 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Iterative Vision-and-Language Navigation
Oct 06, 2022
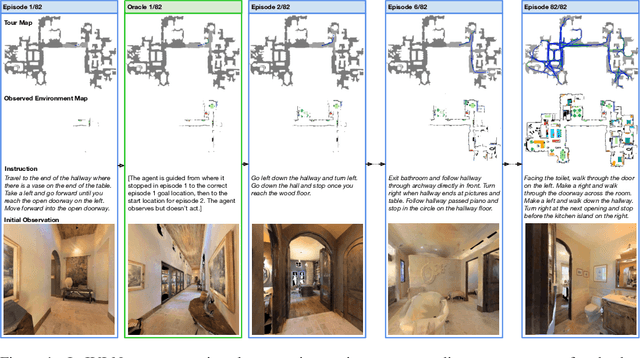
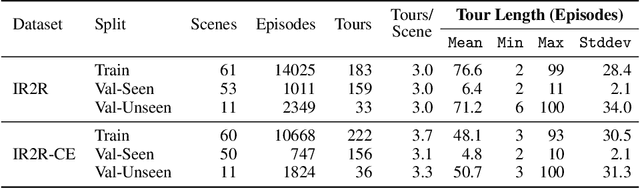
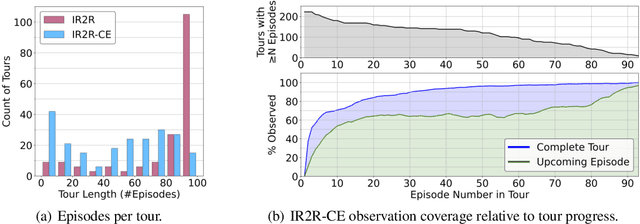

We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent's memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
Learning many-body Hamiltonians with Heisenberg-limited scaling
Oct 06, 2022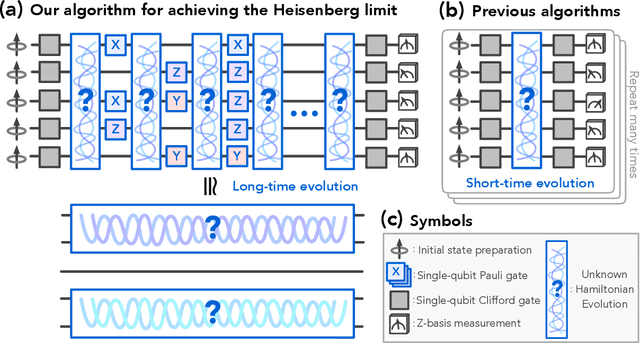
Learning a many-body Hamiltonian from its dynamics is a fundamental problem in physics. In this work, we propose the first algorithm to achieve the Heisenberg limit for learning an interacting $N$-qubit local Hamiltonian. After a total evolution time of $\mathcal{O}(\epsilon^{-1})$, the proposed algorithm can efficiently estimate any parameter in the $N$-qubit Hamiltonian to $\epsilon$-error with high probability. The proposed algorithm is robust against state preparation and measurement error, does not require eigenstates or thermal states, and only uses $\mathrm{polylog}(\epsilon^{-1})$ experiments. In contrast, the best previous algorithms, such as recent works using gradient-based optimization or polynomial interpolation, require a total evolution time of $\mathcal{O}(\epsilon^{-2})$ and $\mathcal{O}(\epsilon^{-2})$ experiments. Our algorithm uses ideas from quantum simulation to decouple the unknown $N$-qubit Hamiltonian $H$ into noninteracting patches, and learns $H$ using a quantum-enhanced divide-and-conquer approach. We prove a matching lower bound to establish the asymptotic optimality of our algorithm.
SpikeSim: An end-to-end Compute-in-Memory Hardware Evaluation Tool for Benchmarking Spiking Neural Networks
Oct 24, 2022
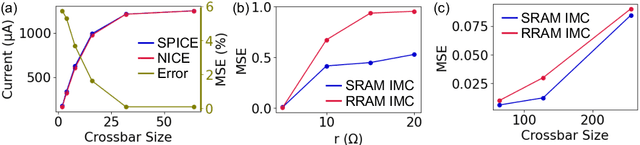
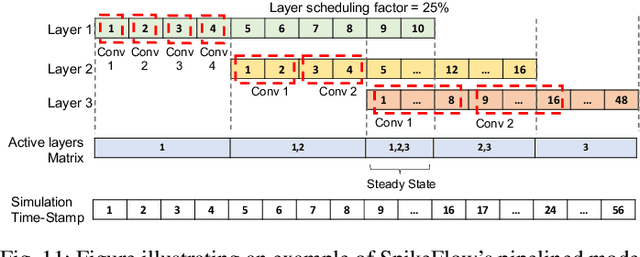
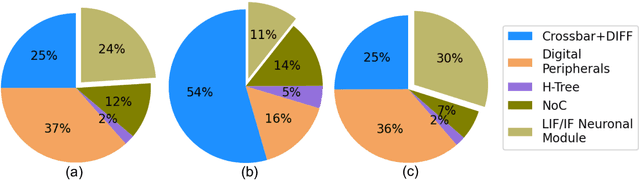
SNNs are an active research domain towards energy efficient machine intelligence. Compared to conventional ANNs, SNNs use temporal spike data and bio-plausible neuronal activation functions such as Leaky-Integrate Fire/Integrate Fire (LIF/IF) for data processing. However, SNNs incur significant dot-product operations causing high memory and computation overhead in standard von-Neumann computing platforms. Today, In-Memory Computing (IMC) architectures have been proposed to alleviate the "memory-wall bottleneck" prevalent in von-Neumann architectures. Although recent works have proposed IMC-based SNN hardware accelerators, the following have been overlooked- 1) the adverse effects of crossbar non-ideality on SNN performance due to repeated analog dot-product operations over multiple time-steps, 2) hardware overheads of essential SNN-specific components such as the LIF/IF and data communication modules. To this end, we propose SpikeSim, a tool that can perform realistic performance, energy, latency and area evaluation of IMC-mapped SNNs. SpikeSim consists of a practical monolithic IMC architecture called SpikeFlow for mapping SNNs. Additionally, the non-ideality computation engine (NICE) and energy-latency-area (ELA) engine performs hardware-realistic evaluation of SpikeFlow-mapped SNNs. Based on 65nm CMOS implementation and experiments on CIFAR10, CIFAR100 and TinyImagenet datasets, we find that the LIF/IF neuronal module has significant area contribution (>11% of the total hardware area). We propose SNN topological modifications leading to 1.24x and 10x reduction in the neuronal module's area and the overall energy-delay-product value, respectively. Furthermore, in this work, we perform a holistic comparison between IMC implemented ANN and SNNs and conclude that lower number of time-steps are the key to achieve higher throughput and energy-efficiency for SNNs compared to 4-bit ANNs.
Context-Situated Pun Generation
Oct 24, 2022
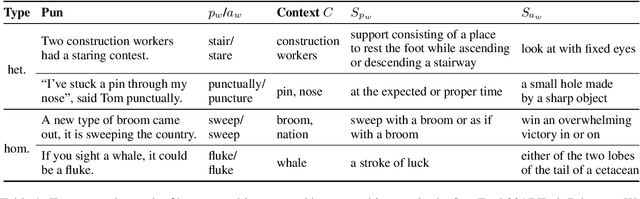
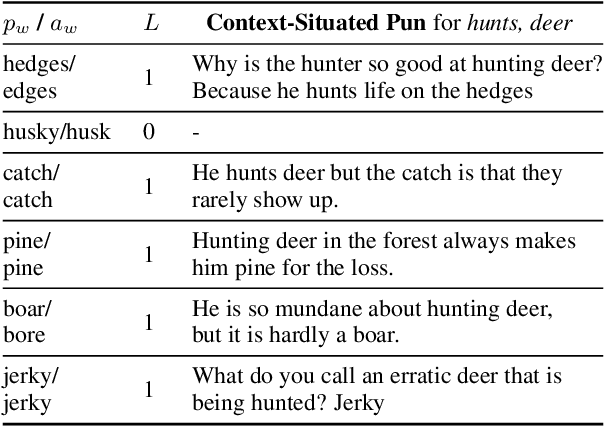
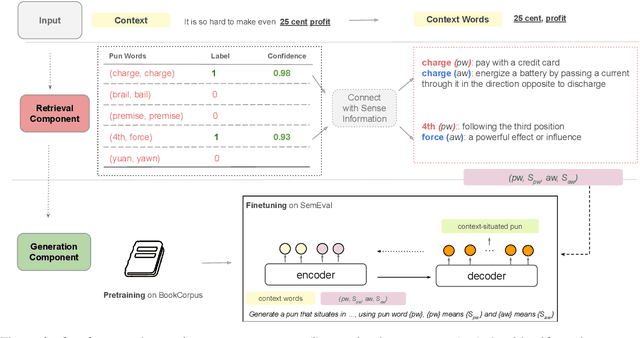
Previous work on pun generation commonly begins with a given pun word (a pair of homophones for heterographic pun generation and a polyseme for homographic pun generation) and seeks to generate an appropriate pun. While this may enable efficient pun generation, we believe that a pun is most entertaining if it fits appropriately within a given context, e.g., a given situation or dialogue. In this work, we propose a new task, context-situated pun generation, where a specific context represented by a set of keywords is provided, and the task is to first identify suitable pun words that are appropriate for the context, then generate puns based on the context keywords and the identified pun words. We collect CUP (Context-sitUated Pun), containing 4.5k tuples of context words and pun pairs. Based on the new data and setup, we propose a pipeline system for context-situated pun generation, including a pun word retrieval module that identifies suitable pun words for a given context, and a generation module that generates puns from context keywords and pun words. Human evaluation shows that 69% of our top retrieved pun words can be used to generate context-situated puns, and our generation module yields successful puns 31% of the time given a plausible tuple of context words and pun pair, almost tripling the yield of a state-of-the-art pun generation model. With an end-to-end evaluation, our pipeline system with the top-1 retrieved pun pair for a given context can generate successful puns 40% of the time, better than all other modeling variations but 32% lower than the human success rate. This highlights the difficulty of the task, and encourages more research in this direction.
PAL: Program-aided Language Models
Nov 18, 2022



Large language models (LLMs) have recently demonstrated an impressive ability to perform arithmetic and symbolic reasoning tasks when provided with a few examples at test time (few-shot prompting). Much of this success can be attributed to prompting methods for reasoning, such as chain-of-thought, that employ LLMs for both understanding the problem description by decomposing it into steps, as well as solving each step of the problem. While LLMs seem to be adept at this sort of step-by-step decomposition, LLMs often make logical and arithmetic mistakes in the solution part, even when the problem is correctly decomposed. We present Program-Aided Language models (PaL): a new method that uses the LLM to understand natural language problems and generate programs as the intermediate reasoning steps, but offloads the solution step to a programmatic runtime such as a Python interpreter. With PaL, decomposing the natural language problem into runnable steps remains the only learning task for the LLM, while solving is delegated to the interpreter. We experiment with 12 reasoning tasks from BIG-Bench Hard and other benchmarks, including mathematical reasoning, symbolic reasoning, and algorithmic problems. In all these natural language reasoning tasks, generating code using an LLM and reasoning using a Python interpreter leads to more accurate results than much larger models, and we set new state-of-the-art results in all 12 benchmarks. For example, PaL using Codex achieves state-of-the-art few-shot accuracy on the GSM benchmark of math word problems when the model is allowed only a single decoding, surpassing PaLM-540B with chain-of-thought prompting by an absolute 8% .In three reasoning tasks from the BIG-Bench Hard benchmark, PaL outperforms CoT by 11%. On GSM-hard, a more challenging version of GSM that we create, PaL outperforms chain-of-thought by an absolute 40%.
TensAIR: Online Learning from Data Streams via Asynchronous Iterative Routing
Nov 18, 2022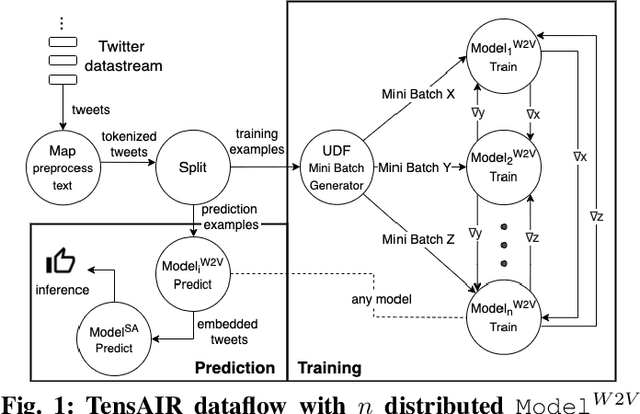
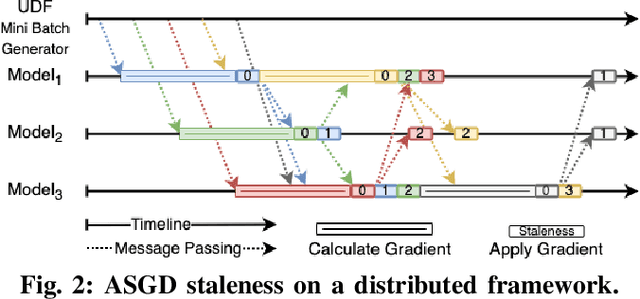
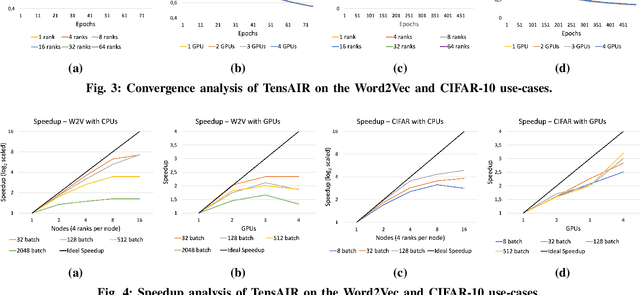
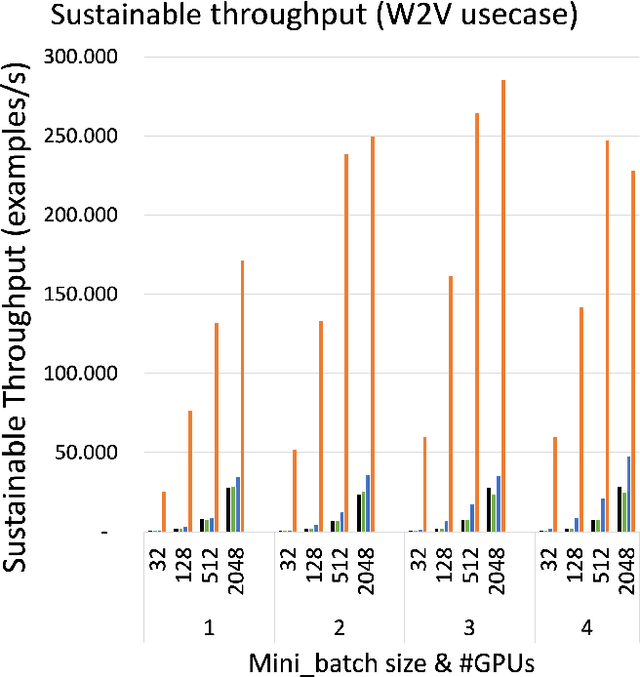
Online learning (OL) from data streams is an emerging area of research that encompasses numerous challenges from stream processing, machine learning, and networking. Recent extensions of stream-processing platforms, such as Apache Kafka and Flink, already provide basic extensions for the training of neural networks in a stream-processing pipeline. However, these extensions are not scalable and flexible enough for many real-world use-cases, since they do not integrate the neural-network libraries as a first-class citizen into their architectures. In this paper, we present TensAIR, which provides an end-to-end dataflow engine for OL from data streams via a protocol to which we refer as asynchronous iterative routing. TensAIR supports the common dataflow operators, such as Map, Reduce, Join, and has been augmented by the data-parallel OL functions train and predict. These belong to the new Model operator, in which an initial TensorFlow model (either freshly initialized or pre-trained) is replicated among multiple decentralized worker nodes. Our decentralized architecture allows TensAIR to efficiently shard incoming data batches across the distributed model replicas, which in turn trigger the model updates via asynchronous stochastic gradient descent. We empirically demonstrate that TensAIR achieves a nearly linear scale-out in terms of (1) the number of worker nodes deployed in the network, and (2) the throughput at which the data batches arrive at the dataflow operators. We exemplify the versatility of TensAIR by investigating both sparse (Word2Vec) and dense (CIFAR-10) use-cases, for which we are able to demonstrate very significant performance improvements in comparison to Kafka, Flink, and Horovod. We also demonstrate the magnitude of these improvements by depicting the possibility of real-time concept drift adaptation of a sentiment analysis model trained over a Twitter stream.
Improving Pixel-Level Contrastive Learning by Leveraging Exogenous Depth Information
Nov 18, 2022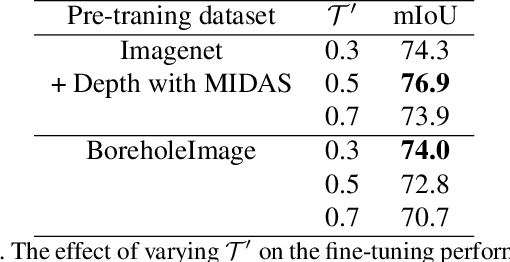
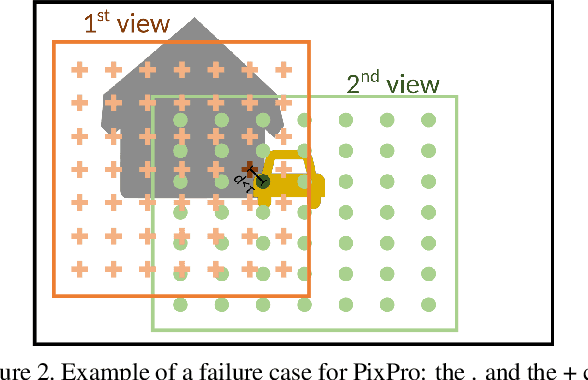
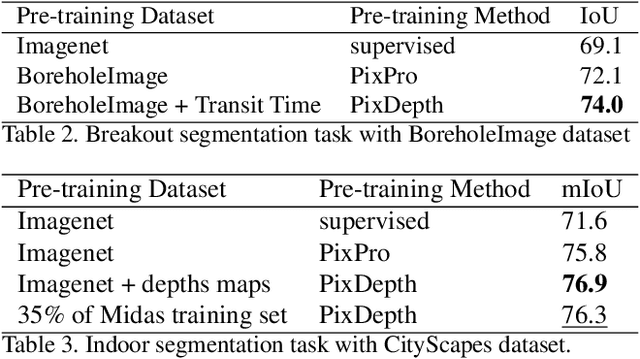
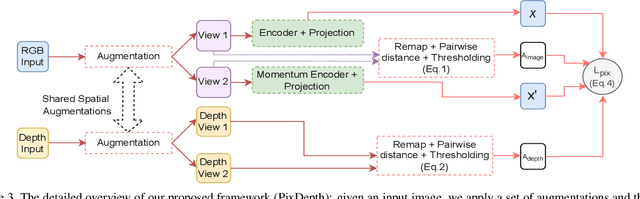
Self-supervised representation learning based on Contrastive Learning (CL) has been the subject of much attention in recent years. This is due to the excellent results obtained on a variety of subsequent tasks (in particular classification), without requiring a large amount of labeled samples. However, most reference CL algorithms (such as SimCLR and MoCo, but also BYOL and Barlow Twins) are not adapted to pixel-level downstream tasks. One existing solution known as PixPro proposes a pixel-level approach that is based on filtering of pairs of positive/negative image crops of the same image using the distance between the crops in the whole image. We argue that this idea can be further enhanced by incorporating semantic information provided by exogenous data as an additional selection filter, which can be used (at training time) to improve the selection of the pixel-level positive/negative samples. In this paper we will focus on the depth information, which can be obtained by using a depth estimation network or measured from available data (stereovision, parallax motion, LiDAR, etc.). Scene depth can provide meaningful cues to distinguish pixels belonging to different objects based on their depth. We show that using this exogenous information in the contrastive loss leads to improved results and that the learned representations better follow the shapes of objects. In addition, we introduce a multi-scale loss that alleviates the issue of finding the training parameters adapted to different object sizes. We demonstrate the effectiveness of our ideas on the Breakout Segmentation on Borehole Images where we achieve an improvement of 1.9\% over PixPro and nearly 5\% over the supervised baseline. We further validate our technique on the indoor scene segmentation tasks with ScanNet and outdoor scenes with CityScapes ( 1.6\% and 1.1\% improvement over PixPro respectively).
OSS Mentor A framework for improving developers contributions via deep reinforcement learning
Oct 24, 2022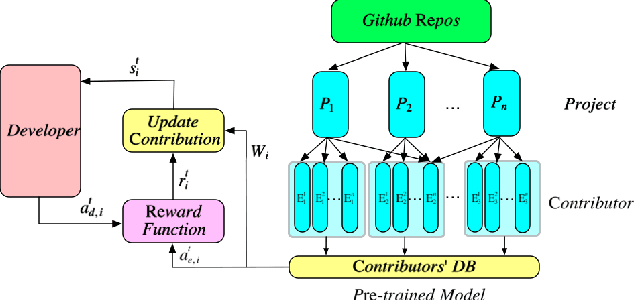
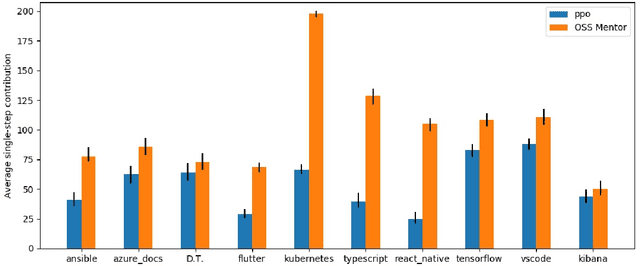
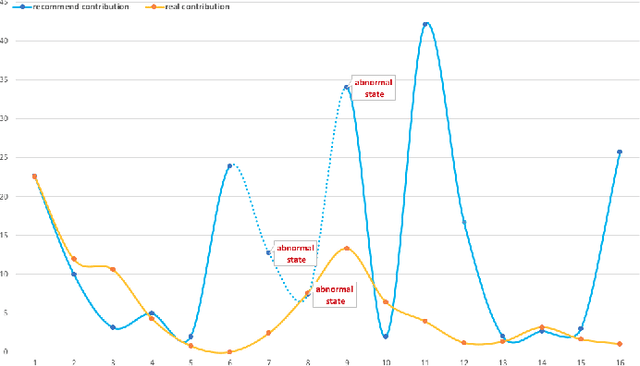
In open source project governance, there has been a lot of concern about how to measure developers' contributions. However, extremely sparse work has focused on enabling developers to improve their contributions, while it is significant and valuable. In this paper, we introduce a deep reinforcement learning framework named Open Source Software(OSS) Mentor, which can be trained from empirical knowledge and then adaptively help developers improve their contributions. Extensive experiments demonstrate that OSS Mentor significantly outperforms excellent experimental results. Moreover, it is the first time that the presented framework explores deep reinforcement learning techniques to manage open source software, which enables us to design a more robust framework to improve developers' contributions.
Learning Adaptive Evolutionary Computation for Solving Multi-Objective Optimization Problems
Nov 01, 2022
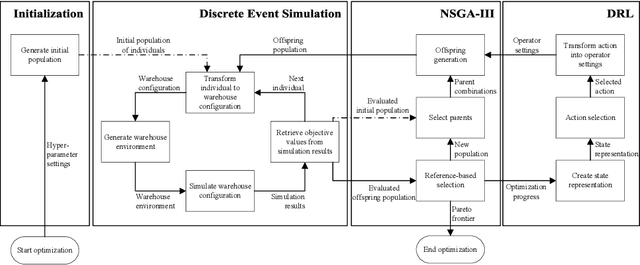
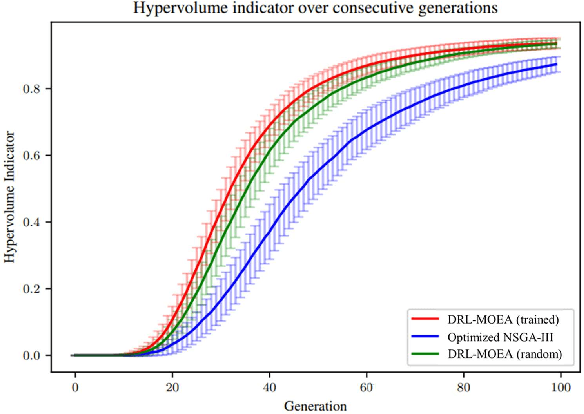
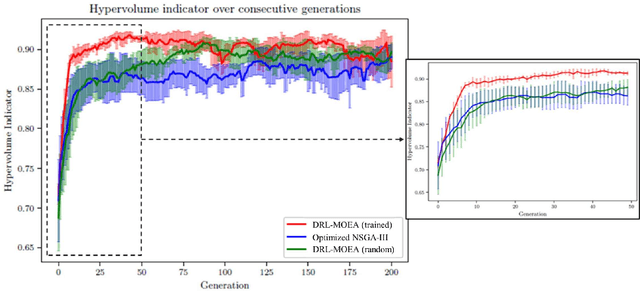
Multi-objective evolutionary algorithms (MOEAs) are widely used to solve multi-objective optimization problems. The algorithms rely on setting appropriate parameters to find good solutions. However, this parameter tuning could be very computationally expensive in solving non-trial (combinatorial) optimization problems. This paper proposes a framework that integrates MOEAs with adaptive parameter control using Deep Reinforcement Learning (DRL). The DRL policy is trained to adaptively set the values that dictate the intensity and probability of mutation for solutions during optimization. We test the proposed approach with a simple benchmark problem and a real-world, complex warehouse design and control problem. The experimental results demonstrate the advantages of our method in terms of solution quality and computation time to reach good solutions. In addition, we show the learned policy is transferable, i.e., the policy trained on a simple benchmark problem can be directly applied to solve the complex warehouse optimization problem, effectively, without the need for retraining.
Evaluating Impact of Social Media Posts by Executives on Stock Prices
Nov 01, 2022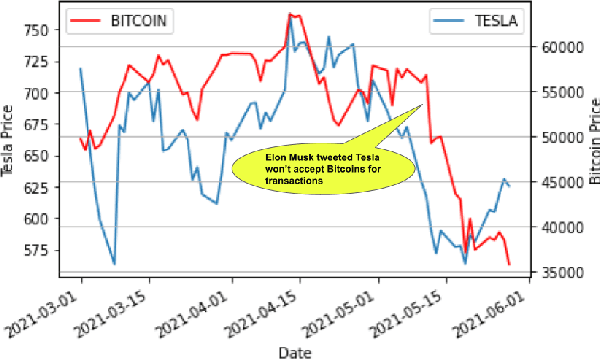
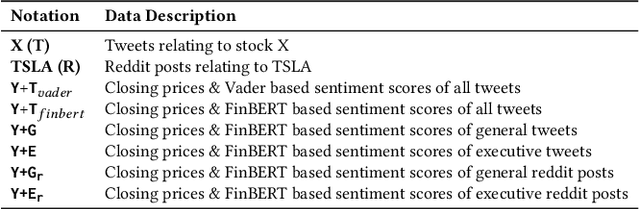
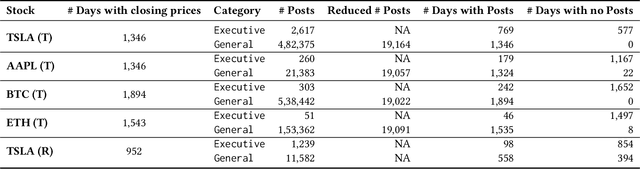
Predicting stock market movements has always been of great interest to investors and an active area of research. Research has proven that popularity of products is highly influenced by what people talk about. Social media like Twitter, Reddit have become hotspots of such influences. This paper investigates the impact of social media posts on close price prediction of stocks using Twitter and Reddit posts. Our objective is to integrate sentiment of social media data with historical stock data and study its effect on closing prices using time series models. We carried out rigorous experiments and deep analysis using multiple deep learning based models on different datasets to study the influence of posts by executives and general people on the close price. Experimental results on multiple stocks (Apple and Tesla) and decentralised currencies (Bitcoin and Ethereum) consistently show improvements in prediction on including social media data and greater improvements on including executive posts.