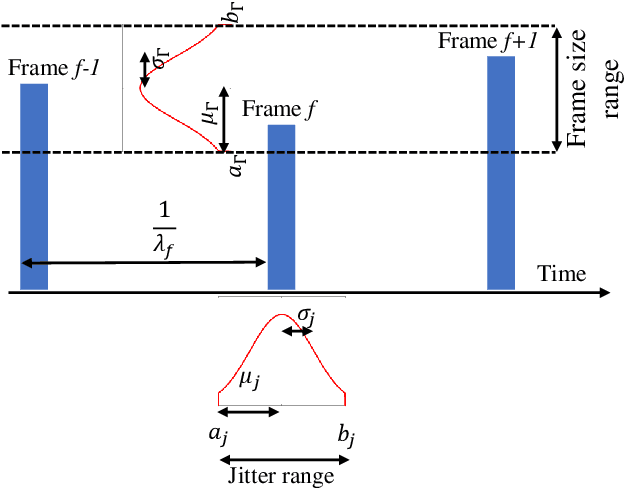
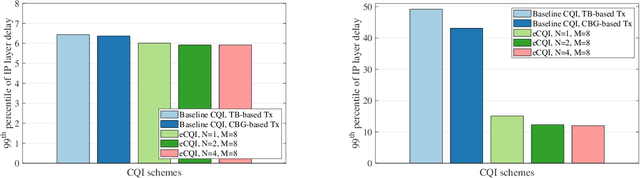
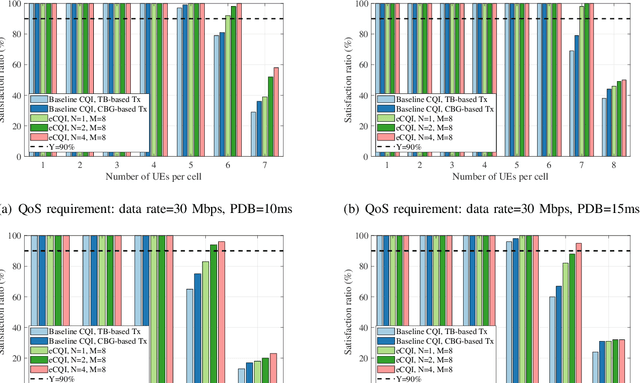
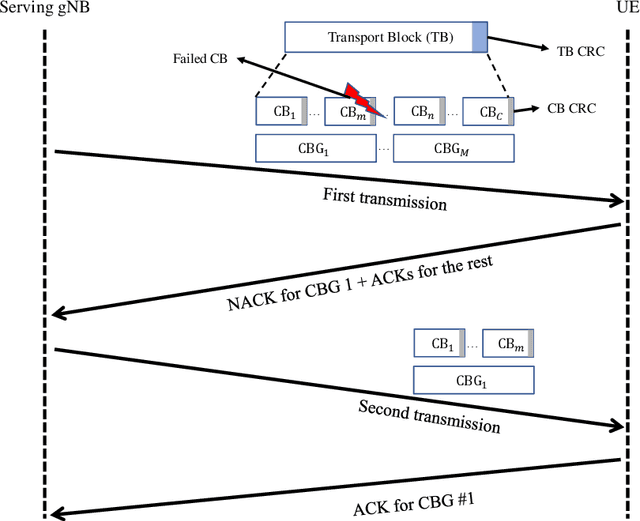
One of the rapidly emerging services for fifth-generation (5G)-Advanced is eXtended Reality (XR) which combines several immersive experiences and cloud gaming services. Those services are demanding as they call for relatively high data rates under tight latency constraints, sometimes also referred to as dependable real-time applications. Supporting as many XR users per cell requires highly efficient radio solutions. In this paper, we propose an enhanced channel quality indicator (CQI) that results in a better link adaptation to unleash the full performance potential of code block group (CBG) based transmissions for XR cases. We present both an analytical analysis of the related problems and solutions, as well as an extensive dynamic system-level performance assessment in line with the 3rd generation partnership project (3GPP)-defined advanced simulation methodologies. Our results show an increased XR system capacity of 17% to 33% as compared to what can be supported by current 5G systems with baseline CQI schemes. We also present enhanced CQI complexity-reducing techniques based on derived closed-form expressions that are attractive to the user equipment (UE) implementation.
DBGSL: Dynamic Brain Graph Structure Learning
Sep 27, 2022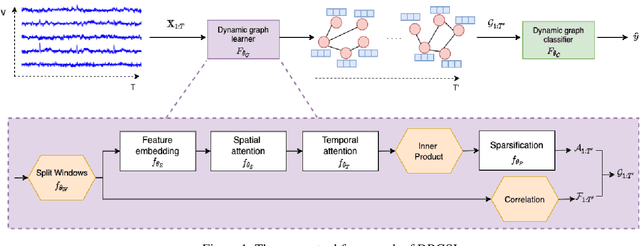
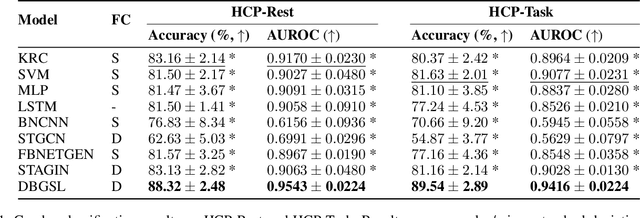
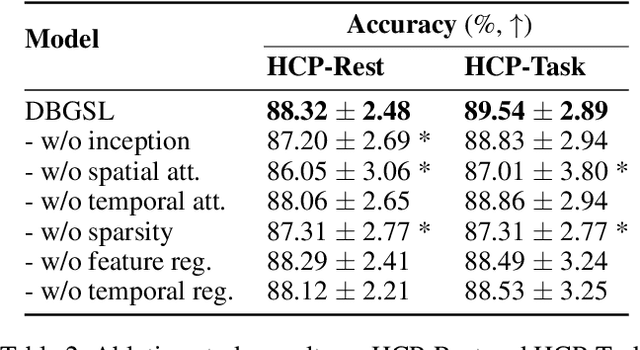

Functional connectivity (FC) between regions of the brain is commonly estimated through statistical dependency measures applied to functional magnetic resonance imaging (fMRI) data. The resulting functional connectivity matrix (FCM) is often taken to represent the adjacency matrix of a brain graph. Recently, graph neural networks (GNNs) have been successfully applied to FCMs to learn brain graph representations. A common limitation of existing GNN approaches, however, is that they require the graph adjacency matrix to be known prior to model training. As such, it is implicitly assumed the ground-truth dependency structure of the data is known. Unfortunately, for fMRI this is not the case as the choice of which statistical measure best represents the dependency structure of the data is non-trivial. Also, most GNN applications to fMRI assume FC is static over time, which is at odds with neuroscientific evidence that functional brain networks are time-varying and dynamic. These compounded issues can have a detrimental effect on the capacity of GNNs to learn representations of brain graphs. As a solution, we propose Dynamic Brain Graph Structure Learning (DBGSL), a supervised method for learning the optimal time-varying dependency structure of fMRI data. Specifically, DBGSL learns a dynamic graph from fMRI timeseries via spatial-temporal attention applied to brain region embeddings. The resulting graph is then fed to a spatial-temporal GNN to learn a graph representation for classification. Experiments on large resting-state as well as task fMRI datasets for the task of gender classification demonstrate that DBGSL achieves state-of-the-art performance. Moreover, analysis of the learnt dynamic graphs highlights prediction-related brain regions which align with findings from existing neuroscience literature.
Spatiotemporal Cardiac Statistical Shape Modeling: A Data-Driven Approach
Sep 06, 2022

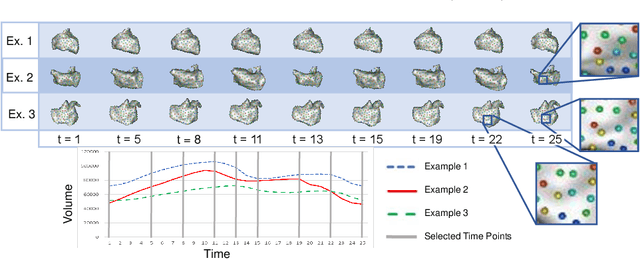
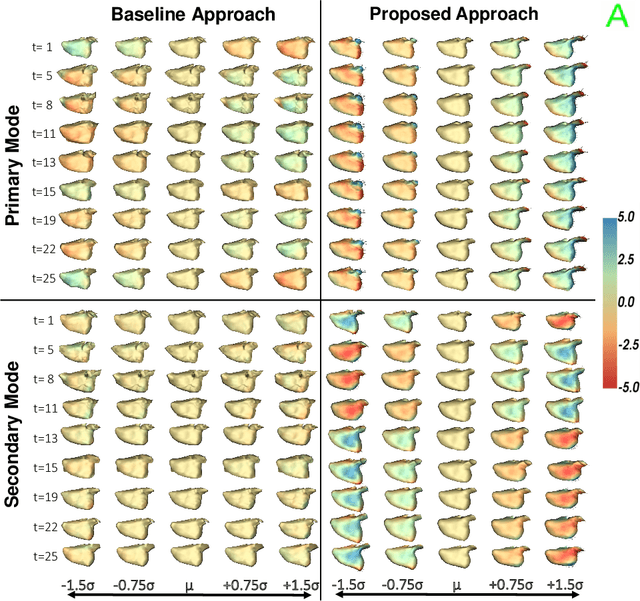
Clinical investigations of anatomy's structural changes over time could greatly benefit from population-level quantification of shape, or spatiotemporal statistic shape modeling (SSM). Such a tool enables characterizing patient organ cycles or disease progression in relation to a cohort of interest. Constructing shape models requires establishing a quantitative shape representation (e.g., corresponding landmarks). Particle-based shape modeling (PSM) is a data-driven SSM approach that captures population-level shape variations by optimizing landmark placement. However, it assumes cross-sectional study designs and hence has limited statistical power in representing shape changes over time. Existing methods for modeling spatiotemporal or longitudinal shape changes require predefined shape atlases and pre-built shape models that are typically constructed cross-sectionally. This paper proposes a data-driven approach inspired by the PSM method to learn population-level spatiotemporal shape changes directly from shape data. We introduce a novel SSM optimization scheme that produces landmarks that are in correspondence both across the population (inter-subject) and across time-series (intra-subject). We apply the proposed method to 4D cardiac data from atrial-fibrillation patients and demonstrate its efficacy in representing the dynamic change of the left atrium. Furthermore, we show that our method outperforms an image-based approach for spatiotemporal SSM with respect to a generative time-series model, the Linear Dynamical System (LDS). LDS fit using a spatiotemporal shape model optimized via our approach provides better generalization and specificity, indicating it accurately captures the underlying time-dependency.
Data-driven design of fault diagnosis for three-phase PWM rectifier using random forests technique with transient synthetic features
Nov 02, 2022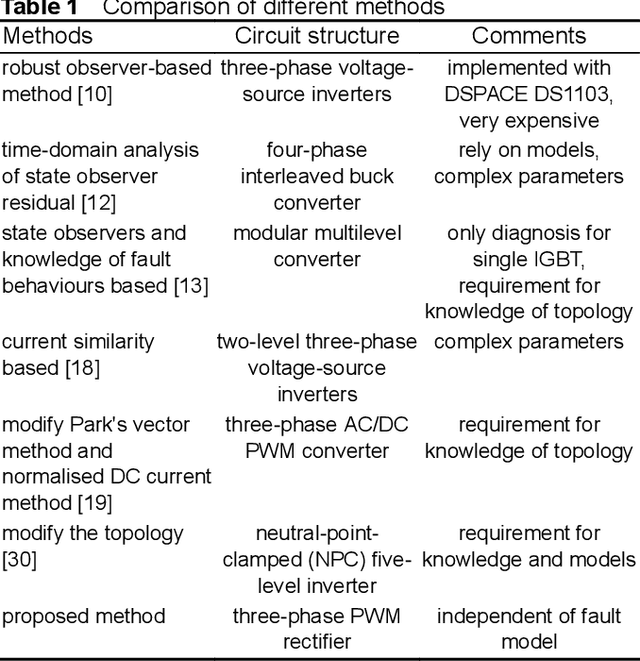
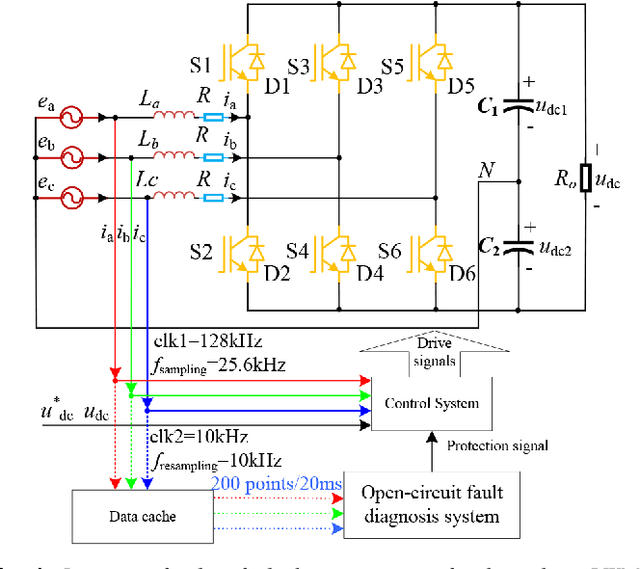
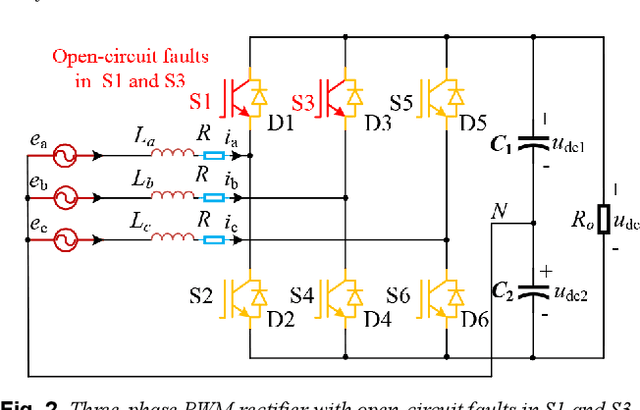
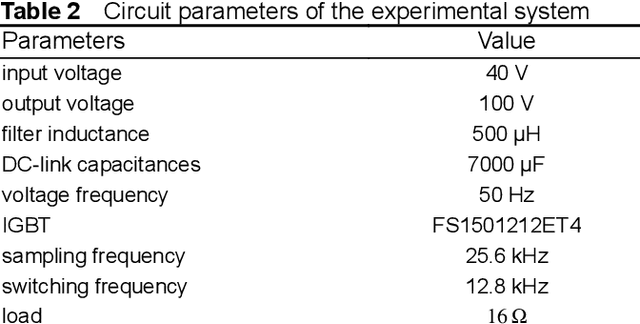
A three-phase pulse-width modulation (PWM) rectifier can usually maintain operation when open-circuit faults occur in insulated-gate bipolar transistors (IGBTs), which will lead the system to be unstable and unsafe. Aiming at this problem, based on random forests with transient synthetic features, a data-driven online fault diagnosis method is proposed to locate the open-circuit faults of IGBTs timely and effectively in this study. Firstly, by analysing the open-circuit fault features of IGBTs in the three-phase PWM rectifier, it is found that the occurrence of the fault features is related to the fault location and time, and the fault features do not always appear immediately with the occurrence of the fault. Secondly, different data-driven fault diagnosis methods are compared and evaluated, the performance of random forests algorithm is better than that of support vector machine or artificial neural networks. Meanwhile, the accuracy of fault diagnosis classifier trained by transient synthetic features is higher than that trained by original features. Also, the random forests fault diagnosis classifier trained by multiplicative features is the best with fault diagnosis accuracy can reach 98.32%. Finally, the online fault diagnosis experiments are carried out and the results demonstrate the effectiveness of the proposed method, which can accurately locate the open-circuit faults in IGBTs while ensuring system safety.
Ambiguity-Aware Multi-Object Pose Optimization for Visually-Assisted Robot Manipulation
Nov 02, 2022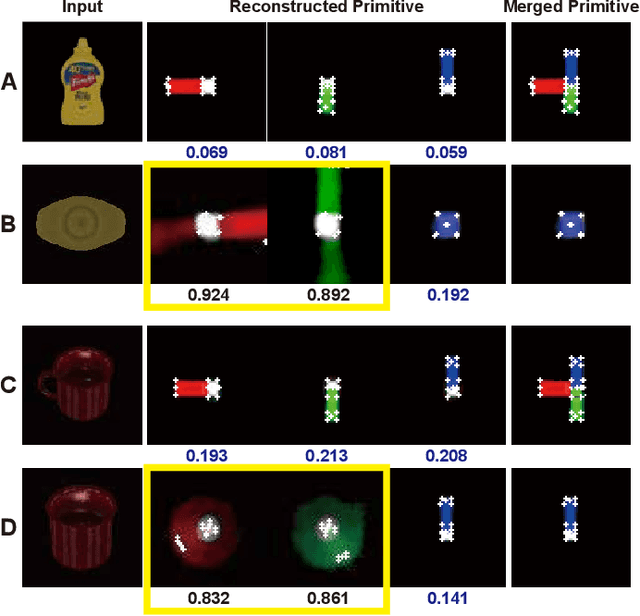
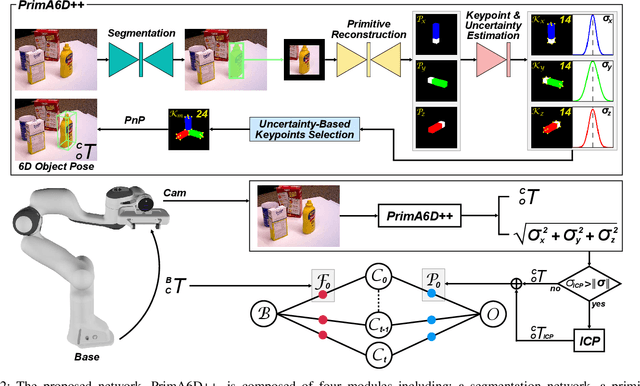
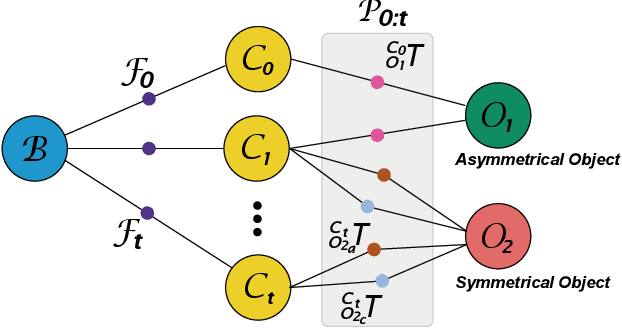
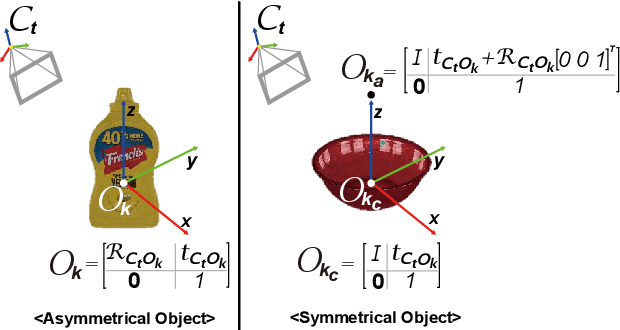
6D object pose estimation aims to infer the relative pose between the object and the camera using a single image or multiple images. Most works have focused on predicting the object pose without associated uncertainty under occlusion and structural ambiguity (symmetricity). However, these works demand prior information about shape attributes, and this condition is hardly satisfied in reality; even asymmetric objects may be symmetric under the viewpoint change. In addition, acquiring and fusing diverse sensor data is challenging when extending them to robotics applications. Tackling these limitations, we present an ambiguity-aware 6D object pose estimation network, PrimA6D++, as a generic uncertainty prediction method. The major challenges in pose estimation, such as occlusion and symmetry, can be handled in a generic manner based on the measured ambiguity of the prediction. Specifically, we devise a network to reconstruct the three rotation axis primitive images of a target object and predict the underlying uncertainty along each primitive axis. Leveraging the estimated uncertainty, we then optimize multi-object poses using visual measurements and camera poses by treating it as an object SLAM problem. The proposed method shows a significant performance improvement in T-LESS and YCB-Video datasets. We further demonstrate real-time scene recognition capability for visually-assisted robot manipulation. Our code and supplementary materials are available at https://github.com/rpmsnu/PrimA6D.
OPA-3D: Occlusion-Aware Pixel-Wise Aggregation for Monocular 3D Object Detection
Nov 02, 2022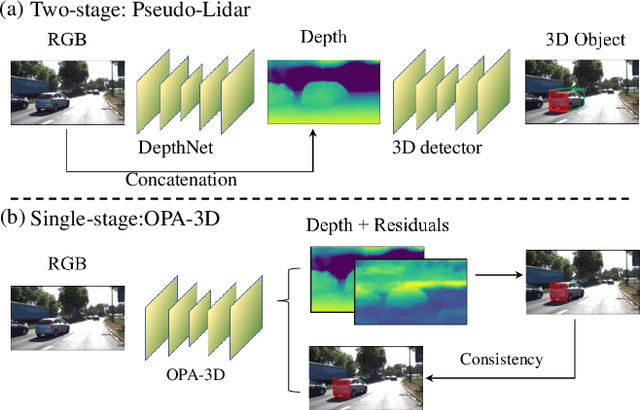
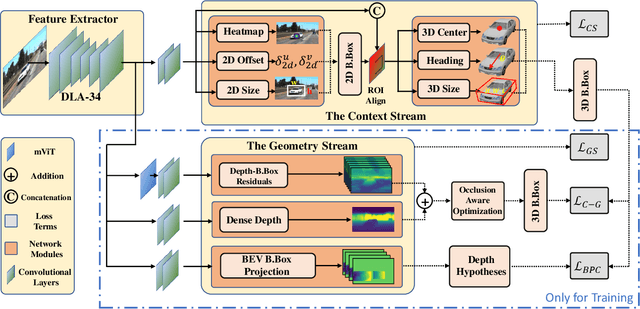
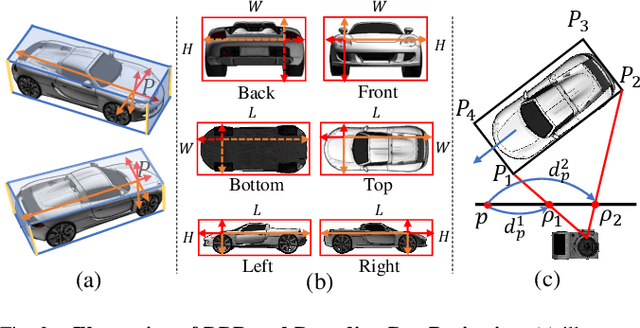

Despite monocular 3D object detection having recently made a significant leap forward thanks to the use of pre-trained depth estimators for pseudo-LiDAR recovery, such two-stage methods typically suffer from overfitting and are incapable of explicitly encapsulating the geometric relation between depth and object bounding box. To overcome this limitation, we instead propose OPA-3D, a single-stage, end-to-end, Occlusion-Aware Pixel-Wise Aggregation network that to jointly estimate dense scene depth with depth-bounding box residuals and object bounding boxes, allowing a two-stream detection of 3D objects, leading to significantly more robust detections. Thereby, the geometry stream denoted as the Geometry Stream, combines visible depth and depth-bounding box residuals to recover the object bounding box via explicit occlusion-aware optimization. In addition, a bounding box based geometry projection scheme is employed in an effort to enhance distance perception. The second stream, named as the Context Stream, directly regresses 3D object location and size. This novel two-stream representation further enables us to enforce cross-stream consistency terms which aligns the outputs of both streams, improving the overall performance. Extensive experiments on the public benchmark demonstrate that OPA-3D outperforms state-of-the-art methods on the main Car category, whilst keeping a real-time inference speed. We plan to release all codes and trained models soon.