 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
tsflex: flexible time series processing & feature extraction
Nov 24, 2021
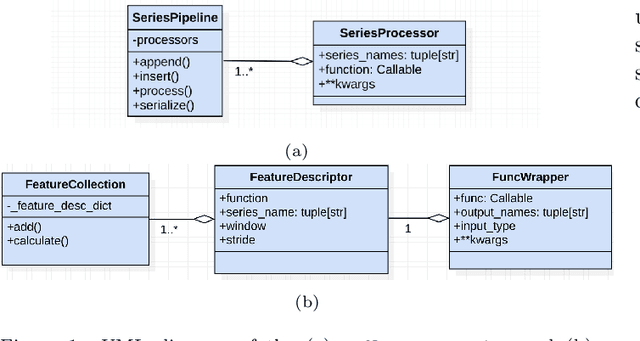

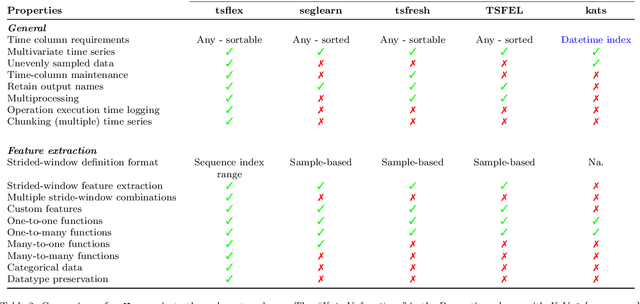
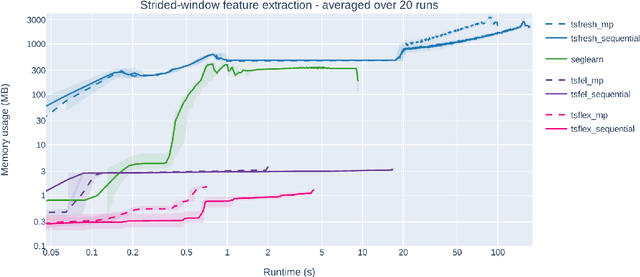
Time series processing and feature extraction are crucial and time-intensive steps in conventional machine learning pipelines. Existing packages are limited in their real-world applicability, as they cannot cope with irregularly-sampled and asynchronous data. We therefore present $\texttt{tsflex}$, a domain-independent, flexible, and sequence first Python toolkit for processing & feature extraction, that is capable of handling irregularly-sampled sequences with unaligned measurements. This toolkit is sequence first as (1) sequence based arguments are leveraged for strided-window feature extraction, and (2) the sequence-index is maintained through all supported operations. $\texttt{tsflex}$ is flexible as it natively supports (1) multivariate time series, (2) multiple window-stride configurations, and (3) integrates with processing and feature functions from other packages, while (4) making no assumptions about the data sampling rate regularity and synchronization. Other functionalities from this package are multiprocessing, in-depth execution time logging, support for categorical & time based data, chunking sequences, and embedded serialization. $\texttt{tsflex}$ is developed to enable fast and memory-efficient time series processing & feature extraction. Results indicate that $\texttt{tsflex}$ is more flexible than similar packages while outperforming these toolkits in both runtime and memory usage.
Effective Early Stopping of Point Cloud Neural Networks
Sep 30, 2022Early stopping techniques can be utilized to decrease the time cost, however currently the ultimate goal of early stopping techniques is closely related to the accuracy upgrade or the ability of the neural network to generalize better on unseen data without being large or complex in structure and not directly with its efficiency. Time efficiency is a critical factor in neural networks, especially when dealing with the segmentation of 3D point cloud data, not only because a neural network itself is computationally expensive, but also because point clouds are large and noisy data, making learning processes even more costly. In this paper, we propose a new early stopping technique based on fundamental mathematics aiming to upgrade the trade-off between the learning efficiency and accuracy of neural networks dealing with 3D point clouds. Our results show that by employing our early stopping technique in four distinct and highly utilized neural networks in segmenting 3D point clouds, the training time efficiency of the models is greatly improved, with efficiency gain values reaching up to 94\%, while the models achieving in just a few epochs approximately similar segmentation accuracy metric values like the ones that are obtained in the training of the neural networks in 200 epochs. Also, our proposal outperforms four conventional early stopping approaches in segmentation accuracy, implying a promising innovative early stopping technique in point cloud segmentation.
Exploit Customer Life-time Value with Memoryless Experiments
Jan 17, 2022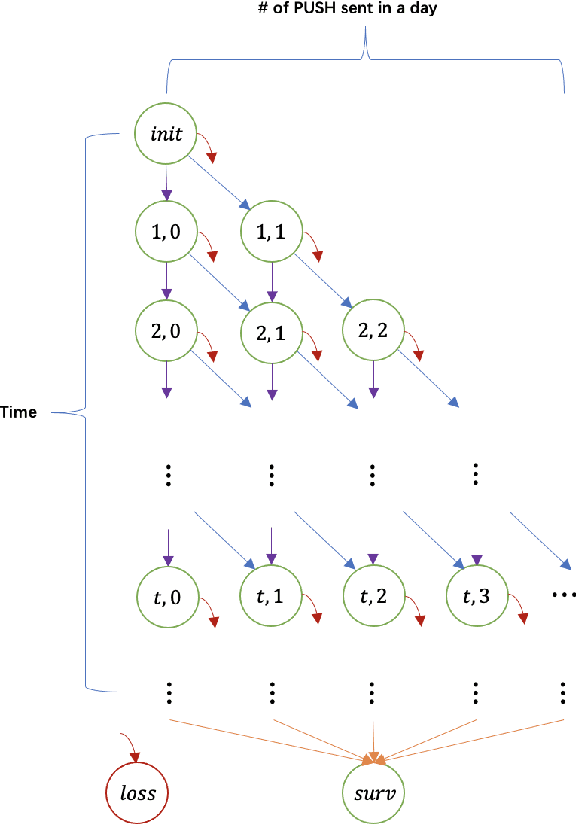
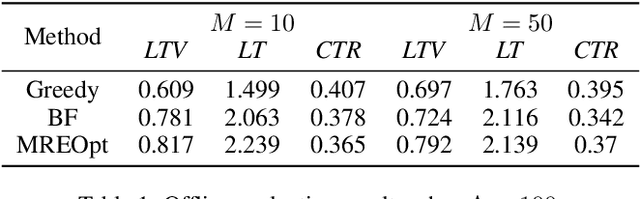
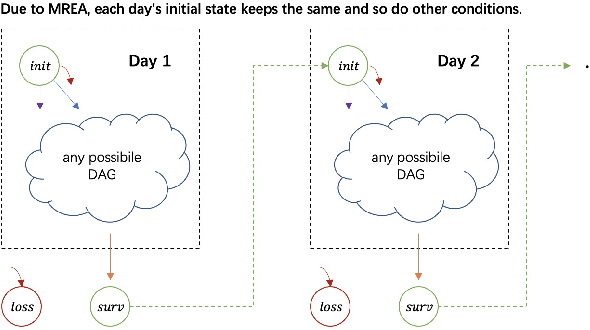
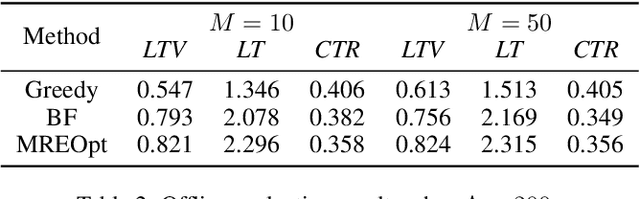
As a measure of the long-term contribution produced by customers in a service or product relationship, life-time value, or LTV, can more comprehensively find the optimal strategy for service delivery. However, it is challenging to accurately abstract the LTV scene, model it reasonably, and find the optimal solution. The current theories either cannot precisely express LTV because of the single modeling structure, or there is no efficient solution. We propose a general LTV modeling method, which solves the problem that customers' long-term contribution is difficult to quantify while existing methods, such as modeling the click-through rate, only pursue the short-term contribution. At the same time, we also propose a fast dynamic programming solution based on a mutated bisection method and the memoryless repeated experiments assumption. The model and method can be applied to different service scenarios, such as the recommendation system. Experiments on real-world datasets confirm the effectiveness of the proposed model and optimization method. In addition, this whole LTV structure was deployed at a large E-commerce mobile phone application, where it managed to select optimal push message sending time and achieved a 10\% LTV improvement.
Variant Parallelism: Lightweight Deep Convolutional Models for Distributed Inference on IoT Devices
Oct 15, 2022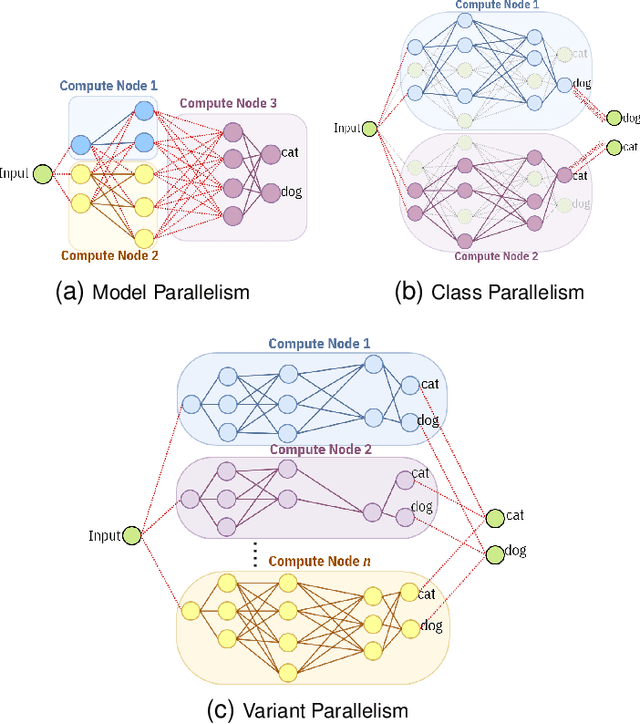
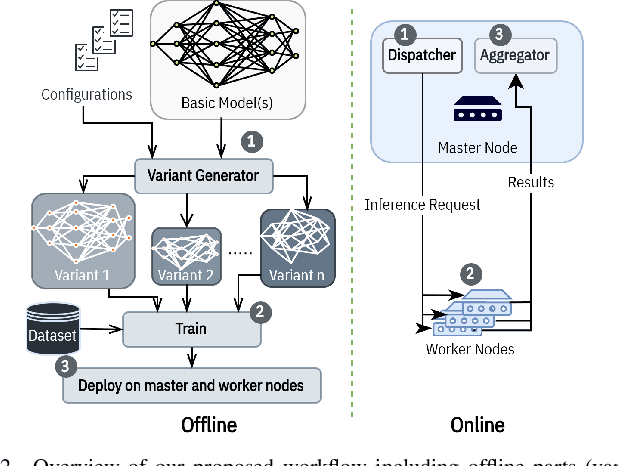
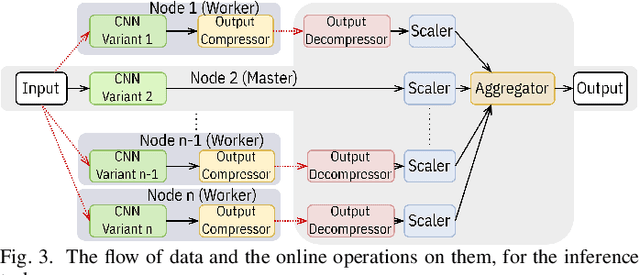

Two major techniques are commonly used to meet real-time inference limitations when distributing models across resource-constrained IoT devices: (1) model parallelism (MP) and (2) class parallelism (CP). In MP, transmitting bulky intermediate data (orders of magnitude larger than input) between devices imposes huge communication overhead. Although CP solves this problem, it has limitations on the number of sub-models. In addition, both solutions are fault intolerant, an issue when deployed on edge devices. We propose variant parallelism (VP), an ensemble-based deep learning distribution method where different variants of a main model are generated and can be deployed on separate machines. We design a family of lighter models around the original model, and train them simultaneously to improve accuracy over single models. Our experimental results on six common mid-sized object recognition datasets demonstrate that our models can have 5.8-7.1x fewer parameters, 4.3-31x fewer multiply-accumulations (MACs), and 2.5-13.2x less response time on atomic inputs compared to MobileNetV2 while achieving comparable or higher accuracy. Our technique easily generates several variants of the base architecture. Each variant returns only 2k outputs 1 <= k <= (#classes/2), representing Top-k classes, instead of tons of floating point values required in MP. Since each variant provides a full-class prediction, our approach maintains higher availability compared with MP and CP in presence of failure.
A Novel Block-Wise Index Modulation Scheme for High-Mobility OTFS Communications
Oct 25, 2022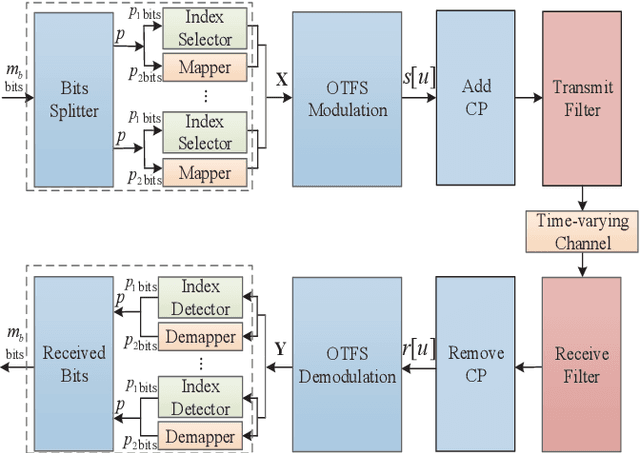
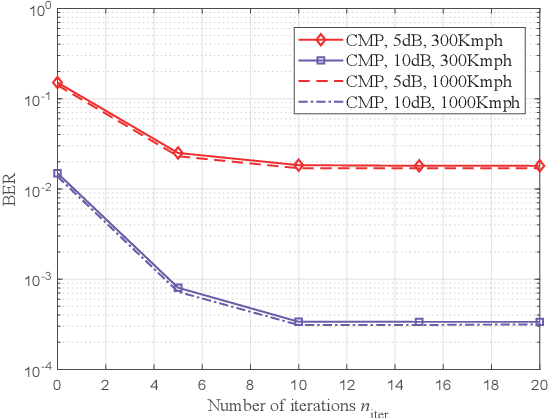
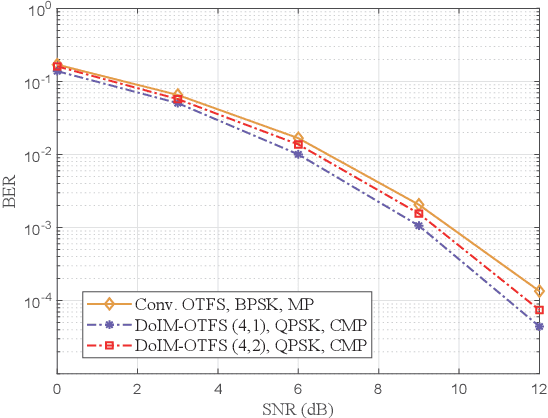
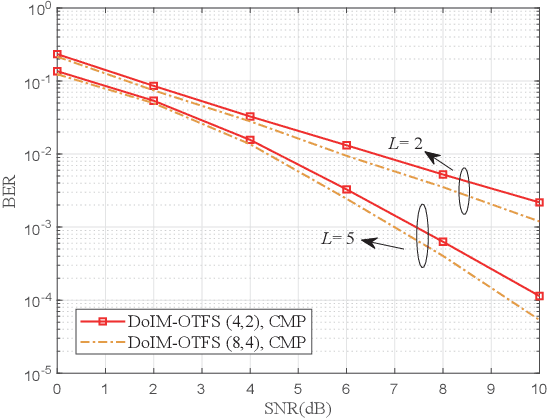
As a promising technique for high-mobility wireless communications, orthogonal time frequency space (OTFS) has been proved to enjoy excellent advantages with respect to traditional orthogonal frequency division multiplexing (OFDM). However, a challenging problem is to design efficient systems to further improve the performance. In this paper, we propose a novel block-wise index modulation (IM) scheme for OTFS systems, named Doppler-IM with OTFS (DoIM-OTFS), where a block of Doppler resource bins are activated simultaneously. For practical implementation, we develop a low complexity customized message passing (CMP) algorithm for our proposed DoIM-OTFS scheme. Simulation results demonstrate our proposed DoIM-OTFS system outperforms traditional OTFS system without IM. The proposed CMP algorithm can achieve desired performance and robustness to the imperfect channel state information (CSI).
Large Scale Real-World Multi-Person Tracking
Nov 03, 2022
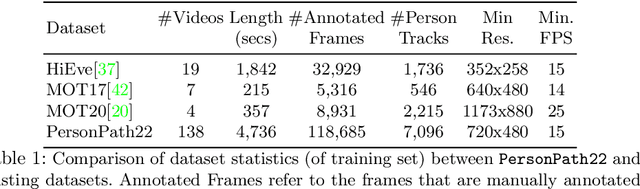
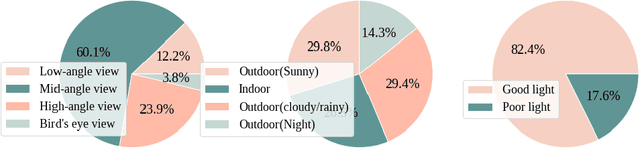
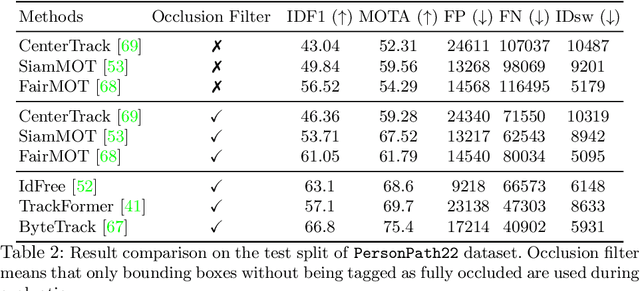
This paper presents a new large scale multi-person tracking dataset -- \texttt{PersonPath22}, which is over an order of magnitude larger than currently available high quality multi-object tracking datasets such as MOT17, HiEve, and MOT20 datasets. The lack of large scale training and test data for this task has limited the community's ability to understand the performance of their tracking systems on a wide range of scenarios and conditions such as variations in person density, actions being performed, weather, and time of day. \texttt{PersonPath22} dataset was specifically sourced to provide a wide variety of these conditions and our annotations include rich meta-data such that the performance of a tracker can be evaluated along these different dimensions. The lack of training data has also limited the ability to perform end-to-end training of tracking systems. As such, the highest performing tracking systems all rely on strong detectors trained on external image datasets. We hope that the release of this dataset will enable new lines of research that take advantage of large scale video based training data.
Speech-based emotion recognition with self-supervised models using attentive channel-wise correlations and label smoothing
Nov 03, 2022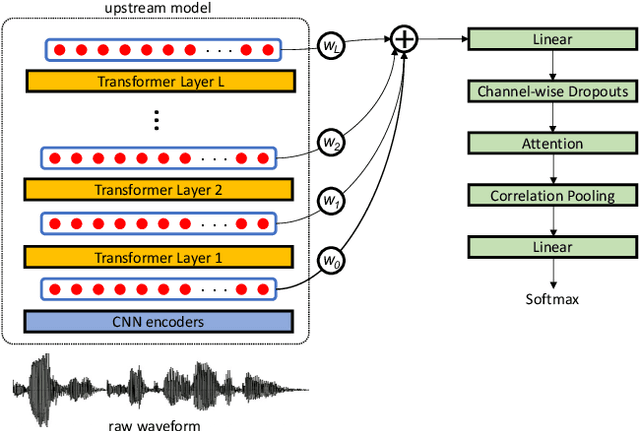
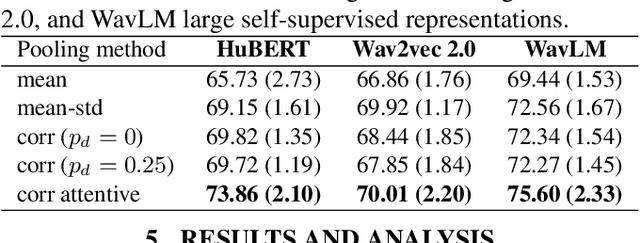
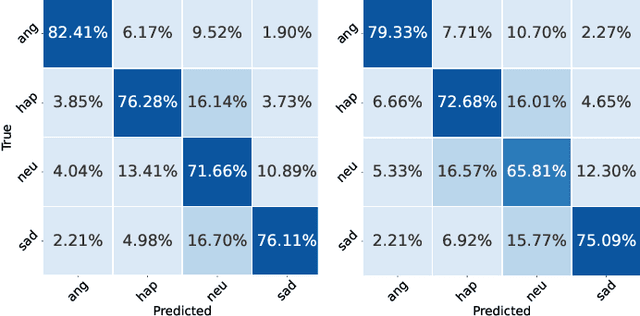
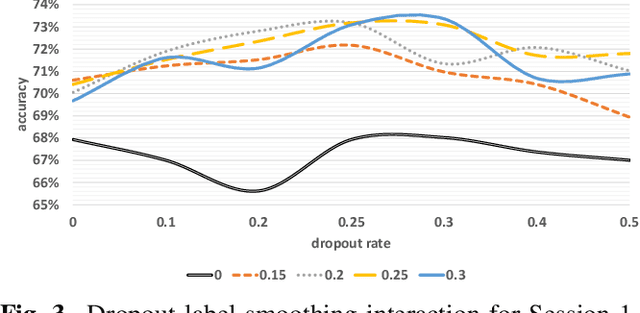
When recognizing emotions from speech, we encounter two common problems: how to optimally capture emotion-relevant information from the speech signal and how to best quantify or categorize the noisy subjective emotion labels. Self-supervised pre-trained representations can robustly capture information from speech enabling state-of-the-art results in many downstream tasks including emotion recognition. However, better ways of aggregating the information across time need to be considered as the relevant emotion information is likely to appear piecewise and not uniformly across the signal. For the labels, we need to take into account that there is a substantial degree of noise that comes from the subjective human annotations. In this paper, we propose a novel approach to attentive pooling based on correlations between the representations' coefficients combined with label smoothing, a method aiming to reduce the confidence of the classifier on the training labels. We evaluate our proposed approach on the benchmark dataset IEMOCAP, and demonstrate high performance surpassing that in the literature. The code to reproduce the results is available at github.com/skakouros/s3prl_attentive_correlation.
Toward Unsupervised Outlier Model Selection
Nov 03, 2022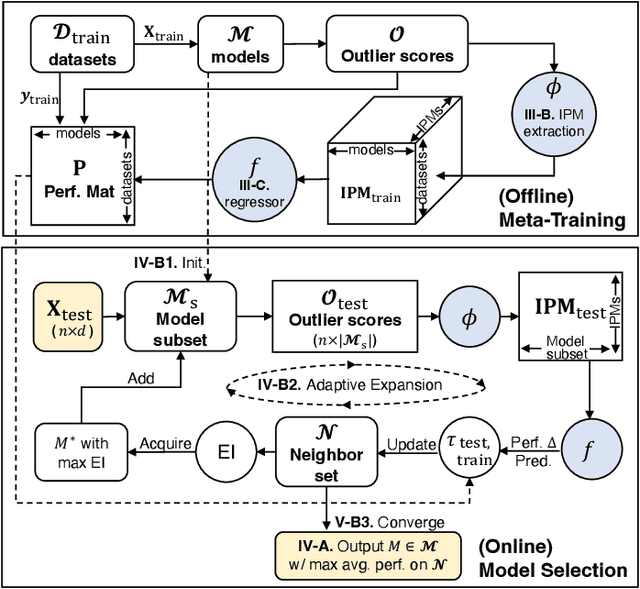
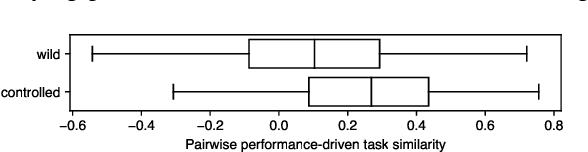
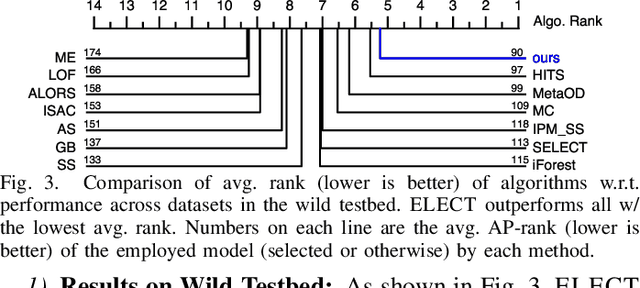
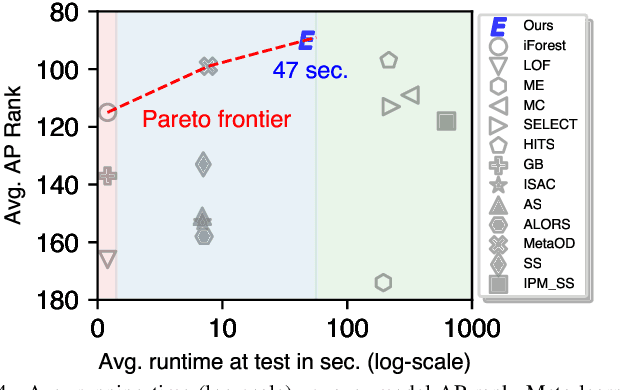
Today there exists no shortage of outlier detection algorithms in the literature, yet the complementary and critical problem of unsupervised outlier model selection (UOMS) is vastly understudied. In this work we propose ELECT, a new approach to select an effective candidate model, i.e. an outlier detection algorithm and its hyperparameter(s), to employ on a new dataset without any labels. At its core, ELECT is based on meta-learning; transferring prior knowledge (e.g. model performance) on historical datasets that are similar to the new one to facilitate UOMS. Uniquely, it employs a dataset similarity measure that is performance-based, which is more direct and goal-driven than other measures used in the past. ELECT adaptively searches for similar historical datasets, as such, it can serve an output on-demand, being able to accommodate varying time budgets. Extensive experiments show that ELECT significantly outperforms a wide range of basic UOMS baselines, including no model selection (always using the same popular model such as iForest) as well as more recent selection strategies based on meta-features.
Along Similar Lines: Local Obstacle Avoidance for Long-term Autonomous Path Following
Nov 03, 2022
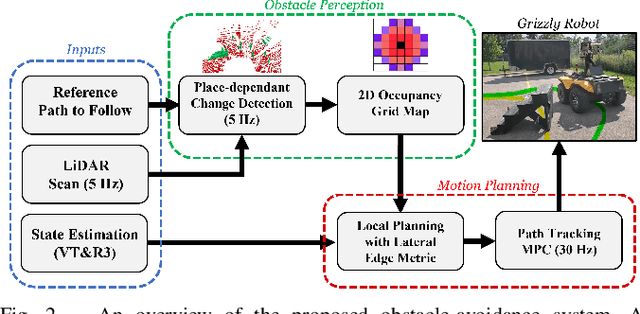
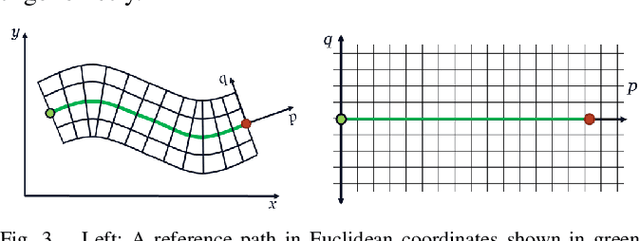
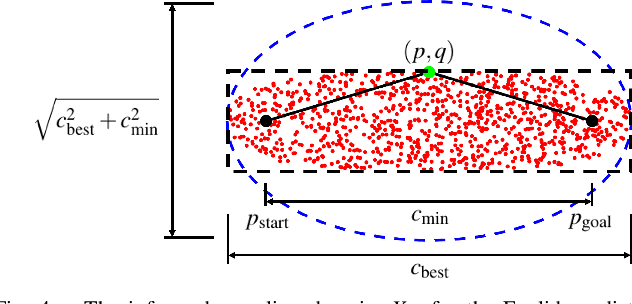
Visual Teach and Repeat 3 (VT&R3), a generalization of stereo VT&R, achieves long-term autonomous path-following using topometric mapping and localization from a single rich sensor stream. In this paper, we improve the capabilities of a LiDAR implementation of VT&R3 to reliably detect and avoid obstacles in changing environments. Our architecture simplifies the obstacle-perception problem to that of place-dependent change detection. We then extend the behaviour of generic sample-based motion planners to better suit the teach-and-repeat problem structure by introducing a new edge-cost metric paired with a curvilinear planning space. The resulting planner generates naturally smooth paths that avoid local obstacles while minimizing lateral path deviation to best exploit prior terrain knowledge. While we use the method with VT&R, it can be generalized to suit arbitrary path-following applications. Experimental results from online run-time analysis, unit testing, and qualitative experiments on a differential drive robot show the promise of the technique for reliable long-term autonomous operation in complex unstructured environments.
Leveraging Domain Features for Detecting Adversarial Attacks Against Deep Speech Recognition in Noise
Nov 03, 2022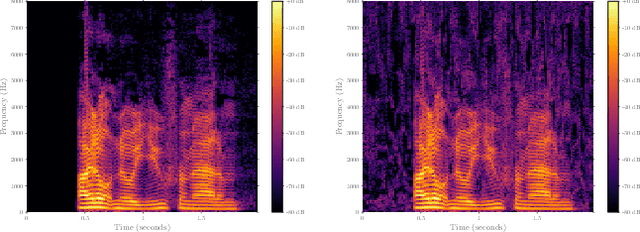
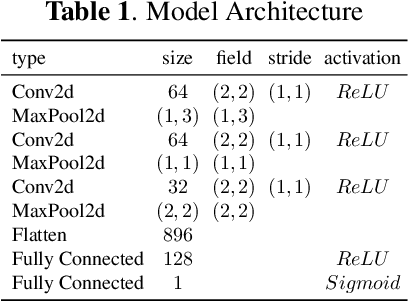
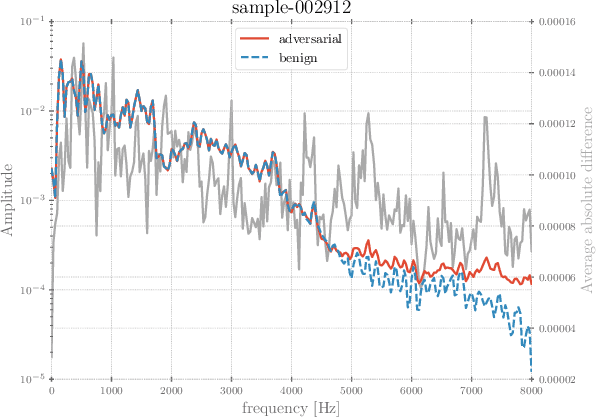
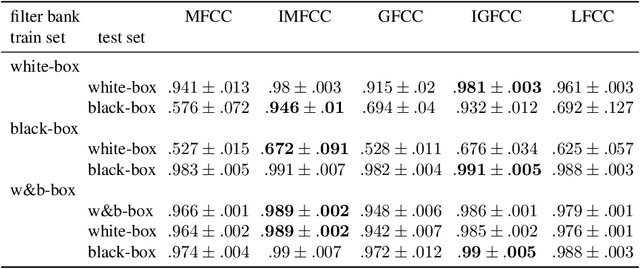
In recent years, significant progress has been made in deep model-based automatic speech recognition (ASR), leading to its widespread deployment in the real world. At the same time, adversarial attacks against deep ASR systems are highly successful. Various methods have been proposed to defend ASR systems from these attacks. However, existing classification based methods focus on the design of deep learning models while lacking exploration of domain specific features. This work leverages filter bank-based features to better capture the characteristics of attacks for improved detection. Furthermore, the paper analyses the potentials of using speech and non-speech parts separately in detecting adversarial attacks. In the end, considering adverse environments where ASR systems may be deployed, we study the impact of acoustic noise of various types and signal-to-noise ratios. Extensive experiments show that the inverse filter bank features generally perform better in both clean and noisy environments, the detection is effective using either speech or non-speech part, and the acoustic noise can largely degrade the detection performance.