 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Design and Evaluation of a Generic Visual SLAM Framework for Multi-Camera Systems
Oct 13, 2022
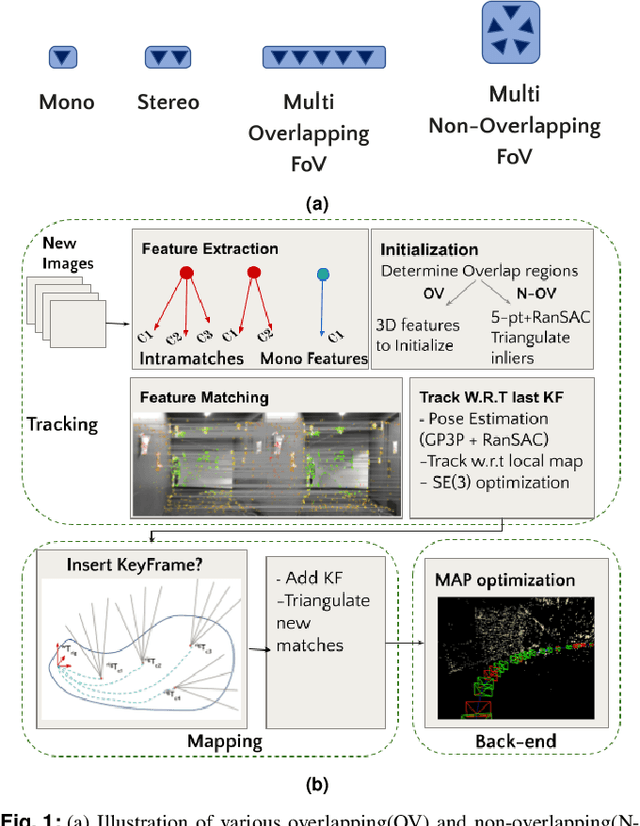

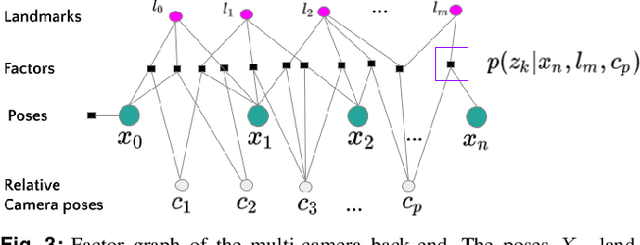

Multi-camera systems have been shown to improve the accuracy and robustness of SLAM estimates, yet state-of-the-art SLAM systems predominantly support monocular or stereo setups. This paper presents a generic sparse visual SLAM framework capable of running on any number of cameras and in any arrangement. Our SLAM system uses the generalized camera model, which allows us to represent an arbitrary multi-camera system as a single imaging device. Additionally, it takes advantage of the overlapping fields of view (FoV) by extracting cross-matched features across cameras in the rig. This limits the linear rise in the number of features with the number of cameras and keeps the computational load in check while enabling an accurate representation of the scene. We evaluate our method in terms of accuracy, robustness, and run time on indoor and outdoor datasets that include challenging real-world scenarios such as narrow corridors, featureless spaces, and dynamic objects. We show that our system can adapt to different camera configurations and allows real-time execution for typical robotic applications. Finally, we benchmark the impact of the critical design parameters - the number of cameras and the overlap between their FoV that define the camera configuration for SLAM. All our software and datasets are freely available for further research.
Combining Embeddings and Fuzzy Time Series for High-Dimensional Time Series Forecasting in Internet of Energy Applications
Dec 03, 2021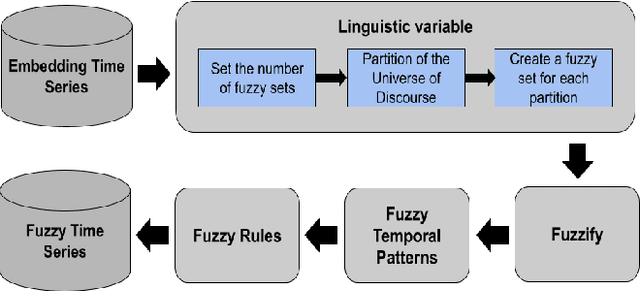



The prediction of residential power usage is essential in assisting a smart grid to manage and preserve energy to ensure efficient use. An accurate energy forecasting at the customer level will reflect directly into efficiency improvements across the power grid system, however forecasting building energy use is a complex task due to many influencing factors, such as meteorological and occupancy patterns. In addiction, high-dimensional time series increasingly arise in the Internet of Energy (IoE), given the emergence of multi-sensor environments and the two way communication between energy consumers and the smart grid. Therefore, methods that are capable of computing high-dimensional time series are of great value in smart building and IoE applications. Fuzzy Time Series (FTS) models stand out as data-driven non-parametric models of easy implementation and high accuracy. Unfortunately, the existing FTS models can be unfeasible if all features were used to train the model. We present a new methodology for handling high-dimensional time series, by projecting the original high-dimensional data into a low dimensional embedding space and using multivariate FTS approach in this low dimensional representation. Combining these techniques enables a better representation of the complex content of multivariate time series and more accurate forecasts.
DiffusER: Discrete Diffusion via Edit-based Reconstruction
Oct 30, 2022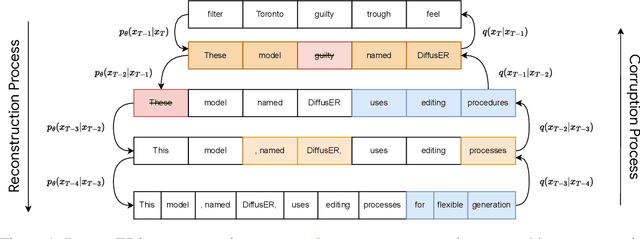

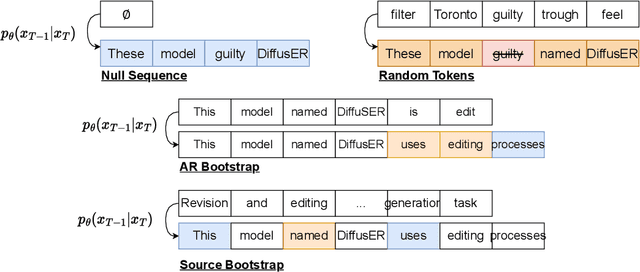
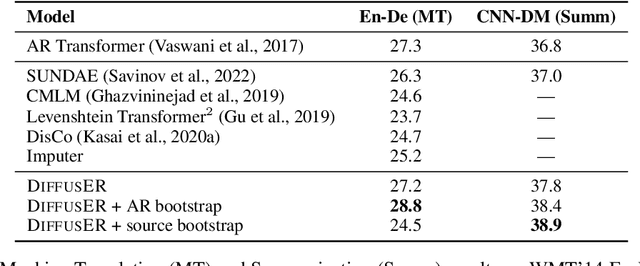
In text generation, models that generate text from scratch one token at a time are currently the dominant paradigm. Despite being performant, these models lack the ability to revise existing text, which limits their usability in many practical scenarios. We look to address this, with DiffusER (Diffusion via Edit-based Reconstruction), a new edit-based generative model for text based on denoising diffusion models -- a class of models that use a Markov chain of denoising steps to incrementally generate data. DiffusER is not only a strong generative model in general, rivalling autoregressive models on several tasks spanning machine translation, summarization, and style transfer; it can also perform other varieties of generation that standard autoregressive models are not well-suited for. For instance, we demonstrate that DiffusER makes it possible for a user to condition generation on a prototype, or an incomplete sequence, and continue revising based on previous edit steps.
tsflex: flexible time series processing & feature extraction
Nov 24, 2021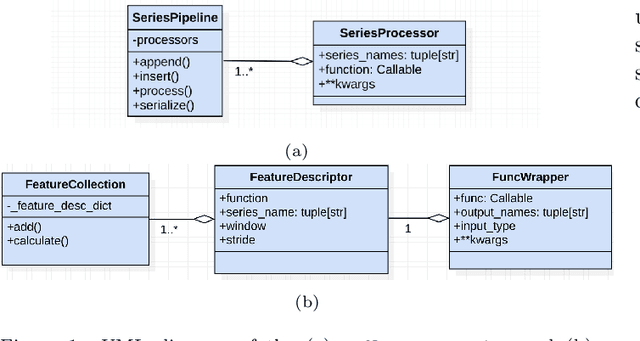

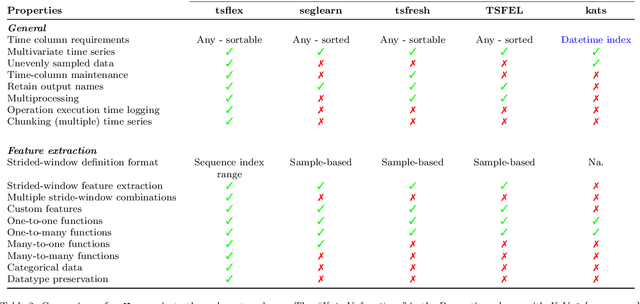
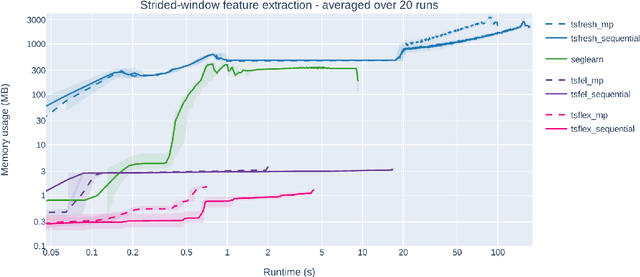
Time series processing and feature extraction are crucial and time-intensive steps in conventional machine learning pipelines. Existing packages are limited in their real-world applicability, as they cannot cope with irregularly-sampled and asynchronous data. We therefore present $\texttt{tsflex}$, a domain-independent, flexible, and sequence first Python toolkit for processing & feature extraction, that is capable of handling irregularly-sampled sequences with unaligned measurements. This toolkit is sequence first as (1) sequence based arguments are leveraged for strided-window feature extraction, and (2) the sequence-index is maintained through all supported operations. $\texttt{tsflex}$ is flexible as it natively supports (1) multivariate time series, (2) multiple window-stride configurations, and (3) integrates with processing and feature functions from other packages, while (4) making no assumptions about the data sampling rate regularity and synchronization. Other functionalities from this package are multiprocessing, in-depth execution time logging, support for categorical & time based data, chunking sequences, and embedded serialization. $\texttt{tsflex}$ is developed to enable fast and memory-efficient time series processing & feature extraction. Results indicate that $\texttt{tsflex}$ is more flexible than similar packages while outperforming these toolkits in both runtime and memory usage.
Model Generalization in Arrival Runway Occupancy Time Prediction by Feature Equivalences
Jan 25, 2022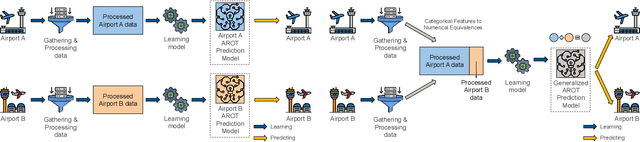
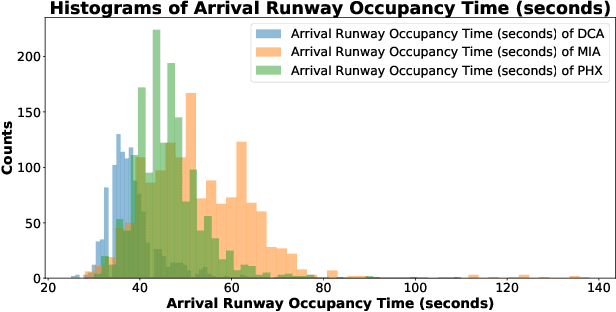
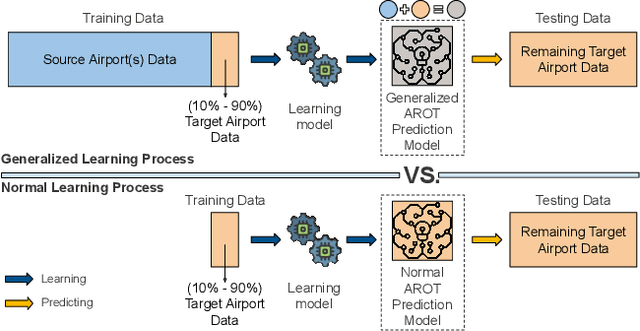
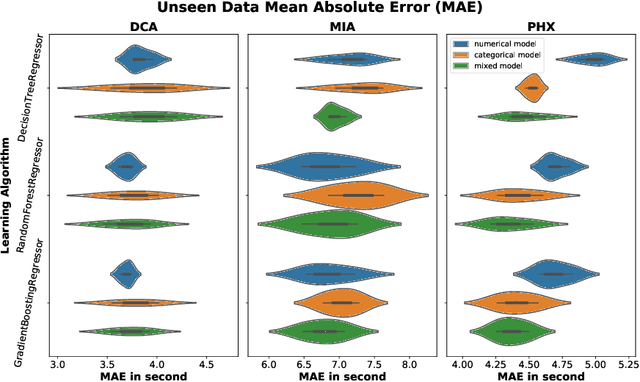
General real-time runway occupancy time prediction modelling for multiple airports is a current research gap. An attempt to generalize a real-time prediction model for Arrival Runway Occupancy Time (AROT) is presented in this paper by substituting categorical features by their numerical equivalences. Three days of data, collected from Saab Sensis' Aerobahn system at three US airports, has been used for this work. Three tree-based machine learning algorithms: Decision Tree, Random Forest and Gradient Boosting are used to assess the generalizability of the model using numerical equivalent features. We have shown that the model trained on numerical equivalent features not only have performances at least on par with models trained on categorical features but also can make predictions on unseen data from other airports.
Deep Appearance Prefiltering
Nov 08, 2022


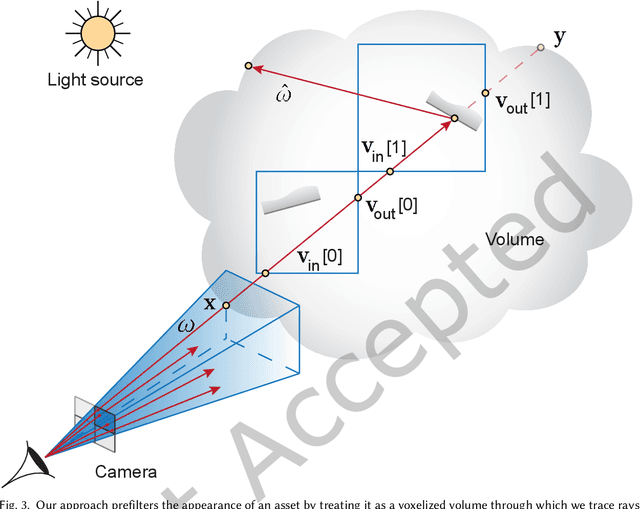
Physically based rendering of complex scenes can be prohibitively costly with a potentially unbounded and uneven distribution of complexity across the rendered image. The goal of an ideal level of detail (LoD) method is to make rendering costs independent of the 3D scene complexity, while preserving the appearance of the scene. However, current prefiltering LoD methods are limited in the appearances they can support due to their reliance of approximate models and other heuristics. We propose the first comprehensive multi-scale LoD framework for prefiltering 3D environments with complex geometry and materials (e.g., the Disney BRDF), while maintaining the appearance with respect to the ray-traced reference. Using a multi-scale hierarchy of the scene, we perform a data-driven prefiltering step to obtain an appearance phase function and directional coverage mask at each scale. At the heart of our approach is a novel neural representation that encodes this information into a compact latent form that is easy to decode inside a physically based renderer. Once a scene is baked out, our method requires no original geometry, materials, or textures at render time. We demonstrate that our approach compares favorably to state-of-the-art prefiltering methods and achieves considerable savings in memory for complex scenes.
Multiple Signal Classification Based Joint Communication and Sensing System
Nov 08, 2022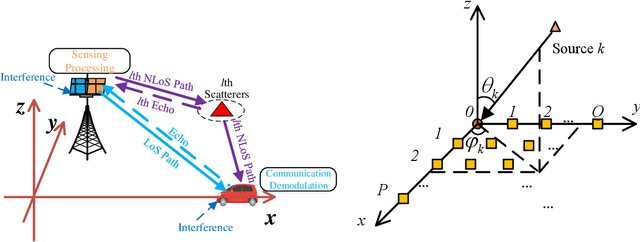
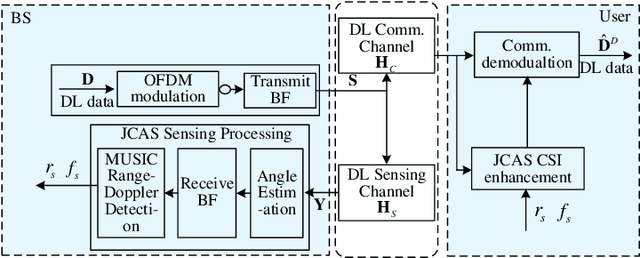
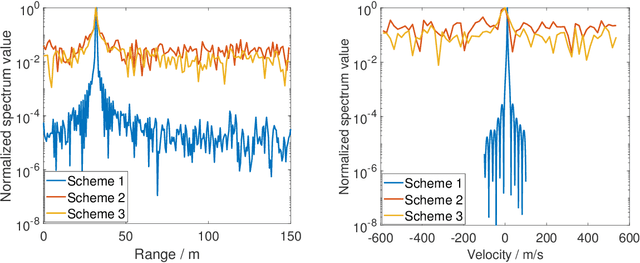
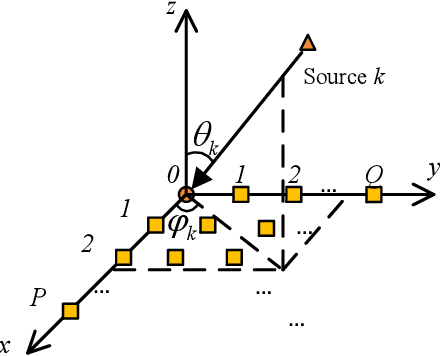
Joint communication and sensing (JCS) has become a promising technology for mobile networks because of its higher spectrum and energy efficiency. Up to now, the prevalent fast Fourier transform (FFT)-based sensing method for mobile JCS networks is on-grid based, and the grid interval determines the resolution. Because the mobile network usually has limited consecutive OFDM symbols in a downlink (DL) time slot, the sensing accuracy is restricted by the limited resolution, especially for velocity estimation. In this paper, we propose a multiple signal classification (MUSIC)-based JCS system that can achieve higher sensing accuracy for the angle of arrival, range, and velocity estimation, compared with the traditional FFT-based JCS method. We further propose a JCS channel state information (CSI) enhancement method by leveraging the JCS sensing results. Finally, we derive a theoretical lower bound for sensing mean square error (MSE) by using perturbation analysis. Simulation results show that in terms of the sensing MSE performance, the proposed MUSIC-based JCS outperforms the FFT-based one by more than 20 dB. Moreover, the bit error rate (BER) of communication demodulation using the proposed JCS CSI enhancement method is significantly reduced compared with communication using the originally estimated CSI.
Downlink and Uplink Cooperative Joint Communication and Sensing
Nov 08, 2022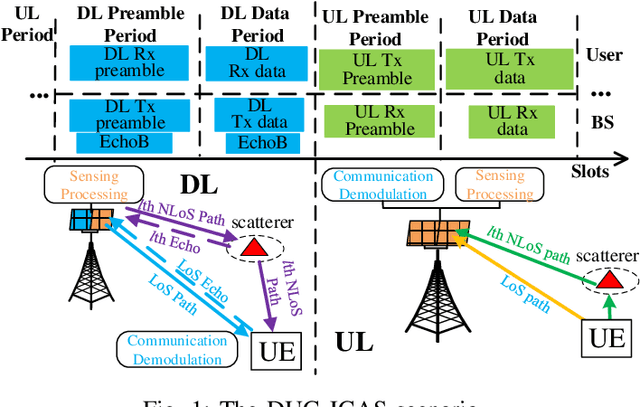
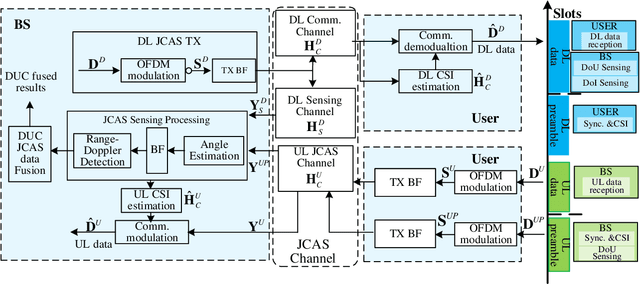
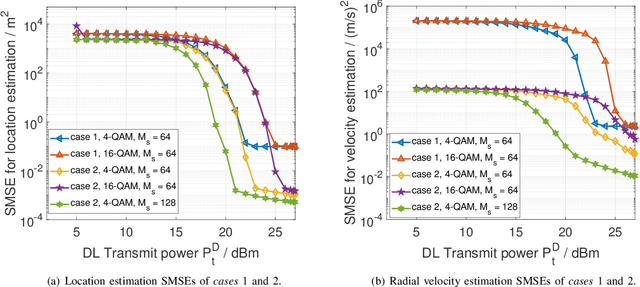
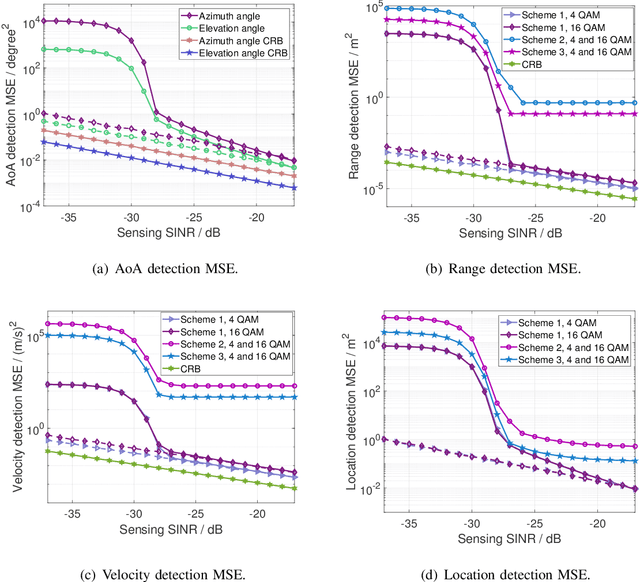
Downlink (DL) and uplink (UL) joint communication and sensing (JCAS) technologies have been individually studied for realizing sensing using DL and UL communication signals, respectively. Since the spatial environment and JCAS channels in the consecutive DL and UL JCAS time slots are generally unchanged, DL and UL JCAS may be jointly designed to achieve better sensing performance. In this paper, we propose a novel DL and UL cooperative (DUC) JCAS scheme, including a unified multiple signal classification (MUSIC)-based JCAS sensing scheme for both DL and UL JCAS and a DUC JCAS fusion method. The unified MUSIC JCAS sensing scheme can accurately estimate AoA, range, and Doppler based on a unified MUSIC-based sensing module. The DUC JCAS fusion method can distinguish between the sensing results of the communication user and other dumb targets. Moreover, by exploiting the channel reciprocity, it can also improve the sensing and channel state information (CSI) estimation accuracy. Extensive simulation results validate the proposed DUC JCAS scheme. It is shown that the minimum location and velocity estimation mean square errors of the proposed DUC JCAS scheme are about 20 dB lower than those of the state-of-the-art separated DL and UL JCAS schemes.
Continuous longitudinal fetus brain atlas construction via implicit neural representation
Sep 14, 2022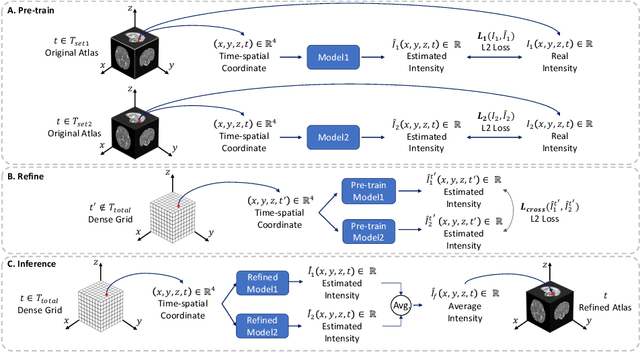
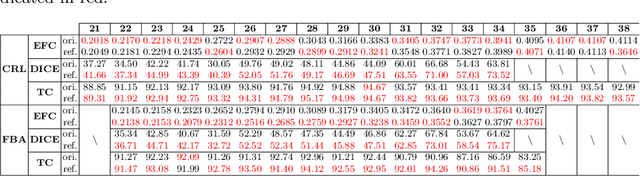
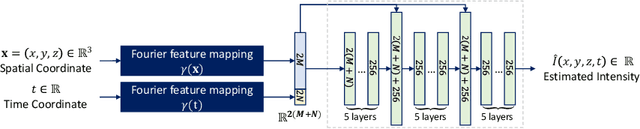
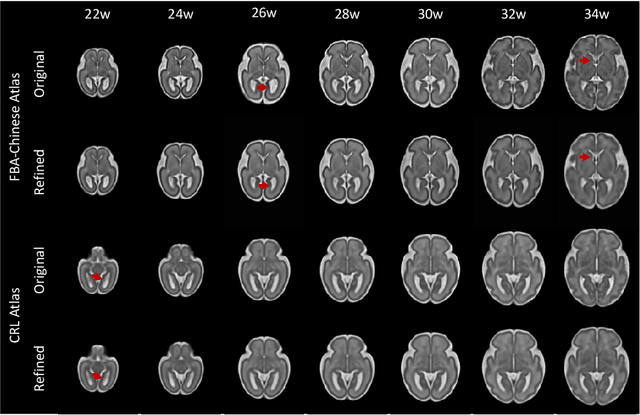
Longitudinal fetal brain atlas is a powerful tool for understanding and characterizing the complex process of fetus brain development. Existing fetus brain atlases are typically constructed by averaged brain images on discrete time points independently over time. Due to the differences in onto-genetic trends among samples at different time points, the resulting atlases suffer from temporal inconsistency, which may lead to estimating error of the brain developmental characteristic parameters along the timeline. To this end, we proposed a multi-stage deep-learning framework to tackle the time inconsistency issue as a 4D (3D brain volume + 1D age) image data denoising task. Using implicit neural representation, we construct a continuous and noise-free longitudinal fetus brain atlas as a function of the 4D spatial-temporal coordinate. Experimental results on two public fetal brain atlases (CRL and FBA-Chinese atlases) show that the proposed method can significantly improve the atlas temporal consistency while maintaining good fetus brain structure representation. In addition, the continuous longitudinal fetus brain atlases can also be extensively applied to generate finer 4D atlases in both spatial and temporal resolution.
Enhancing Flood Forecasting with Dual State-Parameter Estimation and Ensemble-based SAR Data Assimilation
Nov 14, 2022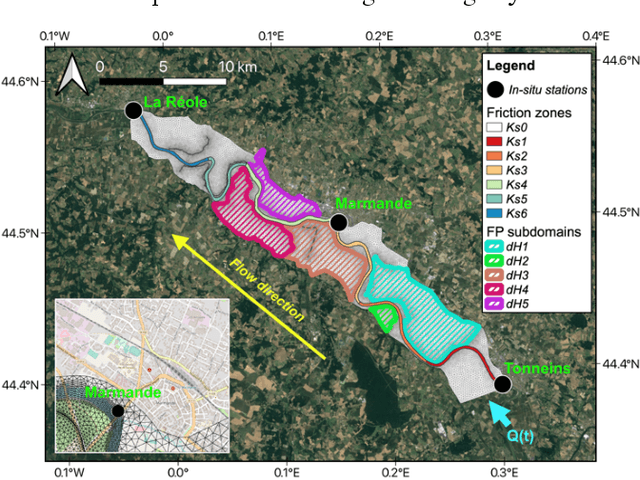
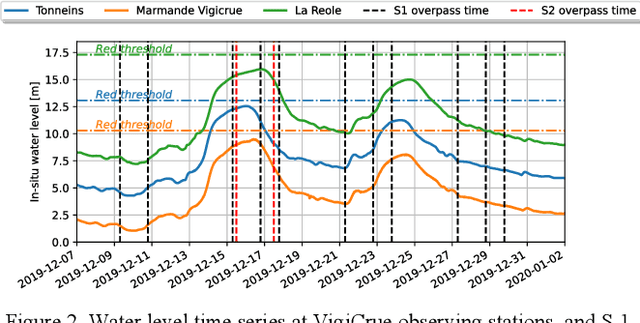
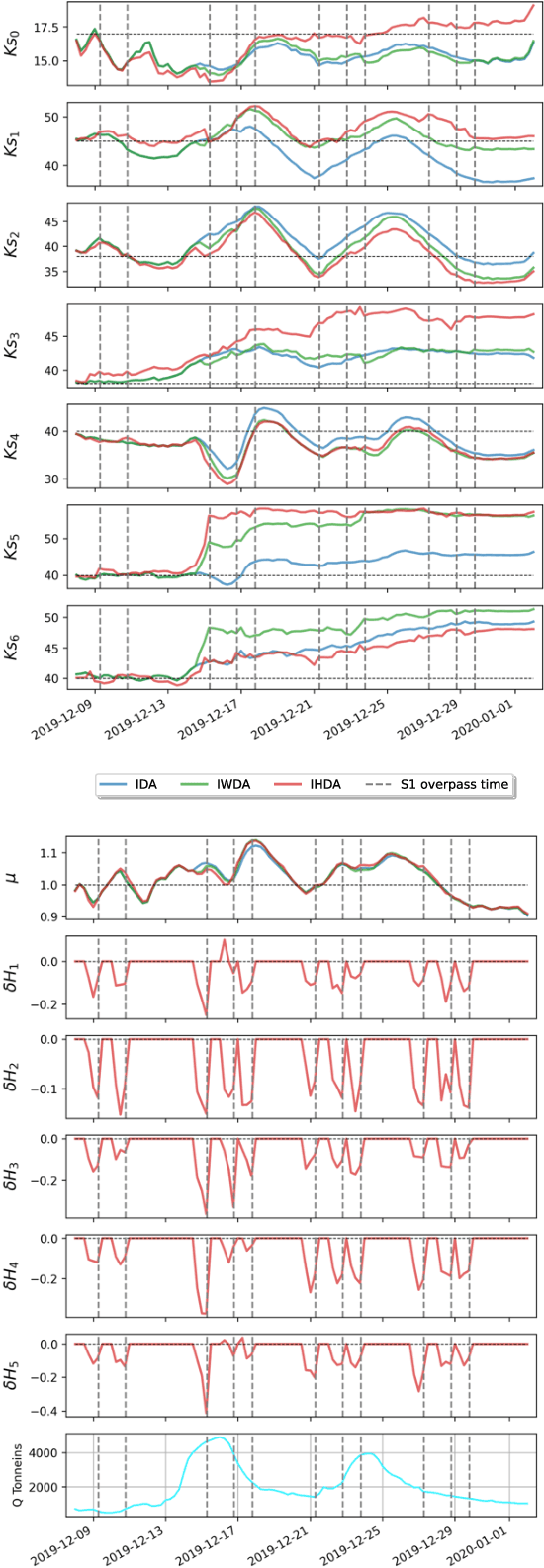
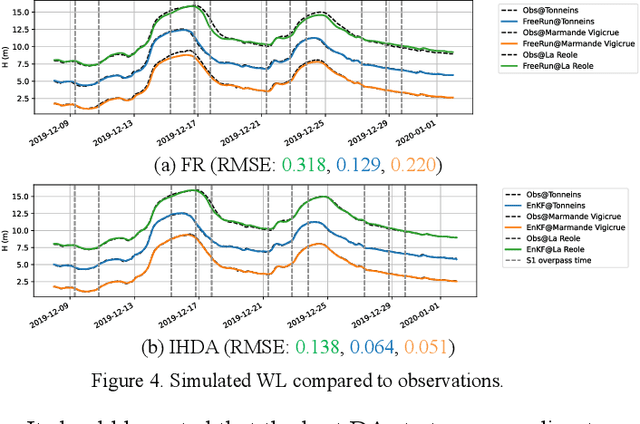
Ensemble data assimilation in flood forecasting depends strongly on the density, frequency and statistics of errors associated with the observation network. This work focuses on the assimilation of 2D flood extent data, expressed in terms of wet surface ratio, in addition to the in-situ water level data. The objective is to improve the representation of the flood plain dynamics with a TELEMAC-2D model and an Ensemble Kalman Filter (EnKF). The EnKF control vector is composed of friction coefficients and corrective parameters to the input forcing. It is augmented with the water level state averaged over selected subdomains of the floodplain. This work focuses on the 2019 flood event that occurred over the Garonne Marmandaise catchment. The merits of assimilating SAR-derived flood plain data complementary to in-situ water level observations are shown in the control parameter and observation spaces with 1D and 2D assessment metrics. It was also shown that the assimilation of Wet surface Ratio in the flood plain complementary to in-situ data in the river bed brings significative improvement when a corrective term on flood plain hydraulic state is included in the control vector. Yet, it has barely no impact in the river bed that is sufficiently well described by in-situ data. We highlighted that the correction of the hydraulic state in the flood plain significantly improved the flood dynamics, especially during the recession. This proof-of-concept study paves the way towards near-real-time flood forecast, making the most of remote sensing-derived flood observations.